le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Abbiamo parlato in precedenza delle conoscenze di base come puntatori e strutture. All'inizio di questo articolo faremo alcune applicazioni complesse di queste conoscenze di base, come le code.
Infatti, nel 2018, ho registrato una serie di video sull'architettura dei programmi, che includevano tutorial passo passo sulla formazione delle code e una serie di idee e tecniche pratiche di programmazione di alto livello. È stata ben accolta e riconosciuta da molti fan amici. .
Tuttavia, poiché il tutorial è stato registrato relativamente presto, la qualità del suono è relativamente scarsa e alcuni dettagli non sono perfetti. Pertanto, questa spina è sempre stata conficcata nel mio cuore, per consentire agli irriducibili del campo di addestramento speciale per microcontrollori Wuji di apprendere i nostri progetti in modo più efficiente e migliore, di recente ho intenzione di riorganizzare questi contenuti di base e trasformarli in una serie di. tutorial grafici/video sull'architettura software 2.0.
Quando lavoravo come ingegnere di ricerca e sviluppo, mi imbattevo spesso in alcuni prodotti di comunicazione, come schede di controllo industriale, PDU e Internet delle cose.
In generale, quando si realizza questo tipo di prodotto, sarà un mal di testa durante la scrittura e la ricezione di flussi di dati, sia che si tratti di comunicazione seriale o wireless.
Ad esempio, STM32 riceve il flusso di dati della porta seriale.
All'inizio ho definito un array e una variabile di indice dell'array per elaborare il flusso di dati ricevuto. Il codice è il seguente:

Questo metodo presenta molti problemi e aumenta la complessità degli ingegneri che scrivono codice.
La manutenzione del codice è complessa
Poiché è necessario controllare manualmente i limiti del buffer dell'array per evitare errori fuori limite, gli array non sono facili da espandere e gestire come le code quando è necessario elaborare flussi di dati più complessi o aggiungere nuove origini dati.
I dati sono soggetti a confusione
Gli array che operano direttamente in un servizio di interruzione (ISR) possono causare competizione tra le risorse con il programma principale. Se più attività accedono allo stesso array, sono necessari meccanismi di sincronizzazione aggiuntivi (come i blocchi mutex) per evitare condizioni di competizione dei dati e incoerenze.
Se la ricezione e l'elaborazione dei dati non sono sincronizzate, l'utilizzo degli array può causare confusione nell'ordine dei dati, con conseguente perdita di pacchetti di dati causata da problemi del programma. Ho già avuto a che fare con questo problema. Ho bisogno di codice aggiuntivo per risolverlo, il che aumenta la complessità del programma. Inoltre, non ho esperienza e non è stabile realizzarlo dopo tutto lo sforzo.
Questo tipo di problema mi ha infastidito per molto tempo. È stato solo quando ho cambiato lavoro in seguito e ho letto il codice scritto da altri ingegneri che ho capito che le code possono risolvere questi punti critici. Da allora, il modo in cui gestisco il flusso di dati è diventato il seguente:

Sembra molto più semplice? In effetti, l'algoritmo di elaborazione dei dati della coda non è semplice: utilizza semplicemente la coda per creare un modello generale per l'elaborazione dei dati. La prossima volta che incontri esigenze simili, puoi utilizzarlo direttamente il codice. Più riutilizzabile.
Questa è solo una delle applicazioni delle code. L'essenza delle code è la memorizzazione nella cache dei dati e l'eliminazione delle code segue la regola first-in, first-out.
Ciò significa prima memorizzare i dati, quindi prelevarli per l'elaborazione quando la CPU ha tempo libero o quando vengono soddisfatte determinate condizioni del programma.
Sulla base di questa caratteristica si possono derivare molte applicazioni pratiche. Soprattutto quando si ha a che fare con applicazioni che devono garantire l'ordine dei dati.
Ho riassunto alcuni dei posti che utilizzo di più.
Quando il microcontrollore riceve i dati tramite la porta seriale, solitamente utilizza una coda per bufferizzare i byte ricevuti, il che garantisce che i dati non vadano persi prima di essere elaborati dal programma principale.
Nei dispositivi di riproduzione o registrazione audio, le code vengono utilizzate per memorizzare nel buffer i dati dei campioni audio per implementare la riproduzione o la registrazione passo passo. Ad esempio: nel Progetto 6 del nostro campo di addestramento speciale per microcontrollori Wuji, l'host di allarme WiFi e 4G ha una funzione di comando vocale. Ad esempio, se si preme il pulsante di inserimento fuori casa, verrà emessa la voce "attivazione fuori casa". verrà riprodotto e se viene premuto il pulsante di inserimento in casa, verrà riprodotta la voce "inserimento in casa".

Se premo velocemente questi due pulsanti, per assicurarmi che la voce possa essere riprodotta completamente, posso prima inserire l'evento chiave nella cache della coda, in modo che la voce possa essere riprodotta completamente in sequenza.
Nei sistemi che utilizzano RTOS, le code vengono utilizzate per la consegna dei messaggi e la sincronizzazione tra le attività e supportano la pianificazione di attività complesse.
Dopo aver rilevato gli eventi chiave, è possibile metterli prima in coda e il programma principale può elaborarli per evitare che gli eventi chiave vadano persi a causa della pressione troppo veloce dei tasti. Questo è attualmente utilizzato nel nostro progetto.
I dati ADC che raccogliamo possono anche essere messi in coda dopo una determinata elaborazione in modo che possano essere elaborati o analizzati al momento opportuno.
L'interazione dei dati dell'aggiornamento del firmware è relativamente ampia, il che è molto adatto per l'utilizzo delle code per garantire l'integrità dei dati. Viene utilizzato anche nel nostro progetto 6. Durante il processo di aggiornamento del firmware, i blocchi di dati del firmware scaricati possono essere messi in coda e quindi. scritti nella memoria flash in sequenza. Esistono molte applicazioni simili. Tutto sommato, le code mi hanno risolto molti problemi difficili.
La coda è una struttura dati lineare che segue il principio FIFO (first-in-first-out), ovvero i primi dati ad entrare nella coda saranno i primi ad essere rimossi. In una coda, i dati vengono solitamente inseriti nella coda a un'estremità, chiamata coda della coda, e i dati vengono rimossi dalla coda all'altra estremità, chiamata testa della coda. Questa struttura rende le code molto adatte a situazioni in cui i dati devono essere elaborati in modo ordinato.

Possiamo pensare alla coda come all'inserimento di palline da ping pong in un tubo a due vie. Inseriamo palline da ping pong nel tubo da sinistra. Tiriamo fuori la pallina da ping pong dal lato destro del tubo. Questa azione si chiama rimozione della coda.
Le palline da ping pong nel tubo si allineeranno in formazione. La pallina da ping pong che entra per prima uscirà per prima. Questa è la regola first-in-first-out in coda.
Le palline da ping-pong vengono confrontate con i dati. La pipeline è una cache che memorizza i dati. Il numero di palline da ping-pong che la pipeline può contenere indica la quantità di dati che la cache può archiviare. La coda nell'immagine sopra può memorizzare 4 dati. È equivalente a Buff[4].
L'implementazione del programma della coda avviene tramite un array di dimensione fissa, un puntatore head e un puntatore tail. Gli array sono responsabili della memorizzazione dei dati. Il puntatore head è responsabile dell'indirizzo da cui i dati devono essere prelevati durante la rimozione dalla coda. Il puntatore di coda è responsabile dell'indirizzo in cui devono essere archiviati i dati quando vengono accodati. Pertanto, le operazioni di accodamento e di rimozione dalla coda sono due puntatori, che riproducono l'algoritmo first-in-first-out dei dati nell'array.
Diversi ingegneri implementano i codici di coda in modo diverso. Se non hai una ricca esperienza di progetto o se non hai mai utilizzato le code in precedenza, non essere imbarazzato perché devi essere in grado di scrivere l'algoritmo della coda.
Quando ho iniziato, ho anche trapiantato direttamente i programmi di coda di altre persone e ho continuato a usarli nei miei progetti. Dopo averli utilizzati con competenza in diversi progetti, ho studiato il codice dettagliato dell'implementazione dell'algoritmo di coda e l'ho scritto io stesso alcune volte.
Pertanto, veterani del nostro campo di addestramento speciale, non scrivetelo voi stessi all'inizio, imparate prima a usarlo, trarrete deduzioni da un esempio, applicatelo a diversi scenari e progetti e poi provate a scriverlo voi stessi dopo aver acquisito familiarità. con esso. Questa è una sequenza di apprendimento molto importante.
Prendi come esempio il programma di coda del nostro campo di formazione speciale del progetto Infinite Microcontroller. Ci sono 4 funzioni in totale.
Coda vuota(x)
Cancella la funzione della coda Prima di ogni utilizzo della coda, la coda deve essere cancellata. La funzione cancella farà sì che il puntatore head e il puntatore tail puntino a un indirizzo valido per impostazione predefinita, che è il primo elemento dell'array si verificherà un'eccezione dell'indirizzo.
Descrizione formale del parametro: x - è una variabile della struttura della coda
QueueDataIn(x,y,z)
La funzione di accodamento dei dati consiste nell'inserire uno o più byte di dati nella coda specificata.
Descrizione formale dei parametri:
x - Variabile della struttura della coda
y - indirizzo dati
z - La quantità di dati da accodare, in byte.
Avviso:
①.I dati inseriti possono essere solo di tipo unsigned char.
② Se la coda è piena e i dati continuano ad essere in coda, i dati verranno sovrascritti dalla prima posizione dati.
QueueDataOut(x,y)
La funzione di rimozione della coda dei dati consiste nel prendere un byte di dati dalla coda specificata.
Descrizione formale dei parametri: x - Variabile della struttura della coda y - I dati prelevati, l'indirizzo da memorizzare
Nota: la nostra funzione di rimozione dalla coda può accettare solo un byte di dati alla volta.
LunghezzaDatiCoda(x)
Cancella tutti i dati nella coda specificata. Descrizione formale dei parametri: x - variabile della struttura della coda
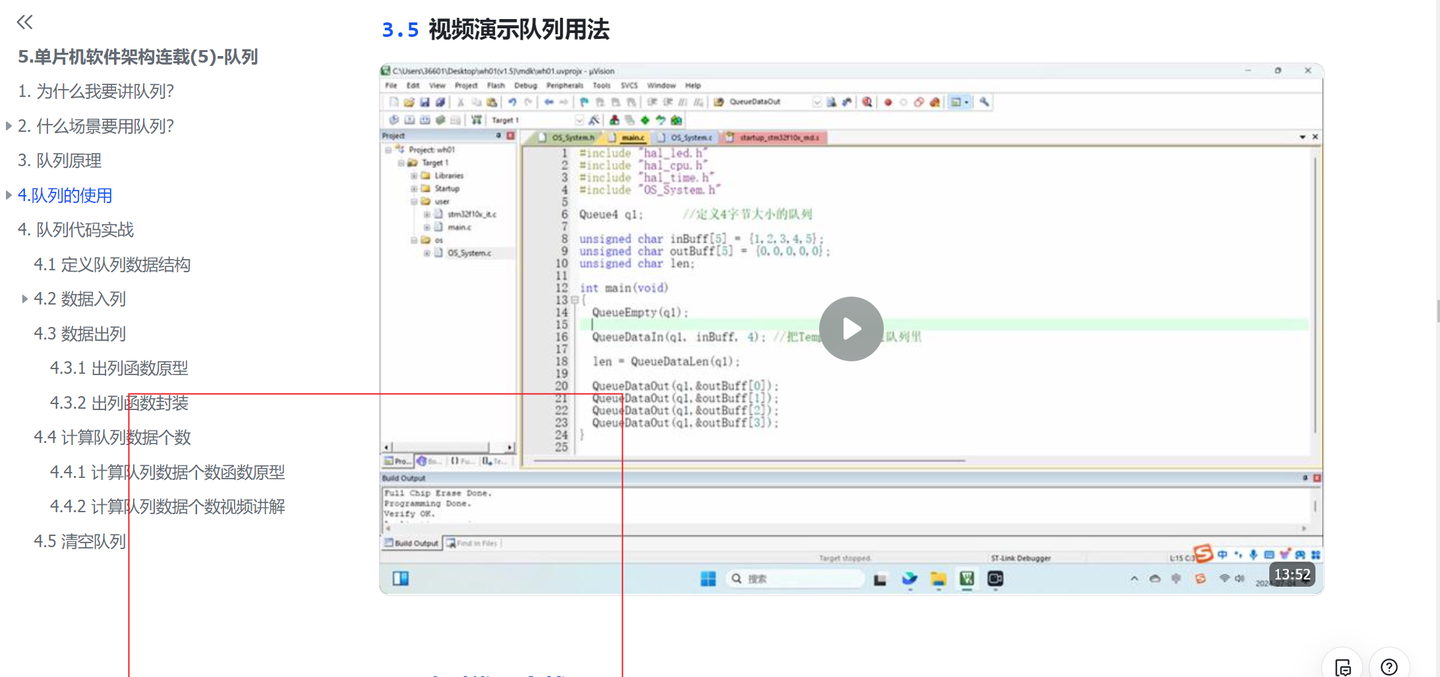
Il seguente contenuto prevede alcune spiegazioni di codice e video, che sono scomode da modificare. Puoi contattarmi per organizzare Feishu per una migliore esperienza di lettura.
Recentemente, molti fan mi hanno chiesto come imparare i microcontrollori. Sulla base della mia esperienza decennale nel settore, ho trascorso un mese e ho compilato attentamente un "microcomputer a chip singolo".
Il miglior percorso di apprendimento per microcontrollori + tutorial da livello base a avanzato per microcontrollori + toolkit", Tutto condiviso gratuitamente con i fan più accaniti! ! !
A parte questo, condivido in lacrime ciò che ho in fondo alla mia scatola22 popolari progetti open source,IncludereCodice sorgente + schema + PCB + documentazione, lascia che tuDiventa un maestro rapidamente!

Per pacchetti tutorial e percorsi di apprendimento dettagliati, contattamiL'inizio di questo articolo qui sotto。

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]