내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗
🌻 近期刚转战 CSDN,会严格把控文章质量,绝不滥竽充数,欢迎多多交流。👍
이 기사에서는 블로거 회사에서 권장하는 중요 가치 처리 조치와 범위 교정 구현 계획을 공유합니다.
주로 기반으로카프카 + Flink + Elasticsearch 구현 보안 문제가 포함되어 있으므로 주로 솔루션 소개에 대한 내용을 논의해야 할 경우 메시지를 남길 수 있습니다.
좋아요, 시작해 보겠습니다.
중요한 가치란 이러한 검사 및 검사 결과가 나타날 때 환자가 생명을 위협할 수 있는 상황에 처할 수 있음을 나타내는 것을 의미합니다. 임상의는 검사 및 검사 정보를 적시에 확보하고 환자에게 효과적인 중재 조치를 신속하게 제공해야 합니다. 환자의 생명을 구할 수 있는 치료. 중요한 가치 정보는 임상의에게 생명이 위험에 처한 환자에게 시기적절하고 효과적인 치료를 제공하여 환자가 사고로 인해 심각한 결과를 겪고 구조 기회를 잃는 것을 방지할 수 있습니다.
핵심 가치 보고 시스템의 수립 및 실행은 의료진 및 기술진의 주도성과 책임감을 효과적으로 향상시키고, 의료진 및 기술진의 이론 수준을 향상시키며, 의료진 및 기술진의 서비스 인식을 향상시켜 임상 진단에 적극적으로 참여할 수 있습니다. , 임상 및 의료 기술 부서의 효과적인 의사 소통과 협력을 촉진합니다. 중요한 가치 관리는 병원 관리의 중요한 부분이며, 중요한 가치의 신속한 식별, 확인, 공개, 적시 수신은 물론 프로세스의 모니터링 및 분석이 시스템 정보 관리의 목표이자 방향입니다.
현재 대부분의 중요 가치 관리 시스템에는 다음과 같은 문제가 있습니다.
1. 다양한 임계값 검사 항목은 고정된 기준 범위에 따라 판단됩니다. 프로젝트 범위의 상한 및 하한에 대한 동적 조정이 지원되지 않습니다. 수치 비교는 종종 과학적 범위 판단 및 교정 방법이 부족하여 간단하고 투박하게 이루어집니다. 임상 현실에 부합하지 않는 "거짓" 중요 값에 대한 빈번한 통지는 임상 의료진의 업무에 큰 영향을 미칩니다.
2. 임계값에 대한 의료진의 개입조치는 단순히 조치사항을 작성하여 의료기술부서에 피드백하는 것 뿐이며, 질병진행 및 간호기록과의 상호작용이 없으며, 처리과정에서 기억과 기억이 형성되지 않습니다. 동일한 상황에 대한 작업은 반복적인 작업과 시간이 필요한 경우가 많으며 편차가 발생하기 쉽습니다.
3. 중요한 가치는 광범위한 링크와 관련되어 있으며 통합 프로세스 관리가 없기 때문에 링크가 누락되기 쉽고 완전한 폐쇄 루프를 형성하지 못하는 동시에 전체 프로세스에는 링크 모니터링, 로그 추적, 예외 처리 계획이 있으며 병원 전체의 통계 요약 페이지도 부족하여 병원 중요성을 개선하기 위한 전반적인 솔루션을 제공할 수 없습니다.
이 특허 발명의 목적은 Kafka + 플링크 + Elasticsearch 및 기타 기술은 임계값 관리 전 과정에서 임계값 결정 범위를 과학적으로 교정하는 솔루션을 구현하고 임계값 프로세스 관리에 있어 현재 문제를 해결하기 위한 임계값 처리 방법을 지능적으로 권장합니다. 부정확한 판단 기준, 미사용 치료 데이터, 병원 전체의 불완전한 임계값 최적화 메커니즘을 사용하여 임계값 프로세스를 최적화하고 임계값 처리 효율성을 개선하며 완전한 폐쇄 루프 추적을 형성하고 궁극적으로 완전한 임계값을 구축합니다. -프로세스 관리 시스템.
1. 너무 빈번한 알림을 방지하고 임계 값 항목의 합리적인 범위를 지속적으로 보정하기 위해 "가짜" 임계 값 처리 계획을 수립합니다.
2. 일일 임계값을 처리하기 위한 조치를 저장하고 메모리를 형성합니다. 임계값이 도달하면 의료진에게 다양한 프롬프트를 제공하고 충전 보조 역할을 할 수 있습니다.
3. 메시지 센터의 이벤트 중심 메커니즘을 기반으로 임상 비즈니스 시나리오의 모든 측면을 최대한 포괄하는 완전한 중요 가치 처리 프로세스를 구축합니다. 데이터 센터는 완전한 중요 가치 정보를 저장하고 폐쇄 루프를 제공합니다. 각 부서의 중요 가치를 수집하는 디스플레이 및 데이터 쿼리 인터페이스 폐쇄 루프 데이터는 중요 가치 지표의 정기적인 추적, 분석 및 평가를 용이하게 하기 위해 방향 지표 데이터를 생성하고 각 부서가 자체 중요 가치 처리를 발견하고 개선하도록 감독합니다. 병원 전체의 중요 가치 처리 효율성을 향상시킵니다.
이 솔루션은 Kafka + Flink + 엘라스틱서치 임계값 범위 교정 및 권장 조치를 달성하기 위한 구체적인 기술 솔루션은 다음과 같습니다.
1. Kafka 환경을 배포합니다. 프로그램은 Kafka 관련 종속성을 도입하고 관련 구성 및 기능 통합을 수행하며 "중요 값 전송" 및 "중요 값 피드백" 이벤트를 정의하고 이벤트의 메시지 입력 매개 변수 형식 및 XSD 확인 텍스트를 구성합니다. two 각 이벤트는 Kafka의 두 가지 주제로 사용됩니다. 그 중 Kafka는 메시지 미들웨어 역할을 하며 생산자와 소비자의 협업 모드를 제공하는 역할을 담당합니다.
2. Elasticsearch 환경을 배포합니다. 이 프로그램은 Elasticsearch 관련 종속성을 도입하고 관련 구성 및 기능 통합을 수행합니다. Elasticsearch는 중요한 가치 원본 데이터, 관련 데이터, 작업 결과 등을 저장하는 데 사용되는 여러 인덱스 구조를 정의합니다. Elasticsearch 기능을 사용하여 통계 분석을 수행합니다.
3. Flink 환경을 배포합니다. 프로그램은 Flink 관련 종속성을 도입하고 관련 구성 및 기능 통합을 수행합니다. Flink는 한편으로는 Kafka가 전달하는 주제 메시지를 소비하는 데 사용됩니다. 한편, 관련 API를 통해 데이터 연산 후 출력은 Elasticsearch에 저장됩니다.
1. 외부 메시지 생성자 인터페이스 제공
메시지 센터 생산자 인터페이스를 개발하여 외부 시스템에 공개합니다. 이 인터페이스는 "중요한 값 전송"과 "중요한 값 피드백"의 두 가지 시나리오에서 사용할 수 있습니다.
주요 논리는 합리성 검증, 메시지 입력 매개변수에 대한 구문 분석 및 처리를 수행한 다음 Kafka API를 호출하여 메시지를 보내고 생산자 싱글톤을 사용하여 메시지 전송을 완료하는 것입니다.
보낼 주제는 "Critical Value Sending" 또는 "Critical Value Feedback" 입니다.
2. Flink를 사용하여 Kafka 사용
Flink의 **Flink Source API를 사용하고, Kafka를 데이터 소스로 추가하고, "중요한 가치 전송"과 "중요한 가치 피드백"이라는 두 가지 주제를 구독하세요.
가져온 메시지의 경우 메시지 소비 처리를 위한 코드 블록을 추가합니다.
3. Flink를 사용하여 스트림 데이터 처리
3.1 중요한 가치 전송 프로세스
Kafka에서 가져온 "Critical Value Sending" 주제 데이터에 대해 해당 처리를 수행합니다.
1) 정규식을 사용하여 메시지 입력 매개변수에서 임계값 ID, 보고 ID, 환자 ID, 방문 ID 등을 포함하되 이에 국한되지 않는 임계값 핵심 속성 콘텐츠를 추출하고, 각 핵심 속성의 코드 및 값을 식별합니다. 그것을 Map 구조로 조립합니다.
2) 위 핵심정보를 이용하여 Oracle로부터 위 내용에 대한 임계값 업무 관련 신고정보, 환자정보, 의료상담정보, 이력정보를 추출하고, 임계값 간격 분포정보, 임계값 처리조치 분포 및 기타 정보를 추출합니다. Elasticsearch에서 보조 분석을 위해 이러한 콘텐츠를 수집합니다.
3) Flink Transform API를 사용하여 지도 데이터를 포괄적으로 처리하고 관련 결과를 얻습니다.
4) 임계값을 전송하는 과정에서 범위 교정과 관련된 계산 및 권장 조치는 다음과 같습니다.
a. 프로젝트의 임계값에 대한 기본 정보를 얻고 임계값이 현재 임계값의 상한 및 하한을 충족하는지 확인합니다.
b. 프로젝트 임계값의 간격 분포를 얻고, 임계값이 속하는 간격 분포를 결정하고, 업데이트하고, 결과를 취합합니다.
c) 프로젝트의 중요한 가치에 대한 과거 처리 조치의 분포를 얻고, 이를 계산을 통해 얻은 후, 다양한 차원에서 다양한 조치의 발생 빈도에 따라 배열한 후 결과를 취합합니다.
d. 프로젝트의 임계값이 이력에서 발생했을 때 동일한 이상이 있는 다른 항목을 획득하고 해당 프로젝트와 현재 임계값 항목 간의 연계 관계를 계산합니다.
e. 프로젝트의 중요한 가치에 해당하는 프로젝트의 역사적 가치를 획득하고 추세 분석을 수행하며 결과를 취합합니다.
f. 보조 분석을 위해 프로젝트의 중요한 가치에 대한 기타 관련 및 확장 정보를 얻고 결과를 수집합니다.
g. 원본 임계값 데이터를 Elasticsearch에 저장하고, 3단계에서 모든 계산 결과를 취합하고, 다음 단계로 진입하여 채우기 보조 역할을 합니다.
3.2.중요가치 처리과정
Kafka에서 가져온 "중요 가치 처리" 주제 데이터에 대해 해당 처리를 수행합니다.
1) 정규식을 사용하여 메시지 입력 매개변수에서 임계값 ID, 처리 방법, 처리 조치, 프로세서 등을 포함하되 이에 국한되지 않는 임계값 처리의 속성 내용을 추출하고, 각 키 속성의 코드 및 값을 식별합니다. 이를 지도 구조로 조립합니다.
2) 임계값과 함께 전송하고, 위의 핵심 정보를 활용하여 Oracle 및 Elasticsearch에서 관련 정보를 추출하여 보조 분석을 수행합니다.
3) Flink Transform API를 사용하여 지도 데이터를 포괄적으로 처리하고 관련 결과를 얻습니다.
4) 임계값 처리 과정에서 범위 교정과 관련된 계산 및 권장 조치는 다음과 같습니다.
a. 의사가 임계값에 대한 정상적인 개입 조치를 제공하면 임계값의 트리거 범위에 대한 신뢰도가 높아졌음을 의미합니다. 먼저 항목의 임계값에 대한 빈도 기록 정보를 업데이트합니다. 그룹 값이며 이때 업데이트할 수 있습니다. 임계값 범위 간격 데이터는 특정 프로젝트에 대한 보다 정확한 임계값 범위를 나타냅니다. 이 간격의 임계값이 원래 임계값 범위 내에 있으면 해당 숫자는 임계값이 원래 발생을 초과하면 임계값 범위 간격 데이터가 더 정확해집니다. 임계값 간격의 경우 새 간격 데이터가 추가되고 범위가 확장됩니다. 마지막으로 의사의 치료 조치와 임계 값이 측정 메모리 인덱스에 연관되어 저장됩니다. 인덱스 기록에는 다음이 포함되지만 이에 국한되지는 않습니다. 다양한 프로젝트에 사용되는 치료 조치에는 해당 조치가 속하는 간격이 포함됩니다. , 과거 트리거 값에 포함되는 내용, 관련 환자의 현재 및 과거 보고서, 의료 방문, 중요한 가치 및 기타 정보.
b. 의사가 피드백 질문 버튼을 클릭하는 등 임계값에 대해 비정상적인 처리를 제공하는 경우 임계값 트리거 범위의 신뢰성이 감소함을 의미합니다. 먼저 임계값의 핵심 정보를 피드백 질문 색인에 삽입합니다. ; 그런 다음 임계값 범위로 이동합니다. 관련 비정상 데이터도 간격 지수에 삽입됩니다. 마지막으로 처리 조치 지수도 업데이트되며 피드백 질문도 처리 조치의 일부로 제공됩니다. 해당 통계 분석 페이지에서 범위 변경 여부를 수동으로 최종 결정합니다.
4. Flink를 사용하여 Elasticsearch로 출력
Flink Elasticsearch API를 사용하여 ElasticsearchSink를 결과 출력으로 추가하고 이전 단계에서 계산된 결과를 다양한 차원에 따라 ES의 다양한 인덱스 구조에 저장합니다.
임계값 원본 데이터 색인, 임계값 확장 데이터 색인, 임계값 간격 빈도 분포 지수, 임계값 처리 측정 분포 지수 등을 포함하되 그 이상입니다.
3.1 중요한 가치 전송 프로세스
핵심 서비스에서 데이터를 처리한 후 사용자 통합 포털의 백엔드 인터페이스를 호출한 다음 WebSocket을 사용하여 프런트엔드 및 백엔드 메시지 푸시를 완료하거나 핵심 서비스에서 WebSocket을 직접 통합하여 포털 프런트 엔드와의 상호 작용을 담당하고 마지막으로 팝업 인터페이스를 지배하기 위해 사용자 포털 프런트 엔드에 중요한 값을 표시합니다.
화면을 장악한 팝업창에서는 임계값에 해당하는 기본 정보, 보고서 정보, 환자 정보 외에 의사가 제출할 중재 조치를 작성하거나 피드백 질문 버튼을 클릭할 수도 있다.
다음과 같은 충전 보조 정보가 주요 팝업 창에 표시됩니다.
a. 프로젝트의 중요한 가치에 대한 다양한 치료 조치의 발생 빈도를 의사는 신속하게 클릭하여 재사용할 수 있습니다.
b. 프로젝트의 다양한 트리거 간격에서 임계값의 빈도는 의사가 임계값을 확인하는 참조로 사용됩니다.
c. 프로젝트의 역사적 추세에 대한 비교 분석 차트 및 프로젝트에 중요한 가치가 있을 때와 다른 중요한 가치가 발생할 때 동일한 비정상적인 프로젝트 정보의 발생 빈도
d. 치료 이력, 보고 이력, 중요 가치 이력 등과 같은 기타 이력 참고 정보
3.2.중요가치 처리과정
의사가 화면을 장악한 임계값 팝업 창을 처리할 때 통합 포털 백엔드 인터페이스를 호출하고 Kafka의 "Critical Value Process" 주제 데이터를 트리거하고 핵심 서비스의 임계값 처리 링크를 입력합니다.
의사에게는 두 가지 처리 모드가 있습니다. 중재 조치를 작성하여 제출하거나 피드백 질문 버튼을 클릭하면 두 가지 방법 모두 처리 프로세스를 종료할 수 있습니다.
6.1. 타이밍 서비스를 설정하고 집계 기능을 사용하여 ES 데이터에 대한 2차 처리를 수행하면 처리 결과가 새 인덱스 공간에 계속 저장됩니다.
6.2. 처리 전후의 중요 가치 지수 데이터를 표시하고 분석 팁을 제공하는 프런트 엔드 BI 인터페이스를 개발합니다.
1) 기준 범위에 대한 분석 및 판단 결과를 제공하여 교정 범위 변경 여부를 수동으로 최종 확인할 수 있습니다.
2) 다양한 치료방안에 대한 권장분석을 제공하며, 이용횟수, 처리경로, 해당값 범위, 과거 프로젝트 동향, 타 병행사업과의 연관성, 과거진단정보에 따라 다양한 통계 및 가이드라인을 제공합니다. 등을 분석합니다.
1) 임계값 평가 지표 정의: 의료 부서에서는 처리율%, 평균 처리 시간 h, 적시 처리율/24시간 처리율%, 환자 6시간 후속 조치율% 등 임계값 평가 지표를 정의해야 합니다. , 임계값 처리의 총 횟수 등;
2) 핵심가치 통계: 의료과는 각 부서의 핵심가치 관리 시스템 이행을 정기적으로 감독, 검사, 추적, 분석하고, 핵심가치 보고 및 처리의 적시성을 정기적으로 평가해야 합니다. 의료 포털의 임계값 구성 요소에서는 각 부서의 임계값 데이터가 집계되어 표시됩니다. 부서 및 의사의 두 가지 차원에 따라 다양한 지표의 순위 및 세부 데이터가 표시됩니다. 병원 전체의 차이점을 한눈에 정기적으로 비교하여 시점별 지표를 비교하고 병원의 중요 단계에 대한 개선 계획을 수립합니다.
3) 핵심가치 피드백 : 진료과에서는 실제 임상상황에 따라 핵심가치 항목과 핵심가치를 업데이트 및 조정해야 하며, 부서의 핵심가치 관리를 학과의 의료품질 평가에 통합하고, 의료진에 대한 핵심가치 피드백 구성요소를 개발해야 합니다. 포털을 통해 이러한 피드백을 일률적으로 수집, 분석 및 해결합니다.
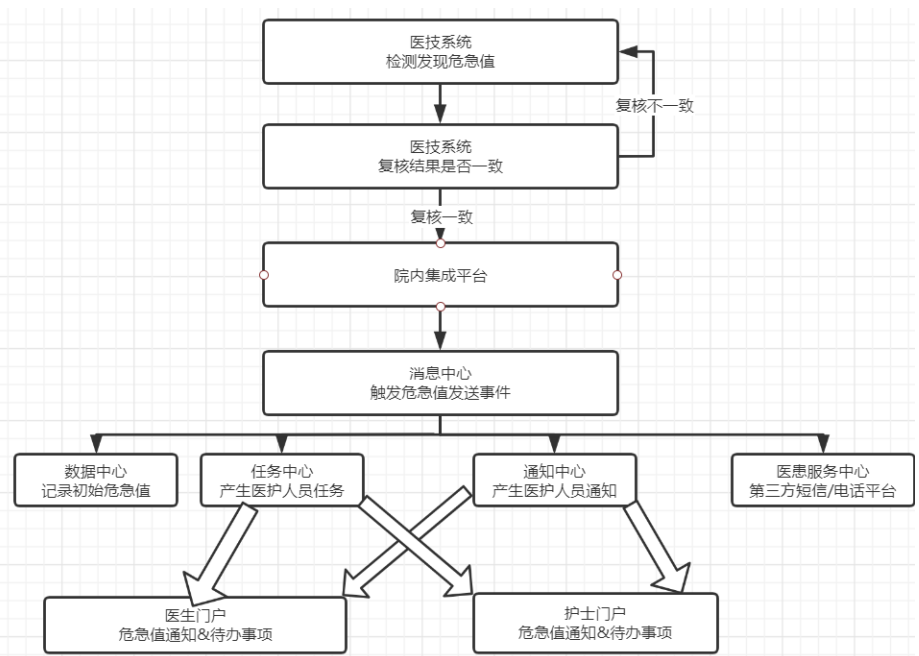
프로세스: LIS - 데이터 센터 - 생산자 - Kafka 소스 - Flink - 처리 - Elasticsearch
1. 의료기사가 위급한 상황을 발견한 경우 검사자(검사자)는 먼저 검사 기구, 장비 및 검사 과정의 정상 여부를 확인하고, 검체의 올바른 여부, 작동의 올바른지, 기구의 전송 오류 여부를 확인해야 한다. 임상 및 검사 확인 후, (검사) 과정 전반에 이상이 없는 경우 적시에 재검사를 실시합니다. (실제 상황에 따라 영상의학과에서 재검사 필요 여부를 결정할 수 있습니다.) 두 번의 재심사가 동일하게 심사(심사) 결과가 나올 수 있나요?
2. 검사(검사) 시스템이 임계 값을 전송한 후 병원 통합 플랫폼을 통해 데이터 센터 임계 값 전송 인터페이스에 대한 호출을 시작합니다. 먼저 임계 값이 저장되고 메시지 센터 생산자 인터페이스가 시작됩니다. 이 계획에서는 "중요한 값인 "주제"를 Kafka에 전달하도록 호출됩니다.
3. 이 솔루션의 핵심 서비스는 Flink를 사용하여 Kafka의 중요 값을 구독하여 Topic을 보내고, Flink Transform API를 사용하여 수신된 데이터를 처리하여 필요한 데이터를 구성한 다음 Flink Elasticsearch API를 사용하여 ElasticsearchSink를 추가하여 결과를 출력합니다. Elasticsearch 관련 색인에;
4. 핵심 서비스에서 데이터를 처리한 후 사용자 통합 포털의 백엔드 인터페이스를 호출한 다음 WebSocket을 사용하여 프런트엔드 및 백엔드 메시지 푸시를 완료하거나 핵심 서비스를 직접 통합할 수 있습니다. WebSocket은 포털 프런트 엔드와의 상호 작용을 담당합니다. 마지막으로 사용자 포털의 프런트 엔드에 임계값 팝업 인터페이스가 표시됩니다.
5. 이 시점에서 전송 프로세스가 종료됩니다.
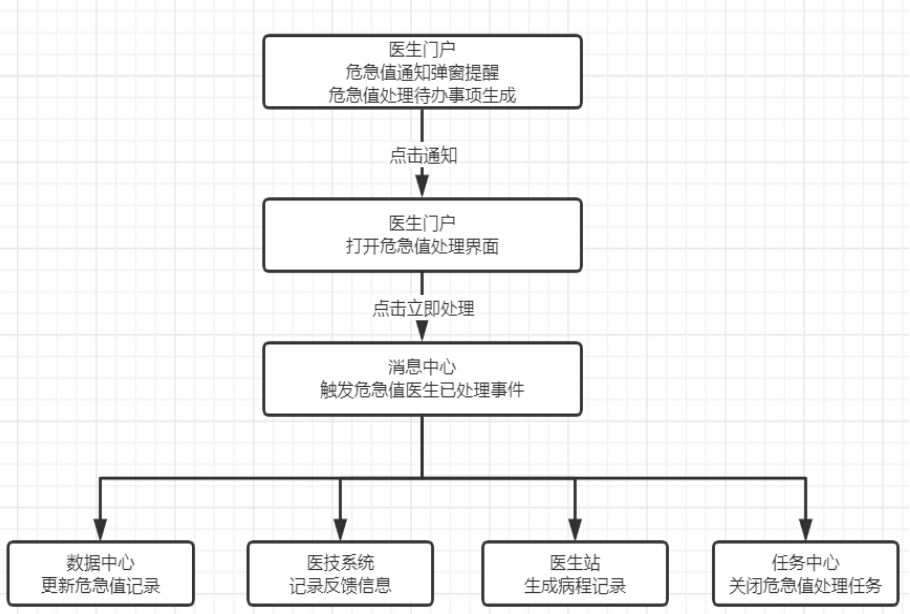
프로세스: 포털 - 데이터 센터 - 생산자 - Kafka 소스 - Flink - 처리 - Elasticsearch
1. 포털 시스템을 일상적으로 사용하는 동안 의사 사용자가 임계값 알림을 받으면 화면을 장악하는 팝업 창 형태로 표시됩니다.
2. 의사는 환자의 임계값 정보는 물론 보고정보, 진료상담 정보 등을 토대로 판단합니다. 임계값 항목에 해당하는 것으로 확인되면 해당 중재 조치를 작성하고, 데이터 센터의 임계값 처리 로직을 트리거합니다.
3. 데이터 센터는 먼저 임계 값 정보를 업데이트한 다음 병원 통합 플랫폼을 통해 검사(검사) 시스템의 임계 값 전송 인터페이스에 대한 호출을 시작한 다음 이 솔루션의 메시지 센터 생산자 인터페이스를 호출하여 " Kafka의 중요한 가치 처리" 주제;
4. 이 솔루션의 핵심 서비스는 Flink를 사용하여 Kafka의 중요한 가치 처리 주제를 구독하고 Flink Transform API를 사용하여 수신된 데이터를 처리하여 필요한 데이터를 구성한 다음 Flink Elasticsearch API를 사용하여 ElasticsearchSink를 추가하여 출력합니다. 결과는 Elasticsearch의 관련 색인에 있습니다.
5. 2단계에서 의사가 임계 값이 허위 경보라고 판단한 경우 "피드백 질문" 버튼을 클릭하여 후속 분석을 위해 "의료 관리 모듈" 인터페이스에 오류 문제를 보고합니다.
1. Kafka + Flink의 조합을 기반으로 빅 데이터 스트리밍 엔진 기술을 활용하여 중요한 가치 전송 및 처리 시나리오에 대한 신뢰성, 효율성, 실시간 및 확장성이 뛰어난 데이터 처리를 달성하고 최종적으로 중요한 가치를 달성합니다. 범위 교정 및 권장 조치의 목적
2. Elasticsearch를 사용하여 다양한 지수 계산 결과를 저장한 다음 ES의 집계 기능을 사용하여 결과에 대한 2차 분석 및 처리를 수행합니다. 전체 솔루션의 확장성과 재사용성이 크게 향상되었습니다.
3. 중요 가치 시나리오에 메시지 센터 이벤트 기반 메커니즘을 적용하고, 중요 가치 폐쇄 루프 프로세스의 주요 노드에 대한 메시지 이벤트를 설정하고, 동적 구독을 통해 이벤트에 대한 구독 서비스를 지정합니다. 프로세스는 명확하고 연결 가능합니다. 실제 비즈니스 시나리오의 모든 측면을 최대한 다루고 비즈니스 범위와 직원 참여를 개선하여 메시지 센터를 허브로 사용하여 완전한 중요 가치 처리 프로세스를 구축합니다.
위는 블로거 회사의 "Kafka + Flink + ES 기반 권장 중요 가치 처리 조치 및 범위 조정" 계획을 소개합니다.
💗 后续会逐步分享企业实际开发中的实战经验,有需要交流的可以联系博主。

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com