2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Im weiten Bereich der Unternehmensdatenverwaltung besteht der erste und entscheidende Schritt darin, die Notwendigkeit einer Datenverwaltung klar zu kommunizieren. Dazu gehört ein klares Verständnis und eine klare Aufzeichnung der Datentypen, über die das Unternehmen verfügt, wo diese gespeichert werden und über die Besonderheiten der aktuellen Datenverwaltung. Das Verständnis der Datenbestände einer Organisation ist die Grundlage für die Entwicklung einer effektiven Data-Governance-Strategie. Unternehmen müssen alle Arten von Datenbeständen identifizieren und inventarisieren, einschließlich strukturierter und unstrukturierter Daten, sowie deren Verteilung im gesamten Unternehmen.
In diesem Zusammenhang rückt die Bedeutung von Datenmodellen immer stärker in den Vordergrund.Das Datenmodell dient als Werkzeug zur Beschreibung der Datenstruktur und der Beziehung zwischen Daten.Datenamt Bietet grundlegende Rahmenbedingungen und Regeln. Unter Data Governance versteht man den Prozess zur Gewährleistung von Datenqualität, -sicherheit und -konformität. Zur Erreichung dieser Ziele sind Datenmodelle erforderlich.
Ziel dieses Artikels ist es, die Beziehung zwischen Datenmodellen und Daten-Governance zu untersuchen und zu untersuchen, wie die Datenverwaltungsfähigkeiten eines Unternehmens durch effektives Datenmodelldesign und Daten-Governance-Praktiken verbessert werden können. Wir werden zunächst die grundlegenden Konzepte und Komponenten von Datenmodellen sowie die Bedeutung von Datenmodellen vorstellen. Wir werden die Rolle von Datenmodellen bei der Datenverwaltung ausführlich diskutieren, einschließlich der Verwendung von Datenmodellen zur Unterstützung des Metadatenmanagements, des Datenqualitätsmanagements, der Gewährleistung von Datensicherheit und Compliance usw.
Durch die Diskussion in diesem Artikel möchten wir den Lesern helfen, die Bedeutung von Datenmodellen und Datenverwaltung besser zu verstehen und zu verstehen, wie sie voneinander abhängen und sich gegenseitig fördern, um gemeinsam die Datenstrategie des Unternehmens voranzutreiben.
Für weitere Details empfiehlt sich der Download des „Big Data Construction Plan“:
https://s.fanruan.com/5iyug
Teilen Sie echte Fälle der digitalen Transformation in der Branche und bieten Sie komplette digitale Lösungen!
Ein Datenmodell ist für Daten das, was ein Architekturmodell für ein Gebäude ist. Es bietet eine detaillierte Beschreibung der Dateneigenschaften. Kurz gesagt handelt es sich bei einem Datenmodell um eine Reihe standardisierter, leicht verständlicher Symbole, mit denen die Struktur und Beziehungen von Daten ausgedrückt werden, um die Implementierung und den Betrieb von Computersystemen zu erleichtern. Diese Modelle bieten einen klaren Rahmen für die Datenverwaltung, -analyse und -anwendung und stellen sicher, dass Daten auf geordnete und konsistente Weise verstanden und verwendet werden.
Das Datenmodell erfasst umfassend alle Aspekte von Daten durch drei Kernelemente, nämlich Datenstruktur, Datenoperationen und Datenbeschränkungen.
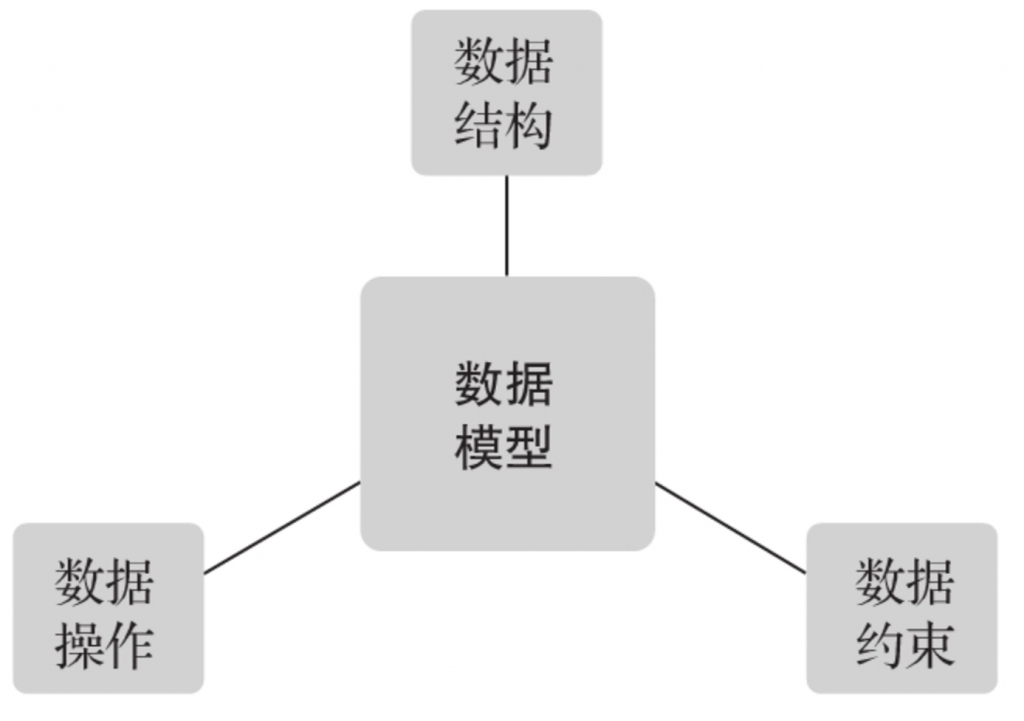
Die Datenstruktur stellt hauptsächlich die statischen Aspekte des Systems dar und umfasst Datenklassifizierung, Attribute, Merkmale und Wechselbeziehungen zwischen verschiedenen Dateneinheiten. Als Eckpfeiler des Datenmodells spielt es eine entscheidende Rolle bei der Definition des Wesens des Datenmodells. Im Kontext von Datenbanksystemen hängt der Name eines Datenmodells häufig mit der Art seiner Datenstruktur zusammen. Beispielsweise entsprechen „hierarchisches Modell“ und „relationales Modell“ jeweils hierarchischen und relationalen Datenstrukturen.
Datenoperationen umfassen die dynamischen Aspekte des Systems, einschließlich des Hinzufügens, Aktualisierens, Löschens und Abrufens von Daten. Ein vollständiges Datenmodell muss die spezifische Bedeutung dieser Operationen, die Operationssyntax, die Regeln und die zur Implementierung dieser Operationen verwendete Programmiersprache oder Abfragesprache klar definieren.
Dateneinschränkungen stellen eine Reihe von Integritätsregeln dar, die die Daten und ihre Beziehungen im Datenmodell einschränken. Diese Regeln stellen die Genauigkeit, Rechtmäßigkeit und Konsistenz der Datenspeicherung und der Zustandsänderungen des Datenmodells sicher. Beispiele für Integritätsregeln sind beispielsweise die Sicherstellung, dass die Kundennummer in einer Tabelle in der Datenbank eindeutig ist oder dass das Namensfeld nicht leer sein darf. Durch diese Einschränkungen können die Qualität der Daten und die Konsistenz des Datenmodells aufrechterhalten werden.
Ein Datenmodell ist ein Werkzeug, das Datenobjekte, die Beziehungen zwischen ihnen und die damit verbundenen Regeln konzeptionell beschreibt. Je nach Anwendungsanforderungen und Abstraktionsebene können Datenmodelle in die folgenden drei Haupttypen unterteilt werden:
Konzeptionelle Modelle zielen darauf ab, wichtige Geschäftskonzepte und ihre Beziehungen zueinander, wie z. B. Kunden, Lieferanten, Produkte, Verträge, Vertriebskanäle und Produktionsprozesse, zu erfassen und auszudrücken. Sein Hauptziel besteht darin, einen Rahmen zu schaffen, der die konzeptionelle Ebene des Unternehmens widerspiegelt und Entitäten, Attribute und Beziehungen zwischen ihnen klarstellt. Das konzeptionelle Modell konzentriert sich auf den Ausdruck der Geschäftslogik und beschreibt detailliert die Objektentitäten, die den Geschäftskonzepten und ihren gegenseitigen Beziehungen entsprechen, um das Verständnis und die Analyse durch Geschäftspersonal und Systementwickler zu erleichtern.
Zu den drei Grundkomponenten, aus denen das konzeptionelle Modell besteht, gehören:
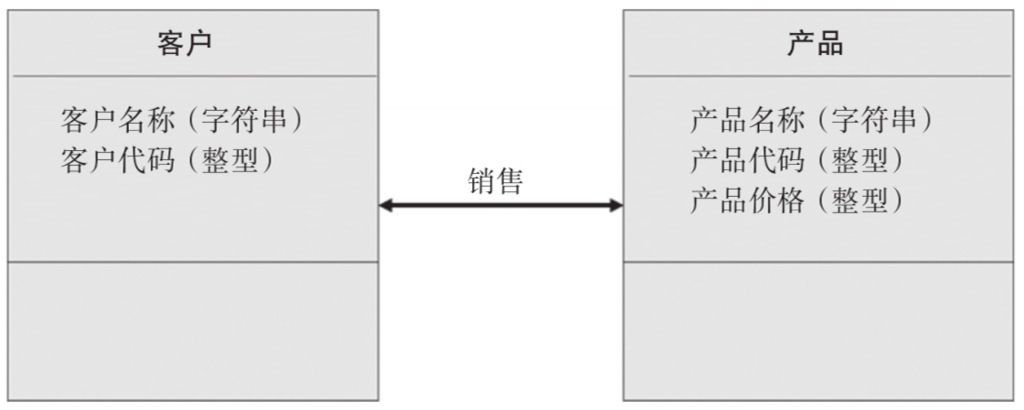
Am Beispiel des Vertriebsgeschäfts können Kunden und Produkte als zwei verschiedene Einheiten betrachtet werden; Kundentyp, Kundenname und Lieferadresse sind Attribute der Kundeneinheit, Produktname und Produktpreis sind Attribute der Produkteinheit ; und Verkaufsverhalten stellt eine Beziehung zwischen Kunden und Produkten dar.
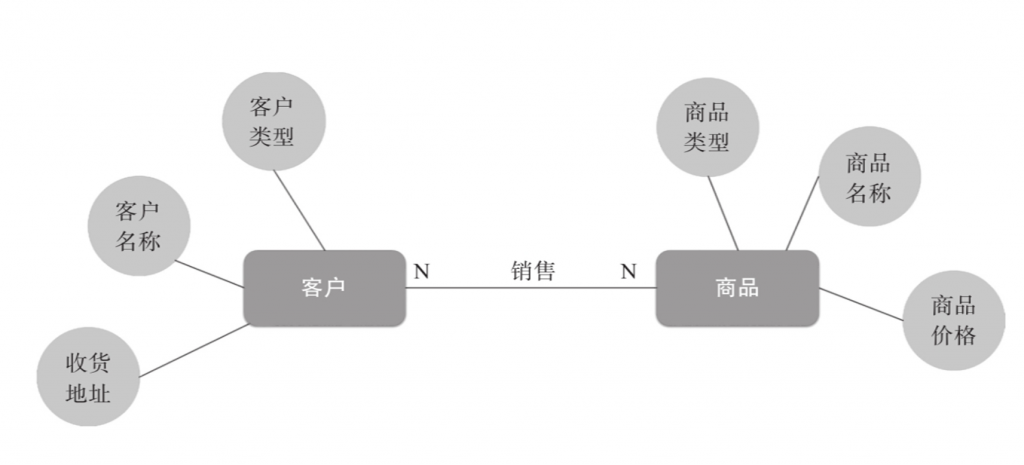
Bei der Erstellung eines konzeptionellen Modells müssen zunächst der Umfang des Systems und die beteiligten Schlüsselobjekte geklärt werden. Die Entwurfsarbeit beginnt normalerweise mit einem ausgewählten Themenbereich, und spezifische Details der Datenbankstruktur werden in der Modellierungsphase des konzeptionellen Modells normalerweise nicht berücksichtigt.
Durch die Festlegung grundlegender Geschäftskonzepte und -bereiche stellen konzeptionelle Modelle allen Beteiligten eine gemeinsame Terminologie und Definitionen zur Verfügung und bilden so eine gemeinsame Sprachbasis.
Das konzeptionelle Modell wird verwendet, um den Umfang der Modellierung zu definieren, das Konstruktionsthema zu bestimmen, die wichtigsten Geschäftsbeziehungen zu ordnen und den Rahmen des logischen Datenmodells zu erstellen.
Es handelt sich um eine Sammlung von Konzepten, die von Designern auf der Grundlage eines tiefgreifenden Verständnisses der Benutzerbedürfnisse und Geschäftsfelder verfeinert wurden und nach Analyse und Synthese die Geschäftsanforderungen der Benutzer beschreiben. Das konzeptionelle Modell hängt nicht von einem bestimmten Informationssystem ab. Es handelt sich um eine konzeptionelle Struktur, die unabhängig vom Informationstechnologiepersonal ist und lediglich den Informationsbedarf widerspiegelt.
Es verfügt nicht nur über starke semantische Ausdrucksfähigkeiten und kann verschiedene semantische Kenntnisse in Anwendungen direkt ausdrücken, sondern sollte auch prägnant, klar und leicht verständlich gestaltet sein. Bei der Data-Governance-Planung werden häufig konzeptionelle Modelle verwendet, um Data-Governance-Themen zu planen und dabei zu helfen, Geschäftsobjekte und ihre Beziehungen zueinander zu ordnen.
Das logische Modell ist eine umfassende Darstellung der Datenanforderungen des Unternehmens. Es beschreibt die Datenentitäten und ihre Beziehungen, Attribute, Definitionen, Beschreibungen und Beispiele. Das logische Modell konzentriert sich mehr auf die Implementierungsdetails des Systems. Um den Systementwurf zu vereinfachen, können manchmal mehrere Einheiten zu einer gemeinsamen Einheit zusammengeführt werden.
Dennoch ist das logische Modell immer noch unabhängig vom spezifischen Datenbanksystemdesign. Es bietet eine Abstraktionsschicht für das physische Design der Datenbank, kann jedoch nicht direkt in der tatsächlichen Entwicklung der Datenbank verwendet werden. Das logische Modell ist ein Zwischenschritt beim Übergang zum physischen Datenbankdesign. Es gewährleistet die Konsistenz und Standardisierung des Designs und legt den Grundstein für die anschließende Datenbankimplementierung.
Das logische Modell kann die spezifischen Anforderungen der Geschäftsabteilung genau erfassen und ausdrücken und bietet wichtige Leitlinien für die Implementierung des Systems auf physischer Ebene.
Seine Hauptaufgabe besteht darin, den Datenarchitekturentwurf des Unternehmens anhand von Entitäten und ihren Wechselbeziehungen darzustellen. Das Hauptziel des Entwurfs eines logischen Modells besteht darin, einen Entwurf der Unternehmensdatenarchitektur zu erstellen und die Entwicklung und den Aufbau des Systems zu steuern. Darüber hinaus wurde das logische Modell unter Verwendung von Geschäftsbegriffen entworfen, sodass es zu einer Kommunikationsbrücke zwischen Geschäftspersonal und technischem Personal und zu einem wirksamen Instrument für die Kommunikation zwischen beiden Parteien wird.
Durch logische Modelle können technische Teams Geschäftsanforderungen besser verstehen und in einen Teil des Systemdesigns umsetzen, während Geschäftsteams sicherstellen können, dass ihre Anforderungen in der technischen Implementierung genau widergespiegelt werden.
Das physische Modell bietet eine konkrete Abstraktionsebene für das Datenbankdesign und enthält detaillierte Metadateninformationen, die für die Erstellung der visuellen Struktur der Datenbank von entscheidender Bedeutung sind. Das physische Modell ermöglicht es Designern, die verschiedenen Komponenten einer Datenbank detailliert zu planen, einschließlich Spaltenschlüssel, Datenintegritätsbeschränkungen, Indizes, Trigger und andere Funktionen im Zusammenhang mit Datenbankverwaltungssystemen (DBMS). Durch das physische Modell können Entwickler die physischen Eigenschaften der Datenbank vor der tatsächlichen Bereitstellung der Datenbank modellieren und optimieren, um sicherzustellen, dass die Leistung und Effizienz der Datenbank die spezifischen Anforderungen des Systems erfüllen können.
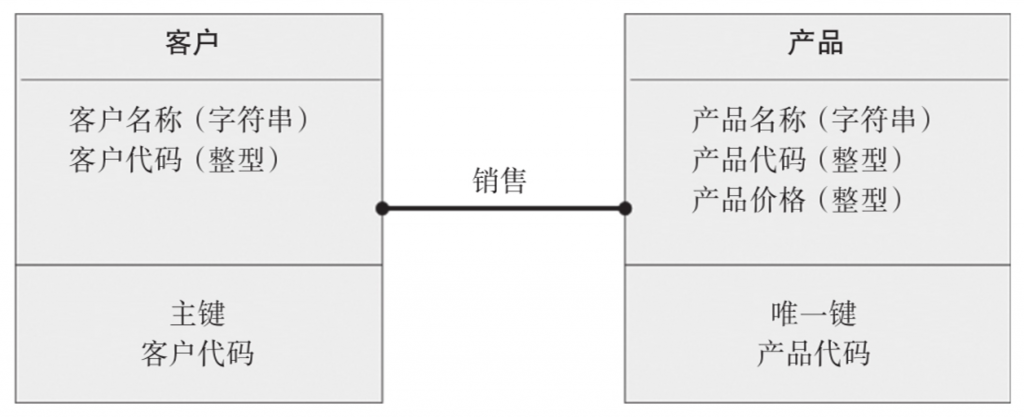
Im Vergleich zum logischen Modell geht das physikalische Modell noch einen Schritt weiter. Es beschreibt die spezifischen Beziehungen zwischen Tabellen im Detail, wie z. B. die Zuordnung von Primärschlüsseln und Fremdschlüsseln, die Erstellung von Indizes usw. Im physischen Modell werden den Spalten jedes Datenelements Attribute wie spezifischer Datentyp, Länge, Standardwert, Einschränkungen, Speicherkonfiguration und Zugriffsberechtigungen zugewiesen.
Es ist zu beachten, dass unterschiedliche Datenbanksysteme möglicherweise unterschiedliche physische Modelldesigns erfordern. Beispielsweise gibt es einige Unterschiede in der Datenmodellierung zwischen relationalen Datenbanken wie MySQL und Oracle und NoSQL-Datenbanken.
Die Hauptfunktion des physischen Modells besteht darin, das logische Modell in ein Schema umzuwandeln, das im Datenbanksystem implementiert werden kann, um Daten tatsächlich zu speichern und zu verwalten.
Ein gut gestaltetes physisches Modell kann die Effizienz der Datenspeicherung optimieren, die Genauigkeit und Vollständigkeit der Daten sicherstellen und auch die Entwicklung von Datenbankanwendungssystemen erleichtern. Durch sorgfältig entworfene physische Modelle können Sie die Datenbankleistung verbessern, Wartungskosten senken und den effizienten Betrieb von Anwendungen unterstützen.
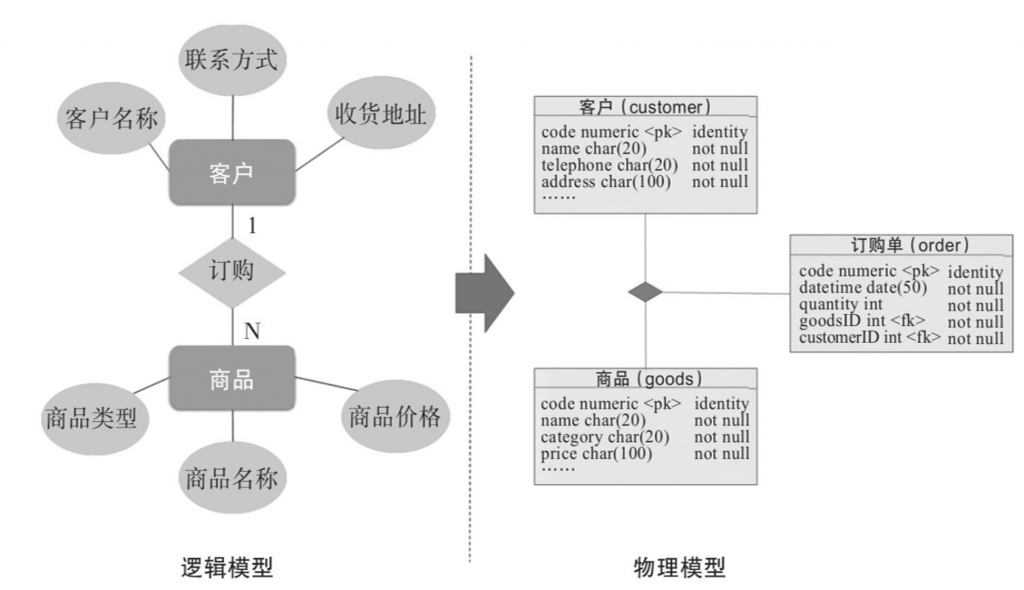
Die Entwurfsaufgabe des physikalischen Modells beschränkt sich nicht nur auf die Erfüllung der Grundanforderungen für den Systembetrieb und die Datenspeicherung, sondern muss auch die Optimierung der Systemleistung umfassend berücksichtigen. Dazu gehören folgende Kernaspekte:
Das Ziel des physikalischen Modellentwurfs besteht darin, die Effizienz der Datenspeicherung und die Stabilität des Systembetriebs sicherzustellen und gleichzeitig die Fähigkeit des Systems zur Datenverarbeitung zu verbessern, um die Leistungsanforderungen des Unternehmens zu erfüllen und gleichzeitig die Datengenauigkeit und -integrität aufrechtzuerhalten.
Datenmodelle spielen eine häufige und entscheidende Rolle in wichtigen Datenmanagement- und Anwendungsprojekten wie der Entwicklung von Anwendungssystemen, der Datenintegration, dem Aufbau eines Data Warehouse, der Stammdatenverwaltung und der Verwaltung von Datenbeständen. Es ist keine Übertreibung, es als den Eckpfeiler der Datenverwaltung zu betrachten.
Vergleicht man die Unternehmensinformatisierung mit dem menschlichen Körper, dann ist das Datenmodell das Skelett, das den menschlichen Körper trägt. Die Wechselbeziehungen und Flusswege zwischen Daten bilden das Blutgefäß und Venensystem, und die Daten selbst entsprechen Blut. Das Datenmodell stellt sicher, dass Daten wie Blut reibungslos fließen und im Unternehmensinformationssystem effektiv funktionieren.
Unabhängig davon, ob es sich um eine Betriebsdatenbank oder ein Data Warehouse handelt, ist das Datenmodell das zentrale Werkzeug zum Organisieren von Daten und zum Steuern des Entwurfs von Datentabellen. Linus Torvalds, der Gründer von Linux, sagte, dass „schlechte Programmierer sich um Code kümmern, gute Programmierer sich um Datenstrukturen und ihre Beziehungen kümmern“ und unterstreicht die Bedeutung von Datenmodellen. Nur durch das Datenmodell können Daten geordnet organisiert und gespeichert werden, wodurch eine effiziente, kostengünstige, hocheffiziente und qualitativ hochwertige Nutzung von Big Data erreicht wird.
So wie ein Architekt Pläne erstellt, bevor er ein Haus baut, sollten die Daten vor der Entwicklung einer App gründlich berücksichtigt werden. Eine Datenumgebung ohne ganzheitliche Perspektive kann dazu führen, dass Techniker angesichts von Systemausfällen oder Datenproblemen hilflos zurückbleiben. Datenmodelle helfen dabei, Probleme zu definieren, fehlende und redundante Daten zu identifizieren und optimale Lösungen auszuwählen.
Datenmodelle helfen dabei, Anwendungen zu geringeren Kosten zu erstellen und Fehler und Auslassungen frühzeitig zu erkennen. Ein gutes Datenmodell kann auch als Referenz zum Schreiben von SQL-Code verwendet werden und so den Entwicklungsprozess beschleunigen. Untersuchungen zeigen, dass die Datenmodellierung zwar nur einen kleinen Teil der Projektkosten ausmacht, die Programmierkosten jedoch erheblich senken kann.
In Unternehmen müssen Geschäftsmitarbeiter, Datenanalysten, Architekten, Datenbankdesigner, Entwickler usw. mit unterschiedlichem Hintergrund gemeinsam Datenprobleme und -anforderungen besprechen. Als effizientes Kommunikationsinstrument können Datenmodelle alle Beteiligten dabei unterstützen, schnell einen Konsens zu erzielen. Die Konsistenz der Geschäftsterminologie ermöglicht es Geschäftsleuten, die Arbeit der Entwickler zu verstehen und zu validieren, was zu einem Konsens führt.
Viele Probleme mit der Datenbankleistung werden nicht durch Software, sondern durch unsachgemäße Datenbanknutzung verursacht. Das Datenmodell bietet eine Möglichkeit, die Datenbank zu verstehen, erfordert klare und konsistente Konzepte und die Konvertierung des logischen Modells in ein auf Regeln basierendes Datenbankdesign und die anschließende Anpassung zur Optimierung der Leistung.
Das Datenmodell trägt zur Verbesserung der Datenqualität durch Datenbank-Primär- und Fremdschlüsseleinstellungen, Datenqualitätsregeleinschränkungen und Referenzdatenintegrität bei. Datenfehler sind schwerwiegender als Anwendungsfehler, und sobald Daten in einer großen Datenbank beschädigt sind, können die Folgen katastrophal sein.
Datensortierung und -modellierung sind wichtige Werkzeuge für die Bestandsaufnahme und Zuordnung von Unternehmensdaten. Das Datenmodell hilft, den Geschäfts- und Datenstatus umfassend zu verstehen und potenzielle Geschäfts- und Datenprobleme zu analysieren. Ein erfolgreiches Datenmodelldesign fördert die effektive Kommunikation von Geschäftsanforderungen, verbessert die Datengenauigkeit und Benutzerfreundlichkeit und legt eine solide Grundlage für die Unternehmensdatenverwaltung.
Im Datenarchitektursystem des Unternehmens spielt das Datenmodell eine entscheidende Schlüsselrolle. Es realisiert die Verbindung zwischen Geschäftsanforderungen und Datenbanksystemen im Datenverwaltungsprozess. Die Verantwortlichkeiten des Datenmodells beschränken sich nicht nur auf die Definition der Speicherstruktur und der Datenzugriffsmethode, sondern sind auch eng mit mehreren wichtigen Datenverwaltungsbereichen verbunden, darunter Metadatenverwaltung, Datenstandardentwicklung, Stammdatenkoordination, Datenqualitätsüberwachung und Datensicherheit und Datenmanagement.
Im Gesamtrahmen der Daten-Governance ist die sorgfältige Gestaltung und Verwaltung von Datenmodellen der erste Schritt, um mit der Daten-Governance-Arbeit zu beginnen. Ein gut gestaltetes Datenmodell kann die Effizienz und Effektivität der Unternehmensdatenverwaltung erheblich verbessern und den reibungslosen Fortschritt und langfristigen Erfolg der Datenverwaltungsarbeit sicherstellen. Durch die Optimierung von Datenmodellen können Unternehmen die Genauigkeit, Konsistenz und Zugänglichkeit der Daten sicherstellen und so eine solide Datenunterstützung für Entscheidungsfindung, Geschäftsprozesse und strategische Planung bereitstellen.
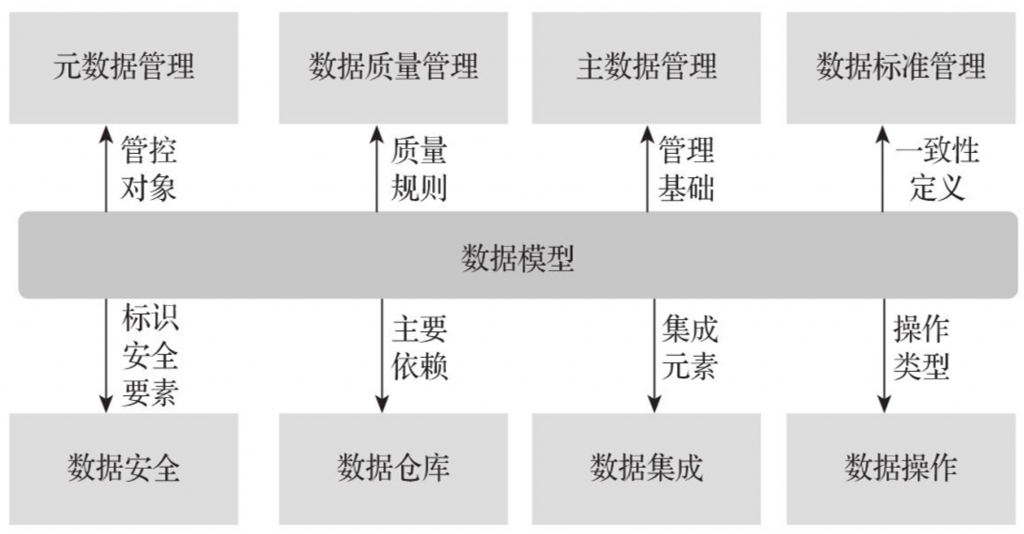
Beim Aufbau des Datenmodells umfasst das Geschäftsmodell hauptsächlich die Beschreibung von Geschäftsthemen und Geschäftsregeln.Bildet den Kern der Geschäftsmetadaten . Das physische Modell umfasst Datenentitäten, Beziehungen zwischen Entitäten, Datenstrukturen und Verbindungen zwischen Primärschlüsseln und Fremdschlüsseln usw., die den Hauptteil der technischen Metadaten bilden.
Die Korrelation zwischen Daten ist der Eckpfeiler der Metadaten-Herkunftsanalyse. Daher kann das Datenmodell gewissermaßen als eine Reihe von Metadaten betrachtet werden, die die Geschäftsanforderungen des Unternehmens beschreiben.
Aus technischer Sicht istDas Stammdatenmanagement basiert auf Datenmodellen . Die wichtigsten Aspekte des Stammdatenmanagements, einschließlich Stammdatendefinition, -verwaltung, -bereinigung, -sammlung und -verteilung sowie Qualitätsmanagement, basieren alle auf dem Stammdaten-Metamodell.
Das Datenmodell bietet MDM eine klare und konsistente Datenstrukturdefinition, die die Planung und Implementierung von Stammdatenmanagementlösungen leitet.
In einer Multisystem-InformationsumgebungDie Inkonsistenz des Datenmodells ist die Hauptursache für Datenqualitätsprobleme . Das Datenmodell stellt wichtige Metadateneingaben für das Datenqualitätsmanagement bereit, einschließlich der Konsistenzdefinition von Geschäftsmetadaten und der Definition von Datenqualitätsregeln, und legt damit den Grundstein für die anschließende Formulierung von Datenqualitätsregeln, die Datenqualitätsprüfung und die Erstellung von Datenqualitätsberichten.
Ein gut gestaltetes Datenmodell kann Inkonsistenzen in Datenstatistiken reduzieren und das Risiko von Datenberechnungsfehlern verringern.
Ein Datenmodell ist eine Möglichkeit, komplexe Datenstrukturen in der realen Welt abstrakt zu beschreiben. Es ist auch ein Ausdruck von Geschäftsregeln. Aus Datenbanksicht liegt die Bedeutung von Daten in ihrer Fähigkeit, die definierten Geschäftsregeln genau wiederzugeben. Nur korrekte Geschäftsregeln können Entitäten, Attribute, Beziehungen und Einschränkungen klar definieren.
daher,Die Standardisierung von Datenmodellen ist ein wichtiges Glied im Datenstandardisierungsprozess. . Die Geschäftsregeln im Datenmodell werden aus einer detaillierten Beschreibung der Betriebsabläufe des Unternehmens abgeleitet, die dem Unternehmen bei der Erstellung und Ausführung spezifischer Geschäftsaktivitäten helfen.
Daher müssen Geschäftsregeln klar formuliert und rechtzeitig aktualisiert werden, wenn sich die Betriebsumgebung des Unternehmens ändert, um sicherzustellen, dass das Datenmodell den tatsächlichen Betrieb des Unternehmens korrekt widerspiegeln kann, und so dem Unternehmen dabei helfen, eine Datenstandardisierung zu erreichen.
Datenmodelle sind eine Schlüsselkomponente zur Gewährleistung der Datensicherheit . Beim Aufbau eines Datenmodells müssen Entitäten, Attribute, Beziehungen und Einschränkungen geklärt und sensible Datenfelder oder Tabellen entsprechend den spezifischen Datenschutzanforderungen des Unternehmens gekennzeichnet werden.
Unternehmen sollten Datenmodelle verwenden, um spezifische Anforderungen und Geschäftsregeln für die Implementierung von Datensicherheitstechnologien zu klären und zu bestimmen, auf welche Datenfelder bestimmtes Personal zugreifen kann und welche Datenfelder desensibilisiert werden müssen.
Datenmodelle sind der Kern von Data Warehouses und Business Intelligence (BI)-Systemen Ein hervorragendes Datenmodell hilft bei der Analyse der Herkunft und Auswirkung von Daten und gewährleistet so eine qualitativ hochwertige Entscheidungsfindung. Beim Aufbau eines Data Warehouse spielt das Datenmodell die Rolle der Datenorganisation und Speicherstrategie, bei der die angemessene Speicherung von Daten aus Sicht der Geschäftsanforderungen, des Datenzugriffs und der Datennutzung im Vordergrund steht. Nur durch die geordnete Organisation und Speicherung von Daten mithilfe von Datenmodellen können wir eine hocheffiziente, kostengünstige, hocheffiziente und qualitativ hochwertige Nutzung von Big Data erreichen.
Das Design des Datenmodells ist der Eckpfeiler des Data-Warehouse-Aufbaus. Es bietet nicht nur eine umfassende Geschäftsübersicht und Gesamtdatenperspektive, sondern fördert auch die reibungslose Kommunikation zwischen Unternehmen und Technologie und sorgt für einen Konsens über die wichtigsten Geschäftsdefinitionen und -terminologie. Darüber hinaus ist das Datenmodell abteilungsübergreifend neutral und in der Lage, alle Geschäftsbereiche abzubilden und abzudecken.
Datenintegration bezieht sich auf die effektive Integration von Daten aus verschiedenen Quellen mit unterschiedlichen Formaten und Merkmalen durch logische oder physische Mittel, damit Unternehmen einen umfassenden Datenaustausch erreichen können. Um eine Zentralisierung und gemeinsame Nutzung von Daten zu erreichen, ist eine eingehende Analyse bestehender Datenmodelle besonders wichtig geworden.
Im Prozess der DatenintegrationStellen Sie die Konsistenz zwischen Schlüsselelementen im Datenmodell sicher ist die primäre Überlegung. Diese Konsistenz umfasst die Übereinstimmung von Datendefinitionen, -strukturen und -beziehungen und ist die Grundlage für eine nahtlose Datenintegration. Nur wenn die Schlüsselkomponenten des Datenmodells konsistent sind, können Daten zwischen verschiedenen Systemen und Anwendungen wirklich miteinander verbunden werden und dem Unternehmen eine einheitliche und integrierte Sicht auf die Daten bieten.
Das Datenmodell beschreibt drei Schlüsselaspekte der Daten:Struktur, Abläufe und Einschränkungen . Der Datenoperationsteil definiert speziell die Arten von Operationen, die an der Datenstruktur ausgeführt werden können, und ihre Ausführungsmethoden und bildet einen Satz von Operationsoperatoren. Zusammen bilden diese Operatoren einen standardisierten Rahmen für die Dateninteraktion und sorgen für die Standardisierung der Dateninteraktion.
Darüber hinaus bieten das standardisierte Strukturdesign und klare Einschränkungen im Datenmodell solide Schutzmaßnahmen für die Datenspeicherung und den Datenbetrieb, wodurch das Risiko von Anomalien während des Datenbetriebs wirksam verringert wird.
Datenmodelle sind der Grundstein für eine erfolgreiche Datenverwaltung. Durch gut konzipierte Datenmodelle können Unternehmen die Datenkonsistenz, -genauigkeit und -zuverlässigkeit sicherstellen, was für das Erreichen der langfristigen Ziele der Datenverwaltung von entscheidender Bedeutung ist. Um dies zu erreichen, müssen Unternehmen einen umfassenden Ansatz für den Aufbau und die Pflege ihrer Datenmodelle verfolgen. Dazu gehört nicht nur technische Präzision, sondern auch ein tiefes Verständnis für Geschäftsprozesse und Benutzerbedürfnisse. Da sich außerdem das Unternehmensumfeld und die Marktbedingungen ständig ändern, müssen Datenmodelle ständig angepasst und optimiert werden, um sich an neue Herausforderungen und Chancen anzupassen.
Data Governance ist ein fortlaufender Prozess, der von Organisationen verlangt, ihre Datenverwaltungspraktiken kontinuierlich zu bewerten und zu verbessern. Durch kontinuierliche Investitionen und Bemühungen können Unternehmen ein starkes Data-Governance-Framework etablieren, das eine solide Datenunterstützung für die Entscheidungsfindung, das Risikomanagement, den Kundenservice und die Innovationsaktivitäten des Unternehmens bietet.
Letztendlich kann eine effektive Datenverwaltung nicht nur die Effizienz und Effektivität des Unternehmensbetriebs verbessern, sondern auch Wettbewerbsvorteile für Unternehmen bringen und sie auf dem Weg der digitalen Transformation voranbringen. Wir hoffen, dass dieser Artikel Unternehmen und Fachleuten, die an der Verbesserung ihrer Datenverwaltungsfähigkeiten arbeiten, wertvolle Einblicke und Anleitungen bietet, um ihnen in einem datengesteuerten Geschäftsumfeld zum Erfolg zu verhelfen.
Für weitere Details empfiehlt sich der Download des „Big Data Construction Plan“:
https://s.fanruan.com/5iyug
Teilen Sie echte Fälle der digitalen Transformation in der Branche und bieten Sie komplette digitale Lösungen!

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet, Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
