2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Inhaltsverzeichnis
Inhaltsverzeichnis
(1) Datenbankbenennungskonvention:
(2) Anmerkungsspezifikationen:
(4) Front-End- und Back-End-Spezifikationen:
(1) Download und Installation:
(2) Erstellen Sie ein neues Projekt und laden Sie Ihre Teamkollegen ein:
(3) Verfassen von Spezifikationen für Schnittstellendokumente
4. Debug-Funktion (muss das Backend kennen)
(Eine Person kann das Land nicht beherrschen!!!)
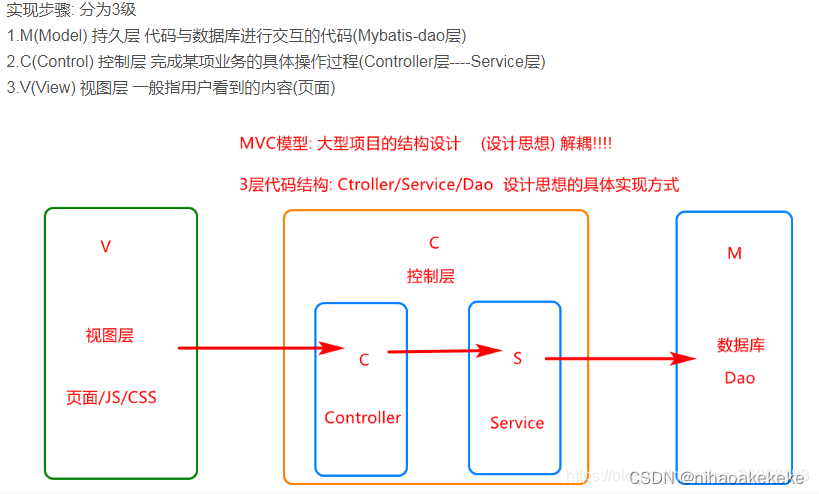
Die konkreten sind:
(1) Entitätsschicht: Die Entitätsschicht speichert bestimmte Objektentitäten, die den Objekten in der Datenbank entsprechen.
(2) DAO-Schicht: (kann in zwei Schichten unterteilt werden (die Schnittstellenschicht des Dao und die Implementierungsschicht des Dao)) ist die Schicht, die mit der Datenbank interagiert und einige Vorgänge zum Hinzufügen, Löschen, Ändern und Abfragen der Datenbank umfasst.
(3) Serviceschicht (kann in zwei Schichten unterteilt werden (Serviceschnittstellenschicht und Serviceimplementierungsschicht)): Hauptverantwortlich für das logische Anwendungsdesign von Geschäftsmodulen.
(4) Controller-Schicht: Die Controller-Schicht ist für die Steuerung bestimmter Geschäftsmodulprozesse verantwortlich. Die Controller-Schicht ist für die Front-End- und Back-End-Interaktion verantwortlich, nimmt Front-End-Anfragen an, ruft die Service-Schicht auf und empfängt die von ihr zurückgegebenen Daten die Serviceschicht und schließlich die Rückgabe bestimmter Seiten und Daten an den Client.
(5) Util-Ebene: Die Tool-Ebene platziert häufig verwendete Tool-Klassen. Beispielsweise können einige gängige Methoden als Util-Funktion geschrieben und dann der Gesamtcode vereinfacht werden.
(6) Ausnahmeschicht: Sie können eine einheitliche Rückgabeausnahmeschicht schreiben.
(7) Filterebene: Filterebene, z. B. einheitliche Filterung der Identitätsauthentifizierung. Wenn der Filter nicht besteht, befindet er sich nur im Gastmodus.
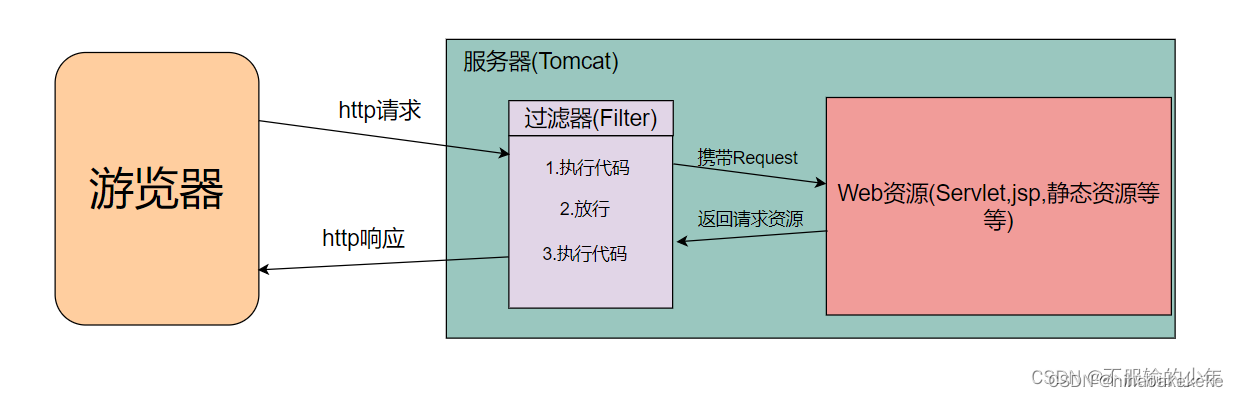
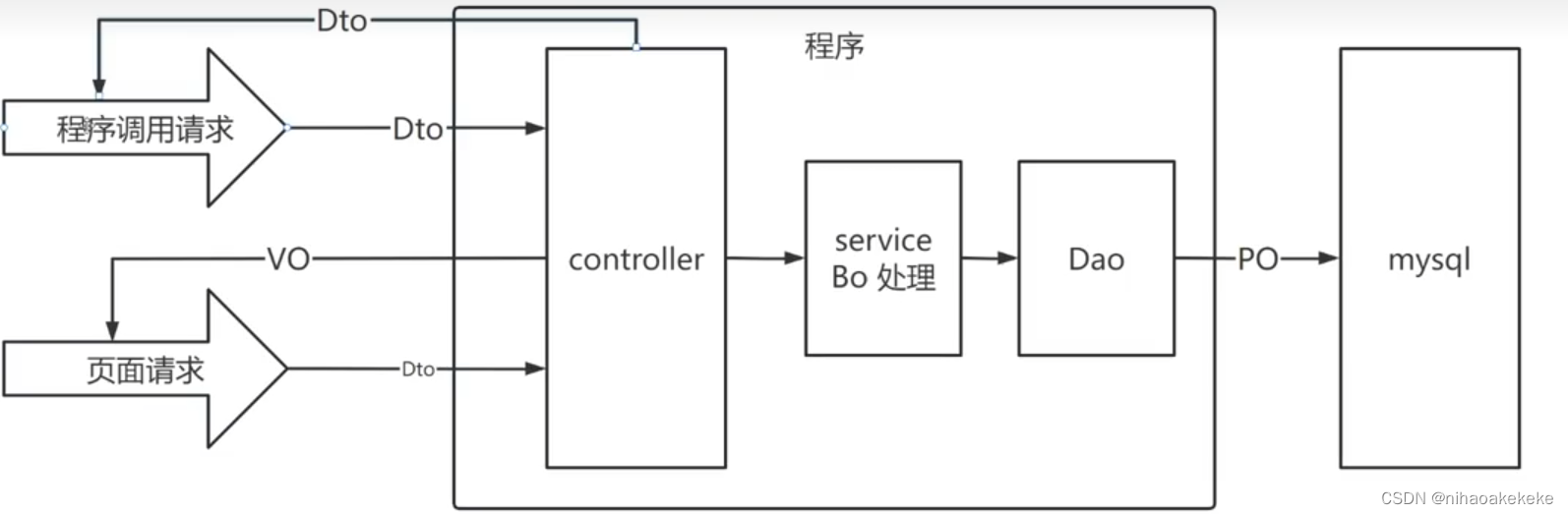
DTO ist die von der Front-End-Anfrage gesendete Datenstruktur.
VO ist die vom Backend als Antwort auf die vom Frontend gesendete Anfrage zurückgegebene Antwort.
PO ist die tatsächliche Entität zwischen der Objektentität und der Datenbankobjekttabelle.
BO ist die Objektentität im Geschäftsverarbeitungsprozess.
Bitte benennen Sie es auf Englisch, nicht auf Chinesisch Pinyin.
Seien Sie leicht verständlich und nicht ausgefallen.
Verwenden Sie Buckelnamen statt gewöhnlicher Namen.
Setzen Sie in regelmäßigen Abständen Zeilenumbrüche ein und schreiben Sie nicht in langen Absätzen.
Seien Sie kommentiert, nicht individualistisch.
Verwenden Sie keine Schlüsselwörter, reservierten Wörter usw., die in Java selbst eine besondere Bedeutung haben! ! !
(1) Der Tabellenname ist eindeutig und mehrere Tabellennamen können nicht denselben Namen verwenden.
(2) Der Tabellenname sollte eine Kombination aus Kleinbuchstaben und Unterstrichen sein. Vermeiden Sie die Verwendung von Großbuchstaben oder Sonderzeichen. Verwenden Sie „user_info“ oder „tbl_user_info“.
(3) Kein Konflikt mit Schlüsselwörtern,Um reservierte Wörter wie „like“, „desc“, „range“, „match“, „delayed“ usw. zu deaktivieren, lesen Sie bitte die offiziellen reservierten Wörter von MySQL.
(4) Datenbankfeldname: Er besteht aus 26 englischen Buchstaben (Groß- und Kleinschreibung beachten) plus dem Unterstrich „_“, wie „user_id“, „user_name“, „user_password“, „user_register_time“, „user_login_time“.
(5) Primär- und Fremdschlüsselspezifikationen:
Primärschlüssel: pk_+Tabellenname
Zum Beispiel:pk_main
Fremdschlüssel: fk_+Slave-Tabellenname+_+Haupttabellenname
Zum Beispiel:fk_sub_main
(1) Klassenanmerkung:
Klassenanmerkungen (Klasse) werden hauptsächlich verwendet, um anzugeben, wofür die Klasse verwendet wird, sowie um einige Informationen wie den Ersteller, die Version des Erstellungsdatums, den Paketnamen usw. anzugeben:
/**
* @version: V1.0
* @Autor: fendo
* @className: Benutzer
* @packageName: Benutzer
* @description: Dies ist die Benutzerklasse
* @data: 2024-07-01 12:20
**/
(2) Methodenanmerkung (Konstruktor):
/**
* @Autor: fendo
* @methodsName: Benutzer hinzufügen
* @description: Einen Benutzer hinzufügen
* @param: xxxx
* @return: Zeichenfolge
* @wirft:
*/
(3) Kommentare zum Codeblock: Erläutern Sie den Zweck eines bestimmten Teils Ihres Codes
/**
* Instanziieren Sie einen Benutzer
* xxxxxxxx
*/
Benutzer Benutzer=neuer Benutzer();
(4) Einzelsatzkommentare: Kommentieren Sie Ihren individuellen Code
Benutzer user=new User(); //Instanziieren eines Benutzers
Benennen Sie es so, dass andere es verstehen können, benennen Sie es in Kamel-Groß-/Kleinschreibung und achten Sie auf die Groß-/Kleinschreibung.
Zum Beispiel: UserController, FileController, BookService
Zum Beispiel: getUserName(), userLogin(), getMessage();
Beispiel: MAX_STOCK_COUNT / CACHE_EXPIRED_TIME
1) Der Methode zum Abrufen eines einzelnen Objekts wird get vorangestellt.2) Methoden zum Abrufen mehrerer Objekte werden mit dem Präfix „list“ und dem Ende mit „Plural“ versehen, z. B. „listObjects“.3) Der Methode zum Erhalten statistischer Werte wird count vorangestellt.4) Der Einfügemethode wird „Speichern/Einfügen“ vorangestellt.5) Der Löschmethode wird „remove/delete“ vorangestellt.6) Der geänderten Methode wird update vorangestellt.
1) Datenobjekt: xxxDO, xxx ist der Name der Datentabelle.2) Datenübertragungsobjekt: xxxDTO, xxx ist der Name, der sich auf das Geschäftsfeld bezieht.3) Anzeigeobjekt: xxxVO, xxx ist im Allgemeinen der Name der Webseite.
Dies ist eine große Gefahr bei der Verwendung vorhandener Objekte. Es wird empfohlen, zur Beurteilung die Gleichheitsmethode zu verwenden.
Positives Beispiel:(1) Geben Sie einen Fehlerbereich an. Wenn die Differenz zwischen zwei Gleitkommazahlen innerhalb dieses Bereichs liegt, werden sie als gleich betrachtet.schweben A = 1,0F - 0,9F ;schweben B = 0,9F - 0,8F ;schweben Unterschied = 1e-6F ;Wenn ( Mathematik . Abs ( A - B ) < Unterschied ) {System . aus . drucken ( "WAHR" );}(2) Verwenden Sie BigDecimal, um den Wert zu definieren, und führen Sie dann Gleitkommazahlenoperationen aus.BigDecimal a = neu Große Dezimalzahl ( "1.0" );BigDecimal b = neu Große Dezimalzahl ( "0.9" );BigDecimal c = neu Große Dezimalzahl ( "0.8" );BigDecimal x = A . subtrahieren ( B );BigDecimal y = B . subtrahieren ( C );Wenn ( X . vergleichen mit ( j ) == 0) {System . aus . drucken ( "WAHR" );}
| Bezeichnertyp | Benennungsregeln | Beispiel |
| Pakete | Das Präfix eines eindeutigen Paketnamens besteht immer nur aus kleinen ASCII-Buchstaben und ist ein Domänenname der obersten Ebene, normalerweise com, edu, gov, mil, net, org oder der englische zweistellige Code, der das im Jahr 1981 angegebene Land identifiziert ISO 3166-Standard. Die nachfolgenden Teile des Paketnamens variieren entsprechend den internen Namenskonventionen verschiedener Organisationen. Solche Namenskonventionen können die Zusammensetzung bestimmter Verzeichnisnamen verwenden, um Abteilungen, Projekte, Maschinen oder Anmeldenamen zu unterscheiden. | com.sun.eng com.apple.quicktime.v2 edu.cmu.cs.bovik.cheese |
| Klassen | Benennungsregeln: Der Klassenname ist ein Substantiv mit gemischter Groß- und Kleinschreibung, wobei der erste Buchstabe jedes Wortes groß geschrieben wird. Versuchen Sie, die Namen Ihrer Klassen prägnant und aussagekräftig zu halten. Verwenden Sie vollständige Wörter und vermeiden Sie Abkürzungen (es sei denn, die Abkürzung wird häufiger verwendet, z. B. URL oder HTML). | Klasse Raster; Klasse ImageSprite; |
| Schnittstellen | Benennungsregeln: Fallregeln ähneln Klassennamen | Schnittstelle RasterDelegate; Schnittstelle Speichern; |
| Methoden | Der Methodenname ist ein Verb in gemischter Schreibweise, wobei der erste Buchstabe des ersten Wortes klein und der erste Buchstabe der nachfolgenden Wörter groß geschrieben wird.Benennung von Kamelfällen | laufen(); schnell rennen(); getBackground(); |
| Variablen | Mit Ausnahme von Variablennamen werden alle Instanzen, einschließlich Klassen und Klassenkonstanten, in gemischter Schreibweise verwendet, wobei der erste Buchstabe des ersten Wortes kleingeschrieben wird und der erste Buchstabe nachfolgender Wörter großgeschrieben wird. Variablennamen sollten nicht mit einem Unterstrich oder Dollarzeichen beginnen, obwohl dies syntaktisch zulässig ist. Variablennamen sollten kurz und aussagekräftig sein. Variablennamen sollten so gewählt werden, dass sie leicht zu merken sind, also ihren Zweck verdeutlichen. | Aufführen<User> Benutzerliste; String-Benutzername; |
| Konstanten | Deklarationen von Klassenkonstanten und ANSI-Konstanten sollten ausschließlich in Großbuchstaben erfolgen, wobei die Wörter durch Unterstriche getrennt sein sollten. (Vermeiden Sie ANSI-Konstanten, da diese leicht zu Fehlern führen können.) | statische endgültige int MIN_WIDTH = 4; statische endgültige int MAX_WIDTH = 999; statische endgültige Int GET_THE_CPU = 1; |
a) GET: Ressourcen vom Server abrufen. (kann als Auswahlvorgang angesehen werden)b) POST: Erstellen Sie eine neue Ressource auf dem Server. (kann als Einfügeoperation betrachtet werden)c) PUT: Ressourcen auf dem Server aktualisieren. (kann als Aktualisierungsvorgang angesehen werden)d) DELETE: Ressourcen vom Server löschen. (kann als Löschvorgang betrachtet werden)
code:http-Statuscode message: Entsprechende Textbeschreibungsinformationen data
listdict- {
- "code": 200,
- "message": "new user has created",
- "data": {
- "id": "user-4d51faba-97ff-4adf-b256-40d7c9c68103",
- "firstName": "crifan",
- "lastName": "Li",
- "password": "654321",
- "phone": "13511112222",
- "createdAt": "2016-10-24T20:39:46",
- "updatedAt": "2016-10-24T20:39:46"
- ......
- }
- }
(3) Antwortstatuscode
Fehler:
2XX Erfolg
200 ok (Anfrage erfolgreich)
204 kein Inhalt (die Anfrage war erfolgreich, aber es wurde kein Ergebnis zurückgegeben)
206 Teilinhalt (der Client fordert einen Teil der Ressource an, der Server antwortet erfolgreich und gibt eine Reihe von Ressourcen zurück)
3XX-Weiterleitung
301 dauerhaft verschieben (permanente Weiterleitung)
302 gefunden (temporäre Weiterleitung)
303 siehe Sonstiges (gibt an, dass GET verwendet werden sollte, da für die der Anforderung entsprechende Ressource ein anderer URI vorhanden ist
Methode zum Abrufen der angeforderten Ressource)
304 nicht geändert (zeigt an, dass der Server die Ressource findet, wenn der Client bedingten Zugriff auf eine Ressource verwendet, die Bedingungen der Anforderung jedoch nicht den Bedingungen entsprechen. Dies hat nichts mit der Umleitung zu tun.)
307 temporäre Weiterleitung (gleiche Bedeutung wie 302)
4XX-Client-Fehler
400 fehlerhafte Anfrage (in der Anfragenachricht liegt ein Syntaxfehler vor)
401 nicht autorisiert (erfordert Authentifizierung (erste Rückgabe) oder Authentifizierung fehlgeschlagen (zweite Rückgabe))
403 verboten (die Anfrage wurde vom Server abgelehnt)
404 nicht gefunden (die angeforderte Ressource kann auf dem Server nicht gefunden werden)
5XX-Serverfehler
500 interner Serverfehler (ein Fehler ist aufgetreten, als der Server die Anfrage ausgeführt hat)
503-Dienst nicht verfügbar (der Server ist überlastet oder aufgrund von Wartungsarbeiten ausgefallen und kann die Anfrage nicht verarbeiten)
veranschaulichen: Das Standardlimit von Nginx beträgt 1 MB und das Standardlimit von Tomcat beträgt 2 MB. Wenn ein geschäftlicher Bedarf besteht, größere Inhalte zu übertragen, können Sie das serverseitige Limit erhöhen.
veranschaulichen: Nachdem die Return-Anweisung im Try-Block erfolgreich ausgeführt wurde, kehrt sie nicht sofort zurück, sondern führt die Anweisung im Final-Block weiter aus. Wenn es hier eine Return-Anweisung gibt, kehrt sie direkt hierher zurück und verwirft den Rückgabepunkt im Versuchen Sie es mit Blockieren.
Link: Klicken Sie auf den Link, um Apifox direkt herunterzuladen (laden Sie einfach die neueste Version herunter). Apifox – eine integrierte Kollaborationsplattform für API-Dokumentation, Debugging, Mocking und Tests. Es verfügt über Funktionen wie Schnittstellendokumentverwaltung, Schnittstellen-Debugging, Mock und automatisiertes Testen, und die Effizienz der Schnittstellenentwicklung, des Testens und des gemeinsamen Debuggens wird um das Zehnfache erhöht. Das beste Tool zur Schnittstellendokumentenverwaltung und zum Testen der Schnittstellenautomatisierung.![]() https://apifox.com/
https://apifox.com/

1. Erstellen Sie Ihr Team und erstellen Sie ein neues Projekt:

Laden Sie Ihre Teamkollegen ein
2. Erstellen Sie eine neue Schnittstelle und ein neues Datenmodell:
(1) Bestimmen Sie, um welche Anforderung es sich handelt (POST, GET, PUT, DELETE):
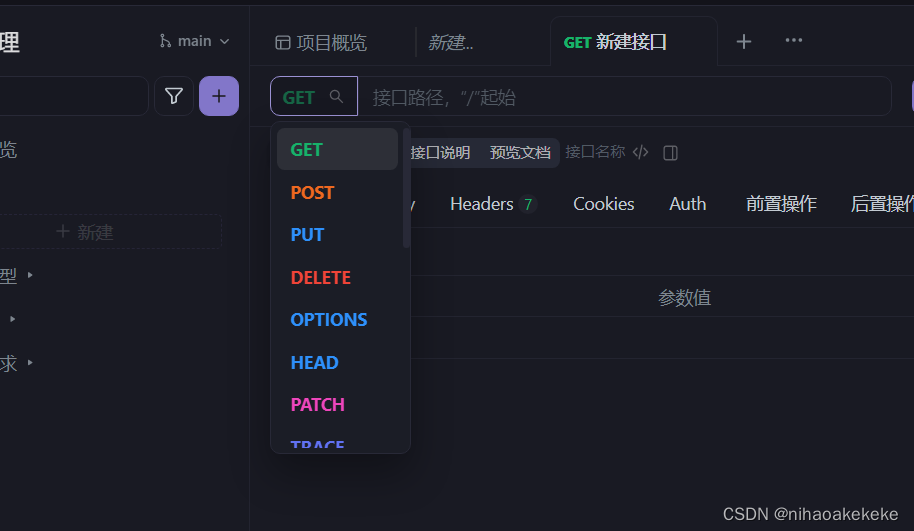
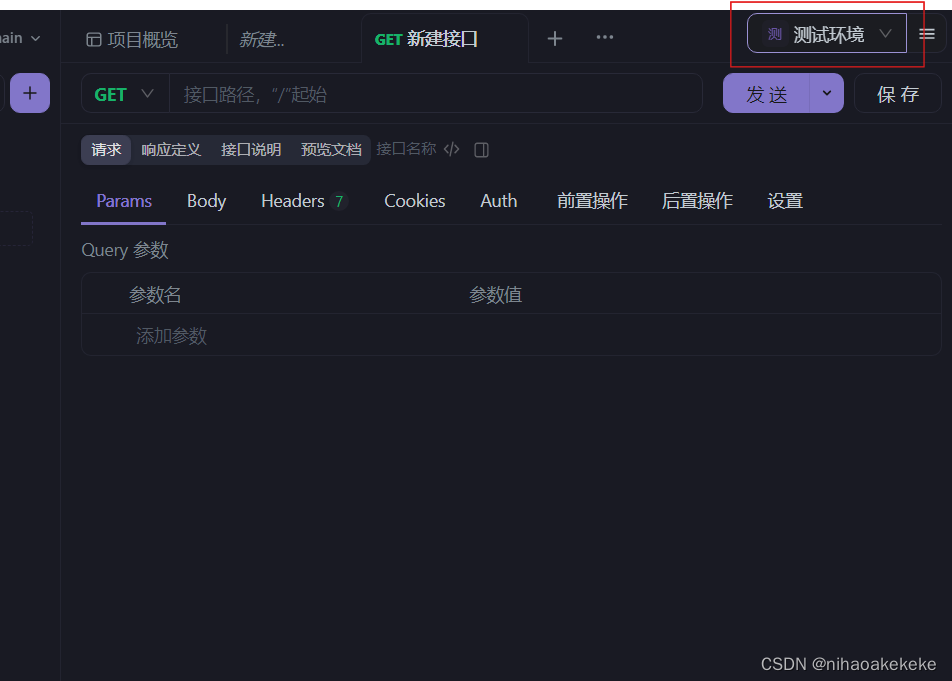
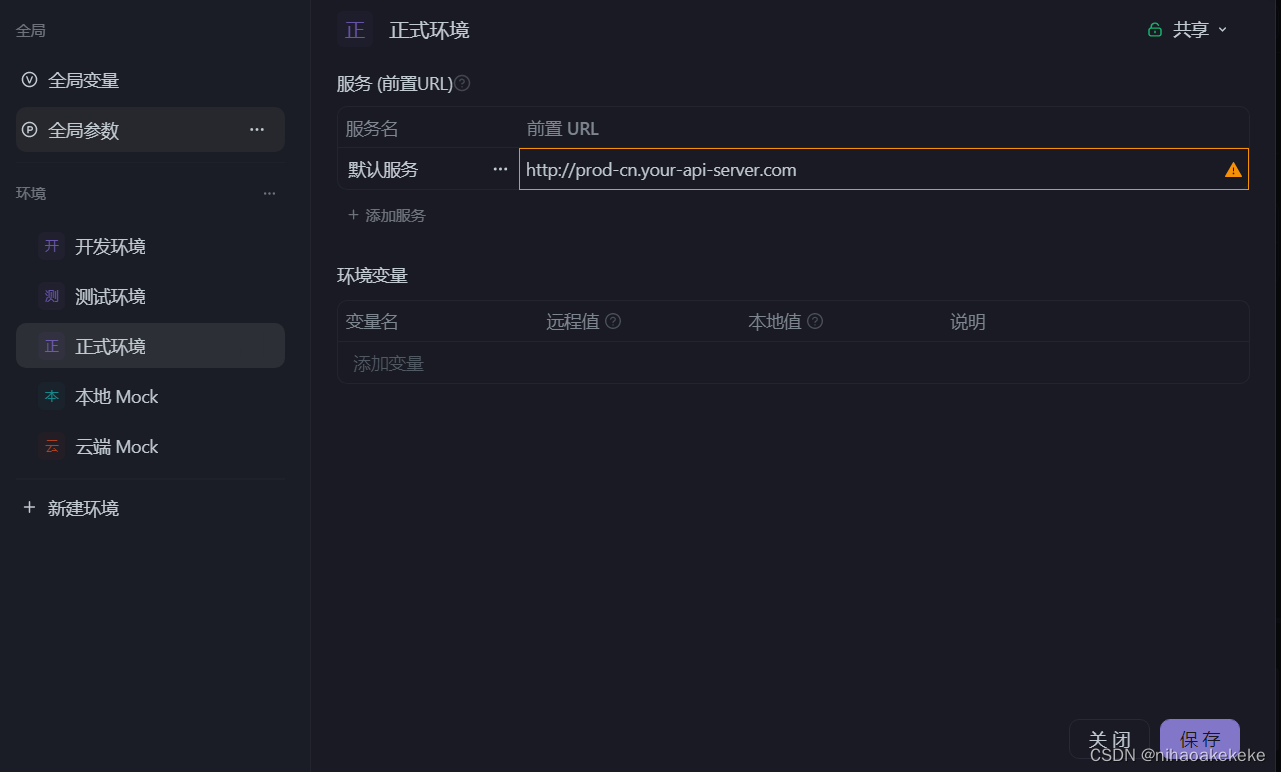
(2) Die Testumgebung muss einheitlich sein und die URLs in verschiedenen Umgebungen sind unterschiedlich:
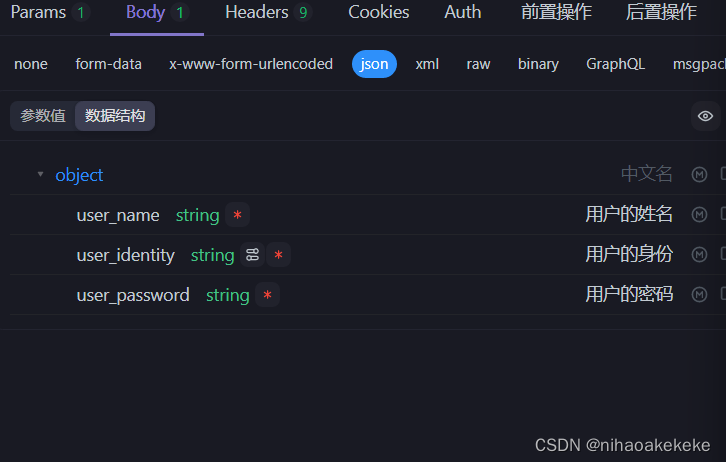
(3) Die Anforderungsparameter werden konfiguriert:
Welche Parameter sind konfiguriert? Geben Sie Parameterbeispiele, chinesische Namen und Parameterbeschreibungen an.
(4) Die Reaktion muss konfiguriert werden:
Beispielsweise muss angegeben werden, welche Art von Informationen in verschiedenen Zuständen zurückgegeben werden, und es müssen Erfolgsbeispiele und Ausnahmebeispiele vorhanden sein (zur Vereinfachung des Frontends).
- {
- "code": 200,
- "message": "登入成功",
- "data": {
- "user_id": 27,
- "user_name": "孟霞",
- "user_password": "123456",
- "user_age": "15",
- "user_photo": "http://dummyimage.com/400x400",
- "user_last_time": "1996-12-11 09:03:49",
- "user_indentity": "messager",
- "user_birthday": "2024-02-23"
- }
- }
(5) Datenmodell kann erstellt werden:
Sie können mehrere Datenmodelle erstellen, was für die Rückgabe von Antwortfeldern sehr praktisch ist und auch für die Anzeige Ihrer Datenfelder im Front-End praktisch ist.

Die Schreibvorgaben und spezifischen Details von apifox.
Apifox-Schnellstart |. Apifox-Hilfedokumentation![]() https://apifox.com/help/
https://apifox.com/help/
(1) Am Anfang des API-Schnittstellendokuments sollte eine Einführung stehen. Dieser Abschnitt kann Folgendes enthalten:
Der Zweck dieses Teils besteht darin, den Lesern die Grundsituation und Hintergrundinformationen der API-Schnittstelle verständlich zu machen.
(2) Schnittstellenliste
Als nächstes müssen wir im API-Schnittstellendokument alle Schnittstellen auflisten. Jede Schnittstelle sollte die folgenden Informationen enthalten:
Der Zweck dieses Abschnitts besteht darin, den Lesern ein schnelles Verständnis der grundlegenden Informationen jeder Schnittstelle zu ermöglichen und die Schnittstellen anhand der Beispiele im Dokument korrekt zu verwenden.
(3) Beschreibung der Anforderungsparameter und Antwortparameter
Nach der Schnittstellenliste müssen wir die Anforderungsparameter und Antwortparameter für jede Schnittstelle detailliert beschreiben. Dieser Abschnitt sollte die folgenden Informationen enthalten:
Für Parametertypen und -formate können Sie Standarddatentypen und -formate verwenden oder je nach spezifischen Umständen eigene Datentypen und -formate definieren. Ob erforderliche Werte und Standardwerte anhand der tatsächlichen Situation ermittelt werden müssen.
(4) Beschreibung des Fehlercodes
Bei der Verwendung der API-Schnittstelle kann es vorkommen, dass ein Fehler auftritt. In diesem Fall muss ein Fehlercode zurückgegeben werden, der die Art und Ursache des Fehlers erläutert. Daher müssen wir in der Dokumentation der API-Schnittstelle alle möglichen Fehlercodes angeben. Dieser Abschnitt sollte die folgenden Informationen enthalten:
Der Zweck dieses Abschnitts besteht darin, dass der Leser alle möglichen Fehlerarten und -ursachen versteht und Fehler anhand der Beispiele in der Dokumentation richtig behandeln kann.

(1) Spezifische Operationen:
Definieren Sie eine Testklasse
Anregung:
Name der Testklasse: Name der getesteten Klasse Test CalculatorTest
Paketname: xx.xx.xx.test cn.itcast.test
Testmethoden definieren: können unabhängig ausgeführt werden
Anregung:
Methodenname: Testmethodenname testAdd()
Rückgabewert: void
Parameterliste: leere Parameter
Fügen Sie @Test zur Methode hinzu
Importieren Sie die Junit-Abhängigkeitsumgebung
Urteilsergebnis:
Rot: fehlgeschlagen
grün: Erfolg
Im Allgemeinen verwenden wir die statische Methode „asserEquals(expected,actual)“ unter der Assert-Klasse, um unsere erwarteten Ergebnisse zu verarbeiten und Ergebnisse auszugeben
Assert.assertEquals(3, Ergebnis);
Die beiden Parameter sind: Erwartungswert, Programmergebniswert
Warum sollte Assert.assertEquals(expected,actual) zur Verarbeitung von Testergebnissen verwendet werden?
Weil wir festlegen, dass Rot für Fehler und Grün für Richtigkeit steht. Wenn wir eine Testmethode verwenden, um die Additionsmethode eines Computers zu testen, geben wir nur dieses Ergebnis aus (vorausgesetzt, es tritt keine Ausnahme auf). Wenn wir 1 und 3 eingeben, erwarten wir das Ergebnis 4, aber was wir ausgeben, ist 2 und was wir erwarten, ist 4. Das zu diesem Zeitpunkt erhaltene Ergebnis entspricht nicht unseren Erwartungen, aber das laufende Ergebnis ist immer noch grün (Stellt richtig dar), ist das nicht richtig? Zu diesem Zeitpunkt können wir die AssertEquals-Methode am Ende verwenden, um den erwarteten Wert und den vom Programm ausgegebenen Ergebniswert zu vergleichen Wenn sie nicht gleich sind, wird es rot sein. Entspricht diese Zeit unserer Definition von Grün und Rot?
- package cn.itcast.test;
-
- import cn.itcast.junit.Calculator;
- import org.junit.Assert;
- import org.junit.Test;
-
- public class CalculatorTest {
- /**
- * 测试add方法
- */
- @Test
- public void testAdd(){
- Calculator c = new Calculator();
- int a = 1, b = 2;
- int result = c.add(1, 2);
- Assert.assertEquals(3, result);
- }
-
- /**
- * 测试sub方法
- */
- @Test
- public void testSub(){
- Calculator c = new Calculator();
- int a = 1, b = 2;
- int result = c.sub(1, 2);
- Assert.assertEquals(-1, 2);
- }
- }
-
@Vor
Wenn Sie @Before vor einer Testmethode hinzufügen, wird diese Methode automatisch ausgeführt, bevor alle Testmethoden ausgeführt werden. Sie wird im Allgemeinen für die Ressourcenanwendung verwendet.
@Nach
Fügen Sie @After vor einer Testmethode hinzu und es wird zu einer Ressourcenfreigabemethode, die automatisch ausgeführt wird, nachdem alle Testmethoden ausgeführt wurden.
Die mit @Before dekorierte Methode wird ausgeführt, bevor die Testmethode ausgeführt wird.
Die mit @After dekorierte Methode wird ausgeführt, nachdem die Testmethode ausgeführt wurde.
Mit @Before oder @After geänderte Methoden werden unabhängig davon ausgeführt, ob die Testmethode auftritt.
(2) Testklassen-Plug-Ins automatisch generieren
(1) Wenn Sie das Schnittstellendokument im Backend schreiben, sollte es klar und deutlich geschrieben sein, damit Ihr Frontend es verstehen kann. Schreiben Sie es nicht so, dass Sie es selbst verstehen können . Der neu geschriebene Name und die Standardwert-Schnittstellenantwort sollten gut geschrieben sein.
(2) Zusätzlich zu dem, was gelehrt wird, können Sie einige andere Dinge selbst lernen, z. B. E-Mail-Verifizierungsregistrierung, Bestätigungscode-Anmeldung, c3p0, MD5-Verschlüsselung, Protokollprotokolle, Ergebnisstil usw.
(3) Das Schreiben des Codes muss ebenfalls standardisiert sein und die Logik muss streng sein. Wo leere Urteile erforderlich sind, müssen leere Urteile gefällt werden, und wo die Sicherheit erhöht werden kann, kann man daraus lernen.
(4) Das Front-End und das Back-End müssen gut zusammenarbeiten. Lassen Sie das Back-End nicht einfach sein eigenes Ding machen, ohne ein Wort zum Front-End zu sagen. Die interaktive Reaktion des Frontends und Backends ist ebenfalls Teil der Bewertung und macht einen großen Teil aus. Die von Ihnen geschriebene Schnittstelle kann nicht nur über apifox ausgeführt werden. Gibt es Fehler, wenn sie auf der spezifischen Frontend-Seite angezeigt wird? ? Gibt es logische Probleme usw., die möglicherweise berücksichtigt werden müssen?
(5) Legen Sie während der Bedarfsanalyse fest, welche Funktionen und Schnittstellen Sie ausführen möchten, das Front-End hat sie jedoch nicht ausgeführt, wenn die ausgeführten Aufgaben Ihr Back-End erfordern interfaces/data , wenn Sie nicht geschrieben haben, denken Sie sorgfältig nach und kommunizieren Sie mehr.
Sie können einen Vergleich mit tatsächlich funktionierenden Projekten oder Ähnlichem durchführen, beispielsweise mit einer Shopping-Website. Dann sollten Sie die Back-End-Schnittstellen dieser Website, die Funktionsmodule und die spezifischen Details mit Taobao vergleichen.
(6) Streben Sie nicht blind nach mehr, seien Sie logisch und vernünftig und lernen Sie, die Teile zu vereinfachen, die vereinfacht werden können. Aber auch die Grundanzahl an Schnittstellen und Codevolumen muss gewährleistet sein. (Die Schnittstellen, die wir ursprünglich geschrieben haben, waren im Grunde mehr als 40)

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

