2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) ist ein maschineller Lernalgorithmus, der auf Gradient Boosting basiert und von Yandex (einem russischen Internetunternehmen, dessen Suchmaschine einst mehr als 60 % des Marktanteils in Russland hielt und das auch andere Internetprodukte und -dienste anbietet) entwickelt wurde. CatBoost ist besonders gut im Umgang mit kategorialen Merkmalen und kann Überanpassungs- und Datenleckprobleme effektiv vermeiden. Der vollständige Name von CatBoost lautet „Categorical Boosting“. Es wurde entwickelt, um eine bessere Leistung bei der Verarbeitung von Daten mit einer großen Anzahl kategorialer Merkmale zu erzielen.
Verarbeitung kategorialer Merkmale: CatBoost kann kategoriale Merkmale ohne zusätzliche Codierung (z. B. One-Hot-Codierung) direkt verarbeiten.
Vermeiden Sie eine Überanpassung: CatBoost verwendet eine neue Methode zur Verarbeitung von Kategoriemerkmalen, die eine Überanpassung effektiv reduziert.
Effizienz: CatBoost schneidet sowohl bei der Trainingsgeschwindigkeit als auch bei der Vorhersagegeschwindigkeit gut ab.
Unterstützt CPU- und GPU-Training: CatBoost kann auf der CPU laufen oder die GPU für beschleunigtes Training nutzen.
Fehlende Werte automatisch behandeln: CatBoost kann fehlende Werte ohne zusätzliche Vorverarbeitungsschritte automatisch verarbeiten.
Das Kernprinzip von CatBoost basiert auf dem Gradient Boosting Decision Tree (GBDT), ist jedoch innovativ bei der Verarbeitung kategorialer Merkmale und der Vermeidung von Überanpassung. Hier sind einige wichtige technische Punkte:
Verarbeitung von Kategoriemerkmalen:
CatBoost führt eine Methode namens „Mean Encoding“ ein, um neue Features basierend auf dem Mittelwert der Kategorien zu berechnen.
Mithilfe einer Technik namens „Zielkodierung“ wird das Risiko von Datenlecks verringert, indem bei der Konvertierung kategorialer Merkmale in numerische Merkmale der Durchschnitt der Zielwerte verwendet wird.
Während des Trainingsprozesses werden die Daten mithilfe statistischer Informationen verarbeitet, um eine direkte Kodierung der Zielvariablen zu vermeiden.
Boosting angeordnet:
Um Datenverlust und Überanpassung zu verhindern, verarbeitet CatBoost die Daten während des Trainings in geordneter Weise.
Ordered Boosting funktioniert durch zufälliges Mischen der Daten während des Trainings und stellt sicher, dass das Modell nur vergangene Daten zu einem bestimmten Zeitpunkt sieht und keine zukünftigen Informationen verwendet, um Entscheidungen zu treffen.
Computeroptimierung:
CatBoost beschleunigt den Feature-Berechnungsprozess durch Vorberechnung und Caching.
Unterstützt CPU- und GPU-Training und kann bei großen Datensätzen gute Leistungen erbringen.
Das Folgende ist ein grundlegendes Beispiel für die Verwendung von CatBoost für eine Klassifizierungsaufgabe. Wir verwenden den Auto MPG-Datensatz (Miles Per Gallon), einen klassischen Regressionsproblemdatensatz, der häufig beim maschinellen Lernen und in der statistischen Analyse verwendet wird. Dieser Datensatz erfasst die Kraftstoffeffizienz (d. h. Meilen pro Gallone) verschiedener Automodelle sowie mehrere andere damit verbundene Merkmale.
Eigenschaften des Datensatzes:
mpg: Meilen pro Gallone (Zielvariable).
Zylinder: Anzahl der Zylinder, gibt die Anzahl der Zylinder im Motor an.
Verschiebung: Hubraum (Kubikzoll).
PS: Motorleistung (PS).
Gewicht: Fahrzeuggewicht in Pfund.
Beschleunigung: Beschleunigungszeit von 0 auf 60 Meilen pro Stunde (Sekunden).
Model Jahr: Fahrzeugproduktionsjahr.
Herkunft: Fahrzeugherkunft (1=USA, 2=Europa, 3=Japan).
Die ersten Zeilen des Datensatzes:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Codebeispiel:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Mittlerer quadrierter Fehler (MSE) : Mittlerer quadratischer Fehler, der die durchschnittliche quadratische Differenz zwischen dem vorhergesagten Wert und dem tatsächlichen Wert darstellt. Je kleiner der Wert, desto besser ist die Modellleistung, hier beträgt der MSE-Wert 4,9042.
Mittlerer absoluter Fehler (MAE) : Mittlerer absoluter Fehler, der die durchschnittliche absolute Differenz zwischen dem vorhergesagten Wert und dem tatsächlichen Wert darstellt. Je kleiner der Wert, desto besser ist die Modellleistung. Hier beträgt der MAE-Wert 1,6381.
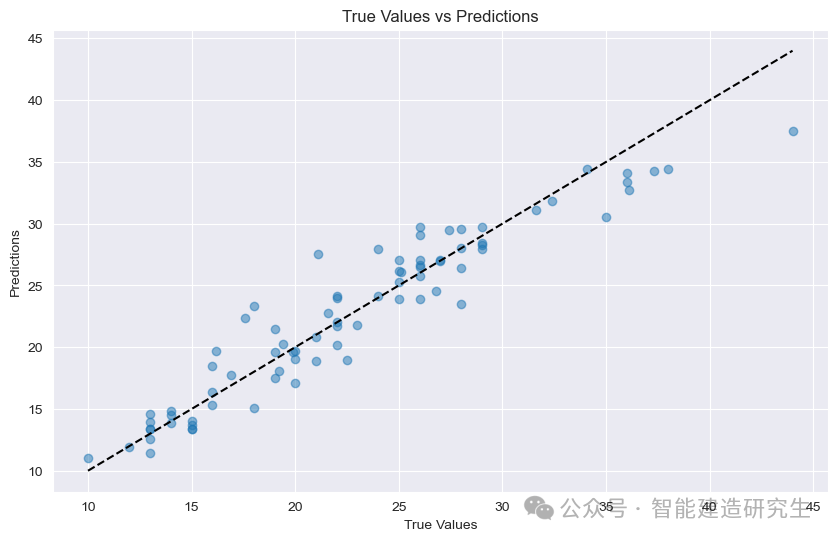
Streudiagramm : Jeder Punkt im Diagramm stellt eine Testprobe dar. Die Abszisse stellt den wahren Wert der Probe (MPG) dar und die Ordinate stellt den vorhergesagten Wert des Modells (MPG) dar.
Diagonale: Die schwarz gepunktete Linie in der Abbildung ist eine 45-Grad-Diagonallinie, die das Vorhersageergebnis unter idealen Bedingungen darstellt, dh der vorhergesagte Wert entspricht dem wahren Wert.
Punkteverteilung:
nahezu diagonal: Zeigt an, dass der vorhergesagte Wert des Modells dem wahren Wert sehr nahe kommt und die Vorhersage genau ist.
Halten Sie sich von der Diagonale fern: Zeigt an, dass zwischen dem vorhergesagten Wert und dem tatsächlichen Wert eine große Lücke besteht und die Vorhersage ungenau ist.
Anhand der Punkte in der Abbildung können Sie erkennen, dass die meisten Punkte in der Nähe der Diagonale konzentriert sind, was darauf hinweist, dass das Modell über eine gute Vorhersageleistung verfügt. Es gibt jedoch auch einige Punkte, die weit von der Diagonale entfernt sind, was darauf hindeutet, dass dies der Fall ist eine gewisse Lücke zwischen den vorhergesagten Werten dieser Stichproben und den wahren Werten.
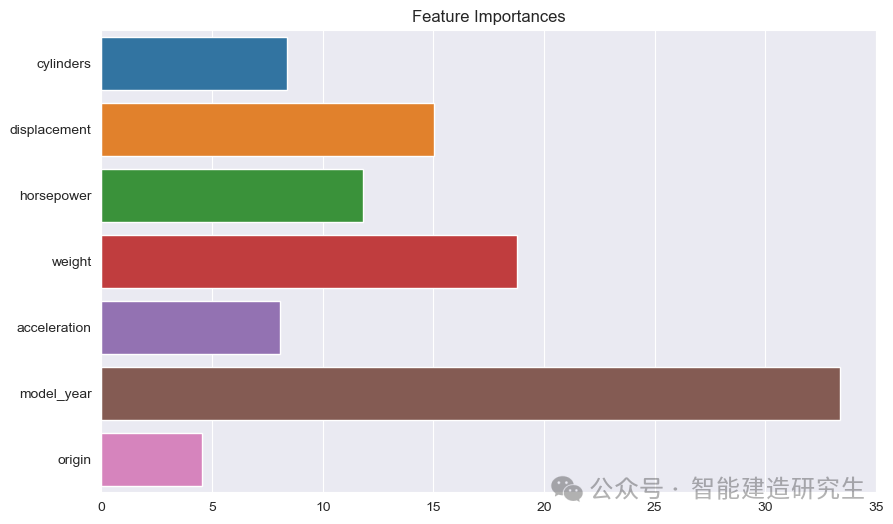
Balkendiagramm : Jeder Balken repräsentiert die Wichtigkeit eines Features im Modell. Je länger der Balken ist, desto größer ist der Beitrag des Features zur Modellvorhersage.
Funktionsname: Listet die Namen aller Features auf der Y-Achse auf.
Wert der Feature-Wichtigkeit: Zeigt den relativen Wichtigkeitswert jedes Features auf der X-Achse an.
Wie auf dem Bild zu sehen ist:
Model Jahr: Das wichtigste aller Merkmale, was darauf hinweist, dass das Produktionsjahr des Fahrzeugs einen starken Einfluss auf die prognostizierte Kraftstoffeffizienz hat.
Gewicht: Das Gewicht eines Autos ist das zweitwichtigste Merkmal und hat auch einen erheblichen Einfluss auf die Kraftstoffeffizienz.
VerschiebungUndPS: Auch Hubraum und Leistung des Motors tragen wesentlich zur Kraftstoffeffizienz bei.
Im Beispiel verwenden wir CatBoost, um den Auto MPG-Datensatz zu verarbeiten, dessen Hauptzweck darin besteht, ein Regressionsmodell zur Vorhersage der Kraftstoffeffizienz eines Autos (d. h. Meilen pro Gallone, MPG) zu erstellen.
Der obige Inhalt ist aus dem Internet zusammengefasst. Wenn er hilfreich ist, leiten Sie ihn bitte weiter.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

