
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) é um algoritmo de aprendizado de máquina baseado em gradiente boosting desenvolvido pela Yandex (uma empresa russa de Internet cujo mecanismo de pesquisa já detinha mais de 60% da participação de mercado na Rússia e também fornece outros produtos e serviços de Internet). CatBoost é particularmente bom no tratamento de recursos categóricos e pode efetivamente evitar problemas de overfitting e vazamento de dados. O nome completo do CatBoost é "Categorical Boosting". Ele foi projetado para ter melhor desempenho ao processar dados que contêm um grande número de recursos categóricos.
Processando recursos categóricos: CatBoost pode processar recursos categóricos diretamente sem codificação adicional (como codificação one-hot).
Evite ajuste excessivo: CatBoost adota um novo método de processamento de recursos de categoria, que reduz efetivamente o overfitting.
Eficiência: CatBoost tem um bom desempenho tanto na velocidade de treinamento quanto na velocidade de previsão.
Suporta treinamento de CPU e GPU: CatBoost pode ser executado na CPU ou usar a GPU para treinamento acelerado.
Lidar automaticamente com valores ausentes: CatBoost pode lidar automaticamente com valores ausentes sem etapas adicionais de pré-processamento.
O princípio básico do CatBoost é baseado na árvore de decisão de aumento de gradiente (GBDT), mas é inovador no processamento de recursos categóricos e evitando overfitting. Aqui estão alguns pontos técnicos importantes:
Processamento de recursos de categoria:
CatBoost introduz um método chamado “codificação média” para calcular novos recursos com base na média das categorias.
Usando uma técnica chamada "codificação de destino", o risco de vazamento de dados é reduzido usando a média dos valores de destino ao converter recursos categóricos em recursos numéricos.
Durante o processo de treinamento, os dados são processados usando informações estatísticas para evitar a codificação direta da variável alvo.
Impulso ordenado:
Para evitar vazamento de dados e ajuste excessivo, CatBoost processa os dados de maneira ordenada durante o treinamento.
O boosting ordenado funciona embaralhando aleatoriamente os dados durante o treinamento e garante que o modelo só veja os dados passados em um determinado momento e não use informações futuras para tomar decisões.
Otimização computacional:
CatBoost acelera o processo de cálculo de recursos por meio de pré-computação e armazenamento em cache.
Suporta treinamento de CPU e GPU e pode funcionar bem em conjuntos de dados em grande escala.
A seguir está um exemplo básico de uso do CatBoost para uma tarefa de classificação. Usamos o conjunto de dados Auto MPG (Miles Per Gallon), que é um conjunto de dados de problema de regressão clássico comumente usado em aprendizado de máquina e análise estatística. Este conjunto de dados registra a eficiência de combustível (ou seja, milhas por galão) de diferentes modelos de automóveis, bem como diversas outras características relacionadas.
Características do conjunto de dados:
milha por galão: Milhas por galão (variável alvo).
cilindros: Número de cilindros, indicando a quantidade de cilindros do motor.
deslocamento: Cilindrada do motor (polegadas cúbicas).
cavalo-vapor: Potência do motor (cavalos de potência).
peso: Peso do veículo em libras.
aceleração: Tempo de aceleração de 0 a 60 mph (segundos).
ano modelo: Ano de produção do veículo.
origem: Origem do veículo (1=Estados Unidos, 2=Europa, 3=Japão).
As primeiras linhas do conjunto de dados:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Exemplo de código:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Erro Quadrático Médio (MSE) : Erro quadrático médio, que representa a diferença quadrática média entre o valor previsto e o valor real. Quanto menor o valor, melhor o desempenho do modelo, aqui o valor do MSE é 4,9042.
Erro Absoluto Médio (MAE) : Erro médio absoluto, que representa a diferença média absoluta entre o valor previsto e o valor real. Quanto menor o valor, melhor o desempenho do modelo, aqui o valor do MAE é 1,6381.
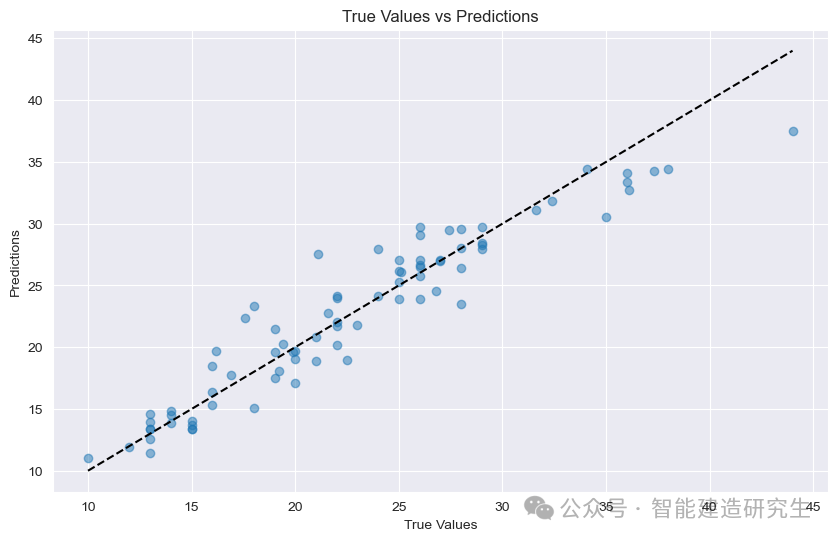
Gráfico de dispersão : Cada ponto na figura representa uma amostra de teste. A abscissa representa o valor verdadeiro da amostra (MPG) e a ordenada representa o valor previsto do modelo (MPG).
diagonal: A linha pontilhada preta na figura é uma linha diagonal de 45 graus, que representa o resultado da previsão em condições ideais, ou seja, o valor previsto é igual ao valor verdadeiro.
Distribuição de pontos:
perto da diagonal: indica que o valor previsto do modelo está muito próximo do valor verdadeiro e a previsão é precisa.
fique longe da diagonal: indica que há uma grande lacuna entre o valor previsto e o valor real e que a previsão é imprecisa.
A partir dos pontos da figura, você pode ver que a maioria dos pontos está concentrada perto da diagonal, o que indica que o modelo tem um bom desempenho de previsão. Porém, também existem alguns pontos que estão distantes da diagonal, indicando que existe. uma certa lacuna entre os valores previstos dessas amostras e os valores reais.
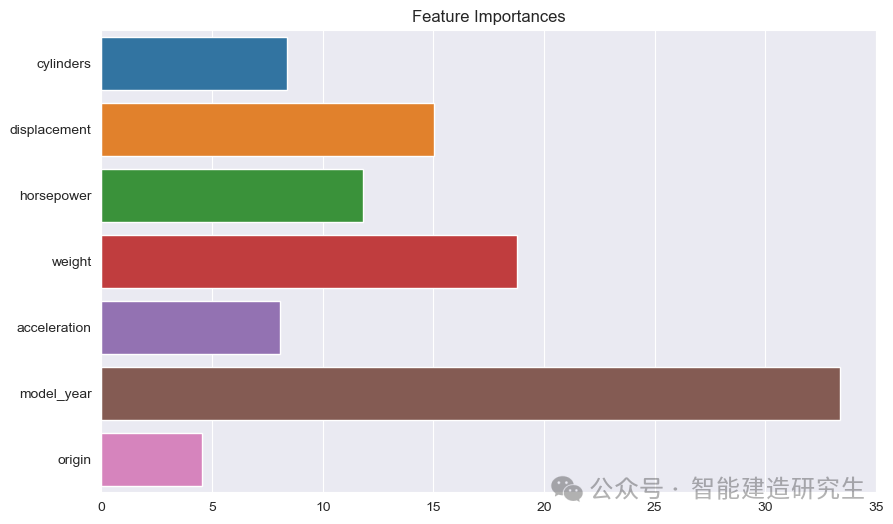
Gráfico de barras : Cada barra representa a importância de um recurso no modelo. Quanto mais longa a barra, maior será a contribuição do recurso para a previsão do modelo.
Nome do recurso: lista os nomes de todos os recursos no eixo Y.
Valor de importância do recurso: mostra o valor de importância relativa de cada recurso no eixo X.
Como pode ser visto na foto:
ano modelo: A mais importante entre todas as características, indicando que o ano de produção do carro tem um forte impacto na eficiência de combustível prevista.
peso: O peso de um carro é a segunda característica mais importante e também tem um impacto significativo na eficiência de combustível.
deslocamentoecavalo-vapor: A cilindrada e a potência do motor também contribuem significativamente para a eficiência de combustível.
No exemplo, usamos CatBoost para processar o conjunto de dados Auto MPG, cujo objetivo principal é construir um modelo de regressão para prever a eficiência de combustível de um carro (ou seja, milhas por galão, MPG).
O conteúdo acima foi resumido da Internet. Se for útil, encaminhe-o na próxima vez!

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]