
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Категорическое бустинг) — алгоритм машинного обучения, основанный на градиентном бустинге, разработанный Яндексом (российской интернет-компанией, чья поисковая система когда-то занимала более 60% доли рынка в России, а также предоставляла другие интернет-продукты и услуги). CatBoost особенно хорошо справляется с категориальными функциями и позволяет эффективно избегать проблем переобучения и утечки данных. Полное название CatBoost — «Категорическое повышение». Оно предназначено для повышения производительности при обработке данных, содержащих большое количество категориальных функций.
Обработка категориальных признаков: CatBoost может напрямую обрабатывать категориальные функции без дополнительного кодирования (например, горячего кодирования).
Избегайте переобучения: CatBoost использует новый метод обработки функций категорий, который эффективно уменьшает переобучение.
Эффективность: CatBoost показывает хорошие результаты как по скорости обучения, так и по скорости прогнозирования.
Поддерживает обучение процессора и графического процессора.: CatBoost может работать на процессоре или использовать графический процессор для ускоренного обучения.
Автоматически обрабатывать пропущенные значения: CatBoost может автоматически обрабатывать пропущенные значения без дополнительных шагов предварительной обработки.
Основной принцип CatBoost основан на дереве решений повышения градиента (GBDT), но он является инновационным в обработке категориальных функций и предотвращении переобучения. Вот некоторые ключевые технические моменты:
Обработка признаков категории:
CatBoost представляет метод под названием «кодирование среднего значения» для расчета новых функций на основе среднего значения категорий.
Используя метод, называемый «целевое кодирование», риск утечки данных снижается за счет использования среднего значения целевых значений при преобразовании категориальных признаков в числовые признаки.
В процессе обучения данные обрабатываются с использованием статистической информации, чтобы избежать прямого кодирования целевой переменной.
Заказное усиление:
Чтобы предотвратить утечку данных и переобучение, CatBoost упорядоченно обрабатывает данные во время обучения.
Упорядоченное повышение работает путем случайного перемешивания данных во время обучения и гарантирует, что модель видит прошлые данные только в определенный момент и не использует будущую информацию для принятия решений.
Вычислительная оптимизация:
CatBoost ускоряет процесс расчета объектов за счет предварительного вычисления и кэширования.
Поддерживает обучение процессоров и графических процессоров и может хорошо работать с крупномасштабными наборами данных.
Ниже приведен базовый пример использования CatBoost для задачи классификации. Мы используем набор данных Auto MPG (мили на галлон), который представляет собой классический набор данных для задачи регрессии, обычно используемый в машинном обучении и статистическом анализе. В этом наборе данных фиксируется топливная экономичность (т. е. количество миль на галлон) различных моделей автомобилей, а также некоторые другие связанные характеристики.
Характеристики набора данных:
миль на галлон: миль на галлон (целевая переменная).
цилиндры: Число цилиндров, указывающее количество цилиндров в двигателе.
смещение: Объем двигателя (кубические дюймы).
Лошадиные силы: Мощность двигателя (лошадиные силы).
масса: Вес автомобиля в фунтах.
ускорение: Время разгона от 0 до 60 миль в час (секунд).
год выпуска: Год выпуска автомобиля.
источник: Происхождение автомобиля (1=США, 2=Европа, 3=Япония).
Первые несколько строк набора данных:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Пример кода:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Среднеквадратическая ошибка (СКО) : Среднеквадратическая ошибка, которая представляет собой среднеквадратическую разницу между прогнозируемым значением и фактическим значением. Чем меньше значение, тем лучше производительность модели, здесь значение MSE равно 4,9042.
Средняя абсолютная ошибка (MAE) : Средняя абсолютная ошибка, которая представляет собой среднюю абсолютную разницу между прогнозируемым значением и фактическим значением. Чем меньше значение, тем лучше производительность модели, здесь значение MAE составляет 1,6381.
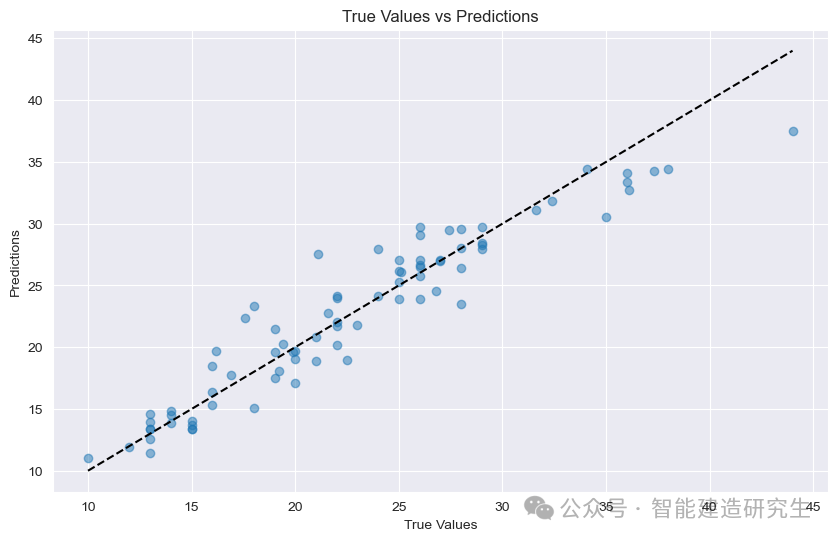
График рассеяния : Каждая точка на рисунке представляет тестовый образец. По оси абсцисс отображается истинное значение выборки (миль на галлон), а по оси ординат — прогнозируемое значение модели (миль на галлон).
диагональ: Черная пунктирная линия на рисунке представляет собой диагональную линию под углом 45 градусов, которая представляет результат прогнозирования в идеальных условиях, то есть прогнозируемое значение равно истинному значению.
Распределение очков:
близко к диагонали: указывает, что прогнозируемое значение модели очень близко к истинному значению и прогноз является точным.
держись подальше от диагонали: указывает на большой разрыв между прогнозируемым значением и фактическим значением, а также на то, что прогноз является неточным.
Из точек на рисунке видно, что большинство точек сосредоточено вблизи диагонали, что указывает на хорошую прогнозируемость модели. Однако есть также некоторые точки, которые находятся далеко от диагонали, что указывает на ее наличие. определенный разрыв между прогнозируемыми значениями этих образцов и истинными значениями.
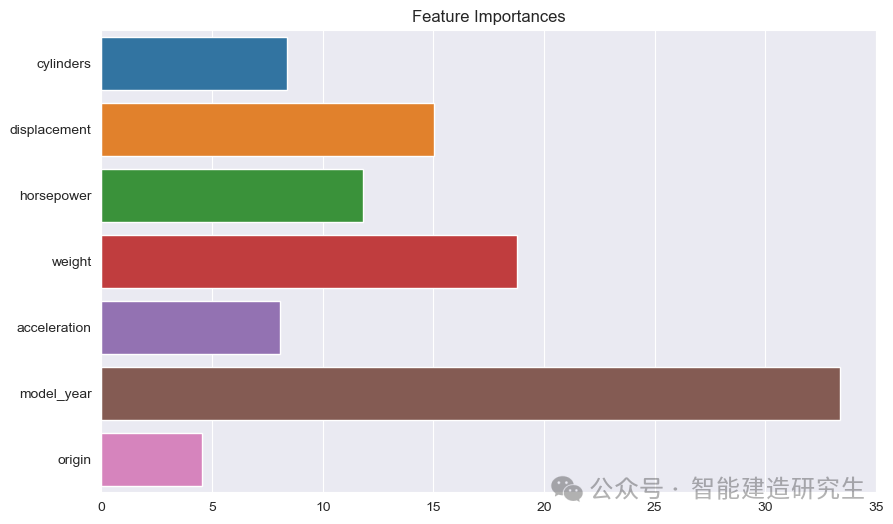
Гистограмма : каждая полоса отражает важность функции в модели. Чем длиннее полоса, тем больший вклад признака в прогноз модели.
Название функции: список названий всех объектов по оси Y.
Значение важности функции: Показывает относительную важность каждой функции по оси X.
Как видно из картинки:
год выпуска: Самая важная из всех характеристик, указывающая на то, что год выпуска автомобиля оказывает сильное влияние на прогнозируемую топливную экономичность.
масса: Вес автомобиля является второй по значимости характеристикой и также оказывает существенное влияние на топливную экономичность.
смещениеиЛошадиные силы: Объем и мощность двигателя также существенно влияют на топливную экономичность.
В этом примере мы используем CatBoost для обработки набора данных Auto MPG, основная цель которого — построить регрессионную модель для прогнозирования топливной эффективности автомобиля (т. е. миль на галлон, миль на галлон).
Вышеуказанный контент взят из Интернета. Если он вам полезен, перешлите его. Увидимся в следующий раз!

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com