2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) इति यन्त्रशिक्षण-एल्गोरिदम् अस्ति यत् Gradient boosting इत्यस्य आधारेण Yandex (रूसी-अन्तर्जाल-कम्पनी यस्याः अन्वेषण-इञ्जिन् एकदा रूस-देशे ६०% अधिकं मार्केट्-भागं धारयति स्म, अन्ये अन्तर्जाल-उत्पादाः सेवाश्च अपि प्रदाति) इत्यनेन विकसितम् अस्ति CatBoost विशेषतया श्रेणीगतविशेषतानां नियन्त्रणे उत्तमः अस्ति तथा च प्रभावीरूपेण अतिफिटिंग् तथा डाटा लीकेज समस्यां परिहरितुं शक्नोति । CatBoost इत्यस्य पूर्णं नाम "Categorical Boosting" इति अस्ति ।
श्रेणीगतविशेषतानां संसाधनम्: CatBoost अतिरिक्त-एन्कोडिंग् (यथा एक-उष्ण-एन्कोडिंग्) विना प्रत्यक्षतया श्रेणीगत-विशेषताः संसाधितुं शक्नोति ।
अतिफिटिंग् परिहरन्तु: CatBoost श्रेणीविशेषतानां संसाधनस्य नूतनां पद्धतिं स्वीकुर्वति, यत् प्रभावीरूपेण अतिफिटिंग् न्यूनीकरोति ।
कुशलता: CatBoost प्रशिक्षणवेगयोः भविष्यवाणीवेगयोः च उत्तमं प्रदर्शनं करोति ।
CPU तथा GPU प्रशिक्षणं समर्थयति: CatBoost CPU इत्यत्र चालयितुं शक्नोति अथवा त्वरितप्रशिक्षणार्थं GPU इत्यस्य उपयोगं कर्तुं शक्नोति।
स्वयमेव लुप्तमूल्यानि सम्पादयन्तु: CatBoost स्वयमेव अतिरिक्तपूर्वसंसाधनपदार्थान् विना अनुपलब्धमूल्यानि नियन्त्रयितुं शक्नोति।
CatBoost इत्यस्य मूलसिद्धान्तः ग्रेडिएण्ट् बूस्टिंग् डिसिजन ट्री (GBDT) इत्यस्य आधारेण अस्ति, परन्तु श्रेणीगतविशेषतानां संसाधने अतिफिटिंग् परिहरणे च अभिनवः अस्ति अत्र केचन प्रमुखाः तान्त्रिकबिन्दवः सन्ति- १.
श्रेणी विशेषता संसाधन:
CatBoost इत्यनेन "mean encoding" इति पद्धतिः प्रवर्तते यत् श्रेणीनां mean इत्यस्य आधारेण नूतनानां विशेषतानां गणना भवति ।
"लक्ष्यसङ्केतन" इति तकनीकस्य उपयोगेन श्रेणीगतविशेषतानां संख्यात्मकविशेषतासु परिवर्तनं कुर्वन् लक्ष्यमूल्यानां औसतस्य उपयोगेन दत्तांशलीकेजस्य जोखिमः न्यूनीकरोति
प्रशिक्षणप्रक्रियायाः कालखण्डे लक्ष्यचरस्य प्रत्यक्षतया एन्कोडिंग् न कर्तुं सांख्यिकीयसूचनायाः उपयोगेन दत्तांशस्य संसाधनं भवति ।
आदेशित बूस्टिंग:
दत्तांशस्य लीकेजं, अतिफिटिङ्ग् च निवारयितुं CatBoost प्रशिक्षणकाले क्रमेण दत्तांशं संसाधयति ।
क्रमबद्धं बूस्टिंग् प्रशिक्षणकाले यादृच्छिकरूपेण आँकडानां परिवर्तनं कृत्वा कार्यं करोति तथा च सुनिश्चितं करोति यत् मॉडलः केवलं एकस्मिन् निश्चिते क्षणे पूर्वदत्तांशं पश्यति तथा च निर्णयार्थं भविष्यस्य सूचनानां उपयोगं न करोति।
कम्प्यूटेशनल अनुकूलन:
CatBoost पूर्वगणना तथा संग्रहणद्वारा विशेषतागणनाप्रक्रियाम् त्वरयति ।
CPU तथा GPU प्रशिक्षणं समर्थयति तथा च बृहत्-परिमाणस्य आँकडा-समूहेषु उत्तमं प्रदर्शनं कर्तुं शक्नोति ।
वर्गीकरणकार्यस्य कृते CatBoost इत्यस्य उपयोगस्य मूलभूतं उदाहरणं निम्नलिखितम् अस्ति वयं Auto MPG (Miles Per Gallon) आँकडासमूहस्य उपयोगं कुर्मः, यत् यन्त्रशिक्षणे सांख्यिकीयविश्लेषणे च सामान्यतया उपयुज्यमानः एकः क्लासिकः प्रतिगमनसमस्यादत्तांशसमूहः अस्ति अयं दत्तांशसमूहः भिन्न-भिन्न-कार-माडलस्य ईंधन-दक्षतां (अर्थात् प्रति-गैलन-माइल) अपि च अन्येषां कतिपयानां सम्बद्धानां लक्षणानाम् अभिलेखनं करोति ।
दत्तांशसमूहस्य लक्षणम् : १.
mpg: प्रति गैलन माइल (लक्ष्यचर)।
सिलिण्डराः: सिलिण्डरस्य संख्या, इञ्जिनस्य सिलिण्डरस्य संख्यां सूचयति।
विस्थापनम्: इञ्जिन विस्थापन (घन इञ्च)।
अश्वशक्तिः: इञ्जिनशक्तिः (अश्वशक्तिः)।
भारः: वाहनस्य भारः पौण्ड्-मात्रायां।
त्वरणम्: 0 तः 60 मील प्रतिघण्टा (सेकेण्ड्) पर्यन्तं त्वरणसमयः।
मॉडल_वर्ष: वाहन उत्पादन वर्ष।
श्रोतं: वाहनस्य उत्पत्तिः (१=संयुक्तराज्यसंस्था, २=यूरोप, ३=जापान)।
दत्तांशसमूहस्य प्रथमाः कतिचन पङ्क्तयः : १.
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
कोड उदाहरणम् : १.
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
माध्य वर्गदोष (MSE) 1.1. : औसतवर्गदोषः, यः पूर्वानुमानितमूल्येन वास्तविकमूल्येन च औसतवर्गान्तरं प्रतिनिधियति । मूल्यं यत्किमपि लघु भवति तत् आदर्शप्रदर्शनं उत्तमं भवति, अत्र MSE इत्यस्य मूल्यं ४.९०४२ भवति ।
माध्य निरपेक्ष त्रुटि (MAE) 1.1. : Mean absolute error, यत् पूर्वानुमानितमूल्यं वास्तविकमूल्यं च मध्ये औसतनिरपेक्षं भेदं प्रतिनिधियति । मूल्यं यत्किमपि लघु भवति तत् आदर्शप्रदर्शनं उत्तमं भवति, अत्र MAE इत्यस्य मूल्यं १.६३८१ भवति ।
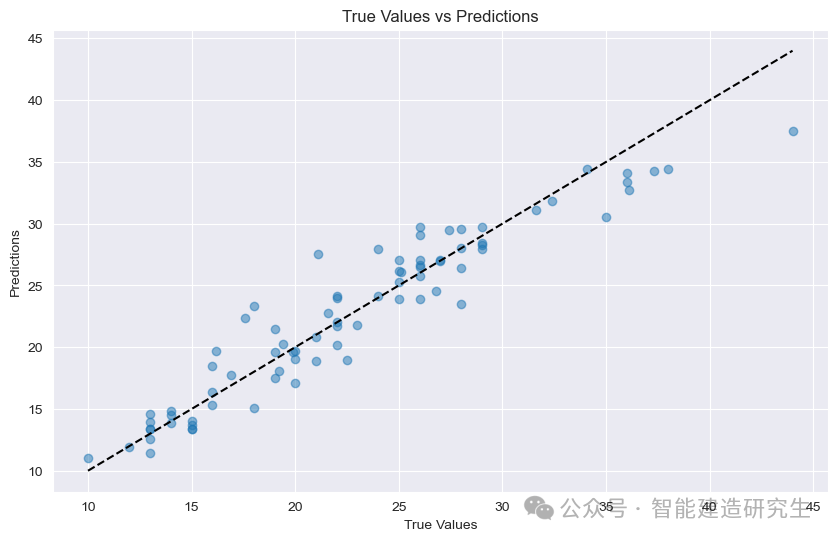
प्रकीर्णन कथानक : आलेखे प्रत्येकं बिन्दुः परीक्षणनमूनायाः प्रतिनिधित्वं करोति । अक्षांशः नमूनायाः (MPG) यथार्थं मूल्यं प्रतिनिधियति, क्रमाङ्कः च प्रतिरूपस्य पूर्वानुमानितमूल्यं (MPG) प्रतिनिधियति ।
तिर्यक्: आकृतौ कृष्णबिन्दुरेखा ४५-अङ्कस्य तिर्यक्रेखा अस्ति, या आदर्शस्थितौ पूर्वानुमानपरिणामस्य प्रतिनिधित्वं करोति, अर्थात् पूर्वानुमानितमूल्यं सत्यमूल्येन बराबरं भवति
बिन्दुवितरणं : १.
तिर्यक् इत्यस्य समीपे: आदर्शस्य पूर्वानुमानितं मूल्यं यथार्थमूल्येन अतीव समीपे अस्ति, पूर्वानुमानं च समीचीनं भवति इति सूचयति ।
तिर्यक् दूरं तिष्ठन्तु: पूर्वानुमानितमूल्येन वास्तविकमूल्येन च महत् अन्तरं वर्तते, पूर्वानुमानं च अशुद्धं इति सूचयति ।
चित्रे विद्यमानबिन्दुभ्यः भवन्तः द्रष्टुं शक्नुवन्ति यत् अधिकांशः बिन्दवः तिर्यक् समीपे एव केन्द्रीकृताः सन्ति, यत् सूचयति यत् आदर्शस्य उत्तमं भविष्यवाणीप्रदर्शनं भवति तथापि केचन बिन्दवः अपि सन्ति ये तिर्यक् तः दूराः सन्ति, येन ज्ञायते यत् अस्ति एतेषां नमूनानां पूर्वानुमानितमूल्यानां यथार्थमूल्यानां च मध्ये एकः निश्चितः अन्तरः ।
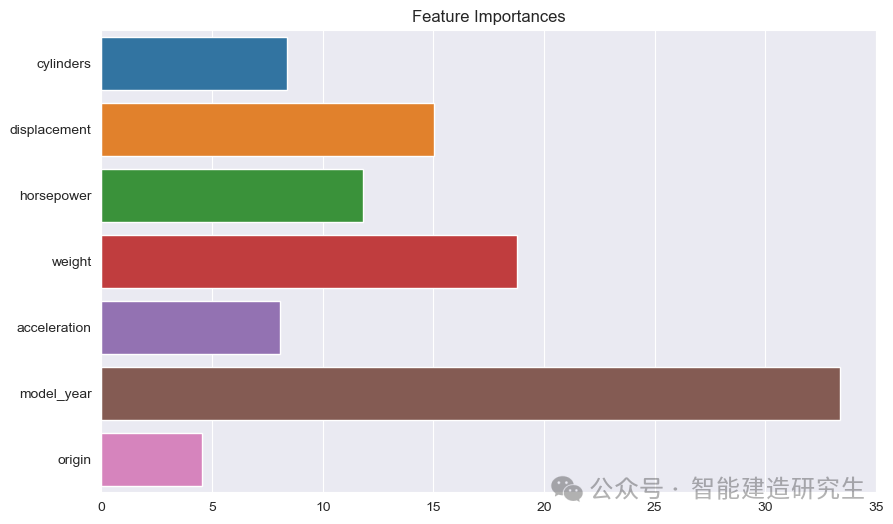
बार चार्ट : प्रत्येकं पट्टिका मॉडल् मध्ये कस्यचित् विशेषतायाः महत्त्वं प्रतिनिधियति । पट्टिका यथा दीर्घा भवति तथा तथा आदर्शपूर्वसूचने विशेषतायाः योगदानं अधिकं भवति ।
विशेषता नाम: Y-अक्षे सर्वेषां विशेषतानां नामानि सूचीबद्धं करोति ।
विशेषता महत्त्व मूल्यम्: X-अक्षे प्रत्येकस्य विशेषतायाः सापेक्षिकमहत्त्वमूल्यं दर्शयति ।
यथा चित्रात् दृश्यते- १.
मॉडल_वर्ष: सर्वेषु विशेषतासु सर्वाधिकं महत्त्वपूर्णं, यत् सूचयति यत् कारस्य उत्पादनवर्षस्य पूर्वानुमानित-इन्धन-दक्षतायां प्रबलः प्रभावः भवति ।
भारः: कारस्य भारः द्वितीयं महत्त्वपूर्णं लक्षणं भवति तथा च ईंधनस्य दक्षतायां अपि महत्त्वपूर्णः प्रभावः भवति ।
विस्थापनम्तथाअश्वशक्तिः: इञ्जिनस्य विस्थापनं शक्तिः च ईंधनदक्षतायां महत्त्वपूर्णं योगदानं ददति ।
उदाहरणे वयं Auto MPG दत्तांशसमूहस्य संसाधनार्थं CatBoost इत्यस्य उपयोगं कुर्मः, यस्य मुख्य उद्देश्यं कारस्य ईंधनदक्षतायाः (अर्थात् प्रति गैलनं माइल, MPG) पूर्वानुमानार्थं प्रतिगमनप्रतिरूपस्य निर्माणं भवति
उपर्युक्ता सामग्री अन्तर्जालतः सारांशतः अस्ति यदि सहायकं भवति तर्हि अग्रिमे समये मिलित्वा अग्रे प्रेषयन्तु।

सः ३० वर्षाणाम् अधिकं कालात् प्रौद्योगिक्याः शोधकार्यं कर्तुं समर्पितः अस्ति, तथा च जावा, लिनक्स, जावास्क्रिप्ट्, php, css इत्यादिषु विविधभाषासु प्रवीणः अस्ति, मुक्तस्रोतक्षेत्रे सः बहु योगदानं कृतवान् अस्ति विकासक दस्तावेजीकरणस्थानकं भविष्ये सन्दर्भार्थं प्रौद्योगिकीविकासे केचन विषयाः साझां कर्तुं सर्वे तत् पश्यन्तु

