
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) は、Yandex (検索エンジンがかつてロシア市場の 60% 以上を占め、他のインターネット製品やサービスも提供しているロシアのインターネット企業) によって開発された、勾配ブースティングに基づく機械学習アルゴリズムです。 CatBoost はカテゴリ特徴の処理に特に優れており、過剰適合やデータ漏洩の問題を効果的に回避できます。 CatBoost の正式名は「Categorical Boosting」で、多数のカテゴリ特徴を含むデータを処理するときにパフォーマンスが向上するように設計されています。
カテゴリ特徴の処理: CatBoost は、追加のエンコード (ワンホット エンコードなど) を行わずに、カテゴリ特徴を直接処理できます。
過学習を避ける: CatBoost は、カテゴリ特徴を処理する新しい方法を採用しており、過剰適合を効果的に削減します。
効率: CatBoost は、トレーニング速度と予測速度の両方で優れたパフォーマンスを発揮します。
CPUとGPUのトレーニングをサポート: CatBoost は CPU 上で実行することも、GPU を使用してトレーニングを加速することもできます。
欠損値を自動的に処理する: CatBoost は、追加の前処理手順を行わずに欠損値を自動的に処理できます。
CatBoost の中心原理は、勾配ブースティング決定木 (GBDT) に基づいていますが、カテゴリ特徴の処理と過学習の回避という点で革新的です。重要な技術的なポイントをいくつか示します。
カテゴリ特徴処理:
CatBoost では、カテゴリの平均に基づいて新しい特徴を計算する「平均エンコーディング」と呼ばれる方法が導入されています。
「ターゲットエンコード」と呼ばれる手法を利用し、カテゴリ特徴を数値特徴に変換する際にターゲット値の平均を使用することでデータ漏洩のリスクを軽減します。
トレーニング プロセス中、ターゲット変数が直接エンコードされることを避けるために、データは統計情報を使用して処理されます。
順序付けされたブースティング:
データの漏洩と過剰適合を防ぐために、CatBoost はトレーニング中にデータを秩序だった方法で処理します。
順序付きブースティングは、トレーニング中にデータをランダムにシャッフルすることで機能し、モデルが特定の時点の過去のデータのみを参照し、意思決定に将来の情報を使用しないようにします。
計算の最適化:
CatBoost は、事前計算とキャッシュを通じて特徴計算プロセスを高速化します。
CPU および GPU トレーニングをサポートし、大規模なデータ セットで適切なパフォーマンスを発揮します。
以下は、分類タスクに CatBoost を使用する基本的な例です。Auto MPG (Miles Per Gallon) データ セットを使用します。これは、機械学習と統計分析で一般的に使用される古典的な回帰問題データ セットです。このデータセットは、さまざまな車種の燃料効率 (つまり、ガロンあたりのマイル数) およびその他のいくつかの関連特性を記録します。
データセットの特徴:
mpg: ガロンあたりのマイル数 (ターゲット変数)。
シリンダー:気筒数。エンジンの気筒数を表します。
変位: エンジン排気量 (立方インチ)。
馬力:エンジン出力(馬力)。
重さ: 車両重量 (ポンド単位)。
加速度: 0 から 60 mph (秒) までの加速時間。
モデル年:車両の製造年。
起源: 車両の原産地 (1=米国、2=ヨーロッパ、3=日本)。
データセットの最初の数行:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
コード例:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
平均二乗誤差 (MSE) : 平均二乗誤差。予測値と実際の値の間の平均二乗差を表します。値が小さいほどモデルのパフォーマンスが向上します。ここでは MSE の値は 4.9042 です。
平均絶対誤差 (MAE) : 平均絶対誤差。予測値と実際の値の間の平均絶対差を表します。値が小さいほどモデルのパフォーマンスが向上します。ここでの MAE の値は 1.6381 です。
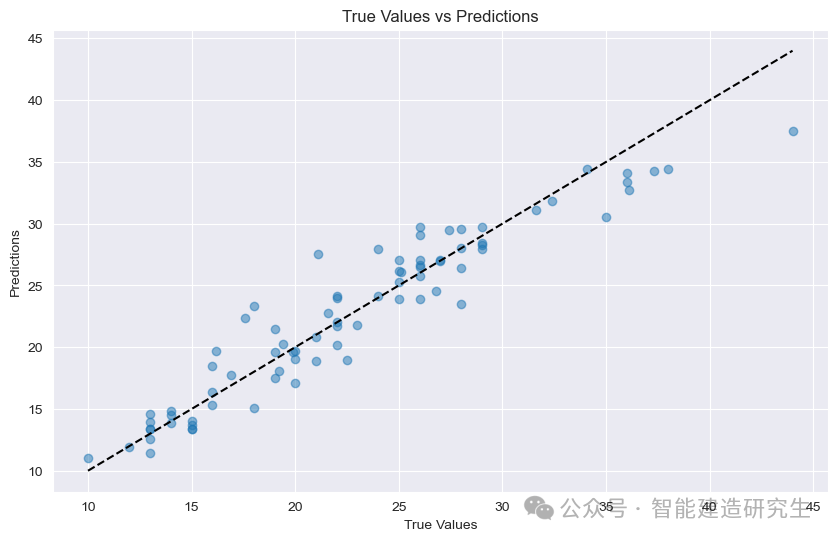
散布図 : 図内の各点はテストサンプルを表します。横軸はサンプルの真の値 (MPG) を表し、縦軸はモデルの予測値 (MPG) を表します。
対角線: 図中の黒い点線は 45 度の対角線であり、理想的な条件、つまり予測値が真の値に等しい場合の予測結果を表しています。
ポイントの配分:
斜めに近い: モデルの予測値が真の値に非常に近く、予測が正確であることを示します。
斜めから離れてください:予測値と実際の値との乖離が大きく、予測が不正確であることを示します。
図の点から、ほとんどの点が対角線付近に集中していることがわかります。これは、モデルの予測性能が優れていることを示していますが、対角線から遠く離れた点もいくつかあることを示しています。これらのサンプルの予測値と真の値の間の一定のギャップ。
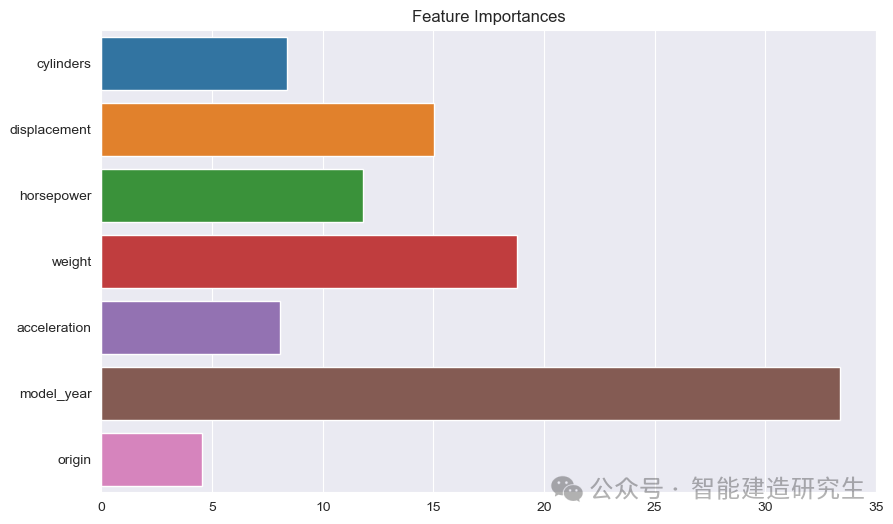
棒グラフ : 各バーは、モデル内のフィーチャーの重要性を表します。バーが長いほど、モデル予測に対する特徴の寄与が大きくなります。
機能名: Y 軸上のすべてのフィーチャの名前をリストします。
特徴の重要度の値: 各フィーチャの相対重要度の値を X 軸に表示します。
写真からわかるように:
モデル年: すべての特徴の中で最も重要で、車の製造年が予測燃費に大きな影響を与えることを示します。
重さ: 車の重量は 2 番目に重要な特性であり、燃費にも大きな影響を与えます。
変位そして馬力:エンジンの排気量やパワーも燃費に大きく貢献します。
この例では、CatBoost を使用して Auto MPG データセットを処理します。その主な目的は、車の燃料効率 (つまり、ガロンあたりのマイル数、MPG) を予測する回帰モデルを構築することです。
上記の内容はインターネットからまとめたものです。お役に立ちましたら、また次回お楽しみください。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: