
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost Το (Categorical Boosting) είναι ένας αλγόριθμος μηχανικής μάθησης που βασίζεται σε gradient boosting που αναπτύχθηκε από την Yandex (μια ρωσική εταιρεία Διαδικτύου της οποίας η μηχανή αναζήτησης κάποτε κατείχε περισσότερο από το 60% του μεριδίου αγοράς στη Ρωσία και παρέχει επίσης άλλα προϊόντα και υπηρεσίες Διαδικτύου). Το CatBoost είναι ιδιαίτερα καλό στο χειρισμό κατηγορικών χαρακτηριστικών και μπορεί να αποφύγει αποτελεσματικά προβλήματα υπερτοποθέτησης και διαρροής δεδομένων. Το πλήρες όνομα του CatBoost είναι "Κατηγορική ενίσχυση".
Επεξεργασία κατηγορικών χαρακτηριστικών: Το CatBoost μπορεί να επεξεργάζεται απευθείας κατηγορικές λειτουργίες χωρίς πρόσθετη κωδικοποίηση (όπως η κωδικοποίηση μίας χρήσης).
Αποφύγετε την υπερβολική τοποθέτηση: Η CatBoost υιοθετεί μια νέα μέθοδο επεξεργασίας χαρακτηριστικών κατηγορίας, η οποία μειώνει αποτελεσματικά την υπερπροσαρμογή.
Αποδοτικότητα: Το CatBoost έχει καλή απόδοση τόσο στην ταχύτητα προπόνησης όσο και στην ταχύτητα πρόβλεψης.
Υποστηρίζει εκπαίδευση CPU και GPU: Το CatBoost μπορεί να τρέξει στη CPU ή να χρησιμοποιήσει τη GPU για ταχεία εκπαίδευση.
Αυτόματος χειρισμός τιμών που λείπουν: Το CatBoost μπορεί να χειριστεί αυτόματα τιμές που λείπουν χωρίς πρόσθετα βήματα προεπεξεργασίας.
Η βασική αρχή του CatBoost βασίζεται στο δέντρο αποφάσεων ενίσχυσης κλίσης (GBDT), αλλά είναι καινοτόμο στην επεξεργασία κατηγορικών χαρακτηριστικών και στην αποφυγή της υπερβολικής προσαρμογής. Ακολουθούν ορισμένα βασικά τεχνικά σημεία:
Επεξεργασία χαρακτηριστικών κατηγορίας:
Το CatBoost εισάγει μια μέθοδο που ονομάζεται "μέση κωδικοποίηση" για τον υπολογισμό νέων χαρακτηριστικών με βάση τον μέσο όρο των κατηγοριών.
Χρησιμοποιώντας μια τεχνική που ονομάζεται "κωδικοποίηση στόχου", ο κίνδυνος διαρροής δεδομένων μειώνεται χρησιμοποιώντας τον μέσο όρο των τιμών-στόχων κατά τη μετατροπή κατηγορικών χαρακτηριστικών σε αριθμητικά χαρακτηριστικά.
Κατά τη διάρκεια της εκπαιδευτικής διαδικασίας, τα δεδομένα επεξεργάζονται χρησιμοποιώντας στατιστικές πληροφορίες για να αποφευχθεί η απευθείας κωδικοποίηση της μεταβλητής στόχου.
Παραγγελία ενίσχυσης:
Προκειμένου να αποφευχθεί η διαρροή δεδομένων και η υπερβολική προσαρμογή, το CatBoost επεξεργάζεται τα δεδομένα με τακτικό τρόπο κατά τη διάρκεια της εκπαίδευσης.
Η Ordered Boosting λειτουργεί ανακατεύοντας τυχαία τα δεδομένα κατά τη διάρκεια της εκπαίδευσης και διασφαλίζει ότι το μοντέλο βλέπει μόνο προηγούμενα δεδομένα σε μια συγκεκριμένη στιγμή και δεν χρησιμοποιεί μελλοντικές πληροφορίες για τη λήψη αποφάσεων.
Υπολογιστική βελτιστοποίηση:
Το CatBoost επιταχύνει τη διαδικασία υπολογισμού χαρακτηριστικών μέσω προυπολογισμού και προσωρινής αποθήκευσης.
Υποστηρίζει εκπαίδευση CPU και GPU και μπορεί να αποδώσει καλά σε σύνολα δεδομένων μεγάλης κλίμακας.
Το παρακάτω είναι ένα βασικό παράδειγμα χρήσης του CatBoost για μια εργασία ταξινόμησης Χρησιμοποιούμε το σύνολο δεδομένων Auto MPG (Miles Per Gallon), το οποίο είναι ένα κλασικό σύνολο δεδομένων προβλημάτων παλινδρόμησης που χρησιμοποιείται συνήθως στη μηχανική μάθηση και τη στατιστική ανάλυση. Αυτό το σύνολο δεδομένων καταγράφει την απόδοση καυσίμου (δηλαδή μίλια ανά γαλόνι) διαφορετικών μοντέλων αυτοκινήτων καθώς και πολλά άλλα σχετικά χαρακτηριστικά.
Χαρακτηριστικά συνόλου δεδομένων:
mpg: Μίλια ανά γαλόνι (μεταβλητή στόχου).
κυλίνδρους: Αριθμός κυλίνδρων, που υποδεικνύει τον αριθμό των κυλίνδρων στον κινητήρα.
μετατόπιση: Κυβισμός κινητήρα (κυβικές ίντσες).
ιπποδύναμη: Ισχύς κινητήρα (ιπποδύναμη).
βάρος: Βάρος οχήματος σε λίβρες.
επιτάχυνση: Χρόνος επιτάχυνσης από 0 έως 60 mph (δευτερόλεπτα).
μοντέλο_έτος: Έτος παραγωγής οχήματος.
προέλευση: Προέλευση οχήματος (1=Ηνωμένες Πολιτείες, 2=Ευρώπη, 3=Ιαπωνία).
Οι πρώτες σειρές του συνόλου δεδομένων:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Παράδειγμα κώδικα:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Μέσο τετράγωνο σφάλμα (MSE) : Μέσο τετραγωνικό σφάλμα, το οποίο αντιπροσωπεύει τη μέση τετραγωνική διαφορά μεταξύ της προβλεπόμενης τιμής και της πραγματικής τιμής. Όσο μικρότερη είναι η τιμή, τόσο καλύτερη είναι η απόδοση του μοντέλου, εδώ η τιμή του MSE είναι 4,9042.
Μέσο απόλυτο σφάλμα (MAE) : Μέσο απόλυτο σφάλμα, το οποίο αντιπροσωπεύει τη μέση απόλυτη διαφορά μεταξύ της προβλεπόμενης τιμής και της πραγματικής τιμής. Όσο μικρότερη είναι η τιμή, τόσο καλύτερη είναι η απόδοση του μοντέλου, εδώ η τιμή του MAE είναι 1,6381.
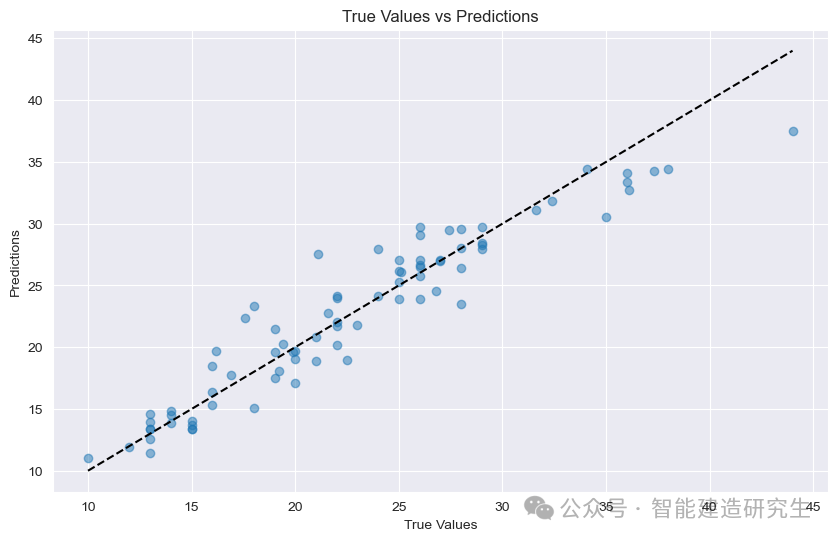
Διάγραμμα διασποράς : Κάθε σημείο στο σχήμα αντιπροσωπεύει ένα δείγμα δοκιμής. Η τετμημένη αντιπροσωπεύει την πραγματική τιμή του δείγματος (MPG) και η τεταγμένη αντιπροσωπεύει την προβλεπόμενη τιμή του μοντέλου (MPG).
διαγώνιος: Η μαύρη διακεκομμένη γραμμή στο σχήμα είναι μια διαγώνια γραμμή 45 μοιρών, η οποία αντιπροσωπεύει το αποτέλεσμα πρόβλεψης υπό ιδανικές συνθήκες, δηλαδή η προβλεπόμενη τιμή είναι ίση με την πραγματική τιμή.
Κατανομή πόντων:
κοντά στη διαγώνιο: Υποδεικνύει ότι η προβλεπόμενη τιμή του μοντέλου είναι πολύ κοντά στην πραγματική τιμή και ότι η πρόβλεψη είναι ακριβής.
μείνετε μακριά από τη διαγώνιο: Υποδεικνύει ότι υπάρχει μεγάλο κενό μεταξύ της προβλεπόμενης τιμής και της πραγματικής τιμής και ότι η πρόβλεψη είναι ανακριβής.
Από τα σημεία του σχήματος, μπορείτε να δείτε ότι τα περισσότερα σημεία είναι συγκεντρωμένα κοντά στη διαγώνιο, πράγμα που δείχνει ότι το μοντέλο έχει καλή απόδοση πρόβλεψης, ωστόσο, υπάρχουν και ορισμένα σημεία που είναι πολύ μακριά από τη διαγώνιο ένα ορισμένο κενό μεταξύ των προβλεπόμενων τιμών αυτών των δειγμάτων και των πραγματικών τιμών.
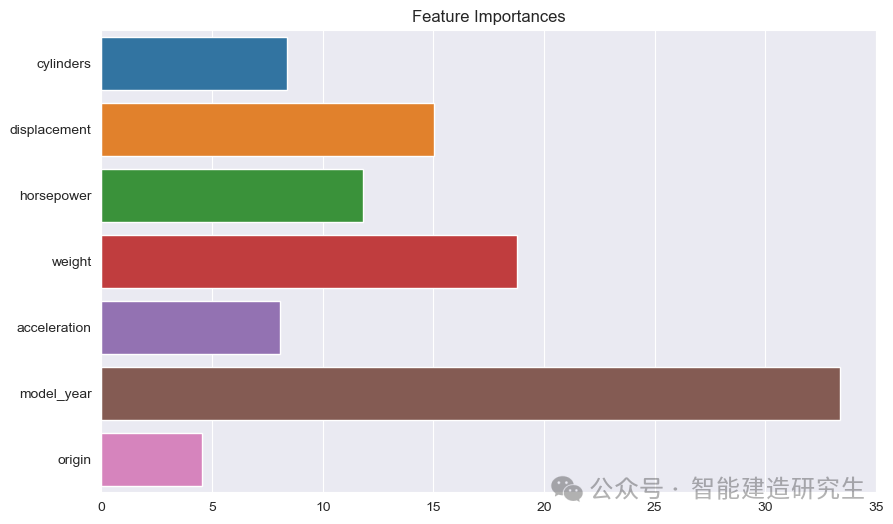
Ραβδόγραμμα : Κάθε γραμμή αντιπροσωπεύει τη σημασία ενός χαρακτηριστικού στο μοντέλο. Όσο μεγαλύτερη είναι η γραμμή, τόσο μεγαλύτερη είναι η συμβολή του χαρακτηριστικού στην πρόβλεψη του μοντέλου.
Όνομα χαρακτηριστικού: Εμφανίζει τα ονόματα όλων των χαρακτηριστικών στον άξονα Υ.
Τιμή σημασίας χαρακτηριστικών: Εμφανίζει τη σχετική τιμή σημασίας κάθε χαρακτηριστικού στον άξονα Χ.
Όπως φαίνεται από την εικόνα:
μοντέλο_έτος: Το πιο σημαντικό από όλα τα χαρακτηριστικά, υποδεικνύοντας ότι το έτος παραγωγής του αυτοκινήτου έχει ισχυρό αντίκτυπο στην προβλεπόμενη απόδοση καυσίμου.
βάρος: Το βάρος ενός αυτοκινήτου είναι το δεύτερο πιο σημαντικό χαρακτηριστικό και έχει επίσης σημαντικό αντίκτυπο στην απόδοση καυσίμου.
μετατόπισηκαιιπποδύναμη: Ο κυβισμός και η ισχύς του κινητήρα συμβάλλουν επίσης σημαντικά στην απόδοση καυσίμου.
Στο παράδειγμα, χρησιμοποιούμε το CatBoost για να επεξεργαστούμε το σύνολο δεδομένων Auto MPG, του οποίου ο κύριος σκοπός είναι να δημιουργήσει ένα μοντέλο παλινδρόμησης για την πρόβλεψη της απόδοσης καυσίμου ενός αυτοκινήτου (δηλαδή, μίλια ανά γαλόνι, MPG).
Το παραπάνω περιεχόμενο συνοψίζεται από το Διαδίκτυο, εάν είναι χρήσιμο, προωθήστε το την επόμενη φορά.

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]