
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) è un algoritmo di apprendimento automatico basato sul gradient boosting sviluppato da Yandex (una società Internet russa il cui motore di ricerca una volta deteneva oltre il 60% della quota di mercato in Russia e fornisce anche altri prodotti e servizi Internet). CatBoost è particolarmente efficace nel gestire le funzionalità categoriche e può evitare efficacemente problemi di overfitting e perdita di dati. Il nome completo di CatBoost è "Categorical Boosting". È progettato per funzionare meglio durante l'elaborazione di dati contenenti un gran numero di caratteristiche categoriche.
Elaborazione di caratteristiche categoriche: CatBoost può elaborare direttamente le funzionalità categoriali senza codifica aggiuntiva (come la codifica one-hot).
Evitare un adattamento eccessivo: CatBoost adotta un nuovo metodo di elaborazione delle caratteristiche di categoria, che riduce efficacemente l'overfitting.
Efficienza: CatBoost funziona bene sia nella velocità di allenamento che nella velocità di previsione.
Supporta l'addestramento di CPU e GPU: CatBoost può essere eseguito sulla CPU o utilizzare la GPU per un allenamento accelerato.
Gestisci automaticamente i valori mancanti: CatBoost può gestire automaticamente i valori mancanti senza ulteriori passaggi di preelaborazione.
Il principio fondamentale di CatBoost si basa sull'albero decisionale con potenziamento del gradiente (GBDT), ma è innovativo nell'elaborazione delle caratteristiche categoriali e nell'evitare l'overfitting. Ecco alcuni punti tecnici chiave:
Elaborazione delle caratteristiche di categoria:
CatBoost introduce un metodo chiamato "codifica media" per calcolare nuove funzionalità in base alla media delle categorie.
Utilizzando una tecnica chiamata "codifica target", il rischio di perdita di dati viene ridotto utilizzando la media dei valori target durante la conversione delle caratteristiche categoriche in caratteristiche numeriche.
Durante il processo di addestramento, i dati vengono elaborati utilizzando informazioni statistiche per evitare di codificare direttamente la variabile target.
Potenziamento ordinato:
Al fine di prevenire perdite di dati e overfitting, CatBoost elabora i dati in modo ordinato durante l'addestramento.
Il potenziamento ordinato funziona mescolando casualmente i dati durante l'addestramento e garantisce che il modello veda solo i dati passati in un determinato momento e non utilizzi le informazioni future per prendere decisioni.
Ottimizzazione computazionale:
CatBoost accelera il processo di calcolo delle funzionalità tramite precalcolo e memorizzazione nella cache.
Supporta l'addestramento di CPU e GPU e può funzionare bene su set di dati su larga scala.
Quello che segue è un esempio di base dell'utilizzo di CatBoost per un'attività di classificazione. Utilizziamo il set di dati Auto MPG (miglia per gallone), che è un classico set di dati di problemi di regressione comunemente utilizzato nell'apprendimento automatico e nell'analisi statistica. Questo set di dati registra l'efficienza del carburante (ovvero miglia per gallone) di diversi modelli di auto, nonché molte altre caratteristiche correlate.
Caratteristiche del set di dati:
mpg: Miglia per gallone (variabile target).
cilindri: Numero di cilindri, indica il numero di cilindri presenti nel motore.
Dislocamento: Cilindrata del motore (pollici cubi).
potenza: Potenza del motore (cavalli).
peso: Peso del veicolo in libbre.
accelerazione: Tempo di accelerazione da 0 a 60 mph (secondi).
anno_modello: Anno di produzione del veicolo.
origine: Origine del veicolo (1=Stati Uniti, 2=Europa, 3=Giappone).
Le prime righe del set di dati:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Esempio di codice:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Errore quadratico medio (MSE) : errore quadratico medio, che rappresenta la differenza quadrata media tra il valore previsto e il valore effettivo. Minore è il valore, migliore è la prestazione del modello, qui il valore di MSE è 4.9042.
Errore assoluto medio (MAE) : errore medio assoluto, che rappresenta la differenza media assoluta tra il valore previsto e il valore effettivo. Minore è il valore, migliore è la prestazione del modello, qui il valore di MAE è 1.6381.
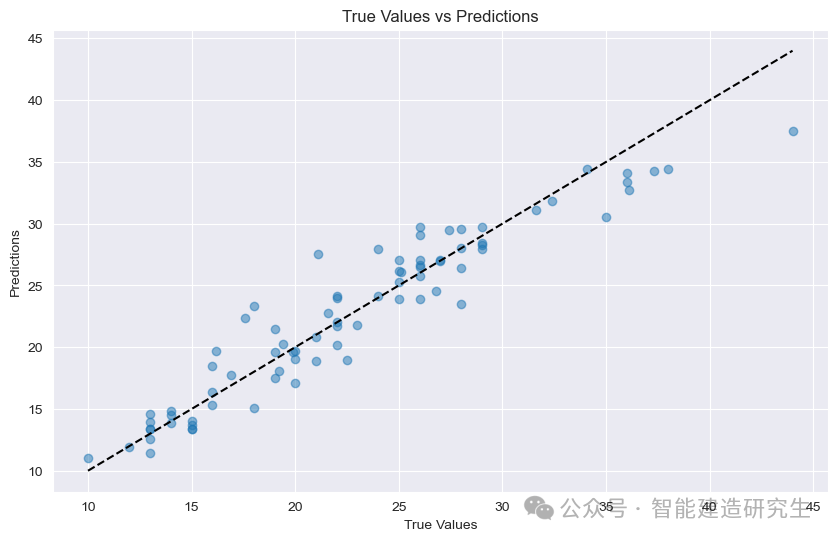
Grafico a dispersione : Ogni punto nel grafico rappresenta un campione di prova. L'ascissa rappresenta il valore reale del campione (MPG) e l'ordinata rappresenta il valore previsto del modello (MPG).
diagonale: La linea tratteggiata nera nella figura è una linea diagonale di 45 gradi, che rappresenta il risultato della previsione in condizioni ideali, ovvero il valore previsto è uguale al valore reale.
Distribuzione dei punti:
vicino alla diagonale: indica che il valore previsto del modello è molto vicino al valore reale e la previsione è accurata.
stai lontano dalla diagonale: indica che esiste un ampio divario tra il valore previsto e il valore effettivo e che la previsione non è accurata.
Dai punti nella figura, puoi vedere che la maggior parte dei punti sono concentrati vicino alla diagonale, il che indica che il modello ha buone prestazioni di previsione. Tuttavia, ci sono anche alcuni punti che sono lontani dalla diagonale, indicando che esiste un certo divario tra i valori previsti di questi campioni e i valori reali.
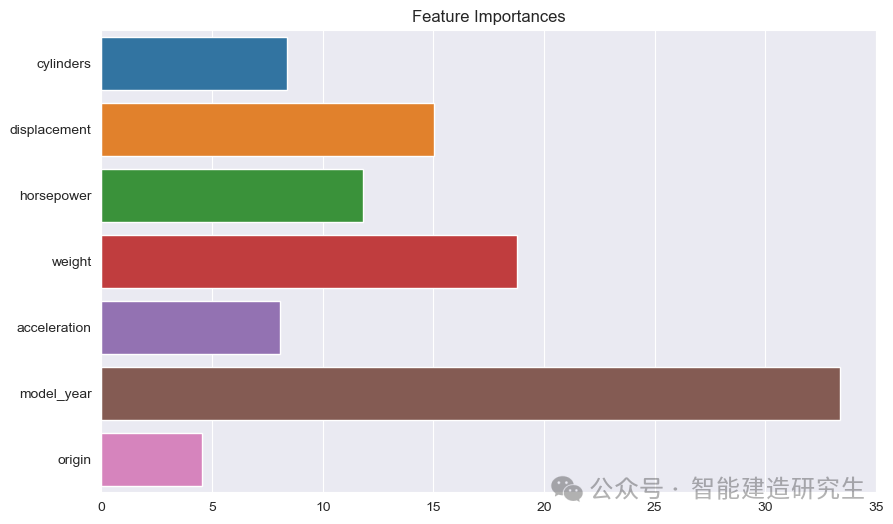
Grafico a barre : Ogni barra rappresenta l'importanza di una caratteristica nel modello. Più lunga è la barra, maggiore è il contributo della caratteristica alla previsione del modello.
Nome della funzione: Elenca i nomi di tutte le funzioni sull'asse Y.
Valore di importanza della caratteristica: mostra il valore di importanza relativa di ciascuna caratteristica sull'asse X.
Come si può vedere dall'immagine:
anno_modello: La più importante tra tutte le caratteristiche, che indica che l'anno di produzione dell'auto ha un forte impatto sul consumo di carburante previsto.
peso: Il peso di un'auto è la seconda caratteristica più importante e ha anche un impatto significativo sul consumo di carburante.
DislocamentoEpotenza: Anche la cilindrata e la potenza del motore contribuiscono in modo significativo all'efficienza del carburante.
Nell'esempio, utilizziamo CatBoost per elaborare il set di dati Auto MPG, il cui scopo principale è creare un modello di regressione per prevedere l'efficienza del carburante di un'auto (ad esempio, miglia per gallone, MPG).
Il contenuto di cui sopra è un riepilogo da Internet. Se è utile, inoltralo. Alla prossima.

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]