
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) es un algoritmo de aprendizaje automático basado en el aumento de gradiente desarrollado por Yandex (una empresa rusa de Internet cuyo motor de búsqueda alguna vez tuvo más del 60% de la participación de mercado en Rusia y también ofrece otros productos y servicios de Internet). CatBoost es particularmente bueno en el manejo de características categóricas y puede evitar eficazmente problemas de sobreajuste y fuga de datos. El nombre completo de CatBoost es "Categorical Boosting". Está diseñado para funcionar mejor al procesar datos que contienen una gran cantidad de características categóricas.
Procesamiento de características categóricas: CatBoost puede procesar directamente características categóricas sin codificación adicional (como la codificación one-hot).
Evite el sobreajuste: CatBoost adopta un nuevo método de procesamiento de características de categorías, que reduce efectivamente el sobreajuste.
Eficiencia: CatBoost funciona bien tanto en velocidad de entrenamiento como en velocidad de predicción.
Admite entrenamiento de CPU y GPU: CatBoost puede ejecutarse en la CPU o utilizar la GPU para un entrenamiento acelerado.
Manejar automáticamente los valores faltantes: CatBoost puede manejar automáticamente los valores faltantes sin pasos de preprocesamiento adicionales.
El principio central de CatBoost se basa en el árbol de decisión de aumento de gradiente (GBDT), pero es innovador en el procesamiento de características categóricas y evita el sobreajuste. Aquí hay algunos puntos técnicos clave:
Procesamiento de características de categoría:
CatBoost introduce un método llamado "codificación media" para calcular nuevas características basadas en la media de las categorías.
Utilizando una técnica llamada "codificación de destino", el riesgo de fuga de datos se reduce utilizando el promedio de los valores de destino al convertir características categóricas en características numéricas.
Durante el proceso de entrenamiento, los datos se procesan utilizando información estadística para evitar codificar la variable objetivo directamente.
Impulso ordenado:
Para evitar la fuga de datos y el sobreajuste, CatBoost procesa los datos de manera ordenada durante el entrenamiento.
El impulso ordenado funciona mezclando aleatoriamente los datos durante el entrenamiento y garantiza que el modelo solo vea datos pasados en un momento determinado y no utilice información futura para tomar decisiones.
Optimización computacional:
CatBoost acelera el proceso de cálculo de características mediante cálculo previo y almacenamiento en caché.
Admite el entrenamiento de CPU y GPU y puede funcionar bien en conjuntos de datos a gran escala.
El siguiente es un ejemplo básico del uso de CatBoost para una tarea de clasificación. Usamos el conjunto de datos Auto MPG (Millas por galón), que es un conjunto de datos de problemas de regresión clásico que se usa comúnmente en el aprendizaje automático y el análisis estadístico. Este conjunto de datos registra la eficiencia del combustible (es decir, millas por galón) de diferentes modelos de automóviles, así como varias otras características relacionadas.
Características del conjunto de datos:
millas por galón: Millas por galón (variable objetivo).
Cilindros: Número de cilindros, indicando el número de cilindros del motor.
desplazamiento: Cilindrada del motor (pulgadas cúbicas).
caballo de fuerza: Potencia del motor (caballos de fuerza).
peso: Peso del vehículo en libras.
aceleración: Tiempo de aceleración de 0 a 60 mph (segundos).
año_modelo: Año de producción del vehículo.
origen: Origen del vehículo (1=Estados Unidos, 2=Europa, 3=Japón).
Las primeras filas del conjunto de datos:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Ejemplo de código:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Error cuadrático medio (MSE) : Error cuadrático medio, que representa la diferencia cuadrática promedio entre el valor previsto y el valor real. Cuanto menor sea el valor, mejor será el rendimiento del modelo; aquí el valor de MSE es 4,9042.
Error absoluto medio (EMA) : Error absoluto medio, que representa la diferencia absoluta promedio entre el valor previsto y el valor real. Cuanto menor sea el valor, mejor será el rendimiento del modelo; aquí el valor de MAE es 1,6381.
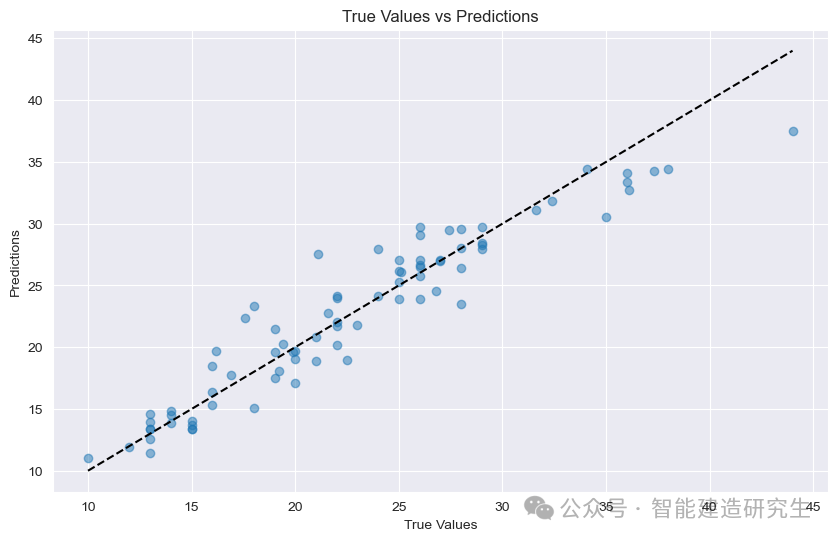
Gráfico de dispersión : Cada punto de la figura representa una muestra de prueba. La abscisa representa el valor real de la muestra (MPG) y la ordenada representa el valor predicho del modelo (MPG).
diagonal: La línea de puntos negra en la figura es una línea diagonal de 45 grados, que representa el resultado de la predicción en condiciones ideales, es decir, el valor predicho es igual al valor real.
Distribución de puntos:
cerca de la diagonal: Indica que el valor predicho del modelo está muy cerca del valor real y la predicción es precisa.
mantente alejado de la diagonal: Indica que existe una gran brecha entre el valor previsto y el valor real, y que la predicción es inexacta.
De los puntos en la figura, se puede ver que la mayoría de los puntos se concentran cerca de la diagonal, lo que indica que el modelo tiene un buen rendimiento de predicción. Sin embargo, también hay algunos puntos que están lejos de la diagonal, lo que indica que sí. una cierta brecha entre los valores predichos de estas muestras y los valores reales.
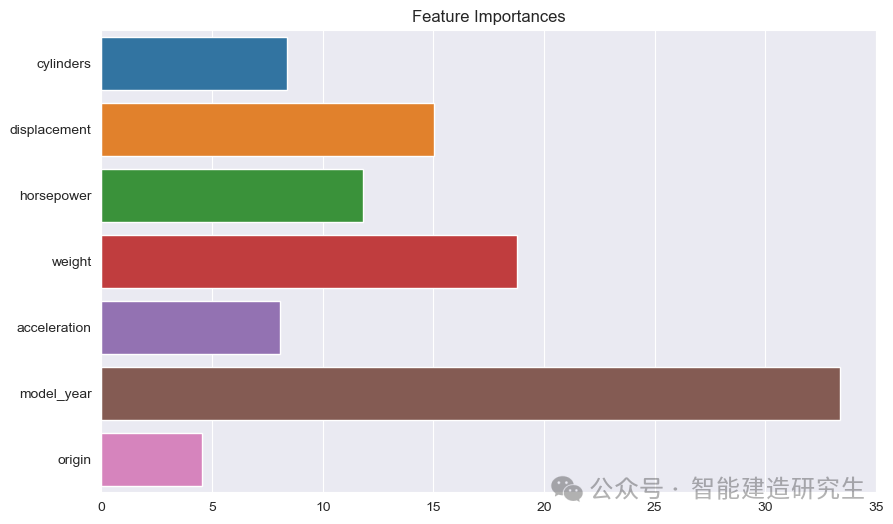
Gráfico de barras : Cada barra representa la importancia de una característica en el modelo. Cuanto más larga sea la barra, mayor será la contribución de la característica a la predicción del modelo.
Nombre de la característica: enumera los nombres de todas las funciones en el eje Y.
Valor de importancia de la característica: Muestra el valor de importancia relativa de cada característica en el eje X.
Como se puede ver en la imagen:
año_modelo: La característica más importante de todas, indica que el año de producción del automóvil tiene un fuerte impacto en la eficiencia de combustible prevista.
peso: El peso de un coche es la segunda característica más importante y también tiene un impacto significativo en la eficiencia del combustible.
desplazamientoycaballo de fuerza: La cilindrada y la potencia del motor también contribuyen significativamente a la eficiencia del combustible.
En el ejemplo, utilizamos CatBoost para procesar el conjunto de datos Auto MPG, cuyo objetivo principal es construir un modelo de regresión para predecir la eficiencia del combustible de un automóvil (es decir, millas por galón, MPG).
El contenido anterior está resumido de Internet. Si es útil, reenvíelo. ¡Hasta la próxima!

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]