2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) on Yandexin (venäläinen Internet-yritys, jonka hakukone omisti aikoinaan yli 60 % Venäjän markkinaosuudesta ja joka tarjoaa myös muita Internet-tuotteita ja -palveluita) kehittämä koneoppimisalgoritmi, joka perustuu gradienttitehostukseen. CatBoost on erityisen hyvä käsittelemään kategorisia ominaisuuksia ja voi tehokkaasti välttää yliasennus- ja tietovuoto-ongelmia. CatBoostin koko nimi on "Categorical Boosting". Se on suunniteltu toimimaan paremmin käsiteltäessä tietoja, jotka sisältävät suuren määrän kategorisia ominaisuuksia.
Kategoristen ominaisuuksien käsittely: CatBoost voi käsitellä kategorisia ominaisuuksia suoraan ilman ylimääräistä koodausta (kuten one-hot-koodausta).
Vältä yliasennusta: CatBoost ottaa käyttöön uuden menetelmän luokkaominaisuuksien käsittelyyn, mikä vähentää tehokkaasti yliasennusta.
Tehokkuus: CatBoost toimii hyvin sekä harjoitusnopeudessa että ennustusnopeudessa.
Tukee CPU- ja GPU-koulutusta: CatBoost voi toimia suorittimella tai käyttää GPU:ta nopeutettuun harjoitteluun.
Käsittele puuttuvat arvot automaattisesti: CatBoost pystyy käsittelemään puuttuvat arvot automaattisesti ilman ylimääräisiä esikäsittelyvaiheita.
CatBoostin ydinperiaate perustuu gradienttitehostuspäätöspuuhun (GBDT), mutta se on innovatiivinen käsittelemään kategorisia ominaisuuksia ja välttämään ylisovitusta. Tässä on joitain keskeisiä teknisiä kohtia:
Luokkaominaisuuksien käsittely:
CatBoost esittelee menetelmän nimeltä "keskiarvokoodaus" uusien ominaisuuksien laskemiseksi luokkien keskiarvon perusteella.
Käyttämällä "kohdekoodaukseksi" kutsuttua tekniikkaa tietovuodon riskiä pienennetään käyttämällä tavoitearvojen keskiarvoa muunnettaessa kategorisia ominaisuuksia numeerisiksi ominaisuuksiksi.
Harjoitteluprosessin aikana dataa käsitellään käyttämällä tilastotietoja, jotta vältytään kohdemuuttujan koodaamiselta suoraan.
Tilattu Boosting:
Tietovuotojen ja ylisovittamisen estämiseksi CatBoost käsittelee tiedot järjestelmällisesti harjoituksen aikana.
Tilattu tehostus toimii sekoittamalla dataa satunnaisesti harjoituksen aikana ja varmistaa, että malli näkee vain tietyllä hetkellä menneitä tietoja eikä käytä tulevaa tietoa päätöksentekoon.
Laskennallinen optimointi:
CatBoost nopeuttaa ominaisuuden laskentaprosessia esilaskennan ja välimuistin avulla.
Tukee CPU- ja GPU-koulutusta ja voi toimia hyvin suurissa tietosarjoissa.
Seuraavassa on perusesimerkki CatBoostin käyttämisestä luokitustehtävässä. Käytämme Auto MPG (Miles Per Gallon) -tietojoukkoa, joka on klassinen regressio-ongelmatietojoukko, jota käytetään yleisesti koneoppimisessa ja tilastoanalyysissä. Tämä tietojoukko tallentaa eri automallien polttoainetehokkuuden (eli mailia gallonaa kohti) sekä useita muita asiaan liittyviä ominaisuuksia.
Tietojoukon ominaisuudet:
mpg: Mailit per gallona (tavoitemuuttuja).
sylinterit: Sylinterien lukumäärä, joka ilmaisee sylinterien lukumäärän moottorissa.
siirtymä: Moottorin iskutilavuus (kuutiometriä).
hevosvoimaa: Moottorin teho (hevosvoimaa).
paino: Ajoneuvon paino paunassa.
kiihtyvyys: Kiihtyvyysaika 0 - 60 mph (sekuntia).
malli_vuosi: Ajoneuvon valmistusvuosi.
alkuperä: Ajoneuvon alkuperä (1 = Yhdysvallat, 2 = Eurooppa, 3 = Japani).
Tietojoukon ensimmäiset rivit:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Esimerkki koodista:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Keskimääräinen neliövirhe (MSE) : Keskimääräinen neliövirhe, joka edustaa keskimääräistä neliöeroa ennustetun arvon ja todellisen arvon välillä. Mitä pienempi arvo, sitä parempi mallin suorituskyky, tässä MSE:n arvo on 4,9042.
Keskimääräinen absoluuttinen virhe (MAE) : Keskimääräinen absoluuttinen virhe, joka edustaa keskimääräistä absoluuttista eroa ennustetun arvon ja todellisen arvon välillä. Mitä pienempi arvo, sitä parempi mallin suorituskyky, tässä MAE:n arvo on 1,6381.
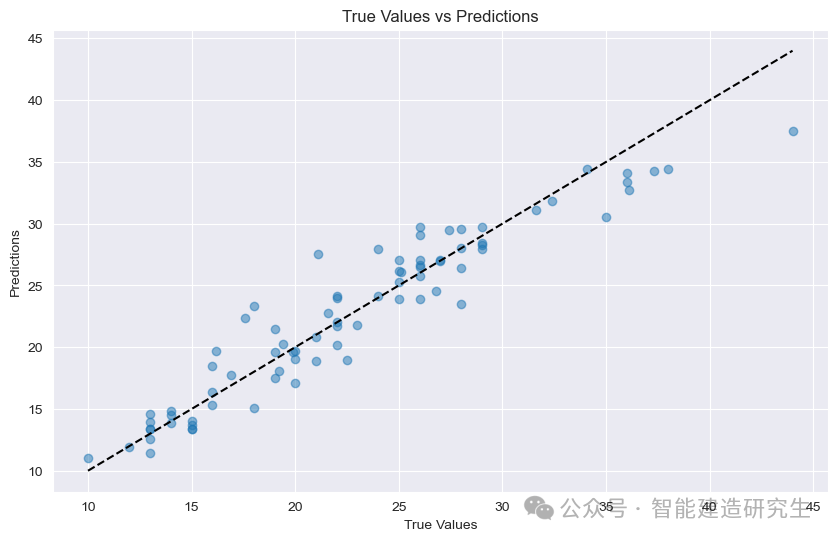
Hajakuvaaja : Jokainen kaavion piste edustaa testinäytettä. Abskissa edustaa näytteen todellista arvoa (MPG) ja ordinaatta edustaa mallin ennustettua arvoa (MPG).
diagonaalinen: Kuvan musta katkoviiva on 45 asteen vinoviiva, joka edustaa ennustustulosta ihanteellisissa olosuhteissa, eli ennustettu arvo on yhtä suuri kuin todellinen arvo.
Pisteiden jakautuminen:
lähellä diagonaalia: Osoittaa, että mallin ennustettu arvo on hyvin lähellä todellista arvoa ja ennuste on tarkka.
pysy kaukana diagonaalista: Osoittaa, että ennustetun arvon ja todellisen arvon välillä on suuri ero ja ennuste on epätarkka.
Kuvan pisteistä näkyy, että suurin osa pisteistä on keskittynyt lähelle diagonaalia, mikä osoittaa, että mallilla on hyvä ennustekyky. Kuitenkin on myös joitain pisteitä, jotka ovat kaukana diagonaalista, mikä osoittaa, että on tietty ero näiden näytteiden ennustettujen arvojen ja todellisten arvojen välillä.
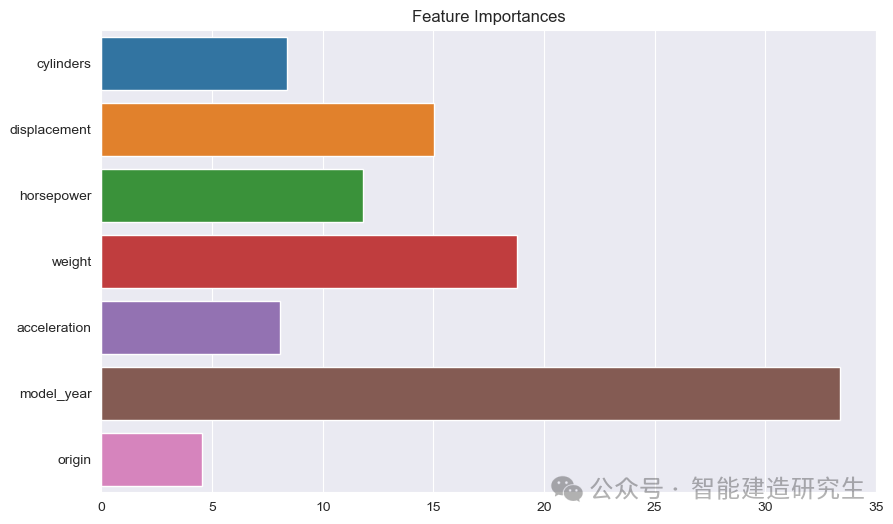
Pylväsdiagrammi : Jokainen palkki edustaa mallin ominaisuuden tärkeyttä. Mitä pidempi palkki, sitä suurempi on ominaisuuden osuus mallin ennustuksessa.
Ominaisuuden nimi: Näyttää kaikkien Y-akselin ominaisuuksien nimet.
Ominaisuuden tärkeysarvo: Näyttää kunkin ominaisuuden suhteellisen tärkeysarvon X-akselilla.
Kuten kuvasta näkyy:
malli_vuosi: Kaikista ominaisuuksista tärkein, mikä osoittaa, että auton valmistusvuodella on vahva vaikutus ennustettuun polttoainetehokkuuteen.
paino: Auton paino on toiseksi tärkein ominaisuus ja sillä on myös merkittävä vaikutus polttoainetehokkuuteen.
siirtymäjahevosvoimaa: Moottorin iskutilavuus ja teho vaikuttavat myös merkittävästi polttoainetehokkuuteen.
Esimerkissä käytämme CatBoostia automaattisen MPG-tietojoukon käsittelemiseen, jonka päätarkoituksena on rakentaa regressiomalli ennustamaan auton polttoainetehokkuutta (eli mailia gallonaa kohti, MPG).
Yllä oleva sisältö on tiivistetty Internetistä, jos siitä on apua, lähetä se eteenpäin.

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema jakaaksesi joitain teknologian kehittämisen ongelmia tulevaa käyttöä varten

