
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Peningkatan Kategoris) adalah algoritme pembelajaran mesin berdasarkan peningkatan gradien yang dikembangkan oleh Yandex (perusahaan Internet Rusia yang mesin pencarinya pernah menguasai lebih dari 60% pangsa pasar di Rusia dan juga menyediakan produk dan layanan Internet lainnya). CatBoost sangat baik dalam menangani fitur kategorikal dan secara efektif dapat menghindari masalah overfitting dan kebocoran data. Nama lengkap CatBoost adalah "Categorical Boosting". Ini dirancang untuk bekerja lebih baik saat memproses data yang berisi banyak fitur kategorikal.
Memproses fitur kategorikal: CatBoost dapat langsung memproses fitur kategoris tanpa pengkodean tambahan (seperti pengkodean one-hot).
Hindari pemasangan yang berlebihan: CatBoost mengadopsi metode baru dalam memproses fitur kategori, yang secara efektif mengurangi overfitting.
Efisiensi: CatBoost berkinerja baik dalam kecepatan pelatihan dan kecepatan prediksi.
Mendukung pelatihan CPU dan GPU: CatBoost dapat berjalan di CPU atau menggunakan GPU untuk pelatihan yang dipercepat.
Secara otomatis menangani nilai yang hilang: CatBoost dapat secara otomatis menangani nilai yang hilang tanpa langkah pra-pemrosesan tambahan.
Prinsip inti CatBoost didasarkan pada pohon keputusan peningkatan gradien (GBDT), namun inovatif dalam memproses fitur kategoris dan menghindari overfitting. Berikut adalah beberapa poin teknis utama:
Pemrosesan fitur kategori:
CatBoost memperkenalkan metode yang disebut "pengkodean rata-rata" untuk menghitung fitur baru berdasarkan rata-rata kategori.
Dengan menggunakan teknik yang disebut "pengkodean target", risiko kebocoran data dikurangi dengan menggunakan rata-rata nilai target saat mengubah fitur kategorikal menjadi fitur numerik.
Selama proses pelatihan, data diproses dengan menggunakan informasi statistik untuk menghindari pengkodean variabel target secara langsung.
Peningkatan yang Dipesan:
Untuk mencegah kebocoran dan overfitting data, CatBoost memproses data secara tertib selama pelatihan.
Peningkatan terurut bekerja dengan mengacak data secara acak selama pelatihan dan memastikan bahwa model hanya melihat data masa lalu pada saat tertentu dan tidak menggunakan informasi masa depan untuk mengambil keputusan.
Optimalisasi komputasi:
CatBoost mempercepat proses penghitungan fitur melalui prakomputasi dan caching.
Mendukung pelatihan CPU dan GPU dan dapat bekerja dengan baik pada kumpulan data berskala besar.
Berikut ini adalah contoh dasar penggunaan CatBoost untuk tugas klasifikasi. Kami menggunakan kumpulan data Auto MPG (Miles Per Gallon), yang merupakan kumpulan data masalah regresi klasik yang biasa digunakan dalam pembelajaran mesin dan analisis statistik. Kumpulan data ini mencatat efisiensi bahan bakar (yaitu mil per galon) berbagai model mobil serta beberapa karakteristik terkait lainnya.
Karakteristik kumpulan data:
mpg: Mil per galon (variabel target).
silinder: Jumlah silinder, menunjukkan jumlah silinder pada mesin.
pemindahan: Perpindahan mesin (inci kubik).
daya kuda: Tenaga mesin (tenaga kuda).
berat: Berat kendaraan dalam pon.
percepatan: Waktu akselerasi dari 0 hingga 60 mph (detik).
model_tahun: Tahun produksi kendaraan.
asal: Asal kendaraan (1=Amerika Serikat, 2=Eropa, 3=Jepang).
Beberapa baris pertama kumpulan data:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Contoh kode:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Kesalahan Kuadrat Rata-rata (MSE) : Mean square error, yang mewakili selisih kuadrat rata-rata antara nilai prediksi dan nilai sebenarnya. Semakin kecil nilainya maka performa model semakin baik, disini nilai MSE sebesar 4,9042.
Kesalahan Absolut Rata-rata (MAE) : Rata-rata kesalahan absolut, yang mewakili perbedaan absolut rata-rata antara nilai prediksi dan nilai sebenarnya. Semakin kecil nilainya maka kinerja model semakin baik, disini nilai MAE sebesar 1,6381.
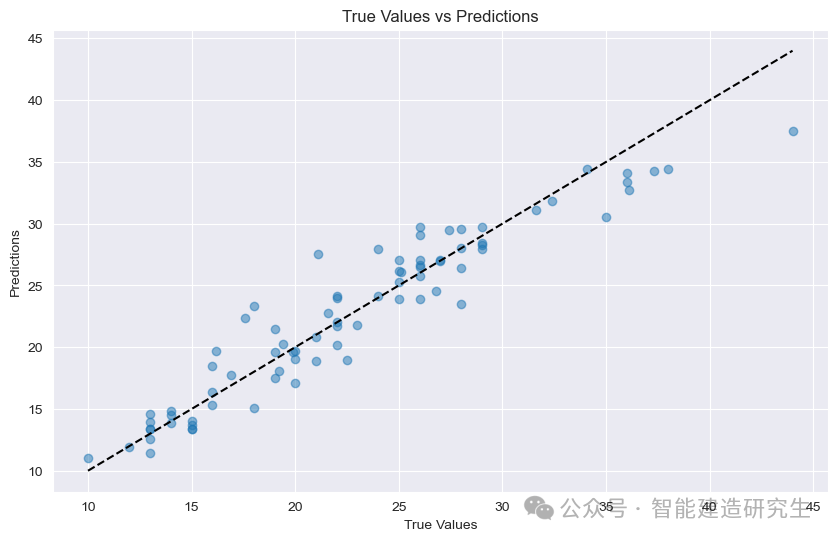
Plot sebar : Setiap titik pada grafik mewakili sampel uji. Absis mewakili nilai sebenarnya dari sampel (MPG), dan ordinat mewakili nilai prediksi model (MPG).
diagonal: Garis titik-titik hitam pada gambar merupakan garis diagonal 45 derajat yang mewakili hasil prediksi pada kondisi ideal yaitu nilai prediksi sama dengan nilai sebenarnya.
Distribusi poin:
mendekati diagonal: Menunjukkan bahwa nilai prediksi model sangat mendekati nilai sebenarnya, dan prediksi tersebut akurat.
menjauhi diagonal: Menunjukkan adanya kesenjangan yang besar antara nilai prediksi dan nilai sebenarnya, sehingga prediksi tidak akurat.
Dari titik-titik pada gambar terlihat bahwa sebagian besar titik terkonsentrasi di dekat diagonal, yang menunjukkan bahwa model memiliki kinerja prediksi yang baik, namun ada juga beberapa titik yang jauh dari diagonal, yang menunjukkan adanya kesenjangan tertentu antara nilai prediksi sampel ini dan kesenjangan nilai sebenarnya.
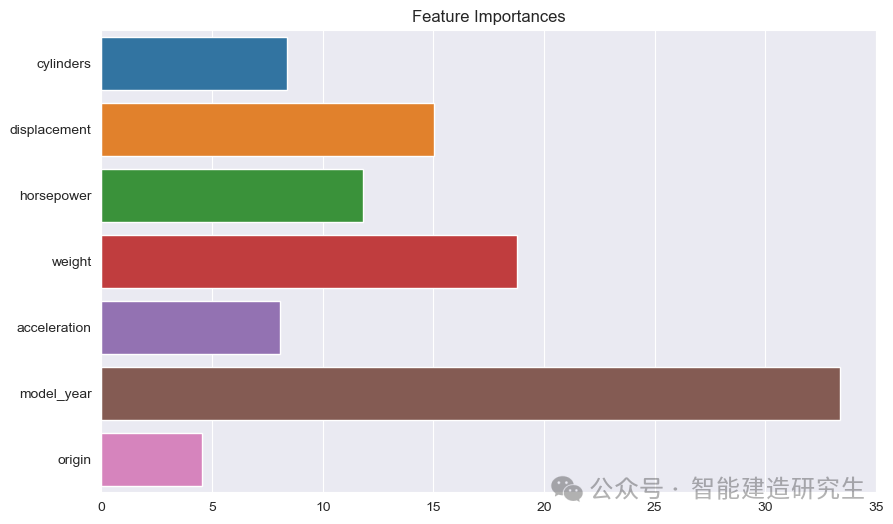
Grafik batang : Setiap batang mewakili pentingnya fitur dalam model. Semakin panjang bilahnya, semakin besar kontribusi fitur terhadap prediksi model.
Nama fitur: Mencantumkan nama semua fitur pada sumbu Y.
Nilai penting fitur: Menampilkan nilai kepentingan relatif setiap fitur pada sumbu X.
Seperti yang terlihat dari gambar:
model_tahun: Yang paling penting di antara semua fitur, yang menunjukkan bahwa tahun produksi mobil memiliki pengaruh yang kuat terhadap prediksi efisiensi bahan bakar.
berat: Bobot sebuah mobil merupakan karakteristik terpenting kedua dan juga mempunyai pengaruh yang signifikan terhadap efisiensi bahan bakar.
pemindahanDandaya kuda: Perpindahan dan tenaga mesin juga berkontribusi signifikan terhadap efisiensi bahan bakar.
Dalam contoh ini, kami menggunakan CatBoost untuk memproses kumpulan data Auto MPG, yang tujuan utamanya adalah membuat model regresi untuk memprediksi efisiensi bahan bakar mobil (yaitu mil per galon, MPG).
Konten di atas dirangkum dari Internet. Jika bermanfaat, silakan teruskan.

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]