2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting) est un algorithme d'apprentissage automatique basé sur le gradient boosting développé par Yandex (une société Internet russe dont le moteur de recherche détenait autrefois plus de 60 % des parts de marché en Russie et fournit également d'autres produits et services Internet). CatBoost est particulièrement efficace dans la gestion des fonctionnalités catégorielles et peut efficacement éviter les problèmes de surajustement et de fuite de données. Le nom complet de CatBoost est « Catégorique Boosting ». Il est conçu pour être plus performant lors du traitement de données contenant un grand nombre de fonctionnalités catégorielles.
Traitement des caractéristiques catégorielles: CatBoost peut traiter directement les fonctionnalités catégorielles sans encodage supplémentaire (tel qu'un encodage à chaud).
Évitez le surapprentissage: CatBoost adopte une nouvelle méthode de traitement des caractéristiques des catégories, qui réduit efficacement le surajustement.
Efficacité: CatBoost fonctionne bien en termes de vitesse d'entraînement et de vitesse de prédiction.
Prend en charge la formation CPU et GPU: CatBoost peut fonctionner sur le CPU ou utiliser le GPU pour un entraînement accéléré.
Gérer automatiquement les valeurs manquantes: CatBoost peut gérer automatiquement les valeurs manquantes sans étapes de prétraitement supplémentaires.
Le principe de base de CatBoost est basé sur un arbre de décision d'amplification de gradient (GBDT), mais il est innovant dans le traitement des caractéristiques catégorielles et en évitant le surajustement. Voici quelques points techniques clés :
Traitement des fonctionnalités de catégorie:
CatBoost introduit une méthode appelée « codage moyen » pour calculer de nouvelles fonctionnalités basées sur la moyenne des catégories.
Grâce à une technique appelée « codage cible », le risque de fuite de données est réduit en utilisant la moyenne des valeurs cibles lors de la conversion des caractéristiques catégorielles en caractéristiques numériques.
Pendant le processus de formation, les données sont traitées à l'aide d'informations statistiques pour éviter de coder directement la variable cible.
Boosting ordonné:
Afin d'éviter les fuites de données et le surapprentissage, CatBoost traite les données de manière ordonnée pendant la formation.
Le boosting ordonné fonctionne en mélangeant aléatoirement les données pendant la formation et garantit que le modèle ne voit les données passées qu'à un moment donné et n'utilise pas les informations futures pour prendre des décisions.
Optimisation informatique:
CatBoost accélère le processus de calcul des fonctionnalités grâce au précalcul et à la mise en cache.
Prend en charge la formation CPU et GPU et peut fonctionner correctement sur des ensembles de données à grande échelle.
Ce qui suit est un exemple de base d'utilisation de CatBoost pour une tâche de classification. Nous utilisons l'ensemble de données Auto MPG (Miles Per Gallon), qui est un ensemble de données de problème de régression classique couramment utilisé dans l'apprentissage automatique et l'analyse statistique. Cet ensemble de données enregistre l'efficacité énergétique (c'est-à-dire les miles par gallon) de différents modèles de voitures ainsi que plusieurs autres caractéristiques connexes.
Caractéristiques de l'ensemble de données :
mpg: Miles par gallon (variable cible).
cylindres: Nombre de cylindres, indiquant le nombre de cylindres du moteur.
déplacement: Cylindrée du moteur (pouces cubes).
chevaux-vapeur: Puissance du moteur (chevaux-vapeur).
poids: Poids du véhicule en livres.
accélération: Temps d'accélération de 0 à 60 mph (secondes).
année modèle: Année de production du véhicule.
origine: Origine du véhicule (1=États-Unis, 2=Europe, 3=Japon).
Les premières lignes de l'ensemble de données :
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
Exemple de code :
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
Erreur quadratique moyenne (MSE) : Erreur quadratique moyenne, qui représente la différence quadratique moyenne entre la valeur prédite et la valeur réelle. Plus la valeur est petite, meilleures sont les performances du modèle, ici la valeur de MSE est de 4,9042.
Erreur absolue moyenne (MAE) : Erreur absolue moyenne, qui représente la différence absolue moyenne entre la valeur prédite et la valeur réelle. Plus la valeur est petite, meilleures sont les performances du modèle, ici la valeur de MAE est de 1,6381.
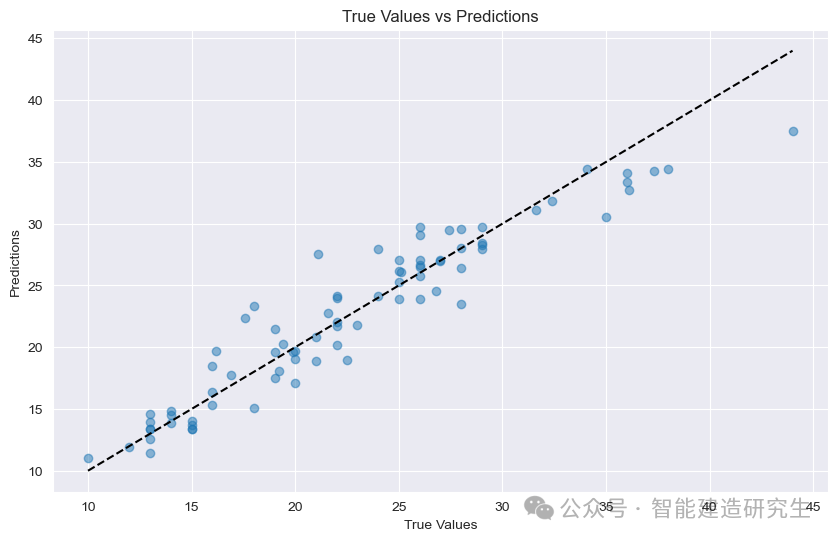
Nuage de points : Chaque point de la figure représente un échantillon test. L'abscisse représente la vraie valeur de l'échantillon (MPG) et l'ordonnée représente la valeur prédite du modèle (MPG).
diagonale: La ligne pointillée noire sur la figure est une ligne diagonale de 45 degrés, qui représente le résultat de la prédiction dans des conditions idéales, c'est-à-dire que la valeur prédite est égale à la valeur réelle.
Répartition des points :
proche de la diagonale: Indique que la valeur prédite du modèle est très proche de la valeur réelle et que la prédiction est précise.
reste loin de la diagonale: Indique qu'il existe un écart important entre la valeur prédite et la valeur réelle et que la prédiction est inexacte.
À partir des points de la figure, vous pouvez voir que la plupart des points sont concentrés près de la diagonale, ce qui indique que le modèle a de bonnes performances de prédiction. Cependant, certains points sont également éloignés de la diagonale, ce qui indique qu'il y en a. un certain écart entre les valeurs prédites de ces échantillons et l'écart des valeurs réelles.
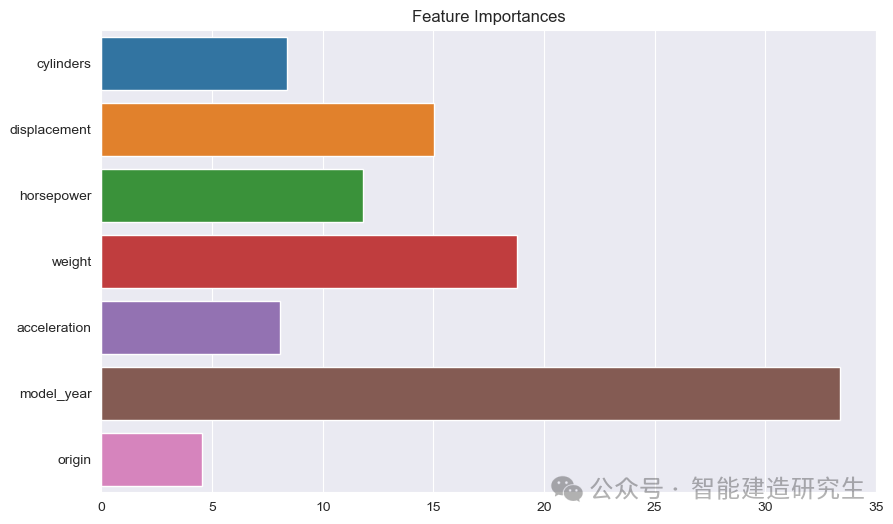
Diagramme à bandes : Chaque barre représente l'importance d'une fonctionnalité dans le modèle. Plus la barre est longue, plus la contribution de la fonctionnalité à la prédiction du modèle est importante.
Nom de la fonctionnalité: Répertorie les noms de toutes les entités sur l'axe Y.
Valeur d'importance des fonctionnalités: affiche la valeur d'importance relative de chaque entité sur l'axe X.
Comme on peut le voir sur la photo :
année modèle: La plus importante de toutes les caractéristiques, indiquant que l’année de production de la voiture a un fort impact sur la consommation de carburant prévue.
poids: Le poids d'une voiture est la deuxième caractéristique la plus importante et a également un impact significatif sur l'efficacité énergétique.
déplacementetchevaux-vapeur: La cylindrée et la puissance du moteur contribuent également de manière significative à l’efficacité énergétique.
Dans l'exemple, nous utilisons CatBoost pour traiter l'ensemble de données Auto MPG, dont l'objectif principal est de créer un modèle de régression pour prédire le rendement énergétique d'une voiture (c'est-à-dire miles par gallon, MPG).
Le contenu ci-dessus est résumé à partir d'Internet. S'il est utile, veuillez le transmettre à la prochaine fois !

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

