
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina

CatBoost (Categorical Boosting)은 Yandex(검색 엔진이 한때 러시아 시장 점유율의 60% 이상을 차지했으며 기타 인터넷 제품 및 서비스도 제공하는 러시아 인터넷 회사)에서 개발한 그래디언트 부스팅을 기반으로 하는 기계 학습 알고리즘입니다. CatBoost는 범주형 기능을 처리하는 데 특히 뛰어나며 과적합 및 데이터 유출 문제를 효과적으로 방지할 수 있습니다. CatBoost의 전체 이름은 "Categorical Boosting"입니다. 이는 다수의 범주형 기능이 포함된 데이터를 처리할 때 더 나은 성능을 발휘하도록 설계되었습니다.
범주형 특성 처리: CatBoost는 별도의 인코딩(예: 원-핫 인코딩) 없이 범주형 기능을 직접 처리할 수 있습니다.
과적합 방지: CatBoost는 카테고리 특성을 처리하는 새로운 방법을 채택하여 과적합을 효과적으로 줄여줍니다.
능률: CatBoost는 훈련 속도와 예측 속도 모두에서 좋은 성능을 발휘합니다.
CPU 및 GPU 훈련 지원: CatBoost는 CPU에서 실행되거나 가속 훈련을 위해 GPU를 사용할 수 있습니다.
결측값 자동 처리: CatBoost는 추가적인 전처리 단계 없이 결측값을 자동으로 처리할 수 있습니다.
CatBoost의 핵심 원리는 GBDT(Gradient Boosting Decision Tree)를 기반으로 하지만 범주형 기능을 처리하고 과적합을 방지하는 데 혁신적입니다. 다음은 몇 가지 주요 기술 사항입니다.
카테고리 특성 처리:
CatBoost는 카테고리의 평균을 기반으로 새로운 기능을 계산하기 위해 "평균 인코딩"이라는 방법을 도입합니다.
'타겟 인코딩'이라는 기술을 이용해 범주형 특성을 수치형 특성으로 변환할 때 타겟 값의 평균을 사용함으로써 데이터 유출 위험을 줄인다.
학습 과정에서는 목표 변수를 직접 인코딩하지 않도록 통계 정보를 사용하여 데이터를 처리합니다.
주문형 부스팅:
데이터 누출 및 과적합을 방지하기 위해 CatBoost는 훈련 중에 데이터를 질서 있게 처리합니다.
순서 부스팅은 훈련 중에 데이터를 무작위로 섞는 방식으로 작동하며, 모델이 특정 순간의 과거 데이터만 보고 결정을 내리는 데 미래 정보를 사용하지 않도록 합니다.
전산 최적화:
CatBoost는 사전 계산 및 캐싱을 통해 기능 계산 프로세스를 가속화합니다.
CPU 및 GPU 교육을 지원하며 대규모 데이터 세트에서 우수한 성능을 발휘할 수 있습니다.
다음은 분류 작업에 CatBoost를 사용하는 기본 예입니다. 우리는 기계 학습 및 통계 분석에 일반적으로 사용되는 고전적인 회귀 문제 데이터 세트인 Auto MPG(Miles Per Gallon) 데이터 세트를 사용합니다. 이 데이터 세트는 다양한 자동차 모델의 연비(즉, 갤런당 마일)뿐만 아니라 기타 여러 관련 특성을 기록합니다.
데이터 세트 특성:
mpg: 갤런당 마일(목표 변수).
실린더: 엔진의 실린더 수를 나타내는 실린더 수입니다.
배수량: 엔진 배기량(입방인치)입니다.
마력: 엔진 출력(마력).
무게: 차량 중량(파운드)입니다.
가속: 0에서 60mph까지의 가속 시간(초)입니다.
모델 연도: 차량 생산연도.
기원: 차량 원산지(1=미국, 2=유럽, 3=일본).
데이터 세트의 처음 몇 행:
- mpg cylinders displacement horsepower weight acceleration model_year origin
- 0 18.0 8 307.0 130.0 3504.0 12.0 70 1
- 1 15.0 8 350.0 165.0 3693.0 11.5 70 1
- 2 18.0 8 318.0 150.0 3436.0 11.0 70 1
- 3 16.0 8 304.0 150.0 3433.0 12.0 70 1
- 4 17.0 8 302.0 140.0 3449.0 10.5 70 1
-
코드 예:
- import pandas as pd # 导入Pandas库,用于数据处理
- import numpy as np # 导入Numpy库,用于数值计算
- from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
- from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
- from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
- import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
- import seaborn as sns # 导入Seaborn库,用于绘制统计图
-
- # 设置随机种子以便结果复现
- np.random.seed(42)
-
- # 从UCI机器学习库加载Auto MPG数据集
- url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
- column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
- data = pd.read_csv(url, names=column_names, na_values='?', comment='t', sep=' ', skipinitialspace=True)
-
- # 查看数据集的前几行
- print(data.head())
-
- # 处理缺失值
- data = data.dropna()
-
- # 特征和目标变量
- X = data.drop('mpg', axis=1) # 特征变量
- y = data['mpg'] # 目标变量
-
- # 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
- X['cylinders'] = X['cylinders'].astype(str)
- X['model_year'] = X['model_year'].astype(str)
- X['origin'] = X['origin'].astype(str)
-
- # 将数据集划分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 定义CatBoost回归器
- model = CatBoostRegressor(
- iterations=1000, # 迭代次数
- learning_rate=0.1, # 学习率
- depth=6, # 决策树深度
- loss_function='RMSE', # 损失函数
- verbose=100 # 输出训练过程信息
- )
-
- # 训练模型
- model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)
-
- # 进行预测
- y_pred = model.predict(X_test)
-
- # 评估模型性能
- mse = mean_squared_error(y_test, y_pred) # 计算均方误差
- mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差
-
- # 打印模型的评估结果
- print(f'Mean Squared Error (MSE): {mse:.4f}')
- print(f'Mean Absolute Error (MAE): {mae:.4f}')
-
- # 绘制真实值与预测值的对比图
- plt.figure(figsize=(10, 6))
- plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
- plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
- plt.xlabel('True Values') # X轴标签
- plt.ylabel('Predictions') # Y轴标签
- plt.title('True Values vs Predictions') # 图标题
- plt.show()
-
- # 特征重要性可视化
- feature_importances = model.get_feature_importance() # 获取特征重要性
- feature_names = X.columns # 获取特征名称
-
- plt.figure(figsize=(10, 6))
- sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
- plt.title('Feature Importances') # 图标题
- plt.show()
-
- # 输出
- '''
- mpg cylinders displacement horsepower weight acceleration
- 0 18.0 8 307.0 130.0 3504.0 12.0
- 1 15.0 8 350.0 165.0 3693.0 11.5
- 2 18.0 8 318.0 150.0 3436.0 11.0
- 3 16.0 8 304.0 150.0 3433.0 12.0
- 4 17.0 8 302.0 140.0 3449.0 10.5
- model_year origin
- 0 70 1
- 1 70 1
- 2 70 1
- 3 70 1
- 4 70 1
- 0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
- 100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
- 200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
- Stopped by overfitting detector (50 iterations wait)
- bestTest = 2.21453232
- bestIteration = 238
- Shrink model to first 239 iterations.
- Mean Squared Error (MSE): 4.9042
- Mean Absolute Error (MAE): 1.6381
- <Figure size 1000x600 with 1 Axes>
- <Figure size 1000x600 with 1 Axes>
- '''
평균 제곱 오차(MSE) : 평균 제곱 오차. 예측 값과 실제 값 간의 평균 제곱 차이를 나타냅니다. 값이 작을수록 모델 성능이 향상되며, 여기서 MSE 값은 4.9042입니다.
평균 절대 오차(MAE) : 평균절대오차. 예측값과 실제값의 평균절대차를 나타냅니다. 값이 작을수록 모델 성능이 향상되며, 여기서 MAE 값은 1.6381입니다.
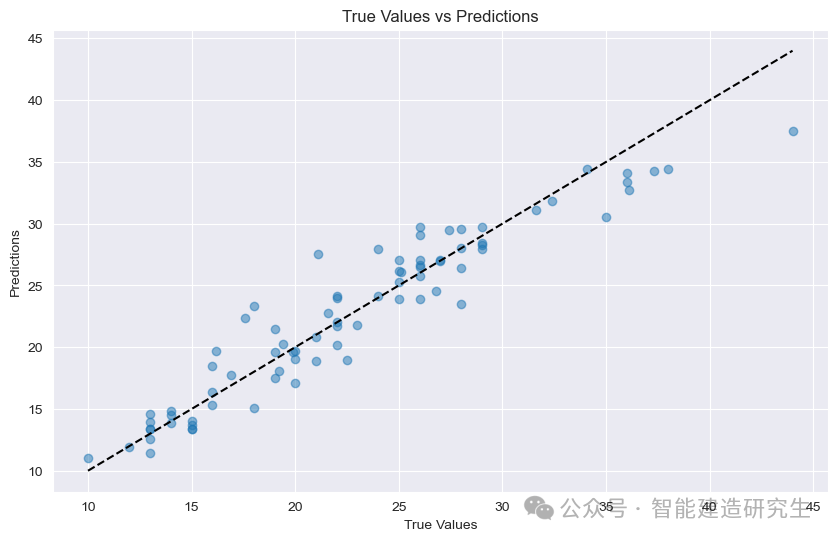
산포도 : 그래프의 각 점은 테스트 샘플을 나타냅니다. 가로축은 샘플의 실제 값(MPG)을 나타내고, 세로축은 모델의 예측값(MPG)을 나타냅니다.
대각선: 그림의 검은색 점선은 45도 대각선으로 이상적인 조건에서의 예측 결과, 즉 예측값이 참값과 동일함을 나타냅니다.
포인트 분배:
대각선에 가깝다: 모델의 예측값이 참값에 매우 가깝고 예측이 정확함을 나타냅니다.
대각선에서 멀리 떨어지세요: 예측값과 실제값 사이에 큰 차이가 있어 예측이 부정확함을 나타냅니다.
그림의 점들을 보면 대부분의 점들이 대각선 근처에 집중되어 있는 것을 볼 수 있는데, 이는 모델의 예측 성능이 좋은 것을 의미하지만, 대각선에서 멀리 떨어져 있는 점들도 있다는 것을 알 수 있습니다. 이러한 샘플의 예측 값과 실제 값 사이에는 일정한 간격이 있습니다.
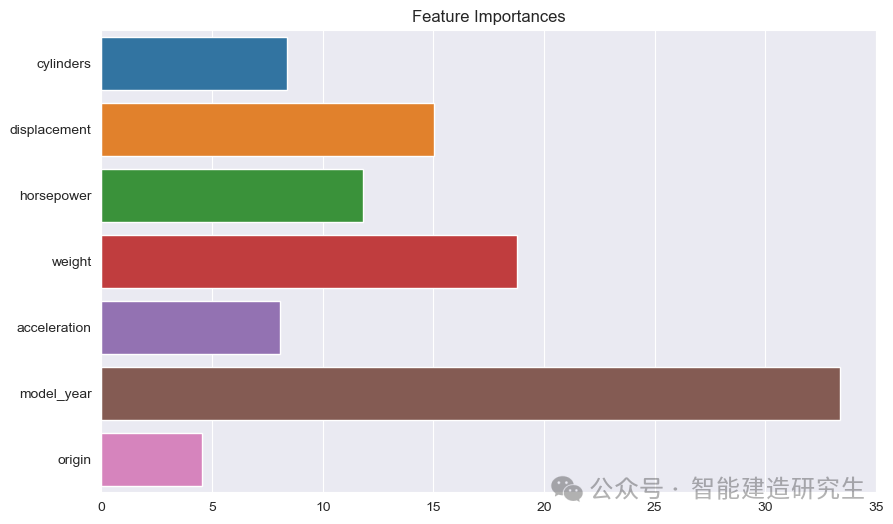
막대 차트 : 각 막대는 모델의 기능의 중요성을 나타냅니다. 막대가 길수록 모델 예측에 대한 특성의 기여도가 높아집니다.
기능 이름: Y축에 모든 지형지물의 이름을 나열합니다.
기능 중요도 값: X축에 각 특성의 상대적 중요도 값을 표시합니다.
그림에서 볼 수 있듯이:
모델 연도: 모든 특성 중에서 가장 중요한 것으로, 자동차 생산 연도가 예상 연비에 큰 영향을 미친다는 것을 나타냅니다.
무게: 자동차의 무게는 두 번째로 중요한 특성이며 연비에도 큰 영향을 미칩니다.
배수량그리고마력: 엔진의 배기량과 출력 역시 연비에 크게 기여합니다.
이 예에서는 CatBoost를 사용하여 Auto MPG 데이터세트를 처리합니다. 이 데이터세트의 주요 목적은 자동차의 연료 효율성(예: 갤런당 마일, MPG)을 예측하기 위한 회귀 모델을 구축하는 것입니다.
위 내용은 인터넷에서 요약한 내용입니다. 도움이 되셨다면 다음에 또 만나요!

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에서 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com