2024-07-08
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Kuvittele, että olet juuri liittynyt suureen yritykseen, joka väittää olevansa "digitaalisessa muutoksessa" big datan kehitysinsinöörinä. Ensimmäisellä työviikolla olet täynnä innostusta etkä malta odottaa, että pääset koukistamaan lihaksiasi ja käyttämään taitojasi datalähtöisten päätösten tekemiseen yrityksessä.

Kun kuitenkin alat kaivaa syvemmälle yrityksesi tietoinfrastruktuuriin ja prosesseihin, huomaat, että edessä olevat haasteet ovat paljon suuremmat kuin odotit:
Näiden haasteiden edessä huomaat, että tässä yrityksessä on vielä pitkä matka todelliseen datalähtöiseen päätöksentekoon. Päätät järjestelmällisesti selvittää nämä ongelmat ymmärtääksesi ja ratkaistaksesi ne paremmin.

Tietosiilot ovat tilanteita, joissa tietoja ei voida tehokkaasti jakaa tietojärjestelmien tai organisaatioyksiköiden välillä. Tämä johtaa päällekkäiseen kehitykseen ja resurssien tuhlaukseen.
esimerkki:
Esimerkki koodista (Python):
# 销售部门的数据库
sales_db = {
"product_a": {"sales": 1000, "revenue": 50000},
"product_b": {"sales": 800, "revenue": 40000}
}
# 库存部门的数据库
inventory_db = {
"product_a": {"stock": 500},
"product_b": {"stock": 200}
}
# 由于数据孤岛,我们无法直接获取销售和库存的综合信息
# 需要手动整合数据
def get_product_info(product):
if product in sales_db and product in inventory_db:
return {
"sales": sales_db[product]["sales"],
"revenue": sales_db[product]["revenue"],
"stock": inventory_db[product]["stock"]
}
return None
print(get_product_info("product_a"))

Tietojen arvoketjun viat viittaavat katkoihin prosessissa tiedonkeruusta lopulliseen käyttöön, jolloin datan arvoa ei pystytä täysin ymmärtämään.
esimerkki:
Esimerkki koodista (Python):
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 假设我们有用户浏览数据
df = pd.DataFrame({
'user_id': range(1000),
'page_views': np.random.randint(1, 100, 1000),
'time_spent': np.random.randint(10, 3600, 1000),
'purchases': np.random.randint(0, 5, 1000)
})
# 尝试建立一个预测模型
X = df[['page_views', 'time_spent']]
y = df['purchases']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评分
print(f"Model Score: {model.score(X_test, y_test)}")
# 但是,如果分析团队不理解这个模型或不知道如何解释结果,
# 那么这个模型就无法为业务决策提供有价值的指导
Tämä ongelma koskee monia tiedonhallinnan näkökohtia, mukaan lukien yhtenäisten standardien, tiedonhallintamekanismien, tarvittavien tietojen, standardoitujen prosessien, erikoistuneiden organisaatioiden ja hallintajärjestelmien puute.

esimerkki:
Esimerkki koodista (Python):
# 假设我们有来自不同国家的客户数据,格式不统一
us_customers = [
{"name": "John Doe", "phone": "1234567890"},
{"name": "Jane Smith", "phone": "0987654321"}
]
uk_customers = [
{"full_name": "David Brown", "tel": " 44 1234567890"},
{"full_name": "Emma Wilson", "tel": " 44 0987654321"}
]
# 由于缺乏统一标准,我们需要手动处理数据
def standardize_customer(customer, country):
if country == "US":
return {
"full_name": customer["name"],
"phone_number": " 1 " customer["phone"]
}
elif country == "UK":
return {
"full_name": customer["full_name"],
"phone_number": customer["tel"]
}
# 标准化数据
standardized_customers = (
[standardize_customer(c, "US") for c in us_customers]
[standardize_customer(c, "UK") for c in uk_customers]
)
print(standardized_customers)
Tämä ongelma koskee tietojen saatavuutta, ymmärrettävyyttä ja jäljitettävyyttä.
esimerkki:
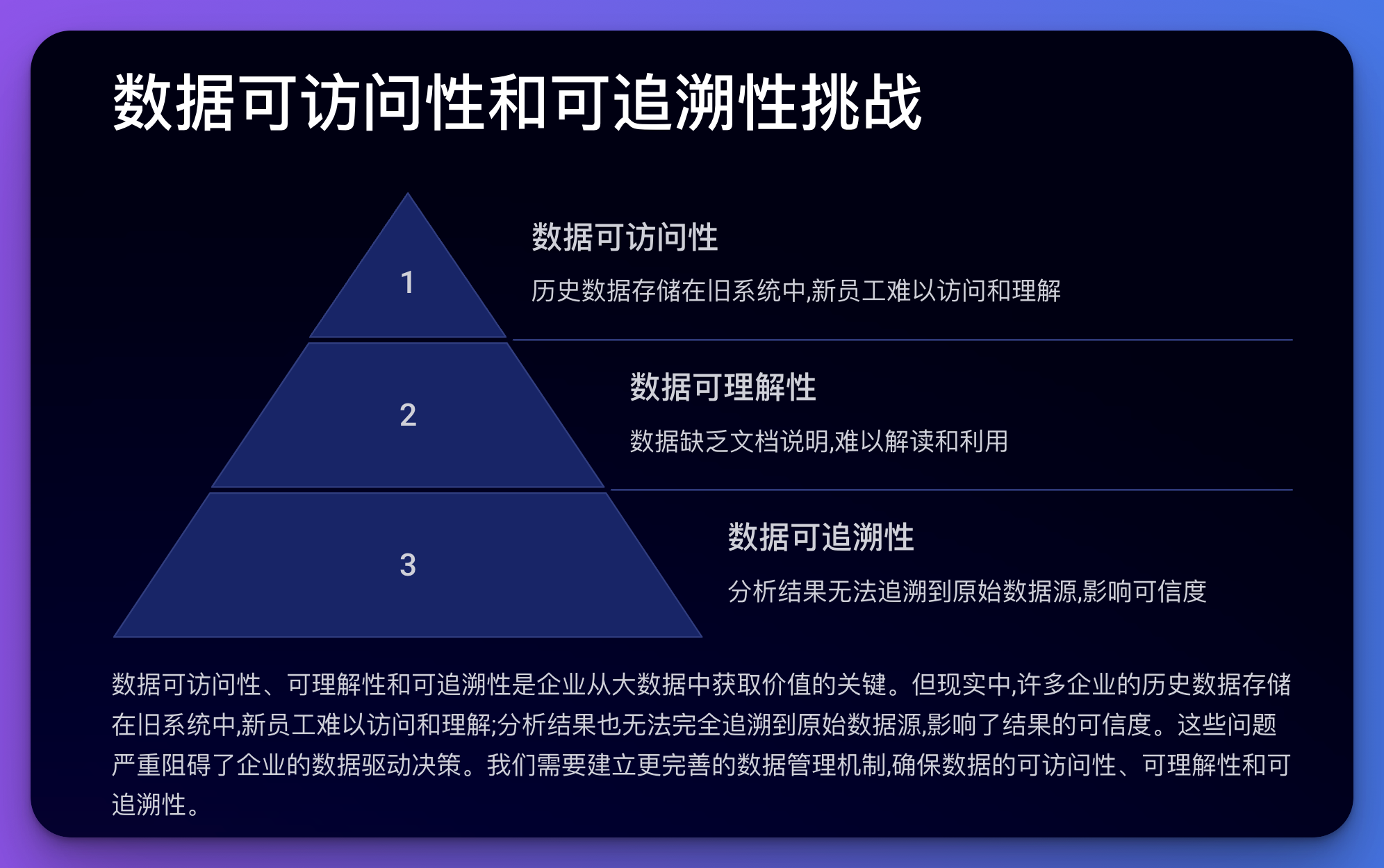
Esimerkki koodista (Python):
import hashlib
import json
from datetime import datetime
class DataRecord:
def __init__(self, data, source):
self.data = data
self.source = source
self.timestamp = datetime.now().isoformat()
self.hash = self._calculate_hash()
def _calculate_hash(self):
record = json.dumps({"data": self.data, "source": self.source, "timestamp": self.timestamp})
return hashlib.sha256(record.encode()).hexdigest()
def __str__(self):
return f"Data: {self.data}, Source: {self.source}, Timestamp: {self.timestamp}, Hash: {self.hash}"
# 创建一些数据记录
record1 = DataRecord("User A purchased Product X", "Sales System")
record2 = DataRecord("Product X inventory decreased by 1", "Inventory System")
print(record1)
print(record2)
# 这种方法可以帮助追踪数据的来源和变化,但仍然需要额外的系统来管理这些记录
Tietojen laatuongelmia ovat epätarkkuudet, epätäydellisyydet, epäjohdonmukaisuudet, päällekkäisyydet jne.

esimerkki:
Esimerkki koodista (Python):
import pandas as pd
import numpy as np
# 创建一个包含一些"脏"数据的DataFrame
df = pd.DataFrame({
'name': ['John', 'Jane', 'John', 'Bob', 'Alice', np.nan],
'age': [30, 25, 30, -5, 200, 35],
'email': ['[email protected]', 'jane@example', '[email protected]', '[email protected]', '[email protected]', 'invalid']
})
print("Original data:")
print(df)
# 数据清洗
def clean_data(df):
# 删除重复行
df = df.drop_duplicates()
# 处理缺失值
df['name'] = df['name'].fillna('Unknown')
# 修正异常值
df.loc[df['age']

个人简介
潜心研究技术三十余年,精通java、linux、javascript、php、css、等等各种语言,在开源领域有诸多贡献,建立开发者文档站,将一些技术开发中的问题分享出来,以供大家查阅

我的联系方式