2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Cet article est constitué des notes du troisième camp d'entraînement modèle à grande échelle pour les universitaires organisé par le Laboratoire d'intelligence artificielle de Shanghai. Il est destiné uniquement à titre de référence pour les individus et les assistants pédagogiques lors de la correction des devoirs.Lien original du tutoriel。
Pour vous inscrire, veuillez rechercher « The Third Scholar Model Practice Camp » sur WeChat.
Cette note est une note annotée personnellement et modifiée sur la base du didacticiel original.
😀Hello大家好,欢迎来到Grand modèle éruditCamp pratique, voici un cours de base préparé par le camp pratique pour les étudiants qui participent au camp pratique pour la première fois et les étudiants de diverses industries qui n'ont aucune connaissance de base de Linux. Ici, nous allons vous apprendre à l'utiliser.Machine de développement InternStudio, et maîtriser quelques basesConnaissance Linux , pour que tout le monde ne sache pas par où commencer dans les cours suivants, j'espère que cela sera utile à tout le monde. Nous avons préparé quelques tâches de niveau pour vous dans les tâches de niveau ici. Lorsque vous aurez terminé les tâches de niveau requises et effectué votre enregistrement, vous recevrez la récompense de puissance de calcul du niveau actuel.commençons!
InternStudio 是大模型时代下的云端算力平台。基于 InternLM 组织下的诸多算法库支持,为开发者提供开箱即用的大语言模型微调环境、工具、数据集,并完美兼容 🤗 HugginFace 开源生态。
Si vous souhaitez en savoir plus sur InternStudio, vous pouvez consulter les documents suivants : Stage en studio
https://studio.intern-ai.org.cn/
Ouvrez d'abord le lien ci-dessus pour accéder à InternStudio. Après vous être connecté, vous accéderez automatiquement à l'interface de la console, comme indiqué dans la figure ci-dessous :
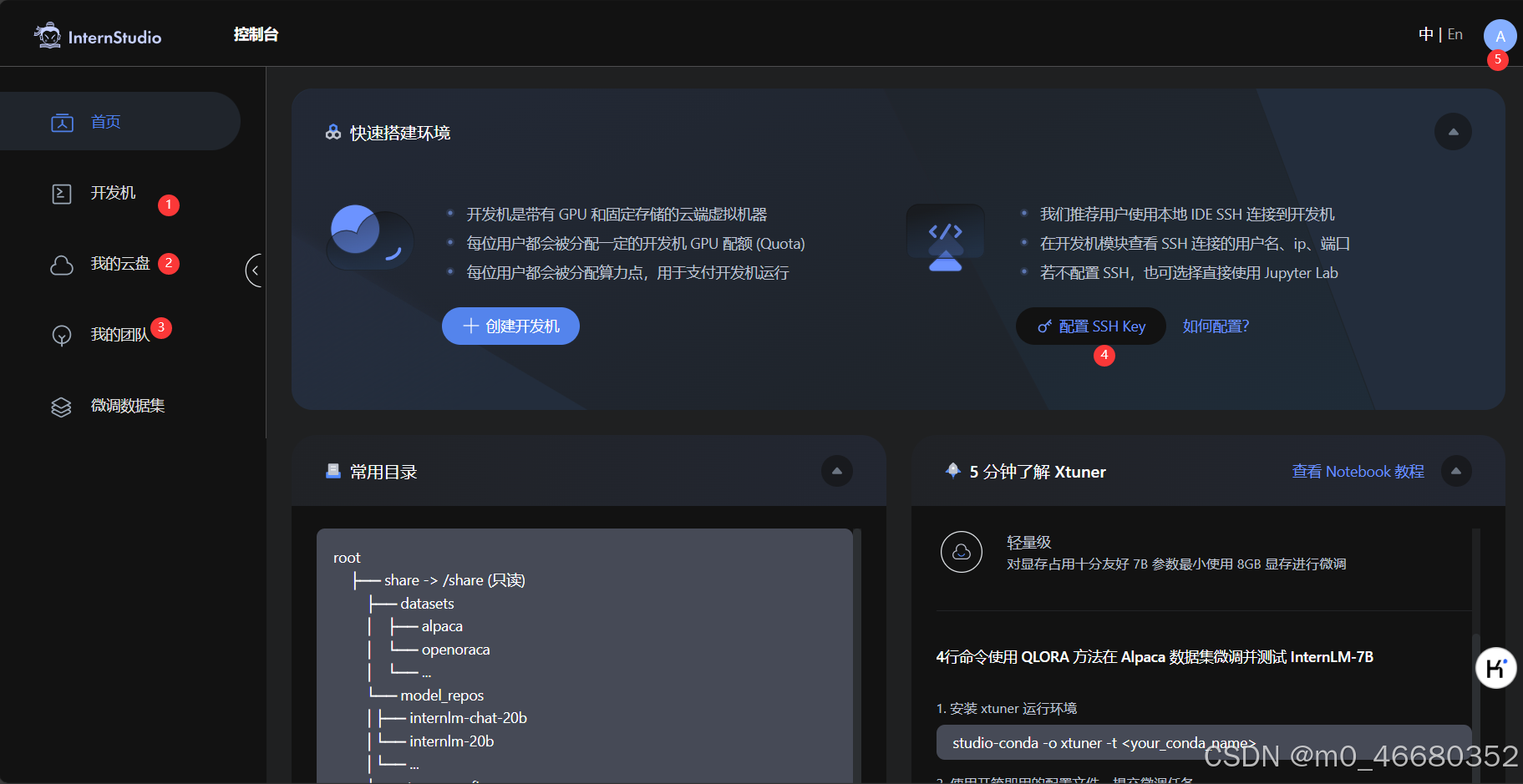
Je vous explique les fonctions des pages correspondant à chaque numéro de série :
Ce qui précède est une brève introduction à la plateforme InternStudio. Voyons comment créer une machine de développement. Nous allons à la page d'accueil et cliquons sur ".Créer une machine de développement”
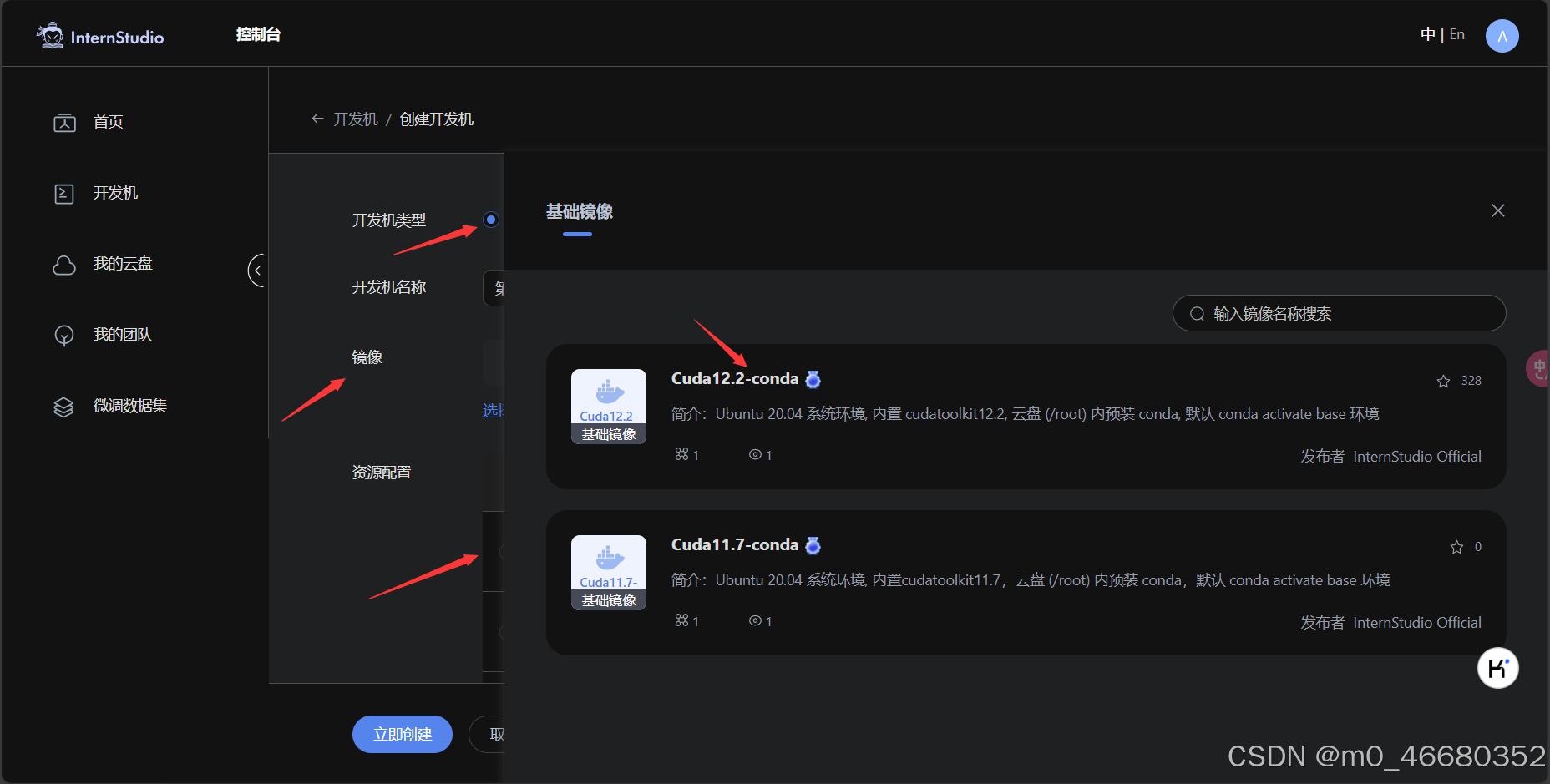
Ici, nous choisissons de créermachine de développement personnel, nommétest,CudaLa version est 12.2,Allocation des ressourcesSélectionnez 10 % et la durée par défaut est correcte.
Une fois la création terminée, dansMachine de développementVous pouvez voir la machine de développement que vous venez de créer sur l'interface. Cliquez pour accéder à la machine de développement.

Après être entré dans la machine de développement, vous pouvez voir la page principale de la machine de développement. La machine de développement propose trois modes :JupyterLab, Terminal et VScode
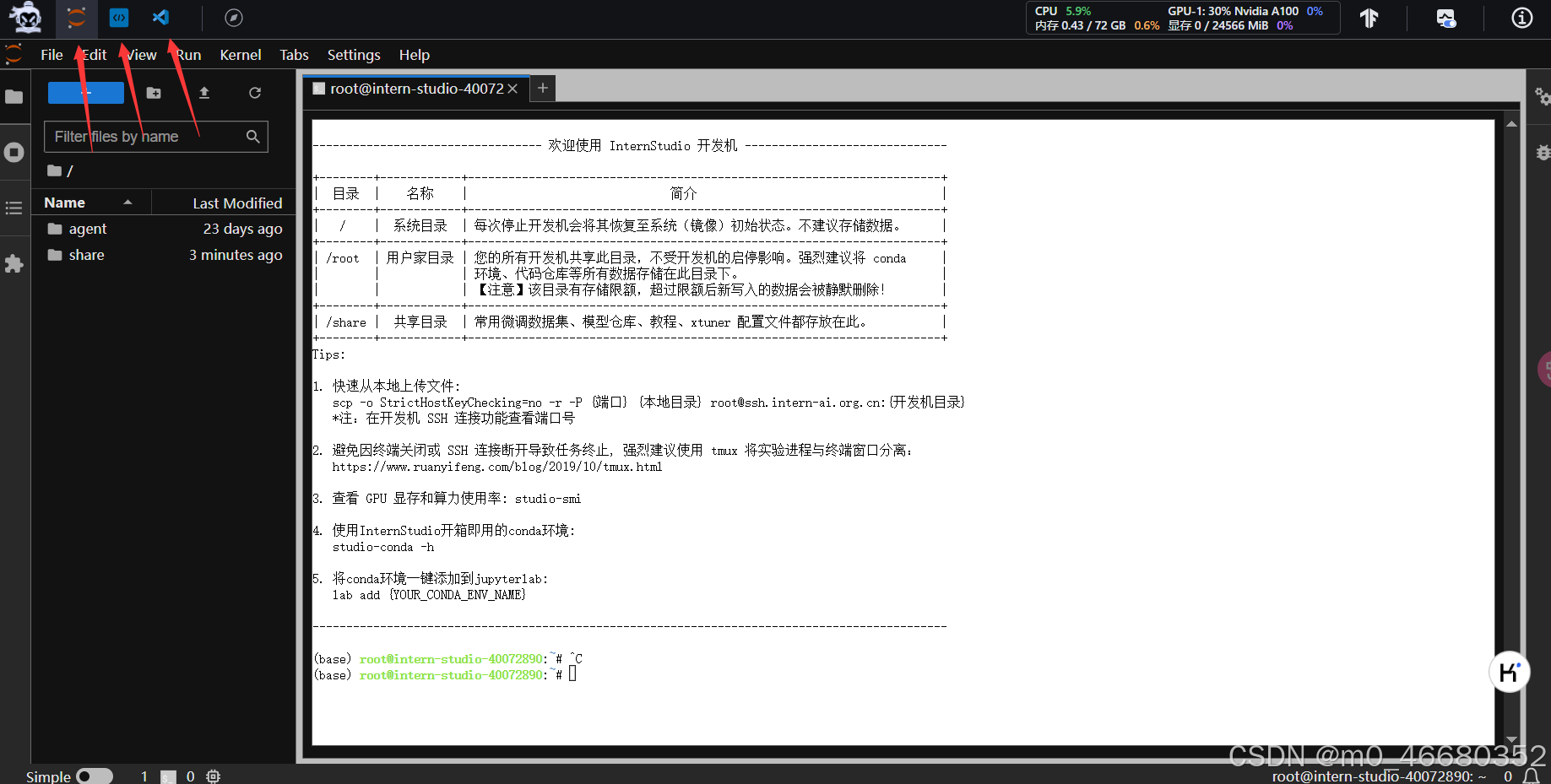
dans:
Nous avons présenté ci-dessusPlateforme InternStudio, et comment créer une machine de développement. Dans cette section, nous voulons comprendre ce qu'est une machine de développement.SSH、Pourquoi utiliser la connexion à distance, Comment utiliser SSHconnexion à distanceMachine de développement, qu'est-ce que c'estCartographie des portset comment procéderCartographie des ports。
SSHLe nom complet est Secure Shell, qui se traduit en chinois par Secure Shell.protocole de sécurité réseau , réalisez un accès sécurisé, un transfert de fichiers et d'autres services grâce à des mécanismes de cryptage et d'authentification. Le protocole SSH fournit des services réseau sécurisés dans un environnement réseau non sécurisé en chiffrant et authentifiant les données réseau.
SSH est (architecture C/S) parserveuretclientAfin d'établir un canal SSH sécurisé, les deux parties doivent d'abord établir une connexion TCP, puis négocier le numéro de version et les différents algorithmes utilisés, et générer le même.clé de session utilisé pour le chiffrement symétrique ultérieur. Après avoir terminé l'authentification de l'utilisateur, les deux parties peuvent établir une session pour l'échange de données.
Ensuite, dans la pratique ultérieure, nousConfigurer les clés SSH, la clé de configuration est telle que nous n'avons pas besoin de saisir le mot de passe à plusieurs reprises lorsque nous nous connectons à distance à la machine de développement, puisPourquoi se connecter à distance ??
L'avantage de la connexion à distance est que si vous utilisez un bureau distant, vous pouvez vous connecter à distance à la machine de développement via SSH, afin de pouvoir développer localement. Et si vous avez besoin d'exécuter du code local et que vous ne disposez pas d'un environnement, une connexion à distance est indispensable.
Tout d'abord, nous utilisons la méthode de saisie du mot de passe pour la connexion à distance SSH. Plus tard, nous expliquerons comment configurer une connexion sans mot de passe.
Après avoir terminé la création de la machine de développement, nous devons ouvrir le terminal powerShell de notre ordinateur et utiliserWin+R Utilisez la touche de raccourci pour ouvrir la boîte d'exécution, entrez PowerShell et ouvrez le terminal PowerShell. (Si vous utilisez le système d'exploitation Linux ou Mac, les étapes suivantes sont les mêmes)
Nous revenons à la plateforme de la machine de développement et entronsMachine de développementRecherchez la machine de développement que nous avons créée sur la page et cliquez surConnexion SSH。

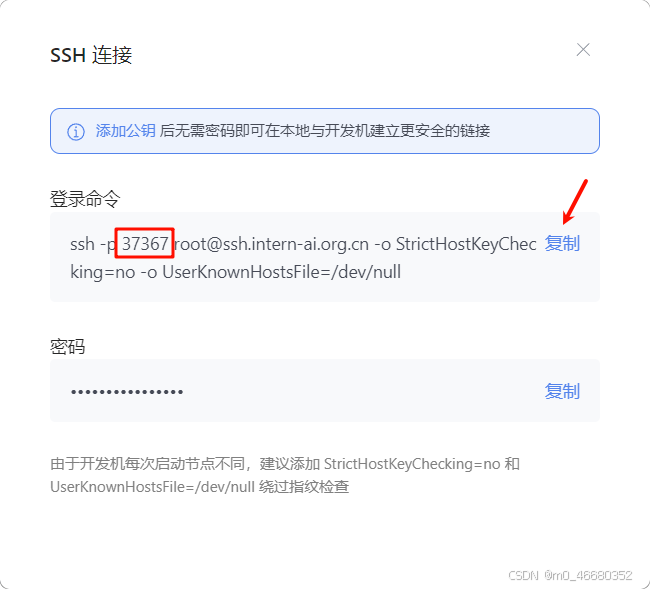
puis copieCommande de connexion, 37367, voici le port SSH utilisé par la machine de développement. Généralement, le port 22 est utilisé sans ce numéro de port, vous ne pouvez pas vous connecter à SSH, et le port de chacun est différent, donc si vous vous connectez à la machine de développement, vous ne pouvez pas vous connecter. , vous devez vérifier si le port est erroné.
Collez la commande copiée dans PowerShell et appuyez sur Entrée. Ici, nous devons saisir le mot de passe. Nous copions le mot de passe sous la commande de connexion et le collons dans le terminal.Notez qu'après avoir copié le mot de passe, cliquez avec le bouton droit pour le coller. La touche de raccourci du shell pour le coller sur certains ordinateurs est.shift+ins, le mot de passe collé ici ne sera pas affiché, c'est normal.
Enfin, appuyez sur Entrée et le contenu suivant apparaît, indiquant le succès :
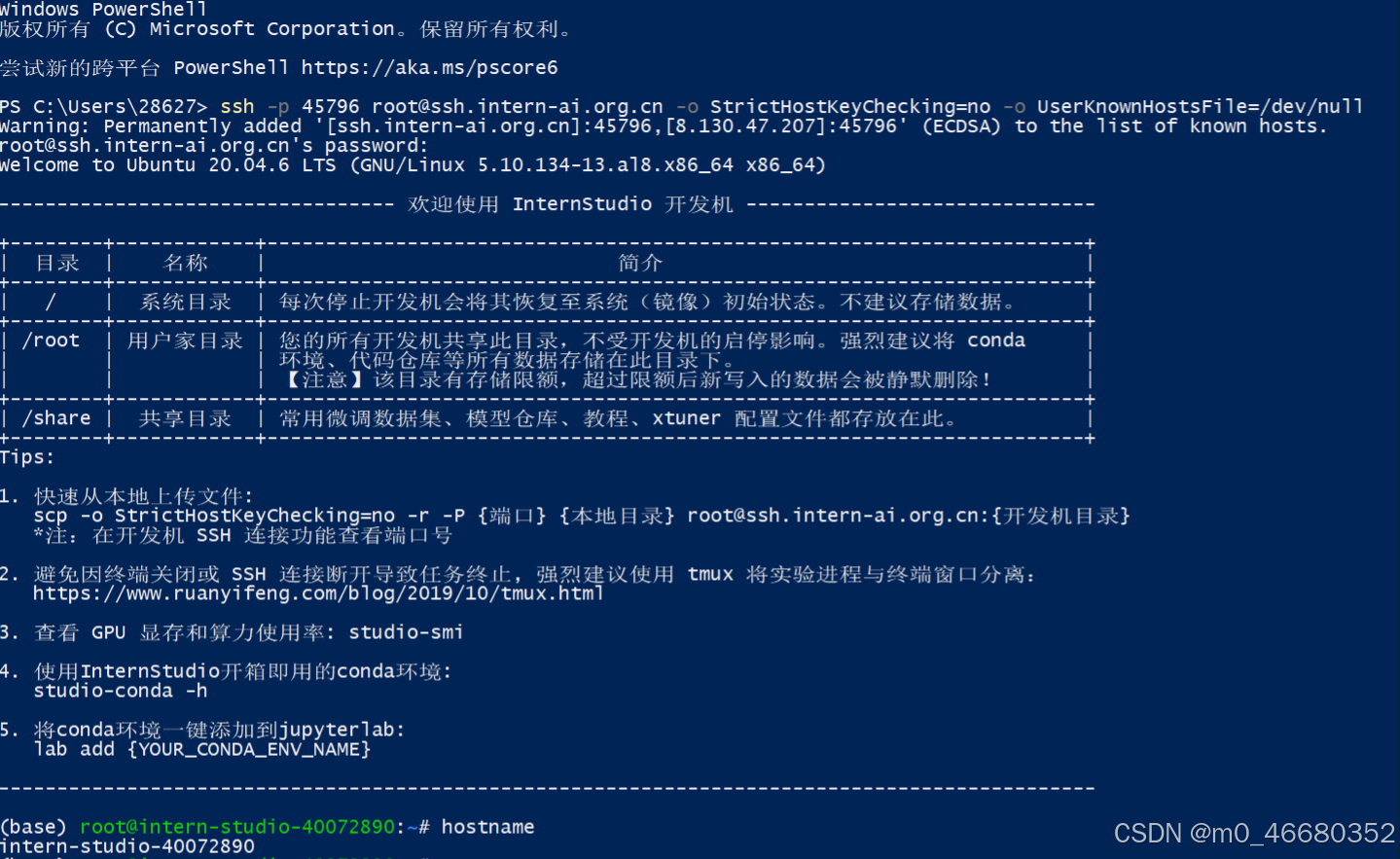
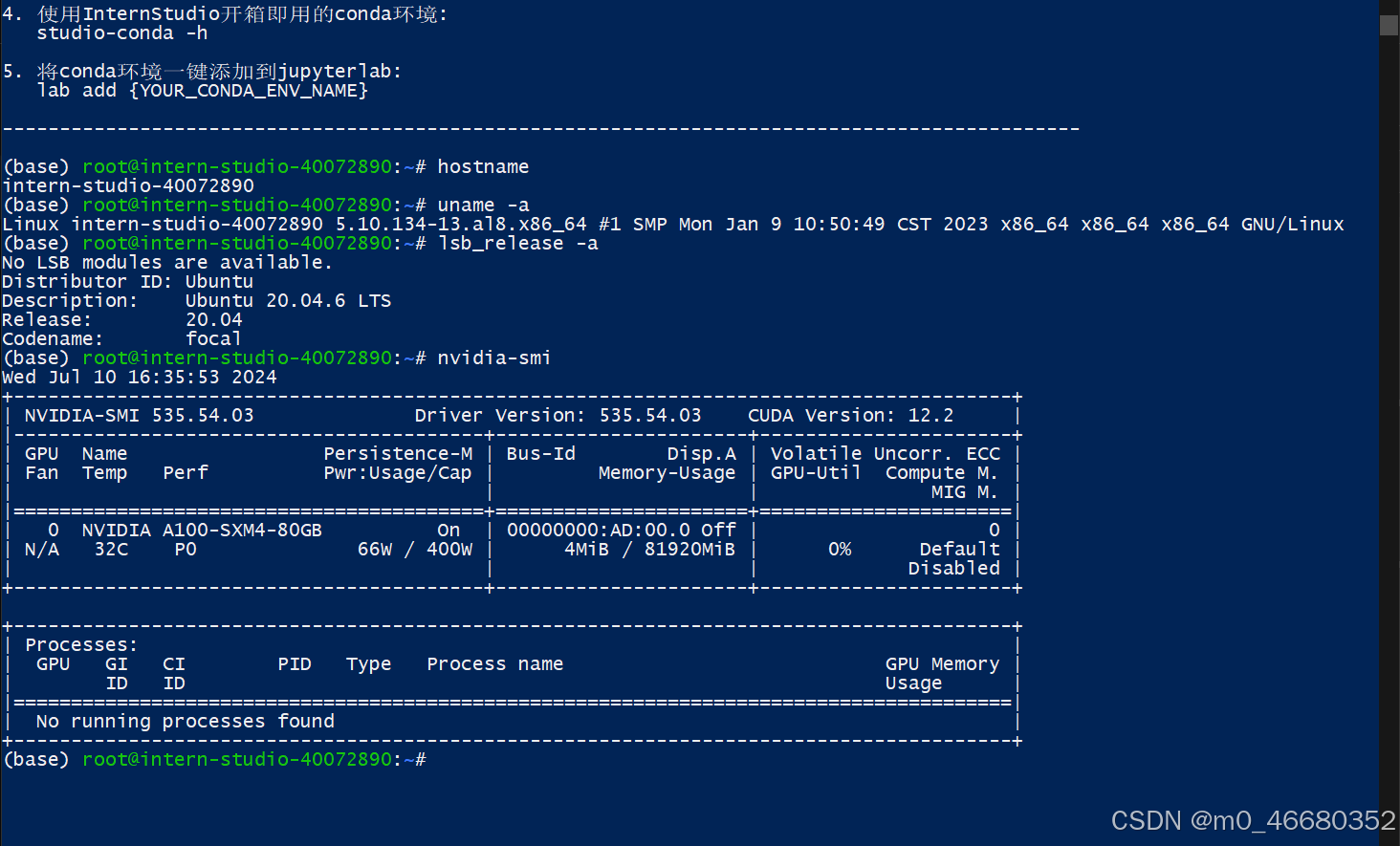
Après nous être connectés à la machine de développement, nous pouvons utiliserhostnamePour afficher le nom de la machine de développement, utilisezuname -aPour afficher les informations sur le noyau de la machine de développement, utilisezlsb_release -aPour afficher les informations sur la version de la machine de développement, utiliseznvidia-smiVérifiez les informations du GPU. Nous parlerons de ces commandes plus tard. Si vous souhaitez quitter la connexion à distance, saisissez-la deux fois.exitC'est ça.
Mais lorsque nous développons et étudions, il est difficile de saisir le mot de passe à chaque fois à distance. Nous pouvons configurer la clé SSH pour ignorer l'étape de saisie du mot de passe. Dans la commande ssh, nous pouvons utiliser.générateur de clés sshcommande pour générer la clé
La clé SSH est une méthode d'authentification de connexion sûre et pratique, utilisée pour l'authentification et la communication cryptée dans le protocole SSH.
générateur de clés sshPrend en charge les clés d'authentification RSA et DSA.
Les paramètres couramment utilisés incluent :
Ici nous utilisons l'algorithme RSA pour générer la clé, la commande est :
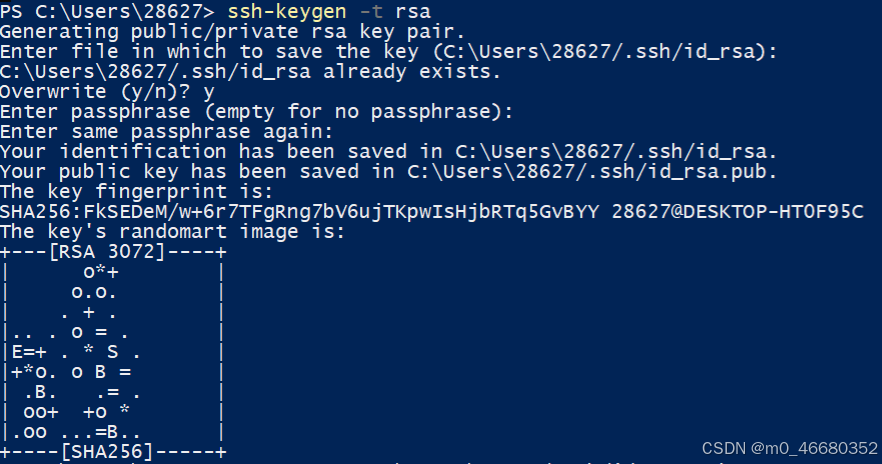
ssh-keygen -t rsa
Après avoir entré la commandeEntrez jusqu'au boutÇa y est, la clé ici est générée par défaut dans~/.ssh/sous le répertoire,~Cela signifie le répertoire personnel, si c'est Windows, c'estC:Users{your_username} .Peut être utilisé dans PowerShellGet-ContentCommande pour afficher la clé générée, qui peut être utilisée s'il s'agit d'un système d'exploitation LinuxcatCommande.
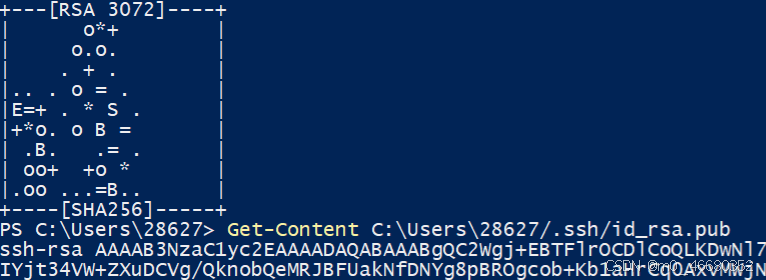
Ensuite, nous revenons à la plateforme de la machine de développement et cliquons sur Configuration sur la page d'accueilClé SSH, puis cliqueAjouter une clé publique SSH,
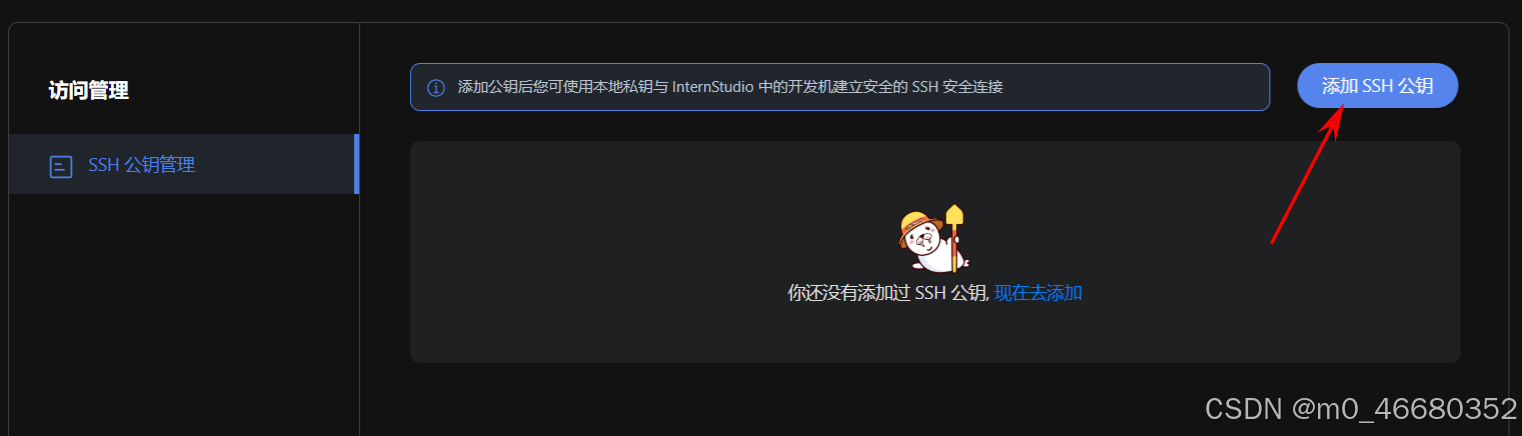
Copiez la clé que vous venez de générer et collez-la dans la zone de clé publique. Enfin, cliquez sur Ajouter maintenant et la configuration de la clé SSH est terminée.
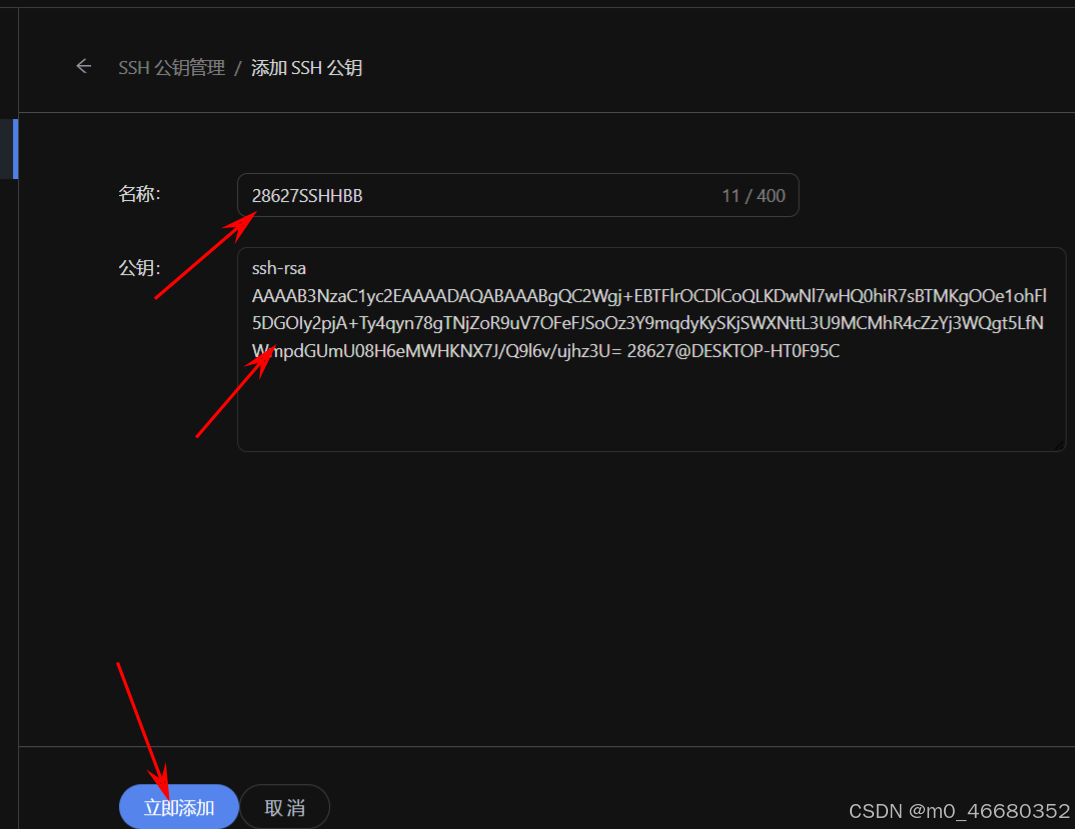
Après avoir terminé la création de la clé SSH, redémarrezTerminalLors de la connexion à distance, l'étape de saisie du mot de passe sera ignorée.
Bien entendu, vous pouvez également utiliser des logiciels de connexion à distance SSH, tels que :Windterm, Xterminal attendez. Ici, nous utilisons VScode pour la connexion à distance. L'avantage d'utiliser VScode est qu'il s'agit d'un éditeur de code, très pratique pour la modification de code et d'autres opérations.
Si nous voulons nous connecter à distance dans VScode, nous devons également installer un ensemble de plug-ins. Vous pouvez rechercher en ligne comment installer VScode. (Le vscode dans la machine de développement ne peut pas rechercher ce plug-in, mais le vscode local le peut)
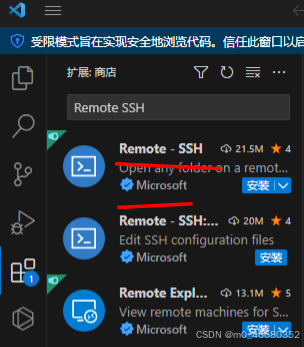
Si vous avez installé VScode, vous pouvez cliquer sur la page d'extension à gauche et saisir "SSH" dans le champ de recherche. Le premier est le plug-in que nous voulons installer.
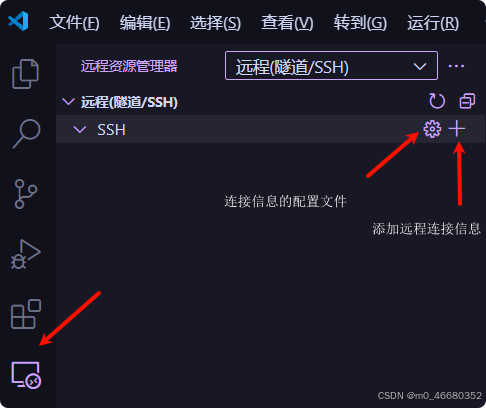
Après avoir installé le plug-in, cliquez sur l'icône de connexion à distance dans la barre latérale, cliquez sur le bouton "+" dans SSH et ajoutez la commande de connexion pour la connexion SSH de la machine de développement.
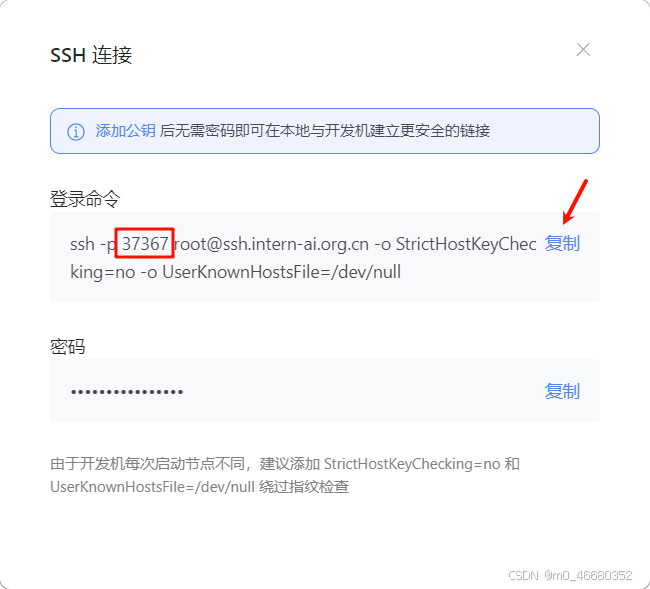
Nous copions la commande de connexion, puis collons la commande dans la fenêtre contextuelle et enfin appuyons sur Entrée :


Le fichier de configuration par défaut convient bien sûr, vous pouvez également le personnaliser. Voici le contenu spécifique du fichier de configuration : (Cela inclut toutes vos informations de connexion à distance)
Host ssh.intern-ai.org.cn #主机ip也可以是域名
HostName ssh.intern-ai.org.cn #主机名
Port 37367 #主机的SSH端口
User root #登录SSH使用的用户
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
Si vous souhaitez ajouter manuellement certaines des options de configuration suivantes, vous devez modifier les parties correspondantes selon le format ci-dessus.
Si *
StrictHostKeyCheckingnoetUserKnownHostsFile*/dev/nullSupprimez la fenêtre contextuelle qui s'affichera pour la vérification des empreintes digitales :
StrictHostKeyChecking noIndique que la vérification stricte des clés d'hôte est désactivée. Cela signifie que lors de la connexion à un nouveau serveur SSH, la clé d'hôte du serveur ne sera pas strictement vérifiée, ce qui peut présenter un certain risque de sécurité.
UserKnownHostsFile /dev/nullIl définit le fichier de clé d'hôte connu de l'utilisateur sur /dev/null, ce qui ignore essentiellement l'enregistrement et l'utilisation des clés d'hôte connues.Cependant, dans les pratiques générales de sécurité, il n'est pas recommandé de désactiver arbitrairement la vérification stricte des clés d'hôte.
Cliquez ensuite sur « Connecter » dans la fenêtre d'invite qui apparaît dans le coin inférieur droit pour vous connecter à distance à la machine de développement.

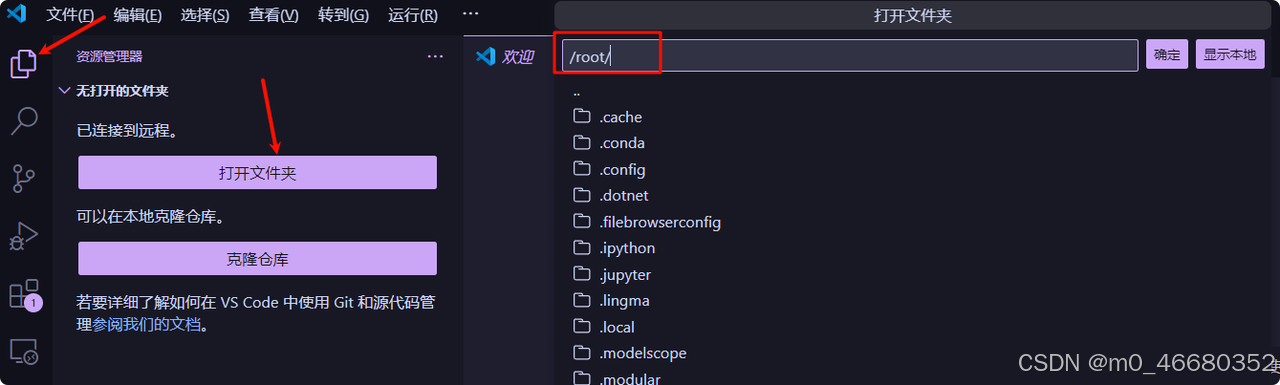
Une fois la connexion à distance terminée, vous pouvez choisir le dossier à ouvrir, qui peut également être appelé répertoire de travail. Vous pouvez choisir le dossier dans la machine de développement ou le dossier local. Le dossier dans la machine de développement est ce que nous avons mentionné précédemment.disque cloud。
Lorsque vous établirez une connexion à distance la prochaine fois, vous n'aurez pas besoin de saisir de commandes de connexion ni d'autres informations. Il vous suffit d'ouvrir la connexion à distance de vscode pour voir les informations sur la machine de développement de la première connexion, comme suit.rootCela signifie que lorsque nous nous connectons pour la première fois à la machine de développement, nous utilisons/rootListe de travail.
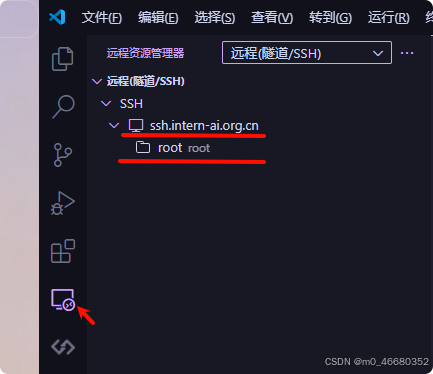
Et sur la photo ci-dessous->Indique que vous devez resélectionner le répertoire de travail après avoir accédé à la machine de développement :

Et sur la photo ci-dessous->Indique l'entrée dans le répertoire de travail sélectionné par la dernière machine de développement :
Le répertoire de travail sélectionné à chaque fois sera affiché sous les informations de la machine de développement : (il y a un répertoire de travail supplémentaire pour l'agent ici)

Ensuite, nous présenterons quandCartographie des ports。
Cartographie des ports Il s'agit d'une technologie réseau qui peut mapper n'importe quel port du réseau externe au port correspondant du réseau interne pour réaliser la communication entre le réseau interne et le réseau externe. Grâce au mappage des ports, les services ou les applications de l'intranet sont accessibles depuis le réseau externe pour permettre une communication pratique sur le réseau.
Alors pourquoi devons-nous effectuer un mappage de ports lorsque nous utilisons une machine de développement ?
Parce que dans les cours suivants, nous réaliserons des modèlesdémo_web Dans la pratique du déploiement, au cours de ce processus, vous rencontrerez probablement le problème d'un chargement incomplet de l'interface utilisateur Web.En effet, lors de l'exécution de web_demo dans l'IDE Web de la machine de développement, l'accès direct au service http/https dans la machine de développement peut rencontrer des problèmes de proxy.ressources de l'interface utilisateurPas complètement chargé.
Donc, pour résoudre ce problème, nous devons mapper les ports de la connexion exécutant web_demo, etLes liens du réseau externe sont mappés vers notre hôte local , nous utilisons l'accès par connexion locale pour résoudre ce problème de proxy. Pratiquons-le maintenant.

Comprenons d'abord comment fonctionne le mappage des ports de la machine de développement sur la base d'un diagramme :
Vous trouverez ci-dessous des étapes pratiques. Comprenez d’abord comment effectuer le mappage des ports.
ssh -p 37367 [email protected] -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no
Ce qui précède est une commande de mappage de port. Exécutez cette commande sur l'hôte pour effectuer le mappage de port. Voici un organigramme pour comprendre le processus de mappage de port :
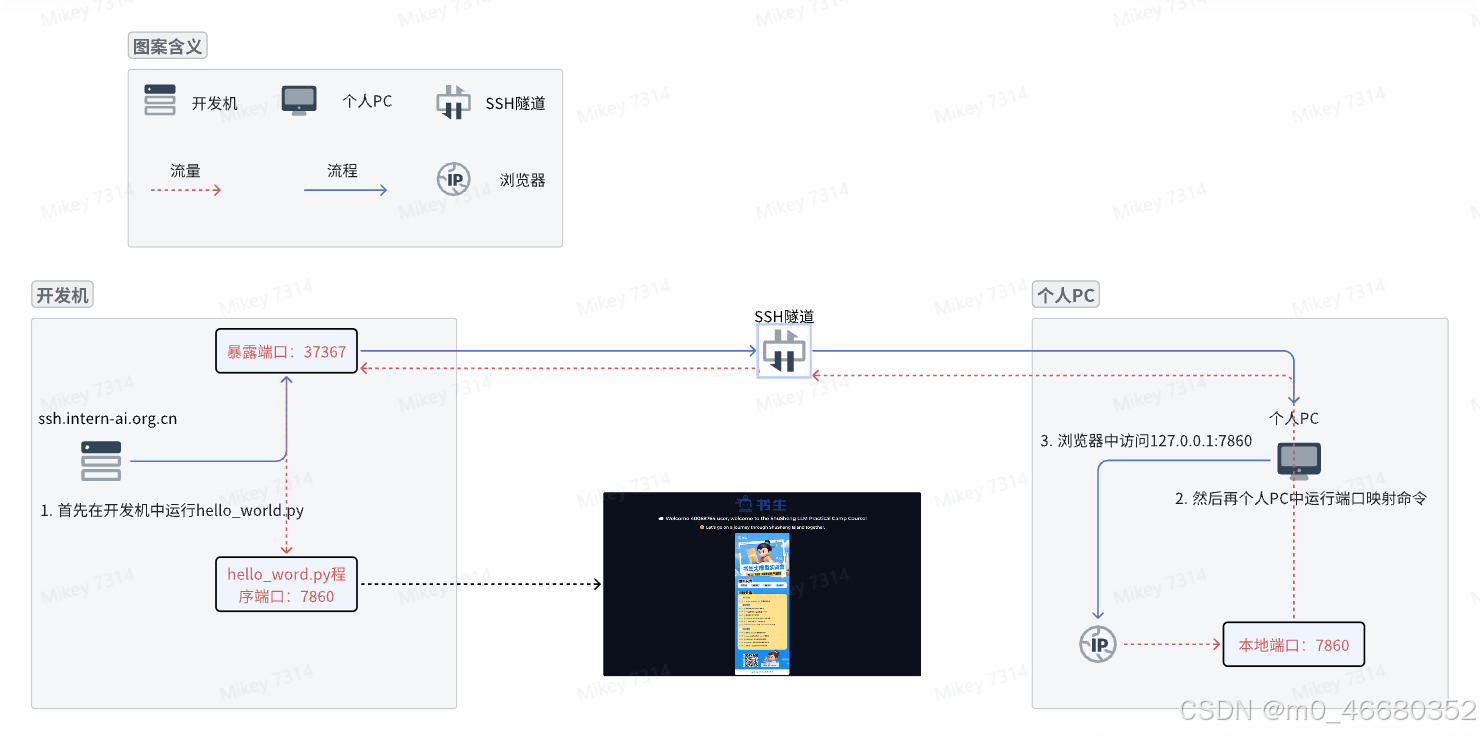
Le PC personnel se connectera à distance au seul port exposé 37367 de la machine de développement (ceci est mentionné lors de SSH, et le port exposé de chaque machine de développement est différent) et définira les options du tunnel. Le port exposé sert de station de transit pour l'acheminement du trafic.
-C: Activez la compression pour réduire la quantité de données transférées.-N: N'exécute pas de commandes à distance, établit uniquement des tunnels.-g: Autoriser les hôtes distants à se connecter aux ports transférés localement.Lorsque cette commande SSH est exécutée sur un PC personnel, le client SSH écoutera sur le port 7860 de la machine locale.
Tout trafic envoyé vers le port local 7860 sera transmis par le tunnel SSH vers le port 7860 sur l'adresse 127.0.0.1 du serveur distant.
Cela signifie que même si ce port de la machine de développement n'est pas directement exposé au réseau externe, nous pouvons accéder en toute sécurité aux services du serveur distant via ce tunnel. .
Nous allons toujours à l'interface de la machine de développement, trouvons notre machine de développement et cliquonsServices personnalisés, copiez la première commande,

ssh -p 37367 [email protected] -CNg -L {本地机器_PORT}:127.0.0.1:{开发机_PORT} -o StrictHostKeyChecking=no
Présentons-lui la signification de chaque partie de la commande :
-p 37367: Spécifie le port pour la connexion SSH à 37367, mentionné précédemment.[email protected]: Indique à utiliser root L'identité de l'utilisateur se connecte àssh.intern-ai.org.cn cet hôte.-CNg:
-C Généralement utilisé pour activer la compression.-N Indique que les commandes à distance ne sont pas exécutées, mais que seules les connexions sont établies pour la redirection de port, etc.-g Autoriser les hôtes distants à se connecter aux ports transférés localement.-L {本地机器_PORT}:127.0.0.1:{开发机_PORT}: Il s'agit de configurer la redirection de port local pour transférer le port spécifié de la machine locale (en {本地机器_PORT} représente) transmis à l'hôte distant (ici, c'est-à-diressh.intern-ai.org.cn)de 127.0.0.1 (c'est-à-dire l'adresse de bouclage locale) et le port de la machine de développement spécifié (défini par{开发机_PORT} exprimer).-o StrictHostKeyChecking=no: désactivez la vérification stricte des clés d'hôte pour éviter les invites ou les erreurs dues à des clés d'hôte inconnues lors de la première connexion.Lorsque vous exécutez une démo Web, vous pouvez utiliser cette commande pour effectuer un mappage de port, par exemple :
Nous créons un fichier hello_world.py (clic droit sur l'interface de la machine de développement pour créer le fichier et changeons le nom en hello_world.py) et remplissons le contenu suivant dans le fichier :
import socket
import re
import gradio as gr
# 获取主机名
def get_hostname():
hostname = socket.gethostname()
match = re.search(r'-(d+)$', hostname)
name = match.group(1)
return name
# 创建 Gradio 界面
with gr.Blocks(gr.themes.Soft()) as demo:
html_code = f"""
<p align="center">
<a href="https://intern-ai.org.cn/home">
<img src="https://intern-ai.org.cn/assets/headerLogo-4ea34f23.svg" alt="Logo" width="20%" style="border-radius: 5px;">
</a>
</p>
<h1 style="text-align: center;">☁️ Welcome {get_hostname()} user, welcome to the ShuSheng LLM Practical Camp Course!</h1>
<h2 style="text-align: center;">😀 Let’s go on a journey through ShuSheng Island together.</h2>
<p align="center">
<a href="https://github.com/InternLM/Tutorial/blob/camp3">
<img src="https://oss.lingkongstudy.com.cn/blog/202406301604074.jpg" alt="Logo" width="20%" style="border-radius: 5px;">
</a>
</p>
"""
gr.Markdown(html_code)
demo.launch()
N'oubliez pas après l'éditionctrl+ssauvegarder
Avant d'exécuter le code, vous devez utiliserpip install gradio==4.29.0Commande pour installer les packages de dépendances suivants (copiez et collez la commande dans le terminal), puis exécutez-en un dans le terminal de Web IDEpython hello_world.pyCommande

Si le mappage des ports n’est pas effectué, il n’est pas accessible via l’adresse IP locale.
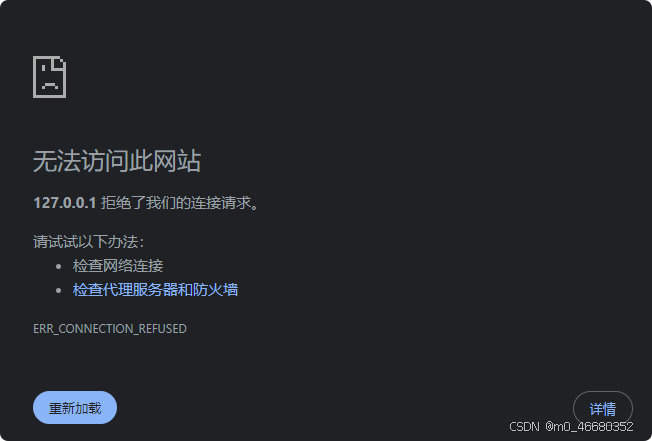
Je peux le saisir dans PowerShell à l'aide de la commande suivante :
ssh -p 37367 [email protected] -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no

Cela représente le succès. (Avis: Cette commande ne renvoie aucun contenu, ce qui signifie que le mappage de port est en cours d'exécution, et vous pouvez ensuite voir l'interface de l'interface utilisateur Web en ouvrant la connexion dans la page Web)

Bien sûr, si nous exécutons différentes interfaces utilisateur Web, nous devons saisir des commandes à plusieurs reprises, ce qui est très gênant, et nous devons utiliser VScode.Nous avons connecté la machine de développement à distance via SSH. VScode fournit un mappage automatique des ports. Nous n'avons pas besoin de le configurer manuellement. Nous pouvons utiliser la touche de raccourci "Ctrl+Shift+~".Réveillez le terminal, les options de port se trouvent sur le côté droit du terminal :

Ici, vous pouvez afficher les informations de mappage de port. Si vous devez modifier le port, vous pouvez modifier le numéro de port dans la colonne du port.
Dans cette partie, je vais vous faire comprendre certains aspects de LinuxOpérations de base , et utilisez quelques outils. Afin que chacun puisse le résoudre par lui-même lorsqu'il rencontre des problèmes, vous pouvez également commenter ici et je vous répondrai à temps.
parce que nous utilisonsMachine de développementrarement utiliségestion des autorités , nous ne le présenterons donc pas. (Les opérations suivantes sont toutes effectuées dans le terminal VScode)
Sous Linux, les opérations courantes de gestion de fichiers incluent :
touch La commande crée un fichier vide.mkdir Commande.cdCommande.pwdCommande.cat Afficher directement tout le contenu du fichier,more etless Peut être consulté en pages.vi ouvim Attendez l'éditeur.cp Commande.lnCommande.mv Commande.rm Commande.rmdir(Seuls les répertoires vides peuvent être supprimés) ou rm -r(Les répertoires non vides peuvent être supprimés).find Commande.lscommande, comme l'utilisation ls -lAfficher des informations détaillées sur les fichiers d'un répertoire.sedCommande.Voici plusieurs commandes que nous utiliserons dans le cours :
Nous pouvons utiliser le toucher pour créer rapidement des fichiers, nous n'avons donc pas besoin de cliquer manuellement pour les créer.Par exemple, nous souhaitons créer undemo.pydocument:
De la même manière, si vous souhaitez créer un fichier nommétestAnnuaire:

Cette commande sera la commande la plus couramment utilisée. Avant de l'utiliser, vous devez expliquer la structure des répertoires aux étudiants qui n'ont pas de compétences en informatique et faire un dessin pour que tout le monde puisse comprendre :
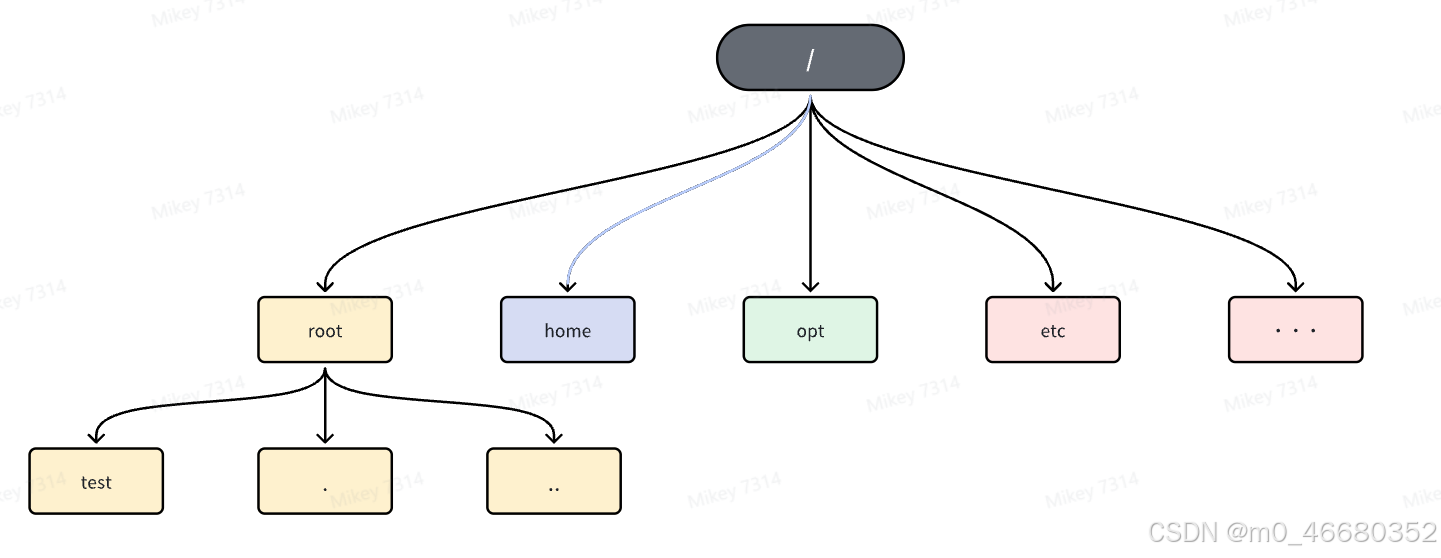
Ce que nous utilisons maintenant, c'estrootrépertoire, qui est également le répertoire personnel de l'utilisateur root.~, dans le système d'exploitation Linux/Représente le répertoire racine. Il existe de nombreux répertoires et fichiers requis par le système dans le répertoire racine. Le répertoire que nous venons de créer existe avec.rootrépertoire, parmi lesquels.Représente le répertoire courant,.. Le répertoire parent représenté.Si je devais entrer maintenanttestrépertoire, puis revenez àrootAnnuaire, nous pouvons faire ceci :
on peut utiliserpwdCommande pour afficher le répertoire actuel : Cela nous permet de déterminer plus facilement dans quel répertoire nous nous trouvons actuellement.
catLa commande peut afficher le contenu du fichier et d'autres commandes peuvent être utilisées--helpCommande pour afficher :
Nous pouvons l'utiliser lorsque nous devons éditer des fichiersviouvimcommande, lorsque vous entrez dans l’édition de fichiers, il existe trois modes :
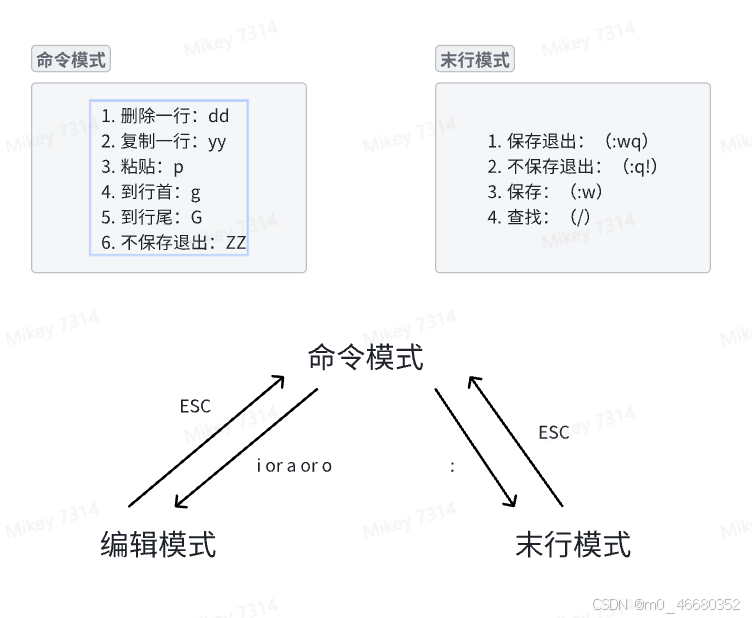
Entrez en mode édition pour utiliseri, l'avantage de vim est que vous pouvez effectuer de simples modifications de fichiers dans le terminal.
**cp**La commande sera fréquemment utilisée dans les cours suivants. Elle est utilisée pour copier un fichier ou un répertoire vers un autre répertoire. Les utilisations courantes incluent :
cp 源文件 目标文件cp -r 源目录 目标目录Mais si l'on veut utiliser le modèle, cette opération prendra beaucoup d'espace disque, on utilise donc généralementln commande, c'est la même chose que le raccourci Windows. Il existe deux types de liens sous Linux :lien physique(lien physique) aveclien logiciel (lien symbolique), un lien physique signifie qu'un fichier peut avoir plusieurs noms, tandis qu'un lien symbolique génère un fichier spécial dont le contenu pointe vers l'emplacement d'un autre fichier. Les liens physiques existent dans le même système de fichiers, mais les liens symboliques peuvent s'étendre sur différents systèmes de fichiers.
Par conséquent, nous utilisons généralement des connexions souples. Ses méthodes d’utilisation courantes sont les suivantes :
ln [参数][源文件或目录][目标文件或目录]
Les paramètres sont les suivants :
mvcommande etrmLes commandes sont utilisées de la même manière, maismvIl est utilisé pour déplacer des fichiers ou des répertoires et peut également être renommé.rmLa commande est utilisée pour supprimer des fichiers ou des répertoires.
Les méthodes couramment utilisées sont les suivantes :
Paramètres couramment utilisés :
-i: Mode interactif, demander avant d'écraser.-f: Forcer la couverture.-u: Déplacez-le uniquement si le fichier source est plus récent que le fichier cible.Exemple d'utilisation :
mv file1.txt dir1/: déplacer le fichier file1.txt Déplacer vers le répertoiredir1 milieu.
mv file1.txt file2.txt: déplacer le fichier file1.txt Renommer enfile2.txt。
commande rm:
Paramètres couramment utilisés :
-i: Mode interactif, demander avant de supprimer.-f: Suppression forcée, ignorant les fichiers inexistants, sans demande de confirmation.-r:Supprimer de manière récursive un répertoire et son contenu.Exemple d'utilisation :
rm file.txt:Supprimer les fichiers file.txt。rm -r dir1/ : Supprimer récursivement des répertoires dir1 et tout son contenu.La commande pour supprimer un répertoire peut également être utiliséermdir。
findLa commande est un puissant outil de recherche de fichiers dans le système Linux. Elle peut trouver des fichiers ou des répertoires qui remplissent les conditions dans le répertoire spécifié et ses sous-répertoires et effectuer les opérations correspondantes.
Ce qui suit estfindQuelques utilisations courantes de la commande :
-name option pour rechercher des fichiers par nom de fichier. Par exemple,find /path/to/directory -name "file.txt"recherchera le répertoire spécifié et ses sous-répertoires nommésfile.txtdocument.-type option pour rechercher des fichiers par type de fichier. Par exemple,find /path/to/directory -type fTous les fichiers ordinaires du répertoire spécifié et de ses sous-répertoires seront trouvés.-size option pour rechercher des fichiers par taille de fichier. Par exemple,find /path/to/directory -size +100MTrouvera les fichiers de plus de 100 Mo dans le répertoire spécifié et ses sous-répertoires.-mtime、-atimeou-ctime Les options recherchent les fichiers en fonction de leur heure de modification, de leur heure d'accès ou de leur heure de changement de statut. Par exemple,find /path/to/directory -mtime -7Trouvera les fichiers dans le répertoire spécifié et ses sous-répertoires qui ont été modifiés dans les 7 jours.-perm option pour rechercher des fichiers en fonction des autorisations de fichiers. Par exemple,find /path/to/directory -perm 755Trouvera les fichiers avec l'autorisation 755 dans le répertoire spécifié et ses sous-répertoires.-userou-group Les options recherchent les fichiers par leur propriétaire ou leur groupe. Par exemple,find /path/to/directory -user usernameRecherchera le répertoire spécifié et ses sous-répertoires appartenant à l'utilisateurusernamedocument.-exec Les options peuvent effectuer les opérations correspondantes sur les fichiers trouvés. Par exemple,find /path/to/directory -name "*.txt" -exec rm {} ;supprimera tous les trouvés se terminant par.txtfichier à la fin.lsLa commande peut être utilisée pour lister le contenu d'un répertoire ainsi quedétails。
Les paramètres et méthodes d'utilisation couramment utilisés sont les suivants :
-a: Afficher tous les fichiers et répertoires, y compris les fichiers cachés (au-delà.fichier ou répertoire commençant par .).-l: Affiche des informations détaillées au format long, y compris les autorisations de fichiers, le propriétaire, la taille, l'heure de modification, etc.-h:et-lUtilisé en combinaison pour afficher la taille du fichier d'une manière lisible par l'homme (par ex.K、M、Gattendez).-R: Répertorie le contenu des sous-répertoires de manière récursive.-t : Affichage par ordre d'heure de modification des fichiers. ,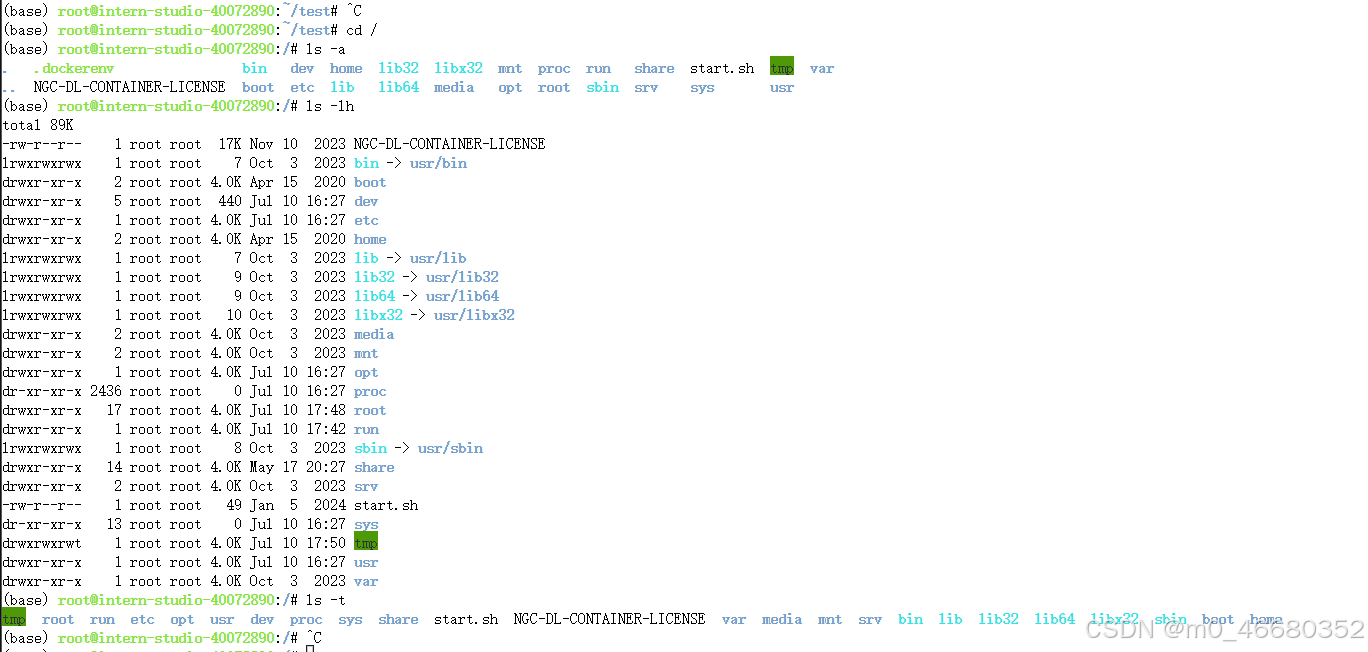
sedCommand est un éditeur de flux, principalement utilisé pour le traitement de texte. Il est souvent utilisé lors du traitement d'opérations de fichiers complexes. Il sera utilisé dans les cours ultérieurs.sedLes paramètres couramment utilisés et les exemples d'utilisation de commandes sont les suivants :
-e<script> ou--expression=<script>: Spécifiez les scripts directement dans la ligne de commande pour le traitement de texte.-f<script文件> ou--file=<script文件>: lit le script à partir du fichier de script spécifié pour le traitement de texte.-n ou--quiet ou--silent: Imprimez uniquement les résultats de sortie traités par le script et n'imprimez pas les lignes sans correspondance.a: ajoute la chaîne de texte spécifiée à la ligne suivante de la ligne actuelle.c: remplace la plage de lignes spécifiée par la chaîne de texte spécifiée.d: supprime la ligne spécifiée.i: ajoute la chaîne de texte spécifiée à la ligne précédente de la ligne actuelle.p : Imprime les lignes sélectionnées.généralement avec-n Utilisées avec les paramètres, seules les lignes correspondantes sont imprimées.s : Utilisez des expressions régulières pour le remplacement de texte. Par exemple,s/old/new/g Remplacez tous les « InternLM » par « InternLM yyds ».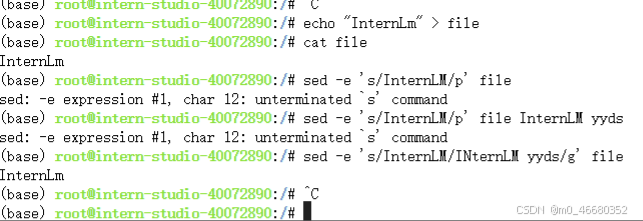
utilisé dans l'exempleechocommande, c'est la même chose qu'en pythonprintIdem, utilisé pour imprimer le contenu, utilisez ici le caractère pipe>Imprimez InternLM dans un fichier. Les caractères pipe couramment utilisés incluent.<et|, on peut par exemple utilisergrepCommande pour afficher les inclusions installées en pythonosForfait terrain :
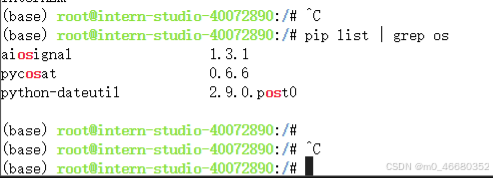
grep Est un puissant outil de recherche de texte. Les paramètres couramment utilisés sont les suivants :
-i: Recherche quelle que soit la casse.-v: Inverse la correspondance, c'est-à-dire affiche les lignes sans correspondance.-n: Afficher le numéro de ligne.-c: Comptez le nombre de lignes correspondantes.La gestion des processusLes commandes sont des outils importants pour la surveillance du système et la gestion des processus. Les commandes de gestion des processus couramment utilisées sont les suivantes :
Il existe également une commande spéciale dans la machine de développementnvidia-smi , qui est un outil de ligne de commande pour l'interface de gestion système NVIDIA, utilisé pour surveiller et gérer les périphériques GPU NVIDIA. Il fournit un moyen rapide d'afficher des informations telles que l'état du GPU, son utilisation, la température, l'utilisation de la mémoire, la consommation d'énergie et les processus exécutés sur le GPU.
Voici des exemples d'utilisation de chaque commande :
ps : Répertoriez les processus dans le système actuel. Différentes informations sur le processus peuvent être affichées à l'aide de différentes options, telles que :ps aux # 显示系统所有进程的详细信息
top : Afficher dynamiquement l’état des processus dans le système. Il met à jour la liste des processus en temps réel, affichant les processus ayant la plus grande utilisation du processeur et de la mémoire.top # 启动top命令,动态显示进程信息
pstree: affiche les processus en cours d'exécution et leurs relations parent-enfant sous la forme d'un diagramme arborescent. pstree # 显示进程树
pgrep : Rechercher les processus correspondant aux critères. Vous pouvez rechercher des processus en fonction du nom du processus, de l'utilisateur et d'autres conditions.pgrep -u username # 查找特定用户的所有进程
nice: Changer la priorité d'un processus.nice Plus la valeur est faible, plus la priorité du processus est élevée.nice -n 10 long-running-command # 以较低优先级运行一个长时间运行的命令
jobs: affiche une liste des tâches de la session de terminal en cours, y compris les processus exécutés en arrière-plan. jobs # 列出当前会话的后台作业
bg etfg:bg Mettez le processus suspendu à s'exécuter en arrière-plan,fg Ramenez le processus en arrière-plan au premier plan.bg # 将最近一个挂起的作业放到后台运行
fg # 将后台作业调到前台运行
kill: Envoie un signal au processus spécifié, généralement utilisé pour tuer le processus. kill PID # 杀死指定的进程ID
Avis,kill La commande est envoyée par défautSIGTERM Signal, qui peut être utilisé si le processus ne répond pas-9utiliserSIGKILL Signal tue avec force le processus :
kill -9 PID # 强制杀死进程
SIGTERMLe signal (Signal Termination) est un signal standard utilisé dans les systèmes d'exploitation Unix et de type Unix pour demander la fin du processus. Ce signal est généralement envoyé lorsque le système ou l'utilisateur souhaite arrêter correctement un processus.etSIGKILLLes signaux sont différents,SIGTERMLes signaux peuvent être capturés et traités par un processus, permettant au processus de nettoyer avant de quitter. (depuis Internet)
Ce qui suit est nvidia-smi Quelques utilisations de base des commandes :
nvidia-smi
nvidia-smi -l 1
Cette commande mettra à jour les informations d'état toutes les 1 secondes.
nvidia-smi -h
nvidia-smi pmon
nvidia-smi --id=0 --ex_pid=12345
Cela mettra fin de force au processus avec le PID 12345 sur l'ID GPU 0.
nvidia-smi -pm 1
nvidia-smi -i 0 -pm 1
La première commande définira tous les GPU en mode performance, la deuxième commande cible uniquement le GPU avec l'ID 0.
nvidia-smi --id=0 -r
Cela redémarrera le GPU avec l'ID 0.
nvidia-smi -h
Ce qui suit est une introduction aux informations sur le GPU à travers une image :
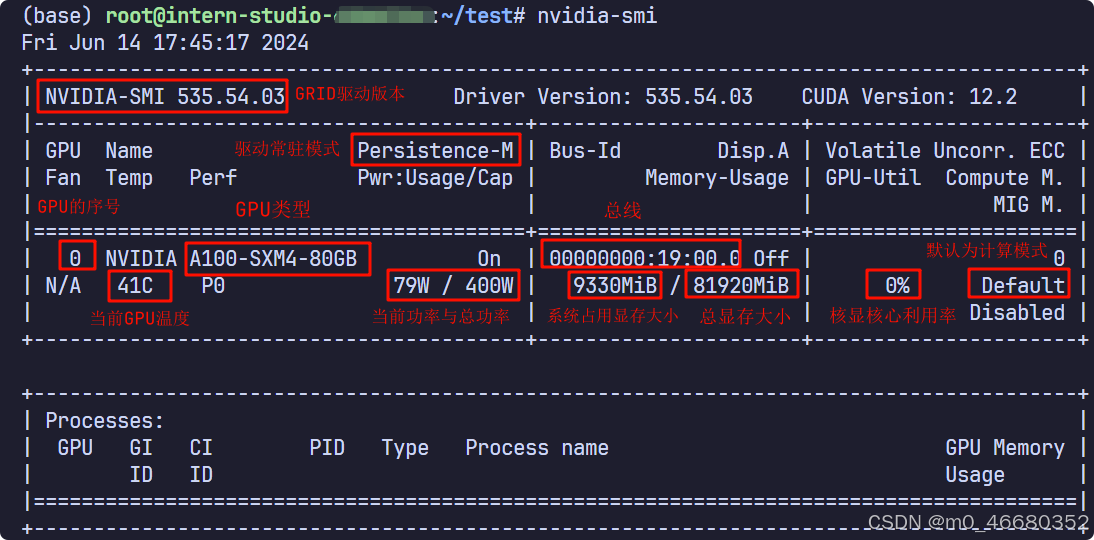
Voici un outilTMUX,TMUX est un multiplexeur de terminaux. Cela permet de basculer facilement entre plusieurs terminaux, de les détacher (cela ne tue pas les terminaux, ils continuent de fonctionner en arrière-plan) et de les reconnecter à d'autres terminaux. Pourquoi introduire cet outil ?Parce que ce sera fait plus tardXtunerLors du réglage fin du modèle, cela prendra beaucoup de temps.TmuxCela peut résoudre la situation dans laquelle le programme est arrêté et interrompu. Voici comment l'installer et l'utiliser.
Étant donné que la machine de développement utilise le système d'exploitation Ubuntu, vous pouvez utiliserlsb_release -a Commande pour afficher les informations du système Ubuntu :
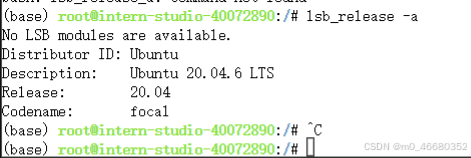
puis utilisezapt install tmuxCommande pour installer tmux. Vous pouvez l'utiliser une fois l'installation terminée.tmuxVous pouvez utiliser tmux avec la commande Si vous souhaitez quitter tmux, vous pouvez utiliser ".Ctrl+d"touche de raccourci.
Sur la machine de développement, seuls les fichiers sous le chemin /root sont stockés de manière persistante. Les logiciels installés sous d'autres chemins seront réinitialisés après le redémarrage.
Les méthodes d'utilisation spécifiques peuvent être consultées sur :
https://www.ruanyifeng.com/blog/2019/10/tmux.html
Conda est un système open source de gestion de packages et de gestion d'environnement qui fonctionne sous Windows, macOS et Linux. Il installe, exécute et met à jour rapidement les progiciels et leurs dépendances. En utilisant Conda, vous pouvez facilement créer, enregistrer, charger et changer différents environnements sur votre machine locale.
Déjà installé sur la machine de développementconda, nous pouvons l'utiliser directement, et il y en a aussi un intégré dans la machine de développementcondaCommandestudio-conda, nous présenterons ci-dessouscondaUtilisation de base de, etstudio-condaComment utiliser et présenterstudio-condaComment est-il réalisé.
Nous le présenterons dans les parties suivantes :
on peut utiliserconda --versionpour voir la machine de développement actuellecondainformation sur la version:

quand on veut utilisercondaL'installation du package sera très lente. Nous pouvons définir la mise en miroir domestique pour améliorer la vitesse d'installation. L'exemple est le suivant :
#设置清华镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
Mais nous utilisons habituellementpipInstallation du package, nous le présenterons plus tardpipetcondadifférence.
Si nous voulons afficher les informations de configuration de conda, nous pouvons utiliserconda config --showcommande, si c'est le paramètre par défaut de la machine de développement, elle renverra : (une partie de l'information)

Ces configurations sont enCondaLa configuration de l'environnement affectera les méthodes et les résultats de l'installation des progiciels, des mises à jour, de la gestion de l'environnement et d'autres opérations.
Cette partie estconda中非常重要的一部分,掌握了这一部分大家就可以将开发环境玩转到飞起了😀。
on peut utiliserconda create -n name python``=3.10 Créez un environnement virtuel, ce qui signifie qu'un environnement virtuel avec la version 3.10 et le nom de Python est créé.Après la création, vous pouvez.condasous le répertoireenvsTrouvé dans l'annuaire.
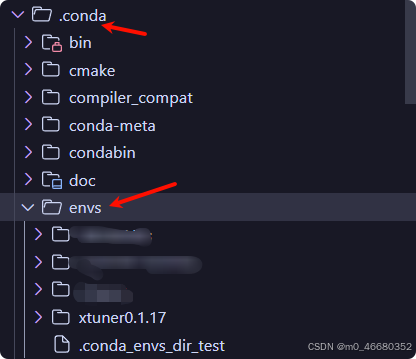
Lorsque la version de Python n'est pas spécifiée, un environnement virtuel basé sur la dernière version de Python sera automatiquement créé. En parallèle, nous pouvons installer les packages nécessaires lors de la création de l'environnement virtuel :conda create -n name numpy matplotlib python=3.10(Mais je ne vous recommande pas de l'utiliser de cette façon)
Les paramètres courants pour créer un environnement virtuel sont les suivants :
Si nous voulons voir de quels environnements virtuels nous disposons, nous pouvons utiliser la commande suivante :
conda env list
conda info -e
conda info --envs
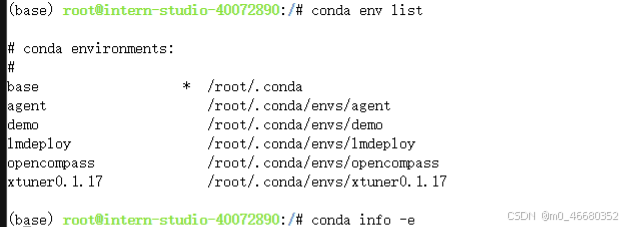
En même temps, nous pouvons également voir le répertoire où se trouve l’environnement.
Après avoir créé l'environnement virtuel, nous pouvons utiliserconda activate name commande pour activer l'environnement virtuel, comment vérifier si le changement est réussi ?C'est facile, il suffit de regarder(base)Qu'il s'agisse du nom de l'environnement virtuel créé.
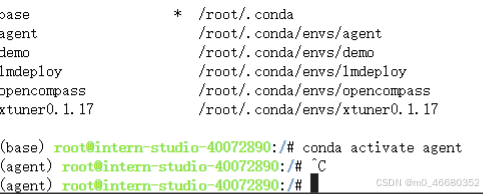
Si vous souhaitez quitter l'environnement virtuel, vous pouvez utiliser :
conda activate
conda deactivate
Les deux commandes reviendrontbasel'environnement parce quebaseC'est l'environnement de base de conda. Si vous observez attentivement,baseLe répertoire d'environnement est d'un niveau supérieur à celui des autres répertoires d'environnement virtuel.
Si vous souhaitez supprimer un environnement virtuel, vous pouvez utiliserconda remove --name name --all, si vous supprimez uniquement un ou plusieurs packages dans l'environnement virtuel, vous pouvez utiliserconda remove --name name package_name
L'exportation d'un environnement virtuel est très nécessaire pour un environnement spécifique, car les dépendances de certains progiciels sont très complexes, et il sera difficile de le recréer et de le configurer vous-même. Si nous exportons l'environnement configuré, nous pourrons le restaurer la prochaine fois. et vous pouvez également partager la configuration avec d'autres.
#获得环境中的所有配置
conda env export --name myenv > myenv.yml
#重新还原环境
conda env create -f myenv.yml
Par exemple nous allonsxtuner0.1.17L'environnement virtuel est exporté et les informations de configuration sont les suivantes :
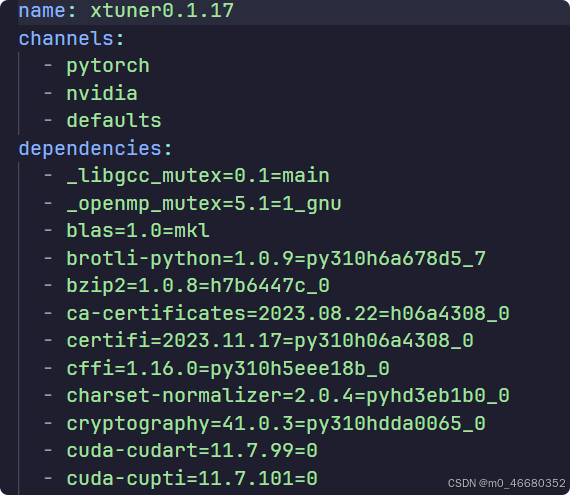
Ceux-ci inclusnom de l'environnement、L'emplacement du référentiel en ligne pour les packages d'environnement virtueletDépendances de l'environnement virtuel . Plus tard, nous utiliserons des méthodes d'utilisation avancées pour restaurer rapidement l'environnement virtuel.
Dans cette partie, nous présentons quelquescondaetpipQuelques différences :
Roue Il s'agit d'un format de package d'installation Python.
Il s'agit d'un format de distribution binaire précompilé, similaire aux binaires compilés dans conda.
Les principaux avantages du format Wheel sont les suivants :
- Installation rapide : comme il a été précompilé, il n'est pas nécessaire de passer par le processus de compilation comme l'installation du code source lors de l'installation, ce qui permet de gagner du temps.
- Cohérence : garantit que les résultats de l'installation sont cohérents sur les différents systèmes et environnements.
Par exemple, si vous souhaitez installer une grande bibliothèque Python, l'utilisation du format Wheel peut éviter les problèmes d'installation causés par les différences d'environnements de compilation sur différentes machines. De plus, pour les systèmes qui ne disposent pas d'environnement de compilation ou qui ont de faibles capacités de compilation, le format Wheel peut rendre le processus d'installation plus fluide.
Cette partie est une partie étendue, car je pense que cette partie est très intéressante et très pratique, donc si vous êtes intéressé, vous pouvez l'apprendre.
Présentons d'abordstudio-conda , qui est une commande intégrée de la machine de développement et est implémentée via un script Shell. Qu’est-ce qu’un script Shell ?
Script shell Fichier texte contenant une série de commandes disposées dans un ordre spécifique pour automatiser les tâches dans un environnement Unix/Linux ou un système d'exploitation similaire.
Les scripts Shell sont généralement écrits dans le langage Shell. Les langages Shell courants tels que Bash, Sh, etc. sont les commandes Linux de base que nous avons présentées précédemment et qui appartiennent au langage Shell.
Il présente les caractéristiques importantes suivantes :
Questudio-condaCela fait partie de l'automatisation. Le fichier de configuration de l'environnement bash de l'utilisateur root dans notre machine de développement est..bashrc, mais en fait le fichier de configuration principal est/share/.aide/config/bashrc, certaines commandes écrites dans ce fichier nous permettent d'effectuer certaines opérations plus rapidement, telles que :
export no_proxy='localhost,127.0.0.1,0.0.0.0,172.18.47.140'
export PATH=/root/.local/bin:$PATH
export HF_ENDPOINT='https://hf-mirror.com'
alias studio-conda="/share/install_conda_env.sh"
alias studio-smi="/share/studio-smi"
exportest utilisé pour définir des variables d'environnement.aliasconsiste à copier un fichier sh dans une variable. Cela peut être exécuté dans le terminal sous forme de commande.studio-condaC'est ça.
icistudio-smiIl est utilisé pour vérifier l'utilisation de la mémoire virtuelle lors de l'ouverture./share/studio-smiLe fichier peut être consulté :
#!/bin/bash
if command -v vgpu-smi &> /dev/null
then
echo "Running studio-smi by vgpu-smi"
vgpu-smi
else
echo "Running studio-smi by nvidia-smi"
nvidia-smi
fi
Ce script est utilisé pour vérifier s'il existe un vgpu-smi commande, si présente, elle sera exécutéevgpu-smi pour afficher les informations d'état d'un GPU virtuel (vGPU) s'il n'est pas présent, il s'exécuteranvidia-smi pour afficher les informations sur l'état du GPU NVIDIA. Comme indiqué ci-dessous:
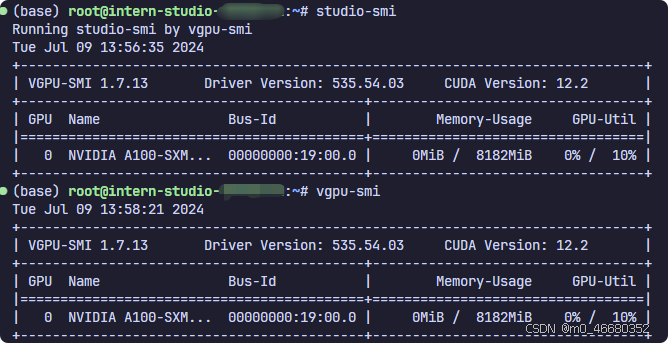
nvidia-smi est un outil de surveillance et de gestion des périphériques GPU NVIDIA physiques, etvgpu-smi Conçu pour surveiller et gérer les ressources GPU virtualisées via la technologie NVIDIA vGPU.
nous voyons/share/install_conda_env.shLe contenu du fichier est le suivant :
#!/bin/bash
# clone internlm-base conda env to user's conda env
# created by xj on 01.07.2024
# modifed by xj on 01.19.2024 to fix bug of conda env clone
# modified by ljy on 01.26.2024 to extend
XTUNER_UPDATE_DATE=`cat /share/repos/UPDATE | grep xtuner |awk -F= '{print $2}'`
HOME_DIR=/root
CONDA_HOME=$HOME_DIR/.conda
SHARE_CONDA_HOME=/share/conda_envs
SHARE_HOME=/share
list() {
cat <<-EOF
预设环境 描述
internlm-base pytorch:2.0.1, pytorch-cuda:11.7
xtuner Xtuner(源码安装: main $(echo -e "033[4mhttps://github.com/InternLM/xtuner/tree/main033[0m"), 更新日期:$XTUNER_UPDATE_DATE)
pytorch-2.1.2 pytorch:2.1.2, pytorch-cuda:11.8
EOF
}
help() {
cat <<-EOF
说明: 用于快速clone预设的conda环境
使用:
1. studio-conda env -l/list 打印预设的conda环境列表
2. studio-conda <target-conda-name> 快速clone: 默认拷贝internlm-base conda环境
3. studio-conda -t <target-conda-name> -o <origin-conda-name> 将预设的conda环境拷贝到指定的conda环境
EOF
}
clone() {
source=$1
target=$2
if [[ -z "$source" || -z "$target" ]]; then
echo -e "033[31m 输入不符合规范 033[0m"
help
exit 1
fi
if [ ! -d "${SHARE_CONDA_HOME}/$source" ]; then
echo -e "033[34m 指定的预设环境: $source不存在033[0m"
list
exit 1
fi
if [ -d "${CONDA_HOME}/envs/$target" ]; then
echo -e "033[34m 指定conda环境的目录: ${CONDA_HOME}/envs/$target已存在, 将清空原目录安装 033[0m"
wait_echo&
wait_pid=$!
rm -rf "${CONDA_HOME}/envs/$target"
kill $wait_pid
fi
echo -e "033[34m [1/2] 开始安装conda环境: <$target>. 033[0m"
sleep 3
tar --skip-old-files -xzvf /share/pkgs.tar.gz -C ${CONDA_HOME}
wait_echo&
wait_pid=$!
conda create -n $target --clone ${SHARE_CONDA_HOME}/${source}
if [ $? -ne 0 ]; then
echo -e "033[31m 初始化conda环境: ${target}失败 033[0m"
exit 10
fi
kill $wait_pid
# for xtuner, re-install dependencies
case "$source" in
xtuner)
source_install_xtuner $target
;;
esac
echo -e "033[34m [2/2] 同步当前conda环境至jupyterlab kernel 033[0m"
lab add $target
source $CONDA_HOME/bin/activate $target
cd $HOME_DIR
echo -e "033[32m conda环境: $target安装成功! 033[0m"
echo """
============================================
ALL DONE!
============================================
"""
}
······
dispatch $@
l'un d'eux*list*()Attends, c'est toutstudio-condafonction, qui peut implémenter certaines opérations, par exemple, nous pouvons utiliserstudio-conda env listPour afficher l'environnement par défaut :

dans*clone*()La fonction principale de la fonction est de copier l'environnement, mais elle ne peut être copiée qu'à partir de l'environnement par défaut. Le code principal est en fait :
tar --skip-old-files -xzvf /share/pkgs.tar.gz -C ${CONDA_HOME}
conda create -n $target --clone ${SHARE_CONDA_HOME}/${source}
Décompressez le package compressé de l'environnement prédéfini, puis créez un environnement virtuel via le clonage. Cependant, une certaine logique est également définie dans le script Shell, mais ce n'est qu'un jugement. Si vous êtes familier avec un langage de programmation, vous devriez pouvoir. pour le comprendre. Si vous ne pouvez pas le comprendre, ce n'est pas non plus un gros problème.
Alors, comment pouvons-nous ajouter notre propre environnement créé àstudio-condaEt le milieu ?
La première étape consiste à créer un nouvel environnement conda sous /share/conda_envs
conda create -p /share/conda_envs/xxx python=3.1x
La deuxième étape consiste à copier les fichiers sous /root/.conda/pkgs sur la machine locale vers /share/pkgs, à les recompresser et à les remplacer (cette étape consiste à stocker les grands packages publics pendant le processus de création de conda pour éviter les téléchargements répétés).
cp -r -n /root/.conda/pkgs/* /share/pkgs/
cd /share && tar -zcvf paquets.tar.gz paquets
La troisième étape consiste à mettre à jour la fonction de liste dans install_conda_env.sh et à ajouter une nouvelle description de l'environnement conda.
Ce qui précède est la méthode fournie par défaut par la machine de développement. En fait, il existe une autre méthode, que nous avons utilisée précédemment.condaExportéxtuner0.1.17Fichiers de configuration pour les environnements virtuels, nous pouvons utiliserconda env create -f xtuner0.1.17.yml commande pour restaurer l’environnement virtuel.Écrivons un script Shell simple pour implémenter cette opération : Nous créonstest.shfichier, écrivez le contenu suivant :
#!/bin/bash
# 定义导出环境的函数
export_env() {
local env_name=$1
echo "正在导出环境: $env_name"
# 导出环境到当前目录下的env_name.yml文件
conda env export -n "$env_name" > "$env_name.yml"
echo "环境导出完成。"
}
# 定义还原环境的函数
restore_env() {
local env_name=$1
echo "正在还原环境: $env_name"
# 从当前目录下的env_name.yml文件还原环境
conda env create -n "$env_name" -f "$env_name.yml"
echo "环境还原完成。"
}
# 检查是否有足够的参数
if [ $# -ne 2 ]; then
echo "使用方法: $0 <操作> <环境名>"
echo "操作可以是 'export' 或 'restore'"
exit 1
fi
# 根据参数执行操作
case "$1" in
export)
export_env "$2"
;;
restore)
restore_env "$2"
;;
*)
echo "未知操作: $1"
exit 1
;;
esac
Une fois la création du script Shell terminée, nous devons accorder des autorisations au script. Vous pouvez utiliser la commande :chmod +x test.sh , puis entrez./test.sh restore xtuner0.1.17Et appuyez sur Entrée pour restaurer l'environnement virtuel.
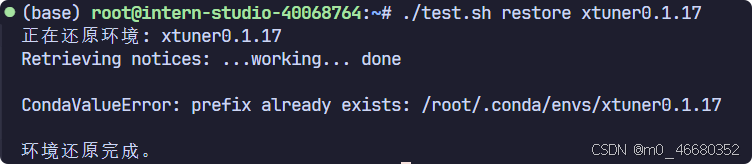
Cependant, ce n'est pas très différent de l'utilisation directe. Si l'on compare cette opération à l'opération dans la machine de développement,studio-conda Combiner les commandes sera très pratique, mais les méthodes de copie de l'environnement sont différentes.Par conséquent, si vous souhaitez le mettre en œuvre, vous devez/share/install_conda_env.shLa logique du fichier est modifiée.
D'accord, c'est tout le contenu de ce niveau. J'espère que le contenu ci-dessus sera utile à tout le monde à l'avenir. Si vous souhaitez en savoir plus sur Linux, vous pouvez lire mon article de blog, même si je ne sais pas comment utiliser Linux. , cela nous sera utile d'apprendre. Les grands modèles n'ont pas beaucoup d'impact, mais si vous apprenez bien Linux, cela rendra votre apprentissage des grands modèles très fluide. Enfin, n’oubliez pas de terminer les niveaux que nous avons fixés plus tôt !
Lien du blog :Linux
Exécutez avec soin ! ! ! !Toutes les données seront perdues. Ceci n'est disponible que sur la plateforme InternStudio. Ne faites pas cela sur votre propre machine.
rm -rf /root, il faudra environ 10 minutes d'attenteln -s /share /root/sharePour réussir la mission de niveau, vous devez prendre des captures d'écran par étapes clés :
| détails de la mission | Temps nécessaire pour terminer | |
|---|---|---|
| Mission | Terminez la connexion SSH et le mappage des ports et exécutezhello_world.py | 10 minutes |
| Tâche facultative 1 | Complétez les commandes Linux de base sur la machine de développement | 10 minutes |
| Tâche facultative 2 | Utilisez VSCODE pour vous connecter à distance à la machine de développement et créer un environnement conda | 10 minutes |
| Tâche facultative 3 | Créer et exécutertest.shdocument | 10 minutes |

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.


