2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Les deux premiers articles ont présenté ce qu'est Flow, comment l'utiliser et les avancées des opérateurs associées. L'article suivant présente principalement l'utilisation de Flow dans des projets réels.
Avant de présenter les scénarios d'application réels de Flow, passons d'abord en revue l'exemple de minuterie introduit dans le premier article de Flow. Nous avons défini un flux de données timeFlow dans ViewModel :
class MainViewModel : ViewModel() {
val timeFlow = flow {
var time = 0
while (true) {
emit(time)
delay(1000)
time++
}
}
Puis dans l'Activité, recevez le flux de données défini précédemment.
lifecycleOwner.lifecycleScope.launch {
viewModel.timeFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
Laissez-moi l'exécuter pour voir l'effet réel :
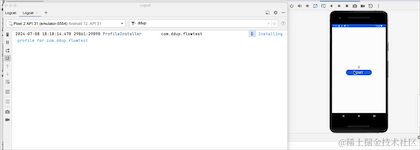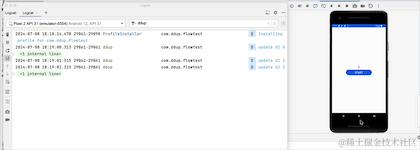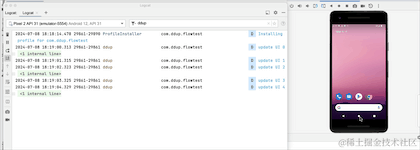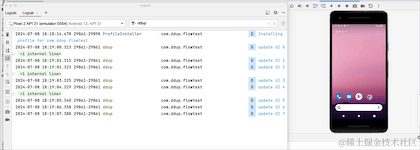
Avez-vous remarqué que lorsque l'application passe en arrière-plan, le journal s'imprime toujours. Ce n'est pas un gaspillage de ressources. Modifions le code de réception :
lifecycleOwner.lifecycleScope.launchWhenStarted {
viewModel.timeFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
Modifions la méthode de démarrage de la coroutine du lancement à launchWhenStarted, et exécutons-la à nouveau pour voir l'effet :
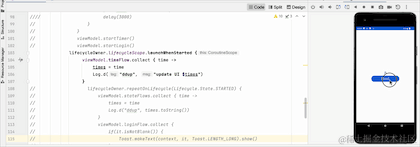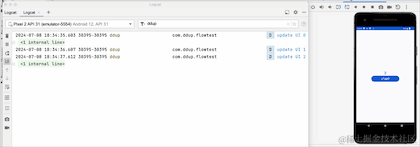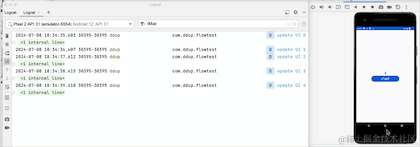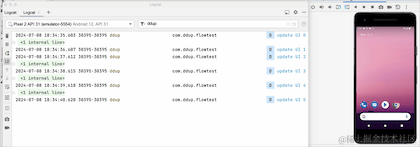
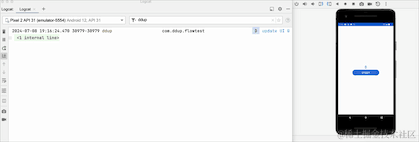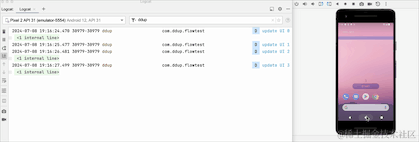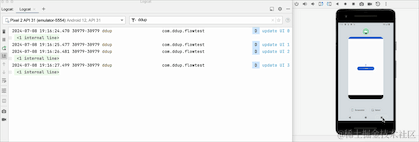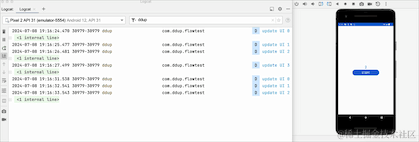
On voit que lorsque l'on clique sur le bouton HOME et qu'on revient en arrière-plan, le journal n'est plus imprimé. On voit que le changement a pris effet, mais le flux a-t-il été annulé. Revenons à la réception pour le prendre ? un regard:
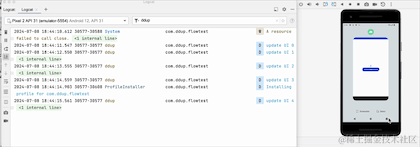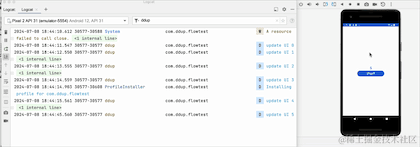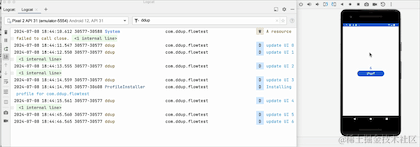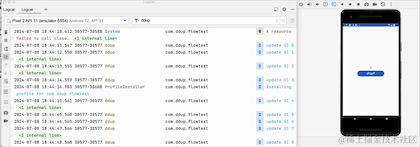
En passant au premier plan, nous pouvons voir que le compteur ne démarre pas à 0, donc en fait il n'annule pas la réception, il met simplement en pause la réception des données en arrière-plan. Le pipeline Flow conserve toujours les données précédentes. L'API a été abandonnée. Google RepeatOnLifecycle est plutôt recommandé et n'a pas le problème de conserver les anciennes données dans le pipeline.
Essayons de transformer le code correspondant :
lifecycleOwner.lifecycleScope.launch {
lifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.timeFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
}
Réexécutez pour voir l'effet :
On peut voir que lors du passage de l'arrière-plan au premier plan, les données repartent de 0, ce qui signifie que lors du passage à l'arrière-plan, Flow annule le travail et toutes les données d'origine sont effacées.
Nous utilisons Flow et grâce à RepeatOnLifecycle, nous pouvons mieux garantir la sécurité de notre programme.
Les introductions précédentes sont toutes des exemples de flux froid. Ensuite, nous présenterons quelques scénarios d'application courants du flux chaud.
Toujours en utilisant l'exemple de minuterie précédent, que se passera-t-il si l'écran passe d'un écran horizontal à un écran vertical ?
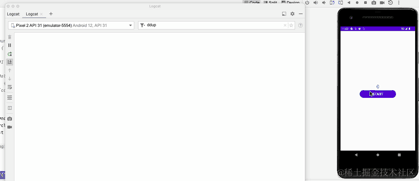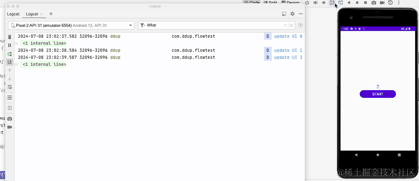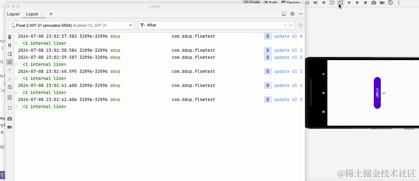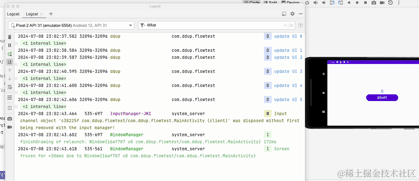
Nous pouvons voir qu'après avoir basculé entre les écrans horizontaux et verticaux, l'activité est recréée. Après la recréation, timeFlow sera à nouveau collecté, le flux froid sera à nouveau collecté et réexécuté, puis le minuteur démarrera. en comptant à partir de 0. Plusieurs fois, nous souhaitons basculer entre les écrans horizontaux et verticaux. À ce stade, nous espérons que l'état de la page restera inchangé, au moins dans un certain laps de temps. Ici, nous modifions le flux froid en un. flux chaud et essayez :
val hotFlow =
timeFlow.stateIn(
viewModelScope,
SharingStarted.WhileSubscribed(5000),
0
)
```
lifecycleOwner.lifecycleScope.launch {
lifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.hotFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
}
```
Ici, nous nous concentrons sur les trois paramètres de stateIn. Le premier est la portée de la coroutine, le second est le temps effectif maximum nécessaire au flux pour maintenir son état de fonctionnement. S'il dépasse le flux, il cessera de fonctionner. Le paramètre est la valeur initiale.
Réexécutez pour voir l'effet :
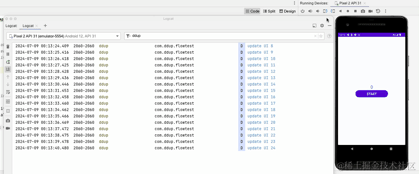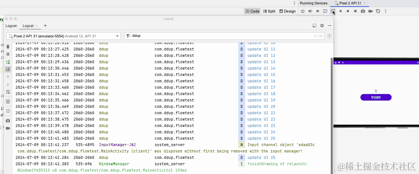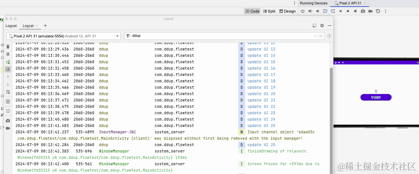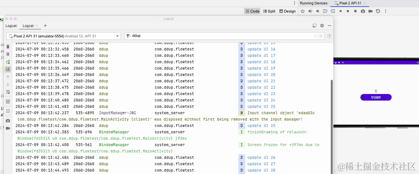
Ici, nous pouvons voir le journal imprimé après avoir basculé entre les écrans horizontaux et verticaux. La minuterie ne démarrera pas à 0.
Nous avons présenté ci-dessus comment modifier un flux froid en flux chaud. Nous n'avons pas encore présenté comment stateFlow peut remplacer LiveData. Voici une introduction à la façon dont stateFlow remplace LiveData :
private val _stateFlow = MutableStateFlow(0)
val stateFlow = _stateFlow.asStateFlow()
fun startTimer() {
val timer = Timer()
timer.scheduleAtFixedRate(object :TimerTask() {
override fun run() {
_stateFlow.value += 1
}
},0,1000)
}
```
viewModel.startTimer()
lifecycleOwner.lifecycleScope.launch {
lifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.stateFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
}
```
Nous définissons un flux chaud StateFlow, puis modifions la valeur stateFlow via une méthode startTimer(), similaire à LiveData setData. Lorsque vous cliquez sur le bouton, commencez à modifier la valeur StateFlow et collectez les valeurs du flux correspondant, similaire au. Méthode LiveData Observe pour surveiller les modifications des données.
Jetons un coup d'œil à l'effet réel de la course :
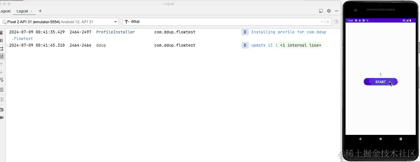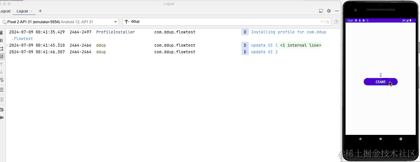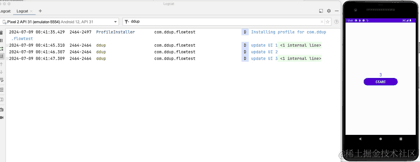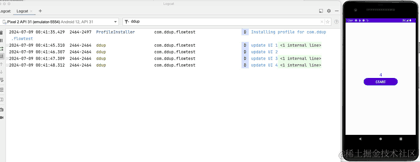
À ce stade, nous avons présenté l'utilisation de base de StateFlow, et nous allons maintenant présenter SharedFlow.
Pour comprendre SharedFlow, nous connaissons d'abord le concept d'événements persistants. Littéralement, lorsqu'un observateur s'abonne à une source de données, si la source de données contient déjà les dernières données, alors les données seront immédiatement transmises à l'observateur. À en juger par l'explication ci-dessus, LiveData est conforme à cette caractéristique collante. Qu'en est-il de StateFlow ? Écrivons une démo simple pour vérifier :
class MainViewModel : ViewModel() {
private val _clickCountFlow = MutableStateFlow(0)
val clickCountFlow = _clickCountFlow.asStateFlow()
fun increaseClickCount() {
_clickCountFlow.value += 1
}
}
//MainActivity
```
val tv = findViewById<TextView>(R.id.tv_content)
val btn = findViewById<Button>(R.id.btn)
btn.setOnClickListener {
viewModel.increaseClickCount()
}
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.clickCountFlow.collect { time ->
tv.text = time.toString()
Log.d("ddup", "update UI $time")
}
}
}
```
Nous définissons d'abord un clickCountFlow dans le MainViewModel, puis dans l'activité, modifions les données clickCountFlow en cliquant sur le bouton, puis recevons le clickCountFlow et affichons les données sur le texte.
Jetons un coup d'œil à l'effet de course :
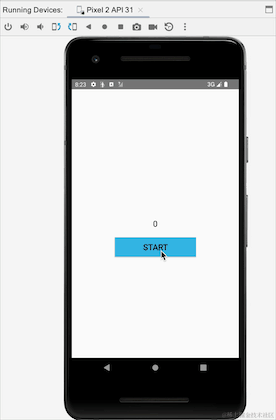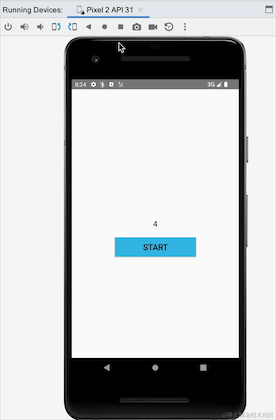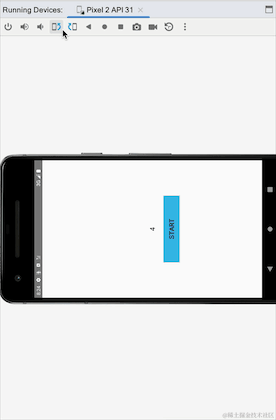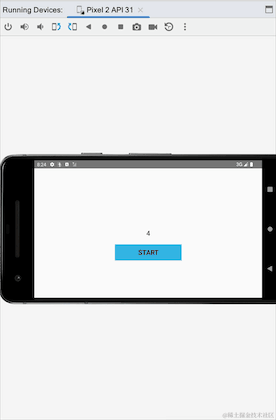
Nous pouvons voir que lors du basculement entre les écrans horizontaux et verticaux, l'activité est recréée et clickCountFlow est recollecté. Les données commencent toujours à partir des 4 précédentes, indiquant que StateFlow est collant. Il ne semble y avoir aucun problème ici, mais allons-y. Regardez un autre exemple. Nous simulons un scénario de clic pour vous connecter, cliquez sur le bouton de connexion pour vous connecter et connectez-vous :
//MainViewModel
private val _loginFlow = MutableStateFlow("")
val loginFlow = _loginFlow.asStateFlow()
fun startLogin() {
// Handle login logic here.
_loginFlow.value = "Login Success"
}
//MainActivity
```
val tv = findViewById<TextView>(R.id.tv_content)
val btn = findViewById<Button>(R.id.btn)
btn.setOnClickListener {
viewModel.startLogin()
}
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.loginFlow.collect {
if (it.isNotBlank()) {
Toast.makeText(this@MainActivity2, it, Toast.LENGTH_LONG).show()
}
}
}
}
```
Le code ci-dessus simule en fait une connexion par clic, puis indique que la connexion est réussie. Jetons un coup d'œil à l'effet réel de l'opération :
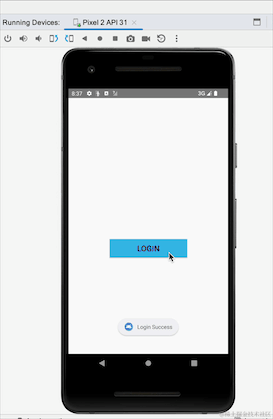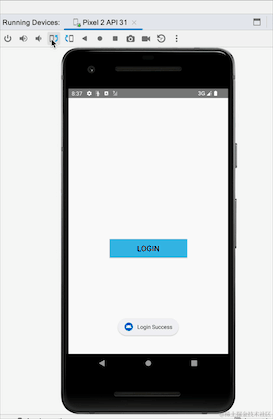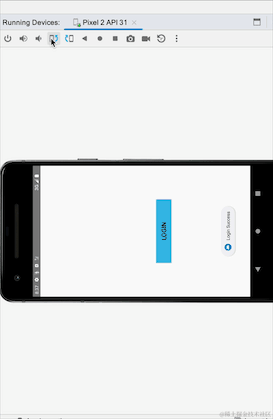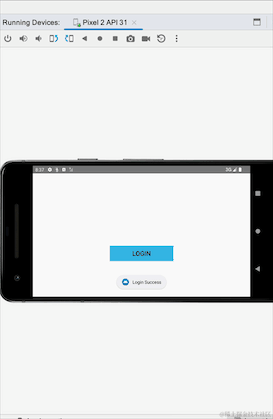
Avez-vous remarqué qu'après avoir basculé entre les écrans horizontaux et verticaux, l'invite de connexion réussie réapparaît ? Nous n'avons pas suivi le processus de reconnexion. Il s'agit du problème de réception répétée de données causée par des événements persistants. SharedFlow et essayez-le :
private val _loginFlow = MutableSharedFlow<String>()
val loginFlow = _loginFlow.asSharedFlow()
fun startLogin() {
// Handle login logic here.
viewModelScope.launch {
_loginFlow.emit("Login Success")
}
}
Nous avons changé StateFlow en SharedFlow. Nous pouvons voir que SharedFlow ne nécessite pas de valeur initiale. La méthode d'émission est ajoutée au lieu de connexion pour envoyer les données, et l'endroit où les données sont reçues reste inchangé.
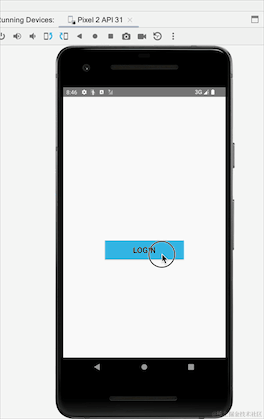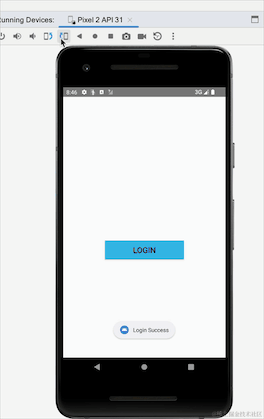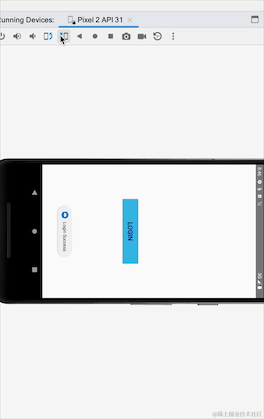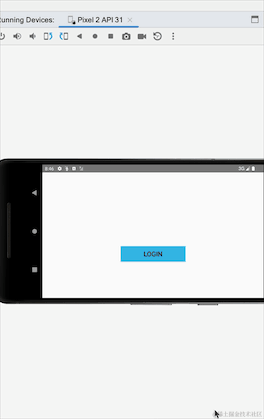
Ici, nous pouvons voir que l'utilisation de SharedFlow ne provoquera pas ce problème de rigidité. En fait, SharedFlow a de nombreux paramètres qui peuvent être configurés :
public fun <T> MutableSharedFlow(
// 每个新的订阅者订阅时收到的回放的数目,默认0
replay: Int = 0,
// 除了replay数目之外,缓存的容量,默认0
extraBufferCapacity: Int = 0,
// 缓存区溢出时的策略,默认为挂起。只有当至少有一个订阅者时,onBufferOverflow才会生效。当无订阅者时,只有最近replay数目的值会保存,并且onBufferOverflow无效。
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
)
Il existe d’autres utilisations de SharedFlow qui attendent que tout le monde les découvre, mais je n’entrerai pas dans les détails ici.
Auparavant, nous avons présenté le flux froid de base au flux chaud, ainsi que l'utilisation courante et les scénarios applicables de StateFlow et SharedFlow. Ensuite, nous nous concentrerons sur plusieurs exemples pratiques pour examiner d'autres scénarios d'application courants de flux.
Nous effectuons généralement une logique complexe et fastidieuse, la traitons dans un sous-thread, puis passons au thread principal pour afficher l'interface utilisateur. Flow prend également en charge la commutation de thread, et flowOn peut placer les opérations précédentes dans le sous-thread correspondant pour le traitement. .
Nous implémentons une lecture localeAssetssous le répertoireperson.jsonfichier et analysez-le,jsonContenu du dossier :
{
"name": "ddup",
"age": 101,
"interest": "earn money..."
}
Analysez ensuite le fichier :
fun getAssetJsonInfo(context: Context, fileName: String): String {
val strBuilder = StringBuilder()
var input: InputStream? = null
var inputReader: InputStreamReader? = null
var reader: BufferedReader? = null
try {
input = context.assets.open(fileName, AssetManager.ACCESS_BUFFER)
inputReader = InputStreamReader(input, StandardCharsets.UTF_8)
reader = BufferedReader(inputReader)
var line: String?
while ((reader.readLine().also { line = it }) != null) {
strBuilder.append(line)
}
} catch (ex: Exception) {
ex.printStackTrace()
} finally {
try {
input?.close()
inputReader?.close()
reader?.close()
} catch (e: IOException) {
e.printStackTrace()
}
}
return strBuilder.toString()
}
Flow lit les fichiers :
/**
* 通过Flow方式,获取本地文件
*/
private fun getFileInfo() {
lifecycleScope.launch {
flow {
//解析本地json文件,并生成对应字符串
val configStr = getAssetJsonInfo(this@MainActivity2, "person.json")
//最后将得到的实体类发送到下游
emit(configStr)
}
.map { json ->
Gson().fromJson(json, PersonModel::class.java) //通过Gson将字符串转为实体类
}
.flowOn(Dispatchers.IO) //在flowOn之上的所有操作都是在IO线程中进行的
.onStart { Log.d("ddup", "onStart") }
.filterNotNull()
.onCompletion { Log.d("ddup", "onCompletion") }
.catch { ex -> Log.d("ddup", "catch:${ex.message}") }
.collect {
Log.d("ddup", "collect parse result:$it")
}
}
}
Journal d'impression final :
2024-07-09 22:00:34.006 12251-12251 ddup com.ddup.flowtest D onStart 2024-07-09 22:00:34.018 12251-12251 ddup com.ddup.flowtest D collect parse result:PersonModel(name=ddup, age=101, interest=earn money...) 2024-07-09 22:00:34.019 12251-12251 ddup com.ddup.flowtest D onCompletion
Nous rencontrons souvent des requêtes d'interface qui dépendent des résultats d'une autre requête, qui sont ce que l'on appelle des requêtes imbriquées. S'il y a trop de requêtes imbriquées, un enfer de rappel se produira. Nous utilisons FLow pour implémenter une exigence similaire :
lifecycleScope.launch {
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED) {
//将两个flow串联起来 先搜索目的地,然后到达目的地
viewModel.getTokenFlows()
.flatMapConcat {
//第二个flow依赖第一个的结果
viewModel.getUserFlows(it)
}.collect {
tv.text = it ?: "error"
}
}
}
Quel est le scénario de combinaison de données de plusieurs interfaces ? Par exemple, nous demandons plusieurs interfaces, puis combinons leurs résultats pour les afficher uniformément ou les utiliser comme paramètres de requête pour une autre interface. Laissez-moi vous demander comment implémenter cela :
La première consiste à les demander un par un puis à les fusionner ;
Le deuxième type consiste à demander simultanément, puis à fusionner toutes les demandes.
Évidemment, le deuxième effet est plus efficace. Regardons le code :
//分别请求电费、水费、网费,Flow之间是并行关系
suspend fun requestElectricCost(): Flow<SpendModel> =
flow {
delay(500)
emit(SpendModel("电费", 10f, 500))
}.flowOn(Dispatchers.IO)
suspend fun requestWaterCost(): Flow<SpendModel> =
flow {
delay(1000)
emit(SpendModel("水费", 20f, 1000))
}.flowOn(Dispatchers.IO)
suspend fun requestInternetCost(): Flow<SpendModel> =
flow {
delay(2000)
emit(SpendModel("网费", 30f, 2000))
}.flowOn(Dispatchers.IO)
Tout d'abord, nous avons simulé et défini plusieurs requêtes réseau dans ViewModel, puis avons fusionné les requêtes :
lifecycleScope.launch {
val electricFlow = viewModel.requestElectricCost()
val waterFlow = viewModel.requestWaterCost()
val internetFlow = viewModel.requestInternetCost()
val builder = StringBuilder()
var totalCost = 0f
val startTime = System.currentTimeMillis()
//NOTE:注意这里可以多个zip操作符来合并Flow,且多个Flow之间是并行关系
electricFlow.zip(waterFlow) { electric, water ->
totalCost = electric.cost + water.cost
builder.append("${electric.info()},n").append("${water.info()},n")
}.zip(internetFlow) { two, internet ->
totalCost += internet.cost
two.append(internet.info()).append(",nn总花费:$totalCost")
}.collect {
tv.text = it.append(",总耗时:${System.currentTimeMillis() - startTime} ms")
Log.d(
"ddup",
"${it.append(",总耗时:${System.currentTimeMillis() - startTime} ms")}"
)
}
}
résultat de l'opération :

Nous constatons que le temps total passé est fondamentalement le même que le temps de requête le plus long.
plusieursFlowne peut pas être placé dans unlifecycleScope.launchAller à l'intérieurcollect{}, parce qu'entrercollect{}Équivalent à une boucle infinie, la ligne de code suivante ne sera jamais exécutée si vous souhaitez écrire unlifecycleScope.launch{}Entrez, vous pouvez le rallumer de l'intérieurlaunch{}La sous-coroutine est exécutée.
Exemple d'erreur :
lifecycleScope.launch {
flow1
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
flow2
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
}
Façon correcte d'écrire :
lifecycleScope.launch {
launch {
flow1
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
}
launch {
flow2
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
}
}
Depuis le cycle de vie de Flow, nous avons introduit la posture d'utilisation correcte du flux pour éviter le gaspillage de ressources, jusqu'à la conversion du flux froid ordinaire en flux chaud, jusqu'à StateFlow remplaçant LiveData et son problème d'adhérence, puis avons résolu le problème d'adhérence grâce à SharedFlow, puis aux scénarios d'application courants, et enfin aux précautions d'utilisation de Flow, couvrent essentiellement la plupart des fonctionnalités et des scénarios d'application de Flow. C'est également le dernier chapitre de l'apprentissage de Flow.
Ce n'est pas facile à créer, mais c'est difficile de l'aimerAimez, collectionnez et commentez pour encourager。
Article de référence
Programmation réactive Kotlin Flow, StateFlow et SharedFlow
Kotlin | Plusieurs scénarios d'utilisation du flux de données Flow

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

