2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Author: Fathead Fish's Fish Tank (Yin Haiwen)
Oracle ACE Pro: Database(Oracle与MySQL)
PostgreSQL ACE Partner
10 years of experience in the database industry, currently mainly engaged in database services
Certified in OCM 11g/12c/19c, MySQL 8.0 OCP, Exadata, CDP, etc.
Motianlun MVP, Moli Star of the Year, ITPUB certified expert, member of the Expert 100 Group, OCM lecturer, PolarDB open source community technical consultant, HaloDB external technical consultant, OceanBase observation group member, Qingxue Society MOP technical community (Youth Database Learning Mutual Aid Association) technical consultant
He is known as "Director", "Security Guard", "The Biggest Enemy of Domestic Databases" and other titles in the circle. He is a non-famous social terrorist.
Public account: Fathead fish’s fish tank; CSDN: Fathead fish’s fish tank (Yin Haiwen); Motianlun: Fathead fish’s fish tank; ITPUB: yhw1809.
Except for authorized reprinting and indicating the source, all other contents are "illegal" plagiarism
We have previously explained the server-related hardware such as CPU, SSD and network. In addition to the motherboard that carries the aforementioned components, there is another very important component, which is memory. Compared with general desktop-level (general home PC) memory, server memory has its own error correction function, which we also call ECC (Error Checking and Correcting) memory.
This issue will briefly explain how ECC memory works.
Memory is an important part of the computer. It is used to temporarily store the calculation data in the CPU and the data exchanged with external storage such as hard disk. It is a bridge for communication between external storage and CPU. All programs in the computer are run in the memory. As long as the computer starts running, the operating system will transfer the data to be calculated from the memory to the CPU for calculation. When the calculation is completed, the CPU will transmit the result.
The emergence of memory is mainly to make up for the huge bandwidth and latency differences between external storage and CPU built-in cache (ie L1, L2, L3). In essence, it is also an intermediate data transfer device that is larger than the CPU built-in cache but generally much smaller than the external storage. It accelerates the preparation of data from slower external storage in advance, reducing or even eliminating the CPU waiting time for obtaining data.
The main memory we use on servers now is DDR memory. We will not go into detail about what DDR is here. The mainstream memory generations are DDR4 and DDR5. In addition to general memory, there is also non-volatile memory PMEM (using Intel Optane as an example) based on the memory interface (or PCIe interface), which provides a larger data cache area with a speed close to that of memory between the memory and external storage.
Generally speaking, servers carry important business systems. There is a large amount of electromagnetic interference during the operation of electronic equipment. These electromagnetic interferences may cause bit flipping (that is, 0 and 1 are swapped) during the data interaction between memory and CPU, so that data execution will go wrong. If it is a general PC software or program running, it may even report an error or crash, but if this problem occurs in an important system, it will cause more serious consequences (after all, the bank does not want your assets to have a few more zeros for no reason, and you don’t want your assets to decrease).
Then ECC memory came into being, actively detecting data errors in the data and correcting them.
Here are two relatively primitive solutions:
That is, a piece of data is transmitted in 3 copies. If a problem occurs at any position of one copy, it can be corrected:

However, a problem also arises. Although the probability of occurrence is very low, if two copies of data have bit flips at the same position, then the data verification and error correction will have problems:

The biggest problem with using this method is the waste of IO bandwidth.
In this way, an error correction code is added to the beginning of the data, that is, an error correction code is added before each segment of data. When the number of 1s in the data is even, the error correction code is 0, and when the number is odd, the error correction code is 1.
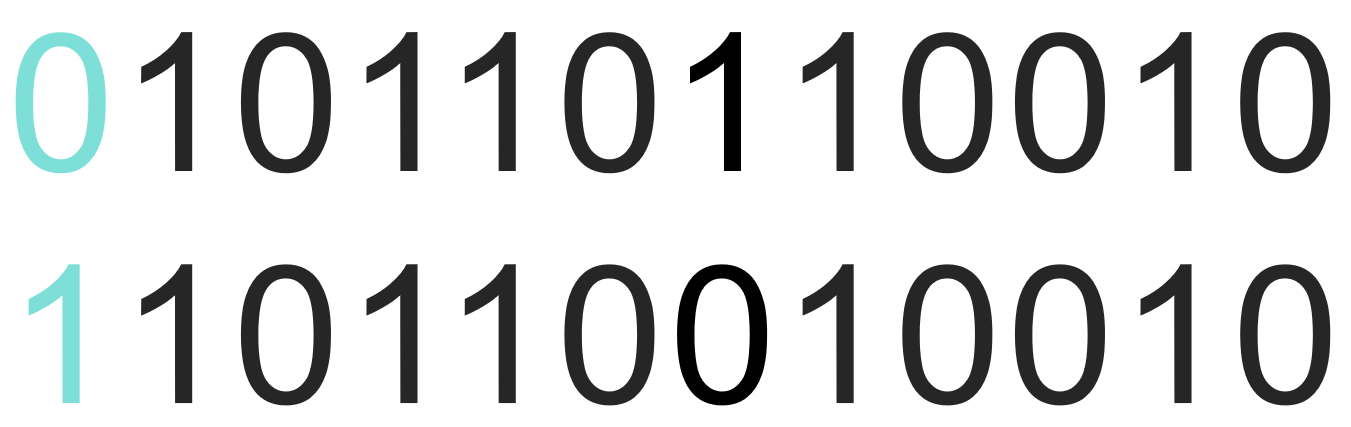
If the error correction code does not match the number of 1s, the data is retransmitted.
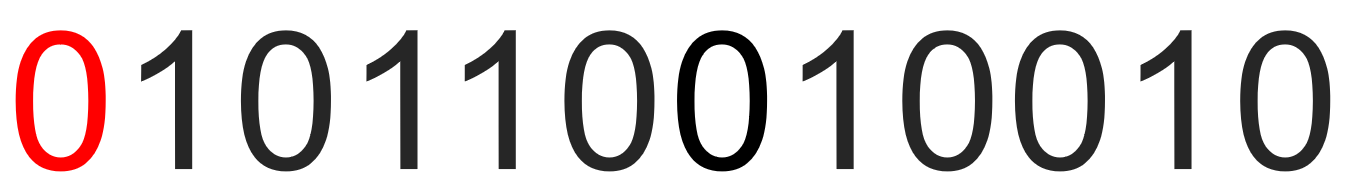
This also creates a problem. Each verification can only determine whether the entire data is normal. In theory, error correction is not achieved, and retransmission will increase delays.
At the same time, if two data errors occur at the same time, the purpose of verification cannot be achieved.
Hamming code is the main error correction method currently used in ECC memory.
Here we go step by step and arrange a 16-bit data in the following way. Assuming that bit 2 is responsible for parity check on the right part, if there are two 1s in this data, bit 2 is 0. If there is an error in the data, and the parity check determines that there is no problem in the right half, then the problem is in the left half, otherwise the problem is on the right.
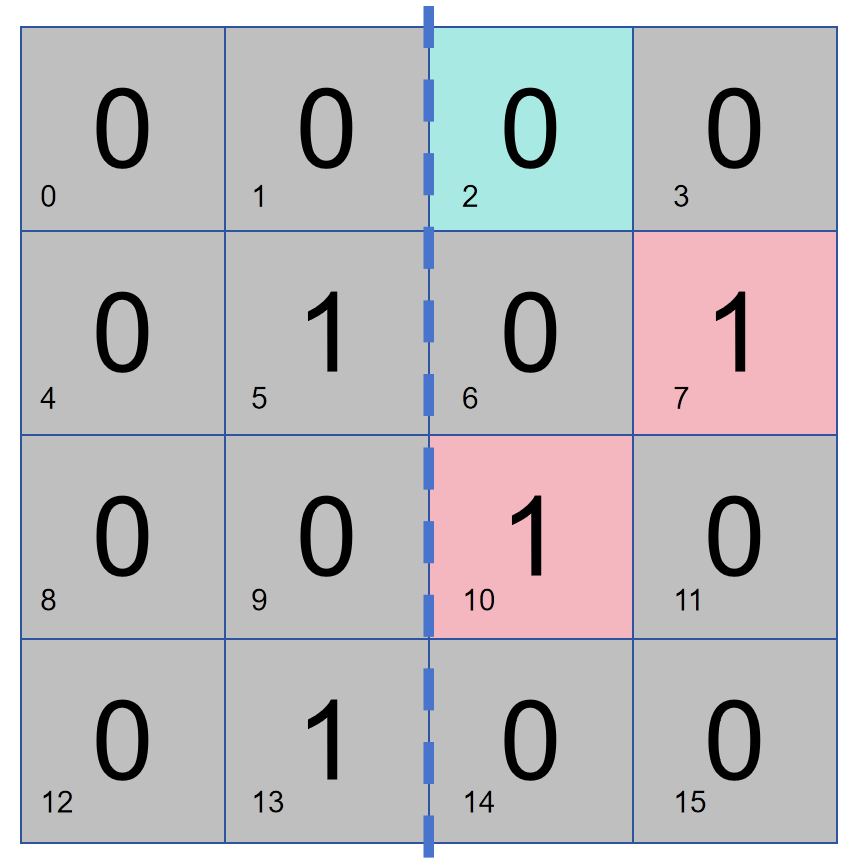
As shown in the figure below, bit 1 performs parity check on columns 2 and 4, so bit 1 stores 1. If there is a problem with the parity check of columns 2 and 4, then the problem lies in columns 2 and 4, otherwise, the problem lies in columns 1 and 3.
The above two methods can be used together to confirm that there is a problem with that column of data:
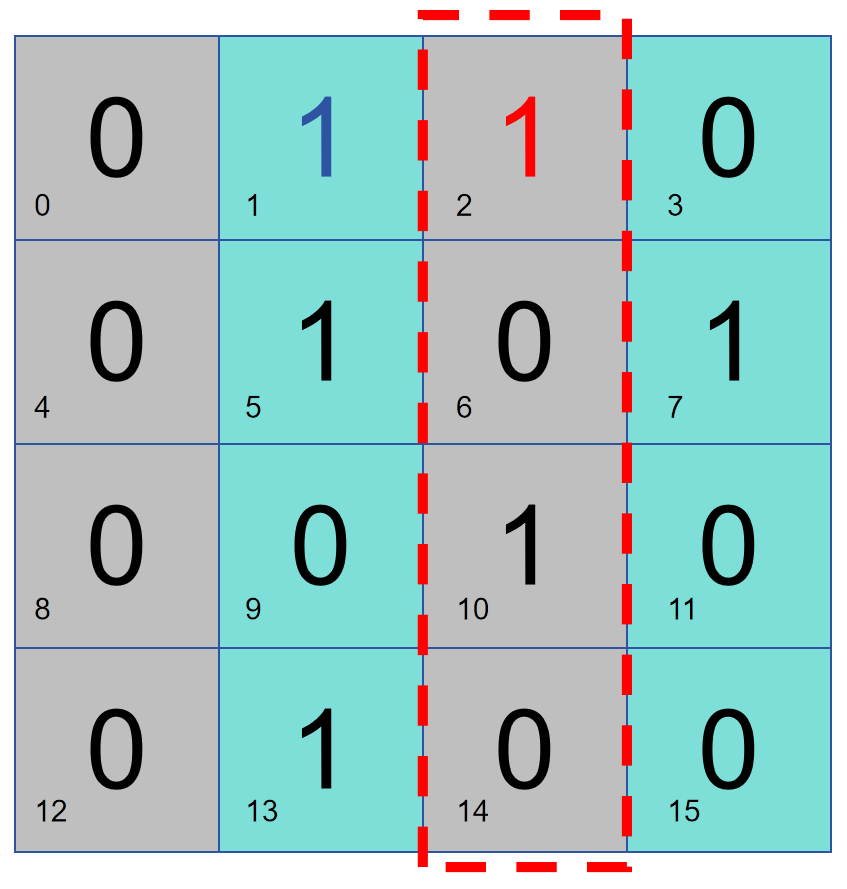
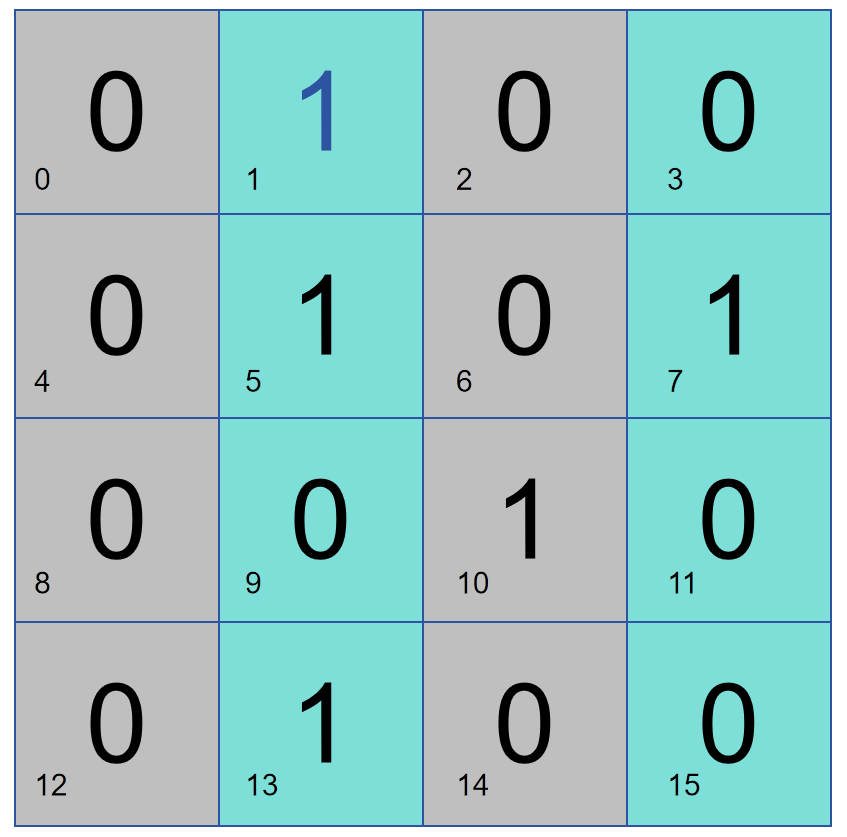
Next, use a similar method to check rows 2 and 4 with bit 4, and check the lower half of the area with bit 8. By performing row-column and partition parity checks, you can find the specific location of the error and perform error correction (flipping).
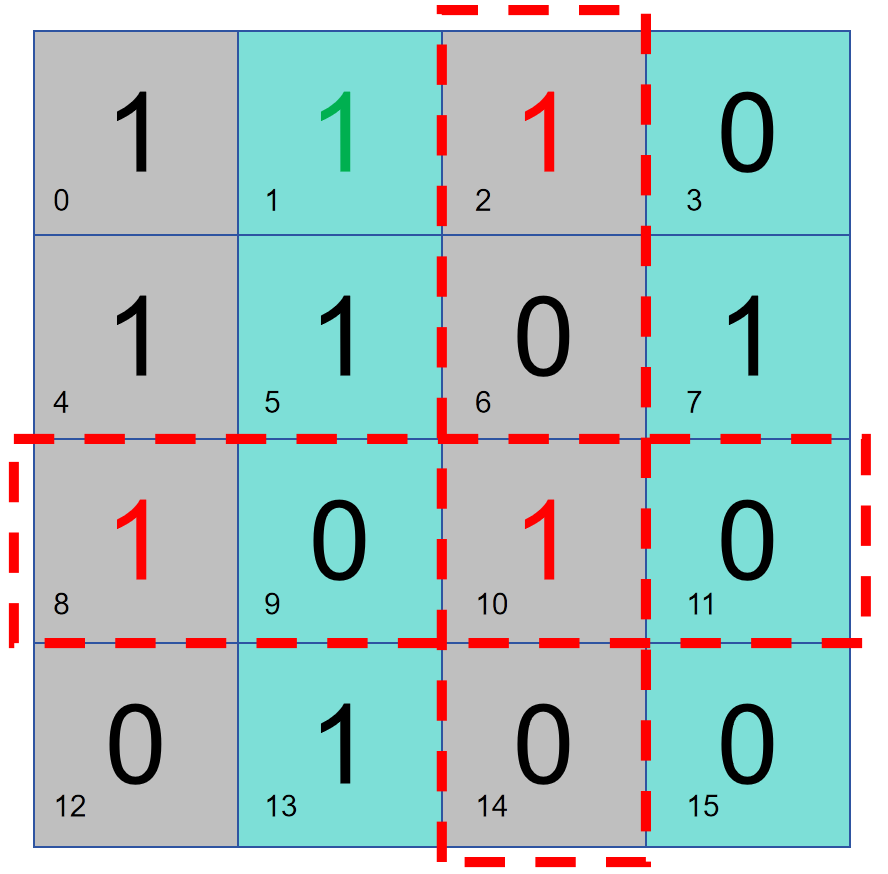
However, the above judgment is based on the assumption that there is a problem with the default data. After the above method is used, the data bit 0 is not included in the protection. Whether it is wrong or not does not affect the result of the above parity check. Therefore, we use the method in 3.2 to check the whole block of data.
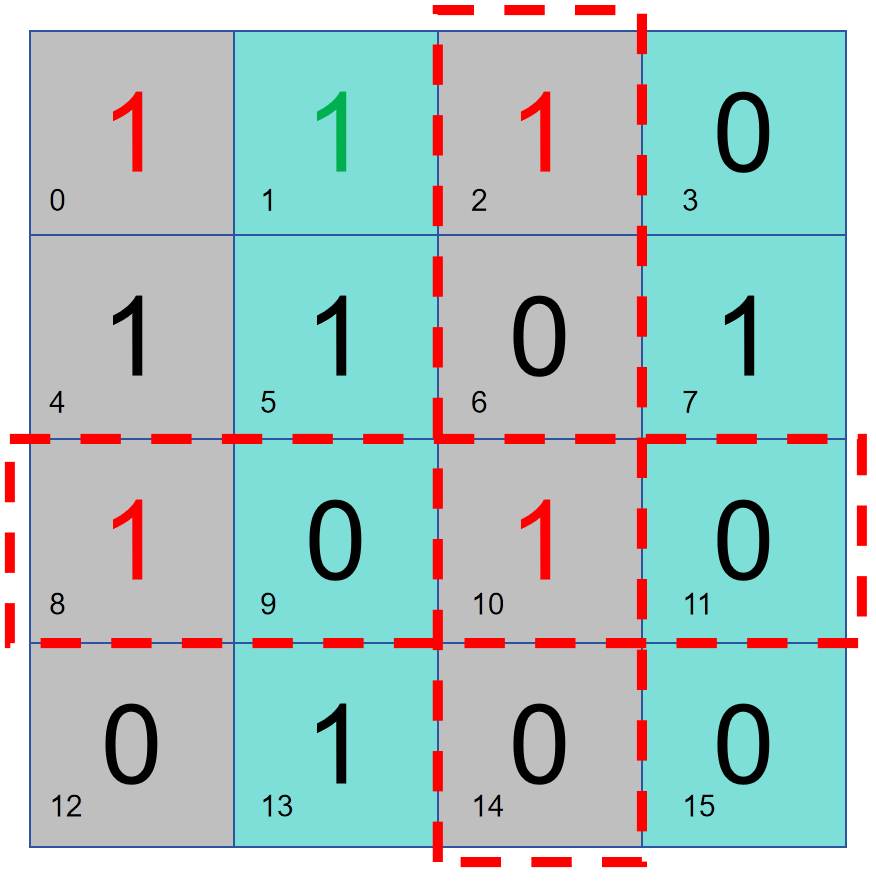
In this case, if there are two errors, the parity check results of the whole disk and the column partition will conflict, and the error location cannot be determined, but it can be determined that the entire block of data is abnormal. Retransmit the data.
But when there are 3 data errors, it is impossible to judge.

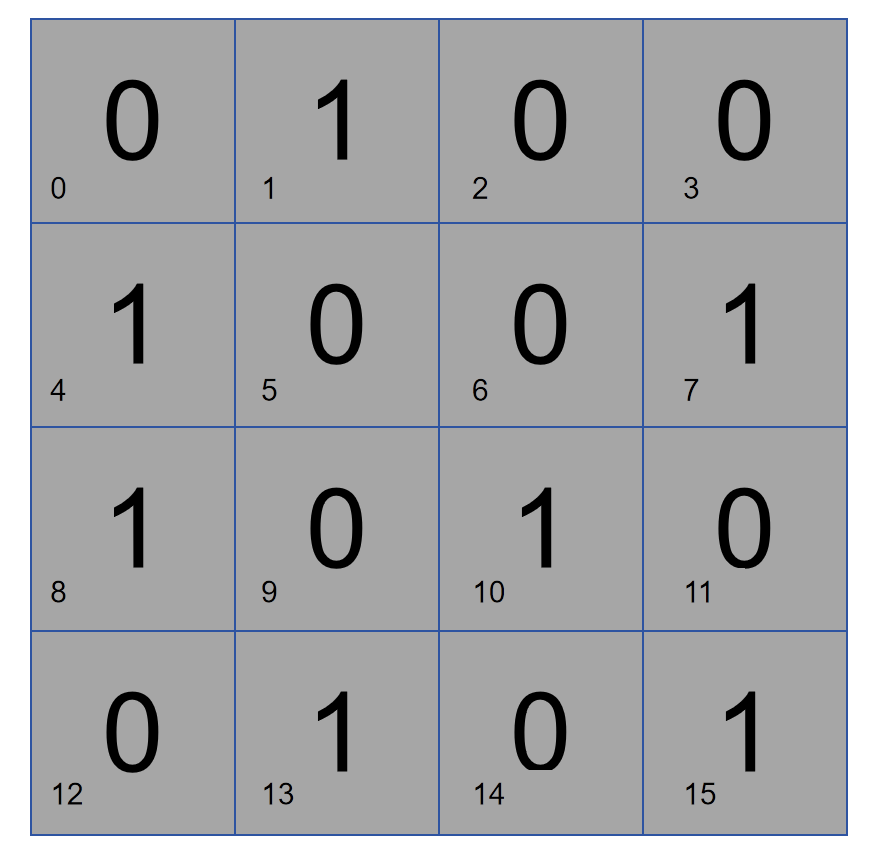
In other words, we will find that the position of the check code is 2 to the power of N:

The check code only needs to be placed at the Nth power of 2, so the larger the block, the less content the error correction code occupies, but the greater the probability of multi-bit flipping. The general ECC transmission block size is 72 bits, 64 bits are data, and 8 bits are error correction codes. Therefore, a general 8G memory only requires 8 1G memory particles, while ECC memory requires 9 1G memory particles to reach 8G capacity, and the extra 1G is used to store the extra capacity occupied by the error correction code.
However, computer error correction will definitely not calculate the error position in the same "silly" way as us. Here we can use the charm of binary to achieve it. We represent the position in binary:

We take out all the positions that are 1 and do a vertical binary OR operation to directly get the problematic position:

Note: There is also a LDPC (Low Density Parity-Check Code), which is a low-density parity check code. The specific implementation principle will not be explained here. This method can determine the problem of multi-bit flipping and is often used for SSD verification and error correction. Due to the high speed and implementation cost of memory, Hamming code is still used to implement ECC.
This issue briefly introduces how ECC memory implements error correction.
Old rules, you know what is written.

I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.
