내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
저자: 살찐 물고기의 어항 (Yin Haiwen)
Oracle ACE Pro: 데이터베이스(Oracle과 MySQL)
PostgreSQL ACE 파트너
데이터베이스 업계 경력 10년, 현재 주로 데이터베이스 서비스에 종사
OCM 11g/12c/19c, MySQL 8.0 OCP, Exadata, CDP 및 기타 인증 보유
Mo Tianlun MVP, 올해의 Moli Star, ITPUB 인증 전문가, 100인 전문가 그룹 회원, OCM 강사, PolarDB 오픈 소스 커뮤니티 기술 컨설턴트, HaloDB 외부 기술 컨설턴트, OceanBase 관찰 그룹 회원, 청소년 협회 MOP 기술 커뮤니티(Youth Database 학습공제회 )기술고문
그는 서클에 '이사', '보안', '국내 데이터베이스의 최대 적'이라는 직함을 가지고 있으며 유명한 사회 테러리스트(사회 테러리스트)는 아닙니다.
공개 계정: 살찐 머리 물고기 탱크; CSDN: 살찐 머리 물고기 탱크(Yin Haiwen); Mo Tianlun: 살찐 머리 물고기 탱크; ITPUB: yhw1809.
허가를 받아 재인쇄하거나 출처를 명시하지 않는 한 모두 '불법' 표절입니다.
앞서 CPU, SSD, 네트워크 등 서버와 관련된 하드웨어에 대해 설명했습니다. 위에서 언급한 구성 요소를 탑재한 마더보드 외에도 일반 데스크톱 수준(일반 가정용 PC)에 비해 매우 중요한 구성 요소인 메모리도 있습니다. ) 메모리, 서버 메모리에는 자체 오류 수정 기능이 있으며, 이를 ECC(Error Checking and Correcting) 메모리라고도 합니다.
이번 호에서는 ECC 메모리 작동 방식을 간략하게 설명합니다.
메모리는 컴퓨터의 중요한 구성요소로 CPU에 연산 데이터를 임시로 저장하고 하드디스크 등 외부 메모리와 데이터를 교환하는 데 사용됩니다. 외부 메모리와 CPU 사이의 다리 역할을 하는 컴퓨터의 모든 프로그램은 메모리에서 실행됩니다. 컴퓨터가 실행되기 시작하면 운영 체제는 계산해야 하는 데이터를 메모리에서 CPU로 전송하여 계산이 완료되면 CPU에서 결과를 전송합니다.
메모리의 출현은 주로 외부 저장소와 CPU 내장 캐시(즉, L1, L2, L3) 사이의 엄청난 대역폭과 지연 시간 차이를 보완하기 위한 것입니다. 본질적으로 CPU 내장 캐시보다 크지만 일반적으로 그렇습니다. 외부 저장소보다 훨씬 작습니다. 중간 데이터 전송 장치는 느린 외부 저장소에서 데이터 준비를 미리 가속화하여 CPU가 데이터를 얻는 데 걸리는 대기 시간을 줄이거나 없앨 수 있습니다.
현재 우리가 서버에 주로 사용하는 메모리는 DDR 메모리입니다. 여기서는 DDR이 무엇인지 자세히 설명하지 않겠습니다. 주류 메모리 세대는 DDR4와 DDR5입니다. 일반 메모리 외에도 메모리 인터페이스(또는 PCIe 인터페이스) 기반의 비휘발성 메모리 PMEM(인텔 옵테인을 예로 들어)도 있는데, 이는 메모리와 외부 스토리지 사이에 더 큰 데이터를 제공하고 캐시 영역의 속도.
일반적으로 서버는 중요한 업무 시스템을 담고 있는데, 전자 장비의 작동 중에는 전자기 간섭이 많이 발생합니다. 이러한 전자기 간섭으로 인해 메모리와 메모리 간의 데이터 상호 작용 중에 비트 플립(즉, 0과 1의 교환)이 발생할 수 있습니다. CPU, 이런 식으로 데이터 실행 시 오류가 발생하게 되는데, 일반적인 PC 소프트웨어나 프로그램이라면 오류나 충돌을 보고할 수도 있지만, 중요한 시스템에서 이런 문제가 발생하면 더 심각한 결과를 초래할 수 있습니다. (결국 은행은 아무 이유 없이 자산이 늘어나는 것을 원하지 않습니다. 몇 0이면 자산이 감소하는 것을 원하지 않습니다.)
그러다가 데이터에 있는 데이터 오류를 능동적으로 발견하고 수정하는 ECC 메모리가 탄생했습니다.
다음은 상대적으로 원시적인 두 가지 솔루션입니다.
즉, 데이터 조각이 3개의 복사본으로 전송됩니다. 특정 복사본에 문제가 있으면 수정할 수 있습니다.

그러나 문제도 발생했습니다. 발생 확률은 매우 낮지만 두 데이터 조각이 동일한 위치에 비트 플립된 경우 데이터 검증 및 오류 수정에 문제가 발생합니다.

이 방법을 사용할 때 가장 큰 문제점은 IO 대역폭의 낭비입니다.
이와 같이 데이터의 시작 부분에 오류 정정 코드를 추가한다. 즉, 데이터의 1의 개수가 짝수일 때 오류 정정 코드를 추가한다. 0이고, 홀수일 경우 오류정정코드는 1이다.
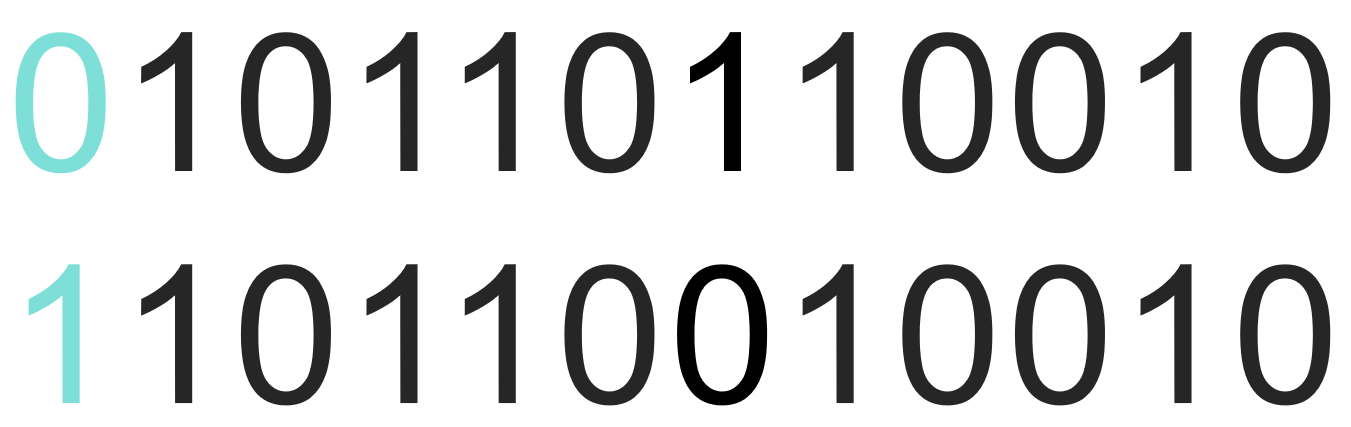
오류 수정 코드가 1의 개수와 일치하지 않으면 데이터가 재전송됩니다.
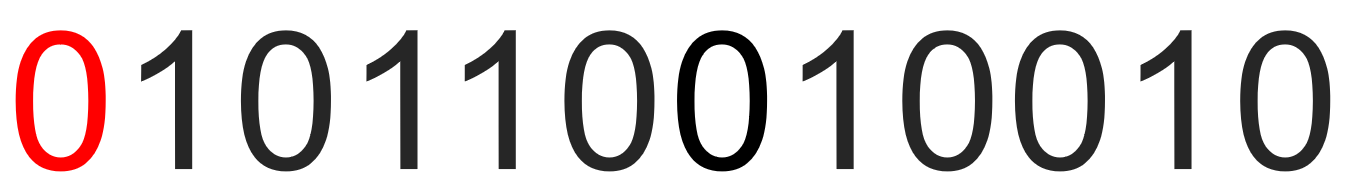
이는 또한 문제를 야기합니다. 각 검증에서는 전체 데이터가 정상인지 여부만 확인할 수 있습니다. 이론적으로는 오류 수정이 수행되지 않으며 재전송이 지연됩니다.
동시에 두 가지 데이터 오류가 동시에 발생하면 여전히 검증 목적을 달성할 수 없습니다.
Hamming 코드는 현재 ECC 메모리에서 사용되는 주요 검증 및 오류 정정 방법입니다.
여기서는 16비트 데이터를 다음과 같이 배열해 보겠습니다. 그러면 비트 2가 오른쪽 부분에 대한 패리티 검사를 담당한다고 가정합니다. 그러면 이 데이터에는 2개의 1이 있고 비트 2는 0입니다. 데이터에 오류가 있고 패리티 검사에서 오른쪽 절반에 문제가 없다고 판단하면 문제는 왼쪽 절반에 있고, 그렇지 않으면 문제는 오른쪽 절반에 있습니다.
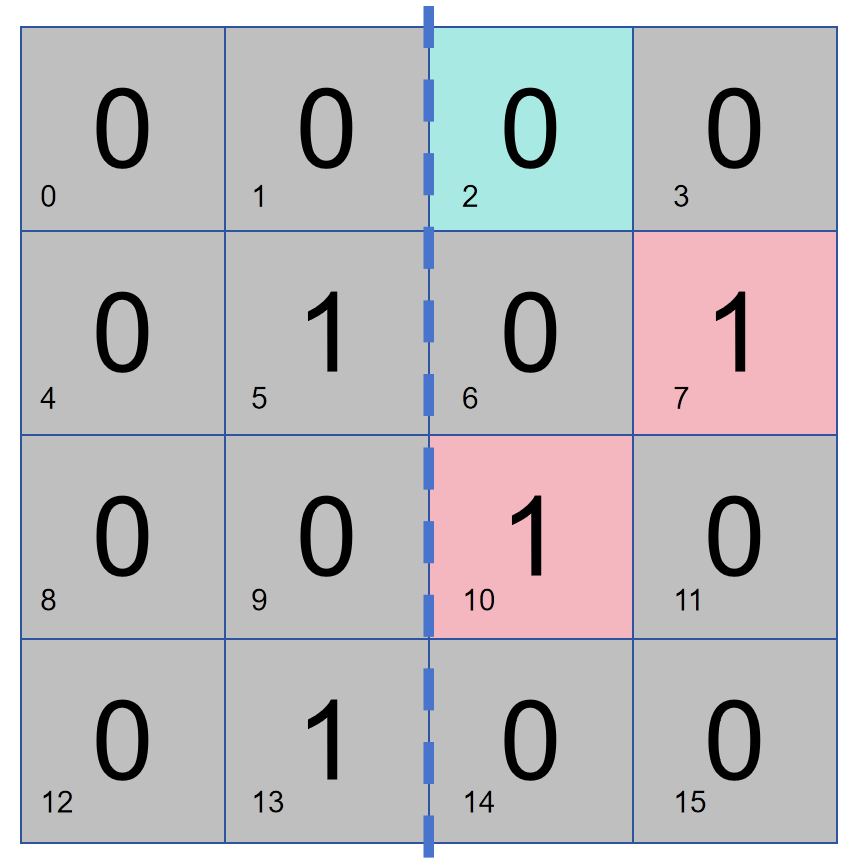
아래 그림과 같이 비트 1은 열 2와 열 4에 대해 패리티 검사를 수행한 다음 비트 1은 1을 저장합니다. 열 2와 4에 패리티 검사에 문제가 있으면 열 2와 4에 문제가 있고, 그렇지 않으면 열 1과 3에 문제가 있습니다.
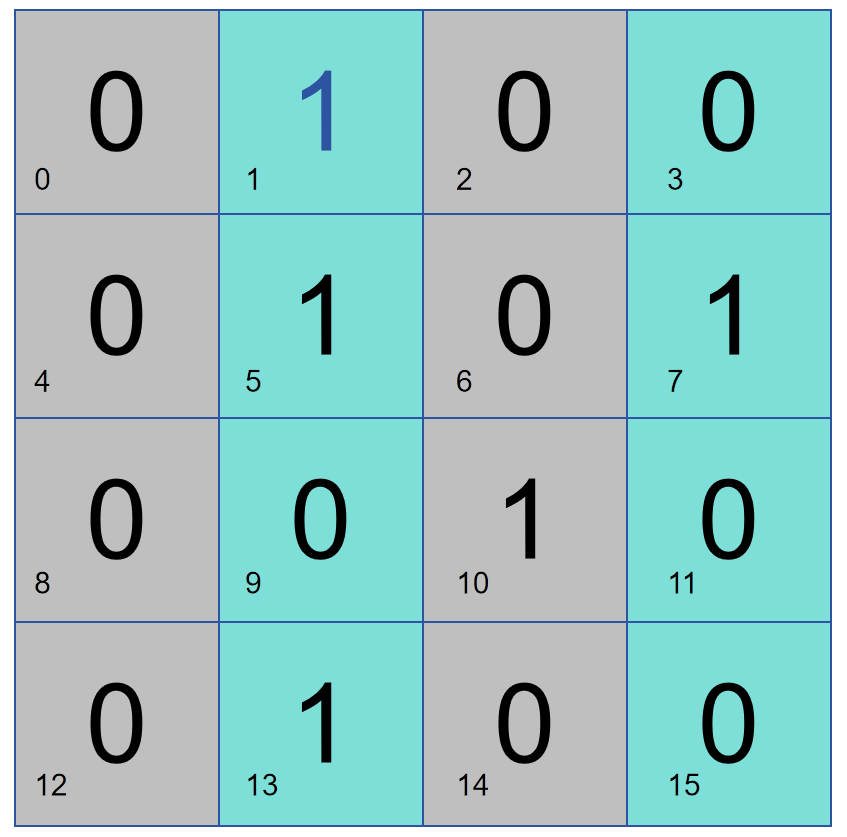
위의 두 가지 방법을 조합하면 어떤 데이터 열에 문제가 있는지 쉽게 확인할 수 있습니다.
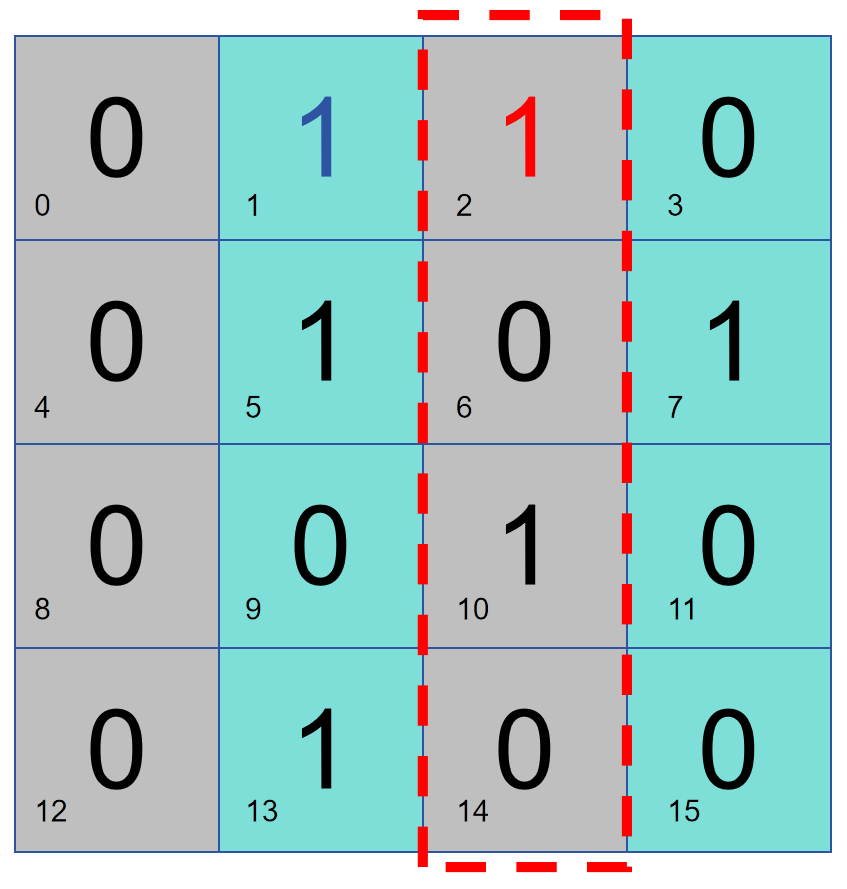
다음으로 비슷한 방법으로 비트 4를 사용하여 행 2와 4를 확인하고 비트 8을 사용하여 하위 절반을 확인하면 행 분리 및 파티션 패리티 검사를 통해 특정 오류 위치를 찾아 오류 정정(플립)을 수행할 수 있습니다. 그게 다야.
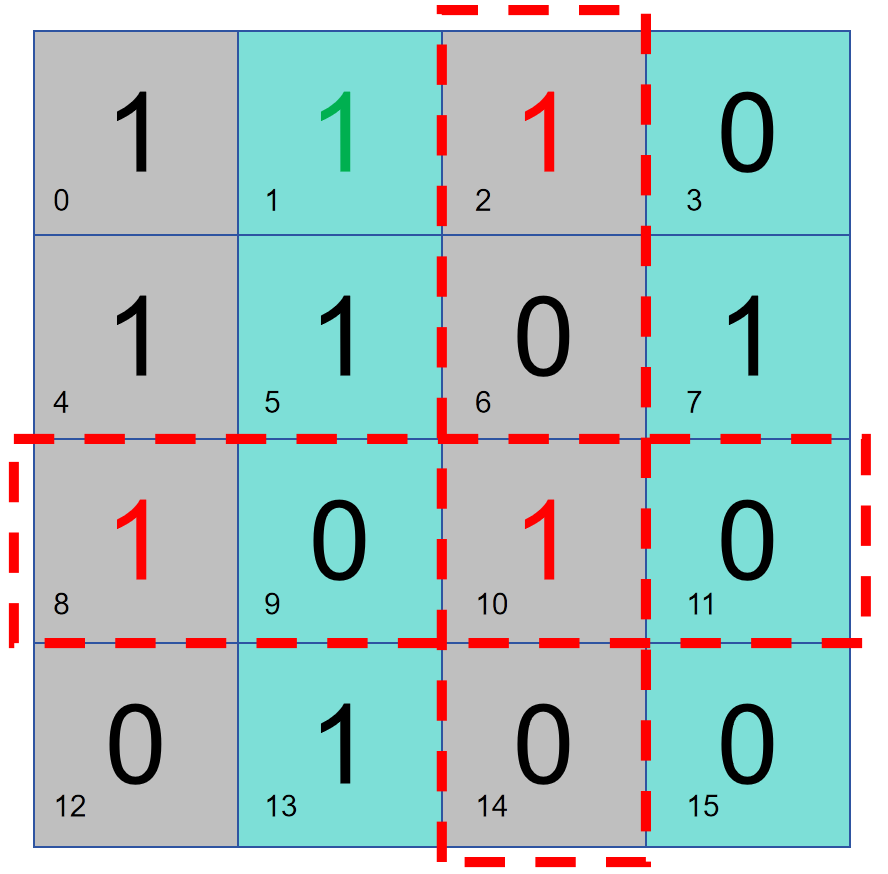
그러나 위 판단의 전제는 기본 데이터에 문제가 있다는 것입니다. 위 방법을 사용하여 판단한 후에는 데이터 비트 번호 0이 잘못되었는지 여부에 영향을 미치지 않습니다. 위의 패리티 검사 결과입니다. 따라서 우리는 3.2의 방법을 사용하여 전체 데이터 블록을 검증하기 위해 비트 0을 사용합니다.
이 경우 오류가 2개일 경우 전체 디스크 패리티 검사와 파티션 패리티 검사 결과가 충돌하게 되는데, 오류 위치를 확인할 수는 없으나 전체 데이터 블록이 비정상이라고 판단할 수는 있다. 데이터를 다시 전송하면 됩니다.
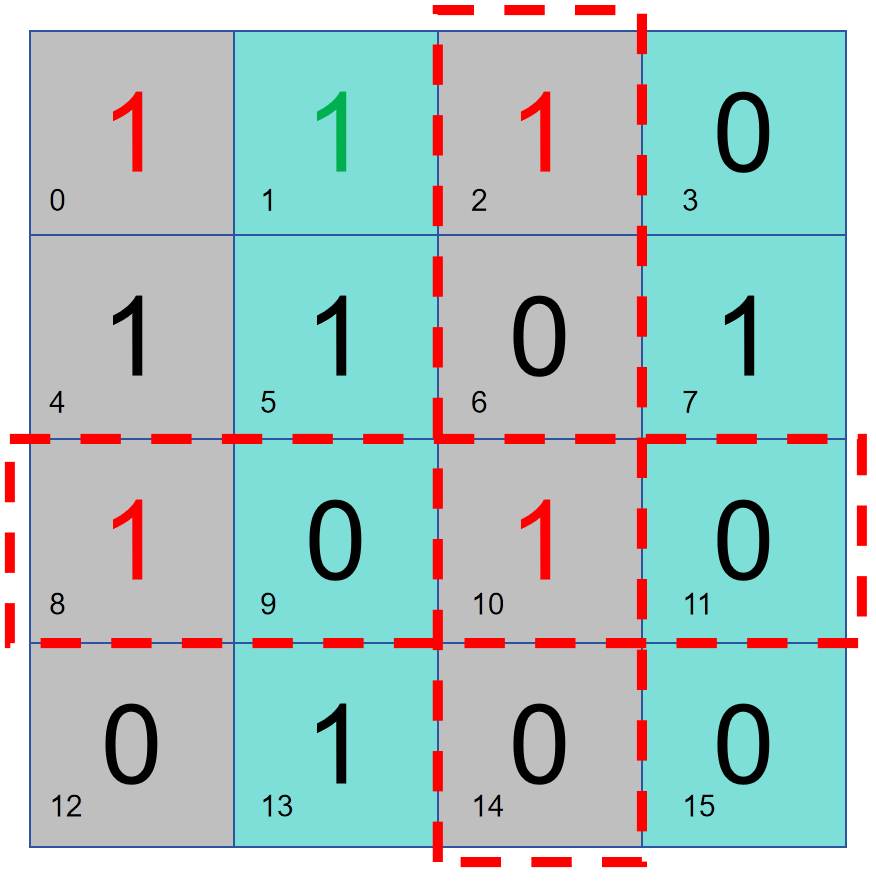
하지만 데이터 오류가 3개 있으면 판단이 불가능해진다.

다른 방법으로 확인 코드의 위치가 모두 2의 N승임을 알 수 있습니다.

검사 코드는 2의 N제곱에만 배치하면 됩니다. 블록이 클수록 오류 정정 코드가 차지하는 내용은 줄어들지만 여러 비트가 뒤집힐 가능성은 커집니다. 일반적인 ECC 전송 블록 크기는 72bit이고, 64bit는 데이터, 8bit는 오류 정정 코드이다. 따라서 일반적으로 8G 용량의 메모리에는 1G의 메모리 입자 8개만 필요한 반면, 8G 용량의 ECC 메모리에는 1G의 메모리 입자 9개가 필요합니다. 추가 1G는 추가 오류 정정 코드 용량을 저장하는 데 사용됩니다.
그러나 컴퓨터 오류 수정은 일반적인 "어리석은" 방식으로 오류 위치를 계산하지 않습니다. 여기서는 이를 달성하기 위해 바이너리의 매력을 사용할 수 있습니다.

1인 모든 위치를 꺼내고 문제가 있는 위치를 직접 얻기 위해 수직 이진 OR 연산을 수행합니다.

첨부: 저밀도 패리티 검사 코드인 LDPC(Low Density Parity-Check Code)도 있습니다. 여기서는 구체적인 구현 원리를 설명하지 않습니다. 이 방법은 다중 비트 뒤집기 문제를 확인할 수 있으며 종종 발생합니다. SSD 검증에 사용됩니다. 메모리의 빠른 속도와 구현 비용으로 인해 여전히 ECC를 구현하는 데 해밍 코드가 사용됩니다.
이번 호에서는 ECC 메모리가 오류 수정을 구현하는 방법을 간략하게 소개합니다.
오래된 규칙은 쓰여진 내용을 아는 것입니다.

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com