2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Auteur : L'aquarium des poissons à grosse tête (Yin Haiwen)
Oracle ACE Pro : base de données (Oracle et MySQL)
Partenaire ACE PostgreSQL
10 ans d'expérience dans le secteur des bases de données, actuellement principalement engagé dans les services de bases de données
Possède les certifications OCM 11g/12c/19c, MySQL 8.0 OCP, Exadata, CDP et autres
Mo Tianlun MVP, Moli Star of the Year, expert certifié ITPUB, membre du groupe d'experts de 100, conférencier OCM, consultant technique de la communauté open source PolarDB, consultant technique externe HaloDB, membre du groupe d'observation OceanBase, Youth Association MOP Technology Community (Youth Database Association d'entraide d'apprentissage)Conseiller technique
Il a des titres tels que « Directeur », « Sécurité » et « Le plus grand ennemi des bases de données nationales » dans le cercle, et n'est pas un terroriste social célèbre (terroriste social)
Compte public : Aquarium à poisson à grosse tête ; CSDN : Aquarium à poisson à grosse tête (Yin Haiwen) : Aquarium à poisson à grosse tête ; ITPUB : yhw1809 ;
Sauf réimpression avec autorisation et indication de la source, il s’agit d’un plagiat « illégal ».
J'ai déjà expliqué le matériel impliqué dans les serveurs tels que le processeur, le SSD et le réseau. En plus de la carte mère portant les composants mentionnés ci-dessus, il existe également un composant très important, qui est la mémoire. Par rapport au niveau général du bureau (accueil général). PC) Mémoire, la mémoire du serveur possède sa propre fonction de correction d'erreurs, que nous appelons également mémoire ECC (Error Checking and Correcting).
Ce numéro expliquera brièvement le fonctionnement de la mémoire ECC.
La mémoire est un composant important de l'ordinateur. Elle est utilisée pour stocker temporairement les données de calcul dans le processeur et échanger des données avec des mémoires externes telles que des disques durs. C'est le pont entre la mémoire externe et le processeur. Tous les programmes de l'ordinateur s'exécutent en mémoire. Tant que l'ordinateur démarre, le système d'exploitation transférera les données à calculer de la mémoire vers le CPU pour le calcul. Une fois le calcul terminé, le CPU transmettra les résultats.
L'émergence de la mémoire vise principalement à compenser les énormes différences de bande passante et de latence entre le stockage externe et le cache intégré du processeur (c'est-à-dire L1, L2, L3). En substance, il est plus grand que le cache intégré du processeur, mais en général. beaucoup plus petit que le stockage externe. Le périphérique de transfert de données intermédiaire peut accélérer à l'avance la préparation des données à partir d'un stockage externe plus lent, réduisant voire éliminant le temps d'attente pour que le processeur obtienne les données.
La mémoire que nous utilisons principalement sur les serveurs est désormais la mémoire DDR. Je n’entrerai pas ici dans une explication approfondie de ce qu’est la DDR. Les générations de mémoire principales sont la DDR4 et la DDR5. En plus de la mémoire générale, il existe également une mémoire non volatile PMEM basée sur l'interface mémoire (ou interface PCIe) (en prenant Intel Optane comme exemple), qui fournit une plus grande quantité de données entre la mémoire et le stockage externe et est proche de la vitesse de la zone de cache.
De manière générale, les serveurs transportent des systèmes commerciaux importants. Il y a de nombreuses interférences électromagnétiques lors du fonctionnement des équipements électroniques. Ces interférences électromagnétiques peuvent provoquer des basculements de bits (c'est-à-dire l'échange de 0 et 1) lors de l'interaction des données entre la mémoire et la mémoire. CPU , de cette manière, des erreurs se produiront lors de l'exécution des données. S'il s'agit d'un logiciel ou d'un programme PC général, il peut même signaler une erreur ou un crash. Cependant, si ce problème se produit dans un système important, cela entraînera des conséquences plus graves. (après tout, la banque ne veut pas que votre patrimoine augmente sans raison. Quelques 0, vous ne voulez pas que votre patrimoine diminue).
Ensuite, la mémoire ECC est née, découvrant de manière proactive les erreurs de données et les corrigeant.
Voici deux solutions relativement primitives :
Autrement dit, une donnée est transmise en 3 copies. S'il y a un problème quelque part dans une certaine copie, il peut être corrigé :

Mais des problèmes sont également apparus, bien que la probabilité d'apparition soit très faible, si deux éléments de données ont des retournements de bits à la même position, des problèmes se poseront au niveau de la vérification des données et de la correction des erreurs :

Le plus gros problème lié à l’utilisation de cette méthode est le gaspillage de bande passante IO.
De cette manière, un code de correction d'erreur est ajouté au début des données, c'est-à-dire qu'un code de correction d'erreur est ajouté avant chaque élément de données. Lorsque le nombre de 1 dans les données est un nombre pair, le code de correction d'erreur est. 0, et lorsque le nombre est impair, le code correcteur d'erreur est 1.
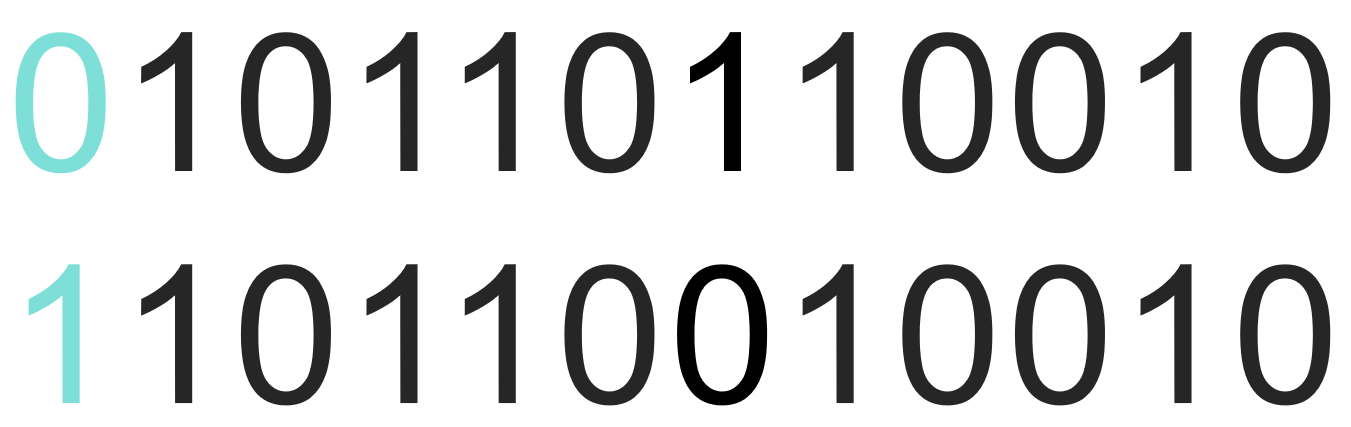
Si le code de correction d'erreur ne correspond pas au nombre de 1, les données sont retransmises.
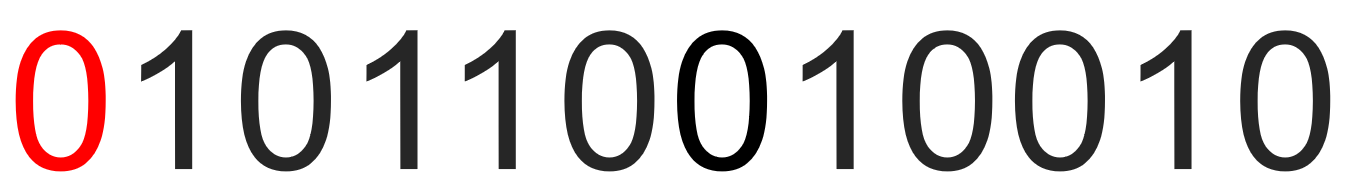
Cela crée également un problème. Chaque vérification peut uniquement déterminer si l'ensemble des données est normale. En théorie, la correction des erreurs n'est pas effectuée et la retransmission augmentera le délai.
Dans le même temps, si deux erreurs de données se produisent en même temps, l’objectif de la vérification ne peut toujours pas être atteint.
Le code de Hamming est la principale méthode de vérification et de correction d'erreurs actuellement utilisée dans la mémoire ECC.
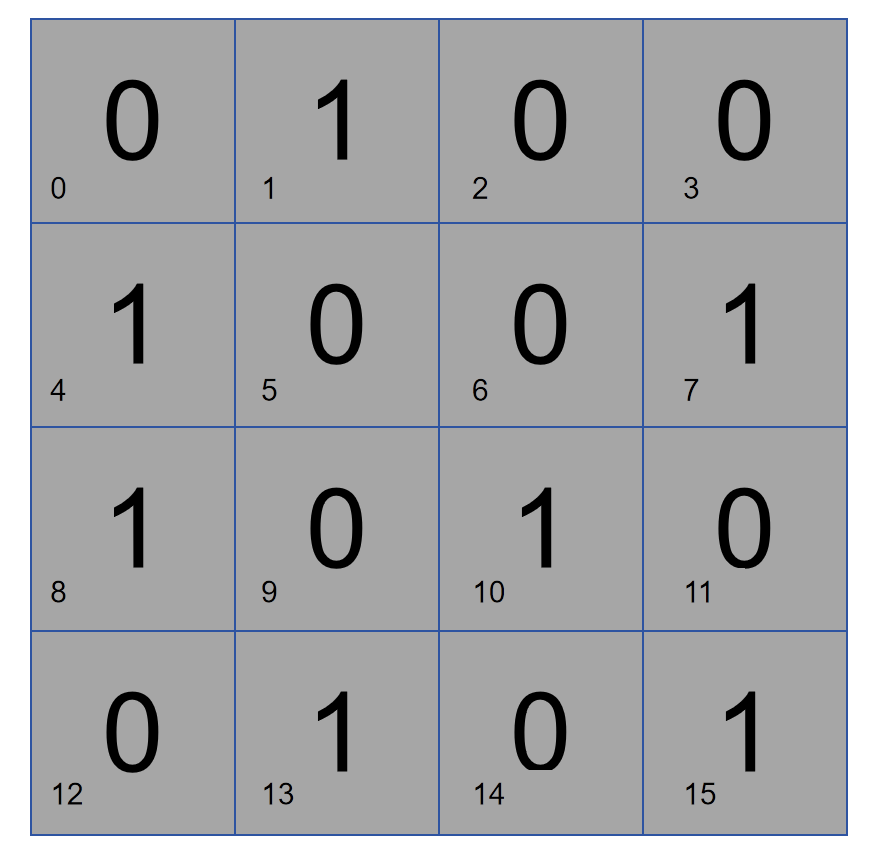
Allons-y étape par étape et organisons une donnée de 16 bits de la manière suivante. Supposons que le bit 2 soit responsable du contrôle de parité sur la partie droite, alors ces données ont deux 1 et le bit 2 est 0. S'il y a une erreur dans les données et que le contrôle de parité détermine qu'il n'y a pas de problème dans la moitié droite, alors le problème se situe dans la moitié gauche, sinon le problème se situe dans la moitié droite.
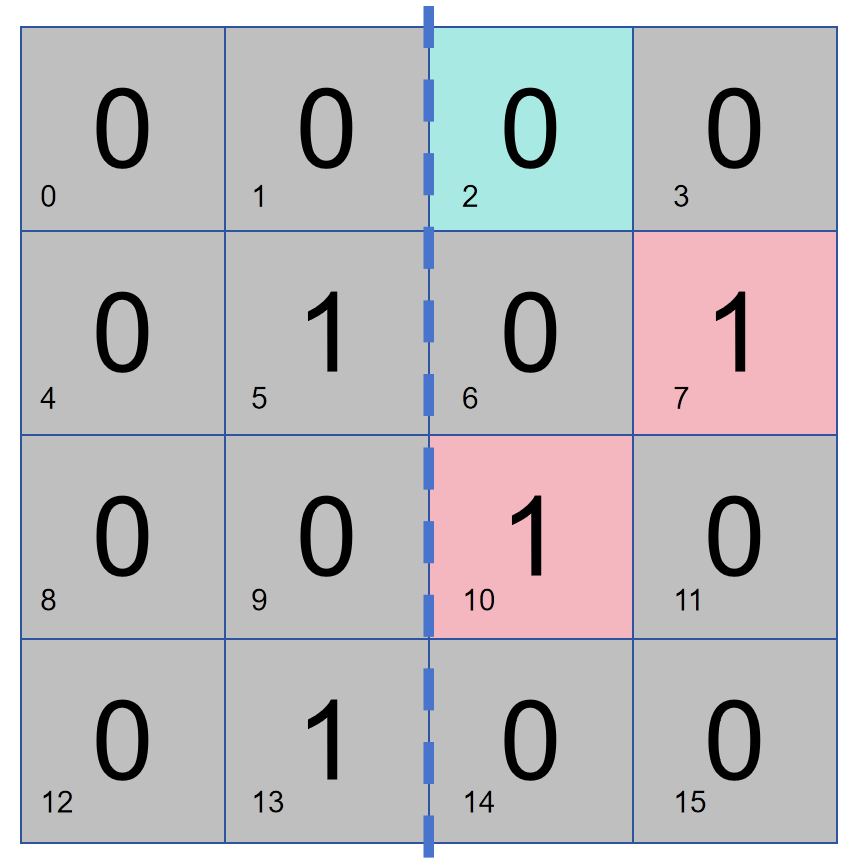
Comme le montre la figure ci-dessous, le bit 1 effectue un contrôle de parité sur les colonnes 2 et 4, puis le bit 1 stocke 1. S'il y a un problème de contrôle de parité dans les colonnes 2 et 4, alors le problème se situe dans les colonnes 2 et 4, sinon il y a un problème dans les colonnes 1 et 3.
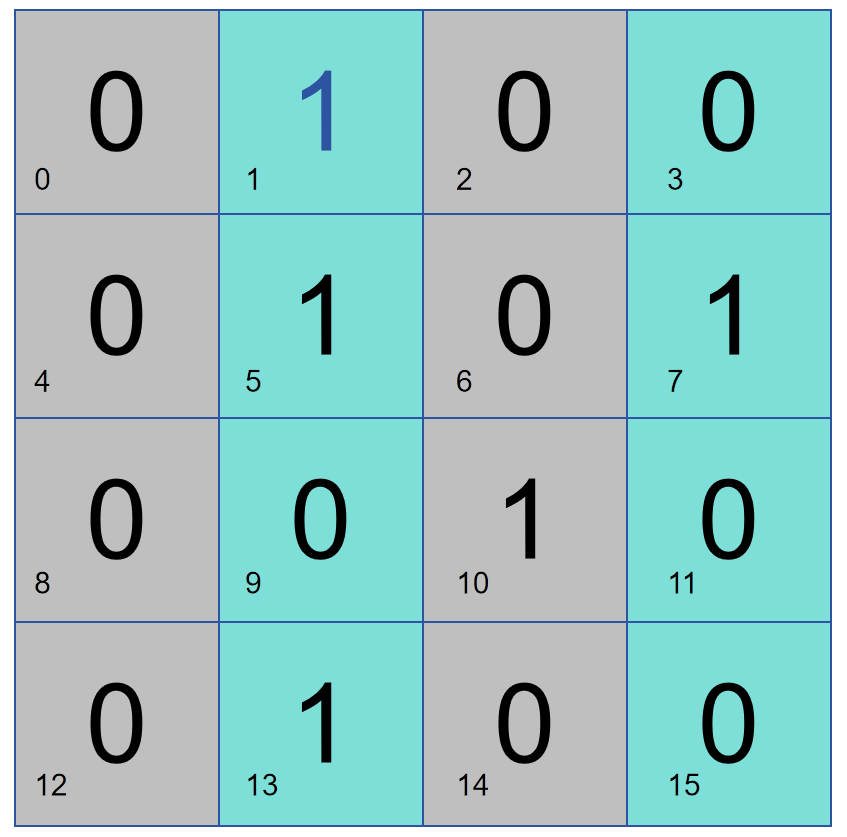
La combinaison des deux méthodes ci-dessus peut facilement confirmer quelle colonne de données pose problème :
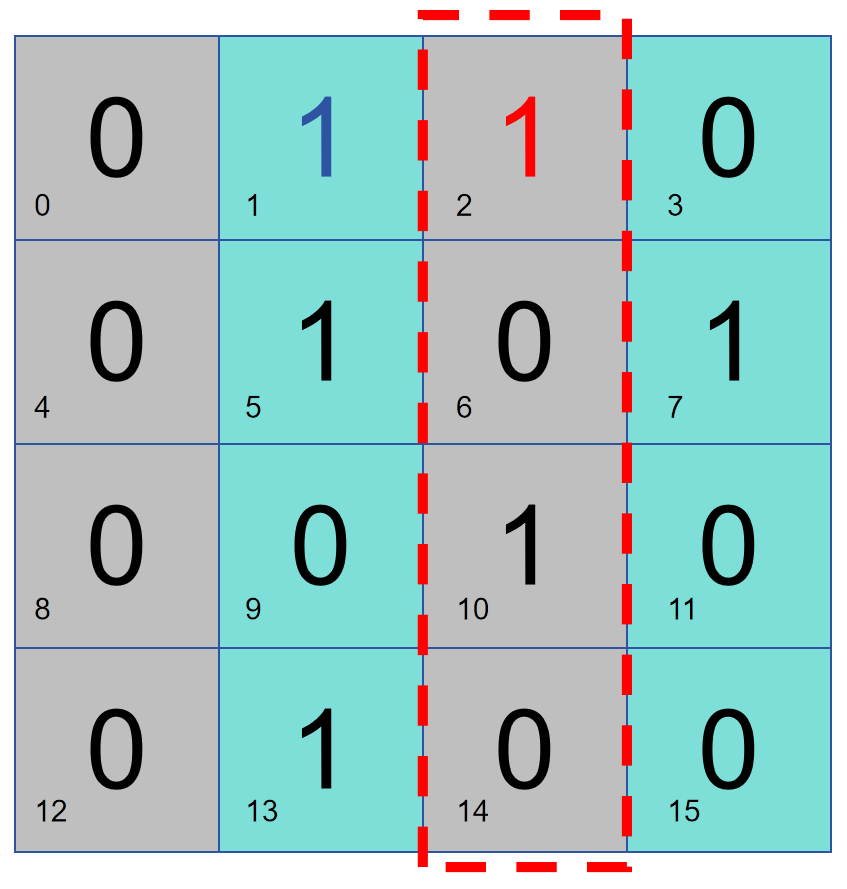
Ensuite, utilisez une méthode similaire, en utilisant le bit 4 pour vérifier les lignes 2 et 4, et le bit 8 pour vérifier la moitié inférieure. Grâce à la séparation des lignes et au contrôle de parité des partitions, vous pouvez trouver l'emplacement spécifique de l'erreur et effectuer une correction d'erreur (inversion). C'est ça.
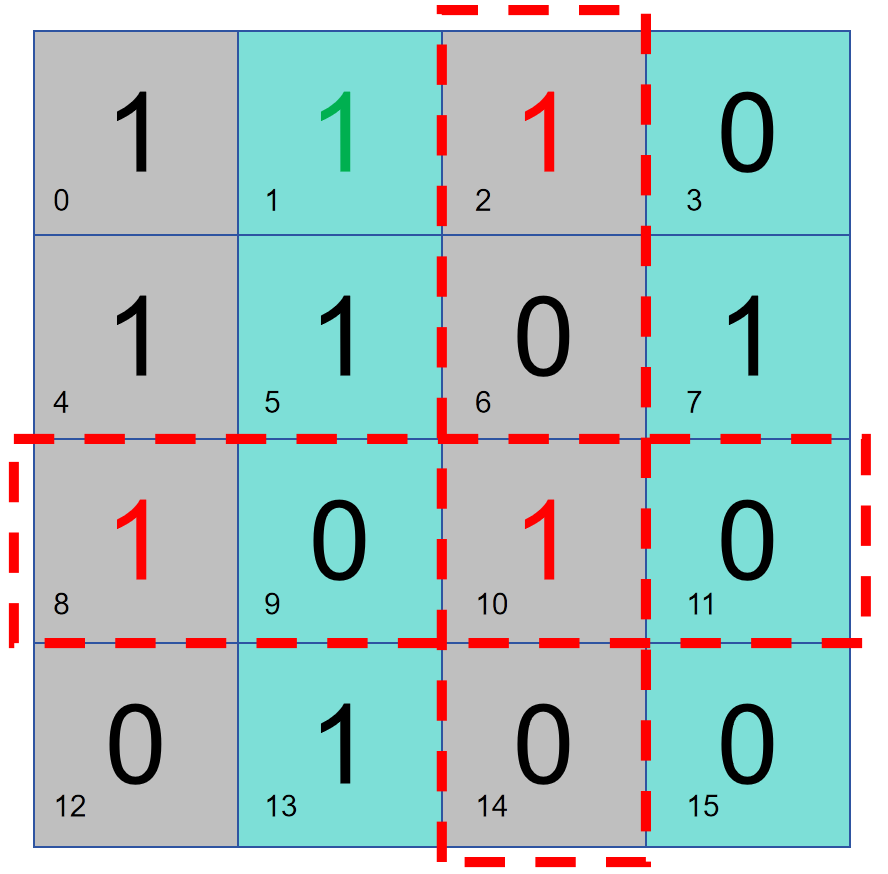
Cependant, la prémisse du jugement ci-dessus est qu'il y a un problème avec les données par défaut. Une fois la méthode ci-dessus utilisée pour juger, le bit de données n° 0 n'est pas inclus dans la protection. Qu'il soit erroné ou non n'affecte pas. le résultat du contrôle de parité ci-dessus. Par conséquent, nous utilisons le bit 0 pour vérifier l’intégralité du bloc de données en utilisant la méthode de 3.2.
Dans ce cas, s'il y a deux erreurs, les résultats du contrôle de parité complet du disque et du contrôle de parité de la partition seront en conflit. Il est impossible de déterminer l'emplacement de l'erreur, mais il peut être déterminé que l'ensemble du bloc de données est anormal. Retransmettez simplement les données.
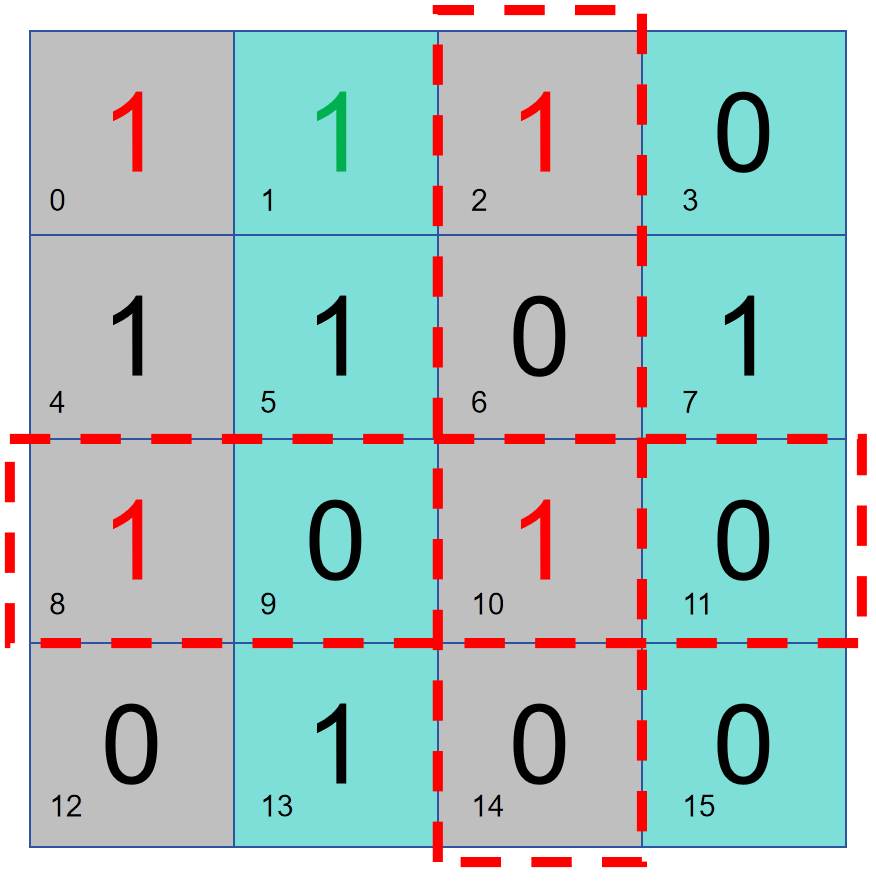
Mais lorsqu’il y a trois erreurs de données, il devient impossible de juger.

D'une autre manière, nous constaterons que les positions des codes de contrôle sont toutes 2 à la puissance N :

Le code de contrôle doit uniquement être placé à la Nième position de puissance de 2. Plus le bloc est grand, moins le contenu est occupé par le code de correction d'erreur, mais plus la probabilité de retournements de bits multiples est grande. La taille générale du bloc de transmission ECC est de 72 bits, 64 bits pour les données et 8 bits pour le code de correction d'erreur. Par conséquent, généralement une mémoire d'une capacité de 8 Go ne nécessite que huit particules de mémoire de 1 Go, tandis qu'une mémoire ECC d'une capacité de 8 Go nécessite neuf particules de mémoire de 1 Go. Le 1 Go supplémentaire est utilisé pour stocker la capacité supplémentaire du code de correction d'erreur.
Cependant, la correction d'erreur informatique ne calculera certainement pas la position de l'erreur de la manière "idiote" habituelle. Cela peut être réalisé en utilisant le charme du binaire. Nous représentons la position en binaire :

Nous supprimons toutes les positions qui valent 1 et effectuons une opération OU binaire verticale pour obtenir directement la position problématique :

Pièce jointe : Il existe également un LDPC (Low Density Parity-Check Code), qui est un code de contrôle de parité à faible densité. Le principe de mise en œuvre spécifique ne sera pas expliqué ici. Cette méthode peut déterminer le problème du retournement multi-bits et l'est souvent. utilisé pour la vérification SSD. En raison de la vitesse élevée et du coût de mise en œuvre de la mémoire, les codes de Hamming sont toujours utilisés pour implémenter ECC.
Ce numéro présente brièvement comment la mémoire ECC implémente la correction d'erreurs.
La vieille règle est de savoir ce qui est écrit.

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
