
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
L'algoritmo genetico (GA) è un algoritmo di ottimizzazione ispirato alla selezione naturale e alla genetica. Fu proposto per la prima volta dallo studioso americano John Holland negli anni '70, con l'obiettivo di studiare l'adattabilità nei sistemi naturali e applicato a problemi di ottimizzazione nell'informatica.
1975: John Holland propose per primo il concetto di algoritmo genetico nel suo libro "Adattamento nei sistemi naturali e artificiali".
Anni '80: Gli algoritmi genetici iniziarono ad essere utilizzati in campi come l'ottimizzazione delle funzioni e l'ottimizzazione combinatoria, e gradualmente attirarono l'attenzione.
Anni '90: Con il miglioramento della potenza di calcolo dei computer, gli algoritmi genetici sono stati ampiamente utilizzati in ingegneria, economia, biologia e altri campi.
Dal 2000 ad oggi: La teoria e l'applicazione degli algoritmi genetici si sono ulteriormente sviluppate e sono emersi una varietà di algoritmi migliorati, come ad esempio遗传编程(Programmazione genetica)差分进化(Evoluzione differenziale) ecc.
L'algoritmo genetico è un metodo di ricerca casuale basato sulla selezione naturale e sulla genetica. La sua idea di base è simulare il processo di evoluzione biologica.scegliere、attraversoEMutazioniL'operazione genera continuamente una nuova generazione di popolazioni, avvicinandosi gradualmente alla soluzione ottimale.
inizializzazione: Genera casualmente la popolazione iniziale.
scegliere: seleziona gli individui migliori in base alla funzione fitness.
attraverso: Crea un nuovo individuo scambiando parte dei geni dell'individuo genitore.
Mutazioni: Altera casualmente alcuni geni di un individuo.
Iterare: Ripetere i processi di selezione, crossover e mutazione finché non viene soddisfatta la condizione di terminazione.
Supponiamo che la dimensione della popolazione sia N e che la lunghezza cromosomica di ciascun individuo sia L. Il processo matematico dell'algoritmo genetico è il seguente:
inizializzazione: Genera popolazione, dove si trova il cromosoma.
Calcolo dell'idoneità: Calcola il valore di fitness di ciascun individuo.
scegliere: seleziona gli individui in base ai valori di fitness. I metodi comunemente utilizzati includono la selezione della roulette, la selezione del torneo, ecc.
attraverso: Selezionare alcuni individui per l'operazione crossover per generare nuovi individui.
Mutazioni: Esegui operazioni di mutazione su alcuni nuovi individui per generare individui mutati.
aggiornare la popolazione: sostituire i vecchi individui con nuovi individui per formare una nuova generazione di popolazione.
Condizione di cessazione: Se viene raggiunta la condizione di terminazione preimpostata (come il numero di iterazioni o la soglia di fitness), viene generata la soluzione ottimale.
Gli algoritmi genetici sono stati ampiamente utilizzati in molti campi a causa della loro adattabilità e robustezza:
Ottimizzazione strutturale: Progettare una struttura leggera e ad alta resistenza.
Ottimizzazione dei parametri: regola i parametri di sistema per prestazioni ottimali.
Ottimizzazione del portafoglio: Allocare le risorse di investimento per massimizzare i rendimenti.
previsione del mercato: Prevedere i prezzi delle azioni e le tendenze del mercato.
Confronto di sequenze geniche: Confrontare e analizzare sequenze di DNA.
Previsione della struttura delle proteine: Prevedere la struttura tridimensionale di una proteina.
Formazione sulla rete neurale: Ottimizza i pesi e la struttura delle reti neurali.
Selezione delle funzionalità: seleziona le funzionalità più utili per la classificazione o la regressione.
L'esempio di codice seguente implementa un algoritmo genetico per risolvere il problema del commesso viaggiatore.旅行商问题(TSP) è un classico problema di ottimizzazione combinatoria che mira a trovare il percorso più breve affinché un venditore ambulante possa visitare ciascuna città in un dato insieme di città esattamente una volta e infine tornare alla città di partenza, cioè minimizzare la distanza totale di viaggio o Costo, ampiamente utilizzato nella logistica, nella programmazione della produzione e in altri campi.
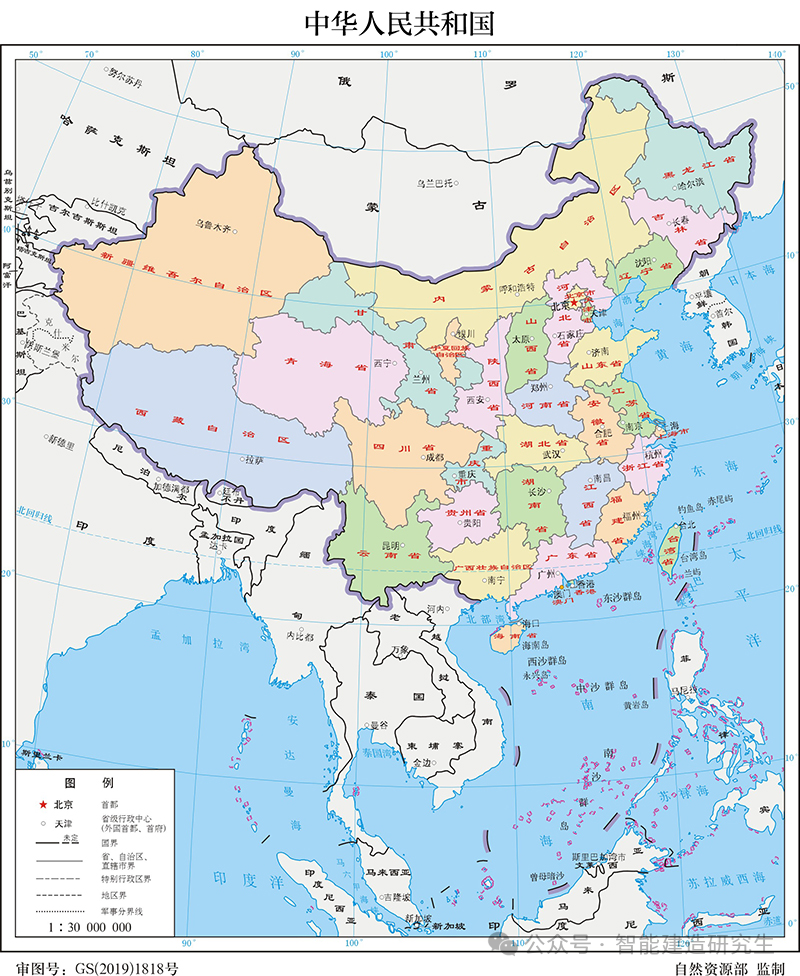
Per prima cosa definiamo tutte le capitali provinciali della Cina (inclusiTaipei, capitale della provincia cinese di Taiwan) e i relativi dati di coordinate e utilizzo哈夫曼公式Calcolare la distanza tra due punti e poi passare遗传算法Crea una popolazione iniziale, riproduci, muta e genera la generazione successiva, ottimizza continuamente il percorso e infine registra la distanza e il percorso corrispondente del percorso più breve in ogni generazione, trova il percorso più breve in tutte le iterazioni e visualizzalo visivamente sulla mappaTutte le località della città、La forma fisica cambia con il numero di iterazioni Oltre al percorso ottimale, il risultato finale mostra il percorso più breve da Chongqing attraverso tutte le città e la sua distanza totale. Sono stati eseguiti un totale di due corsi di formazione. Il primo numero di iterazione era 2000 e il tempo di esecuzione era di circa 3 minuti. Il secondo numero di iterazione era impostato su 20000 e il tempo di esecuzione era di circa 15 minuti.
Per riassumere in una frase: partendo da Chongqing, viaggia verso tutte le capitali provinciali della Cina e usa algoritmi genetici per trovare il percorso più breve. Quella che segue è l'implementazione del codice:
- import numpy as np
- import matplotlib.pyplot as plt
- from mpl_toolkits.basemap import Basemap
- import random
- from math import radians, sin, cos, sqrt, atan2
-
- # 设置随机种子以保证结果可重复
- random.seed(42)
- np.random.seed(42)
-
- # 定义城市和坐标列表,包括台北
- cities = {
- "北京": (39.9042, 116.4074),
- "天津": (39.3434, 117.3616),
- "石家庄": (38.0428, 114.5149),
- "太原": (37.8706, 112.5489),
- "呼和浩特": (40.8426, 111.7511),
- "沈阳": (41.8057, 123.4315),
- "长春": (43.8171, 125.3235),
- "哈尔滨": (45.8038, 126.5349),
- "上海": (31.2304, 121.4737),
- "南京": (32.0603, 118.7969),
- "杭州": (30.2741, 120.1551),
- "合肥": (31.8206, 117.2272),
- "福州": (26.0745, 119.2965),
- "南昌": (28.6820, 115.8579),
- "济南": (36.6512, 117.1201),
- "郑州": (34.7466, 113.6254),
- "武汉": (30.5928, 114.3055),
- "长沙": (28.2282, 112.9388),
- "广州": (23.1291, 113.2644),
- "南宁": (22.8170, 108.3665),
- "海口": (20.0174, 110.3492),
- "重庆": (29.5638, 106.5507),
- "成都": (30.5728, 104.0668),
- "贵阳": (26.6477, 106.6302),
- "昆明": (25.0460, 102.7097),
- "拉萨": (29.6520, 91.1721),
- "西安": (34.3416, 108.9398),
- "兰州": (36.0611, 103.8343),
- "西宁": (36.6171, 101.7782),
- "银川": (38.4872, 106.2309),
- "乌鲁木齐": (43.8256, 87.6168),
- "台北": (25.032969, 121.565418)
- }
-
- # 城市列表和坐标
- city_names = list(cities.keys())
- locations = np.array(list(cities.values()))
- chongqing_index = city_names.index("重庆")
-
- # 使用哈夫曼公式计算两点间的距离
- def haversine(lat1, lon1, lat2, lon2):
- R = 6371.0 # 地球半径,单位为公里
- dlat = radians(lat2 - lat1)
- dlon = radians(lon1 - lon2)
- a = sin(dlat / 2)**2 + cos(radians(lat1)) * cos(radians(lat2)) * sin(dlon / 2)**2
- c = 2 * atan2(sqrt(a), sqrt(1 - a))
- distance = R * c
- return distance
-
- # 计算路径总距离的函数,单位为公里
- def calculate_distance(path):
- return sum(haversine(locations[path[i]][0], locations[path[i]][1], locations[path[i + 1]][0], locations[path[i + 1]][1]) for i in range(len(path) - 1))
-
- # 创建初始种群
- def create_initial_population(size, num_cities):
- population = []
- for _ in range(size):
- individual = random.sample(range(num_cities), num_cities)
- # 确保重庆为起点
- individual.remove(chongqing_index)
- individual.insert(0, chongqing_index)
- population.append(individual)
- return population
-
- # 对种群进行排名
- def rank_population(population):
- # 按照路径总距离对种群进行排序
- return sorted([(i, calculate_distance(individual)) for i, individual in enumerate(population)], key=lambda x: x[1])
-
- # 选择交配池
- def select_mating_pool(population, ranked_pop, elite_size):
- # 选择排名前elite_size的个体作为交配池
- return [population[ranked_pop[i][0]] for i in range(elite_size)]
-
- # 繁殖新个体
- def breed(parent1, parent2):
- # 繁殖两个父母生成新个体
- geneA = int(random.random() * (len(parent1) - 1)) + 1
- geneB = int(random.random() * (len(parent1) - 1)) + 1
- start_gene = min(geneA, geneB)
- end_gene = max(geneA, geneB)
- child = parent1[:start_gene] + parent2[start_gene:end_gene] + parent1[end_gene:]
- child = list(dict.fromkeys(child))
- missing = set(range(len(parent1))) - set(child)
- for m in missing:
- child.append(m)
- # 确保重庆为起点
- child.remove(chongqing_index)
- child.insert(0, chongqing_index)
- return child
-
- # 突变个体
- def mutate(individual, mutation_rate):
- for swapped in range(1, len(individual) - 1):
- if random.random() < mutation_rate:
- swap_with = int(random.random() * (len(individual) - 1)) + 1
- individual[swapped], individual[swap_with] = individual[swap_with], individual[swapped]
- return individual
-
- # 生成下一代
- def next_generation(current_gen, elite_size, mutation_rate):
- ranked_pop = rank_population(current_gen)
- mating_pool = select_mating_pool(current_gen, ranked_pop, elite_size)
- children = []
- length = len(mating_pool) - elite_size
- pool = random.sample(mating_pool, len(mating_pool))
- for i in range(elite_size):
- children.append(mating_pool[i])
- for i in range(length):
- child = breed(pool[i], pool[len(mating_pool)-i-1])
- children.append(child)
- next_gen = [mutate(ind, mutation_rate) for ind in children]
- return next_gen
-
- # 遗传算法主函数
- def genetic_algorithm(population, pop_size, elite_size, mutation_rate, generations):
- pop = create_initial_population(pop_size, len(population))
- progress = [(0, rank_population(pop)[0][1], pop[0])] # 记录每代的最短距离和代数
- for i in range(generations):
- pop = next_generation(pop, elite_size, mutation_rate)
- best_route_index = rank_population(pop)[0][0]
- best_distance = rank_population(pop)[0][1]
- progress.append((i + 1, best_distance, pop[best_route_index]))
- best_route_index = rank_population(pop)[0][0]
- best_route = pop[best_route_index]
- return best_route, progress
-
- # 调整参数
- pop_size = 500 # 增加种群大小
- elite_size = 100 # 增加精英比例
- mutation_rate = 0.005 # 降低突变率
- generations = 20000 # 增加迭代次数
-
- # 运行遗传算法
- best_route, progress = genetic_algorithm(city_names, pop_size, elite_size, mutation_rate, generations)
-
- # 找到最短距离及其对应的代数
- min_distance = min(progress, key=lambda x: x[1])
- best_generation = min_distance[0]
- best_distance = min_distance[1]
-
- # 图1:地图上显示城市位置
- fig1, ax1 = plt.subplots(figsize=(10, 10))
- m1 = Basemap(projection='merc', llcrnrlat=18, urcrnrlat=50, llcrnrlon=80, urcrnrlon=135, resolution='l', ax=ax1)
- m1.drawcoastlines()
- m1.drawcountries()
- m1.fillcontinents(color='lightgray', lake_color='aqua')
- m1.drawmapboundary(fill_color='aqua')
- for i, (lat, lon) in enumerate(locations):
- x, y = m1(lon, lat)
- m1.plot(x, y, 'bo')
- ax1.text(x, y, str(i), fontsize=8)
- ax1.set_title('City Locations')
- plt.show()
-
- # 图2:适应度随迭代次数变化
- fig2, ax2 = plt.subplots(figsize=(10, 5))
- ax2.plot([x[1] for x in progress])
- ax2.set_ylabel('Distance (km)')
- ax2.set_xlabel('Generation')
- ax2.set_title('Fitness over Iterations')
- # 在图中标注最短距离和对应代数
- ax2.annotate(f'Gen: {best_generation}nDist: {best_distance:.2f} km',
- xy=(best_generation, best_distance),
- xytext=(best_generation, best_distance + 100),
- arrowprops=dict(facecolor='red', shrink=0.05))
- plt.show()
-
- # 图3:显示最优路径
- fig3, ax3 = plt.subplots(figsize=(10, 10))
- m2 = Basemap(projection='merc', llcrnrlat=18, urcrnrlat=50, llcrnrlon=80, urcrnrlon=135, resolution='l', ax=ax3)
- m2.drawcoastlines()
- m2.drawcountries()
- m2.fillcontinents(color='lightgray', lake_color='aqua')
- m2.drawmapboundary(fill_color='aqua')
-
- # 绘制最优路径和有向箭头
- for i in range(len(best_route) - 1):
- x1, y1 = m2(locations[best_route[i]][1], locations[best_route[i]][0])
- x2, y2 = m2(locations[best_route[i + 1]][1], locations[best_route[i + 1]][0])
- m2.plot([x1, x2], [y1, y2], color='g', linewidth=1, marker='o')
-
- # 只添加一个代表方向的箭头
- mid_index = len(best_route) // 2
- mid_x1, mid_y1 = m2(locations[best_route[mid_index]][1], locations[best_route[mid_index]][0])
- mid_x2, mid_y2 = m2(locations[best_route[mid_index + 1]][1], locations[best_route[mid_index + 1]][0])
- ax3.annotate('', xy=(mid_x2, mid_y2), xytext=(mid_x1, mid_y1), arrowprops=dict(facecolor='blue', shrink=0.05))
-
- # 在最优路径图上绘制城市位置
- for i, (lat, lon) in enumerate(locations):
- x, y = m2(lon, lat)
- m2.plot(x, y, 'bo')
- ax3.text(x, y, str(i), fontsize=8)
-
- # 添加起点和终点标记
- start_x, start_y = m2(locations[best_route[0]][1], locations[best_route[0]][0])
- end_x, end_y = m2(locations[best_route[-1]][1], locations[best_route[-1]][0])
- ax3.plot(start_x, start_y, marker='^', color='red', markersize=15, label='Start (Chongqing)') # 起点
- ax3.plot(end_x, end_y, marker='*', color='blue', markersize=15, label='End') # 终点
-
- # 添加总距离的图例
- ax3.legend(title=f'Total Distance: {best_distance:.2f} km')
-
- ax3.set_title('Optimal Path')
- plt.show()
-
Visualizzazione della posizione di tutte le capitali provinciali della Cina:
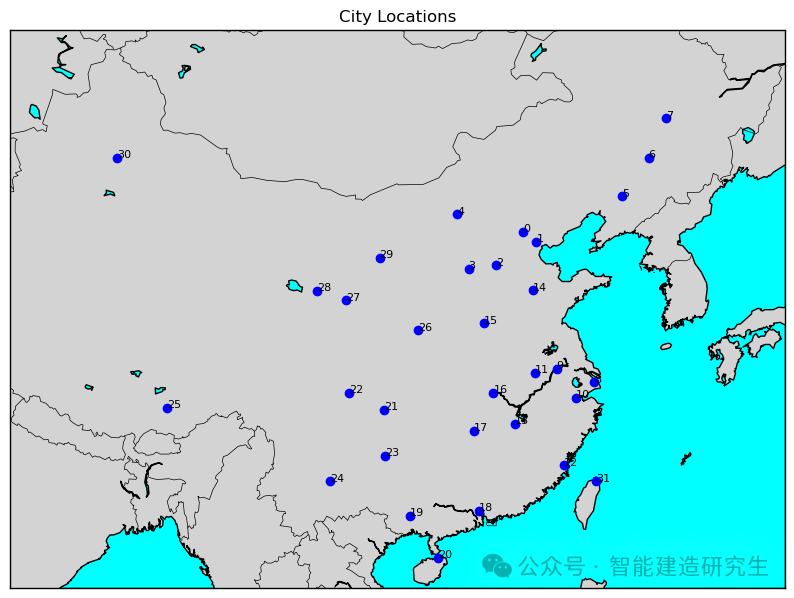
Il numero di iterazioni è 2.000 (la distanza più breve è 31594 chilometri):
Trova l'iterazione del percorso più breve nel processo di iterazione storica e visualizza il percorso più breve.
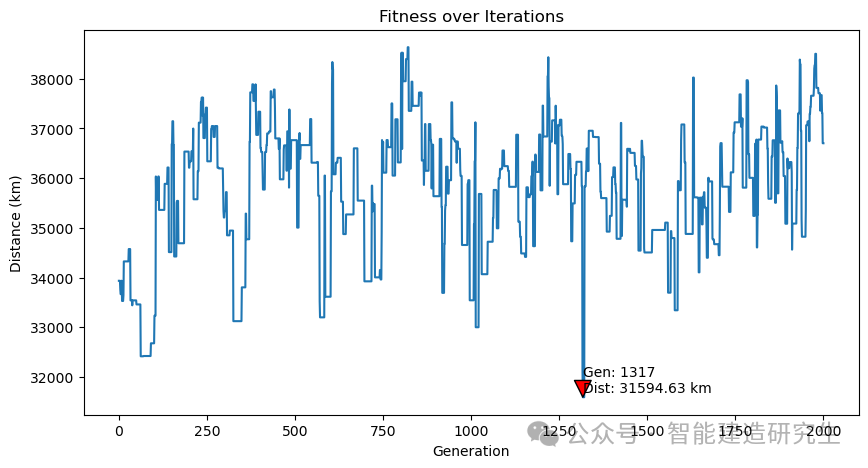
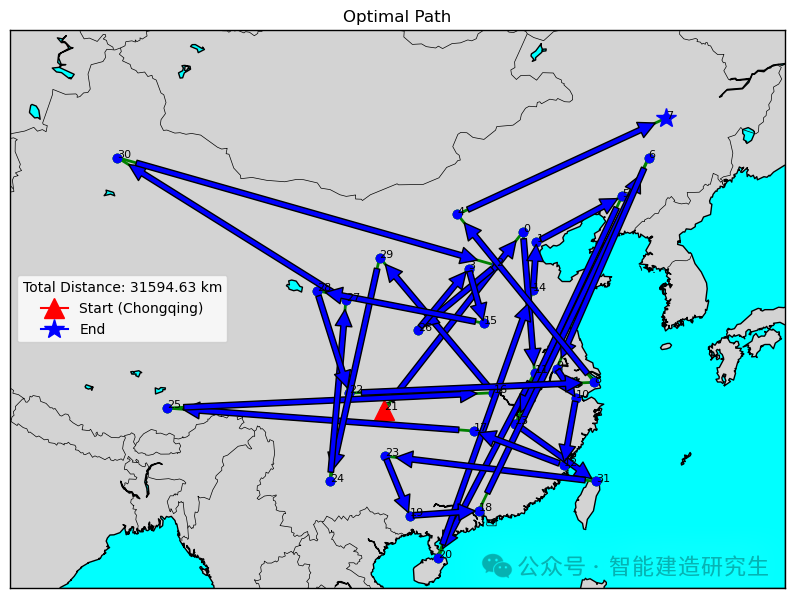
Caso 2: il numero di iterazioni è 20.000 (la distanza più breve ottenuta è 29.768 chilometri)
Trova l'iterazione con il percorso più breve nel processo di iterazione storica e visualizza il percorso più breve per tale iterazione.
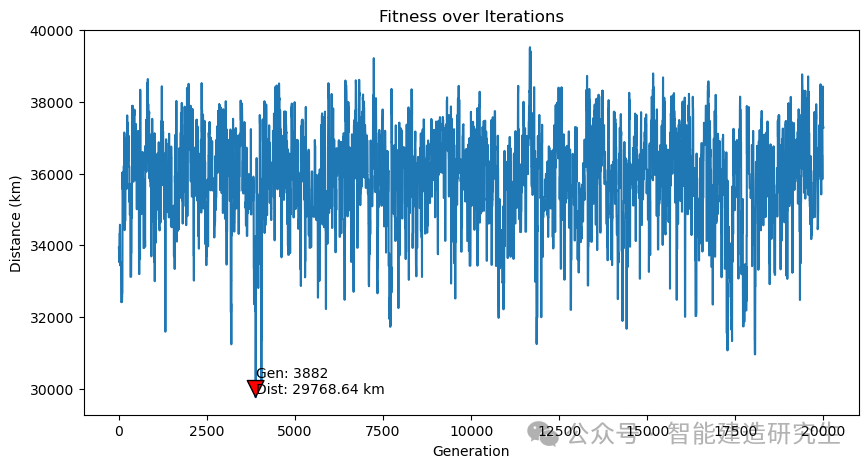
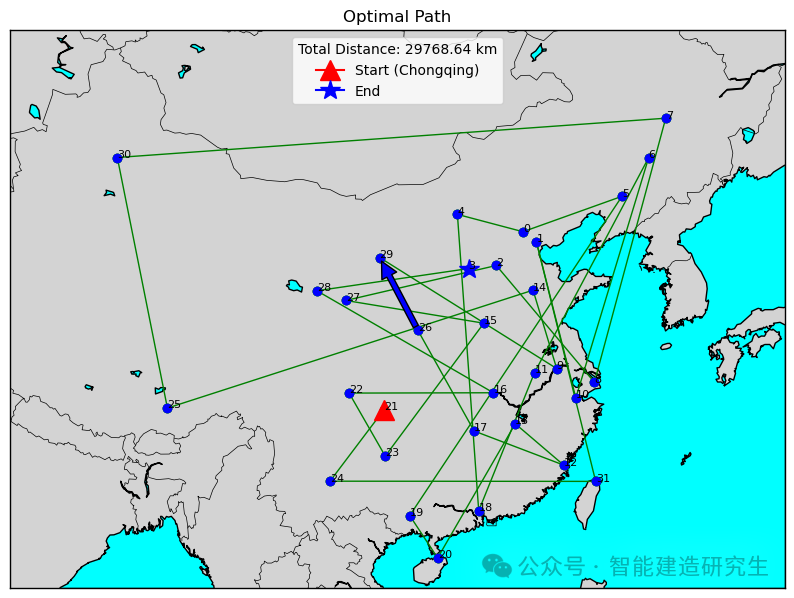
Il contenuto di cui sopra è un riepilogo da Internet. Se è utile, inoltralo. Alla prossima.

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]