
minhas informações de contato
Correspondênciamesophia@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Algoritmo Genético (GA) é um algoritmo de otimização inspirado na seleção natural e na genética. Foi proposto pela primeira vez pelo estudioso americano John Holland na década de 1970, com o objetivo de estudar adaptabilidade em sistemas naturais e aplicado a problemas de otimização em ciência da computação.
1975: John Holland propôs pela primeira vez o conceito de algoritmo genético em seu livro "Adaptação em Sistemas Naturais e Artificiais".
década de 1980: Algoritmos genéticos começaram a ser usados em áreas como otimização de funções e otimização combinatória e gradualmente atraíram a atenção.
década de 1990: Com a melhoria do poder de computação dos computadores, os algoritmos genéticos têm sido amplamente utilizados em engenharia, economia, biologia e outros campos.
Dos anos 2000 até o presente: A teoria e a aplicação de algoritmos genéticos desenvolveram-se ainda mais e surgiram uma variedade de algoritmos aprimorados, como遗传编程(Programação Genética)、差分进化(Evolução Diferencial) etc.
O algoritmo genético é um método de busca aleatória baseado na seleção natural e na genética. Sua ideia básica é simular o processo de evolução biológica.escolher、cruzareMutaçõesA operação gera continuamente uma nova geração de populações, aproximando-se gradativamente da solução ótima.
inicialização: Gere aleatoriamente a população inicial.
escolher: Selecione indivíduos melhores com base na função de condicionamento físico.
cruzar: Crie um novo indivíduo trocando parte dos genes do indivíduo progenitor.
Mutações: Altere aleatoriamente alguns genes de um indivíduo.
Iterar: Repita os processos de seleção, cruzamento e mutação até que a condição de terminação seja atendida.
Suponha que o tamanho da população seja N e o comprimento dos cromossomos de cada indivíduo seja L. O processo matemático do algoritmo genético é o seguinte:
inicialização: Gera população, onde está o cromossomo.
Cálculo de aptidão: Calcule o valor de aptidão de cada indivíduo.
escolher: Selecione indivíduos com base em valores de aptidão Os métodos comumente usados incluem seleção de roleta, seleção de torneio, etc.
cruzar: Selecione alguns indivíduos para operação cruzada para gerar novos indivíduos.
Mutações: Execute operações de mutação em alguns novos indivíduos para gerar indivíduos mutantes.
atualizar população: Substitua indivíduos antigos por novos indivíduos para formar uma nova geração de população.
Condição de rescisão: Se a condição de término predefinida (como o número de iterações ou limite de aptidão) for atingida, a solução ideal será gerada.
Algoritmos genéticos têm sido amplamente utilizados em muitos campos devido à sua adaptabilidade e robustez:
Otimização estrutural: Projetar estrutura leve e de alta resistência.
Otimização de parâmetros: Ajuste os parâmetros do sistema para obter desempenho ideal.
Otimização de portfólio: Alocar ativos de investimento para maximizar os retornos.
previsão de mercado: Prever preços de ações e tendências de mercado.
Comparação de sequência genética: Compare e analise sequências de DNA.
Previsão da estrutura proteica: Prever a estrutura tridimensional de uma proteína.
Treinamento de rede neural: Otimize os pesos e a estrutura das redes neurais.
Seleção de recursos: selecione os recursos mais benéficos para classificação ou regressão.
O exemplo de código a seguir implementa um algoritmo genético para resolver o problema do caixeiro viajante.旅行商问题(TSP) é um problema clássico de otimização combinatória que visa encontrar o caminho mais curto para um caixeiro viajante visitar cada cidade de um determinado conjunto de cidades exatamente uma vez e finalmente retornar à cidade de origem, ou seja, minimizar a distância total de viagem ou Custo, amplamente utilizado em logística, programação de produção e outras áreas.
Primeiro definimos todas as capitais provinciais da China (incluindoTaipei, capital da província de Taiwan, na China) e seus dados de coordenadas e use哈夫曼公式Calcule a distância entre dois pontos e depois passe遗传算法Crie uma população inicial, reproduza, transforme e gere a próxima geração, otimize continuamente o caminho e, finalmente, registre a distância e o caminho correspondente do caminho mais curto em cada geração, encontre o caminho mais curto em todas as iterações e exiba-o visualmente no mapaTodos os locais da cidade、A aptidão muda com o número de iterações Além do caminho ideal, o resultado final mostra o caminho mais curto de Chongqing por todas as cidades e sua distância total. Um total de dois treinamentos foram realizados. O número da primeira iteração foi 2.000 e o tempo de execução foi de cerca de 3 minutos. O número da segunda iteração foi definido como 20.000 e o tempo de execução foi de cerca de 15 minutos.
Resumindo em uma frase: começando em Chongqing, viaje para todas as capitais de província da China e use algoritmos genéticos para encontrar o caminho mais curto. A seguir está a implementação do código:
- import numpy as np
- import matplotlib.pyplot as plt
- from mpl_toolkits.basemap import Basemap
- import random
- from math import radians, sin, cos, sqrt, atan2
-
- # 设置随机种子以保证结果可重复
- random.seed(42)
- np.random.seed(42)
-
- # 定义城市和坐标列表,包括台北
- cities = {
- "北京": (39.9042, 116.4074),
- "天津": (39.3434, 117.3616),
- "石家庄": (38.0428, 114.5149),
- "太原": (37.8706, 112.5489),
- "呼和浩特": (40.8426, 111.7511),
- "沈阳": (41.8057, 123.4315),
- "长春": (43.8171, 125.3235),
- "哈尔滨": (45.8038, 126.5349),
- "上海": (31.2304, 121.4737),
- "南京": (32.0603, 118.7969),
- "杭州": (30.2741, 120.1551),
- "合肥": (31.8206, 117.2272),
- "福州": (26.0745, 119.2965),
- "南昌": (28.6820, 115.8579),
- "济南": (36.6512, 117.1201),
- "郑州": (34.7466, 113.6254),
- "武汉": (30.5928, 114.3055),
- "长沙": (28.2282, 112.9388),
- "广州": (23.1291, 113.2644),
- "南宁": (22.8170, 108.3665),
- "海口": (20.0174, 110.3492),
- "重庆": (29.5638, 106.5507),
- "成都": (30.5728, 104.0668),
- "贵阳": (26.6477, 106.6302),
- "昆明": (25.0460, 102.7097),
- "拉萨": (29.6520, 91.1721),
- "西安": (34.3416, 108.9398),
- "兰州": (36.0611, 103.8343),
- "西宁": (36.6171, 101.7782),
- "银川": (38.4872, 106.2309),
- "乌鲁木齐": (43.8256, 87.6168),
- "台北": (25.032969, 121.565418)
- }
-
- # 城市列表和坐标
- city_names = list(cities.keys())
- locations = np.array(list(cities.values()))
- chongqing_index = city_names.index("重庆")
-
- # 使用哈夫曼公式计算两点间的距离
- def haversine(lat1, lon1, lat2, lon2):
- R = 6371.0 # 地球半径,单位为公里
- dlat = radians(lat2 - lat1)
- dlon = radians(lon1 - lon2)
- a = sin(dlat / 2)**2 + cos(radians(lat1)) * cos(radians(lat2)) * sin(dlon / 2)**2
- c = 2 * atan2(sqrt(a), sqrt(1 - a))
- distance = R * c
- return distance
-
- # 计算路径总距离的函数,单位为公里
- def calculate_distance(path):
- return sum(haversine(locations[path[i]][0], locations[path[i]][1], locations[path[i + 1]][0], locations[path[i + 1]][1]) for i in range(len(path) - 1))
-
- # 创建初始种群
- def create_initial_population(size, num_cities):
- population = []
- for _ in range(size):
- individual = random.sample(range(num_cities), num_cities)
- # 确保重庆为起点
- individual.remove(chongqing_index)
- individual.insert(0, chongqing_index)
- population.append(individual)
- return population
-
- # 对种群进行排名
- def rank_population(population):
- # 按照路径总距离对种群进行排序
- return sorted([(i, calculate_distance(individual)) for i, individual in enumerate(population)], key=lambda x: x[1])
-
- # 选择交配池
- def select_mating_pool(population, ranked_pop, elite_size):
- # 选择排名前elite_size的个体作为交配池
- return [population[ranked_pop[i][0]] for i in range(elite_size)]
-
- # 繁殖新个体
- def breed(parent1, parent2):
- # 繁殖两个父母生成新个体
- geneA = int(random.random() * (len(parent1) - 1)) + 1
- geneB = int(random.random() * (len(parent1) - 1)) + 1
- start_gene = min(geneA, geneB)
- end_gene = max(geneA, geneB)
- child = parent1[:start_gene] + parent2[start_gene:end_gene] + parent1[end_gene:]
- child = list(dict.fromkeys(child))
- missing = set(range(len(parent1))) - set(child)
- for m in missing:
- child.append(m)
- # 确保重庆为起点
- child.remove(chongqing_index)
- child.insert(0, chongqing_index)
- return child
-
- # 突变个体
- def mutate(individual, mutation_rate):
- for swapped in range(1, len(individual) - 1):
- if random.random() < mutation_rate:
- swap_with = int(random.random() * (len(individual) - 1)) + 1
- individual[swapped], individual[swap_with] = individual[swap_with], individual[swapped]
- return individual
-
- # 生成下一代
- def next_generation(current_gen, elite_size, mutation_rate):
- ranked_pop = rank_population(current_gen)
- mating_pool = select_mating_pool(current_gen, ranked_pop, elite_size)
- children = []
- length = len(mating_pool) - elite_size
- pool = random.sample(mating_pool, len(mating_pool))
- for i in range(elite_size):
- children.append(mating_pool[i])
- for i in range(length):
- child = breed(pool[i], pool[len(mating_pool)-i-1])
- children.append(child)
- next_gen = [mutate(ind, mutation_rate) for ind in children]
- return next_gen
-
- # 遗传算法主函数
- def genetic_algorithm(population, pop_size, elite_size, mutation_rate, generations):
- pop = create_initial_population(pop_size, len(population))
- progress = [(0, rank_population(pop)[0][1], pop[0])] # 记录每代的最短距离和代数
- for i in range(generations):
- pop = next_generation(pop, elite_size, mutation_rate)
- best_route_index = rank_population(pop)[0][0]
- best_distance = rank_population(pop)[0][1]
- progress.append((i + 1, best_distance, pop[best_route_index]))
- best_route_index = rank_population(pop)[0][0]
- best_route = pop[best_route_index]
- return best_route, progress
-
- # 调整参数
- pop_size = 500 # 增加种群大小
- elite_size = 100 # 增加精英比例
- mutation_rate = 0.005 # 降低突变率
- generations = 20000 # 增加迭代次数
-
- # 运行遗传算法
- best_route, progress = genetic_algorithm(city_names, pop_size, elite_size, mutation_rate, generations)
-
- # 找到最短距离及其对应的代数
- min_distance = min(progress, key=lambda x: x[1])
- best_generation = min_distance[0]
- best_distance = min_distance[1]
-
- # 图1:地图上显示城市位置
- fig1, ax1 = plt.subplots(figsize=(10, 10))
- m1 = Basemap(projection='merc', llcrnrlat=18, urcrnrlat=50, llcrnrlon=80, urcrnrlon=135, resolution='l', ax=ax1)
- m1.drawcoastlines()
- m1.drawcountries()
- m1.fillcontinents(color='lightgray', lake_color='aqua')
- m1.drawmapboundary(fill_color='aqua')
- for i, (lat, lon) in enumerate(locations):
- x, y = m1(lon, lat)
- m1.plot(x, y, 'bo')
- ax1.text(x, y, str(i), fontsize=8)
- ax1.set_title('City Locations')
- plt.show()
-
- # 图2:适应度随迭代次数变化
- fig2, ax2 = plt.subplots(figsize=(10, 5))
- ax2.plot([x[1] for x in progress])
- ax2.set_ylabel('Distance (km)')
- ax2.set_xlabel('Generation')
- ax2.set_title('Fitness over Iterations')
- # 在图中标注最短距离和对应代数
- ax2.annotate(f'Gen: {best_generation}nDist: {best_distance:.2f} km',
- xy=(best_generation, best_distance),
- xytext=(best_generation, best_distance + 100),
- arrowprops=dict(facecolor='red', shrink=0.05))
- plt.show()
-
- # 图3:显示最优路径
- fig3, ax3 = plt.subplots(figsize=(10, 10))
- m2 = Basemap(projection='merc', llcrnrlat=18, urcrnrlat=50, llcrnrlon=80, urcrnrlon=135, resolution='l', ax=ax3)
- m2.drawcoastlines()
- m2.drawcountries()
- m2.fillcontinents(color='lightgray', lake_color='aqua')
- m2.drawmapboundary(fill_color='aqua')
-
- # 绘制最优路径和有向箭头
- for i in range(len(best_route) - 1):
- x1, y1 = m2(locations[best_route[i]][1], locations[best_route[i]][0])
- x2, y2 = m2(locations[best_route[i + 1]][1], locations[best_route[i + 1]][0])
- m2.plot([x1, x2], [y1, y2], color='g', linewidth=1, marker='o')
-
- # 只添加一个代表方向的箭头
- mid_index = len(best_route) // 2
- mid_x1, mid_y1 = m2(locations[best_route[mid_index]][1], locations[best_route[mid_index]][0])
- mid_x2, mid_y2 = m2(locations[best_route[mid_index + 1]][1], locations[best_route[mid_index + 1]][0])
- ax3.annotate('', xy=(mid_x2, mid_y2), xytext=(mid_x1, mid_y1), arrowprops=dict(facecolor='blue', shrink=0.05))
-
- # 在最优路径图上绘制城市位置
- for i, (lat, lon) in enumerate(locations):
- x, y = m2(lon, lat)
- m2.plot(x, y, 'bo')
- ax3.text(x, y, str(i), fontsize=8)
-
- # 添加起点和终点标记
- start_x, start_y = m2(locations[best_route[0]][1], locations[best_route[0]][0])
- end_x, end_y = m2(locations[best_route[-1]][1], locations[best_route[-1]][0])
- ax3.plot(start_x, start_y, marker='^', color='red', markersize=15, label='Start (Chongqing)') # 起点
- ax3.plot(end_x, end_y, marker='*', color='blue', markersize=15, label='End') # 终点
-
- # 添加总距离的图例
- ax3.legend(title=f'Total Distance: {best_distance:.2f} km')
-
- ax3.set_title('Optimal Path')
- plt.show()
-
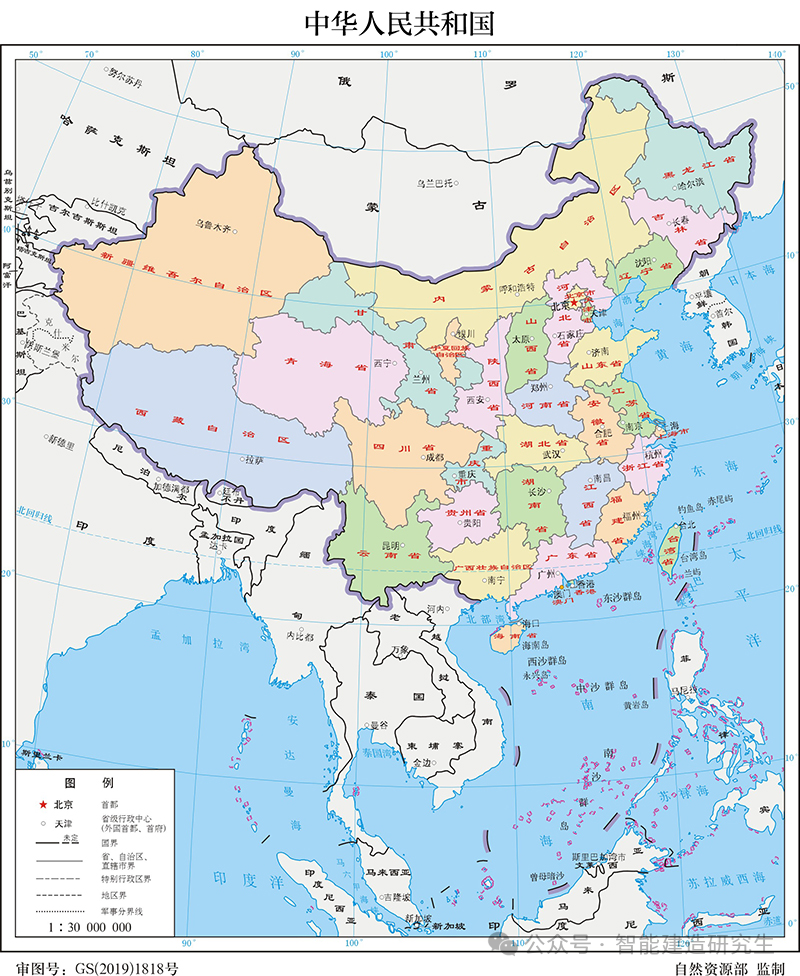
Visualização da localização de todas as capitais provinciais da China:
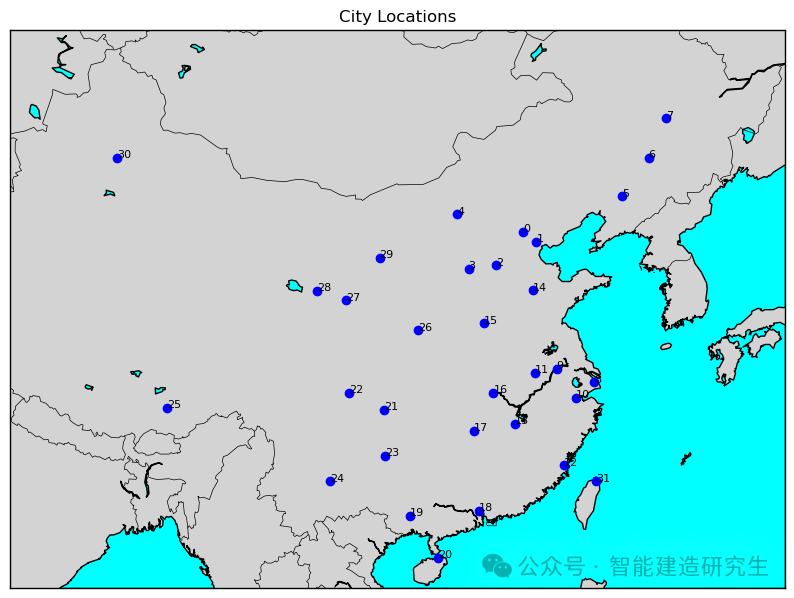
O número de iterações é 2.000 (a distância mais curta é 31.594 quilômetros):
Encontre a iteração do caminho mais curto no processo de iteração histórica e visualize o caminho mais curto.
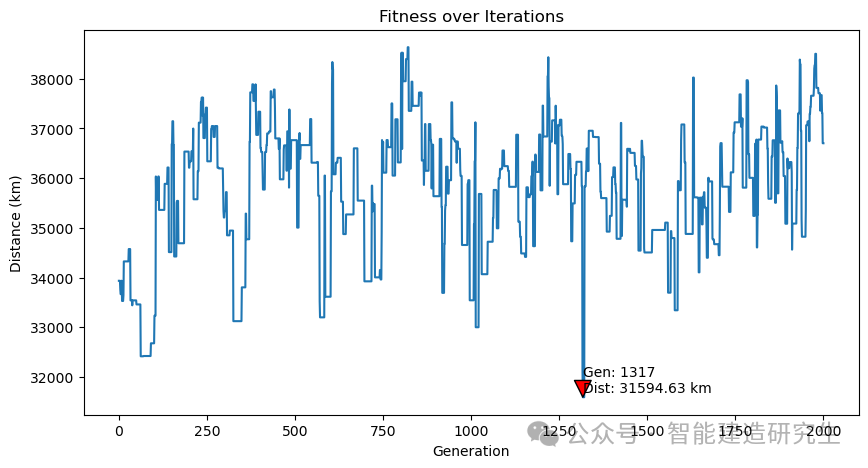
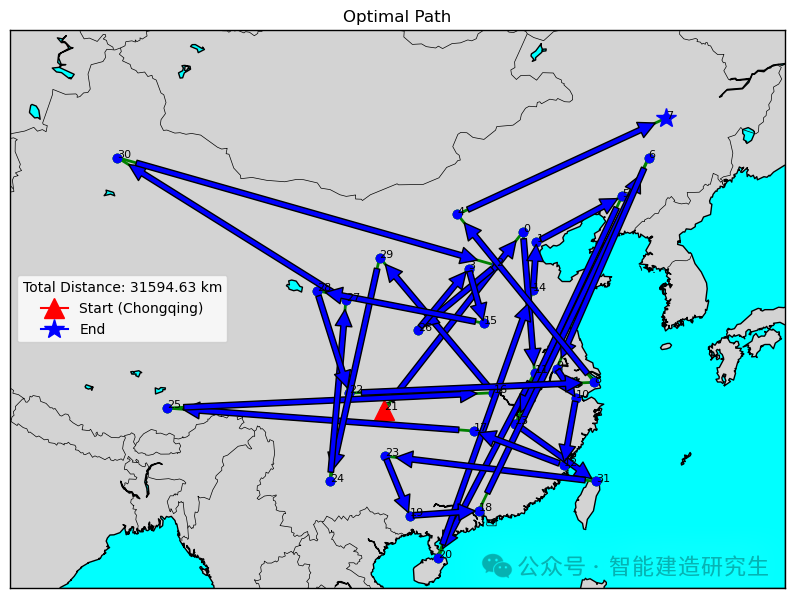
Caso 2: O número de iterações é 20.000 (a menor distância obtida é 29.768 quilômetros)
Encontre a iteração com o caminho mais curto no processo de iteração histórica e visualize o caminho mais curto para essa iteração.
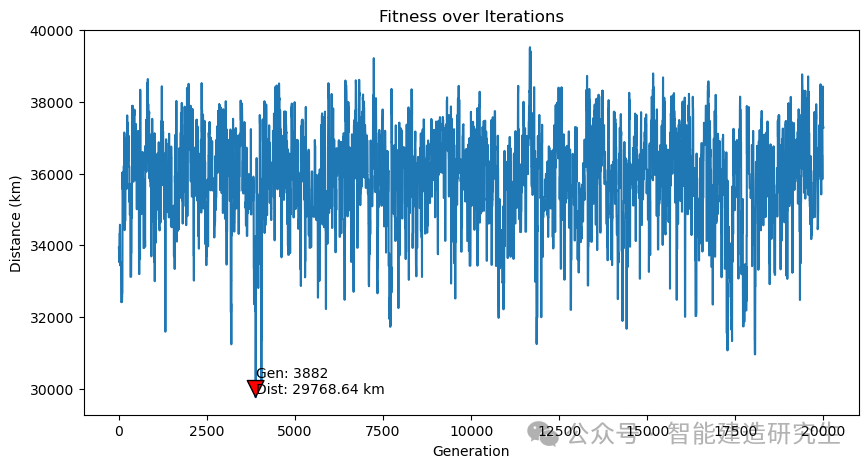
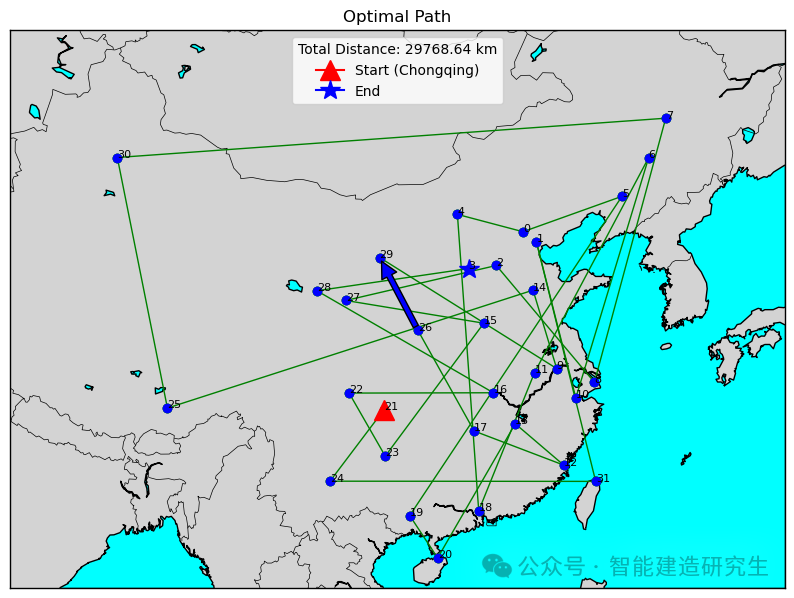
O conteúdo acima foi resumido da Internet. Se for útil, encaminhe-o na próxima vez!

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondênciamesophia@protonmail.com