내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
K8s 오프라인 배포

k8s 오프라인 배포
자세한 내용은 "Docker의 오프라인 설치 및 백엔드 프로젝트의 오프라인 패키징" 문서를 참조하세요.
https://blog.csdn.net/qq_45371023/article/details/140279746?spm=1001.2014.3001.5501
사용된 모든 파일은 다음 위치에 있습니다.
링크: https://pan.baidu.com/s/10cb-dXkgdShdjPEBCyvTrw?pwd=fpuy
추출 코드: fpuy
1. cri_dockerd 설치
rpm -ivh cri-dockerd-0.3.9-3.el8.x86_64.rpm

2. 시스템 데몬 다시 로드 → cri-dockerd가 자동으로 시작되도록 설정 → cri-dockerd 시작
시스템 데몬 다시 로드
sudo systemctl daemon-reload
cri-dockerd가 자동으로 시작되도록 설정
sudo systemctl enable cri-docker.socket cri-docker
cri-dockerd 시작
sudo systemctl start cri-docker.socket cri-docker
sudo systemctl status cri-docker.socket
sudo systemctl status cri-docker
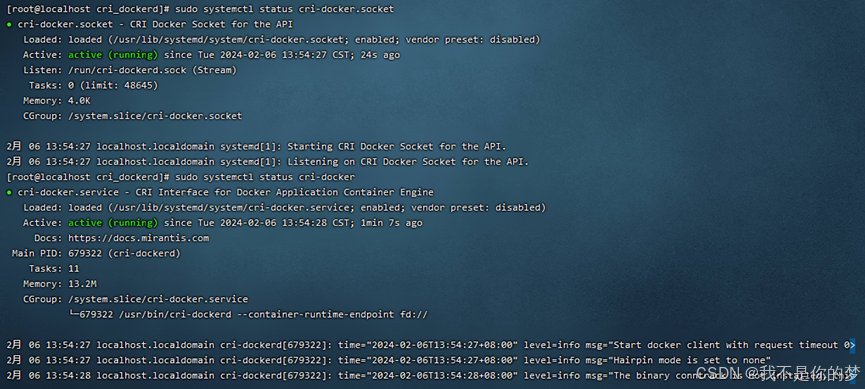
문제: cri-docker를 시작하지 못했습니다.
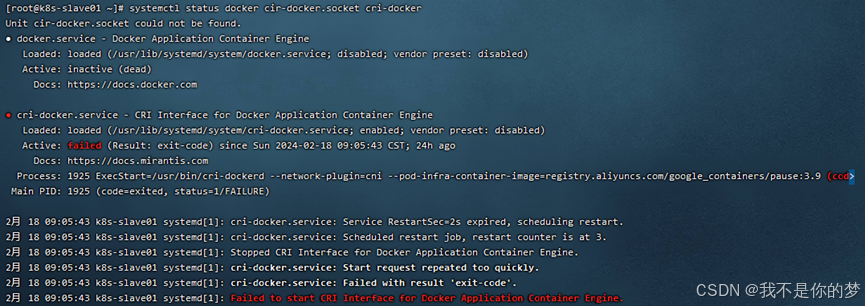
측정하다:
방법 1: systemctl restart docker # 다시 시작 docker
방법 2: docker를 제거하고 다시 설치한 후 위 단계를 다시 수행합니다.
1. kubectl 설치
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
2. 설치가 완료되었는지 확인하세요
kubectl version --client

3. 포트를 열거나 방화벽을 닫습니다. (원활한 설치 과정을 보장하기 위해)
개방형 포트(클라우드 서버)
포트 6443 열기
sudo firewall-cmd --zone=public --add-port=6443/tcp --permanent
방화벽 다시 로드
sudo firewall-cmd --reload
열려 있는 모든 포트 보기
sudo firewall-cmd --zone=public --list-ports
아니면 방화벽(가상머신)을 끄세요
방화벽 끄기
sudo systemctl stop firewalld
방화벽 자동 시작 끄기
sudo systemctl disable firewalld
4. SELinux를 비활성화합니다(컨테이너가 시스템 리소스에 액세스할 수 있는지 확인).
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
5. kubeadm, kubelet, kubectl 설치
3_yum_package 아래에 있는 관련 오프라인 설치 패키지를 rpm 형식으로 다운로드합니다. 이 명령을 사용하여 디렉터리에 모든 rpm 설치 패키지를 설치합니다.
cd 3_yum_package && rpm -ivh *.rpm
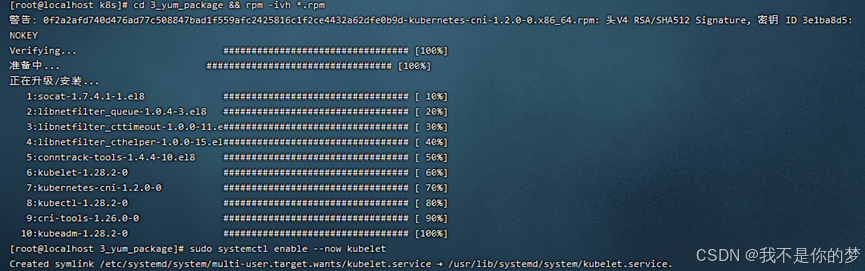
6. kubelet이 자동으로 시작되도록 설정
sudo systemctl enable --now kubelet

위의 단계를 완료하면 다음과 같은 환경이 생성됩니다.
·IP 주소가 다른 두 서버 또는 가상 머신은 서로 통신하고 LAN 상태를 유지할 수 있습니다. IP 주소는 192.168로 설정됩니다..34 및 192.168..35
·컨테이너 런타임(Docker+cri_dockerd)이 두 서버 모두에 설치되고 kubernetes 구성 요소인 kubectl, kubeadm 및 kubelet이 설치되었습니다.
7. 스왑 파티션을 닫습니다. 이는 임시 종료와 영구 종료로 나누어지며, 가상 머신 환경에서는 자주 켜지고 꺼지기 때문에 영구 종료를 권장하며, 클라우드 환경에서는 임시 종료를 권장합니다.
스왑 파티션을 일시적으로 닫습니다.
swapoff -a
스왑 파티션을 영구적으로 닫으려면 fstab에서 스왑이 포함된 줄을 주석 처리하세요.
vi /etc/fstab
# /dev/mapper/centos-swap 스왑 스왑 기본값 0 0
다시 시작하면 cri-dockerd의 상태가 변경될 수 있습니다. 실제 배포에서는 다시 시작을 선택하지 않았는데, 이유는 docker를 다시 설치하면 됩니다. cri-dockerd를 실행한 다음 cri-dockerd를 시작하여 cri -dockerd 상태를 정상으로 만듭니다.
재부팅하다
8. k8s 운영 환경으로 runc를 설치합니다.
Runc 설치
sudo install -m 755 runc.amd64 /usr/local/bin/runc
# 설치가 잘 되었는지 확인
runc -v

9. Docker 및 cri-dockerd 국내 이미지 가속 설정(이 폴더에서 사용할 다음 소프트웨어 패키지의 이름에는 미러 주소가 있으므로 kubectl이 인터넷에서 소프트웨어 패키지를 가져오도록 요구하고 이후 로컬 미러를 무시하지 않도록 LAN에서도 해당 미러 가속을 구성하는 것이 좋습니다. 설치가 완료되었습니다.)
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://tsvqojsz.mirror.aliyuncs.com"]
}
EOF
# 找到第10行
vi /usr/lib/systemd/system/cri-docker.service
# 修改为ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
Docker 구성 요소 다시 시작
systemctl daemon-reload && systemctl restart docker cri-docker.socket cri-docker
# Docker 구성 요소 상태 확인
systemctl status docker cir-docker.socket cri-docker
10. 호스트 이름과 호스트를 확인하세요
마스터 노드
호스트 이름은 k8s-master입니다
vi /etc/hostname
도메인 이름 매핑 추가
echo "192.168.**.35 k8s-slave01">> /etc/hosts
기타 노드
호스트 이름은 k8s-slave01입니다
vi /etc/hostname
도메인 이름 매핑 추가
echo "192.168.**.34 k8s-master" >> /etc/hosts
11. IPv4를 전달하고 iptables가 브리지 흐름을 확인하도록 합니다.
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
재부팅 후에도 지속되는 필수 sysctl 매개변수 설정
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
#다시 시작하지 않고 sysctl 매개변수 적용
sudo sysctl --system
lsmod | grep br_netfilter
lsmod | grep overlay
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
# 초기화 중에 iptables 오류가 계속 표시되면 다음을 실행하세요.
echo "1">/proc/sys/net/bridge/bridge-nf-call-iptables
echo "1">/proc/sys/net/ipv4/ip_forward
12. 마스터 노드 초기화
초기화하기 전에 kubeadm config 이미지를 통해 초기화에 필요한 도커 이미지를 가져와야 합니다.

이미지 docker load -i **.tar 설치
관련 이미지 파일은 5_kubeadm-images에 존재합니다.
초기화를 수행합니다.
kubeadm init --node-name=k8s-master list--image-repository=registry.aliyuncs.com/google_containers --cri-socket=unix:///var/run/cri-dockerd.sock --apiserver-advertise-address=192.168.**.34 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
–image-repository=registry.aliyuncs.com/google_containers # 다운로드한 컨테이너 이미지 소스를 Alibaba Cloud로 대체합니다. 그렇지 않으면 네트워크상의 이유로 이미지를 풀다운할 수 없으며 실행이 확실히 실패합니다.
–cri-socket=unix:///var/run/cri-dockerd.sock # Containerd도 Docker의 구성 요소 중 하나이기 때문에 이는 지정된 컨테이너 런타임입니다. Docker를 다운로드하면 초기화를 수행할 때에도 Containerd가 다운로드됩니다. 여러 컨테이너 런타임 환경이 있음을 감지하면 수동으로 하나를 선택해야 합니다. 또한 여기서는 Containerd가 실제로 Docker보다 훨씬 가볍다는 것을 알 수 있습니다.
–apiserver-advertise-address=192.168.56.50 # API 서버의 브로드캐스트 주소를 설정합니다. 여기서 로컬 IPv4 주소를 선택합니다. API SERVER를 다른 노드에 설정하지 않으려면 다른 주소로 변경하지 마세요.
–pod-network-cidr=10.244.0.0/16 # Pod 네트워크에서 사용할 수 있는 IP 주소 범위를 지정합니다. 아직 확실하지 않은 경우 무시하고 이 값을 사용할 수 있습니다.
–service-cidr=10.96.0.0/12 # 서비스의 가상 IP 주소에 대한 추가 IP 주소 세그먼트를 지정하십시오. 아직 확실하지 않은 경우 이 값을 사용하면 됩니다.
문제: cordns:v1.10.1 검사가 존재하지 않습니다. 실제로 cordns:v1.10.1이 이미 존재하지만 cordns:1.10.1입니다.
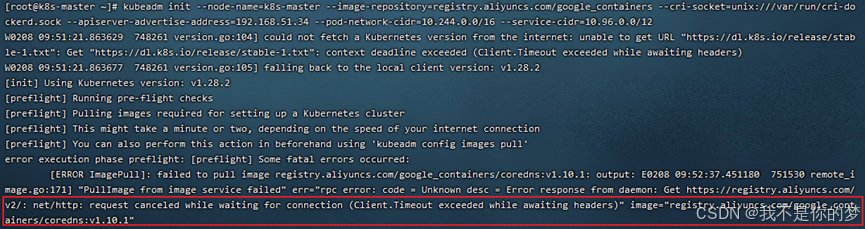
조치: 코드 태그를 수정합니다.
docker tag registry.aliyuncs.com/google_containers/coredns:1.10.1 registry.aliyuncs.com/google_containers/coredns:v1.10.1
초기화 명령을 다시 실행하십시오.
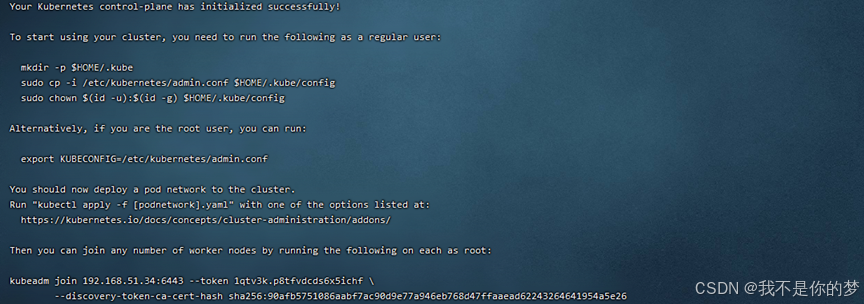
노드 조인에 필요한 kubeadm Join 아래 정보를 기록합니다. 위 예시에 대한 관련 정보는 다음과 같습니다.
kubeadm join 192.168.51.34:6443 --token 1qtv3k.p8tfvdcds6x5ichf
--discovery-token-ca-cert-hash sha256:90afb5751086aabf7ac90d9e77a946eb768d47ffaaead62243264641954a5e26
잊어버린 경우 kubeadm token list를 사용하여 토큰이 24시간 동안 존재하는지 쿼리하고 kubeadm token create --print-join-command를 다시 생성한 후 kubeadm token delete tokenid를 사용하여 삭제할 수 있습니다.
루트가 아닌 사용자는 실행하십시오.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
루트 사용자가 직접 실행
일시적으로 적용되며 다시 시작하면 무효화됩니다.
export KUBECONFIG=/etc/kubernetes/admin.conf
이는 영구적으로 적용됩니다. kubeadm Reset 및 init를 다시 실행한 후에는 이 명령을 다시 실행할 필요가 없습니다.
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
영구적으로 유효한 명령을 실행한 후에는 해당 명령을 소싱하여 유효하게 만들어야 합니다.
source ~/.bash_profile
구성이 유효한지 확인
echo $KUBECONFIG
/etc/kubernetes/admin.conf
13. 네트워크 플러그인 설치 및 구성
여기서 플란넬은 kube-flannel.yml 파일을 서버에 다운로드하고 업로드하는 데 사용됩니다.
설치를 위해 해당 이미지를 서버에 업로드합니다. kube-flannel.yml 및 이미지 파일은 6_kube-flannel에 있습니다.
네트워크 카드 쿼리
이프컨피그
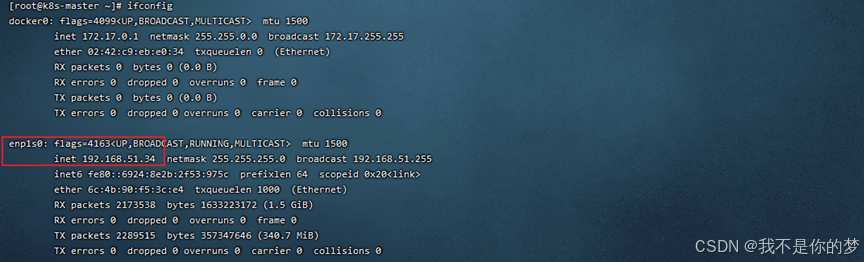
kube-flannel.yml은 기본적으로 enp1s0 네트워크 카드를 찾습니다. 이 예에서 34 네트워크 카드는 enp1s0이며 수정할 필요가 없습니다.
//kube-flannel.yml을 35로 수정하고 –iface=enp0s3을 추가하여 지정합니다(여기서 enp0s3은 위 상자의 부분과 같이 IP에 해당하는 네트워크 카드입니다). 매개변수 위치는 다음과 같습니다.
container:
......
command:
- /opt/bin/flanneld
arg:
- --ip-masq
- --kube-subnet-mgr
- --iface=enp4s0
Kubernetes용 플란넬 네트워크 플러그인 구성
kubectl apply -f /data/k8s/6_kube-flannel/kube-flannel.yml

cat /run/flannel/subnet.env
# 해당 파일이나 폴더가 없으면 수동으로 생성해야 합니다. 내용은 아래와 같습니다.
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
14. 노드 노드가 마스터에 합류
14.1. 마스터 노드 머신의 /etc/kubernetes/admin.conf를 슬레이브 노드 머신에 복사합니다.
scp /etc/kubernetes/admin.conf 192.168.56.51:/etc/kubernetes/
# 영구적으로 적용하려면 여기에서 직접 admin.conf를 추가하는 것을 잊지 마세요.
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
복사하는 동안 문제가 있는 경우:
192.168.55.187에 대한 ECDSA 호스트 키가 변경되었으며 엄격한 검사를 요청했습니다. 호스트 키 검증에 실패했습니다.
복구하려면 다음 명령문을 실행하십시오.
ssh-keygen -R 192.168.55.187
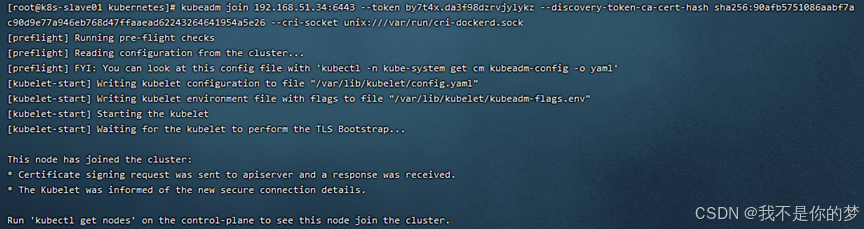
14.2. Join 명령을 실행합니다. (마스터 노드가 성공적으로 초기화된 후 Join 명령이 주어집니다.)
예를 들어:
kubeadm join 192.168.51.34:6443 --토큰 by7t4x.da3f98dzrvjylykz --발견 토큰 ca 인증서 해시 sha256:90afb5751086aabf7ac90d9e77a946eb768d47ffaaead62243264641954a5e26 --cri 소켓 unix:///var/run/cri-dockerd.sock
14.3. kubectl get 노드 실행

k8s 클러스터가 성공적으로 배포되었습니다! ! !
kubectl 노드 얻기
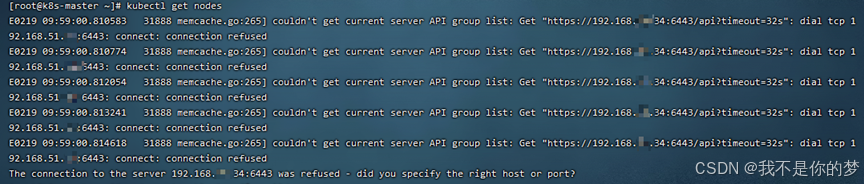
조치: 스왑이 닫혀 있는지 확인하고 방화벽이 포트 6443을 여는지 확인하세요.
교환 닫기

일시적으로 방화벽을 끄십시오.

성공

kubectl 노드 얻기
클러스터에 k8s 노드를 추가한 후 노드 상태가 NotReady인지 확인하세요.

측정하다:
systemctl restart kubelet.service
systemctl restart docker.service
kubelet 및 docker 다시 시작

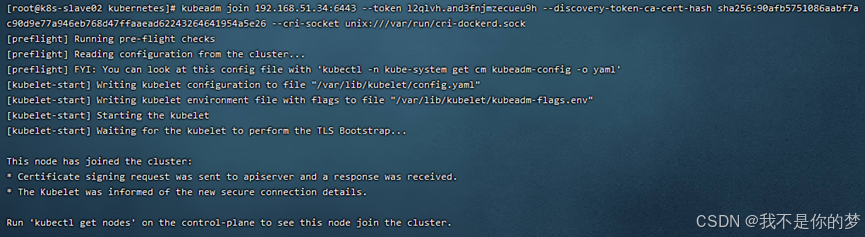
kubeadm은 192.168.51.34:6443 --토큰 l2qlvh.and3fnjmzecueu9h --검색 토큰 ca 인증서 해시 sha256:90afb5751086aabf7ac90d9e77a946eb768d47ffaaead62243264641954a5e26 --cri 소켓 unix:///var/run/cri-dockerd.sock에 가입합니다.
k8s 클러스터에 하위 노드를 추가할 때 초기화 시간 초과가 발생합니다.

측정하다:
kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sock
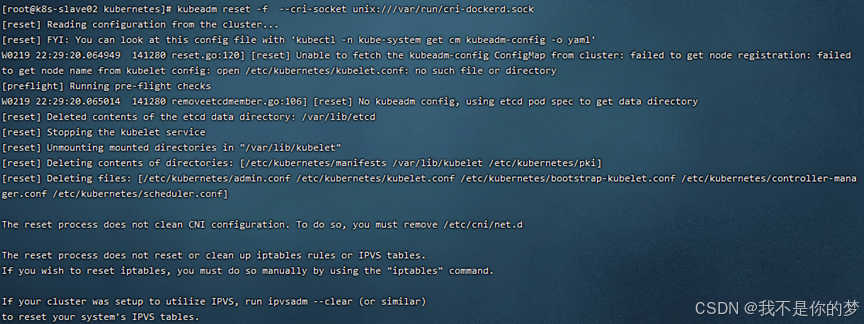
성공

마스터 노드 머신의 /etc/kubernetes/admin.conf를 슬레이브 노드 머신에 복사합니다.
scp /etc/kubernetes/admin.conf 192.168.55.187:/etc/kubernetes/
파일 복사에 실패할 경우 오류 메시지는 다음과 같습니다.
192.168.55.187에 대한 ECDSA 호스트 키가 변경되었으며 엄격한 검사를 요청했습니다.
호스트 키 확인에 실패했습니다.
복구하려면 다음 명령문을 실행하십시오.
ssh-keygen -R 192.168.55.187
kubectl delete node k8s-slave01
kubectl delete node k8s-slave02
kubectl delete node k8s-master
슬레이브 노드
rm -rf /etc/kubernetes/*
kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
마스터 노드
rm -rf /etc/kubernetes/*
rm -rf ~/.kube/*
rm -rf /var/lib/etcd/*
kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sock
필요한 경우 k8s 클러스터를 다시 초기화합니다.
kubeadm init --node-name=k8s-master --image-repository=registry.aliyuncs.com/google_containers --cri-socket=unix:///var/run/cri-dockerd.sock --apiserver-advertise-address=192.168.51.34 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
마스터 노드
kubectl apply -f /data/k8s/6_kube-flannel/kube-flannel.yml
kubectl get pod -A
마스터 노드
scp /etc/kubernetes/admin.conf 192.168.51.35:/etc/kubernetes/
scp /etc/kubernetes/admin.conf 192.168.51.36:/etc/kubernetes/
슬레이브 노드
kubeadm join 192.168.51.34:6443 --token 1k9kdy.dvn2qbtd7rjar1ly
--discovery-token-ca-cert-hash sha256:ff90d8ed41ae1902a839194f179a1c3ba8374a5197ea3111e10e5ca1c09fa442 --cri-socket unix:///var/run/cri-dockerd.sock
kubectl get pod -A
kubectl get nodes

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에서 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com