
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Размещены ли объекты в Java в куче памяти?
Ладно, это слишком абстрактно. Давайте посмотрим, где выделяется память следующего объекта?
- public void test() {
- Object object = new Object();
- }
- 这个方法中的object对象,是在堆中分配内存么?
Произнесите результат: объект может выделять память в стеке или в куче.
Вот ключевой момент: в реализации JVM, чтобы улучшить производительность JVM и сэкономить место в памяти, JVM предоставляет функцию, называемую «анализ побега». Анализ побега является относительно передовой технологией оптимизации на данный момент. Виртуальная машина Java, а также JIT. Очень важный метод оптимизации. jdk6 только начал внедрять эту технологию, jdk7 начал включать escape-анализ по умолчанию, jdk8 начал улучшать escape-анализ и включил его по умолчанию. До JDK 9 escape-анализ будет использоваться в качестве метода оптимизации по умолчанию, без каких-либо специальных параметров компиляции. необходимы.
Теперь поймите предложение «объект может выделять память в стеке или выделять память в куче». До jdk7 объект здесь должен выделять память в куче, в jdk7 и 8 можно выделять память в стеке, потому что jdk7; начал поддерживаться только Escape-анализ; jdk9, скорее всего, выделяется в стеке (объект здесь очень маленький), потому что jdk9 по-настоящему поддерживает и включает Escape-анализ только по умолчанию.
С развитием JIT-компиляторов (компиляторов «точно в срок») и постепенной зрелости технологии escape-анализа технология оптимизации распределения стека и скалярной замены приведет к тому, что «все объекты будут размещаться в куче» станут менее абсолютными в Java In. В виртуальной машине объектам выделяется память в куче, но есть особый случай, то есть, если после escape-анализа обнаруживается, что объект не выходит из метода, его можно оптимизировать для размещения в стеке. Когда метод выполняется. По завершении кадр стека извлекается и объект освобождается. Это устраняет необходимость выделять память в куче и выполнять сборку мусора ().Hotspot в настоящее время этого не делает.). Это также наиболее распространенная технология хранения вне кучи.
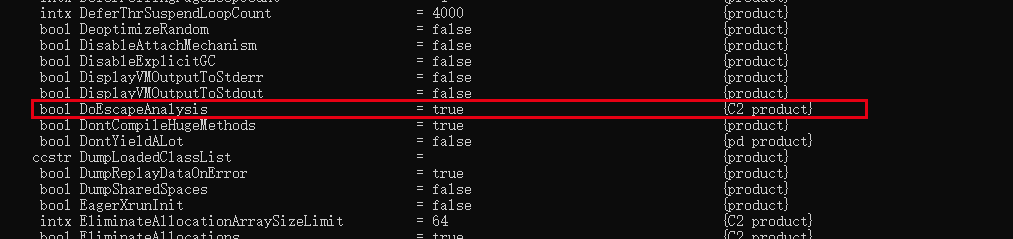
После JDK 6u23 (запоминающаяся основная версия JDK7) escape-анализ включен по умолчанию в Hotspot. Если вы используете более раннюю версию, вы можете отобразить escape-анализ с помощью параметра «-XX:+DoEscapeAnalysis». Просмотрите результаты фильтрации для анализа побега.
Hotspot реализует скалярную замену посредством escape-анализа (неэкранированные объекты заменяются скалярами и агрегатами, что может повысить эффективность кода), но неэкранированные объекты по-прежнему будут выделять память в куче, поэтому можно сказать, что все объекты распределяются. память в куче.
Кроме того, глубоко настроен на основе Open JDK.ТаоБао ВМ, среди которых инновационная технология GCIH (GC invisible heap) реализует вне кучи перемещение объектов с длительным жизненным циклом из кучи за пределы кучи, а GC не управляет объектами Java внутри GCIH, тем самым уменьшая частоту повторного использования GC и улучшая цель. эффективности восстановления GC.
Куча: При выполнении каждого метода одновременно создается кадр стека для хранения такой информации, как таблицы локальных переменных, стеки операций, динамические соединения, выходы из методов и т. д. Процесс от вызова каждого метода до завершения выполнения соответствует процессу перемещения кадра стека в стек до извлечения из стека в стеке виртуальной машины.
куча:Когда создается экземпляр объекта, он размещается в куче, а ссылка на кучу помещается в стек.
побег:Когда на указатель на объект ссылаются несколько методов или потоков, мы говорим, что указатель экранируется. Обычно возвращаемые объекты и глобальные переменные обычно экранируются.
Анализ побега:Метод, используемый для анализа этого явления побега, называется анализом побега.
Оптимизация Escape-анализа — размещение в стеке:Распределение в стеке означает, что экземпляр, созданный локальной переменной в методе (без экранирования), выделяется в стеке и его не нужно размещать в куче. После завершения выделения выполнение продолжается в стеке вызовов. Наконец, поток завершается, пространство стека перерабатывается, а также перерабатываются локальные объекты Variable.


Ответ: Не обязательно.
Если условия escape-анализа соблюдены, объект можно разместить в стеке.Уменьшите выделение памяти в куче и нагрузку на сборщик мусора.Поскольку память стека ограничена, если объект удовлетворяет условиям скалярной замены,Дальнейшая операция проводится над предметом по разбиению его на части.Конкретный метод скалярной замены: JVM далее разбивает объект и разлагает его на несколько переменных-членов, используемых этим методом.Таким образом, достигается цель лучшего использования памяти стека и регистров.
Это межфункциональный алгоритм анализа глобального потока данных, который может эффективно снизить нагрузку на синхронизацию и нагрузку на выделение кучи памяти в программах Java. Посредством escape-анализа компилятор Java Hotspot может проанализировать диапазон использования ссылки на новый объект и решить, следует ли помещать объект в кучу.
Основное поведение escape-анализа заключается в анализе динамической области объектов:
В принципе оптимизации компилятора компьютерного языка escape-анализ относится к методу анализа динамического диапазона указателей. Он связан с анализом указателей и анализом формы принципа оптимизации компилятора. Когда переменная (или объект) выделяется в методе, ее указатель может быть возвращен или на него можно ссылаться глобально, на который будут ссылаться другие методы или потоки. Это явление называется экранированием указателя (или ссылки). С точки зрения непрофессионала, если на указатель объекта ссылаются несколько методов или потоков, мы называем указатель объекта (или объект) Escape (поскольку в этот момент объект выходит из локальной области действия метода или потока).
Краткое описание: «Escape-анализ: статический анализ, определяющий динамический диапазон указателей. Он может анализировать, где в программе можно получить доступ к указателю». В контексте JVM-компиляции escape-анализ определит, будет ли вновь созданный объект ускользает.
Основа для своевременной компиляции для определения того, ускользает ли объект: один — хранится ли объект в куче (статическое поле или поле экземпляра объекта в куче), а другой — передается ли объект в кучу. неизвестный код.
Escape Analysis в настоящее время является относительно передовой технологией оптимизации виртуальных машин Java. Как и анализ отношений наследования типов, это не средство прямой оптимизации кода, а технология анализа, которая обеспечивает основу для других средств оптимизации.
Escape-анализ: это очень важная технология JIT-оптимизации, используемая для определения того, будет ли объект доступен вне метода, то есть для выхода из области действия метода. Escape-анализ — это этап JIT-компилятора. С помощью JIT мы можем определить, какие объекты могут быть ограничены для использования внутри метода и не будут выходить наружу. Затем их можно оптимизировать, например, разместить их в стеке, а не в куче. Или выполните скалярную замену, чтобы разделить объект на несколько базовых типов для хранения. Это межфункциональный алгоритм анализа глобального потока данных, который может эффективно снизить нагрузку на синхронизацию, распределение кучи памяти и нагрузку на сборку мусора в программах Java. С помощью escape-анализа компилятор Java Hotspot может проанализировать диапазон использования ссылки на новый объект и решить, следует ли помещать этот объект в кучу.
Escape-анализ в основном фокусируется на локальных переменных, чтобы определить, вышли ли объекты, размещенные в куче, за пределы области действия метода. Это связано с анализом указателей и анализом формы принципов оптимизации компилятора. Когда переменная (или объект) выделяется в методе, ее указатель может быть возвращен или на него можно ссылаться глобально, на который будут ссылаться другие методы или потоки. Это явление называется экранированием указателя (или ссылки). С точки зрения непрофессионала, если на указатель объекта ссылаются несколько методов или потоков, мы говорим, что указатель объекта ускользнул. Правильное проектирование структуры кода и использования данных позволяет лучше использовать escape-анализ для оптимизации производительности программы. Мы также можем уменьшить накладные расходы на размещение объектов в куче и улучшить использование памяти с помощью escape-анализа.
Escape-анализ — это метод, используемый для определения того, вышел ли объект за пределы области действия метода в течение своего существования. При разработке Java escape-анализ используется для определения жизненного цикла и объема объектов с целью выполнения соответствующей оптимизации и повышения производительности программы и эффективности использования памяти.
Когда объект создается, его можно использовать внутри метода или передать другим методам или потокам и продолжать существовать вне метода. Если объект не выходит за пределы области действия метода, JVM может разместить его в стеке, а не в куче, избегая таким образом накладных расходов на выделение памяти в куче и сборку мусора.
- 关于逃逸分析的论文在1999年就已经发表,但直到Sun JDK 1.6才实现了逃逸分析,而且直到现在这项优化尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是不能保证逃逸分析的性能收益必定高于它的消耗。如果要完全准确的判断一个对象是否会逃逸,需要进行数据流敏感的一系列复杂分析,从而确定程序各个分支执行时对此对象的影响。这是一个相对高耗时的过程,如果分析完后发现没有几个不逃逸的对象,那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小的算法来完成逃逸分析。还有一点是,基于逃逸分析的一些优化手段,如上面提到的“栈上分配”,由于HotSpot虚拟机目前的实现方式导致栈上分配实现起来比较复杂,因此在HotSpot中暂时还没有做这项优化。
- 在测试结果中,实施逃逸分析后的程序在MicroBenchmarks中往往能运行出不错的成绩,但是在实际的应用程序,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或因分析过程耗时但却无法有效判别出非逃逸对象而导致性能(即使编译的收益)有所下降,所以在很长的一段时间里,即使是Server Compiler,也默认不开启逃逸分析(在JDK 1.6 Update 23的Server Compiler中才开始默认开启了逃逸分析),甚至在某些版本(如JDK 1.6 Update 18)中还曾经短暂的完全禁止了这项优化。
- 如果有需要,并且确认对程序运行有益,用户可以使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析,开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数-XX:EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:PrintEliminateAllocations查看标量的替换情况。
- 尽管目前逃逸分析的技术仍不是十分成熟,但是他却是即时编译器优化技术的一个重要的方向,在今后的虚拟机中,逃逸分析技术肯定会支撑起一系列使用有效的优化技术。
Основной принцип анализа побега JVM заключается в определении ситуации побега объекта с помощью двух методов анализа: статического и динамического.
В системе компиляции Java процесс преобразования файла исходного кода Java в машинную инструкцию, исполняемую компьютером, требует двух этапов компиляции:
Первый раздел компиляции относится к интерфейсному компилятору..java-файлконвертировано вфайл .class (файл байт-кода). Продуктами внешнего компилятора могут быть Javac JDK или инкрементный компилятор Eclipse JDT.
На втором этапе компиляции JVM интерпретирует байт-код и транслирует его в соответствующие машинные инструкции, считывает байт-код один за другим, а затем интерпретирует и переводит его в машинный код один за другим.
Очевидно, что из-за промежуточного процесса интерпретации скорость его выполнения неизбежно будет намного медленнее, чем у исполняемой программы с двоичным байт-кодом. Это функция традиционного интерпретатора JVM (Интерпретатора).
Для решения этой проблемы эффективности была внедрена технология JIT (Just In Time Compiler).
После внедрения технологии JIT Java-программы по-прежнему интерпретируются и выполняются через интерпретатор. То есть основное тело по-прежнему интерпретируется и выполняется, но промежуточные звенья частично удаляются.
JIT Compiler (Just-in-timeCompiler) компиляция «точно в срок». Самое раннее решение по реализации Java состояло из набора трансляторов (интерпретаторов), которые транслировали каждую инструкцию Java в эквивалентную инструкцию микропроцессора и выполняли их последовательно в соответствии с порядком перевода инструкций, поскольку инструкция Java могла быть переведена в дюжину или десятки команд. эквивалентных инструкций микропроцессора, этот режим выполняется очень медленно.
Когда JVM обнаруживает, что определенный метод или блок кода выполняется особенно часто, она будет считать это «кодом горячей точки». Затем JIT преобразует часть «горячего кода» в машинный код, относящийся к локальной машине, оптимизирует его, а затем кэширует переведенный машинный код для следующего использования.
Где кэшировать переведенный машинный код? Этот кеш называется кэшем кода. Видно, что методы достижения высокого уровня параллелизма между JVM и WEB-приложениями схожи, и они по-прежнему используют архитектуру кэша.
Когда JVM в следующий раз встретит тот же «горячий» код, она пропускает промежуточную ссылку интерпретации, загружает машинный код непосредственно из кэша кода и выполняет его напрямую, без повторной компиляции.
Таким образом, общая цель JIT — обнаружение «горячего» кода, а «горячий» код стал ключом к повышению производительности. Именно так появилось название «горячая точка» JVM. Идентификация «горячего» кода и запись его имени — это дело всей жизни.
Таким образом, общая стратегия JVM такова:
Для большинства необычных кодов нам не нужно тратить время на их компиляцию в машинный код, а проводить их интерпретацию и выполнение;
С другой стороны, горячий код, занимающий лишь небольшую часть, можно скомпилировать в машинный код, чтобы добиться идеальной скорости работы.
Появление JIT (JIT-компиляция) и разница между интерпретаторами
(1) Интерпретатор интерпретирует байт-код в машинный код. Даже если в следующий раз он встретит тот же байт-код, он все равно выполнит повторную интерпретацию.
(2) JIT компилирует некоторые байт-коды в машинные коды и сохраняет их в кэше кода. При следующем обнаружении того же кода он будет выполнен напрямую без повторной компиляции.
(3) Интерпретатор интерпретирует байт-код в машинный код, общий для всех платформ.
(4) JIT сгенерирует машинный код для конкретной платформы в зависимости от типа платформы.
JVM содержит несколько JIT-компиляторов, в основном C1 и C2, а также Graal (экспериментальный).
Несколько JIT-компиляторов оптимизируют байт-код и генерируют машинный код.
JVM делит статус выполнения на 5 уровней:
Уровень 0, Переводчик
Уровень 1, скомпилирован и выполнен с использованием JIT-компилятора C1 (без профилирования).
Уровень 2, скомпилирован и выполнен с использованием JIT-компилятора C1 (с базовым профилированием).
Уровень 3, скомпилированный и выполненный с использованием JIT-компилятора C1 (с полным профилированием).
Уровень 4, компилируется и выполняется с использованием JIT-компилятора C2.
JVM не включает C2 напрямую. Вместо этого она сначала собирает статус работы программы посредством компиляции C1, а затем на основе результатов анализа определяет, следует ли включать C2.
В режиме многоуровневой компиляции статус выполнения виртуальной машины делится на пять уровней: от простого к сложному, от быстрого к медленному.
Во время компиляции, помимо кэширования горячего кода для ускорения процесса, JIT также выполняет множество оптимизаций кода.
Целью некоторых оптимизаций являетсяУменьшите нагрузку на распределение кучи памяти Один из важных методов JIT-оптимизации называется escape-анализом. Согласно escape-анализу, JIT-компилятор в процессе компиляции оптимизирует код следующим образом:
Он проверяет статическую структуру кода, чтобы определить, может ли объект покинуть объект. Например, когда объект присваивается переменной-члену класса или возвращается внешнему методу, можно определить, что объект экранируется.
Он определяет, ускользает ли объект, наблюдая за поведением вызовов методов и ссылок на объекты. Например, если на объект ссылаются несколько потоков, можно считать, что объект ускользнул.
Escape-анализ выполняет углубленный анализ кода, чтобы определить, вышел ли объект за пределы области действия метода во время его существования. Если объект не уходит, JVM может разместить его в стеке, а не в куче.
Объект имеет три состояния escape: глобальное escape, escape параметра и отсутствие escape.
глобальный побег(GlobalEscape): то есть область действия объекта выходит за пределы текущего метода или текущего потока.
Обычно существуют следующие сценарии:
① Объект является статической переменной.
② Объект – это объект, который сбежал
③ Объект используется как возвращаемое значение текущего метода.
Экранирование параметров(ArgEscape): то есть объект передается как параметр метода или на него ссылается параметр, но во время вызывающего процесса глобальное экранирование не происходит. Это состояние определяется байт-кодом вызываемого метода.
Побег невозможен: То есть объект в методе не экранируется.
Пример кода состояния выхода выглядит следующим образом:
- public class EscapeAnalysisTest {
-
- public static Object globalVariableObject;
-
- public Object instanceObject;
-
- public void globalVariableEscape(){
- globalVariableObject = new Object(); // 静态变量,外部线程可见,发生逃逸
- }
-
- public void instanceObjectEscape(){
- instanceObject = new Object(); // 赋值给堆中实例字段,外部线程可见,发生逃逸
- }
-
- public Object returnObjectEscape(){
- return new Object(); // 返回实例,外部线程可见,发生逃逸
- }
-
- public void noEscape(){
- Object noEscape = new Object(); // 仅创建线程可见,对象无逃逸
- }
-
- }
1. Экранирование метода. В теле метода определите локальную переменную, на которую может ссылаться внешний метод, например, передавать методу в качестве вызывающего параметра или возвращать непосредственно как объект. Или можно понять, что объект выскакивает из метода.
Экранирование метода включает в себя:
- 我们可以用下面的代码来表示这个现象。
-
- //StringBuffer对象发生了方法逃逸
- public static StringBuffer createStringBuffer(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb;
- }
- 上面的例子中,StringBuffer 对象通过return语句返回。
-
- StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。
-
- 甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
-
- 不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。
-
- 具体的代码如下:
-
- // 非方法逃逸
- public static String createString(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb.toString();
- }
- 可以看出,想要逃逸方法的话,需要让对象本身被外部调用,或者说, 对象的指针,传递到了 方法之外。
Как быстро определить, произошел ли escape-анализ Давайте посмотрим, вызывается ли новая сущность объекта вне метода?
- public class EscapeAnalysis {
-
- public EscapeAnalysis obj;
-
- /**
- * 方法返回EscapeAnalysis对象,发生逃逸
- * @return
- */
- public EscapeAnalysis getInstance() {
- return obj == null ? new EscapeAnalysis():obj;
- }
-
- /**
- * 为成员属性赋值,发生逃逸
- */
- public void setObj() {
- this.obj = new EscapeAnalysis();
- }
-
- /**
- * 对象的作用于仅在当前方法中有效,没有发生逃逸
- */
- public void useEscapeAnalysis() {
- EscapeAnalysis e = new EscapeAnalysis();
- }
-
- /**
- * 引用成员变量的值,发生逃逸
- */
- public void useEscapeAnalysis2() {
- EscapeAnalysis e = getInstance();
- }
- }
2. Выход из потока: к этому объекту обращаются другие потоки, например, он присваивается переменной экземпляра и к нему обращаются другие потоки. Объект вышел из текущего потока.
Escape-анализ может привнести в программы Java следующие стратегии оптимизации: размещение в стеке, устранение синхронизации, скалярная замена и встраивание методов;
Параметры, связанные с анализом побега:
- -XX:+DoEscapeAnalysis 开启逃逸分析
- -XX:+PrintEscapeAnalysis 开启逃逸分析后,可通过此参数查看分析结果。
- -XX:+EliminateAllocations 开启标量替换
- -XX:+EliminateLocks 开启同步消除
- -XX:+PrintEliminateAllocations 开启标量替换后,查看标量替换情况。
Escape-анализ может определить, какие объекты не выйдут из области действия метода, и разместить эти объекты в стеке, а не в куче. Объекты, размещенные в стеке, создаются и уничтожаются в течение жизненного цикла вызова метода без сборки мусора, что повышает эффективность выполнения программы.
В обычных обстоятельствах объекты, которые не могут покинуть объект, занимают относительно большое пространство. Если пространство в стеке можно использовать, большое количество объектов будет уничтожено после завершения метода, что уменьшит нагрузку на сборщик мусора.
Идеи распределения в стекеРаспределение в стеке — это технология оптимизации, предоставляемая JVM.
Идея заключается в следующем:
Проблема: поскольку память стека относительно мала, большие объекты не могут и не подходят для размещения в стеке.
Включить распределение в стеке
Распределение в стеке основано на escape-анализе и скалярной замене, поэтому escape-анализ и скалярная замена должны быть включены. Конечно, JDK1.8 включен по умолчанию.
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
-
-
- 开启标量替换:-XX:+EliminateAllocations
- 关闭标量替换:-XX:-EliminateAllocations
- 显示标量替换详情:-XX:+PrintEliminateAllocations
Пример размещения в стеке:
- 示例1
- import java.lang.management.ManagementFactory;
- import java.util.List;
- /**
- * 逃逸分析优化-栈上分配
- * 栈上分配,意思是方法内局部变量(未发生逃逸)生成的实例在栈上分配,不用在堆中分配,分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。
- * 一般生成的实例都是放在堆中的,然后把实例的指针或引用压入栈中。
- *虚拟机参数设置如下,表示做了逃逸分析 消耗时间在10毫秒以下
- * -server -Xmx10M -Xms10M
- -XX:+DoEscapeAnalysis -XX:+PrintGC
- *
- *虚拟机参数设置如下,表示没有做逃逸分析 消耗时间在1000毫秒以上
- * -server -Xmx10m -Xms10m
- -XX: -DoEscapeAnalysis -XX:+PrintGC
- * @author 734621
- *
- */
-
- public class OnStack{
- public static void alloc(){
- byte[] b=new byte[2];
- b[0]=1;
- }
- public static void main(String [] args){
- long b=System.currentTimeMillis();
- for(int i=0;i<100000000;i++){
- alloc();
- }
- long e=System.currentTimeMillis();
- System.out.println("消耗时间为:" + (e - b));
- List<String> paramters = ManagementFactory.getRuntimeMXBean().getInputArguments();
- for(String p : paramters){
- System.out.println(p);
- }
- }
- }
-
-
- 加逃逸分析的结果
- [GC (Allocation Failure) 2816K->484K(9984K), 0.0013117 secs]
- 消耗时间为:7
- -Xmx10m
- -Xms10m
- -XX:+DoEscapeAnalysis
- -XX:+PrintGC
-
-
-
- 没有加逃逸分析的结果如下:
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0003174 secs]
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0002524 secs]
- 消耗时间为:1150
- -Xmx10m
- -Xms10m
- -XX:-DoEscapeAnalysis
- -XX:+PrintGC
-
-
- 以上测试可以看出,栈上分配可以明显提高效率: 效率是不开启的1150/7= 160倍
-
-
- 示例2
- 我们通过举例来说明 开启逃逸分析 和 未开启逃逸分析时候的情况
-
- class User {
- private String name;
- private String age;
- private String gender;
- private String phone;
- }
- public class StackAllocation {
- public static void main(String[] args) throws InterruptedException {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- System.out.println("花费的时间为:" + (end - start) + " ms");
-
- // 为了方便查看堆内存中对象个数,线程sleep
- Thread.sleep(10000000);
- }
-
- private static void alloc() {
- // 未发生逃逸
- User user = new User();
- }
- }
- 设置JVM参数,表示未开启逃逸分析
- -Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails
- 花费的时间为:664 ms
- 然后查看内存的情况,发现有大量的User存储在堆中
-
- 开启逃逸分析
- -Xmx1G -Xms1G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails
- 然后查看运行时间,我们能够发现花费的时间快速减少,同时不会发生GC操作
- 花费的时间为:5 ms
- 在看内存情况,我们发现只有很少的User对象,说明User未发生逃逸,因为它存储在栈中,随着栈的销毁而消失。
В сравнении мы видим
Escape-анализ может обнаружить, что к определенным объектам обращается только один поток и они не передаются другим потокам. Таким образом, можно исключить ненужные операции синхронизации и сократить накладные расходы на выполнение многопоточных программ.
Блокировки синхронизации очень требовательны к производительности, поэтому, когда компилятор определяет, что объект не был экранирован, он удаляет блокировку синхронизации с объекта. JDK1.8 по умолчанию включает блокировки синхронизации, но это основано на включении escape-анализа.
- -XX:+EliminateLocks #开启同步锁消除(JVM默认状态)
- -XX:-EliminateLocks #关闭同步锁消除
- 通过示例: 明显可以看到“逃逸分析和锁消除” 对性能的提升
-
- public void testLock(){
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100_000_000; i++) {
- locketMethod();
- }
- long t2 = System.currentTimeMillis();
- System.out.println("耗时:"+(t2-t1));
- }
-
- public static void locketMethod(){
- EscapeAnalysis escapeAnalysis = new EscapeAnalysis();
- synchronized(escapeAnalysis) {
- escapeAnalysis.obj2="abcdefg";
- }
- }
-
- 设置JVM参数,开启逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:+DoEscapeAnalysis
-
- 设置JVM参数,关闭逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:-DoEscapeAnalysis
-
- 设置JVM参数,关闭锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:-EliminateLocks
-
- 设置JVM参数,开启锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:+EliminateLocks
-
-
Стоимость синхронизации потоков довольно высока, а следствием синхронизации является снижение параллелизма и производительности.
При динамической компиляции синхронизированного блока JIT-компилятор может использовать escape-анализ, чтобы определить, доступен ли объект блокировки, используемый синхронизированным блоком, только для одного потока и не был ли он выпущен для других потоков. В противном случае JIT-компилятор десинхронизирует эту часть кода при компиляции синхронизированного блока. Это может значительно улучшить параллелизм и производительность. Этот процесс отмены синхронизации называется пропуском синхронизации, а также устранением блокировки.
- 例如下面的代码
-
- public void f() {
- Object hellis = new Object();
- synchronized(hellis) {
- System.out.println(hellis);
- }
- }
- 代码中对hellis这个对象加锁,但是hellis对象的生命周期只在f()方法中,并不会被其他线程所访问到,所以在JIT编译阶段就会被优化掉,优化成:
-
- public void f() {
- Object hellis = new Object();
- System.out.println(hellis);
- }
- 我们将其转换成字节码,此处发现,还是有同步锁的身影,是因为优化是在编译阶段的,在加载进内存后发生。

Escape-анализ может разделить объект на несколько скаляров, таких как примитивные типы или другие объекты, и назначить их в разных местах. Это может уменьшить фрагментацию памяти и накладные расходы на доступ к объектам, а также повысить эффективность использования памяти.
Прежде всего, мы должны понимать скаляры и агрегаты. Ссылки на базовые типы и объекты можно понимать как скаляры, и их нельзя далее разложить. Количество, которое можно далее разложить, — это совокупное количество, например: объект.
Объект представляет собой совокупную величину, которую можно дополнительно разложить на скаляры, а ее переменные-члены - на дискретные переменные. Это называется скалярной заменой.
Таким образом, если объект не экранируется, его вообще не нужно создавать. В стеке или регистре будут созданы только используемые им скаляры-члены, что экономит пространство памяти и повышает производительность приложения.
Скалярная замена также включена по умолчанию в JDK1.8, но она также должна быть основана на включенном escape-анализе.
Скаляр — это данные, которые нельзя разбить на более мелкие данные. Примитивный тип данных в Java является скалярным.
Напротив, данные, которые можно разложить, называются агрегатами. Объект в Java является агрегатом, поскольку его можно разложить на другие агрегаты и скаляры.
- public static void main(String args[]) {
- alloc();
- }
- class Point {
- private int x;
- private int y;
- }
- private static void alloc() {
- Point point = new Point(1,2);
- System.out.println("point.x" + point.x + ";point.y" + point.y);
- }
- 以上代码,经过标量替换后,就会变成
-
- private static void alloc() {
- int x = 1;
- int y = 2;
- System.out.println("point.x = " + x + "; point.y=" + y);
- }
На этапе JIT, если с помощью escape-анализа обнаруживается, что к объекту не будет доступен внешний мир, то после JIT-оптимизации объект будет разобран на несколько переменных-членов, содержащихся в нем, и заменен. Этот процесс является скалярной заменой.
Видно, что после анализа выхода было обнаружено, что совокупная величина Point не ускользнула, поэтому она была заменена двумя скалярами. Так в чем же преимущества скалярной замены? То есть это может значительно сократить использование динамической памяти. Потому что, когда нет необходимости создавать объекты, нет необходимости выделять динамическую память. Скалярная замена обеспечивает хорошую основу для распределения в стеке.

Тестирование Escape-анализа
- 逃逸分析测试
- 代码如下,大致思路就是 for 循环 1 亿次,循环体内调用外部的 allot() 方法,而 allot() 方法的作用就是简单创建一个对象,但是这个对象是内部的,所以是未逃逸的,所以理论上 JVM 是会进行优化的,我们拭目以待。并且我们会对比开启和关闭逃逸分析之后各自程序的运行时间:
-
- /**
- * @ClassName: EscapeAnalysisTest
- * @Description: http://www.jetchen.cn 逃逸分析 demo
- * @Author: Jet.Chen
- * @Date: 2020/11/23 14:26
- * @Version: 1.0
- **/
- public class EscapeAnalysisTest {
-
- public static void main(String[] args) {
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- allot();
- }
- long t2 = System.currentTimeMillis();
- System.out.println(t2-t1);
- }
-
- private static void allot() {
- Jet jet = new Jet();
- }
-
- static class Jet {
- public String name;
- }
-
- }
- 上面就是我们进行逃逸分析测试的代码, mian() 方法末尾有一个线程暂停,目的是为了观察此时 JVM 中的内存情况。
-
- Step 1:测试开启逃逸
- 由于环境是 jdk1.8,默认开启了逃逸分析,所以直接运行,得到结果如下,程序耗时 3 毫秒:
-
-
- 此时线程是处于睡眠状态的,我们观察下内存情况,发现堆内存中一共新建了 11 万个 Jet 对象。
-
-
-
- Step 2:测试关闭逃逸
- 我们关闭逃逸分析再来运行一次(使用 java -XX:-DoEscapeAnalysis EscapeAnalysisTest 来运行代码即可),得到结果如下,程序耗时 400 毫秒:
-
-
- 此时我们观察下内存情况,发现堆内存中一共新建了 3 千多万个 Jet 对象。
-
-
- 所以,无论是从代码的执行时间(3 毫秒 VS 400 毫秒),还是从堆内存中对象的数量(11 万个 VS 3 千万个)来分析,在上述场景下,开启逃逸分析是有正向益的。
-
- Step 3:测试标量替换
- 我们测试下开启和关闭 标量替换,如下图:
-
-
- 由上图我们可以看出,在上述极端场景下,开启和关闭标量替换对于性能的影响也是满巨大的,另外,同时也验证了标量替换功能生效的前提是逃逸分析已经开启,否则没有意义。
-
- Step 4:测试锁消除
- 测试锁消除,我们需要简单调整下代码,即给 allot() 方法中的内容加锁处理,如下:
-
- private static void allot() {
- Jet jet = new Jet();
- synchronized (jet) {
- jet.name = "jet Chen";
- }
- }
- 然后我们运行测试代码,测试结果也很明显,在上述场景下,开启和关闭锁消除对程序性能的影响也是巨大的。
-
-
- /**
- * 进行两种测试
- * 关闭逃逸分析,同时调大堆空间,避免堆内GC的发生,如果有GC信息将会被打印出来
- * VM运行参数:-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 开启逃逸分析 jdk8默认开启
- * VM运行参数:-Xmx4G -Xms4G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 执行main方法后
- * jps 查看进程
- * jmap -histo 进程ID
- *
- */
- @Slf4j
- public class EscapeTest {
-
- public static void main(String[] args) {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 500000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- log.info("执行时间:" + (end - start) + " ms");
- try {
- Thread.sleep(Integer.MAX_VALUE);
- } catch (InterruptedException e1) {
- e1.printStackTrace();
- }
- }
-
-
- /**
- * JIT编译时会对代码进行逃逸分析
- * 并不是所有对象存放在堆区,有的一部分存在线程栈空间
- * Ponit没有逃逸
- */
- private static String alloc() {
- Point point = new Point();
- return point.toString();
- }
-
- /**
- *同步省略(锁消除) JIT编译阶段优化,JIT经过逃逸分析之后发现无线程安全问题,就会做锁消除
- */
- public void append(String str1, String str2) {
- StringBuffer stringBuffer = new StringBuffer();
- stringBuffer.append(str1).append(str2);
- }
-
- /**
- * 标量替换
- *
- */
- private static void test2() {
- Point point = new Point(1,2);
- System.out.println("point.x="+point.getX()+"; point.y="+point.getY());
-
- // int x=1;
- // int y=2;
- // System.out.println("point.x="+x+"; point.y="+y);
- }
-
-
- }
-
- @Data
- @AllArgsConstructor
- @NoArgsConstructor
- class Point{
- private int x;
- private int y;
- }
Escape-анализ может определить, что определенные вызовы методов не выходят за рамки текущего метода. Следовательно, эти методы можно оптимизировать в режиме реального времени, чтобы снизить стоимость вызовов методов и повысить эффективность выполнения программы.
Благодаря этим стратегиям оптимизации escape-анализ может помочь JVM лучше оптимизировать код, сократить накладные расходы на сборку мусора, повысить эффективность и скорость выполнения программы, а также сократить использование памяти.
Escape-анализ имеет широкий спектр сценариев применения в реальных приложениях Java. Ниже приведены некоторые распространенные сценарии применения:
Статья об анализе побегов была опубликована в 1999 году, но она не была реализована до версии JDK1.6, и эта технология еще не очень развита.
Основная причина заключается в том, что нет никакой гарантии, что потребление производительности Escape-анализа будет выше, чем его потребление. Хотя escape-анализ может выполнять скалярную замену, выделение стека и устранение блокировок. Однако сам анализ побега также требует серии сложных анализов, что на самом деле является относительно трудоемким процессом.
Крайним примером является то, что после анализа побега обнаруживается, что ни один объект не ускользает. Тогда процесс анализа побегов будет потрачен впустую.
Хотя эта технология еще не очень развита, она также является очень важным средством в технологии оптимизации компилятора «точно в срок». Я заметил, что есть некоторые мнения, что посредством escape-анализа JVM выделит в стеке объекты, которые не будут экранироваться. Это теоретически возможно, но это зависит от выбора JvM-дизайнера. Насколько мне известно, Oracle Hotspot JVM не делает этого. Это было объяснено в документах, связанных с escape-анализом, поэтому ясно, что все экземпляры объектов создаются в куче.
В настоящее время многие книги по-прежнему основаны на версиях, предшествующих JDK7. JDK претерпел большие изменения. Кэш внутренних строк и статических переменных когда-то выделялся в постоянной генерации, а постоянная генерация была заменена областью метаданных. Однако внутренний кэш строк и статические переменные не передаются в область метаданных, а размещаются непосредственно в куче, поэтому это также согласуется с выводом предыдущего пункта: экземпляры объектов размещаются в куче. Приведенный выше пример ускорен из-за скалярной замены.
Если объект не экранируется внутри тела метода или внутри потока (или после анализа экранирования установлено, что ему не удалось экранировать), можно выполнить следующие оптимизации:
В обычных обстоятельствах объекты, которые не могут покинуть объект, занимают относительно большое пространство. Если пространство в стеке можно использовать, большое количество объектов будет уничтожено при завершении метода, что уменьшит нагрузку на сборщик мусора.
Если в методе определяемого вами класса имеется блокировка синхронизации, но во время выполнения к нему обращается только один поток, машинный код после escape-анализа будет выполняться без блокировки синхронизации.
Примитивные типы данных в виртуальной машине Java (числовые типы, такие как int, long, ссылочные типы и т. д.) не подлежат дальнейшей декомпозиции, и их можно назвать скалярами. Напротив, если часть данных можно продолжать разлагать, она называется агрегатом. Наиболее типичным агрегатом в Java является объект. Если escape-анализ доказывает, что к объекту не будет осуществляться доступ извне и что объект является разлагаемым, объект можно не создавать при фактическом выполнении программы, а вместо этого напрямую создать несколько его переменных-членов, используемых этим методом для замены. Дизассемблированные переменные можно анализировать и оптимизировать отдельно. После выравнивания атрибутов нет необходимости устанавливать связи с помощью ссылочных указателей. Их можно хранить непрерывно и компактно, что более удобно для различных хранилищ и экономит много времени на обработку данных. выполнение, вызывающее потерю производительности. В то же время вы также можете выделить пространство в кадре стека или зарегистрировать его соответственно, чтобы исходному объекту не нужно было выделять пространство целиком.
Молодое поколение — это область, где объекты рождаются, растут и умирают. Здесь объект генерируется и используется, а затем собирается сборщиком мусора и заканчивает свою жизнь.
Объекты с длительным жизненным циклом, помещенные в старое поколение, обычно представляют собой объекты Java, скопированные из выжившей области. Конечно, есть и особые случаи. Мы знаем, что обычные объекты будут выделены в TLAB; если объект большой, JVM попытается распределить его напрямую по другим местам в Эдеме, если объект слишком велик, то этого не произойдет; Если вы сможете найти достаточно длинное непрерывное свободное пространство в пространстве нового поколения, JVM напрямую выделит его старому поколению. Когда GC встречается только у молодого поколения, процесс переработки объектов молодого поколения называется MinorGc.
Когда GC встречается в старом поколении, его называют MajorGc или FullGC. Как правило, частота встречаемости MinorGc намного выше, чем у MajorGC, то есть частота сборки мусора в старом поколении будет намного ниже, чем в молодом поколении.
Анализ выхода JVM использует два метода анализа: статический и динамический, чтобы определить, может ли объект выйти за пределы области действия метода. Это может помочь JVM оптимизировать код и повысить производительность и эффективность использования памяти программ Java.
Стратегии оптимизации escape-анализа включают распределение в стеке, устранение синхронизации, скалярную замену и встраивание методов. Эти стратегии оптимизации могут снизить затраты на сбор мусора, повысить эффективность и скорость выполнения программы, а также сократить использование памяти.
Ссылаться на:
https://zhuanlan.zhihu.com/p/693382698
JVM-Heap-Escape Analysis-08-CSDN Блог
JIT-экранирование памяти Analysis_java отключает скалярную замену — блог CSDN
java -XX:+PrintFlagsFinal #输出打印所有参数jvm参数



Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com