
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
¿Los objetos en Java están asignados en la memoria del montón?
Bien, es demasiado abstracto. Seamos más específicos. Veamos dónde se asigna la memoria del siguiente objeto.
- public void test() {
- Object object = new Object();
- }
- 这个方法中的object对象,是在堆中分配内存么?
Diga el resultado: el objeto puede asignar memoria en la pila o en el montón.
Aquí está el punto clave: en la implementación de JVM, para mejorar el rendimiento de JVM y ahorrar espacio en la memoria, JVM proporciona una función llamada "análisis de escape" que es una tecnología de optimización relativamente de vanguardia en la actualidad. Máquina virtual Java y también es una técnica de optimización JIT muy importante. jdk6 solo comenzó a introducir esta tecnología, jdk7 comenzó a habilitar el análisis de escape de forma predeterminada, jdk8 comenzó a mejorar el análisis de escape y lo habilitó de forma predeterminada. Hasta JDK 9, el análisis de escape se utilizará como método de optimización predeterminado y no habrá parámetros de compilación especiales. son requeridos.
Ahora comprenda la oración "el objeto puede asignar memoria en la pila o asignar memoria en el montón". Antes de jdk7, el objeto aquí debe asignar memoria en el montón en jdk7 y 8, es posible asignar memoria en la pila, porque jdk7; solo se ha comenzado a admitir el análisis de escape; lo más probable es que jdk9 esté asignado en la pila (el objeto aquí es muy pequeño), porque jdk9 realmente solo admite y habilita el análisis de escape de forma predeterminada.
Con el desarrollo de los compiladores JIT (compiladores justo a tiempo) y la madurez gradual de la tecnología de análisis de escape, la asignación de pila y la tecnología de optimización de reemplazo escalar harán que "todos los objetos se asignarán en el montón" se vuelvan menos absolutos en Java. En la máquina virtual, a los objetos se les asigna memoria en el montón, pero hay un caso especial, es decir, si después del análisis de escape se encuentra que un objeto no escapa del método, se puede optimizar para asignarlo en la pila. Cuando se ejecuta el método Cuando se completa, se abre el marco de la pila y se libera el objeto. Esto elimina la necesidad de asignar memoria en el montón y someterse a recolección de basura (.Hotspot no hace esto actualmente). Esta es también la tecnología de almacenamiento fuera del montón más común.
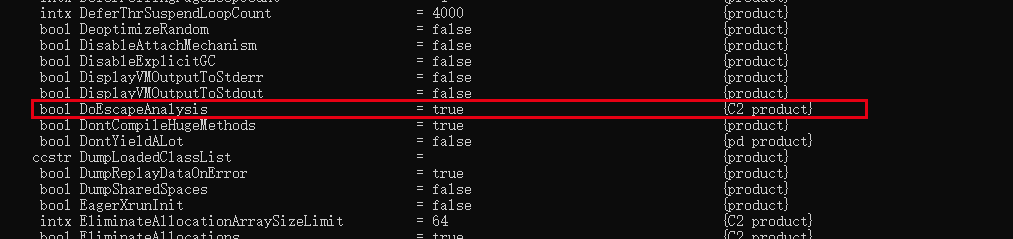
Después de JDK 6u23 (versión principal recordable JDK7), el análisis de escape está habilitado de forma predeterminada en Hotspot. Si usa una versión anterior, puede mostrar el análisis de escape a través de la opción "-XX:+DoEscapeAnalysis". Vea los resultados del filtro para el análisis de escape.
Hotspot implementa el reemplazo escalar a través del análisis de escape (los objetos sin escape se reemplazan con escalares y agregados, lo que puede mejorar la eficiencia del código), pero los objetos sin escape aún asignarán memoria en el montón, por lo que aún se puede decir que todos los objetos están Asignar memoria en el montón.
Además, profundamente personalizado basado en Open JDKMáquina virtual TaoBaoEntre ellos, la innovadora tecnología GCIH (GC invisible heap) implementa fuera del montón, moviendo objetos con ciclos de vida largos desde el montón hacia fuera del montón, y GC no administra objetos Java dentro de GCIH, lo que reduce la frecuencia de reciclaje de GC y mejora el propósito. de la eficiencia de recuperación del GC.
Pila: Cuando se ejecuta cada método, se creará un marco de pila al mismo tiempo para almacenar información como tablas de variables locales, pilas de operaciones, conexiones dinámicas, salidas de métodos, etc. El proceso desde que se llama a cada método hasta que se completa la ejecución corresponde al proceso de un marco de pila desde que se inserta en la pila hasta que se saca de la pila en la pila de la máquina virtual.
montón:Cuando se crea una instancia de un objeto, el objeto se asigna en el montón y se inserta una referencia al montón en la pila.
escapar:Cuando varios métodos o subprocesos hacen referencia a un puntero a un objeto, decimos que el puntero escapa. Generalmente, los objetos devueltos y las variables globales generalmente escapan.
Análisis de escape:El método utilizado para analizar este fenómeno de fuga se llama análisis de fuga.
Optimización del análisis de escape: asignación en la pila:La asignación en la pila significa que la instancia generada por la variable local en el método (no se produce ningún escape) se asigna en la pila y no es necesario asignarla en el montón. Una vez completada la asignación, la ejecución continúa en la pila de llamadas. Finalmente, el hilo finaliza, el espacio de la pila se recicla y los objetos variables locales también se reciclan.


Respuesta: No necesariamente.
Si se cumplen las condiciones del análisis de escape, se puede asignar un objeto en la pila.Reduzca la asignación de memoria dinámica y la presión del GC.Dado que la memoria de la pila es limitada, si el objeto cumple las condiciones para el reemplazo escalar,Se realiza otra operación sobre el objeto para dividirlo en partes.El método específico de reemplazo escalar es: la JVM dividirá aún más el objeto y lo descompondrá en varias variables miembro utilizadas por este método.De este modo, se logra el objetivo de una mejor utilización de la memoria de la pila y de los registros.
Este es un algoritmo de análisis de flujo de datos global de funciones cruzadas que puede reducir efectivamente la carga de sincronización y la presión de asignación del montón de memoria en programas Java. Mediante el análisis de escape, el compilador Java Hotspot puede analizar el rango de uso de la referencia de un nuevo objeto y decidir si asignar este objeto al montón.
El comportamiento básico del análisis de escape es analizar el alcance dinámico de los objetos:
En el principio de optimización del compilador del lenguaje informático, el análisis de escape se refiere al método de analizar el rango dinámico de los punteros. Está relacionado con el análisis de punteros y el análisis de forma del principio de optimización del compilador. Cuando se asigna una variable (u objeto) en un método, su puntero puede ser devuelto o referenciado globalmente, al que otros métodos o subprocesos harán referencia. Este fenómeno se denomina escape de puntero (o referencia). En términos sencillos, si varios métodos o subprocesos hacen referencia al puntero de un objeto, entonces llamamos Escape al puntero (u objeto) del objeto (porque en este momento, el objeto escapa del alcance local del método o subproceso).
Breve descripción: "Análisis de escape: un análisis estático que determina el rango dinámico de los punteros. Puede analizar en qué parte del programa se puede acceder al puntero". En el contexto de la compilación justo a tiempo de JVM, el análisis de escape determinará si el El objeto recién creado se escapa.
La base de la compilación justo a tiempo para determinar si un objeto se escapa: una es si el objeto se almacena en el montón (campo estático o campo de instancia del objeto en el montón), y la otra es si el objeto se pasa a código desconocido.
El análisis de escape es actualmente una tecnología de optimización relativamente de vanguardia en las máquinas virtuales Java. Al igual que el análisis de relaciones de herencia de tipos, no es un medio para optimizar el código directamente, sino una tecnología de análisis que proporciona una base para otros medios de optimización.
Análisis de escape: es una tecnología de optimización JIT muy importante, que se utiliza para determinar si se accederá al objeto fuera del método, es decir, para escapar del alcance del método. El análisis de escape es un paso del compilador JIT. A través de JIT podemos determinar qué objetos se pueden restringir para su uso dentro del método y no escaparán al exterior. Luego se pueden optimizar, como asignarlos en la pila en lugar del montón. O realice un reemplazo escalar para dividir un objeto en varios tipos básicos para su almacenamiento. Es un algoritmo de análisis de flujo de datos global de funciones cruzadas que puede reducir eficazmente la carga de sincronización y la asignación del montón de memoria y la presión de recolección de basura en los programas Java. Mediante el análisis de escape, el compilador Java Hotspot puede analizar el rango de uso de la referencia de un nuevo objeto y decidir si asignar este objeto al montón.
El análisis de escape se centra principalmente en variables locales para determinar si los objetos asignados en el montón han escapado del alcance del método. Está asociado con el análisis de punteros y el análisis de formas de los principios de optimización del compilador. Cuando se asigna una variable (u objeto) en un método, su puntero puede ser devuelto o referenciado globalmente, al que otros métodos o subprocesos harán referencia. Este fenómeno se denomina escape de puntero (o referencia). En términos sencillos, si varios métodos o subprocesos hacen referencia al puntero de un objeto, entonces decimos que el puntero del objeto se ha escapado. Diseñar adecuadamente la estructura del código y el uso de datos puede utilizar mejor el análisis de escape para optimizar el rendimiento del programa. También podemos reducir la sobrecarga de asignar objetos en el montón y mejorar la utilización de la memoria mediante el análisis de escape.
El análisis de escape es una técnica utilizada para determinar si un objeto escapó fuera del alcance de un método durante su vida. En el desarrollo de Java, el análisis de escape se utiliza para determinar el ciclo de vida y el alcance de los objetos con el fin de realizar la optimización correspondiente y mejorar el rendimiento del programa y la eficiencia de utilización de la memoria.
Cuando se crea un objeto, se puede usar dentro de un método o se puede pasar a otros métodos o subprocesos y continuar existiendo fuera del método. Si el objeto no escapa del alcance del método, la JVM puede asignarlo en la pila en lugar del montón, evitando así la sobrecarga de la asignación de memoria del montón y la recolección de basura.
- 关于逃逸分析的论文在1999年就已经发表,但直到Sun JDK 1.6才实现了逃逸分析,而且直到现在这项优化尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是不能保证逃逸分析的性能收益必定高于它的消耗。如果要完全准确的判断一个对象是否会逃逸,需要进行数据流敏感的一系列复杂分析,从而确定程序各个分支执行时对此对象的影响。这是一个相对高耗时的过程,如果分析完后发现没有几个不逃逸的对象,那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小的算法来完成逃逸分析。还有一点是,基于逃逸分析的一些优化手段,如上面提到的“栈上分配”,由于HotSpot虚拟机目前的实现方式导致栈上分配实现起来比较复杂,因此在HotSpot中暂时还没有做这项优化。
- 在测试结果中,实施逃逸分析后的程序在MicroBenchmarks中往往能运行出不错的成绩,但是在实际的应用程序,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或因分析过程耗时但却无法有效判别出非逃逸对象而导致性能(即使编译的收益)有所下降,所以在很长的一段时间里,即使是Server Compiler,也默认不开启逃逸分析(在JDK 1.6 Update 23的Server Compiler中才开始默认开启了逃逸分析),甚至在某些版本(如JDK 1.6 Update 18)中还曾经短暂的完全禁止了这项优化。
- 如果有需要,并且确认对程序运行有益,用户可以使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析,开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数-XX:EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:PrintEliminateAllocations查看标量的替换情况。
- 尽管目前逃逸分析的技术仍不是十分成熟,但是他却是即时编译器优化技术的一个重要的方向,在今后的虚拟机中,逃逸分析技术肯定会支撑起一系列使用有效的优化技术。
El principio básico del análisis de escape JVM es determinar la situación de escape del objeto mediante dos métodos de análisis: estático y dinámico.
En el sistema de compilación Java, el proceso de convertir un archivo de código fuente Java en una instrucción de máquina ejecutable por computadora requiere dos etapas de compilación:
La primera sección de compilación se refiere al compilador front-end.archivo .javaconvertido aarchivo .class (archivo de código de bytes). Los productos del compilador front-end pueden ser Javac de JDK o el compilador incremental en Eclipse JDT.
En la segunda etapa de compilación, la JVM interpreta el código de bytes y lo traduce en las instrucciones de máquina correspondientes, lee el código de bytes uno por uno y lo interpreta y traduce al código de máquina uno por uno.
Obviamente, debido al proceso intermedio de interpretación, su velocidad de ejecución será inevitablemente mucho más lenta que la de un programa de código de bytes binario ejecutable. Esta es la función del intérprete JVM tradicional (Intérprete).
Para solucionar este problema de eficiencia, se introdujo la tecnología JIT (Just In Time Compiler).
Después de la introducción de la tecnología JIT, los programas Java todavía se interpretan y ejecutan a través del intérprete, es decir, el cuerpo principal todavía se interpreta y ejecuta, pero los enlaces intermedios se eliminan parcialmente.
Compilación justo a tiempo del compilador JIT (Just-in-timeCompiler). La primera solución de implementación de Java consistía en un conjunto de traductores (intérpretes) que traducían cada instrucción de Java en una instrucción de microprocesador equivalente y las ejecutaban secuencialmente según el orden de las instrucciones traducidas, porque una instrucción de Java podía traducirse en una docena o docenas de instrucciones equivalentes del microprocesador, este modo se ejecuta muy lentamente.
Cuando la JVM descubre que un determinado método o bloque de código se ejecuta con especial frecuencia, lo considerará "Código de punto activo". Luego, JIT traducirá parte del "código activo" al código de máquina relacionado con la máquina local, lo optimizará y luego almacenará en caché el código de máquina traducido para el próximo uso.
¿Dónde almacenar en caché el código de máquina traducido? Este caché se llama Code Cache. Se puede ver que los métodos para lograr una alta concurrencia entre las aplicaciones JVM y WEB son similares y todavía utilizan la arquitectura de caché.
Cuando la JVM encuentra el mismo código activo la próxima vez, omite el enlace intermedio de interpretación, carga el código de máquina directamente desde Code Cache y lo ejecuta directamente sin volver a compilarlo.
Por lo tanto, el objetivo general de JIT es descubrir el código activo, y el código activo se ha convertido en la clave para mejorar el rendimiento. Así surgió el nombre hotspot JVM. Identificar el código activo y escribirlo en el nombre es una búsqueda de toda la vida.
Por tanto, la estrategia general de JVM es:
Para la mayoría de los códigos poco comunes, no necesitamos perder tiempo compilándolos en código de máquina, sino ejecutarlos mediante interpretación y ejecución;
Por otro lado, para el código activo que solo ocupa una pequeña parte, podemos compilarlo en código de máquina para lograr la velocidad de ejecución ideal.
El surgimiento de JIT (compilación justo a tiempo) y la diferencia entre intérpretes
(1) El intérprete interpreta el código de bytes en código de máquina. Incluso si encuentra el mismo código de bytes la próxima vez, realizará una interpretación repetida.
(2) JIT compila algunos códigos de bytes en códigos de máquina y los almacena en el caché de código. La próxima vez que encuentre el mismo código, se ejecutará directamente sin volver a compilarlo.
(3) El intérprete interpreta el código de bytes en código de máquina que es común a todas las plataformas.
(4) JIT generará código de máquina específico de la plataforma según el tipo de plataforma.
JVM contiene múltiples compiladores justo a tiempo, principalmente C1 y C2, y Graal (experimental).
Múltiples compiladores justo a tiempo optimizarán el código de bytes y generarán código de máquina
JVM divide el estado de ejecución en 5 niveles:
Nivel 0, Intérprete
Nivel 1, compilado y ejecutado usando el compilador justo a tiempo C1 (sin creación de perfiles)
Capa 2, compilada y ejecutada usando el compilador justo a tiempo C1 (con perfiles básicos)
Capa 3, compilada y ejecutada usando el compilador justo a tiempo C1 (con perfilado completo)
Nivel 4, compilado y ejecutado usando el compilador justo a tiempo C2
La JVM no habilitará C2 directamente. En cambio, primero recopila el estado de ejecución del programa a través de la compilación de C1 y luego determina si habilitar C2 en función de los resultados del análisis.
En el modo de compilación en capas, el estado de ejecución de la máquina virtual se divide en cinco capas, de simple a compleja y de rápida a lenta.
Durante la compilación, además de almacenar en caché el código activo para acelerar el proceso, JIT también realizará muchas optimizaciones en el código.
El propósito de algunas de las optimizaciones esReducir la presión de asignación del montón de memoria , una de las técnicas importantes en la optimización JIT se llama análisis de escape. Según el análisis de escape, el compilador justo a tiempo optimizará el código de la siguiente manera durante el proceso de compilación:
Comprueba la estructura estática del código para determinar si el objeto puede escapar. Por ejemplo, cuando un objeto se asigna a una variable miembro de una clase o se devuelve a un método externo, se puede determinar que el objeto escapa.
Determina si un objeto escapa observando el comportamiento de las llamadas a métodos y las referencias a objetos. Por ejemplo, cuando varios subprocesos hacen referencia a un objeto, se puede considerar que el objeto ha escapado.
El análisis de escape realiza un análisis en profundidad del código para determinar si el objeto escapó fuera del alcance del método durante la vida útil del método. Si el objeto no escapa, la JVM puede asignarlo a la pila en lugar del montón.
Un objeto tiene tres estados de escape: escape global, escape de parámetros y sin escape.
escape global(GlobalEscape): es decir, el alcance de un objeto escapa del método actual o del hilo actual.
Generalmente existen los siguientes escenarios:
① El objeto es una variable estática.
② El objeto es un objeto que ha escapado.
③ El objeto se utiliza como valor de retorno del método actual.
escape de parámetros(ArgEscape): es decir, un objeto se pasa como parámetro de método o se hace referencia a él mediante un parámetro, pero no se produce ningún escape global durante el proceso de llamada. Este estado está determinado por el código de bytes del método llamado.
no hay escapatoria: Es decir, el objeto del método no escapa.
El código de muestra del estado de escape es el siguiente:
- public class EscapeAnalysisTest {
-
- public static Object globalVariableObject;
-
- public Object instanceObject;
-
- public void globalVariableEscape(){
- globalVariableObject = new Object(); // 静态变量,外部线程可见,发生逃逸
- }
-
- public void instanceObjectEscape(){
- instanceObject = new Object(); // 赋值给堆中实例字段,外部线程可见,发生逃逸
- }
-
- public Object returnObjectEscape(){
- return new Object(); // 返回实例,外部线程可见,发生逃逸
- }
-
- public void noEscape(){
- Object noEscape = new Object(); // 仅创建线程可见,对象无逃逸
- }
-
- }
1. Escape de método: en el cuerpo de un método, defina una variable local, a la que un método externo puede hacer referencia, como pasarla a un método como parámetro de llamada o devolverla directamente como un objeto. O se puede entender que el objeto salta del método.
Los métodos de escape incluyen:
- 我们可以用下面的代码来表示这个现象。
-
- //StringBuffer对象发生了方法逃逸
- public static StringBuffer createStringBuffer(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb;
- }
- 上面的例子中,StringBuffer 对象通过return语句返回。
-
- StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。
-
- 甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
-
- 不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。
-
- 具体的代码如下:
-
- // 非方法逃逸
- public static String createString(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb.toString();
- }
- 可以看出,想要逃逸方法的话,需要让对象本身被外部调用,或者说, 对象的指针,传递到了 方法之外。
¿Cómo determinar rápidamente si se ha producido un análisis de escape? Veamos si la nueva entidad de objeto se llama fuera del método.
- public class EscapeAnalysis {
-
- public EscapeAnalysis obj;
-
- /**
- * 方法返回EscapeAnalysis对象,发生逃逸
- * @return
- */
- public EscapeAnalysis getInstance() {
- return obj == null ? new EscapeAnalysis():obj;
- }
-
- /**
- * 为成员属性赋值,发生逃逸
- */
- public void setObj() {
- this.obj = new EscapeAnalysis();
- }
-
- /**
- * 对象的作用于仅在当前方法中有效,没有发生逃逸
- */
- public void useEscapeAnalysis() {
- EscapeAnalysis e = new EscapeAnalysis();
- }
-
- /**
- * 引用成员变量的值,发生逃逸
- */
- public void useEscapeAnalysis2() {
- EscapeAnalysis e = getInstance();
- }
- }
2. Escape de subproceso: otros subprocesos acceden a este objeto, como el asignado a una variable de instancia y el acceso de otros subprocesos. El objeto escapó del hilo actual.
El análisis de escape puede aportar las siguientes estrategias de optimización a los programas Java: asignación en la pila, eliminación de sincronización, reemplazo escalar e inserción de métodos;
Parámetros relacionados con el análisis de escape:
- -XX:+DoEscapeAnalysis 开启逃逸分析
- -XX:+PrintEscapeAnalysis 开启逃逸分析后,可通过此参数查看分析结果。
- -XX:+EliminateAllocations 开启标量替换
- -XX:+EliminateLocks 开启同步消除
- -XX:+PrintEliminateAllocations 开启标量替换后,查看标量替换情况。
El análisis de escape puede determinar qué objetos no escaparán del alcance del método y asignar estos objetos en la pila en lugar del montón. Los objetos asignados en la pila se crean y destruyen dentro del ciclo de vida de la llamada al método sin recolección de basura, lo que mejora la eficiencia de ejecución del programa.
En circunstancias normales, los objetos que no pueden escapar ocupan un espacio relativamente grande. Si se puede utilizar el espacio en la pila, una gran cantidad de objetos se destruirán cuando finalice el método, lo que reducirá la presión del GC.
Ideas de asignación en la pilaLa asignación en la pila es una tecnología de optimización proporcionada por JVM.
La idea es:
Problema: dado que la memoria de la pila es relativamente pequeña, los objetos grandes no pueden ni son adecuados para su asignación en la pila.
Habilitar la asignación en la pila
La asignación en la pila se basa en el análisis de escape y el reemplazo escalar, por lo que el análisis de escape y el reemplazo escalar deben estar habilitados. Por supuesto, JDK1.8 está habilitado de forma predeterminada.
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
-
-
- 开启标量替换:-XX:+EliminateAllocations
- 关闭标量替换:-XX:-EliminateAllocations
- 显示标量替换详情:-XX:+PrintEliminateAllocations
Ejemplo de asignación en pila:
- 示例1
- import java.lang.management.ManagementFactory;
- import java.util.List;
- /**
- * 逃逸分析优化-栈上分配
- * 栈上分配,意思是方法内局部变量(未发生逃逸)生成的实例在栈上分配,不用在堆中分配,分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。
- * 一般生成的实例都是放在堆中的,然后把实例的指针或引用压入栈中。
- *虚拟机参数设置如下,表示做了逃逸分析 消耗时间在10毫秒以下
- * -server -Xmx10M -Xms10M
- -XX:+DoEscapeAnalysis -XX:+PrintGC
- *
- *虚拟机参数设置如下,表示没有做逃逸分析 消耗时间在1000毫秒以上
- * -server -Xmx10m -Xms10m
- -XX: -DoEscapeAnalysis -XX:+PrintGC
- * @author 734621
- *
- */
-
- public class OnStack{
- public static void alloc(){
- byte[] b=new byte[2];
- b[0]=1;
- }
- public static void main(String [] args){
- long b=System.currentTimeMillis();
- for(int i=0;i<100000000;i++){
- alloc();
- }
- long e=System.currentTimeMillis();
- System.out.println("消耗时间为:" + (e - b));
- List<String> paramters = ManagementFactory.getRuntimeMXBean().getInputArguments();
- for(String p : paramters){
- System.out.println(p);
- }
- }
- }
-
-
- 加逃逸分析的结果
- [GC (Allocation Failure) 2816K->484K(9984K), 0.0013117 secs]
- 消耗时间为:7
- -Xmx10m
- -Xms10m
- -XX:+DoEscapeAnalysis
- -XX:+PrintGC
-
-
-
- 没有加逃逸分析的结果如下:
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0003174 secs]
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0002524 secs]
- 消耗时间为:1150
- -Xmx10m
- -Xms10m
- -XX:-DoEscapeAnalysis
- -XX:+PrintGC
-
-
- 以上测试可以看出,栈上分配可以明显提高效率: 效率是不开启的1150/7= 160倍
-
-
- 示例2
- 我们通过举例来说明 开启逃逸分析 和 未开启逃逸分析时候的情况
-
- class User {
- private String name;
- private String age;
- private String gender;
- private String phone;
- }
- public class StackAllocation {
- public static void main(String[] args) throws InterruptedException {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- System.out.println("花费的时间为:" + (end - start) + " ms");
-
- // 为了方便查看堆内存中对象个数,线程sleep
- Thread.sleep(10000000);
- }
-
- private static void alloc() {
- // 未发生逃逸
- User user = new User();
- }
- }
- 设置JVM参数,表示未开启逃逸分析
- -Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails
- 花费的时间为:664 ms
- 然后查看内存的情况,发现有大量的User存储在堆中
-
- 开启逃逸分析
- -Xmx1G -Xms1G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails
- 然后查看运行时间,我们能够发现花费的时间快速减少,同时不会发生GC操作
- 花费的时间为:5 ms
- 在看内存情况,我们发现只有很少的User对象,说明User未发生逃逸,因为它存储在栈中,随着栈的销毁而消失。
En comparación, podemos ver
El análisis de escape puede detectar que solo un subproceso accede a ciertos objetos y no escapan a otros subprocesos. Por lo tanto, se pueden eliminar operaciones de sincronización innecesarias y se reduce la sobrecarga de ejecución de programas multiproceso.
Los bloqueos de sincronización consumen mucho rendimiento, por lo que cuando el compilador determina que un objeto no ha escapado, eliminará el bloqueo de sincronización del objeto. JDK1.8 habilita bloqueos de sincronización de forma predeterminada, pero se basa en habilitar el análisis de escape.
- -XX:+EliminateLocks #开启同步锁消除(JVM默认状态)
- -XX:-EliminateLocks #关闭同步锁消除
- 通过示例: 明显可以看到“逃逸分析和锁消除” 对性能的提升
-
- public void testLock(){
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100_000_000; i++) {
- locketMethod();
- }
- long t2 = System.currentTimeMillis();
- System.out.println("耗时:"+(t2-t1));
- }
-
- public static void locketMethod(){
- EscapeAnalysis escapeAnalysis = new EscapeAnalysis();
- synchronized(escapeAnalysis) {
- escapeAnalysis.obj2="abcdefg";
- }
- }
-
- 设置JVM参数,开启逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:+DoEscapeAnalysis
-
- 设置JVM参数,关闭逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:-DoEscapeAnalysis
-
- 设置JVM参数,关闭锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:-EliminateLocks
-
- 设置JVM参数,开启锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:+EliminateLocks
-
-
El costo de la sincronización de subprocesos es bastante alto y la consecuencia de la sincronización es una reducción de la concurrencia y el rendimiento.
Al compilar dinámicamente un bloque sincronizado, el compilador JIT puede utilizar el análisis de escape para determinar si solo un subproceso puede acceder al objeto de bloqueo utilizado por el bloque sincronizado y no se ha liberado a otros subprocesos. De lo contrario, el compilador JIT desincronizará esta parte del código al compilar este bloque sincronizado. Esto puede mejorar enormemente la simultaneidad y el rendimiento. Este proceso de cancelación de sincronización se llama omisión de sincronización, también llamada eliminación de bloqueo.
- 例如下面的代码
-
- public void f() {
- Object hellis = new Object();
- synchronized(hellis) {
- System.out.println(hellis);
- }
- }
- 代码中对hellis这个对象加锁,但是hellis对象的生命周期只在f()方法中,并不会被其他线程所访问到,所以在JIT编译阶段就会被优化掉,优化成:
-
- public void f() {
- Object hellis = new Object();
- System.out.println(hellis);
- }
- 我们将其转换成字节码,此处发现,还是有同步锁的身影,是因为优化是在编译阶段的,在加载进内存后发生。

El análisis de escape puede dividir un objeto en múltiples escalares, como tipos primitivos u otros objetos, y asignarlos en diferentes ubicaciones. Esto puede reducir la fragmentación de la memoria y la sobrecarga de acceso a objetos, y mejorar la eficiencia de la utilización de la memoria.
En primer lugar, debemos comprender los escalares y los agregados. Las referencias a tipos y objetos básicos pueden entenderse como escalares y no pueden descomponerse más. La cantidad que se puede descomponer aún más es la cantidad agregada, como por ejemplo: objeto.
El objeto es una cantidad agregada, que se puede descomponer en escalares y sus variables miembro en variables discretas. Esto se denomina reemplazo escalar.
De esta manera, si un objeto no escapa, no es necesario crearlo en absoluto. Solo los miembros escalares que utiliza se crearán en la pila o registro, lo que ahorra espacio en la memoria y mejora el rendimiento de la aplicación.
La sustitución escalar también está habilitada de forma predeterminada en JDK1.8, pero también debe basarse en que el análisis de escape esté habilitado.
Un escalar es un dato que no se puede dividir en datos más pequeños. El tipo de datos primitivo en Java es escalar.
Por el contrario, los datos que se pueden descomponer se denominan agregados. Un objeto en Java es un agregado porque se puede descomponer en otros agregados y escalares.
- public static void main(String args[]) {
- alloc();
- }
- class Point {
- private int x;
- private int y;
- }
- private static void alloc() {
- Point point = new Point(1,2);
- System.out.println("point.x" + point.x + ";point.y" + point.y);
- }
- 以上代码,经过标量替换后,就会变成
-
- private static void alloc() {
- int x = 1;
- int y = 2;
- System.out.println("point.x = " + x + "; point.y=" + y);
- }
En la etapa JIT, si a través del análisis de escape se descubre que el mundo exterior no accederá a un objeto, luego de la optimización JIT, el objeto se descompondrá en varias variables miembro contenidas en él y se reemplazará. Este proceso es un reemplazo escalar.
Se puede ver que después del análisis de escape, se encontró que la cantidad agregada Punto no escapó, por lo que fue reemplazada por dos escalares. Entonces, ¿cuáles son los beneficios de la sustitución escalar? Es decir, puede reducir en gran medida el uso de memoria dinámica. Porque una vez que no es necesario crear objetos, no es necesario asignar memoria de montón. La sustitución escalar proporciona una buena base para la asignación en la pila.

Pruebas de análisis de escape
- 逃逸分析测试
- 代码如下,大致思路就是 for 循环 1 亿次,循环体内调用外部的 allot() 方法,而 allot() 方法的作用就是简单创建一个对象,但是这个对象是内部的,所以是未逃逸的,所以理论上 JVM 是会进行优化的,我们拭目以待。并且我们会对比开启和关闭逃逸分析之后各自程序的运行时间:
-
- /**
- * @ClassName: EscapeAnalysisTest
- * @Description: http://www.jetchen.cn 逃逸分析 demo
- * @Author: Jet.Chen
- * @Date: 2020/11/23 14:26
- * @Version: 1.0
- **/
- public class EscapeAnalysisTest {
-
- public static void main(String[] args) {
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- allot();
- }
- long t2 = System.currentTimeMillis();
- System.out.println(t2-t1);
- }
-
- private static void allot() {
- Jet jet = new Jet();
- }
-
- static class Jet {
- public String name;
- }
-
- }
- 上面就是我们进行逃逸分析测试的代码, mian() 方法末尾有一个线程暂停,目的是为了观察此时 JVM 中的内存情况。
-
- Step 1:测试开启逃逸
- 由于环境是 jdk1.8,默认开启了逃逸分析,所以直接运行,得到结果如下,程序耗时 3 毫秒:
-
-
- 此时线程是处于睡眠状态的,我们观察下内存情况,发现堆内存中一共新建了 11 万个 Jet 对象。
-
-
-
- Step 2:测试关闭逃逸
- 我们关闭逃逸分析再来运行一次(使用 java -XX:-DoEscapeAnalysis EscapeAnalysisTest 来运行代码即可),得到结果如下,程序耗时 400 毫秒:
-
-
- 此时我们观察下内存情况,发现堆内存中一共新建了 3 千多万个 Jet 对象。
-
-
- 所以,无论是从代码的执行时间(3 毫秒 VS 400 毫秒),还是从堆内存中对象的数量(11 万个 VS 3 千万个)来分析,在上述场景下,开启逃逸分析是有正向益的。
-
- Step 3:测试标量替换
- 我们测试下开启和关闭 标量替换,如下图:
-
-
- 由上图我们可以看出,在上述极端场景下,开启和关闭标量替换对于性能的影响也是满巨大的,另外,同时也验证了标量替换功能生效的前提是逃逸分析已经开启,否则没有意义。
-
- Step 4:测试锁消除
- 测试锁消除,我们需要简单调整下代码,即给 allot() 方法中的内容加锁处理,如下:
-
- private static void allot() {
- Jet jet = new Jet();
- synchronized (jet) {
- jet.name = "jet Chen";
- }
- }
- 然后我们运行测试代码,测试结果也很明显,在上述场景下,开启和关闭锁消除对程序性能的影响也是巨大的。
-
-
- /**
- * 进行两种测试
- * 关闭逃逸分析,同时调大堆空间,避免堆内GC的发生,如果有GC信息将会被打印出来
- * VM运行参数:-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 开启逃逸分析 jdk8默认开启
- * VM运行参数:-Xmx4G -Xms4G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 执行main方法后
- * jps 查看进程
- * jmap -histo 进程ID
- *
- */
- @Slf4j
- public class EscapeTest {
-
- public static void main(String[] args) {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 500000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- log.info("执行时间:" + (end - start) + " ms");
- try {
- Thread.sleep(Integer.MAX_VALUE);
- } catch (InterruptedException e1) {
- e1.printStackTrace();
- }
- }
-
-
- /**
- * JIT编译时会对代码进行逃逸分析
- * 并不是所有对象存放在堆区,有的一部分存在线程栈空间
- * Ponit没有逃逸
- */
- private static String alloc() {
- Point point = new Point();
- return point.toString();
- }
-
- /**
- *同步省略(锁消除) JIT编译阶段优化,JIT经过逃逸分析之后发现无线程安全问题,就会做锁消除
- */
- public void append(String str1, String str2) {
- StringBuffer stringBuffer = new StringBuffer();
- stringBuffer.append(str1).append(str2);
- }
-
- /**
- * 标量替换
- *
- */
- private static void test2() {
- Point point = new Point(1,2);
- System.out.println("point.x="+point.getX()+"; point.y="+point.getY());
-
- // int x=1;
- // int y=2;
- // System.out.println("point.x="+x+"; point.y="+y);
- }
-
-
- }
-
- @Data
- @AllArgsConstructor
- @NoArgsConstructor
- class Point{
- private int x;
- private int y;
- }
El análisis de escape puede determinar que ciertas llamadas a métodos no escaparán del alcance del método actual. Por lo tanto, estos métodos se pueden optimizar en línea para reducir el costo de las llamadas a métodos y mejorar la eficiencia de ejecución del programa.
A través de estas estrategias de optimización, el análisis de escape puede ayudar a la JVM a optimizar mejor el código, reducir la sobrecarga de recolección de basura, mejorar la eficiencia y la capacidad de respuesta de la ejecución del programa y reducir el uso de memoria.
El análisis de escape tiene una amplia gama de escenarios de aplicación en aplicaciones Java reales. Los siguientes son algunos escenarios de aplicación comunes:
El artículo sobre análisis de escape se publicó en 1999, pero no se implementó hasta JDK1.6 y esta tecnología aún no está muy madura.
La razón fundamental es que no hay garantía de que el consumo de rendimiento del análisis de escape sea mayor que su consumo. Aunque el análisis de escape puede realizar sustitución escalar, asignación de pilas y eliminación de bloqueos. Sin embargo, el análisis de escape en sí también requiere una serie de análisis complejos, lo que en realidad es un proceso que requiere relativamente tiempo.
Un ejemplo extremo es que después del análisis de escape, se descubre que ningún objeto no escapa. Entonces el proceso de análisis de la fuga es en vano.
Aunque esta tecnología no está muy madura, también es un medio muy importante en la tecnología de optimización del compilador justo a tiempo. Noté que hay algunas opiniones de que a través del análisis de escape, la JVM asignará objetos en la pila que no escaparán. Esto es teóricamente posible, pero depende de la elección del diseñador de JvM. Hasta donde yo sé, Oracle Hotspot JVM no hace esto. Esto se explica en los documentos relacionados con el análisis de escape, por lo que está claro que todas las instancias de objetos se crean en el montón.
En la actualidad, muchos libros todavía se basan en versiones anteriores a JDK7. JDK ha sufrido grandes cambios. El caché de cadenas internas y variables estáticas alguna vez se asignó en la generación permanente, y la generación permanente ha sido reemplazada por el área de metadatos. Sin embargo, el caché de cadenas interno y las variables estáticas no se transfieren al área de metadatos, sino que se asignan directamente en el montón, por lo que esto también es coherente con la conclusión del punto anterior: las instancias de objetos se asignan en el montón. El ejemplo anterior se acelera debido a la sustitución escalar.
Si un objeto no escapa dentro del cuerpo del método o dentro del subproceso (o se determina que no pudo escapar después del análisis de escape), se pueden realizar las siguientes optimizaciones:
En circunstancias normales, los objetos que no pueden escapar ocupan un espacio relativamente grande. Si se puede utilizar el espacio en la pila, una gran cantidad de objetos se destruirán cuando finalice el método, lo que reducirá la presión del GC.
Si hay un bloqueo de sincronización en el método de la clase que usted define, pero solo un subproceso accede a él en tiempo de ejecución, el código de máquina después del análisis de escape se ejecutará sin el bloqueo de sincronización.
Los tipos de datos primitivos en la máquina virtual Java (tipos numéricos como int, long y tipos de referencia, etc.) no se pueden descomponer más y se pueden denominar escalares. Por el contrario, si un dato puede seguir descomponiéndose, se denomina agregado. El agregado más típico en Java es un objeto. Si el análisis de escape demuestra que no se accederá a un objeto externamente y que el objeto es descomponible, es posible que el objeto no se cree cuando el programa se ejecuta realmente, sino que se creen directamente varias de sus variables miembro utilizadas por este método. Las variables desensambladas se pueden analizar y optimizar por separado. Una vez aplanados los atributos, no es necesario establecer relaciones a través de punteros de referencia. Se pueden almacenar de forma continua y compacta, lo que es más amigable para varios almacenamientos y ahorra una gran cantidad de datos durante el manejo. ejecución causando pérdida de rendimiento. Al mismo tiempo, también puede asignar espacio en el marco de la pila o registrarse respectivamente, de modo que el objeto original no necesite asignar espacio en su conjunto.
La generación joven es el área donde los objetos nacen, crecen y mueren. Aquí se genera y usa un objeto, y finalmente el recolector de basura lo recolecta y termina su vida.
Los objetos con ciclos de vida largos colocados en la generación anterior suelen ser objetos Java copiados del área de supervivencia. Por supuesto, también hay casos especiales. Sabemos que los objetos ordinarios se asignarán en TLAB; si el objeto es grande, la JVM intentará asignarlo directamente a otras ubicaciones en Eden; Si puede encontrar un espacio libre continuo lo suficientemente largo en la nueva generación, la JVM lo asignará directamente a la generación anterior. Cuando GC solo ocurre en la generación joven, el acto de reciclar objetos de la generación joven se llama MinorGc.
Cuando la GC ocurre en la generación anterior, se llama MajorGc o FullGC. Generalmente, la frecuencia de aparición de MinorGc es mucho mayor que la de MajorGC, es decir, la frecuencia de recolección de basura en la generación anterior será mucho menor que en la generación joven.
El análisis de escape de JVM utiliza dos métodos de análisis, estático y dinámico, para determinar si un objeto puede escapar del alcance de un método. Puede ayudar a la JVM a optimizar el código y mejorar el rendimiento y la eficiencia de utilización de la memoria de los programas Java.
Las estrategias de optimización para el análisis de escape incluyen asignación en la pila, eliminación de sincronización, sustitución escalar e incorporación de métodos. Estas estrategias de optimización pueden reducir la sobrecarga de la recolección de basura, mejorar la eficiencia y la capacidad de respuesta de la ejecución del programa y reducir el uso de memoria.
Referirse a:
https://zhuanlan.zhihu.com/p/693382698
JVM-Heap-Escape Analysis-08-CSDN Blog
Análisis de escape de memoria JIT_java desactiva el reemplazo escalar-CSDN Blog
java -XX:+PrintFlagsFinal #输出打印所有参数jvm参数



Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]