
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Gli oggetti in Java sono allocati nella memoria heap?
Ok, è troppo astratto. Cerchiamo di essere più specifici. Vediamo dove è allocata la memoria del seguente oggetto?
- public void test() {
- Object object = new Object();
- }
- 这个方法中的object对象,是在堆中分配内存么?
Di' il risultato: l'oggetto può allocare memoria nello stack o nell'heap.
Ecco il punto chiave: nell'implementazione della JVM, al fine di migliorare le prestazioni della JVM e risparmiare spazio di memoria, la JVM fornisce una funzionalità chiamata "analisi di fuga". L'analisi di fuga è una tecnologia di ottimizzazione relativamente all'avanguardia nel momento attuale Java virtual machine, ed è anche una tecnica di ottimizzazione JIT molto importante. jdk6 ha iniziato solo a introdurre questa tecnologia, jdk7 ha iniziato ad abilitare l'analisi di fuga per impostazione predefinita, jdk8 ha iniziato a migliorare l'analisi di fuga e l'ha abilitata per impostazione predefinita. Fino a JDK 9, l'analisi di fuga verrà utilizzata come metodo di ottimizzazione predefinito e nessun parametro di compilazione speciale sono necessarie.
Ora comprendi la frase "l'oggetto può allocare memoria sullo stack o allocare memoria sull'heap". Prima di jdk7, l'oggetto qui deve allocare memoria sull'heap; in jdk7 e 8, è possibile allocare memoria sullo stack, perché jdk7 solo l'analisi di fuga ha iniziato a essere supportata; jdk9 è molto probabilmente allocato nello stack (l'oggetto qui è molto piccolo), perché jdk9 supporta e abilita veramente solo l'analisi di fuga per impostazione predefinita.
Con lo sviluppo dei compilatori JIT (compilatori just-in-time) e la graduale maturità della tecnologia di analisi di fuga, l'allocazione dello stack e la tecnologia di ottimizzazione della sostituzione scalare faranno sì che "tutti gli oggetti verranno allocati nell'heap" diventino meno assoluti in Java In Nella macchina virtuale, agli oggetti viene allocata memoria nell'heap, ma esiste un caso speciale, ovvero se dopo l'analisi dell'escape si scopre che un oggetto non esce dal metodo, è possibile ottimizzarlo per essere allocato nello stack. Quando il metodo viene eseguito Una volta completato, lo stack frame viene estratto e l'oggetto viene rilasciato. Ciò elimina la necessità di allocare memoria sull'heap e sottoporsi alla garbage collection (.Hotspot attualmente non lo fa). Questa è anche la tecnologia di archiviazione off-heap più comune.
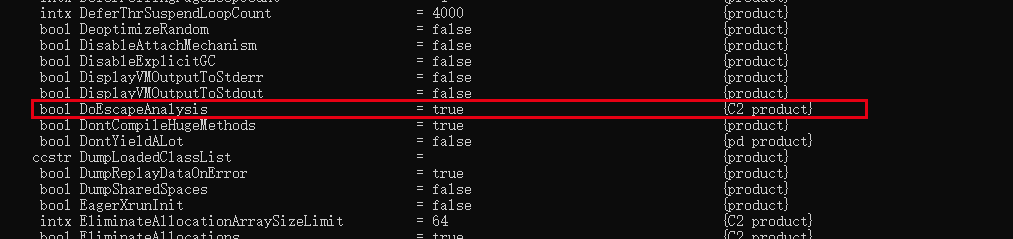
Dopo JDK 6u23 (versione principale JDK7 ricordabile), l'analisi di escape è abilitata per impostazione predefinita in Hotspot. Se si utilizza una versione precedente, è possibile visualizzare l'analisi di escape tramite l'opzione "-XX:+DoEscapeAnalysis" Pass "-XX:+PrintEscapeAnalysis". Visualizza i risultati del filtro per l'analisi della fuga.
Hotspot implementa la sostituzione scalare tramite l'analisi di escape (gli oggetti senza escape vengono sostituiti con scalari e aggregati, che possono migliorare l'efficienza del codice), ma gli oggetti senza escape allocheranno comunque memoria sull'heap, quindi si può ancora dire che tutti gli oggetti sono allocati memoria nel mucchio.
Inoltre, profondamente personalizzato basato su Open JDKMacchina fotografica TaoBao, tra cui l'innovativa tecnologia GCIH (GC invisibile heap) implementa l'off-heap, spostando oggetti con lunghi cicli di vita dall'heap all'esterno dell'heap, e GC non gestisce gli oggetti Java all'interno di GCIH, riducendo così la frequenza di riciclo di GC e migliorando lo scopo dell’efficienza di recupero del GC.
Pila: Quando viene eseguito ciascun metodo, verrà creato contemporaneamente uno stack frame per archiviare informazioni quali tabelle delle variabili locali, stack di operazioni, connessioni dinamiche, uscite dei metodi, ecc. Il processo da ciascun metodo chiamato fino al completamento dell'esecuzione corrisponde al processo di uno stack frame dall'inserimento nello stack all'estrazione dallo stack nello stack della macchina virtuale.
mucchio:Quando viene istanziato un oggetto, l'oggetto viene allocato nell'heap e un riferimento all'heap viene inserito nello stack.
fuga:Quando si fa riferimento a un puntatore a un oggetto da più metodi o thread, si dice che il puntatore esegue l'escape. In genere, gli oggetti restituiti e le variabili globali generalmente eseguono l'escape.
Analisi della fuga:Il metodo utilizzato per analizzare questo fenomeno di fuga è chiamato analisi di fuga
Ottimizzazione dell'analisi di fuga - allocazione sullo stack:L'allocazione nello stack significa che l'istanza generata dalla variabile locale nel metodo (non si verifica alcun escape) viene allocata nello stack e non deve essere allocata nell'heap. Una volta completata l'allocazione, l'esecuzione continua nello stack delle chiamate. Alla fine, il thread termina, lo spazio dello stack viene riciclato e anche gli oggetti Variable locale vengono riciclati.


Risposta: Non necessariamente.
Se le condizioni dell'analisi di fuga sono soddisfatte, un oggetto può essere allocato nello stack.Ridurre l'allocazione della memoria heap e la pressione del GC.Poiché la memoria dello stack è limitata, se l'oggetto soddisfa le condizioni per la sostituzione scalare,Sul soggetto viene eseguita un'ulteriore operazione per scomporlo in parti.Il metodo specifico di sostituzione scalare è: la JVM suddividerà ulteriormente l'oggetto e scomporrà l'oggetto in diverse variabili membro utilizzate da questo metodo.In questo modo viene raggiunto l'obiettivo di un migliore utilizzo della memoria dello stack e dei registri.
Si tratta di un algoritmo di analisi del flusso di dati globale multifunzionale che può ridurre efficacemente il carico di sincronizzazione e la pressione sull'allocazione dell'heap di memoria nei programmi Java. Attraverso l'analisi di escape, il compilatore Java Hotspot può analizzare l'intervallo di utilizzo del riferimento di un nuovo oggetto e decidere se allocare l'oggetto nell'heap.
Il comportamento di base dell'analisi di fuga è analizzare l'ambito dinamico degli oggetti:
Nel principio di ottimizzazione del compilatore del linguaggio informatico, l'analisi di fuga si riferisce al metodo di analisi della gamma dinamica dei puntatori. È correlata all'analisi dei puntatori e all'analisi della forma del principio di ottimizzazione del compilatore. Quando una variabile (o un oggetto) viene allocata in un metodo, il suo puntatore può essere restituito o referenziato globalmente, a cui faranno riferimento altri metodi o thread. Questo fenomeno è chiamato escape del puntatore (o riferimento). In parole povere, se il puntatore di un oggetto viene referenziato da più metodi o thread, allora chiamiamo il puntatore dell'oggetto (o oggetto) Escape (perché in questo momento l'oggetto sfugge all'ambito locale del metodo o del thread).
Breve descrizione: "Analisi di escape: un'analisi statica che determina la gamma dinamica dei puntatori. Può analizzare dove è possibile accedere al puntatore nel programma." Nel contesto della compilazione just-in-time di JVM, l'analisi di escape determinerà se il file l'oggetto appena creato sfugge.
La base per la compilazione just-in-time per determinare se un oggetto sfugge: una è se l'oggetto è archiviato nell'heap (campo statico o campo di istanza dell'oggetto nell'heap) e l'altra è se l'oggetto viene passato in codice sconosciuto.
L'analisi di fuga è attualmente una tecnologia di ottimizzazione relativamente all'avanguardia nelle macchine virtuali Java, come l'analisi delle relazioni di ereditarietà dei tipi, non è un mezzo per ottimizzare direttamente il codice, ma una tecnologia di analisi che fornisce una base per altri mezzi di ottimizzazione.
Analisi di fuga: è una tecnologia di ottimizzazione JIT molto importante, utilizzata per determinare se si accederà all'oggetto al di fuori del metodo, cioè per sfuggire all'ambito del metodo. L'analisi della fuga è un passaggio del compilatore JIT. Attraverso JIT possiamo determinare quali oggetti possono essere limitati all'uso all'interno del metodo e non sfuggiranno all'esterno, quindi possono essere ottimizzati, ad esempio allocandoli nello stack anziché nell'heap Oppure esegui la sostituzione scalare per dividere un oggetto in più tipi di base per l'archiviazione. Si tratta di un algoritmo di analisi del flusso di dati globale multifunzionale in grado di ridurre efficacemente il carico di sincronizzazione, l'allocazione dell'heap di memoria e la pressione della raccolta dei rifiuti nei programmi Java. Attraverso l'analisi di escape, il compilatore Java Hotspot può analizzare l'intervallo di utilizzo del riferimento di un nuovo oggetto e decidere se allocare questo oggetto nell'heap.
L'analisi di fuga si concentra principalmente sulle variabili locali per determinare se gli oggetti allocati nell'heap sono sfuggiti all'ambito del metodo. È associato all'analisi dei puntatori e all'analisi della forma dei principi di ottimizzazione del compilatore. Quando una variabile (o un oggetto) viene allocata in un metodo, il suo puntatore può essere restituito o referenziato globalmente, a cui faranno riferimento altri metodi o thread. Questo fenomeno è chiamato escape del puntatore (o riferimento). In parole povere, se il puntatore di un oggetto viene referenziato da più metodi o thread, allora diciamo che il puntatore dell'oggetto è sfuggito. Progettare correttamente la struttura del codice e l'utilizzo dei dati può utilizzare meglio l'analisi di escape per ottimizzare le prestazioni del programma. Possiamo anche ridurre il sovraccarico derivante dall'allocazione degli oggetti nell'heap e migliorare l'utilizzo della memoria attraverso l'analisi dell'escape.
L'analisi di fuga è una tecnica utilizzata per determinare se un oggetto è sfuggito all'ambito di un metodo durante la sua vita. Nello sviluppo Java, l'analisi di escape viene utilizzata per determinare il ciclo di vita e l'ambito degli oggetti al fine di eseguire l'ottimizzazione corrispondente e migliorare le prestazioni del programma e l'efficienza di utilizzo della memoria.
Quando un oggetto viene creato, può essere utilizzato all'interno di un metodo oppure può essere passato ad altri metodi o thread e continuare a esistere all'esterno del metodo. Se l'oggetto non esce dall'ambito del metodo, la JVM può allocarlo nello stack anziché nell'heap, evitando così il sovraccarico dell'allocazione della memoria sull'heap e della garbage collection.
- 关于逃逸分析的论文在1999年就已经发表,但直到Sun JDK 1.6才实现了逃逸分析,而且直到现在这项优化尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是不能保证逃逸分析的性能收益必定高于它的消耗。如果要完全准确的判断一个对象是否会逃逸,需要进行数据流敏感的一系列复杂分析,从而确定程序各个分支执行时对此对象的影响。这是一个相对高耗时的过程,如果分析完后发现没有几个不逃逸的对象,那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小的算法来完成逃逸分析。还有一点是,基于逃逸分析的一些优化手段,如上面提到的“栈上分配”,由于HotSpot虚拟机目前的实现方式导致栈上分配实现起来比较复杂,因此在HotSpot中暂时还没有做这项优化。
- 在测试结果中,实施逃逸分析后的程序在MicroBenchmarks中往往能运行出不错的成绩,但是在实际的应用程序,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或因分析过程耗时但却无法有效判别出非逃逸对象而导致性能(即使编译的收益)有所下降,所以在很长的一段时间里,即使是Server Compiler,也默认不开启逃逸分析(在JDK 1.6 Update 23的Server Compiler中才开始默认开启了逃逸分析),甚至在某些版本(如JDK 1.6 Update 18)中还曾经短暂的完全禁止了这项优化。
- 如果有需要,并且确认对程序运行有益,用户可以使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析,开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数-XX:EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:PrintEliminateAllocations查看标量的替换情况。
- 尽管目前逃逸分析的技术仍不是十分成熟,但是他却是即时编译器优化技术的一个重要的方向,在今后的虚拟机中,逃逸分析技术肯定会支撑起一系列使用有效的优化技术。
Il principio di base dell'analisi di fuga JVM è determinare la situazione di fuga dell'oggetto attraverso due metodi di analisi: statico e dinamico.
Nel sistema di compilazione Java, il processo di trasformazione di un file di codice sorgente Java in un'istruzione macchina eseguibile dal computer richiede due fasi di compilazione:
La prima sezione di compilazione si riferisce al compilatore front-endfile .javaconvertito infile .class (file di codice byte). I prodotti del compilatore front-end possono essere Javac di JDK o il compilatore incrementale in Eclipse JDT.
Nella seconda fase di compilazione, la JVM interpreta il bytecode e lo traduce nelle corrispondenti istruzioni macchina, legge il bytecode uno per uno e lo interpreta e lo traduce in codice macchina uno per uno.
Ovviamente, a causa del processo intermedio di interpretazione, la sua velocità di esecuzione sarà inevitabilmente molto più lenta di quella di un programma eseguibile in bytecode binario. Questa è la funzione del tradizionale interprete JVM (Interprete).
Per risolvere questo problema di efficienza è stata introdotta la tecnologia JIT (Just In Time Compiler).
Dopo l'introduzione della tecnologia JIT, i programmi Java vengono ancora interpretati ed eseguiti tramite l'interprete, ovvero la parte principale viene ancora interpretata ed eseguita, ma i collegamenti intermedi vengono parzialmente rimossi.
JIT Compiler (Just-in-timeCompiler) compilazione just-in-time. La prima soluzione di implementazione Java consisteva in un insieme di traduttori (interpreti) che traducevano ciascuna istruzione Java in un'istruzione equivalente del microprocessore e le eseguivano in sequenza secondo l'ordine delle istruzioni tradotte, perché un'istruzione Java poteva essere tradotta in una dozzina o dozzine di istruzioni. istruzioni equivalenti del microprocessore, questa modalità viene eseguita molto lentamente.
Quando la JVM rileva che un determinato metodo o blocco di codice viene eseguito con particolare frequenza, lo considererà "Codice Hot Spot". Quindi JIT tradurrà parte dell'"hot code" in codice macchina relativo alla macchina locale, lo ottimizzerà e quindi memorizzerà nella cache il codice macchina tradotto per l'uso successivo.
Dove memorizzare nella cache il codice macchina tradotto? Questa cache si chiama Code Cache. Si può vedere che i metodi per ottenere un'elevata concorrenza tra applicazioni JVM e WEB sono simili e utilizzano ancora l'architettura della cache.
Quando la JVM incontra lo stesso hot code la volta successiva, salta il collegamento intermedio di interpretazione, carica il codice macchina direttamente dalla Code Cache e lo esegue direttamente senza compilarlo nuovamente.
Pertanto, l'obiettivo generale di JIT è scoprire l'hot code e l'hot code è diventato la chiave per migliorare le prestazioni. Ecco come è nato il nome hotspot JVM. È una ricerca permanente identificare l'hot code e scriverlo sul nome.
Pertanto, la strategia complessiva di JVM è:
Per la maggior parte dei codici non comuni, non è necessario dedicare tempo alla loro compilazione in codice macchina, ma eseguirne l'interpretazione e l'esecuzione;
D'altra parte, per l'hot code che occupa solo una piccola parte, possiamo compilarlo in codice macchina per ottenere la velocità di esecuzione ideale.
L'emergere del JIT (compilazione just in time) e la differenza tra gli interpreti
(1) L'interprete interpreta il bytecode in codice macchina Anche se incontra lo stesso bytecode la prossima volta, eseguirà comunque un'interpretazione ripetuta.
(2) JIT compila alcuni bytecode in codici macchina e li memorizza nella Code Cache la prossima volta che si incontra lo stesso codice, verrà eseguito direttamente senza compilarlo nuovamente.
(3) L'interprete interpreta il bytecode in codice macchina comune a tutte le piattaforme.
(4) JIT genererà un codice macchina specifico della piattaforma in base al tipo di piattaforma.
JVM contiene più compilatori just-in-time, principalmente C1 e C2 e Graal (sperimentale).
Più compilatori just-in-time ottimizzeranno il bytecode e genereranno codice macchina
JVM divide lo stato di esecuzione in 5 livelli:
Livello 0, Interprete
Livello 1, compilato ed eseguito utilizzando il compilatore just-in-time C1 (senza profilazione)
Livello 2, compilato ed eseguito utilizzando il compilatore just-in-time C1 (con profilazione di base)
Livello 3, compilato ed eseguito utilizzando il compilatore just-in-time C1 (con profilazione completa)
Livello 4, compilato ed eseguito utilizzando il compilatore just-in-time C2
La JVM non abiliterà direttamente C2. Raccoglierà invece prima lo stato di esecuzione del programma tramite la compilazione C1, quindi determinerà se abilitare C2 in base ai risultati dell'analisi.
Nella modalità di compilazione a livelli, lo stato di esecuzione della macchina virtuale è diviso in cinque livelli da semplice a complesso, da veloce a lento.
Durante la compilazione, oltre a memorizzare nella cache l'hot code per accelerare il processo, JIT eseguirà anche numerose ottimizzazioni sul codice.
Lo scopo di alcune ottimizzazioni è quello diRidurre la pressione sull'allocazione dell'heap di memoria , una delle tecniche importanti nell'ottimizzazione JIT è chiamata analisi di fuga. Secondo l'analisi di escape, il compilatore just-in-time ottimizzerà il codice come segue durante il processo di compilazione:
Controlla la struttura statica del codice per determinare se l'oggetto può sfuggire. Ad esempio, quando un oggetto viene assegnato a una variabile membro di una classe o restituito a un metodo esterno, è possibile determinare che l'oggetto sfugge.
Determina se un oggetto sfugge osservando il comportamento delle chiamate ai metodi e dei riferimenti agli oggetti. Ad esempio, quando più thread fanno riferimento a un oggetto, si può ritenere che l'oggetto sia sfuggito.
L'analisi di fuga esegue un'analisi approfondita del codice per determinare se l'oggetto è uscito dall'ambito del metodo durante la durata del metodo. Se l'oggetto non sfugge, la JVM può allocarlo nello stack anziché nell'heap.
Un oggetto ha tre stati di fuga: fuga globale, fuga da parametro e nessuna fuga.
fuga globale(GlobalEscape): ovvero l'ambito di un oggetto sfugge al metodo corrente o al thread corrente.
Generalmente si presentano i seguenti scenari:
① L'oggetto è una variabile statica
② L'oggetto è un oggetto che è scappato
③ L'oggetto viene utilizzato come valore di ritorno del metodo corrente
Fuga dei parametri(ArgEscape): ovvero un oggetto viene passato come parametro del metodo o referenziato da un parametro, ma non si verifica alcun escape globale durante il processo chiamante. Questo stato è determinato dal bytecode del metodo chiamato.
nessuna via d'uscita: Cioè, l'oggetto nel metodo non sfugge.
Il codice di esempio dello stato di escape è il seguente:
- public class EscapeAnalysisTest {
-
- public static Object globalVariableObject;
-
- public Object instanceObject;
-
- public void globalVariableEscape(){
- globalVariableObject = new Object(); // 静态变量,外部线程可见,发生逃逸
- }
-
- public void instanceObjectEscape(){
- instanceObject = new Object(); // 赋值给堆中实例字段,外部线程可见,发生逃逸
- }
-
- public Object returnObjectEscape(){
- return new Object(); // 返回实例,外部线程可见,发生逃逸
- }
-
- public void noEscape(){
- Object noEscape = new Object(); // 仅创建线程可见,对象无逃逸
- }
-
- }
1. Escape del metodo: nel corpo del metodo, definire una variabile locale, a cui può fare riferimento un metodo esterno, ad esempio passata a un metodo come parametro chiamante o restituita direttamente come oggetto. Oppure si può capire che l'oggetto salta fuori dal metodo.
Gli escape del metodo includono:
- 我们可以用下面的代码来表示这个现象。
-
- //StringBuffer对象发生了方法逃逸
- public static StringBuffer createStringBuffer(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb;
- }
- 上面的例子中,StringBuffer 对象通过return语句返回。
-
- StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。
-
- 甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
-
- 不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。
-
- 具体的代码如下:
-
- // 非方法逃逸
- public static String createString(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb.toString();
- }
- 可以看出,想要逃逸方法的话,需要让对象本身被外部调用,或者说, 对象的指针,传递到了 方法之外。
Come determinare rapidamente se si è verificata l'analisi di fuga. Vediamo se la nuova entità oggetto viene chiamata all'esterno del metodo.
- public class EscapeAnalysis {
-
- public EscapeAnalysis obj;
-
- /**
- * 方法返回EscapeAnalysis对象,发生逃逸
- * @return
- */
- public EscapeAnalysis getInstance() {
- return obj == null ? new EscapeAnalysis():obj;
- }
-
- /**
- * 为成员属性赋值,发生逃逸
- */
- public void setObj() {
- this.obj = new EscapeAnalysis();
- }
-
- /**
- * 对象的作用于仅在当前方法中有效,没有发生逃逸
- */
- public void useEscapeAnalysis() {
- EscapeAnalysis e = new EscapeAnalysis();
- }
-
- /**
- * 引用成员变量的值,发生逃逸
- */
- public void useEscapeAnalysis2() {
- EscapeAnalysis e = getInstance();
- }
- }
2. Escape del thread: questo oggetto è accessibile da altri thread, ad esempio assegnato a una variabile di istanza e accessibile da altri thread. L'oggetto è sfuggito al thread corrente.
L'analisi di fuga può apportare le seguenti strategie di ottimizzazione ai programmi Java: allocazione nello stack, eliminazione della sincronizzazione, sostituzione scalare e incorporamento del metodo;
Parametri relativi all'analisi della fuga:
- -XX:+DoEscapeAnalysis 开启逃逸分析
- -XX:+PrintEscapeAnalysis 开启逃逸分析后,可通过此参数查看分析结果。
- -XX:+EliminateAllocations 开启标量替换
- -XX:+EliminateLocks 开启同步消除
- -XX:+PrintEliminateAllocations 开启标量替换后,查看标量替换情况。
L'analisi di fuga può determinare quali oggetti non sfuggiranno all'ambito del metodo e allocare questi oggetti nello stack anziché nell'heap. Gli oggetti allocati nello stack vengono creati e distrutti all'interno del ciclo di vita della chiamata al metodo senza garbage collection, migliorando così l'efficienza di esecuzione del programma.
In circostanze normali, gli oggetti che non possono fuggire occupano uno spazio relativamente grande. Se lo spazio sullo stack può essere utilizzato, un gran numero di oggetti verrà distrutto al termine del metodo, riducendo la pressione del GC.
Idee di allocazione in pilaL'allocazione sullo stack è una tecnologia di ottimizzazione fornita dalla JVM.
L'idea è:
Problema: poiché la memoria dello stack è relativamente piccola, gli oggetti di grandi dimensioni non possono e non sono adatti per l'allocazione nello stack.
Abilita l'allocazione sullo stack
L'allocazione nello stack si basa sull'analisi dell'escape e sulla sostituzione scalare, quindi l'analisi dell'escape e la sostituzione scalare devono essere abilitate. Naturalmente, JDK1.8 è abilitato per impostazione predefinita.
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
-
-
- 开启标量替换:-XX:+EliminateAllocations
- 关闭标量替换:-XX:-EliminateAllocations
- 显示标量替换详情:-XX:+PrintEliminateAllocations
Esempio di allocazione sullo stack:
- 示例1
- import java.lang.management.ManagementFactory;
- import java.util.List;
- /**
- * 逃逸分析优化-栈上分配
- * 栈上分配,意思是方法内局部变量(未发生逃逸)生成的实例在栈上分配,不用在堆中分配,分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。
- * 一般生成的实例都是放在堆中的,然后把实例的指针或引用压入栈中。
- *虚拟机参数设置如下,表示做了逃逸分析 消耗时间在10毫秒以下
- * -server -Xmx10M -Xms10M
- -XX:+DoEscapeAnalysis -XX:+PrintGC
- *
- *虚拟机参数设置如下,表示没有做逃逸分析 消耗时间在1000毫秒以上
- * -server -Xmx10m -Xms10m
- -XX: -DoEscapeAnalysis -XX:+PrintGC
- * @author 734621
- *
- */
-
- public class OnStack{
- public static void alloc(){
- byte[] b=new byte[2];
- b[0]=1;
- }
- public static void main(String [] args){
- long b=System.currentTimeMillis();
- for(int i=0;i<100000000;i++){
- alloc();
- }
- long e=System.currentTimeMillis();
- System.out.println("消耗时间为:" + (e - b));
- List<String> paramters = ManagementFactory.getRuntimeMXBean().getInputArguments();
- for(String p : paramters){
- System.out.println(p);
- }
- }
- }
-
-
- 加逃逸分析的结果
- [GC (Allocation Failure) 2816K->484K(9984K), 0.0013117 secs]
- 消耗时间为:7
- -Xmx10m
- -Xms10m
- -XX:+DoEscapeAnalysis
- -XX:+PrintGC
-
-
-
- 没有加逃逸分析的结果如下:
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0003174 secs]
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0002524 secs]
- 消耗时间为:1150
- -Xmx10m
- -Xms10m
- -XX:-DoEscapeAnalysis
- -XX:+PrintGC
-
-
- 以上测试可以看出,栈上分配可以明显提高效率: 效率是不开启的1150/7= 160倍
-
-
- 示例2
- 我们通过举例来说明 开启逃逸分析 和 未开启逃逸分析时候的情况
-
- class User {
- private String name;
- private String age;
- private String gender;
- private String phone;
- }
- public class StackAllocation {
- public static void main(String[] args) throws InterruptedException {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- System.out.println("花费的时间为:" + (end - start) + " ms");
-
- // 为了方便查看堆内存中对象个数,线程sleep
- Thread.sleep(10000000);
- }
-
- private static void alloc() {
- // 未发生逃逸
- User user = new User();
- }
- }
- 设置JVM参数,表示未开启逃逸分析
- -Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails
- 花费的时间为:664 ms
- 然后查看内存的情况,发现有大量的User存储在堆中
-
- 开启逃逸分析
- -Xmx1G -Xms1G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails
- 然后查看运行时间,我们能够发现花费的时间快速减少,同时不会发生GC操作
- 花费的时间为:5 ms
- 在看内存情况,我们发现只有很少的User对象,说明User未发生逃逸,因为它存储在栈中,随着栈的销毁而消失。
In confronto, possiamo vedere
L'analisi dell'escape è in grado di rilevare che determinati oggetti sono accessibili solo da un singolo thread e non passano ad altri thread. Pertanto, è possibile eliminare le operazioni di sincronizzazione non necessarie e ridurre il sovraccarico di esecuzione dei programmi multi-thread.
I blocchi di sincronizzazione consumano molto in termini di prestazioni, quindi quando il compilatore determina che un oggetto non è stato sottoposto a escape, rimuoverà il blocco di sincronizzazione dall'oggetto. JDK1.8 abilita i blocchi di sincronizzazione per impostazione predefinita, ma si basa sull'abilitazione dell'analisi di escape.
- -XX:+EliminateLocks #开启同步锁消除(JVM默认状态)
- -XX:-EliminateLocks #关闭同步锁消除
- 通过示例: 明显可以看到“逃逸分析和锁消除” 对性能的提升
-
- public void testLock(){
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100_000_000; i++) {
- locketMethod();
- }
- long t2 = System.currentTimeMillis();
- System.out.println("耗时:"+(t2-t1));
- }
-
- public static void locketMethod(){
- EscapeAnalysis escapeAnalysis = new EscapeAnalysis();
- synchronized(escapeAnalysis) {
- escapeAnalysis.obj2="abcdefg";
- }
- }
-
- 设置JVM参数,开启逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:+DoEscapeAnalysis
-
- 设置JVM参数,关闭逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:-DoEscapeAnalysis
-
- 设置JVM参数,关闭锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:-EliminateLocks
-
- 设置JVM参数,开启锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:+EliminateLocks
-
-
Il costo della sincronizzazione dei thread è piuttosto elevato e la conseguenza della sincronizzazione è una riduzione della concorrenza e delle prestazioni.
Quando si compila dinamicamente un blocco sincronizzato, il compilatore JIT può utilizzare l'analisi di escape per determinare se l'oggetto di blocco utilizzato dal blocco sincronizzato è accessibile solo da un thread e non è stato rilasciato ad altri thread. In caso contrario, il compilatore JIT desincronizzerà questa parte del codice durante la compilazione di questo blocco sincronizzato. Ciò può migliorare notevolmente la concorrenza e le prestazioni. Questo processo di annullamento della sincronizzazione è denominato omissione della sincronizzazione, detta anche eliminazione dei blocchi.
- 例如下面的代码
-
- public void f() {
- Object hellis = new Object();
- synchronized(hellis) {
- System.out.println(hellis);
- }
- }
- 代码中对hellis这个对象加锁,但是hellis对象的生命周期只在f()方法中,并不会被其他线程所访问到,所以在JIT编译阶段就会被优化掉,优化成:
-
- public void f() {
- Object hellis = new Object();
- System.out.println(hellis);
- }
- 我们将其转换成字节码,此处发现,还是有同步锁的身影,是因为优化是在编译阶段的,在加载进内存后发生。

L'analisi di fuga può dividere un oggetto in più scalari, come tipi primitivi o altri oggetti, e assegnarli in posizioni diverse. Ciò può ridurre la frammentazione della memoria e il sovraccarico di accesso agli oggetti e migliorare l'efficienza di utilizzo della memoria.
Prima di tutto, dobbiamo comprendere gli scalari e gli aggregati. I riferimenti ai tipi e agli oggetti di base possono essere intesi come scalari e non possono essere ulteriormente scomposti. La quantità che può essere ulteriormente scomposta è la quantità aggregata, come ad esempio: oggetto.
L'oggetto è una quantità aggregata, che può essere ulteriormente scomposta in scalari e le sue variabili membro in variabili discrete. Questa operazione è chiamata sostituzione scalare.
In questo modo, se un oggetto non scappa, non è necessario crearlo. Verranno creati solo i membri scalari da esso utilizzati nello stack o nel registro, il che consente di risparmiare spazio di memoria e migliorare le prestazioni dell'applicazione.
Anche la sostituzione scalare è abilitata per impostazione predefinita in JDK1.8, ma deve essere basata anche sull'abilitazione dell'analisi di escape.
Uno scalare è un dato che non può essere suddiviso in dati più piccoli. Il tipo di dati primitivo in Java è scalare.
Al contrario, i dati che possono essere scomposti sono chiamati aggregati. Un oggetto in Java è un aggregato perché può essere scomposto in altri aggregati e scalari.
- public static void main(String args[]) {
- alloc();
- }
- class Point {
- private int x;
- private int y;
- }
- private static void alloc() {
- Point point = new Point(1,2);
- System.out.println("point.x" + point.x + ";point.y" + point.y);
- }
- 以上代码,经过标量替换后,就会变成
-
- private static void alloc() {
- int x = 1;
- int y = 2;
- System.out.println("point.x = " + x + "; point.y=" + y);
- }
Nella fase JIT, se attraverso l'analisi di fuga si scopre che un oggetto non sarà accessibile dal mondo esterno, dopo l'ottimizzazione JIT, l'oggetto verrà smontato in diverse variabili membro in esso contenute e sostituito. Questo processo è una sostituzione scalare.
Si può vedere che dopo l'analisi della fuga, si è riscontrato che la quantità aggregata Punto non è sfuggita, quindi è stata sostituita da due scalari. Quindi quali sono i vantaggi della sostituzione scalare? Cioè, può ridurre notevolmente l'utilizzo della memoria heap. Poiché una volta che non è necessario creare oggetti, non è necessario allocare memoria heap. La sostituzione scalare fornisce una buona base per l'allocazione nello stack.

Test di analisi della fuga
- 逃逸分析测试
- 代码如下,大致思路就是 for 循环 1 亿次,循环体内调用外部的 allot() 方法,而 allot() 方法的作用就是简单创建一个对象,但是这个对象是内部的,所以是未逃逸的,所以理论上 JVM 是会进行优化的,我们拭目以待。并且我们会对比开启和关闭逃逸分析之后各自程序的运行时间:
-
- /**
- * @ClassName: EscapeAnalysisTest
- * @Description: http://www.jetchen.cn 逃逸分析 demo
- * @Author: Jet.Chen
- * @Date: 2020/11/23 14:26
- * @Version: 1.0
- **/
- public class EscapeAnalysisTest {
-
- public static void main(String[] args) {
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- allot();
- }
- long t2 = System.currentTimeMillis();
- System.out.println(t2-t1);
- }
-
- private static void allot() {
- Jet jet = new Jet();
- }
-
- static class Jet {
- public String name;
- }
-
- }
- 上面就是我们进行逃逸分析测试的代码, mian() 方法末尾有一个线程暂停,目的是为了观察此时 JVM 中的内存情况。
-
- Step 1:测试开启逃逸
- 由于环境是 jdk1.8,默认开启了逃逸分析,所以直接运行,得到结果如下,程序耗时 3 毫秒:
-
-
- 此时线程是处于睡眠状态的,我们观察下内存情况,发现堆内存中一共新建了 11 万个 Jet 对象。
-
-
-
- Step 2:测试关闭逃逸
- 我们关闭逃逸分析再来运行一次(使用 java -XX:-DoEscapeAnalysis EscapeAnalysisTest 来运行代码即可),得到结果如下,程序耗时 400 毫秒:
-
-
- 此时我们观察下内存情况,发现堆内存中一共新建了 3 千多万个 Jet 对象。
-
-
- 所以,无论是从代码的执行时间(3 毫秒 VS 400 毫秒),还是从堆内存中对象的数量(11 万个 VS 3 千万个)来分析,在上述场景下,开启逃逸分析是有正向益的。
-
- Step 3:测试标量替换
- 我们测试下开启和关闭 标量替换,如下图:
-
-
- 由上图我们可以看出,在上述极端场景下,开启和关闭标量替换对于性能的影响也是满巨大的,另外,同时也验证了标量替换功能生效的前提是逃逸分析已经开启,否则没有意义。
-
- Step 4:测试锁消除
- 测试锁消除,我们需要简单调整下代码,即给 allot() 方法中的内容加锁处理,如下:
-
- private static void allot() {
- Jet jet = new Jet();
- synchronized (jet) {
- jet.name = "jet Chen";
- }
- }
- 然后我们运行测试代码,测试结果也很明显,在上述场景下,开启和关闭锁消除对程序性能的影响也是巨大的。
-
-
- /**
- * 进行两种测试
- * 关闭逃逸分析,同时调大堆空间,避免堆内GC的发生,如果有GC信息将会被打印出来
- * VM运行参数:-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 开启逃逸分析 jdk8默认开启
- * VM运行参数:-Xmx4G -Xms4G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 执行main方法后
- * jps 查看进程
- * jmap -histo 进程ID
- *
- */
- @Slf4j
- public class EscapeTest {
-
- public static void main(String[] args) {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 500000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- log.info("执行时间:" + (end - start) + " ms");
- try {
- Thread.sleep(Integer.MAX_VALUE);
- } catch (InterruptedException e1) {
- e1.printStackTrace();
- }
- }
-
-
- /**
- * JIT编译时会对代码进行逃逸分析
- * 并不是所有对象存放在堆区,有的一部分存在线程栈空间
- * Ponit没有逃逸
- */
- private static String alloc() {
- Point point = new Point();
- return point.toString();
- }
-
- /**
- *同步省略(锁消除) JIT编译阶段优化,JIT经过逃逸分析之后发现无线程安全问题,就会做锁消除
- */
- public void append(String str1, String str2) {
- StringBuffer stringBuffer = new StringBuffer();
- stringBuffer.append(str1).append(str2);
- }
-
- /**
- * 标量替换
- *
- */
- private static void test2() {
- Point point = new Point(1,2);
- System.out.println("point.x="+point.getX()+"; point.y="+point.getY());
-
- // int x=1;
- // int y=2;
- // System.out.println("point.x="+x+"; point.y="+y);
- }
-
-
- }
-
- @Data
- @AllArgsConstructor
- @NoArgsConstructor
- class Point{
- private int x;
- private int y;
- }
L'analisi di fuga può determinare che alcune chiamate al metodo non sfuggiranno all'ambito del metodo corrente. Pertanto, questi metodi possono essere ottimizzati in linea per ridurre il costo delle chiamate ai metodi e migliorare l'efficienza di esecuzione del programma.
Attraverso queste strategie di ottimizzazione, l'analisi di escape può aiutare la JVM a ottimizzare meglio il codice, ridurre il sovraccarico della garbage collection, migliorare l'efficienza e la reattività dell'esecuzione del programma e ridurre l'utilizzo della memoria.
L'analisi di fuga ha un'ampia gamma di scenari applicativi nelle applicazioni Java effettive. Di seguito sono riportati alcuni scenari applicativi comuni:
Il documento sull'analisi della fuga è stato pubblicato nel 1999, ma non è stato implementato fino al JDK1.6 e questa tecnologia non è ancora molto matura.
La ragione fondamentale è che non vi è alcuna garanzia che il consumo di prestazioni dell'analisi di fuga sarà superiore al suo consumo. Sebbene l'analisi di escape possa eseguire la sostituzione scalare, l'allocazione dello stack e l'eliminazione dei blocchi. Tuttavia, l’analisi della fuga stessa richiede anche una serie di analisi complesse, il che in realtà è un processo relativamente dispendioso in termini di tempo.
Un esempio estremo è che dopo l'analisi della fuga si scopre che nessun oggetto non scappa. Quindi il processo di analisi della fuga è sprecato.
Sebbene questa tecnologia non sia molto matura, è anche uno strumento molto importante nella tecnologia di ottimizzazione dei compilatori just-in-time. Ho notato che ci sono alcune opinioni secondo cui attraverso l'analisi di fuga, la JVM allocherà oggetti nello stack che non sfuggiranno. Questo è teoricamente possibile, ma dipende dalla scelta del progettista JvM. Per quanto ne so, Oracle Hotspot JVM non lo fa. Ciò è stato spiegato nei documenti relativi all'analisi di fuga, quindi è chiaro che tutte le istanze dell'oggetto vengono create nell'heap.
Al momento, molti libri sono ancora basati su versioni precedenti a JDK7. JDK ha subito grandi cambiamenti. La cache delle stringhe interne e delle variabili statiche una volta era allocata nella generazione permanente e la generazione permanente è stata sostituita dall'area dei metadati. Tuttavia, la cache delle stringhe interne e le variabili statiche non vengono trasferite nell'area dei metadati, ma vengono allocate direttamente nell'heap, quindi anche questo è coerente con la conclusione del punto precedente: le istanze dell'oggetto vengono allocate nell'heap. L'esempio sopra è accelerato a causa della sostituzione scalare.
Se un oggetto non fuoriesce all'interno del corpo del metodo o all'interno del thread (o viene stabilito che non è riuscito a sfuggire dopo l'analisi dell'escape), è possibile apportare le seguenti ottimizzazioni:
In circostanze normali, gli oggetti che non possono fuggire occupano uno spazio relativamente grande. Se lo spazio sullo stack può essere utilizzato, un gran numero di oggetti verrà distrutto al termine del metodo, riducendo la pressione del GC.
Se è presente un blocco di sincronizzazione sul metodo della classe definita, ma solo un thread vi accede in fase di esecuzione, il codice macchina dopo l'analisi di escape verrà eseguito senza il blocco di sincronizzazione.
I tipi di dati primitivi nella Java virtual machine (tipi numerici come int, long e tipi di riferimento, ecc.) non possono essere ulteriormente scomposti e possono essere chiamati scalari. Al contrario, se un dato può continuare a essere scomposto, viene chiamato aggregato. L'aggregato più tipico in Java è un oggetto. Se l'analisi di escape dimostra che non sarà possibile accedere a un oggetto dall'esterno e che l'oggetto è scomponibile, l'oggetto potrebbe non essere creato quando il programma viene effettivamente eseguito, ma invece creare direttamente molte delle sue variabili membro utilizzate da questo metodo per sostituire. Le variabili disassemblate possono essere analizzate e ottimizzate separatamente. Dopo che gli attributi sono stati appiattiti, non è necessario stabilire relazioni tramite puntatori di riferimento. Possono essere archiviati in modo continuo e compatto, il che è più amichevole per i vari archivi e consente di risparmiare molta gestione dei dati esecuzione. causando una perdita di prestazioni. Allo stesso tempo, puoi anche allocare spazio rispettivamente sullo stack frame o sul registro, in modo che l'oggetto originale non debba allocare spazio nel suo complesso.
La giovane generazione è l'area dove gli oggetti nascono, crescono e muoiono. Qui viene generato e utilizzato, viene infine raccolto dal netturbino e termina la sua vita.
Gli oggetti con cicli di vita lunghi collocati nella vecchia generazione sono solitamente oggetti Java copiati dall'area sopravvissuta. Naturalmente ci sono anche casi speciali. Sappiamo che gli oggetti ordinari verranno allocati su TLAB; se l'oggetto è grande, la JVM proverà ad allocarlo direttamente in altre posizioni in Eden; se l'oggetto è troppo grande, non lo farà; essere in grado di trovare uno spazio libero continuo sufficientemente lungo nello spazio di nuova generazione, la JVM lo assegnerà direttamente alla vecchia generazione. Quando GC si verifica solo nelle giovani generazioni, l'atto di riciclare gli oggetti delle giovani generazioni si chiama MinorGc.
Quando GC si verifica nella vecchia generazione, si chiama MajorGc o FullGC. In generale, la frequenza di occorrenza di MinorGc è molto più elevata di quella di MajorGC, ovvero la frequenza di garbage collection nella vecchia generazione sarà molto inferiore a quella della giovane generazione.
L'analisi di fuga JVM utilizza due metodi di analisi, statico e dinamico, per determinare se un oggetto può sfuggire all'ambito di un metodo. Può aiutare la JVM a ottimizzare il codice e migliorare le prestazioni e l'efficienza nell'utilizzo della memoria dei programmi Java.
Le strategie di ottimizzazione per l'analisi di escape includono l'allocazione nello stack, l'eliminazione della sincronizzazione, la sostituzione scalare e l'inlining del metodo. Queste strategie di ottimizzazione possono ridurre il sovraccarico della garbage collection, migliorare l'efficienza e la reattività dell'esecuzione del programma e ridurre l'utilizzo della memoria.
fare riferimento a:
Italiano: Italiano: https://zhuanlan.zhihu.com/p/693382698
Blog JVM-Heap-Escape Analysis-08-CSDN
JIT memory escape analysis_java disattiva la sostituzione scalare-CSDN Blog
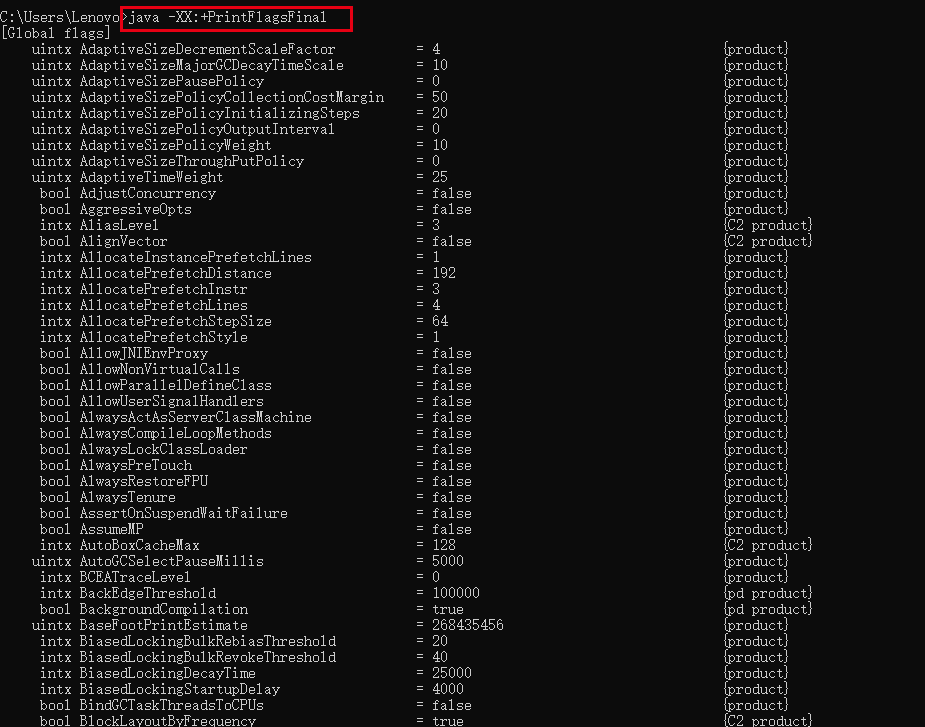
java -XX:+PrintFlagsFinal #输出打印所有参数jvm参数



Si dedica alla ricerca tecnologica da più di trent'anni, è esperto in vari linguaggi come java, linux, javascript, php, css, ecc., e ha apportato numerosi contributi nel campo dell'open source una stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro. Tutti la controllano

Posta[email protected]