2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Varataanko Java-objektit kasamuistiin?
Okei, se on liian abstrakti. Katsotaanpa, mihin seuraavan objektin muisti on varattu.
- public void test() {
- Object object = new Object();
- }
- 这个方法中的object对象,是在堆中分配内存么?
Sano tulos: objekti voi varata muistia pinossa tai kasassa.
Tässä on keskeinen kohta: JVM:n toteutuksessa JVM:n suorituskyvyn parantamiseksi ja muistitilan säästämiseksi JVM tarjoaa "Escape-analyysiksi" kutsutun ominaisuuden, joka on tällä hetkellä suhteellisen huippuluokan optimointitekniikka Java-virtuaalikone, ja se on myös JIT Erittäin tärkeä optimointitekniikka. jdk6 aloitti vasta tämän tekniikan käyttöönotossa, jdk7 alkoi sallia pakoanalyysin oletuksena, jdk8 alkoi parantaa pakoanalyysiä ja otti sen käyttöön oletusarvoisesti JDK 9:ään asti pakoanalyysiä käytetään oletusoptimointimenetelmänä, eikä erityisiä käännösparametreja vaaditaan.
Ymmärrä nyt lause "objekti voi varata muistia pinossa tai varata muistia pinossa". vain Escape-analyysiä on alettu tukea pinossa todennäköisimmin (objekti tässä on hyvin pieni), koska jdk9 tukee ja mahdollistaa vain pakoanalyysin oletuksena.
JIT-kääntäjien (just-in-time-kääntäjien) kehittymisen ja pakoanalyysitekniikan asteittaisen kypsymisen myötä pinon allokointi ja skalaarikorvausoptimointitekniikka saavat "kaikkien objektien allokoinnin kasaan" muuttumaan vähemmän absoluuttisiksi Java Inissa virtuaalikoneen kohteille varataan muistia kasaan, mutta on erikoistapaus, eli jos pakoanalyysin jälkeen havaitaan, että objekti ei karkaa menetelmästä, se voidaan optimoida allokoitavaksi pinoon. Kun menetelmä suoritetaan.Hotspot ei tällä hetkellä tee tätäTämä on myös yleisin varastointitekniikka.
JDK 6u23:n jälkeen (muistettavissa oleva pääversio JDK7) pakoanalyysi on oletuksena käytössä Hotspotissa. Näytä suodatintulokset pakoanalyysiä varten.
Hotspot toteuttaa skalaarikorvauksen Escape-analyysin avulla (ei-pakotetut objektit korvataan skalaareilla ja aggregaatteilla, mikä voi parantaa koodin tehokkuutta), mutta ei-pakotetut objektit varaavat silti muistia kasaan, joten voidaan silti sanoa, että kaikki objektit ovat allokoituja. muisti kasaan.
Lisäksi syvästi räätälöity Open JDK:n perusteellaTaoBao VM, joiden joukossa innovatiivinen GCIH (GC Invisible Hep) -tekniikka toteuttaa kasan ulkopuolella olevia, pitkän elinkaaren omaavia kohteita kasasta kasan ulkopuolelle, eikä GC hallitse Java-objekteja GCIH:n sisällä, mikä vähentää GC:n kierrätystiheyttä ja parantaa tarkoitusta. GC:n talteenoton tehokkuudesta.
Pino: Kun jokainen menetelmä suoritetaan, luodaan samanaikaisesti pinokehys tietojen, kuten paikallisten muuttujataulukoiden, operaatiopinojen, dynaamisten yhteyksien, menetelmän poistumisten jne., tallentamiseen. Prosessi kustakin kutsutusta menetelmästä, kunnes suoritus on valmis, vastaa prosessia, jossa pinokehys työnnetään pinoon ja ponnahtaa ulos pinosta virtuaalikoneen pinossa.
pino:Kun objekti instantioidaan, objekti allokoidaan kasaan ja viittaus kasaan työnnetään pinoon.
paeta:Kun osoittimeen viitataan useilla menetelmillä tai säikeillä, sanomme, että osoitin pakottaa yleensä objektit ja globaalit muuttujat.
Pakenemisanalyysi:Tämän pako-ilmiön analysointiin käytettyä menetelmää kutsutaan pakoanalyysiksi
Escape-analyysin optimointi - allokointi pinossa:Pinon allokointi tarkoittaa, että menetelmässä olevan paikallisen muuttujan luoma ilmentymä (ei tapahdu) varataan pinoon, eikä sitä tarvitse allokoida pinossa Kun varaus on valmis, suoritus jatkuu kutsupinossa. Lopuksi lanka päättyy, pinotila kierrätetään ja myös paikalliset Variable-objektit kierrätetään.


Vastaus: Ei välttämättä.
Jos pakoanalyysin ehdot täyttyvät, pinoon voidaan allokoida objekti.Vähennä keon muistin varausta ja GC-painetta.Koska pinomuisti on rajallinen, jos objekti täyttää skalaarikorvauksen ehdot,Kohdeelle suoritetaan lisäoperaatio sen hajottamiseksi osiin.Skalaarikorvauksen erityinen menetelmä on: JVM hajottaa objektin edelleen ja jakaa objektin useiksi tämän menetelmän käyttämiksi jäsenmuuttujiksi.Siten tavoite pinomuistin ja rekisterien paremmasta hyödyntämisestä saavutetaan.
Tämä on monitoiminen globaali tietovirran analysointialgoritmi, joka voi tehokkaasti vähentää synkronointikuormitusta ja muistin keon varauspainetta Java-ohjelmissa. Escape-analyysin avulla Java Hotspot -kääntäjä voi analysoida uuden objektin viitteen käyttöalueen ja päättää, kohdennetaanko objekti kasaan.
Pakoanalyysin peruskäyttäytyminen on analysoida objektien dynaamista laajuutta:
Tietokonekielen kääntäjän optimointiperiaatteessa pakoanalyysi viittaa osoittimien dynaamisen alueen analysointiin. Se liittyy kääntäjän optimointiperiaatteen osoitinanalyysiin ja muotoanalyysiin. Kun muuttuja (tai objekti) on allokoitu menetelmässä, sen osoitin voidaan palauttaa tai viitata globaalisti, johon viitataan muilla menetelmillä tai säikeillä. Tätä ilmiötä kutsutaan osoittimeksi (tai referenssiksi). Maallikon termein, jos objektin osoittimeen viitataan useilla menetelmillä tai säikeillä, kutsumme objektin osoitinta (tai objektia) Escapeksi (koska tällä hetkellä objekti pakenee metodin tai säikeen paikalliselta laajuudelta).
Lyhyt kuvaus: "Escape-analyysi: staattinen analyysi, joka määrittää osoittimien dynaamisen alueen. Se voi analysoida, missä ohjelmassa osoitin voidaan käyttää äskettäin luotu objekti pakenee.
Perusta just-in-time-käännökselle sen selvittämiseksi, pakeneeko objekti: yksi on, onko objekti tallennettu kasaan (staattinen kenttä vai kasan kohteen ilmentymäkenttä), ja toinen on, siirretäänkö objekti tuntematon koodi.
Escape Analysis on tällä hetkellä suhteellisen huippuluokan optimointitekniikka Java-virtuaalikoneissa, kuten tyypin periytymissuhdeanalyysi, se ei ole keino optimoida koodia suoraan, vaan analyysitekniikka, joka tarjoaa perustan muille optimointimenetelmille.
Escape Analysis: Se on erittäin tärkeä JIT-optimointitekniikka, jota käytetään määrittämään, päästäänkö kohteeseen menetelmän ulkopuolella, eli paeta menetelmän soveltamisalaa. Escape-analyysi on JIT-kääntäjän vaihe. JIT:n avulla voimme määrittää, mitkä objektit voidaan rajoittaa käytettäväksi menetelmän sisällä, eivätkä ne pääse ulos. Sitten ne voidaan optimoida, esimerkiksi allokoida ne pinoon Tai suorita skalaarikorvaus jakaaksesi kohteen useisiin perustyyppeihin tallennusta varten. Se on monitoiminen globaali tietovirran analyysialgoritmi, joka voi tehokkaasti vähentää synkronointikuormitusta ja muistikasan varausta ja roskien keräyspainetta Java-ohjelmissa. Escape-analyysin avulla Java Hotspot -kääntäjä voi analysoida uuden objektin viitteen käyttöalueen ja päättää, kohdennetaanko tämä objekti kasaan.
Escape-analyysi keskittyy pääasiassa paikallisiin muuttujiin sen määrittämiseksi, ovatko kasaan allokoidut objektit jääneet menetelmän ulkopuolelle. Se liittyy osoitinanalyysiin ja kääntäjien optimointiperiaatteiden muoto-analyysiin. Kun muuttuja (tai objekti) on allokoitu menetelmässä, sen osoitin voidaan palauttaa tai viitata globaalisti, johon viitataan muilla menetelmillä tai säikeillä. Tätä ilmiötä kutsutaan osoittimeksi (tai referenssiksi). Maallikon termein, jos objektin osoittimeen viitataan useilla menetelmillä tai säikeillä, sanomme, että objektin osoitin on paennut. Suunnittelemalla koodin rakenne ja tietojen käyttö oikein voidaan pakotusanalyysiä paremmin hyödyntää ohjelman suorituskyvyn optimoimiseksi. Voimme myös vähentää kasaan kohdistuvien objektien allokoinnin lisäkustannuksia ja parantaa muistin käyttöä pakoanalyysin avulla.
Escape-analyysi on tekniikka, jota käytetään määrittämään, pakeniko esine menetelmän ulkopuolelle sen elinkaaren aikana. Java-kehityksessä Escape-analyysillä määritetään objektien elinkaari ja laajuus vastaavan optimoinnin suorittamiseksi sekä ohjelman suorituskyvyn ja muistin käytön tehokkuuden parantamiseksi.
Kun objekti luodaan, sitä voidaan käyttää menetelmän sisällä tai se voidaan siirtää muille menetelmille tai säikeille ja jatkaa olemassaoloa metodin ulkopuolella. Jos objekti ei pakene menetelmän soveltamisalaa, JVM voi varata sen pinoon keon sijaan, jolloin vältetään keon muistin varaamisen ja roskien keräämisen ylimääräiset kustannukset.
- 关于逃逸分析的论文在1999年就已经发表,但直到Sun JDK 1.6才实现了逃逸分析,而且直到现在这项优化尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是不能保证逃逸分析的性能收益必定高于它的消耗。如果要完全准确的判断一个对象是否会逃逸,需要进行数据流敏感的一系列复杂分析,从而确定程序各个分支执行时对此对象的影响。这是一个相对高耗时的过程,如果分析完后发现没有几个不逃逸的对象,那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小的算法来完成逃逸分析。还有一点是,基于逃逸分析的一些优化手段,如上面提到的“栈上分配”,由于HotSpot虚拟机目前的实现方式导致栈上分配实现起来比较复杂,因此在HotSpot中暂时还没有做这项优化。
- 在测试结果中,实施逃逸分析后的程序在MicroBenchmarks中往往能运行出不错的成绩,但是在实际的应用程序,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或因分析过程耗时但却无法有效判别出非逃逸对象而导致性能(即使编译的收益)有所下降,所以在很长的一段时间里,即使是Server Compiler,也默认不开启逃逸分析(在JDK 1.6 Update 23的Server Compiler中才开始默认开启了逃逸分析),甚至在某些版本(如JDK 1.6 Update 18)中还曾经短暂的完全禁止了这项优化。
- 如果有需要,并且确认对程序运行有益,用户可以使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析,开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数-XX:EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:PrintEliminateAllocations查看标量的替换情况。
- 尽管目前逃逸分析的技术仍不是十分成熟,但是他却是即时编译器优化技术的一个重要的方向,在今后的虚拟机中,逃逸分析技术肯定会支撑起一系列使用有效的优化技术。
JVM:n pakoanalyysin perusperiaate on määrittää kohteen pakotilanne kahdella analyysimenetelmällä: staattinen ja dynaaminen.
Java-käännösjärjestelmässä Java-lähdekooditiedoston muuttaminen tietokoneella suoritettavaksi konekäskyksi vaatii kaksi käännösvaihetta:
Kokoelman ensimmäinen osa viittaa käyttöliittymän kääntäjään.java-tiedostomuunnettu.class tiedosto (tavukooditiedosto). Etupään kääntäjätuotteet voivat olla JDK:n Javac tai inkrementaalinen kääntäjä Eclipse JDT:ssä.
Toisessa käännösvaiheessa JVM tulkitsee tavukoodin ja kääntää sen vastaaviksi konekäskyiksi, lukee tavukoodin yksitellen ja tulkitsee ja kääntää sen yksitellen konekoodiksi.
On selvää, että välivaiheen tulkintaprosessin vuoksi sen suoritusnopeus on väistämättä paljon hitaampi kuin suoritettavan binaaritavukoodiohjelman. Tämä on perinteisen JVM-tulkin (interpreter) toiminto.
Tämän tehokkuusongelman ratkaisemiseksi otettiin käyttöön JIT (Just In Time Compiler) -tekniikka.
JIT-teknologian käyttöönoton jälkeen Java-ohjelmat tulkitaan ja suoritetaan edelleen tulkin kautta. Eli pääosa tulkitaan ja suoritetaan, mutta välilinkit poistetaan osittain.
JIT Compiler (Just-in-timeCompiler) juuri-in-time-käännös. Varhaisin Java-toteutusratkaisu koostui joukosta kääntäjiä (tulkkeja), jotka käänsivät jokaisen Java-käskyn vastaavaksi mikroprosessorikäskyksi ja suorittivat ne peräkkäin käännettyjen käskyjen järjestyksen mukaan, koska Java-käsky saattoi kääntää kymmeniksi tai kymmeniksi vastaavat mikroprosessorin käskyt, tämä tila suoritetaan hyvin hitaasti.
Kun JVM havaitsee, että tietty menetelmä tai koodilohko on käynnissä erityisen usein, se pitää sitä "Hot Spot Codena". Sitten JIT kääntää osan "kuumasta koodista" paikalliseen koneeseen liittyväksi konekoodiksi, optimoi sen ja tallentaa sitten käännetyn konekoodin välimuistiin seuraavaa käyttöä varten.
Mihin käännetty konekoodi tallennetaan välimuistiin? Tätä välimuistia kutsutaan koodivälimuistiksi. Voidaan nähdä, että menetelmät korkean samanaikaisuuden saavuttamiseksi JVM- ja WEB-sovellusten välillä ovat samanlaisia, ja ne käyttävät edelleen välimuistiarkkitehtuuria.
Kun JVM kohtaa saman kuumakoodin seuraavan kerran, se ohittaa tulkkauslinkin, lataa konekoodin suoraan koodivälimuistista ja suorittaa sen suoraan kääntämättä sitä uudelleen.
Siksi JIT:n yleistavoite on löytää kuuma koodi, ja siitä on tullut avain suorituskyvyn parantamiseen. Näin syntyi hotspot-nimi JVM. Se on elinikäinen pyrkimys tunnistaa kuuma koodi ja kirjoittaa se nimeen.
Siksi JVM:n yleinen strategia on:
Useimpien epätavallisten koodien kohdalla meidän ei tarvitse käyttää aikaa niiden kääntämiseen konekoodiksi, vaan ne on suoritettava tulkinnan ja suorituksen kautta.
Toisaalta kuumakoodille, joka vie vain pienen osan, voimme kääntää sen konekoodiksi saavuttaaksemme ihanteellisen ajonopeuden.
JIT:n (just in time compilation) syntyminen ja tulkkien välinen ero
(1) Tulkki tulkitsee tavukoodin konekoodiksi, vaikka se kohtaisikin seuraavan kerran saman tavukoodin, se suorittaa silti toistuvan tulkinnan.
(2) JIT kokoaa joitain tavukoodeja konekoodeiksi ja tallentaa ne koodivälimuistiin Kun seuraavan kerran kohtaa saman koodin, se suoritetaan suoraan kääntämättä sitä uudelleen.
(3) Tulkki tulkitsee tavukoodin konekoodiksi, joka on yhteinen kaikille alustoille.
(4) JIT luo alustakohtaisen konekoodin alustatyypin perusteella.
JVM sisältää useita juuri-in-time-kääntäjiä, pääasiassa C1 ja C2 sekä Graal (kokeellinen).
Useat juuri-in-time-kääntäjät optimoivat tavukoodin ja luovat konekoodin
JVM jakaa suoritustilan viiteen tasoon:
Taso 0, tulkki
Taso 1, käännetty ja suoritettu C1 just-in-time -kääntäjällä (ilman profilointia)
Taso 2, käännetty ja suoritettu C1 just-in-time -kääntäjällä (perusprofiloinnilla)
Taso 3, käännetty ja suoritettu C1 just-in-time -kääntäjällä (täydellinen profilointi)
Taso 4, käännetty ja suoritettu C2 just-in-time -kääntäjällä
JVM ei ota suoraan käyttöön C2:ta. Sen sijaan se kerää ensin ohjelman käynnissä olevan tilan C1-käännöksen avulla ja määrittää sitten, otetaanko C2 käyttöön analyysitulosten perusteella.
Kerrostetussa käännöstilassa virtuaalikoneen suoritustila on jaettu viiteen kerrokseen yksinkertaisesta monimutkaiseen, nopeasta hitaaseen.
Kääntämisen aikana JIT tekee koodin nopeuttamiseksi välimuistiin tallennuksen lisäksi myös monia optimointeja koodille.
Joidenkin optimointien tarkoituksena onVähennä muistin varauspainetta Yksi tärkeimmistä JIT-optimoinnin tekniikoista on nimeltään pakoanalyysi. Escape-analyysin mukaan just-in-time-kääntäjä optimoi koodin käännösprosessin aikana seuraavasti:
Se tarkistaa koodin staattisen rakenteen määrittääkseen, voiko objekti paeta. Esimerkiksi, kun objekti määrätään luokan jäsenmuuttujaan tai palautetaan ulkoiseen menetelmään, voidaan määrittää, että objekti pakenee.
Se määrittää, pakeneeko objekti tarkkailemalla menetelmäkutsujen ja objektiviittausten käyttäytymistä. Esimerkiksi kun objektiin viitataan useilla säikeillä, objektin voidaan katsoa pakeneneen.
Escape-analyysi suorittaa koodin perusteellisen analyysin määrittääkseen, onko objekti karannut menetelmän soveltamisalan ulkopuolelle menetelmän elinkaaren aikana. Jos objekti ei pakene, JVM voi allokoida sen pinoon keon sijaan.
Objektilla on kolme pakotilaa: globaali pakotila, parametripoistumistila ja ei pakotilaa.
globaali pako(GlobalEscape): Eli objektin laajuus pakenee nykyisestä menetelmästä tai nykyisestä säikeestä.
Yleensä on olemassa seuraavat skenaariot:
① Objekti on staattinen muuttuja
② Kohde on paennut esine
③ Objektia käytetään nykyisen menetelmän palautusarvona
Parametrien pako(ArgEscape): Eli objekti välitetään menetelmäparametrina tai siihen viitataan parametrilla, mutta kutsuprosessin aikana ei tapahdu globaalia pakoa. Tämä tila määräytyy kutsutun menetelmän tavukoodin mukaan.
ei pakopaikkaa: Eli metodin objekti ei pakene.
Escape-tilan esimerkkikoodi on seuraava:
- public class EscapeAnalysisTest {
-
- public static Object globalVariableObject;
-
- public Object instanceObject;
-
- public void globalVariableEscape(){
- globalVariableObject = new Object(); // 静态变量,外部线程可见,发生逃逸
- }
-
- public void instanceObjectEscape(){
- instanceObject = new Object(); // 赋值给堆中实例字段,外部线程可见,发生逃逸
- }
-
- public Object returnObjectEscape(){
- return new Object(); // 返回实例,外部线程可见,发生逃逸
- }
-
- public void noEscape(){
- Object noEscape = new Object(); // 仅创建线程可见,对象无逃逸
- }
-
- }
1. Method escape: Määritä metodirungossa paikallinen muuttuja, johon voi viitata ulkoinen menetelmä, kuten se voidaan siirtää menetelmälle kutsuvana parametrina tai palauttaa suoraan objektina. Tai voidaan ymmärtää, että objekti hyppää pois menetelmästä.
Menetelmän pakotteita ovat:
- 我们可以用下面的代码来表示这个现象。
-
- //StringBuffer对象发生了方法逃逸
- public static StringBuffer createStringBuffer(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb;
- }
- 上面的例子中,StringBuffer 对象通过return语句返回。
-
- StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。
-
- 甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
-
- 不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。
-
- 具体的代码如下:
-
- // 非方法逃逸
- public static String createString(String s1, String s2) {
- StringBuffer sb = new StringBuffer();
- sb.append(s1);
- sb.append(s2);
- return sb.toString();
- }
- 可以看出,想要逃逸方法的话,需要让对象本身被外部调用,或者说, 对象的指针,传递到了 方法之外。
Kuinka nopeasti selvittää, onko pakoanalyysi tapahtunut. Katsotaan, kutsutaanko uutta objektientiteettiä menetelmän ulkopuolelle?
- public class EscapeAnalysis {
-
- public EscapeAnalysis obj;
-
- /**
- * 方法返回EscapeAnalysis对象,发生逃逸
- * @return
- */
- public EscapeAnalysis getInstance() {
- return obj == null ? new EscapeAnalysis():obj;
- }
-
- /**
- * 为成员属性赋值,发生逃逸
- */
- public void setObj() {
- this.obj = new EscapeAnalysis();
- }
-
- /**
- * 对象的作用于仅在当前方法中有效,没有发生逃逸
- */
- public void useEscapeAnalysis() {
- EscapeAnalysis e = new EscapeAnalysis();
- }
-
- /**
- * 引用成员变量的值,发生逃逸
- */
- public void useEscapeAnalysis2() {
- EscapeAnalysis e = getInstance();
- }
- }
2. Säikeen poisto: Muut säikeet käyttävät tätä objektia, kuten se on määritetty ilmentymämuuttujalle ja muut säikeet. Objekti pakeni nykyisestä säikeestä.
Escape-analyysi voi tuoda seuraavat optimointistrategiat Java-ohjelmiin: allokointi pinossa, synkronoinnin eliminointi, skalaarikorvaus ja menetelmän rivitys;
Escape-analyysiin liittyvät parametrit:
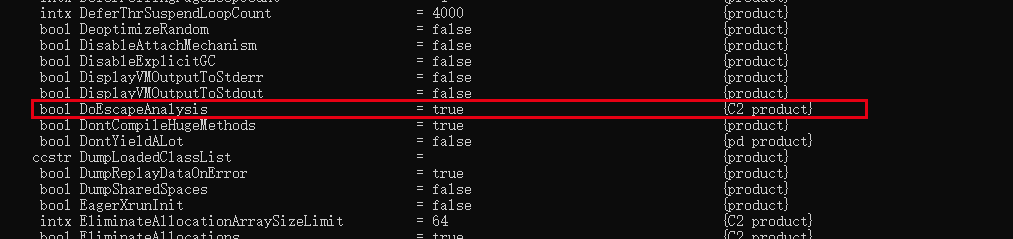
- -XX:+DoEscapeAnalysis 开启逃逸分析
- -XX:+PrintEscapeAnalysis 开启逃逸分析后,可通过此参数查看分析结果。
- -XX:+EliminateAllocations 开启标量替换
- -XX:+EliminateLocks 开启同步消除
- -XX:+PrintEliminateAllocations 开启标量替换后,查看标量替换情况。
Escape-analyysi voi määrittää, mitkä objektit eivät pakene menetelmän soveltamisalaa, ja allokoi nämä objektit pinoon keon sijaan. Pinoon allokoidut objektit luodaan ja tuhoutuvat menetelmäkutsujen elinkaaren aikana ilman roskien keräämistä, mikä parantaa ohjelman suoritustehoa.
Tavallisissa olosuhteissa esineet, jotka eivät pääse pakoon, vievät suhteellisen paljon tilaa. Jos pinossa olevaa tilaa voidaan käyttää, suuri määrä esineitä tuhoutuu menetelmän päättyessä, mikä vähentää GC-painetta.
Allokaatioideoita pinossaPinon allokointi on JVM:n tarjoama optimointitekniikka.
Idea on:
Ongelma: Koska pinomuisti on suhteellisen pieni, suuret objektit eivät voi eivätkä sovellu allokoitaviksi pinossa.
Ota pinossa oleva allokointi käyttöön
Pinon allokointi perustuu pakoanalyysiin ja skalaarikorvaukseen, joten pakoanalyysin ja skalaarikorvauksen on oltava käytössä. JDK1.8 on tietysti oletuksena käytössä.
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
-
-
- 开启标量替换:-XX:+EliminateAllocations
- 关闭标量替换:-XX:-EliminateAllocations
- 显示标量替换详情:-XX:+PrintEliminateAllocations
Esimerkki allokoinnista pinossa:
- 示例1
- import java.lang.management.ManagementFactory;
- import java.util.List;
- /**
- * 逃逸分析优化-栈上分配
- * 栈上分配,意思是方法内局部变量(未发生逃逸)生成的实例在栈上分配,不用在堆中分配,分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。
- * 一般生成的实例都是放在堆中的,然后把实例的指针或引用压入栈中。
- *虚拟机参数设置如下,表示做了逃逸分析 消耗时间在10毫秒以下
- * -server -Xmx10M -Xms10M
- -XX:+DoEscapeAnalysis -XX:+PrintGC
- *
- *虚拟机参数设置如下,表示没有做逃逸分析 消耗时间在1000毫秒以上
- * -server -Xmx10m -Xms10m
- -XX: -DoEscapeAnalysis -XX:+PrintGC
- * @author 734621
- *
- */
-
- public class OnStack{
- public static void alloc(){
- byte[] b=new byte[2];
- b[0]=1;
- }
- public static void main(String [] args){
- long b=System.currentTimeMillis();
- for(int i=0;i<100000000;i++){
- alloc();
- }
- long e=System.currentTimeMillis();
- System.out.println("消耗时间为:" + (e - b));
- List<String> paramters = ManagementFactory.getRuntimeMXBean().getInputArguments();
- for(String p : paramters){
- System.out.println(p);
- }
- }
- }
-
-
- 加逃逸分析的结果
- [GC (Allocation Failure) 2816K->484K(9984K), 0.0013117 secs]
- 消耗时间为:7
- -Xmx10m
- -Xms10m
- -XX:+DoEscapeAnalysis
- -XX:+PrintGC
-
-
-
- 没有加逃逸分析的结果如下:
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0003174 secs]
- [GC (Allocation Failure) 3320K->504K(9984K), 0.0002524 secs]
- 消耗时间为:1150
- -Xmx10m
- -Xms10m
- -XX:-DoEscapeAnalysis
- -XX:+PrintGC
-
-
- 以上测试可以看出,栈上分配可以明显提高效率: 效率是不开启的1150/7= 160倍
-
-
- 示例2
- 我们通过举例来说明 开启逃逸分析 和 未开启逃逸分析时候的情况
-
- class User {
- private String name;
- private String age;
- private String gender;
- private String phone;
- }
- public class StackAllocation {
- public static void main(String[] args) throws InterruptedException {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- System.out.println("花费的时间为:" + (end - start) + " ms");
-
- // 为了方便查看堆内存中对象个数,线程sleep
- Thread.sleep(10000000);
- }
-
- private static void alloc() {
- // 未发生逃逸
- User user = new User();
- }
- }
- 设置JVM参数,表示未开启逃逸分析
- -Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails
- 花费的时间为:664 ms
- 然后查看内存的情况,发现有大量的User存储在堆中
-
- 开启逃逸分析
- -Xmx1G -Xms1G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails
- 然后查看运行时间,我们能够发现花费的时间快速减少,同时不会发生GC操作
- 花费的时间为:5 ms
- 在看内存情况,我们发现只有很少的User对象,说明User未发生逃逸,因为它存储在栈中,随着栈的销毁而消失。
Vertailun vuoksi voimme nähdä
Escape-analyysi voi havaita, että tiettyihin objekteihin pääsee vain yksi säie, eivätkä ne pääse muihin säikeisiin. Näin ollen tarpeettomat synkronointitoimenpiteet voidaan eliminoida ja monisäikeisten ohjelmien suorituskustannukset vähenevät.
Synkronointilukot ovat erittäin suorituskykyä vieviä, joten kun kääntäjä toteaa, että objekti ei ole paennut, se poistaa synkronointilukon objektista. JDK1.8 mahdollistaa synkronointilukot oletuksena, mutta se perustuu pakoanalyysin sallimiseen.
- -XX:+EliminateLocks #开启同步锁消除(JVM默认状态)
- -XX:-EliminateLocks #关闭同步锁消除
- 通过示例: 明显可以看到“逃逸分析和锁消除” 对性能的提升
-
- public void testLock(){
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100_000_000; i++) {
- locketMethod();
- }
- long t2 = System.currentTimeMillis();
- System.out.println("耗时:"+(t2-t1));
- }
-
- public static void locketMethod(){
- EscapeAnalysis escapeAnalysis = new EscapeAnalysis();
- synchronized(escapeAnalysis) {
- escapeAnalysis.obj2="abcdefg";
- }
- }
-
- 设置JVM参数,开启逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:+DoEscapeAnalysis
-
- 设置JVM参数,关闭逃逸分析, 耗时:
- java -Xmx64m -Xms64m -XX:-DoEscapeAnalysis
-
- 设置JVM参数,关闭锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:-EliminateLocks
-
- 设置JVM参数,开启锁消除,再次运行
- java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:+EliminateLocks
-
-
Säikeen synkronoinnin kustannukset ovat melko korkeat, ja synkronoinnin seurauksena samanaikaisuus ja suorituskyky vähenevät.
Käännettäessä dynaamisesti synkronoitua lohkoa JIT-kääntäjä voi käyttää Escape-analyysiä määrittääkseen, pääseekö synkronoidun lohkon käyttämään lukkoobjektiin vain yksi säike, eikä sitä ole vapautettu muille säikeille. Jos ei, JIT-kääntäjä desynkronoi tämän osan koodista kääntäessään tätä synkronoitua lohkoa. Tämä voi parantaa huomattavasti samanaikaisuutta ja suorituskykyä. Tätä synkronoinnin peruutusprosessia kutsutaan synkronoinnin poisjättämiseksi, jota kutsutaan myös lukituksen poistamiseksi.
- 例如下面的代码
-
- public void f() {
- Object hellis = new Object();
- synchronized(hellis) {
- System.out.println(hellis);
- }
- }
- 代码中对hellis这个对象加锁,但是hellis对象的生命周期只在f()方法中,并不会被其他线程所访问到,所以在JIT编译阶段就会被优化掉,优化成:
-
- public void f() {
- Object hellis = new Object();
- System.out.println(hellis);
- }
- 我们将其转换成字节码,此处发现,还是有同步锁的身影,是因为优化是在编译阶段的,在加载进内存后发生。

Escape-analyysi voi jakaa kohteen useisiin skalaareihin, kuten primitiivityyppeihin tai muihin objekteihin, ja määrittää ne eri paikkoihin. Tämä voi vähentää muistin pirstoutumista ja objektien käyttökustannuksia ja parantaa muistin käytön tehokkuutta.
Ensinnäkin meidän on ymmärrettävä skalaarit ja aggregaatit. Viittaukset perustyyppeihin ja esineisiin voidaan ymmärtää skalaareina, eikä niitä voida hajottaa enempää. Määrä, joka voidaan edelleen hajottaa, on kokonaissuure, kuten: objekti.
Objekti on aggregaattisuure, joka voidaan edelleen jakaa skalaariksi ja sen jäsenmuuttujat diskreeteiksi muuttujiksi. Tätä kutsutaan skalaarikorvaukseksi.
Tällä tavalla, jos objekti ei karkaa, sitä ei tarvitse luoda ollenkaan. Pinoon tai rekisteriin luodaan vain sen käyttämät jäsenskalaarit, mikä säästää muistitilaa ja parantaa sovelluksen suorituskykyä.
Skalaarikorvaus on myös oletusarvoisesti käytössä JDK1.8:ssa, mutta sen on myös perustuttava pakoanalyysiin, joka on käytössä.
Skalaari on dataa, jota ei voi jakaa pienemmiksi tiedoiksi. Javan primitiivinen tietotyyppi on skalaari.
Sitä vastoin tietoja, jotka voidaan hajottaa, kutsutaan aggregaatiksi. Java-objekti on aggregaatti, koska se voidaan hajottaa muihin aggregaatteihin ja skalaareihin.
- public static void main(String args[]) {
- alloc();
- }
- class Point {
- private int x;
- private int y;
- }
- private static void alloc() {
- Point point = new Point(1,2);
- System.out.println("point.x" + point.x + ";point.y" + point.y);
- }
- 以上代码,经过标量替换后,就会变成
-
- private static void alloc() {
- int x = 1;
- int y = 2;
- System.out.println("point.x = " + x + "; point.y=" + y);
- }
Jos JIT-vaiheessa todetaan pakoanalyysin avulla, että ulkomaailma ei pääse käsiksi esineeseen, niin JIT-optimoinnin jälkeen objekti puretaan useiksi sen sisältämiksi jäsenmuuttujiksi ja korvataan. Tämä prosessi on skalaarikorvaus.
Voidaan nähdä, että pakoanalyysin jälkeen havaittiin, että aggregaattimäärä Piste ei päässyt karkuun, joten se korvattiin kahdella skalaarilla. Mitä hyötyä skalaarikorvauksesta on? Eli se voi vähentää huomattavasti keon muistin käyttöä. Koska kun objekteja ei tarvitse luoda, ei ole tarvetta varata kasamuistia. Skalaarikorvaus tarjoaa hyvän pohjan pinon allokoinnille.

Pakenemisanalyysin testaus
- 逃逸分析测试
- 代码如下,大致思路就是 for 循环 1 亿次,循环体内调用外部的 allot() 方法,而 allot() 方法的作用就是简单创建一个对象,但是这个对象是内部的,所以是未逃逸的,所以理论上 JVM 是会进行优化的,我们拭目以待。并且我们会对比开启和关闭逃逸分析之后各自程序的运行时间:
-
- /**
- * @ClassName: EscapeAnalysisTest
- * @Description: http://www.jetchen.cn 逃逸分析 demo
- * @Author: Jet.Chen
- * @Date: 2020/11/23 14:26
- * @Version: 1.0
- **/
- public class EscapeAnalysisTest {
-
- public static void main(String[] args) {
- long t1 = System.currentTimeMillis();
- for (int i = 0; i < 100000000; i++) {
- allot();
- }
- long t2 = System.currentTimeMillis();
- System.out.println(t2-t1);
- }
-
- private static void allot() {
- Jet jet = new Jet();
- }
-
- static class Jet {
- public String name;
- }
-
- }
- 上面就是我们进行逃逸分析测试的代码, mian() 方法末尾有一个线程暂停,目的是为了观察此时 JVM 中的内存情况。
-
- Step 1:测试开启逃逸
- 由于环境是 jdk1.8,默认开启了逃逸分析,所以直接运行,得到结果如下,程序耗时 3 毫秒:
-
-
- 此时线程是处于睡眠状态的,我们观察下内存情况,发现堆内存中一共新建了 11 万个 Jet 对象。
-
-
-
- Step 2:测试关闭逃逸
- 我们关闭逃逸分析再来运行一次(使用 java -XX:-DoEscapeAnalysis EscapeAnalysisTest 来运行代码即可),得到结果如下,程序耗时 400 毫秒:
-
-
- 此时我们观察下内存情况,发现堆内存中一共新建了 3 千多万个 Jet 对象。
-
-
- 所以,无论是从代码的执行时间(3 毫秒 VS 400 毫秒),还是从堆内存中对象的数量(11 万个 VS 3 千万个)来分析,在上述场景下,开启逃逸分析是有正向益的。
-
- Step 3:测试标量替换
- 我们测试下开启和关闭 标量替换,如下图:
-
-
- 由上图我们可以看出,在上述极端场景下,开启和关闭标量替换对于性能的影响也是满巨大的,另外,同时也验证了标量替换功能生效的前提是逃逸分析已经开启,否则没有意义。
-
- Step 4:测试锁消除
- 测试锁消除,我们需要简单调整下代码,即给 allot() 方法中的内容加锁处理,如下:
-
- private static void allot() {
- Jet jet = new Jet();
- synchronized (jet) {
- jet.name = "jet Chen";
- }
- }
- 然后我们运行测试代码,测试结果也很明显,在上述场景下,开启和关闭锁消除对程序性能的影响也是巨大的。
-
-
- /**
- * 进行两种测试
- * 关闭逃逸分析,同时调大堆空间,避免堆内GC的发生,如果有GC信息将会被打印出来
- * VM运行参数:-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 开启逃逸分析 jdk8默认开启
- * VM运行参数:-Xmx4G -Xms4G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
- *
- * 执行main方法后
- * jps 查看进程
- * jmap -histo 进程ID
- *
- */
- @Slf4j
- public class EscapeTest {
-
- public static void main(String[] args) {
- long start = System.currentTimeMillis();
- for (int i = 0; i < 500000; i++) {
- alloc();
- }
- long end = System.currentTimeMillis();
- log.info("执行时间:" + (end - start) + " ms");
- try {
- Thread.sleep(Integer.MAX_VALUE);
- } catch (InterruptedException e1) {
- e1.printStackTrace();
- }
- }
-
-
- /**
- * JIT编译时会对代码进行逃逸分析
- * 并不是所有对象存放在堆区,有的一部分存在线程栈空间
- * Ponit没有逃逸
- */
- private static String alloc() {
- Point point = new Point();
- return point.toString();
- }
-
- /**
- *同步省略(锁消除) JIT编译阶段优化,JIT经过逃逸分析之后发现无线程安全问题,就会做锁消除
- */
- public void append(String str1, String str2) {
- StringBuffer stringBuffer = new StringBuffer();
- stringBuffer.append(str1).append(str2);
- }
-
- /**
- * 标量替换
- *
- */
- private static void test2() {
- Point point = new Point(1,2);
- System.out.println("point.x="+point.getX()+"; point.y="+point.getY());
-
- // int x=1;
- // int y=2;
- // System.out.println("point.x="+x+"; point.y="+y);
- }
-
-
- }
-
- @Data
- @AllArgsConstructor
- @NoArgsConstructor
- class Point{
- private int x;
- private int y;
- }
Escape-analyysi voi määrittää, että tietyt menetelmäkutsut eivät pakene nykyisen menetelmän soveltamisalaa. Siksi nämä menetelmät voidaan optimoida inline menetelmäkutsujen kustannusten vähentämiseksi ja ohjelman suoritustehokkuuden parantamiseksi.
Näiden optimointistrategioiden avulla pakoanalyysi voi auttaa JVM:ää optimoimaan koodin paremmin, vähentämään roskien keräämisen yleiskustannuksia, parantamaan ohjelman suoritustehokkuutta ja reagointikykyä sekä vähentämään muistin käyttöä.
Escape-analyysissä on laaja valikoima sovellusskenaarioita todellisissa Java-sovelluksissa. Seuraavassa on joitain yleisiä sovellusskenaarioita:
Paperi pakoanalyysistä julkaistiin vuonna 1999, mutta se otettiin käyttöön vasta JDK1.6:ssa, eikä tämä tekniikka ole vielä kovin kypsä.
Perimmäinen syy on se, että ei ole takeita siitä, että pakoanalyysin suorituskulutus on suurempi kuin sen kulutus. Vaikka pakoanalyysi voi tehdä skalaarikorvauksen, pinon allokoinnin ja lukituksen poistamisen. Itse pakoanalyysi vaatii kuitenkin myös sarjan monimutkaisia analyyseja, mikä on itse asiassa suhteellisen aikaa vievä prosessi.
Äärimmäinen esimerkki on, että pakoanalyysin jälkeen havaitaan, että mikään esine ei karkaa. Sitten pakoanalyysiprosessi menee hukkaan.
Vaikka tämä tekniikka ei ole kovin kypsä, se on myös erittäin tärkeä keino juuri-in-time-kääntäjän optimointiteknologiassa. Huomasin, että on olemassa mielipiteitä, että pakoanalyysin avulla JVM varaa pinoon kohteita, jotka eivät pääse karkuun. Tämä on teoriassa mahdollista, mutta se riippuu JvM-suunnittelijan valinnasta. Sikäli kuin tiedän, Oracle Hotspot JVM ei tee tätä. Tämä on selitetty pakoanalyysiin liittyvissä asiakirjoissa, joten on selvää, että kaikki objektiinstanssit luodaan kasaan.
Tällä hetkellä monet kirjat perustuvat versioihin ennen JDK7:tä. Sisäisten merkkijonojen ja staattisten muuttujien välimuisti on aikoinaan varattu pysyvälle sukupolvelle, ja pysyvä sukupolvi on korvattu metatietoalueella. Sisäistä merkkijonovälimuistia ja staattisia muuttujia ei kuitenkaan siirretä metatietoalueelle, vaan ne allokoidaan suoraan kasaan, joten tämä on myös yhdenmukainen edellisen kohdan päätelmän kanssa: objektiinstanssit allokoidaan kasaan. Yllä oleva esimerkki on nopeutunut skalaarikorvauksen vuoksi.
Jos objekti ei pakene menetelmän rungossa tai säikeessä (tai todetaan, että se ei pakene pakoanalyysin jälkeen), voidaan tehdä seuraavat optimoinnit:
Tavallisissa olosuhteissa esineet, jotka eivät pääse pakoon, vievät suhteellisen paljon tilaa. Jos pinossa olevaa tilaa voidaan käyttää, suuri määrä esineitä tuhoutuu menetelmän päättyessä, mikä vähentää GC-painetta.
Jos määrittämäsi luokan menetelmässä on synkronointilukko, mutta vain yksi säiettä käyttää sitä ajon aikana, konekoodi suoritetaan pakoanalyysin jälkeen ilman synkronointilukkoa.
Java-virtuaalikoneen primitiivisiä tietotyyppejä (numeerisia tyyppejä, kuten int, long ja referenssityypit jne.) ei voida hajottaa edelleen, ja niitä voidaan kutsua skalaariksi. Sitä vastoin, jos dataa voidaan edelleen hajottaa, sitä kutsutaan aggregaatiksi. Tyypillisin Java-aggregaatti on objekti. Jos pakoanalyysi osoittaa, että objektiin ei päästä ulkoisesti ja että objekti on hajotettava, objektia ei välttämättä luoda, kun ohjelma todella suoritetaan, vaan sen sijaan luodaan suoraan useita tämän menetelmän käyttämiä jäsenmuuttujia. Puretut muuttujat voidaan analysoida ja optimoida erikseen. suoritus aiheuttaa suorituskyvyn menetystä. Samalla voit myös varata tilaa pinokehykselle tai rekisterille, jotta alkuperäisen objektin ei tarvitse varata tilaa kokonaisuutena.
Nuori sukupolvi on alue, jossa esineet syntyvät, kasvavat ja kuolevat. Täällä syntyy ja käytetään esinettä, jonka lopulta keräilijä kerää ja lopettaa käyttöikänsä.
Vanhaan sukupolveen sijoitetut pitkän elinkaaren omaavat objektit ovat yleensä selviytymisalueelta kopioituja Java-objekteja. Tietenkin on myös erikoistapauksia. Tiedämme, että jos objekti on suuri, se yrittää allokoida sen suoraan muihin paikkoihin Edenissä pystyä löytämään riittävän pitkän jatkuvan vapaan tilan uudessa sukupolvessa, JVM jakaa sen suoraan vanhalle sukupolvelle. Kun GC:tä esiintyy vain nuorella sukupolvella, nuoren sukupolven esineiden kierrätystä kutsutaan MinorGc:ksi.
Kun GC esiintyy vanhassa sukupolvessa, sitä kutsutaan MajorGc:ksi tai FullGC:ksi. Yleisesti ottaen MinorGc:n esiintymistiheys on paljon suurempi kuin MajorGC:n, eli vanhan sukupolven roskienkeräystaajuus on paljon pienempi kuin nuorella sukupolvella.
JVM-pako-analyysi käyttää kahta analyysimenetelmää, staattista ja dynaamista, määrittääkseen, voiko objekti jäädä menetelmän ulkopuolelle. Se voi auttaa JVM:ää optimoimaan koodin ja parantamaan Java-ohjelmien suorituskykyä ja muistin käytön tehokkuutta.
Pakoanalyysin optimointistrategioita ovat pinon kohdistaminen, synkronoinnin eliminointi, skalaarikorvaus ja menetelmän rivitys. Nämä optimointistrategiat voivat vähentää roskien keräämisen ylimääräisiä kustannuksia, parantaa ohjelman suoritustehokkuutta ja reagointikykyä sekä vähentää muistin käyttöä.
viitata:
https://zhuanlan.zhihu.com/p/693382698
JVM-Heap-Escape Analysis-08-CSDN-blogi
JIT-muistin poistoanalyysi_java sammuttaa skalaarikorvaus-CSDN-blogin
java -XX:+PrintFlagsFinal #输出打印所有参数jvm参数



Hän on omistautunut teknologian tutkimukselle yli kolmenkymmenen vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne., ja hän on tehnyt monia panoksia avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehityksen ongelmia tulevaa käyttöä varten

