Praktische Erfahrung in der Verwendung von Apache DolphinScheduler zum Erstellen und Bereitstellen einer Big-Data-Plattform und zum Übermitteln von Aufgaben an AWS
Li Qingwang - Softwareentwicklungsingenieur, Cisco
Einführung
Hallo zusammen, mein Name ist Li Qingwang, ein Softwareentwicklungsingenieur von Cisco. Unser Team nutzt Apache DolphinScheduler seit fast drei Jahren, um unsere eigene Big-Data-Planungsplattform aufzubauen. Von der ersten Version 2.0.3 bis zur Gegenwart sind wir gemeinsam mit der Community gewachsen. Die heute mit Ihnen geteilten technischen Ideen sind sekundäre Entwicklungen, die auf Version 3.1.1 basieren und einige neue Funktionen hinzufügen, die nicht in der Community-Version enthalten sind.
Heute werde ich mitteilen, wie wir Apache DolphinScheduler verwenden, um eine Big-Data-Plattform aufzubauen und unsere Aufgaben an AWS zu übermitteln. Einige Herausforderungen, die während des Prozesses aufgetreten sind, und unsere Lösungen.
Architekturentwurf und -anpassung
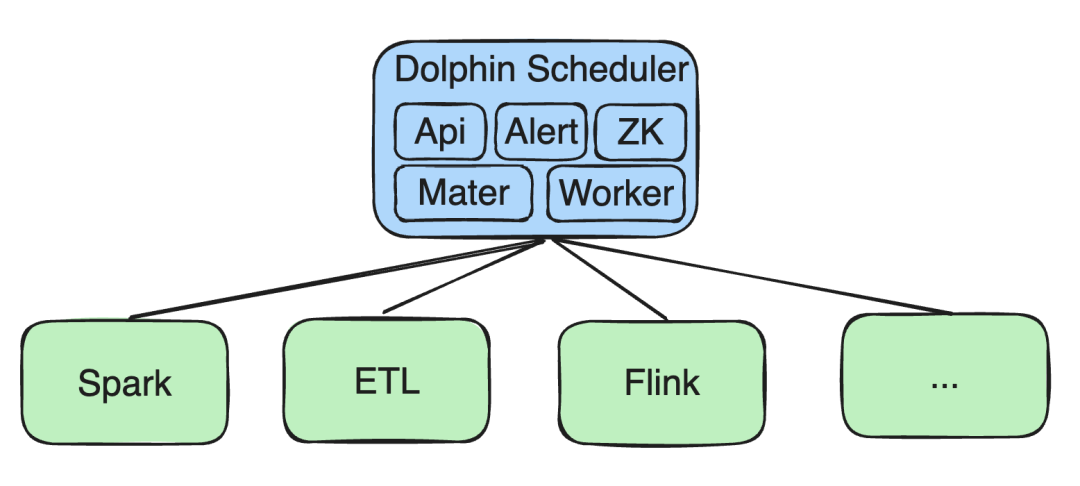
Zunächst werden alle unsere Dienste auf Kubernetes (K8s) bereitgestellt, einschließlich API, Alert und Komponenten wie Zookeeper (ZK), Master und Worker.
Big-Data-Verarbeitungsaufgaben
Wir haben Sekundärentwicklungen für Aufgaben wie Spark, ETL und Flink durchgeführt:
ETL-Aufgaben: Unser Team hat ein einfaches Drag-and-Drop-Tool entwickelt, mit dem Benutzer schnell ETL-Aufgaben generieren können.
Spark-Unterstützung : Die frühe Version unterstützte nur die Ausführung von Spark auf Yarn, und wir haben dafür gesorgt, dass die Ausführung auf K8s durch sekundäre Entwicklung unterstützt wird. Die neueste Version der Community unterstützt derzeit Spark auf K8s.
*Flink-Sekundärentwicklung: Ebenso haben wir Flink On K8s-Streaming-Aufgaben hinzugefügt sowie Unterstützung für SQL-Aufgaben und Python-Aufgaben On K8s.
Support-Job bei AWS
Da das Unternehmen wächst und Datenrichtlinien erforderlich sind, stehen wir vor der Herausforderung, Datenaufgaben in verschiedenen Regionen ausführen zu müssen. Dazu müssen wir eine Architektur aufbauen, die mehrere Cluster unterstützen kann. Nachfolgend finden Sie eine detaillierte Beschreibung unseres Lösungs- und Implementierungsprozesses.
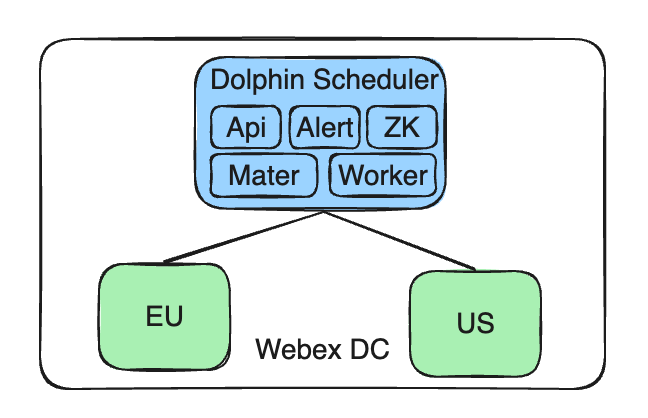
Unsere aktuelle Architektur besteht aus einem zentralisierten Steuerungsendpunkt, einem einzelnen Apache DolphinScheduler-Dienst, der mehrere Cluster verwaltet. Diese Cluster sind in verschiedenen Regionen verteilt, beispielsweise in der EU und den Vereinigten Staaten, um lokale Datenrichtlinien und Isolationsanforderungen einzuhalten.
Architektonische Anpassung
Um dieser Nachfrage gerecht zu werden, haben wir folgende Anpassungen vorgenommen:
Sorgen Sie dafür, dass der Apache DolphinScheduler-Dienst zentral verwaltet wird: Unser DolphinScheduler-Dienst wird weiterhin im selbst erstellten Cisco Webex DC bereitgestellt, wodurch die Zentralisierung und Konsistenz der Verwaltung gewährleistet bleibt.
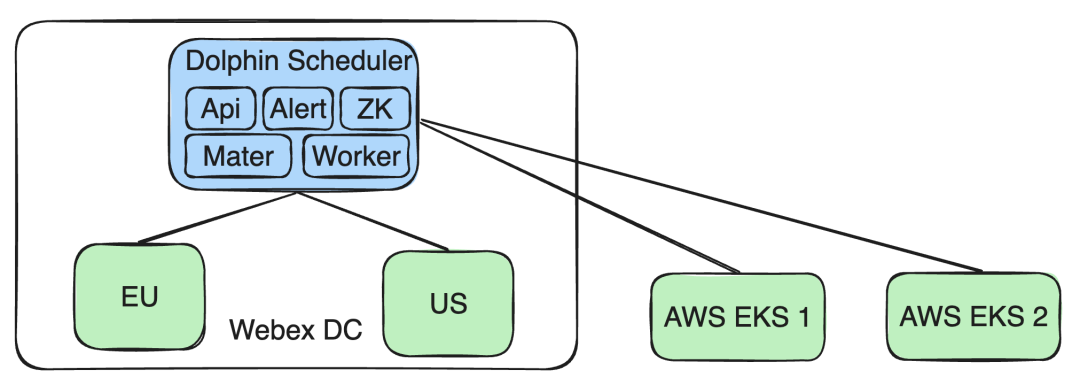
Unterstützen Sie den AWS EKS-Cluster : Gleichzeitig haben wir die Fähigkeiten unserer Architektur erweitert, um mehrere AWS EKS-Cluster zu unterstützen. Auf diese Weise können neue Geschäftsanforderungen für Aufgaben, die auf dem EKS-Cluster ausgeführt werden, erfüllt werden, ohne den Betrieb und die Datenisolation anderer Webex DC-Cluster zu beeinträchtigen.
Durch dieses Design können wir flexibel auf unterschiedliche Geschäftsanforderungen und technische Herausforderungen reagieren und gleichzeitig Datenisolation und Richtlinieneinhaltung gewährleisten.
Als Nächstes stellen wir vor, wie mit der technischen Implementierung und den Ressourcenabhängigkeiten von Apache DolphinScheduler umgegangen wird, wenn Aufgaben in Cisco Webex DC ausgeführt werden.
Ressourcenabhängigkeiten und Speicher
Da alle unsere Aufgaben auf Kubernetes (K8s) laufen, ist es für uns von entscheidender Bedeutung:
Docker-Image
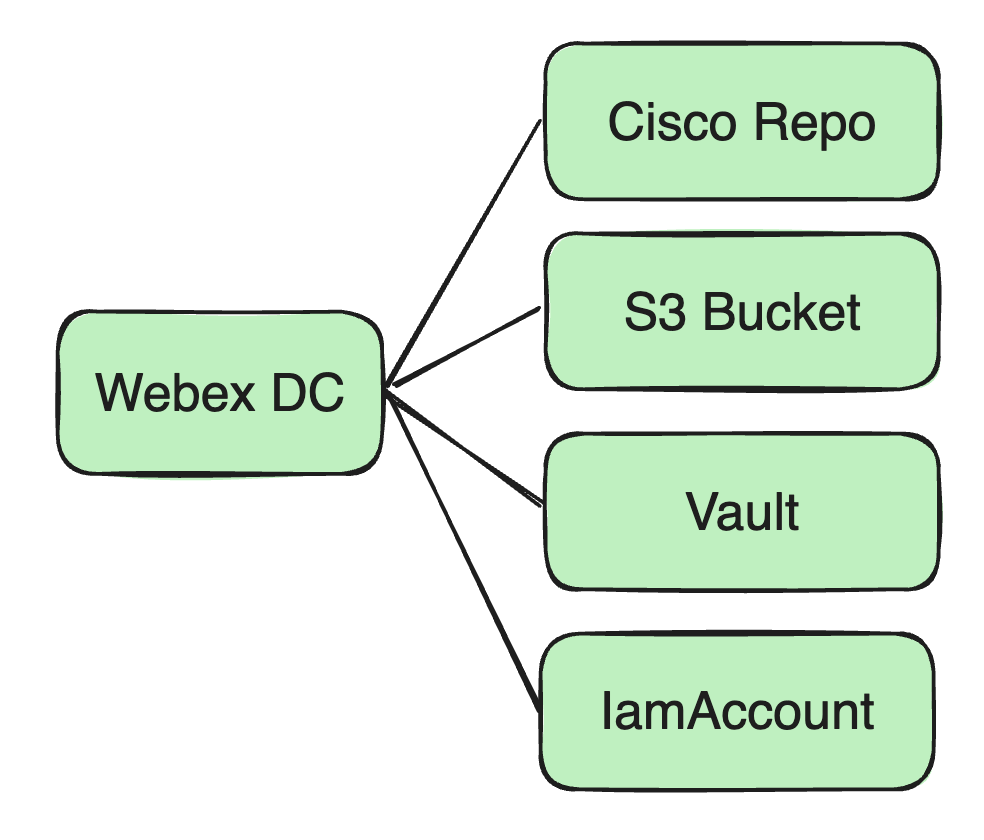
Lagerraum: Bisher wurden alle unsere Docker-Images in einem Docker-Repository bei Cisco gespeichert.
Bildverwaltung: Diese Images stellen die erforderliche Betriebsumgebung und Abhängigkeiten für die verschiedenen von uns ausgeführten Dienste und Aufgaben bereit.
Ressourcendateien und Abhängigkeiten
Jar-Pakete und Konfigurationsdateien usw.: Wir verwenden Amazon S3 Bucket als Ressourcenspeicherzentrum, um das Jar-Paket des Benutzers und mögliche abhängige Konfigurationsdateien zu speichern.
Verwaltung von Sicherheitsressourcen: Einschließlich Datenbankkennwörter, Kafka-Verschlüsselungsinformationen und benutzerabhängige Schlüssel usw. Diese vertraulichen Informationen werden im Vault-Dienst von Cisco gespeichert.
Sichere Zugriffs- und Rechteverwaltung
Um auf S3 Bucket zugreifen zu können, müssen wir AWS-Anmeldeinformationen konfigurieren und verwalten:
IAM-Kontokonfiguration
Berechtigungsverwaltung: Wir verwenden IAM-Konten, um den Zugriff auf AWS-Ressourcen zu verwalten, einschließlich Zugriffsschlüsseln und geheimen Schlüsseln.
K8s-Integration: Diese Anmeldeinformationen werden im Kubernetes-Geheimnis gespeichert und vom Api-Service referenziert, um sicher auf den S3-Bucket zuzugreifen.
Berechtigungskontrolle und Ressourcenisolation: Über IAM-Konten können wir eine differenzierte Berechtigungskontrolle implementieren, um Datensicherheit und Geschäftskonformität zu gewährleisten.
Ablaufprobleme und Gegenmaßnahmen für IAM-Kontozugriffsschlüssel
Bei der Verwendung von IAM-Konten zur Verwaltung von AWS-Ressourcen stehen wir vor dem Problem, dass der Zugriffsschlüssel abläuft. Hier erfahren Sie mehr darüber, wie wir diese Herausforderung angehen.
Problem mit dem Ablauf des Zugriffsschlüssels
Schlüsselperiode: Der AWS-Schlüssel des IAM-Kontos ist normalerweise so eingestellt, dass er alle 90 Tage automatisch abläuft, um die Sicherheit des Systems zu erhöhen.
Auswirkungen auf die Mission: Sobald die Schlüssel ablaufen, können alle Aufgaben, die auf diese Schlüssel angewiesen sind, um auf AWS-Ressourcen zuzugreifen, nicht mehr ausgeführt werden. Daher müssen wir die Schlüssel rechtzeitig aktualisieren, um die Geschäftskontinuität aufrechtzuerhalten.
Als Reaktion auf diese Situation richten wir regelmäßige Neustarts für die Aufgabe ein und richten eine entsprechende Überwachung ein. Wenn vor Ablauf der Ablaufzeit ein Problem mit dem AWS-Konto auftritt, müssen wir unsere entsprechenden Entwickler benachrichtigen, um eine Verarbeitung durchzuführen.
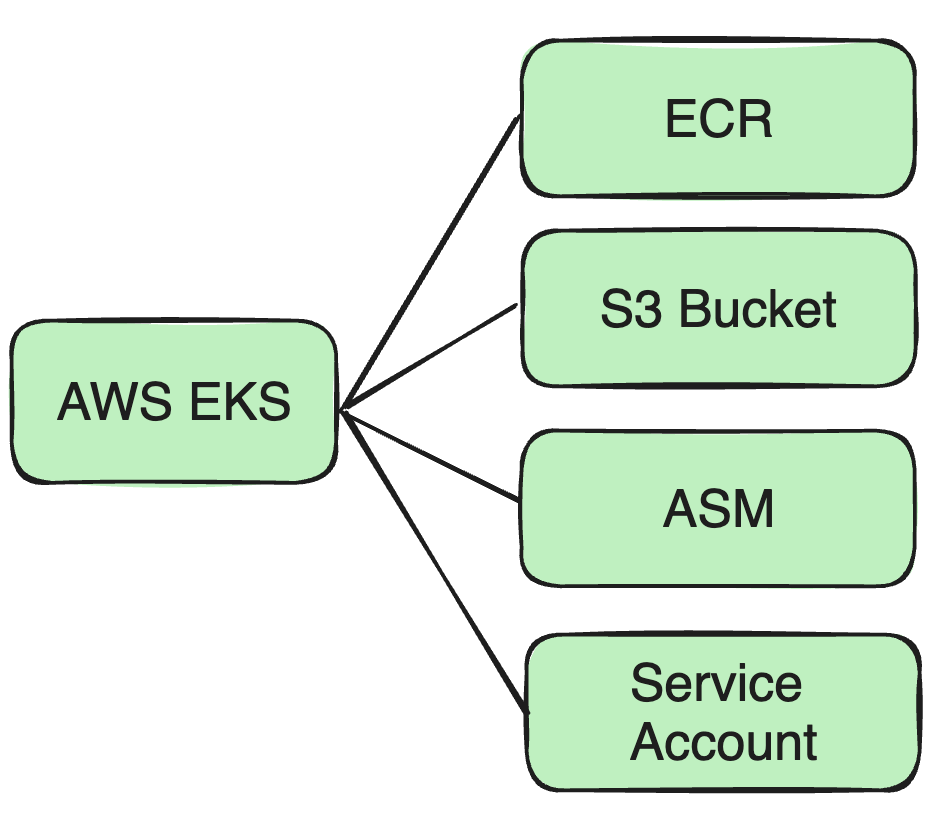
Unterstützen Sie AWS EKS
Da unser Unternehmen auf AWS EKS expandiert, müssen wir eine Reihe von Anpassungen an unserer bestehenden Architektur und Sicherheitsmaßnahmen vornehmen.
Beispielsweise haben wir das gerade erwähnte Docker-Image zuvor in Ciscos eigenem Docker-Repo abgelegt, sodass wir das Docker-Image jetzt auf ECR ablegen müssen.
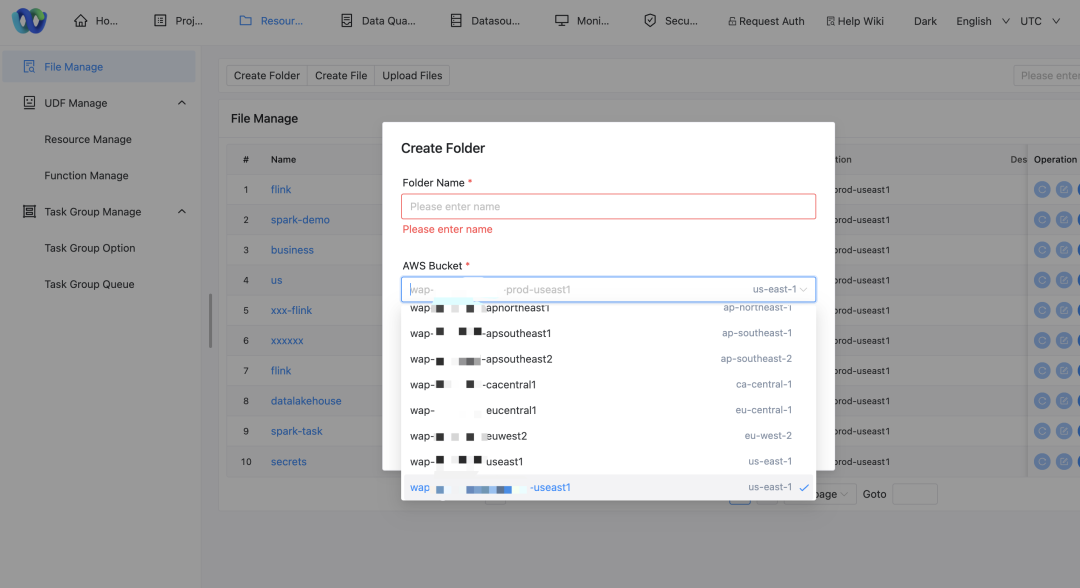
Unterstützung mehrerer S3-Buckets
Aufgrund der dezentralen Natur von AWS-Clustern und der Datenisolationsanforderungen verschiedener Unternehmen müssen wir mehrere S3-Buckets unterstützen, um den Datenspeicheranforderungen verschiedener Cluster gerecht zu werden:
Korrespondenz zwischen Cluster und Bucket: Jeder Cluster greift auf seinen entsprechenden S3-Bucket zu, um die Datenlokalität und -konformität sicherzustellen.
Strategie ändern: Wir müssen unsere Speicherzugriffsrichtlinie anpassen, um das Lesen und Schreiben von Daten aus mehreren S3-Buckets zu unterstützen. Verschiedene Geschäftsparteien müssen auf ihre entsprechenden S3-Buckets zugreifen.
Änderungen an Passwortverwaltungstools
Um die Sicherheit zu verbessern, sind wir vom selbst entwickelten Vault-Service von Cisco auf den Secrets Manager (ASM) von AWS umgestiegen:
Verwendung von ASM: ASM bietet eine stärker integrierte Lösung für die Verwaltung von Passwörtern und Schlüsseln für AWS-Ressourcen.
Wir haben die Methode der Verwendung von IAM-Rollen und Dienstkonten übernommen, um die Sicherheit von Pod zu erhöhen:
Erstellen Sie eine IAM-Rolle und -Richtlinie: Erstellen Sie zunächst eine IAM-Rolle und binden Sie die erforderlichen Richtlinien daran, um sicherzustellen, dass nur die erforderlichen Berechtigungen gewährt werden.
Binden Sie das K8s-Dienstkonto: Erstellen Sie dann ein Kubernetes-Dienstkonto und verknüpfen Sie es mit der IAM-Rolle.
Integration von Pod-Berechtigungen: Wenn ein Pod ausgeführt wird, kann der Pod durch die Zuordnung zum Dienstkonto die erforderlichen AWS-Anmeldeinformationen direkt über die IAM-Rolle erhalten und so auf die erforderlichen AWS-Ressourcen zugreifen.
Diese Anpassungen verbessern nicht nur die Skalierbarkeit und Flexibilität unseres Systems, sondern stärken auch die gesamte Sicherheitsarchitektur, um sicherzustellen, dass der Betrieb in der AWS-Umgebung sowohl effizient als auch sicher ist. Gleichzeitig wird das bisherige Problem des automatischen Ablaufs von Schlüsseln und der Notwendigkeit eines Neustarts vermieden.
Optimieren Sie Ressourcenmanagement und Speicherprozesse
Um den Bereitstellungsprozess zu vereinfachen, planen wir, das Docker-Image direkt an ECR zu übertragen, anstatt einen sekundären Transit zu durchlaufen:
direkt drücken: Ändern Sie den aktuellen Verpackungsprozess, sodass das Docker-Image nach der Erstellung direkt an ECR übertragen wird, wodurch Zeitverzögerungen und potenzielle Fehlerquellen reduziert werden.
Implementierung ändern
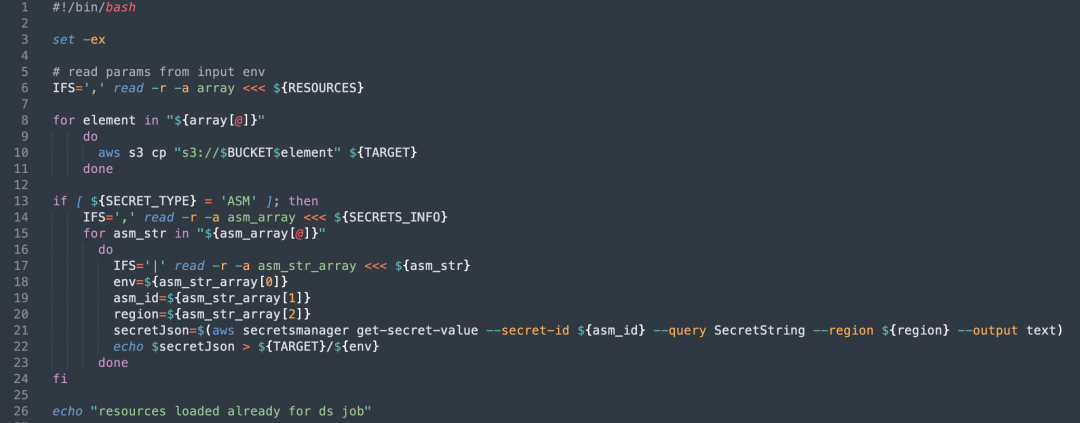
Anpassungen auf Codeebene: Wir haben den DolphinScheduler-Code geändert, um die Unterstützung mehrerer S3-Clients zu ermöglichen, und die Cache-Verwaltung für mehrere S3-Clients hinzugefügt.
Anpassungen der Ressourcenverwaltungs-Benutzeroberfläche: Ermöglicht Benutzern die Auswahl verschiedener AWS-Bucket-Namen für Vorgänge über die Schnittstelle.
Ressourcenzugriff: Der modifizierte Apache DolphinScheduler-Dienst kann jetzt auf mehrere S3-Buckets zugreifen und ermöglicht so eine flexible Datenverwaltung zwischen verschiedenen AWS-Clustern.
Verwaltung und Berechtigungsisolierung von AWS-Ressourcen
Integrieren Sie AWS Secrets Manager (ASM)
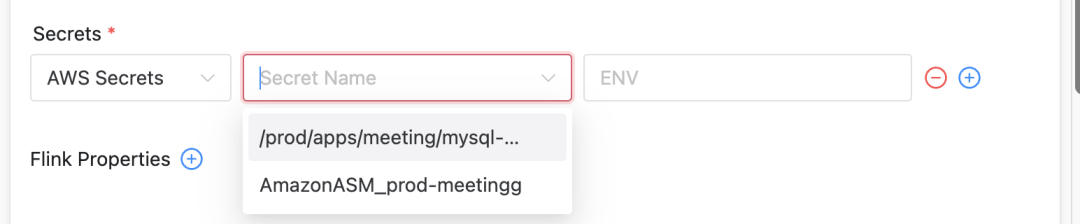
Wir haben Apache DolphinScheduler erweitert, um AWS Secrets Manager zu unterstützen, sodass Benutzer Geheimnisse über verschiedene Clustertypen hinweg auswählen können:
ASM-Funktionsintegration
Verbesserungen der Benutzeroberfläche: In der Benutzeroberfläche von DolphinScheduler wurden die Anzeige- und Auswahlfunktionen verschiedener Secret-Typen hinzugefügt.
Automatische Schlüsselverwaltung: Ordnet den Dateipfad, der das vom Benutzer ausgewählte Geheimnis speichert, während der Laufzeit der tatsächlichen Pod-Umgebungsvariablen zu und gewährleistet so die sichere Verwendung des Schlüssels.
Dynamischer Ressourcenkonfigurations- und Initialisierungsdienst (Init Container)
Um AWS-Ressourcen flexibler zu verwalten und zu initialisieren, haben wir einen Dienst namens Init Container implementiert:
Ressourcenabruf: Init Container ruft automatisch die vom Benutzer konfigurierten S3-Ressourcen ab und platziert sie im angegebenen Verzeichnis, bevor der Pod ausgeführt wird.
Schlüssel- und Konfigurationsverwaltung: Gemäß der Konfiguration prüft und ruft Init Container die Passwortinformationen in ASM ab, speichert sie dann in einer Datei und ordnet sie über Umgebungsvariablen zur Verwendung durch Pod zu.
Anwendung von Terraform bei der Ressourcenerstellung und -verwaltung
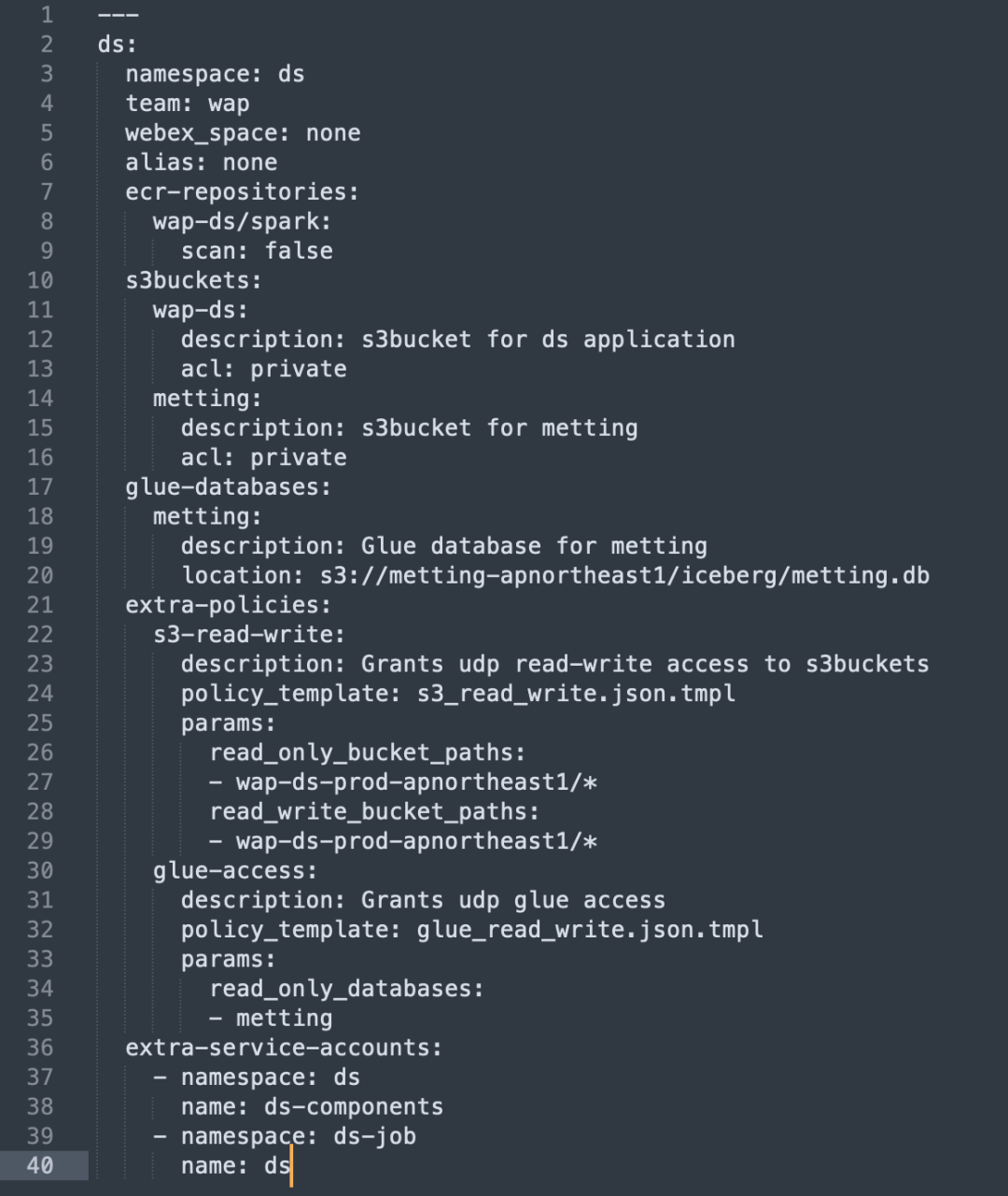
Wir haben den Konfigurations- und Verwaltungsprozess von AWS-Ressourcen über Terraform automatisiert und so die Ressourcenzuweisung und Berechtigungseinstellungen vereinfacht:
Automatische Ressourcenkonfiguration: Verwenden Sie Terraform, um die erforderlichen AWS-Ressourcen wie S3 Bucket und ECR Repo zu erstellen.
IAM-Richtlinien- und Rollenverwaltung: Erstellen Sie automatisch IAM-Richtlinien und -Rollen, um sicherzustellen, dass jede Geschäftseinheit bei Bedarf Zugriff auf die benötigten Ressourcen hat.
Berechtigungsisolierung und Sicherheit
Wir verwenden ausgefeilte Strategien zur Berechtigungsisolation, um sicherzustellen, dass verschiedene Geschäftseinheiten in unabhängigen Namensräumen arbeiten, und vermeiden so Ressourcenzugriffskonflikte und Sicherheitsrisiken:
Implementierungsdetails
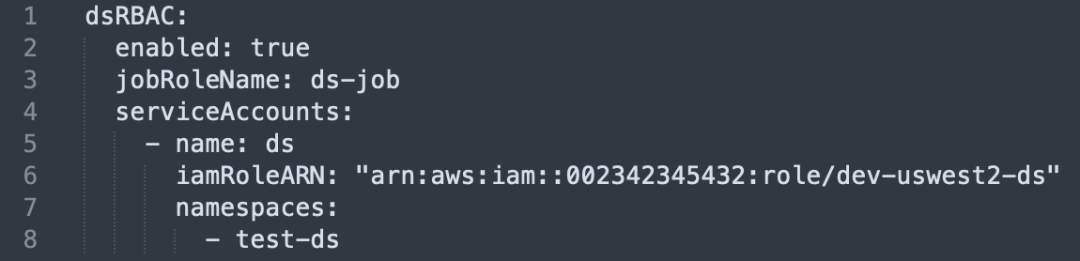
Erstellung und Bindung eines Dienstkontos: Erstellen Sie für jede Geschäftseinheit ein unabhängiges Dienstkonto und binden Sie es an die IAM-Rolle.
Namespace-Isolation: Jeder Dienstkontovorgang greift über die IAM-Rolle innerhalb des angegebenen Namespace auf die entsprechenden AWS-Ressourcen zu.
Verbesserungen bei der Clusterunterstützung und Berechtigungskontrolle
Erweiterungen des Clustertyps
Wir haben ein neues Feld hinzugefügt cluster type, um verschiedene Arten von K8S-Clustern zu unterstützen, die nicht nur Standard-Webex DC-Cluster und AWS EKS-Cluster umfassen, sondern auch spezifische Cluster mit höheren Sicherheitsanforderungen unterstützen:
Clustertypverwaltung
Feld „Clustertyp“.:von Eingeführtcluster typeFelder können wir den Support für verschiedene K8S-Cluster einfach verwalten und erweitern.
Anpassung auf Codeebene: Basierend auf den besonderen Anforderungen bestimmter Cluster können wir Änderungen auf Codeebene vornehmen, um sicherzustellen, dass Sicherheits- und Konfigurationsanforderungen erfüllt werden, wenn Jobs auf diesen Clustern ausgeführt werden.
Wir haben das Auth-System speziell für eine differenzierte Berechtigungskontrolle entwickelt, einschließlich der Berechtigungsverwaltung zwischen Projekten, Ressourcen und Namespaces:
Rechteverwaltungsfunktion
Projekt- und Ressourcenberechtigungen: Benutzer können Berechtigungen über die Projektdimension steuern. Sobald sie über Projektberechtigungen verfügen, haben sie Zugriff auf alle Ressourcen im Rahmen des Projekts.
Namespace-Berechtigungskontrolle: Stellen Sie sicher, dass ein bestimmtes Team die Jobs seines Projekts nur im angegebenen Namespace ausführen kann, und stellen Sie so sicher, dass die Ressourcenisolation ausgeführt wird.
Beispielsweise kann Team A nur bestimmte Projektjobs in seinem A-Namespace ausführen, Benutzer B kann beispielsweise keine Jobs im Namespace von Benutzer A ausführen.
AWS-Ressourcenverwaltungs- und Berechtigungsanwendung
Wir verwenden das Auth-System und andere Tools, um Berechtigungen und Zugriffskontrolle von AWS-Ressourcen zu verwalten und so die Ressourcenzuweisung flexibler und sicherer zu gestalten:
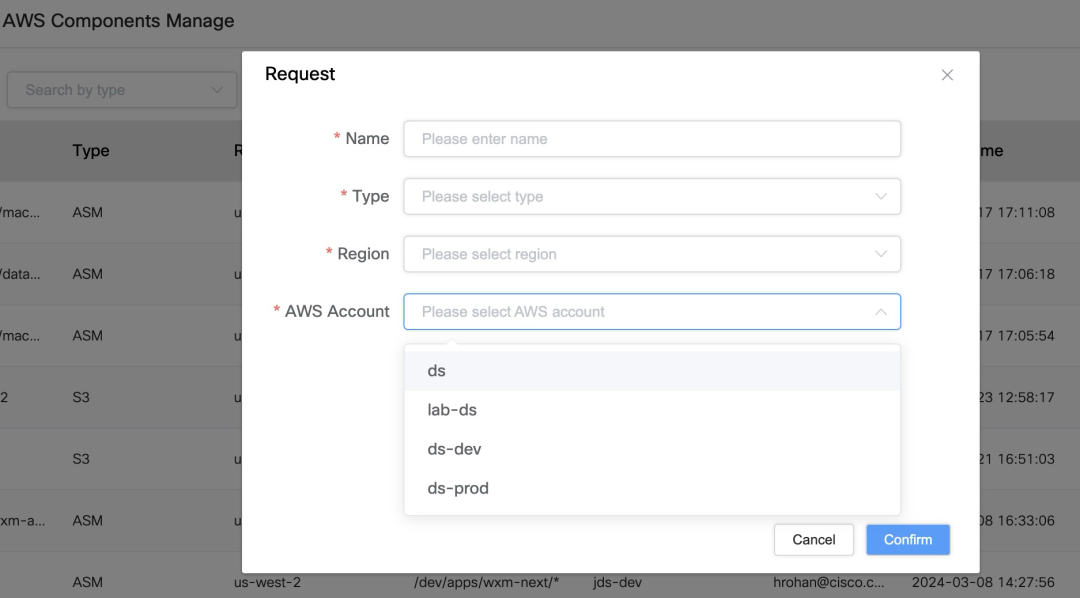
Unterstützung mehrerer AWS-Konten: Im Auth-System können Sie mehrere AWS-Konten verwalten und verschiedene AWS-Ressourcen wie S3 Bucket, ECR, ASM usw. binden.
Ressourcenzuordnung und Berechtigungsanwendung: Benutzer können vorhandene AWS-Ressourcen zuordnen und Berechtigungen im System beantragen, sodass sie beim Ausführen eines Jobs einfach die Ressourcen auswählen können, auf die sie zugreifen müssen.
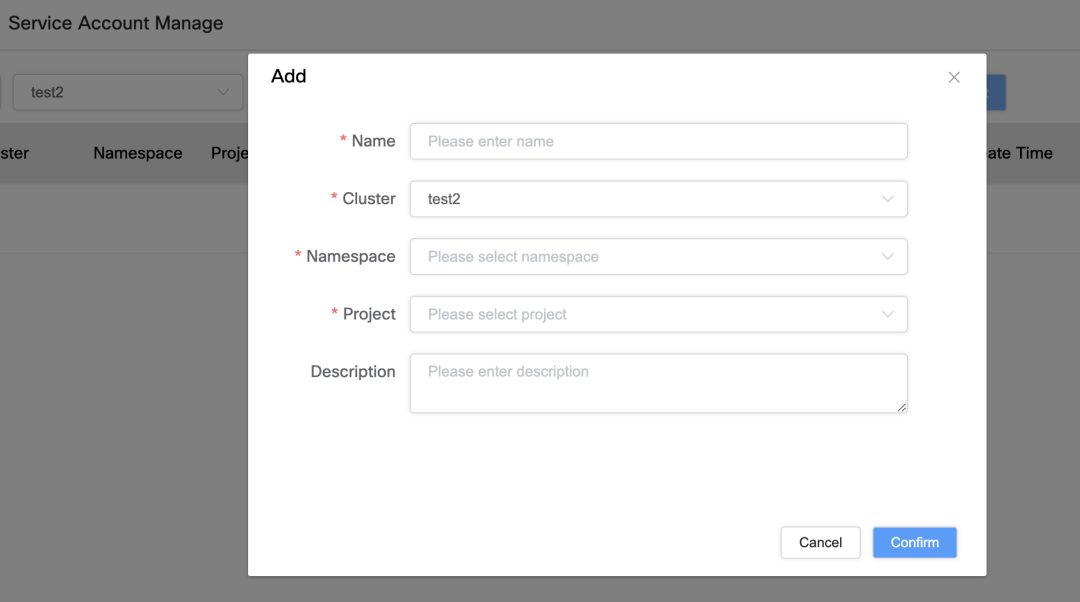
Dienstkontoverwaltung und Berechtigungsbindung
Um Dienstkonten und deren Berechtigungen besser verwalten zu können, haben wir folgende Funktionen implementiert:
Bindung und Verwaltung von Dienstkonten
Der einzige Unterschied zwischen Dienstkonto: Binden Sie das Dienstkonto über einen bestimmten Cluster, Namespace und Projektnamen, um seine Einzigartigkeit sicherzustellen.
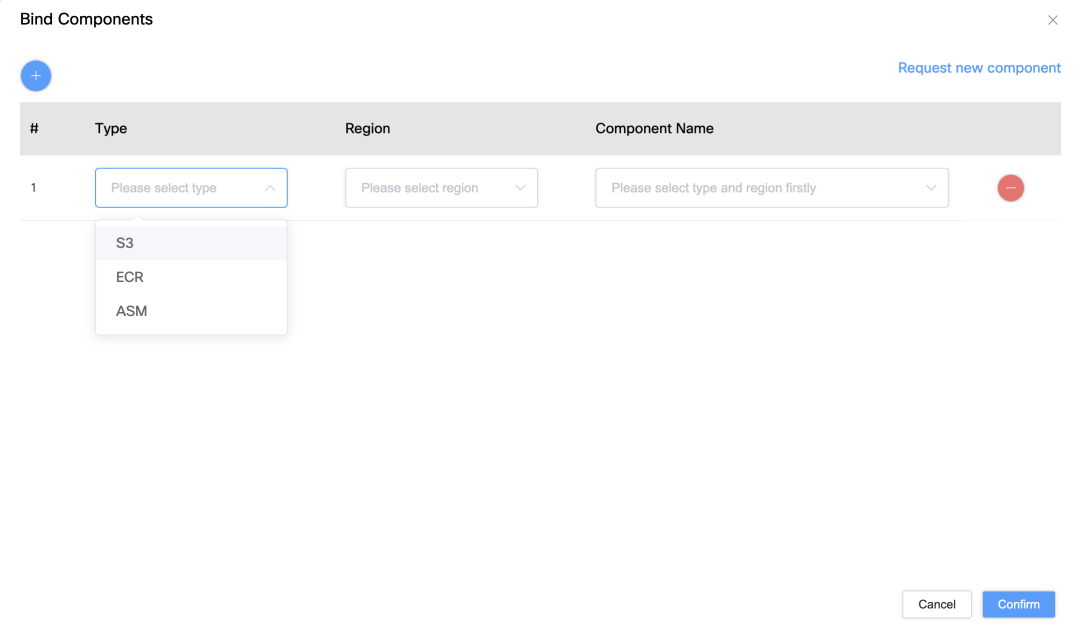
Berechtigungsbindungsschnittstelle: Benutzer können das Servicekonto über die Schnittstelle an bestimmte AWS-Ressourcen wie S3, ASM oder ECR binden, um eine präzise Steuerung der Berechtigungen zu erreichen.
Vereinfachen Sie Abläufe und Ressourcensynchronisierung
Ich habe gerade viel gesagt, aber die eigentliche Bedienung ist für Benutzer relativ einfach. Der gesamte Bewerbungsprozess ist eigentlich eine einmalige Aufgabe. Um die Benutzererfahrung von Apache DolphinScheduler in der AWS-Umgebung weiter zu verbessern Maßnahmen zur Vereinfachung von Betriebsabläufen und zur Verbesserung der Möglichkeiten zur Ressourcensynchronisierung.
Lassen Sie es mich für Sie zusammenfassen:
Vereinfachte Benutzeroberfläche
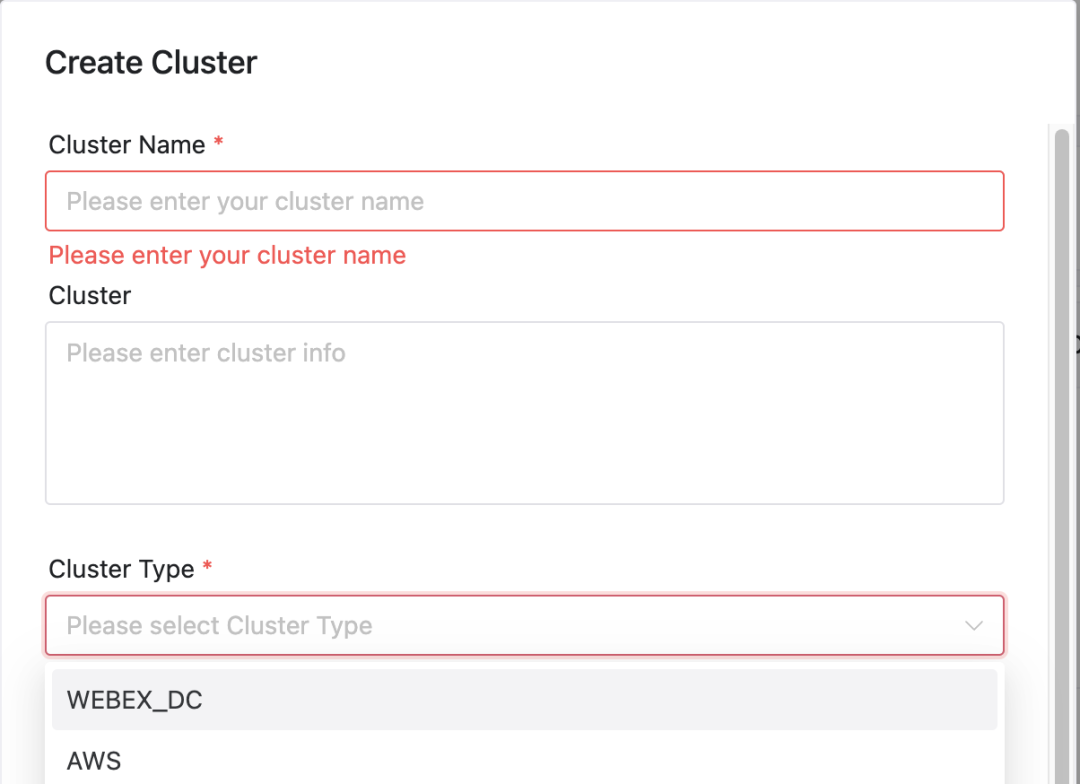
In DolphinScheduler können Benutzer ganz einfach den spezifischen Cluster und Namespace konfigurieren, in dem ihre Jobs ausgeführt werden:
Cluster- und Namespace-Auswahl
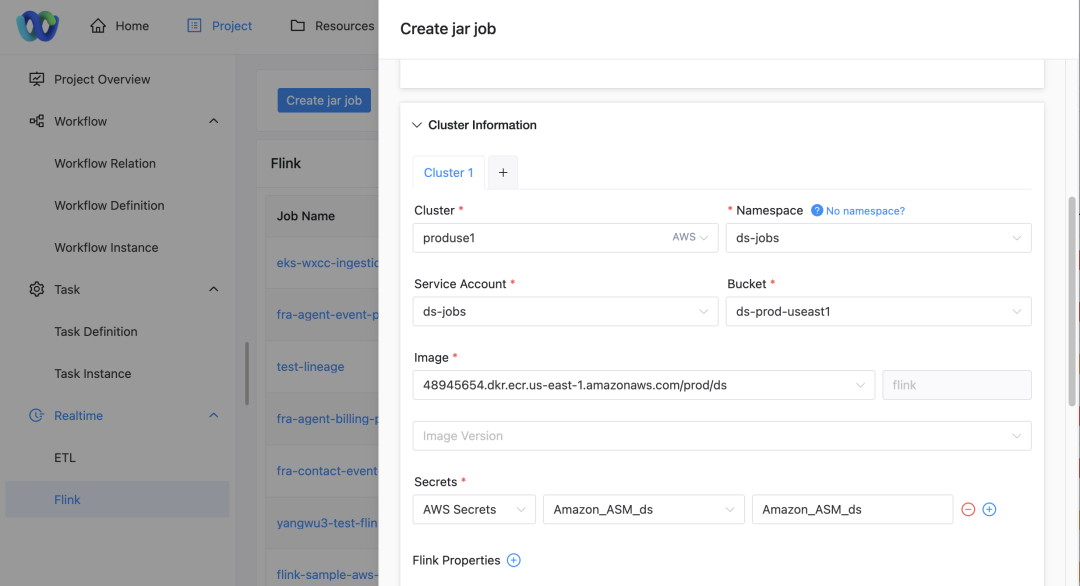
Clusterauswahl: Beim Senden eines Jobs können Benutzer den Cluster auswählen, auf dem der Job ausgeführt werden soll.
Namespace-Konfiguration: Abhängig vom ausgewählten Cluster muss der Benutzer auch den Namensraum angeben, in dem der Job ausgeführt wird.
Dienstkonto und Ressourcenauswahl
Anzeige des Dienstkontos: Auf der Seite wird automatisch das entsprechende Dienstkonto basierend auf dem ausgewählten Projekt, Cluster und Namespace angezeigt.
Konfiguration des Ressourcenzugriffs: Benutzer können den S3-Bucket, die ECR-Adresse und den ASM-Schlüssel, die dem Dienstkonto zugeordnet sind, über die Dropdown-Liste auswählen.
Zukunftsausblick
Bezüglich des aktuellen Designs gibt es noch einige Bereiche, die optimiert und verbessert werden können, um die Benutzereingabe zu verbessern und Betrieb und Wartung zu erleichtern:
Bild-Push-Optimierung: Erwägen Sie, den Transportverpackungsprozess von Cisco zu überspringen und das Paket direkt an ECR zu übertragen, insbesondere bei EKS-spezifischen Bildänderungen.
Ein-Klick-Synchronisierungsfunktion: Wir planen, eine Ein-Klick-Synchronisierungsfunktion zu entwickeln, die es Benutzern ermöglicht, ein Ressourcenpaket in einen S3-Bucket hochzuladen und das Kontrollkästchen zu aktivieren, um es automatisch mit anderen S3-Buckets zu synchronisieren, um die Arbeit wiederholter Uploads zu reduzieren.
Automatische Zuordnung zum Auth-System: Nachdem Aws-Ressourcen über Terraform erstellt wurden, ordnet das System diese Ressourcen automatisch dem Berechtigungsverwaltungssystem zu, um zu verhindern, dass Benutzer Ressourcen manuell eingeben.
Optimierung der Berechtigungskontrolle: Durch die automatisierte Ressourcen- und Berechtigungsverwaltung werden Benutzervorgänge einfacher und die Komplexität der Einrichtung und Verwaltung verringert.
Wir gehen davon aus, dass wir mit diesen Verbesserungen Benutzern dabei helfen können, ihre Jobs mit Apache DolphinScheduler effizienter bereitzustellen und zu verwalten, sei es auf Webex DC oder EKS, und gleichzeitig die Effizienz und Sicherheit der Ressourcenverwaltung zu verbessern.