Li Qingwang - Ingénieur en développement logiciel, Cisco
introduction
Bonjour à tous, je m'appelle Li Qingwang, ingénieur en développement logiciel chez Cisco. Notre équipe utilise Apache DolphinScheduler pour créer notre propre plateforme de planification Big Data depuis près de trois ans. Depuis la version initiale 2.0.3 jusqu'à aujourd'hui, nous avons grandi avec la communauté. Les idées techniques partagées avec vous aujourd'hui sont des développements secondaires basés sur la version 3.1.1, ajoutant quelques nouvelles fonctionnalités non incluses dans la version communautaire.
Aujourd'hui, je vais partager comment nous utilisons Apache DolphinScheduler pour créer une plate-forme Big Data et soumettre et déployer nos tâches sur AWS. Certains défis rencontrés au cours du processus et de nos solutions.
Conception et ajustement de l'architecture
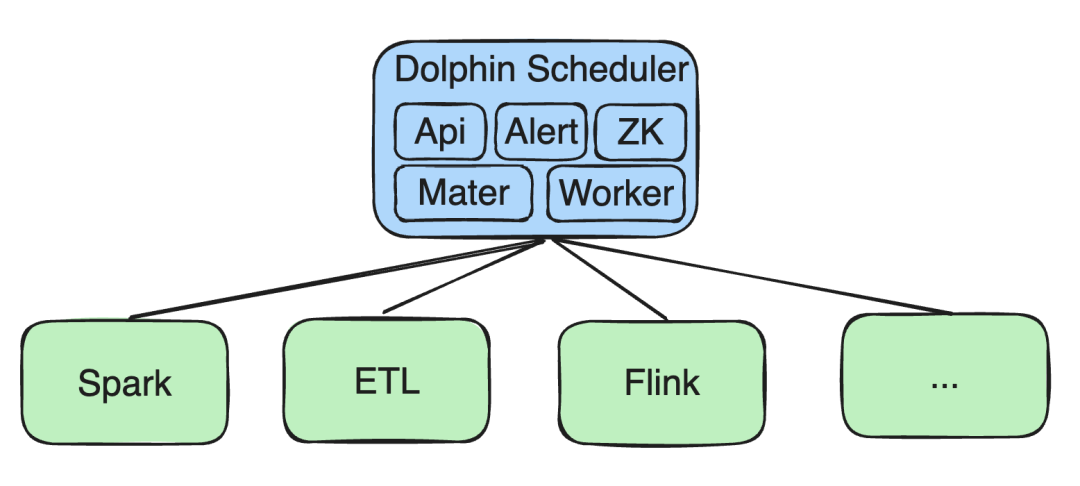
Initialement, tous nos services sont déployés sur Kubernetes (K8s), y compris l'API, Alert et des composants tels que Zookeeper (ZK), Master et Worker.
Tâches de traitement du Big Data
Nous avons réalisé du développement secondaire sur des tâches telles que Spark, ETL et Flink :
Tâches ETL: Notre équipe a développé un outil simple de glisser-déposer grâce auquel les utilisateurs peuvent générer rapidement des tâches ETL.
Prise en charge des étincelles : La première version ne prenait en charge que Spark fonctionnant sur Yarn, et nous l'avons rendu compatible avec K8 via un développement secondaire. La dernière version de la communauté prend actuellement en charge Spark sur les K8.
*Développement secondaire Flink: De même, nous avons ajouté les tâches de streaming Flink sur K8, ainsi que la prise en charge des tâches SQL et des tâches Python sur K8.
Emploi d'assistance sur AWS
À mesure que l'entreprise se développe et que des politiques de données sont nécessaires, nous sommes confrontés au défi de devoir exécuter des tâches de données dans différentes régions. Cela nous oblige à construire une architecture capable de prendre en charge plusieurs clusters. Vous trouverez ci-dessous une description détaillée de notre solution et de notre processus de mise en œuvre.
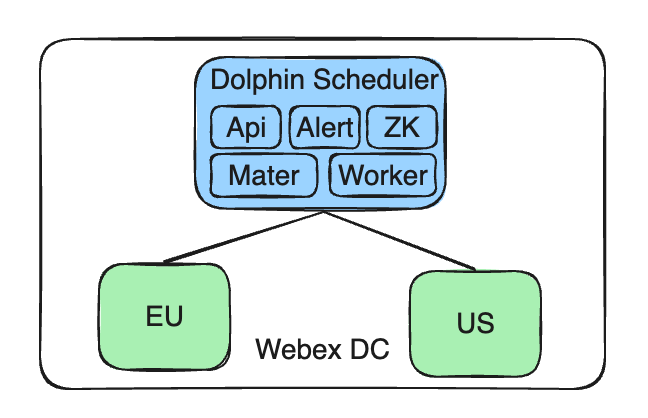
Notre architecture actuelle se compose d'un point de terminaison de contrôle centralisé, d'un seul service Apache DolphinScheduler, qui gère plusieurs clusters. Ces clusters sont répartis dans différentes zones géographiques, telles que l'UE et les États-Unis, afin de se conformer aux politiques locales en matière de données et aux exigences d'isolement.
Ajustement architectural
Pour répondre à cette demande, nous avons procédé aux ajustements suivants :
Gardez le service Apache DolphinScheduler géré de manière centralisée: Notre service DolphinScheduler est toujours déployé dans le Cisco Webex DC auto-construit, maintenant la centralisation et la cohérence de la gestion.
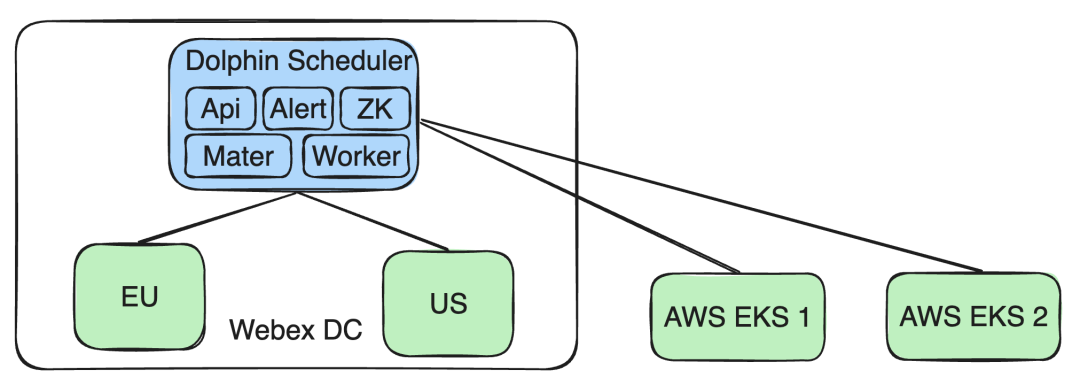
Prise en charge du cluster AWS EKS : Dans le même temps, nous avons étendu les capacités de notre architecture pour prendre en charge plusieurs clusters AWS EKS. De cette manière, les nouvelles exigences commerciales pour les tâches exécutées sur le cluster EKS peuvent être satisfaites sans affecter le fonctionnement et l’isolation des données des autres clusters Webex DC.
Grâce à cette conception, nous pouvons répondre de manière flexible aux différents besoins commerciaux et défis techniques tout en garantissant l’isolation des données et la conformité aux politiques.
Nous présenterons ensuite comment gérer la mise en œuvre technique et les dépendances en matière de ressources d'Apache DolphinScheduler lors de l'exécution de tâches dans Cisco Webex DC.
Dépendances des ressources et stockage
Puisque toutes nos tâches s'exécutent sur Kubernetes (K8s), il est crucial pour nous de :
Image Docker
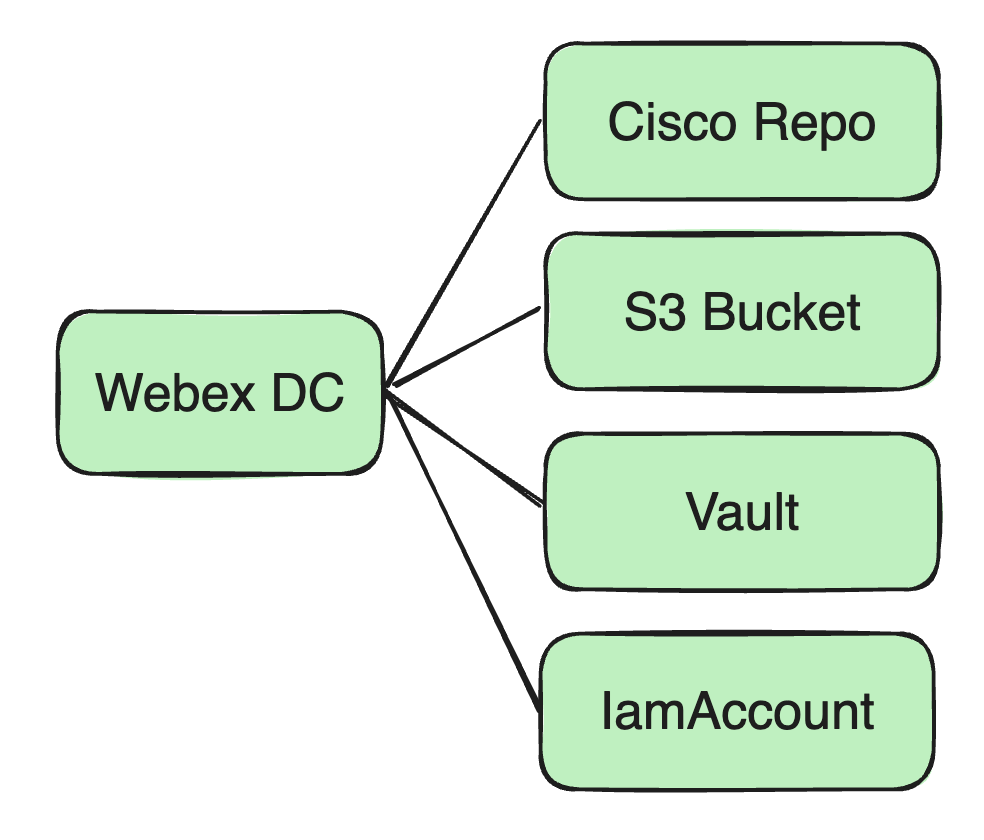
emplacement de stockage: Auparavant, toutes nos images Docker étaient stockées dans un référentiel Docker chez Cisco.
Gestion des images: Ces images fournissent l'environnement d'exploitation et les dépendances nécessaires pour les différents services et tâches que nous exécutons.
Fichiers de ressources et dépendances
Packages Jar et fichiers de configuration, etc.: Nous utilisons Amazon S3 Bucket comme centre de stockage de ressources pour stocker le package Jar de l'utilisateur et les éventuels fichiers de configuration dépendants.
Gestion des ressources de sécurité: Y compris les mots de passe de base de données, les informations de cryptage Kafka et les clés dépendantes de l'utilisateur, etc. Ces informations sensibles sont stockées dans le service Vault de Cisco.
Accès sécurisé et gestion des droits
Pour avoir besoin d'accéder à S3 Bucket, nous devons configurer et gérer les informations d'identification AWS :
Configuration du compte IAM
Gestion des identifiants: Nous utilisons des comptes IAM pour gérer l'accès aux ressources AWS, y compris les clés d'accès et les clés secrètes.
Intégration K8: Ces informations d'identification sont stockées dans le secret Kubernetes et référencées par l'Api-Service pour accéder en toute sécurité au compartiment S3.
Contrôle des autorisations et isolation des ressources: Grâce aux comptes IAM, nous pouvons mettre en œuvre un contrôle précis des autorisations pour garantir la sécurité des données et la conformité de l'entreprise.
Problèmes d'expiration et contre-mesures pour les clés d'accès au compte IAM
Dans le processus d'utilisation des comptes IAM pour gérer les ressources AWS, nous sommes confrontés au problème de l'expiration des clés d'accès. Voici plus d’informations sur la manière dont nous relevons ce défi.
Problème d'expiration de la clé d'accès
période clé: La clé AWS du compte IAM est généralement configurée pour expirer automatiquement tous les 90 jours, ce qui vise à renforcer la sécurité du système.
impact sur la mission: Une fois les clés expirées, toutes les tâches qui dépendent de ces clés pour accéder aux ressources AWS ne pourront plus être exécutées, ce qui nous oblige à mettre à jour les clés en temps opportun pour maintenir la continuité des activités.
En réponse à cette situation, nous mettons en place des redémarrages réguliers de la tâche et mettons en place une surveillance correspondante. S'il y a un problème avec le compte AWS avant l'heure d'expiration, nous devons alors informer nos développeurs correspondants pour effectuer un traitement.
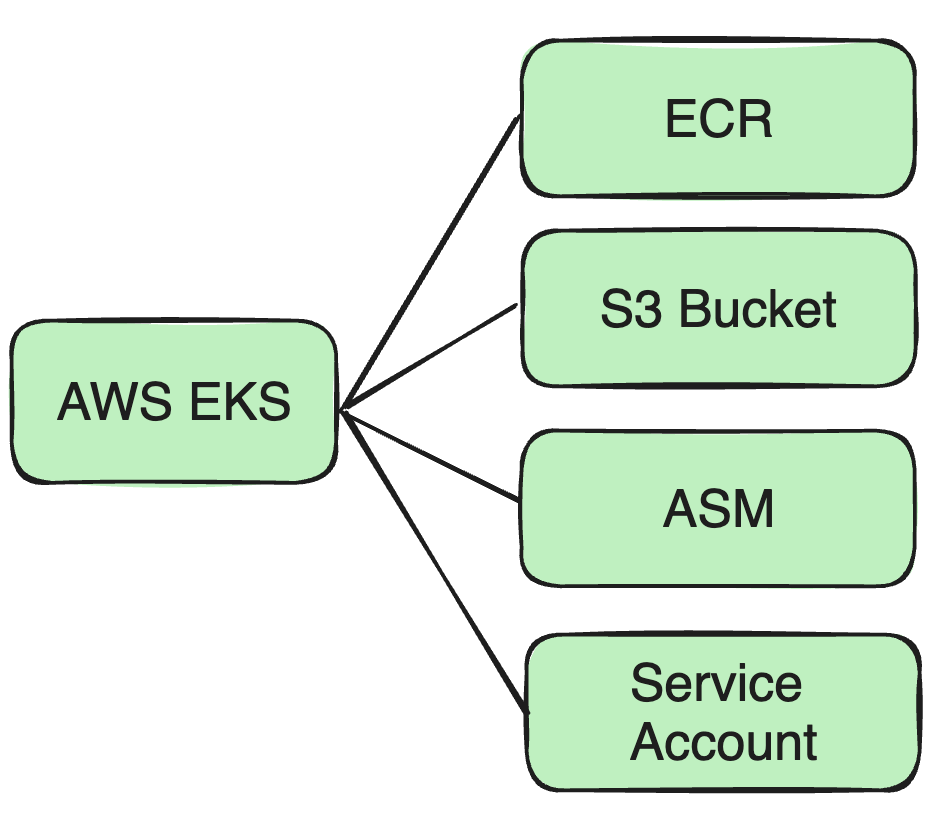
Prise en charge d'AWS EKS
À mesure que notre activité se développe vers AWS EKS, nous devons apporter une série d'ajustements à notre architecture et à nos mesures de sécurité existantes.
Par exemple, comme l'image Docker mentionnée tout à l'heure, nous l'avons précédemment placée dans le dépôt Docker de Cisco, nous devons donc maintenant mettre l'image Docker sur ECR.
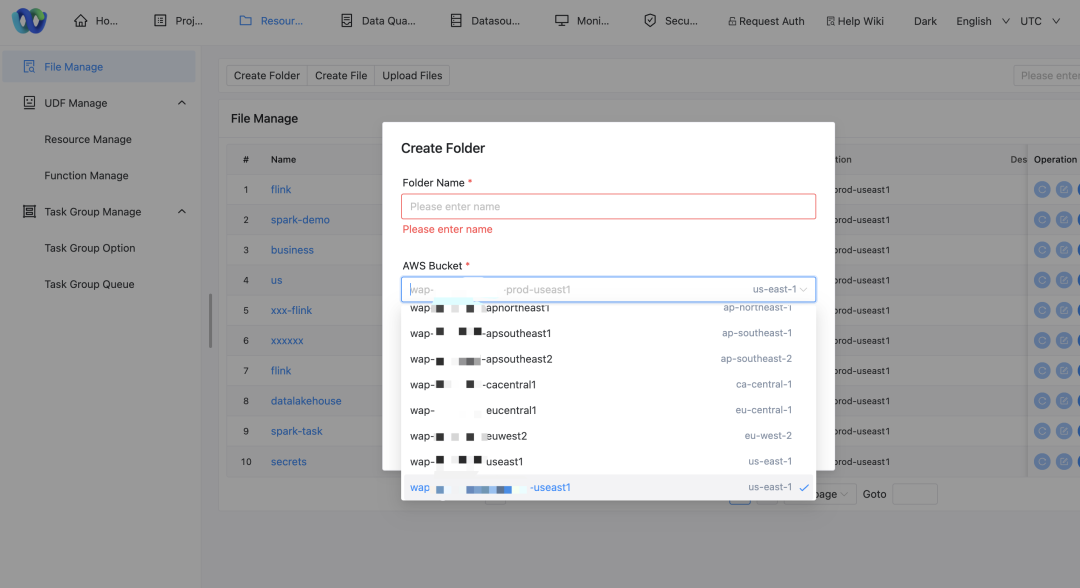
Prise en charge de plusieurs compartiments S3
En raison de la nature décentralisée des clusters AWS et des exigences d'isolation des données des différentes entreprises, nous devons prendre en charge plusieurs compartiments S3 pour répondre aux besoins de stockage de données des différents clusters :
Correspondance entre le cluster et le bucket: Chaque cluster accédera à son bucket S3 correspondant pour garantir la localisation et la conformité des données.
Modifier la stratégie: Nous devons ajuster notre politique d'accès au stockage pour prendre en charge la lecture et l'écriture de données à partir de plusieurs compartiments S3. Différentes parties commerciales doivent accéder à leurs compartiments S3 correspondants.
Modifications apportées aux outils de gestion des mots de passe
Afin d'améliorer la sécurité, nous avons migré du service Vault auto-construit de Cisco vers Secrets Manager (ASM) d'AWS :
Utilisation de l'ASM: ASM fournit une solution plus intégrée pour gérer les mots de passe et les clés des ressources AWS.
Nous avons adopté la méthode d'utilisation du rôle IAM et du compte de service pour améliorer la sécurité du Pod :
Créer un rôle et une stratégie IAM: Créez d'abord un rôle IAM et liez-y les stratégies nécessaires pour garantir que seules les autorisations nécessaires sont accordées.
Lier le compte de service K8s: Créez ensuite un compte de service Kubernetes et associez-le au rôle IAM.
Intégration des autorisations de pod: Lors de l'exécution d'un Pod, en l'associant au compte de service, le Pod peut obtenir les informations d'identification AWS requises directement via le rôle IAM, accédant ainsi aux ressources AWS nécessaires.
Ces ajustements améliorent non seulement l'évolutivité et la flexibilité de notre système, mais renforcent également l'architecture de sécurité globale pour garantir que le fonctionnement dans l'environnement AWS est à la fois efficace et sécurisé. Dans le même temps, cela évite également le problème précédent de l’expiration automatique des clés et de la nécessité de redémarrer.
Optimiser la gestion des ressources et les processus de stockage
Pour simplifier le processus de déploiement, nous prévoyons de pousser l'image Docker directement vers ECR au lieu de passer par un transit secondaire :
pousser directement : modifiez le processus d'empaquetage actuel afin que l'image Docker soit transmise directement à ECR après sa construction, réduisant ainsi les délais et les points d'erreur potentiels.
Mise en œuvre du changement
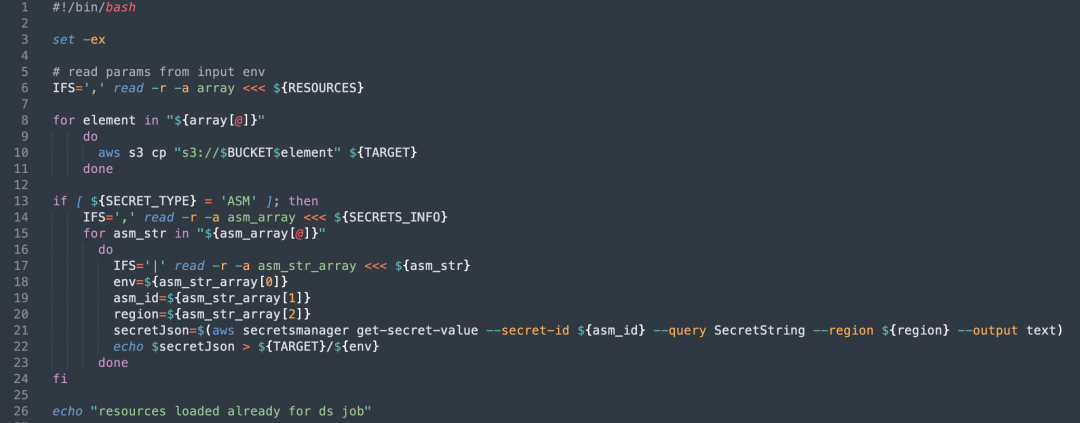
Ajustements au niveau du code: Nous avons modifié le code DolphinScheduler pour lui permettre de prendre en charge plusieurs clients S3 et ajouté la gestion du cache pour plusieurs clients S3.
Ajustements de l’interface utilisateur de gestion des ressources: permet aux utilisateurs de sélectionner différents noms de compartiment AWS pour les opérations via l'interface.
accès aux ressources: Le service Apache DolphinScheduler modifié peut désormais accéder à plusieurs compartiments S3, permettant une gestion flexible des données entre différents clusters AWS.
Gestion et isolation des autorisations des ressources AWS
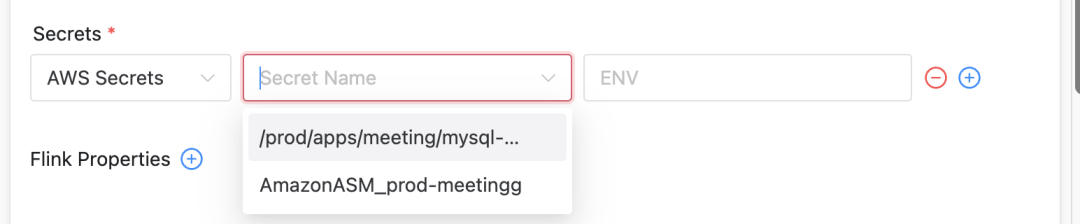
Intégrer AWS Secrets Manager (ASM)
Nous avons étendu Apache DolphinScheduler pour prendre en charge AWS Secrets Manager, permettant aux utilisateurs de sélectionner des secrets dans différents types de cluster :
Intégration fonctionnelle ASM
Améliorations de l'interface utilisateur: Dans l'interface utilisateur de DolphinScheduler, les fonctions d'affichage et de sélection de différents types de secrets sont ajoutées.
Gestion automatique des clés : mappe le chemin du fichier qui enregistre le secret sélectionné par l'utilisateur à la variable d'environnement réelle du Pod pendant l'exécution, garantissant ainsi l'utilisation sûre de la clé.
Service de configuration et d'initialisation des ressources dynamiques (Init Container)
Pour gérer et initialiser les ressources AWS de manière plus flexible, nous avons implémenté un service appelé Init Container :
Extraction de ressources: Init Container extraira automatiquement les ressources S3 configurées par l'utilisateur et les placera dans le répertoire spécifié avant l'exécution du Pod.
Gestion des clés et de la configuration: Selon la configuration, Init Container vérifiera et extraira les informations de mot de passe dans ASM, puis les stockera dans un fichier et les mappera via des variables d'environnement pour une utilisation par Pod.
Application de Terraform dans la création et la gestion des ressources
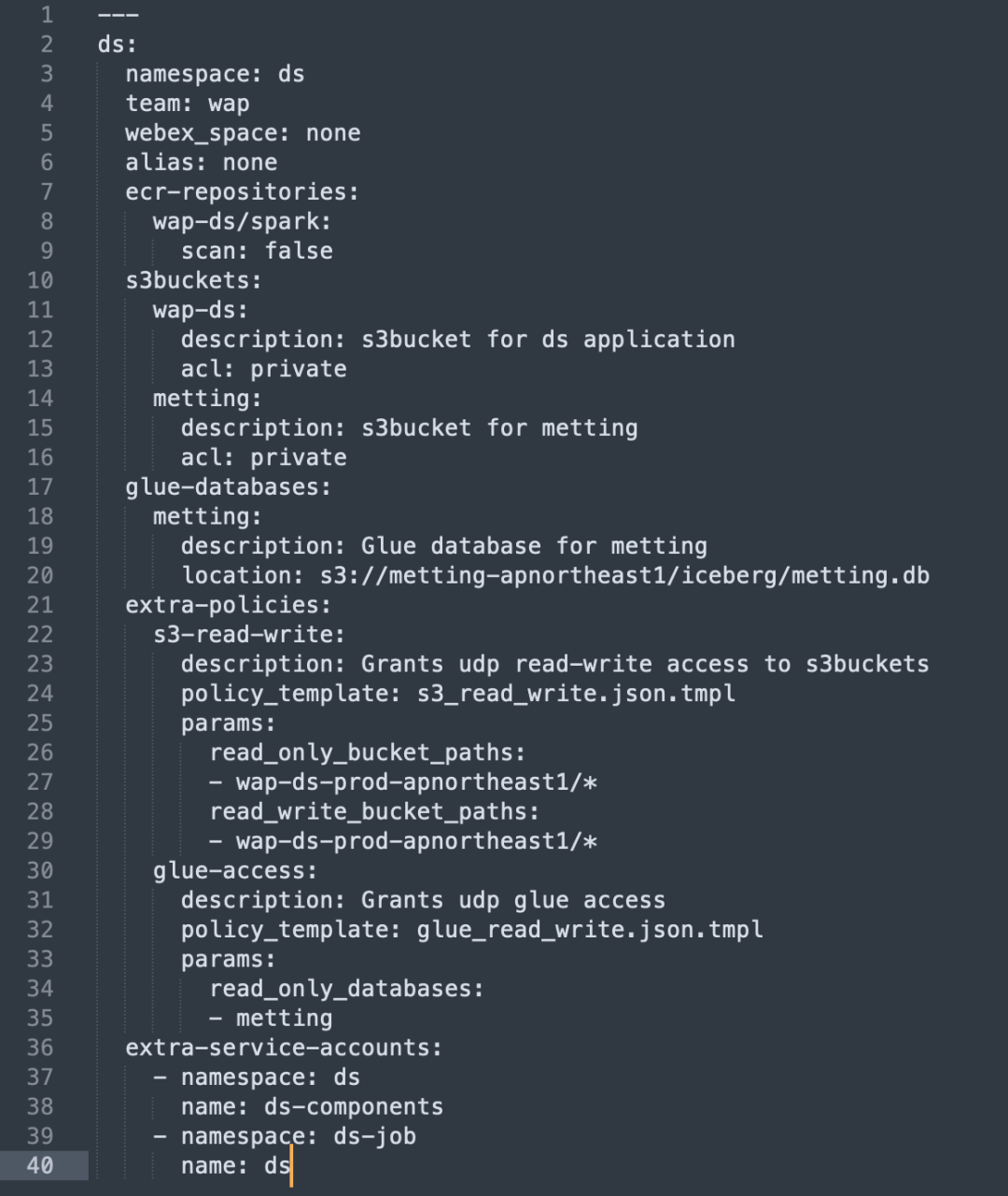
Nous avons automatisé le processus de configuration et de gestion des ressources AWS via Terraform, simplifiant ainsi l'allocation des ressources et les paramètres d'autorisation :
Configuration automatique des ressources: utilisez Terraform pour créer les ressources AWS requises telles que S3 Bucket et ECR Repo.
Politique IAM et gestion des rôles: créez automatiquement des politiques et des rôles IAM pour garantir que chaque unité commerciale dispose d'un accès à la demande aux ressources dont elle a besoin.
Isolation et sécurité des autorisations
Nous utilisons des stratégies sophistiquées d'isolation des autorisations pour garantir que les différentes unités commerciales opèrent dans des espaces de noms indépendants, évitant ainsi les conflits d'accès aux ressources et les risques de sécurité :
Détails d'implémentation
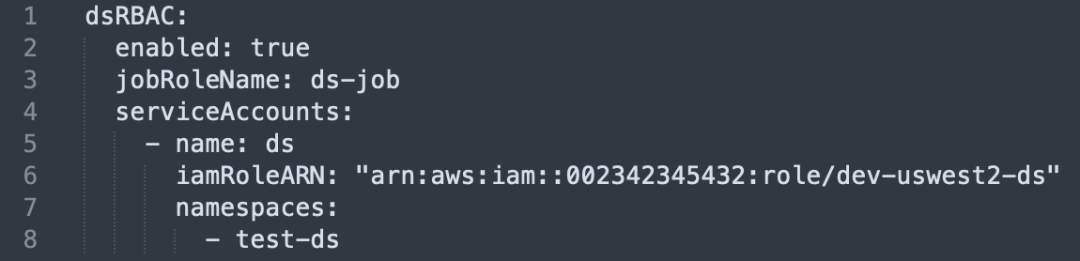
Création et liaison du compte de service: créez un compte de service indépendant pour chaque unité commerciale et liez-le au rôle IAM.
Isolement de l'espace de noms: chaque opération de compte de service accède à ses ressources AWS correspondantes via le rôle IAM dans l'espace de noms spécifié.
Améliorations de la prise en charge des clusters et du contrôle des autorisations
Extensions de type de cluster
Nous avons ajouté un nouveau champ cluster type, pour prendre en charge différents types de clusters K8S, qui incluent non seulement les clusters Webex DC standard et les clusters AWS EKS, mais prennent également en charge des clusters spécifiques avec des exigences de sécurité plus élevées :
Gestion des types de clusters
Champ Type de cluster:par Introduitcluster typedomaines, nous pouvons facilement gérer et étendre la prise en charge de différents clusters K8S.
Personnalisation au niveau du code: En fonction des besoins uniques de clusters spécifiques, nous pouvons apporter des modifications au niveau du code pour garantir que les exigences de sécurité et de configuration sont respectées lors de l'exécution de tâches sur ces clusters.
Système de contrôle des autorisations amélioré (système d'authentification)
Nous avons développé le système Auth spécifiquement pour un contrôle précis des autorisations, y compris la gestion des autorisations entre les projets, les ressources et les espaces de noms :
Fonction de gestion des droits
Autorisations de projet et de ressources: Les utilisateurs peuvent contrôler les autorisations via la dimension du projet. Une fois qu'ils disposent des autorisations du projet, ils ont accès à toutes les ressources du projet.
contrôle des autorisations d'espace de noms: assurez-vous qu'une équipe spécifique ne peut exécuter les tâches de son projet que dans l'espace de noms spécifié, garantissant ainsi l'isolation des ressources en cours d'exécution.
Par exemple, l'équipe A ne peut exécuter que certaines tâches de projet dans son espace de noms A. Par exemple, l'utilisateur B ne peut pas exécuter de tâches dans l'espace de noms de l'utilisateur A.
Application de gestion des ressources et d'autorisations AWS
Nous utilisons le système Auth et d'autres outils pour gérer les autorisations et le contrôle d'accès aux ressources AWS, rendant ainsi l'allocation des ressources plus flexible et sécurisée :
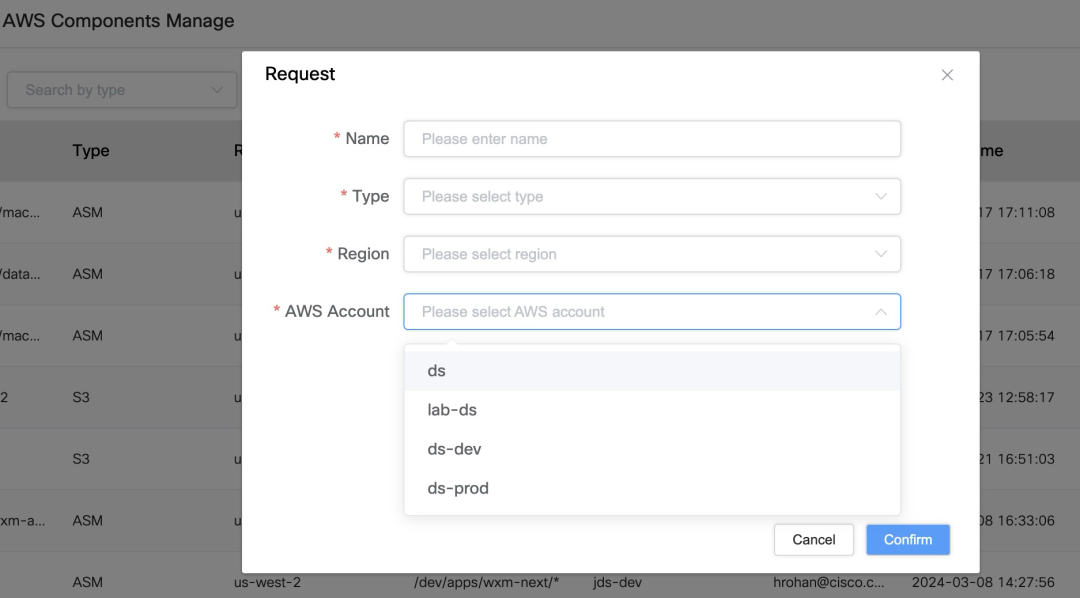
Prise en charge de plusieurs comptes AWS: Dans le système Auth, vous pouvez gérer plusieurs comptes AWS et lier différentes ressources AWS telles que S3 Bucket, ECR, ASM, etc.
Cartographie des ressources et application d'autorisation: Les utilisateurs peuvent mapper les ressources AWS existantes et demander des autorisations dans le système, afin de pouvoir sélectionner facilement les ressources auxquelles ils doivent accéder lors de l'exécution d'une tâche.
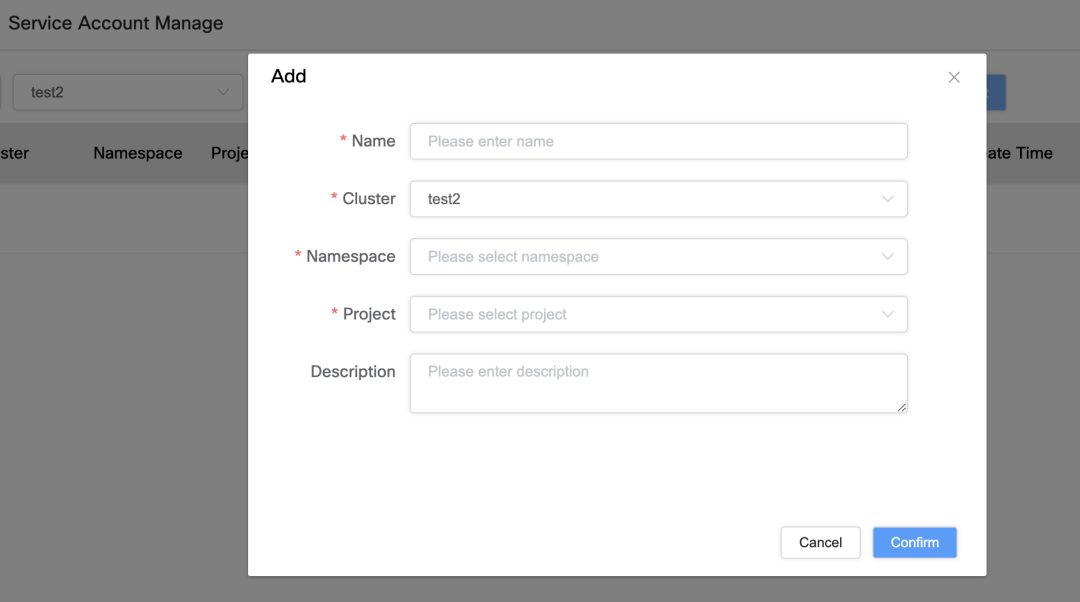
Gestion des comptes de service et liaison des autorisations
Afin de mieux gérer les comptes de service et leurs autorisations, nous avons implémenté les fonctions suivantes :
Liaison et gestion du compte de service
La seule différence entre le compte de service : liez le compte de service via un cluster, un espace de noms et un nom de projet spécifiques pour garantir son unicité.
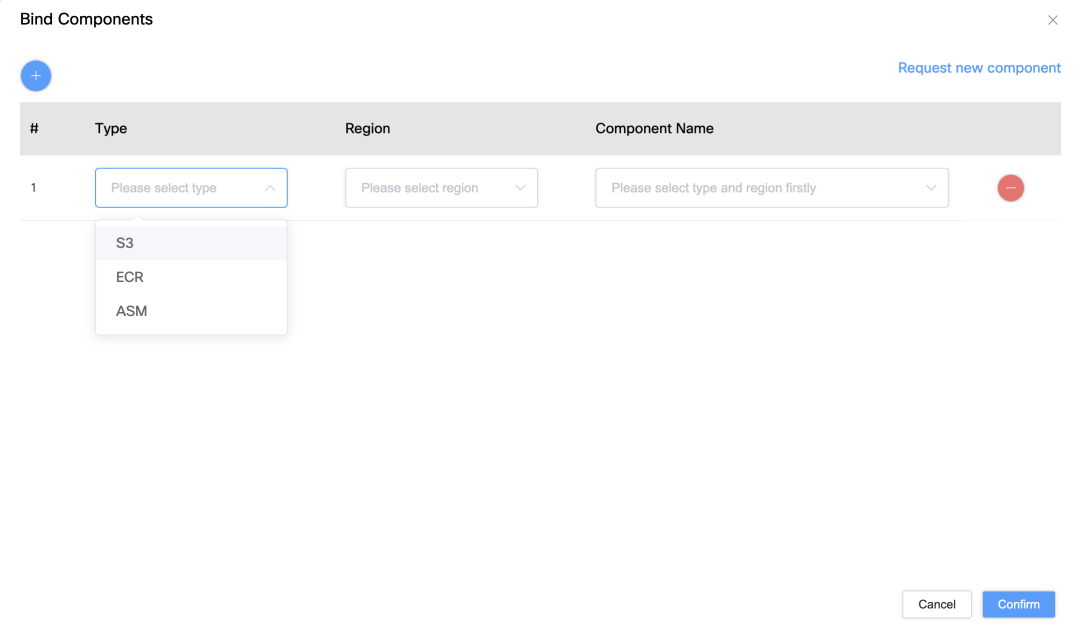
Interface de liaison d'autorisation: Les utilisateurs peuvent lier le compte de service à des ressources AWS spécifiques, telles que S3, ASM ou ECR, sur l'interface pour obtenir un contrôle précis des autorisations.
Simplifiez les opérations et la synchronisation des ressources
Je viens d'en dire beaucoup, mais le fonctionnement réel est relativement simple pour les utilisateurs. L'ensemble du processus de candidature est en fait une tâche ponctuelle. Afin d'améliorer encore l'expérience utilisateur d'Apache DolphinScheduler dans l'environnement AWS, nous avons pris une série de mesures. mesures visant à simplifier les procédures opérationnelles et à améliorer les capacités de synchronisation des ressources.
Laissez-moi vous le résumer :
Interface utilisateur simplifiée
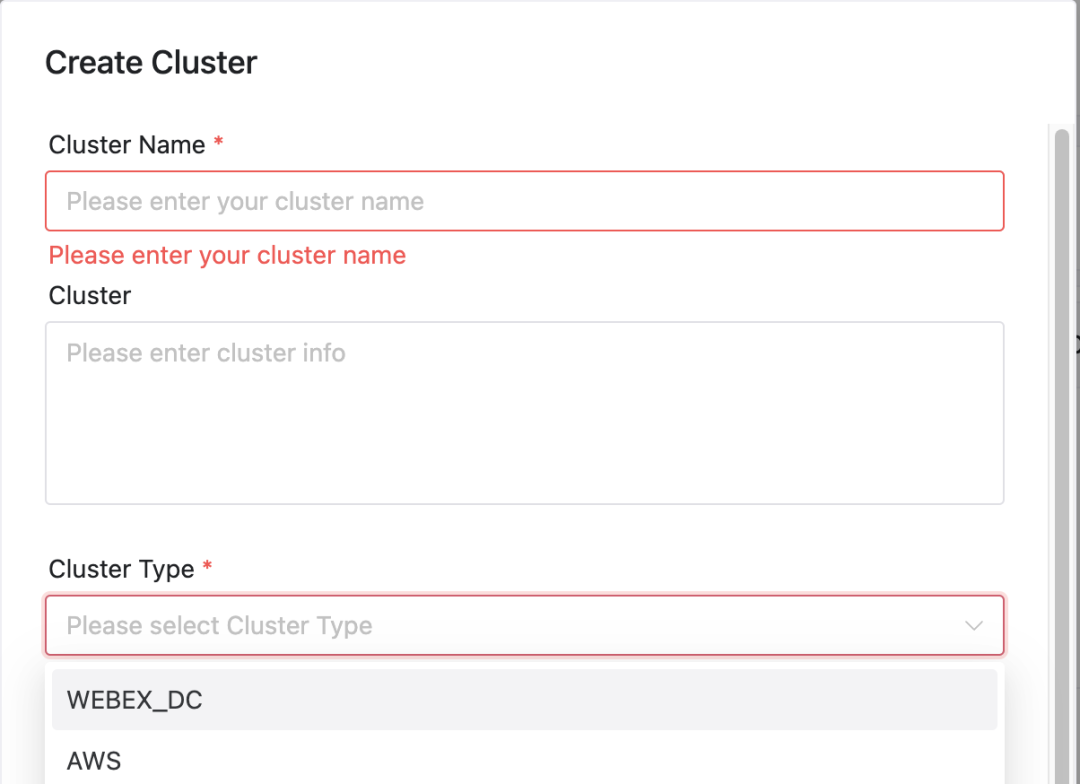
Dans DolphinScheduler, les utilisateurs peuvent facilement configurer le cluster et l'espace de noms spécifiques dans lesquels leurs tâches s'exécutent :
Sélection du cluster et de l'espace de noms
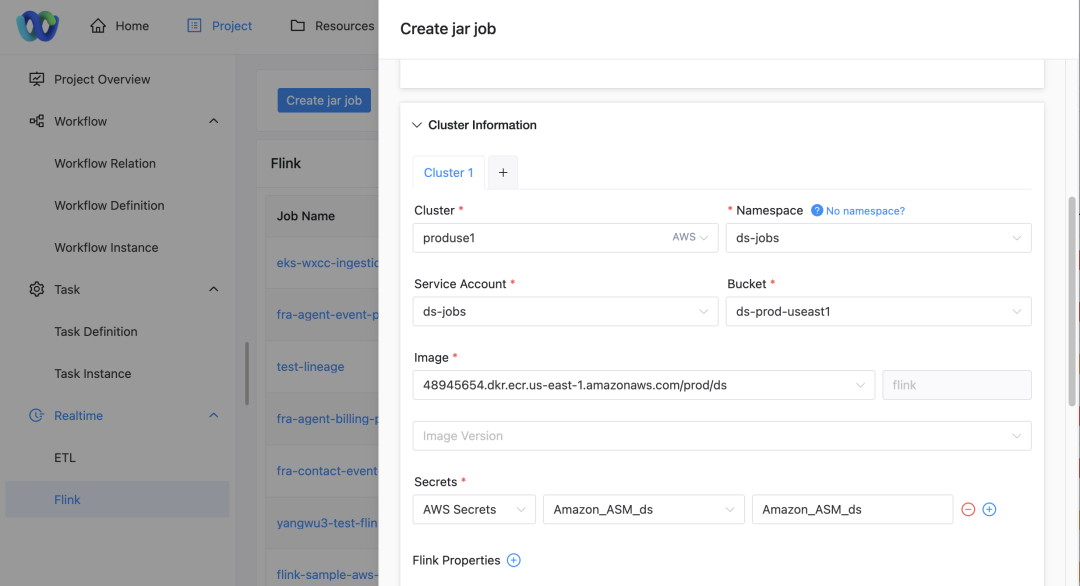
Sélection de cluster: lors de la soumission d'une tâche, les utilisateurs peuvent sélectionner le cluster sur lequel ils souhaitent que la tâche soit exécutée.
configuration de l'espace de noms: En fonction du cluster sélectionné, l'utilisateur doit également spécifier l'espace de noms dans lequel le travail s'exécute.
Compte de service et sélection des ressources
Affichage du compte de service: la page affichera automatiquement le compte de service correspondant en fonction du projet, du cluster et de l'espace de noms sélectionnés.
Configuration de l'accès aux ressources: Les utilisateurs peuvent sélectionner le compartiment S3, l'adresse ECR et la clé ASM associés au compte de service via la liste déroulante.
perspectives d'avenir
Concernant la conception actuelle, certains domaines peuvent encore être optimisés et améliorés pour améliorer la soumission des utilisateurs et faciliter l'exploitation et la maintenance :
Optimisation du push d'images: Envisagez d'ignorer le processus de packaging de transit de Cisco et de transférer le package directement vers ECR, en particulier pour les modifications d'image spécifiques à EKS.
Fonction de synchronisation en un clic: Nous prévoyons de développer une fonction de synchronisation en un clic qui permet aux utilisateurs de télécharger un package de ressources sur un compartiment S3 et de cocher la case pour le synchroniser automatiquement avec d'autres compartiments S3 afin de réduire le travail de téléchargements répétés.
Mapper automatiquement au système d'authentification: Une fois les ressources AWS créées via Terraform, le système mappera automatiquement ces ressources au système de gestion des autorisations pour éviter aux utilisateurs de saisir manuellement les ressources.
Optimisation du contrôle des autorisations: Grâce à la gestion automatisée des ressources et des autorisations, les opérations des utilisateurs deviennent plus simples, réduisant ainsi la complexité de la configuration et de la gestion.
Avec ces améliorations, nous espérons aider les utilisateurs à déployer et gérer leurs tâches plus efficacement à l'aide d'Apache DolphinScheduler, que ce soit sur Webex DC ou EKS, tout en améliorant l'efficacité et la sécurité de la gestion des ressources.