Apache DolphinScheduler を使用してビッグ データ プラットフォームを構築およびデプロイし、タスクを AWS に送信する実務経験
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
著者について
李青旺 - ソフトウェア開発エンジニア、Cisco
導入
皆さん、こんにちは。私の名前は、Cisco のソフトウェア開発エンジニア、Li Qingwang です。私たちのチームは、3 年近くにわたり、Apache DolphinScheduler を使用して独自のビッグ データ スケジューリング プラットフォームを構築してきました。初期バージョン 2.0.3 から現在に至るまで、私たちはコミュニティとともに成長してきました。今日皆さんに共有した技術アイデアは、バージョン 3.1.1 に基づいて、コミュニティ バージョンには含まれていないいくつかの新機能を追加した二次的な開発です。
今日は、Apache DolphinScheduler を使用してビッグデータ プラットフォームを構築し、タスクを AWS に送信してデプロイする方法と、そのプロセス中に遭遇したいくつかの課題とその解決策を共有します。
アーキテクチャの設計と調整
当初、API、アラート、および Zookeeper (ZK)、Master、Worker などのコンポーネントを含むすべてのサービスは Kubernetes (K8s) 上にデプロイされます。
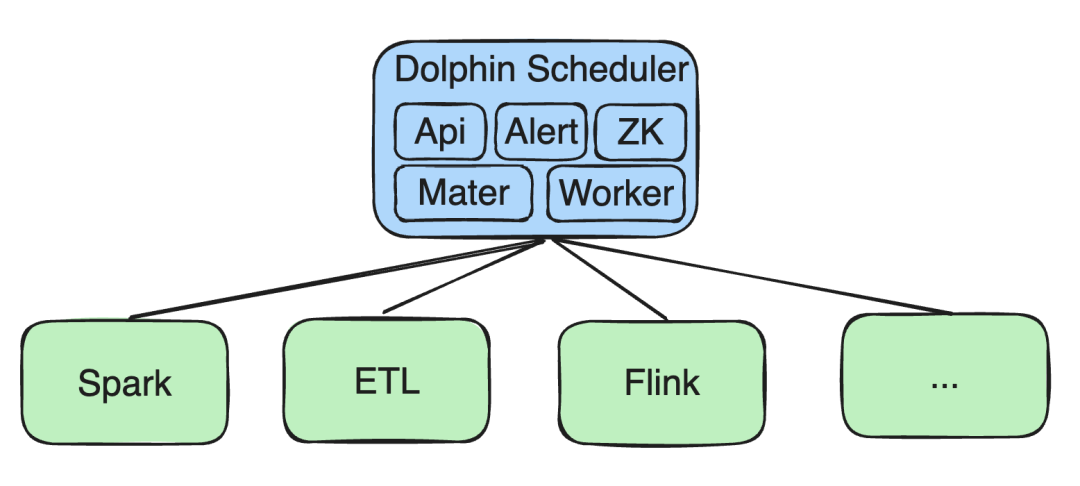
ビッグデータ処理タスク
Spark、ETL、Flink などのタスクの二次開発を実施しました。
- ETLタスク: 私たちのチームは、ユーザーが ETL タスクを迅速に生成できるシンプルなドラッグ アンド ドロップ ツールを開発しました。
- スパークのサポート : 初期バージョンでは Yarn 上での Spark の実行のみをサポートしていましたが、二次開発を通じて K8s 上での実行をサポートしました。コミュニティの最新バージョンは現在、K8 上の Spark をサポートしています。
- ※Flink二次開発: 同様に、Flink On K8s ストリーミング タスクと、K8s 上の SQL タスクおよび Python タスクのサポートを追加しました。
AWS でのサポートの仕事
ビジネスが拡大し、データ ポリシーが必要になるにつれて、私たちはさまざまなリージョンでデータ タスクを実行しなければならないという課題に直面しています。そのためには、複数のクラスターをサポートできるアーキテクチャを構築する必要があります。以下に、ソリューションと実装プロセスの詳細を説明します。
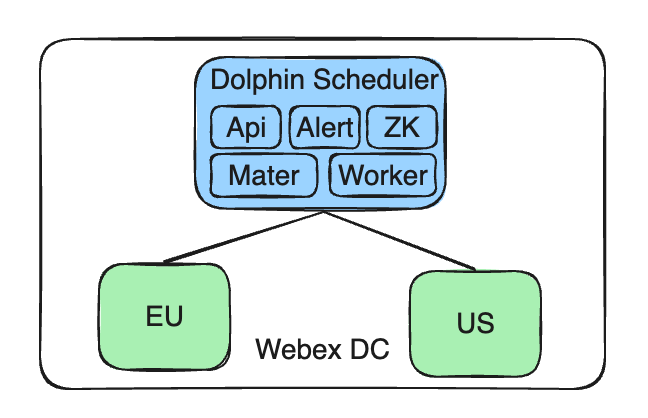
現在のアーキテクチャは、集中制御エンドポイント、複数のクラスターを管理する単一の Apache DolphinScheduler サービスで構成されています。これらのクラスターは、地域のデータ ポリシーと分離要件に準拠するために、EU や米国などのさまざまな地域に分散されています。
アーキテクチャの調整
この需要に応えるために、次の調整を行いました。
- Apache DolphinScheduler サービスを一元管理する: 当社の DolphinScheduler サービスは引き続き自社構築の Cisco Webex DC に展開され、管理の一元化と一貫性が維持されます。
- AWS EKSクラスターをサポート : 同時に、複数の AWS EKS クラスターをサポートするためにアーキテクチャの機能を拡張しました。このようにして、他の Webex DC クラスターの操作やデータ分離に影響を与えることなく、EKS クラスター上で実行されるタスクに対する新しいビジネス要件を満たすことができます。
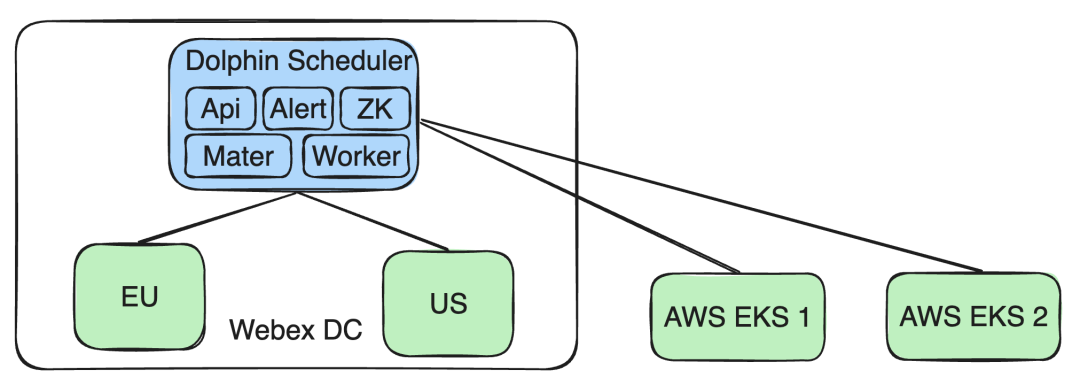
この設計により、データの分離とポリシーへのコンプライアンスを確保しながら、さまざまなビジネス ニーズや技術的課題に柔軟に対応できます。
次に、Cisco Webex DC でタスクを実行するときに、Apache DolphinScheduler の技術的な実装とリソースの依存関係を処理する方法を紹介します。
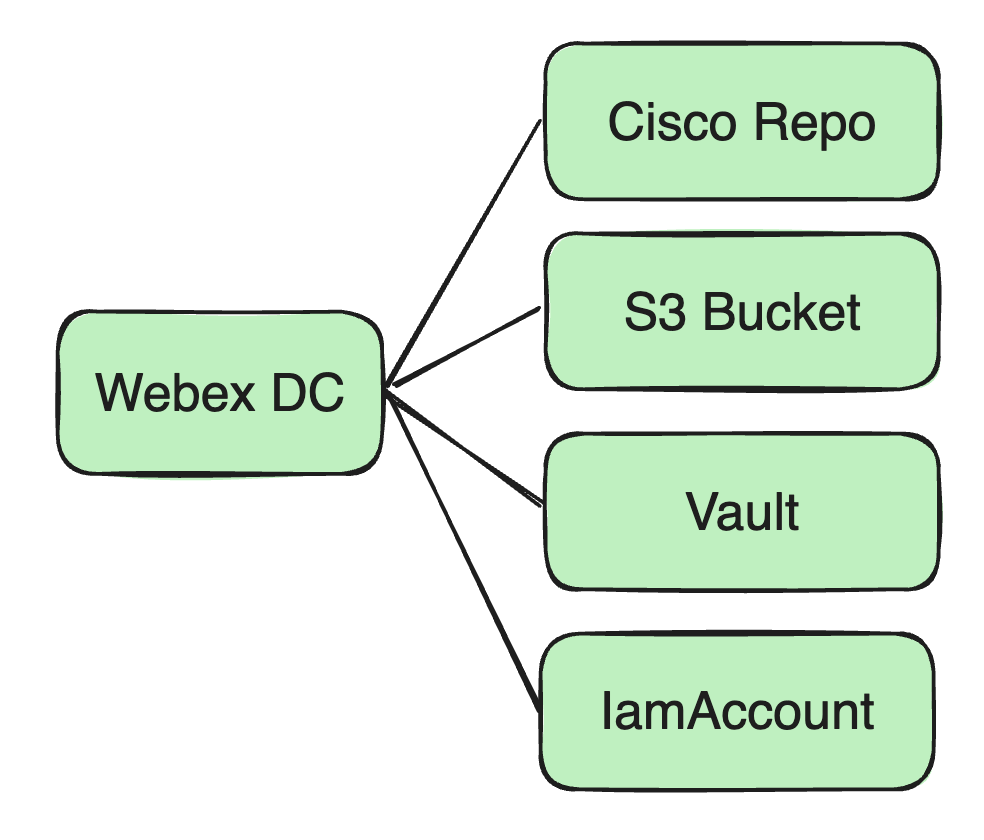
リソースの依存関係とストレージ
すべてのタスクは Kubernetes (K8s) 上で実行されるため、次のことが重要です。
Dockerイメージ
- ストレージの場所:以前は、すべての Docker イメージは Cisco の Docker リポジトリに保存されていました。
- 画像管理: これらのイメージは、実行するさまざまなサービスやタスクに必要な動作環境と依存関係を提供します。
リソースファイルと依存関係
- Jarパッケージや設定ファイルなど: ユーザーの Jar パッケージと依存する可能性のある設定ファイルを保存するリソース ストレージ センターとして Amazon S3 Bucket を使用します。
- セキュリティリソース管理: データベース パスワード、Kafka 暗号化情報、ユーザー依存キーなどが含まれます。これらの機密情報は Cisco の Vault サービスに保存されます。
安全なアクセスと権利管理
S3 バケットにアクセスする必要がある場合は、AWS 認証情報を構成および管理する必要があります。
IAMアカウントの設定
- 資格管理: 当社は IAM アカウントを使用して、アクセス キーや秘密キーなどの AWS リソースへのアクセスを管理します。
- K8sの統合: これらの認証情報は Kubernetes Secret に保存され、S3 バケットに安全にアクセスするために API サービスによって参照されます。
- アクセス許可の制御とリソースの分離: IAM アカウントを通じて、きめ細かい権限制御を実装し、データ セキュリティとビジネス コンプライアンスを確保できます。
IAMアカウントアクセスキーの有効期限問題とその対策
IAM アカウントを使用して AWS リソースを管理する過程で、アクセスキーの有効期限の問題に直面します。私たちがこの課題にどのように取り組んでいるかについて詳しく説明します。
アクセスキーの有効期限の問題
- 重要な期間: IAM アカウントの AWS キーは、システムのセキュリティを強化するために、通常 90 日ごとに自動的に期限切れになるように設定されています。
- ミッションへの影響: キーの有効期限が切れると、これらのキーに依存して AWS リソースにアクセスするすべてのタスクが実行できなくなります。そのため、ビジネスの継続性を維持するには、タイムリーにキーを更新する必要があります。
この状況に対応して、タスクの定期的な再起動を設定し、有効期限が切れる前に AWS アカウントに問題がある場合は、対応する開発者に何らかの処理を行うように通知する必要があります。
AWS EKSのサポート
私たちのビジネスが AWS EKS に拡大するにつれて、既存のアーキテクチャとセキュリティ対策に一連の調整を行う必要があります。 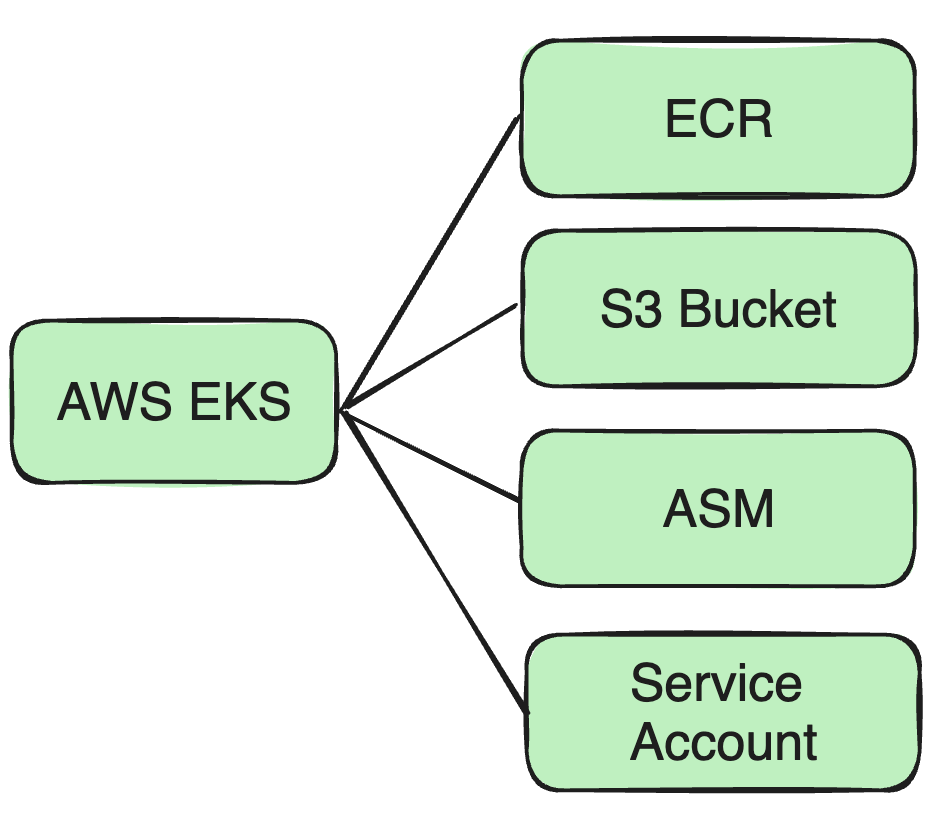
たとえば、先ほど述べた Docker イメージのように、以前は Cisco 独自の Docker リポジトリに配置していたため、今度は Docker イメージを ECR に配置する必要があります。 
複数の S3 バケットのサポート
AWS クラスターの分散型の性質とさまざまなビジネスのデータ分離要件により、さまざまなクラスターのデータ ストレージのニーズを満たすために複数の S3 バケットをサポートする必要があります。 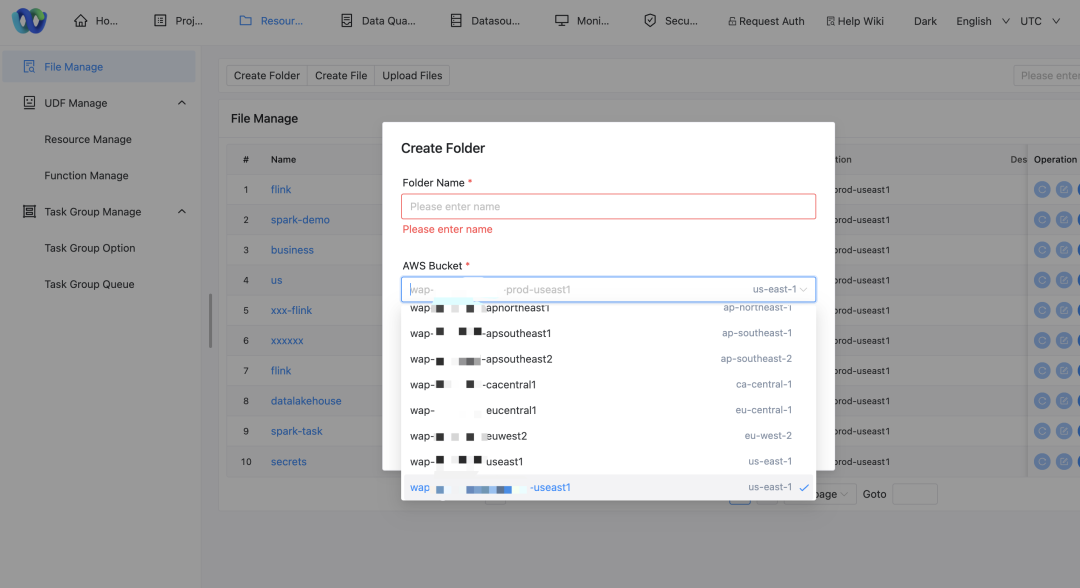
- クラスタとバケットの対応: 各クラスターは対応する S3 バケットにアクセスして、データの局所性とコンプライアンスを確保します。
- 戦略を修正する: 複数の S3 バケットからのデータの読み取りと書き込みをサポートするには、ストレージ アクセス ポリシーを調整する必要があります。さまざまなビジネス パーティが対応する S3 バケットにアクセスする必要があります。
パスワード管理ツールの変更
セキュリティを向上させるために、Cisco が独自に構築した Vault サービスから AWS の Secrets Manager (ASM) に移行しました。
- ASMの使用: ASM は、AWS リソースのパスワードとキーを管理するための、より統合されたソリューションを提供します。
ポッドのセキュリティを強化するために、IAM ロールとサービス アカウントを使用する方法を採用しました。
- IAM ロールとポリシーを作成する: まず IAM ロールを作成し、必要なポリシーをそれにバインドして、必要なアクセス許可のみが付与されるようにします。
- K8s サービス アカウントをバインドする: 次に、Kubernetes サービス アカウントを作成し、それを IAM ロールに関連付けます。
- ポッド権限の統合: ポッドを実行するときに、ポッドをサービス アカウントに関連付けることにより、ポッドは IAM ロールを通じて必要な AWS 認証情報を直接取得できるため、必要な AWS リソースにアクセスできます。
これらの調整により、システムのスケーラビリティと柔軟性が向上するだけでなく、全体的なセキュリティ アーキテクチャが強化され、AWS 環境での運用が効率的かつ安全になることが保証されます。同時に、キーの自動有効期限切れと再起動の必要性という以前の問題も回避されます。
リソース管理とストレージプロセスを最適化する
デプロイメントプロセスを簡素化するために、セカンダリトランジットを経由する代わりに、Docker イメージを ECR に直接プッシュする予定です。
- 直接押す: Docker イメージがビルド後に ECR に直接プッシュされるように、現在のパッケージ化プロセスを変更して、時間の遅延と潜在的なエラー ポイントを削減します。
変更の実装
- コードレベルの調整: DolphinScheduler コードを変更して、複数の S3 クライアントをサポートできるようにし、複数の S3 クライアントのキャッシュ管理を追加しました。
- リソース管理UIの調整: ユーザーがインターフェイスを介して操作に異なる AWS バケット名を選択できるようにします。
- リソースアクセス: 変更された Apache DolphinScheduler サービスは複数の S3 バケットにアクセスできるようになり、異なる AWS クラスター間のデータを柔軟に管理できるようになります。
AWS リソースの管理と権限の分離
AWS Secrets Manager (ASM) の統合
Apache DolphinScheduler を拡張して AWS Secrets Manager をサポートし、ユーザーがさまざまなクラスター タイプにわたってシークレットを選択できるようにしました。
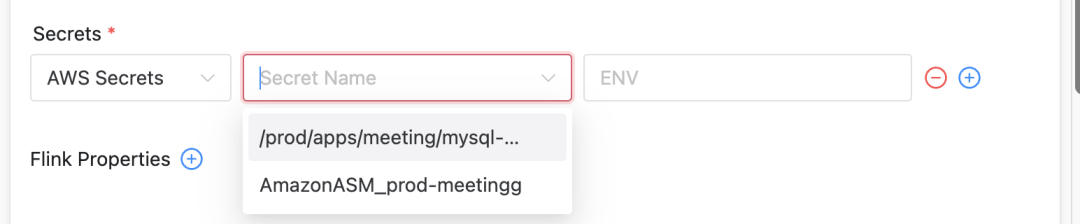
ASM機能統合
- ユーザーインターフェースの改善: DolphinScheduler のユーザー インターフェイスに、さまざまなシークレット タイプの表示および選択機能が追加されます。
- 自動キー管理: ユーザーが選択したシークレットを保存するファイル パスを実行時に実際の Pod 環境変数にマップし、キーの安全な使用を保証します。
動的リソース構成および初期化サービス (Init Container)
AWS リソースをより柔軟に管理および初期化するために、Init Container と呼ばれるサービスを実装しました。
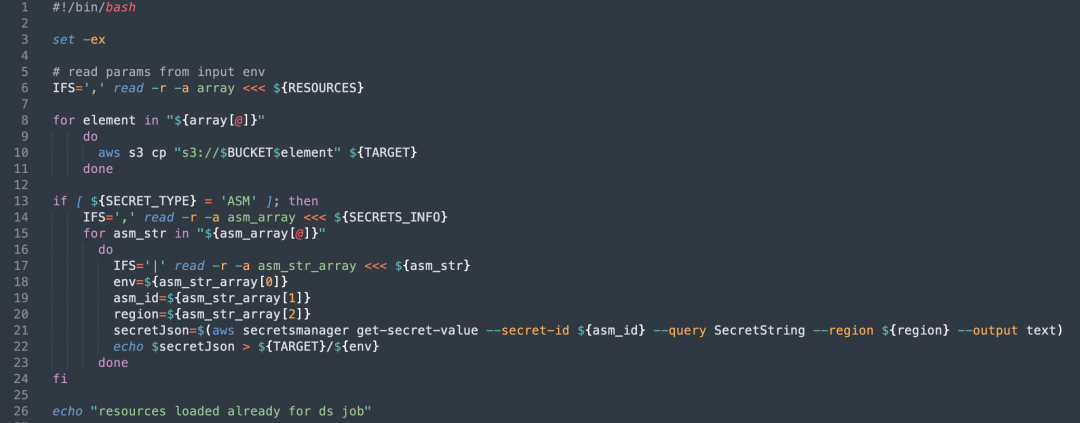
- リソースのプル: Init Container は、ポッドが実行される前に、ユーザーによって構成された S3 リソースを自動的にプルし、指定されたディレクトリに配置します。
- キーと構成の管理: 設定に従って、Init Container は ASM 内のパスワード情報を確認して取得し、それをファイルに保存し、Pod で使用できるように環境変数を介してマッピングします。
Terraform を通じて AWS リソースの構成と管理プロセスを自動化し、リソースの割り当てと権限の設定を簡素化しました。
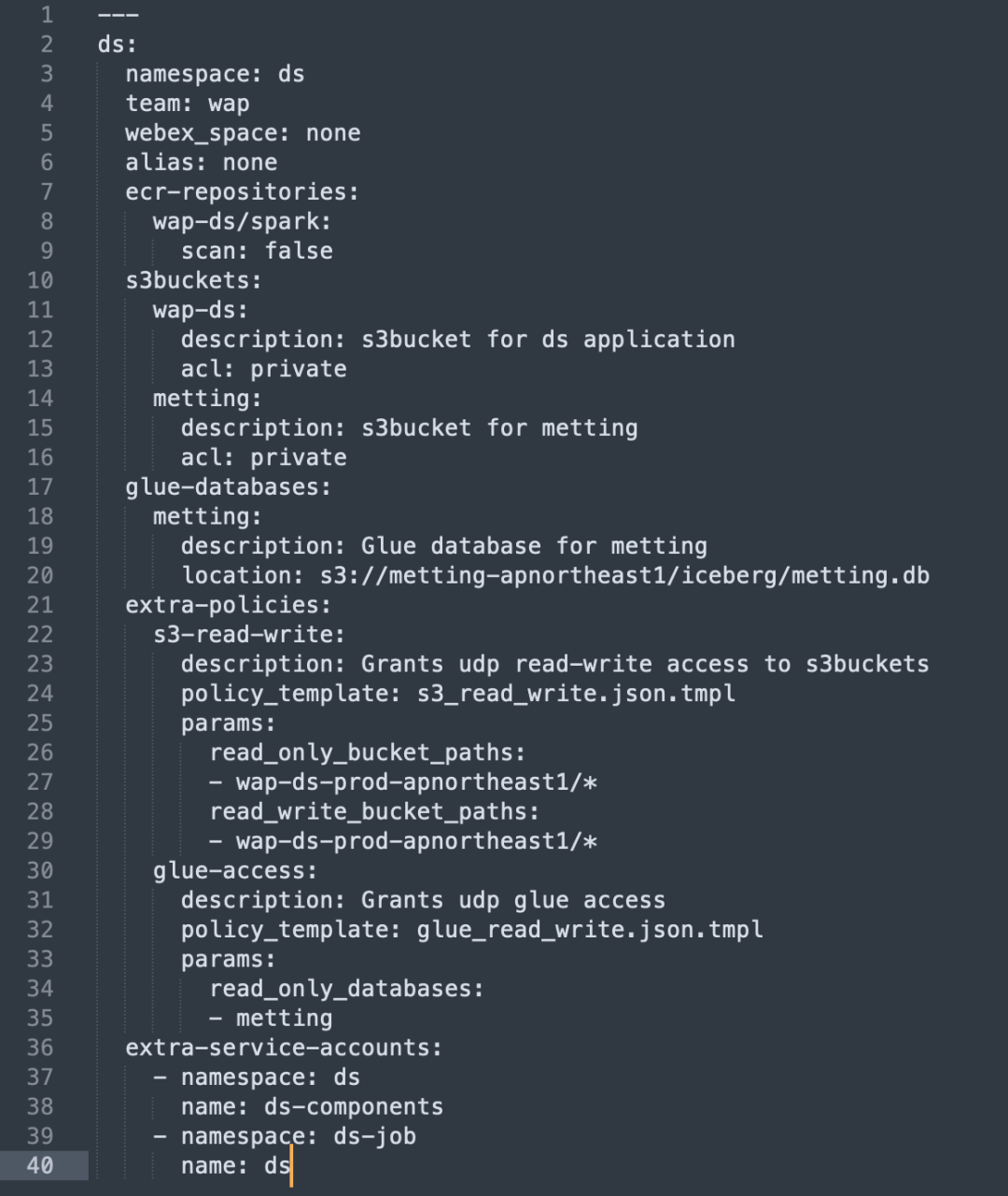
- 自動リソース構成: Terraform を使用して、S3 バケットや ECR リポジトリなどの必要な AWS リソースを作成します。
- IAM ポリシーとロール管理: IAM ポリシーとロールを自動的に作成し、各ビジネス ユニットが必要なリソースにオンデマンドでアクセスできるようにします。
権限の分離とセキュリティ
当社では、高度な権限分離戦略を使用して、さまざまなビジネス ユニットが独立した名前空間で動作するようにし、リソース アクセスの競合やセキュリティ リスクを回避します。
実装の詳細
- サービスアカウントの作成とバインド: ビジネスユニットごとに独立したサービスアカウントを作成し、IAM ロールにバインドします。
- 名前空間の分離: 各サービス アカウントのオペレーションは、指定された名前空間内の IAM ロールを通じて、対応する AWS リソースにアクセスします。
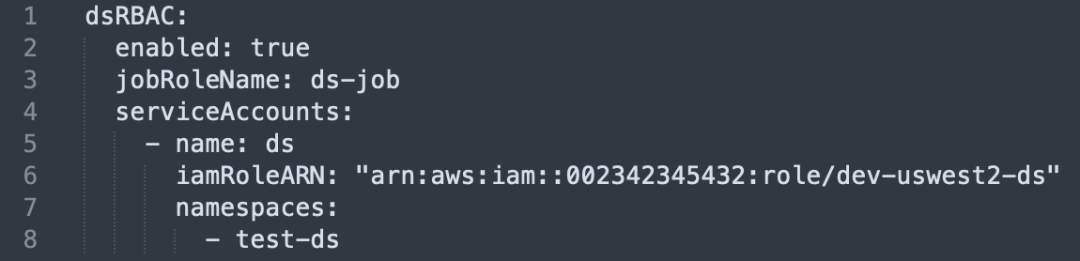
クラスターのサポートと権限制御の改善
クラスタータイプの拡張
新しいフィールドを追加しました cluster type、さまざまなタイプの K8S クラスターをサポートするには、標準の Webex DC クラスターと AWS EKS クラスターだけでなく、より高いセキュリティ要件を持つ特定のクラスターもサポートします。
クラスタタイプの管理
- クラスタータイプフィールド:紹介者による
cluster typeフィールドを使用すると、さまざまな K8S クラスターのサポートを簡単に管理および拡張できます。 - コードレベルのカスタマイズ: 特定のクラスター固有のニーズに基づいて、コード レベルの変更を加えて、これらのクラスターでジョブを実行するときにセキュリティと構成の要件が確実に満たされるようにすることができます。
強化された権限制御システム(Authシステム)
私たちは、プロジェクト、リソース、名前空間間の権限管理など、きめ細かい権限制御を目的とした認証システムを開発しました。
権利管理機能
- プロジェクトとリソースの権限: ユーザーはプロジェクト ディメンションを通じて権限を制御でき、プロジェクト権限を取得すると、プロジェクト内のすべてのリソースにアクセスできるようになります。
- 名前空間の権限制御: 特定のチームが指定された名前空間でのみプロジェクトのジョブを実行できるようにすることで、実行中のリソースが確実に分離されます。
たとえば、チーム A は、その A ネームスペースでのみ特定のプロジェクト ジョブを実行できます。たとえば、ユーザー B はユーザー A のネームスペースでジョブを実行できません。
AWS リソース管理と許可アプリケーション
私たちは認証システムとその他のツールを使用して AWS リソースのアクセス許可とアクセス制御を管理し、リソースの割り当てをより柔軟かつ安全にしています。
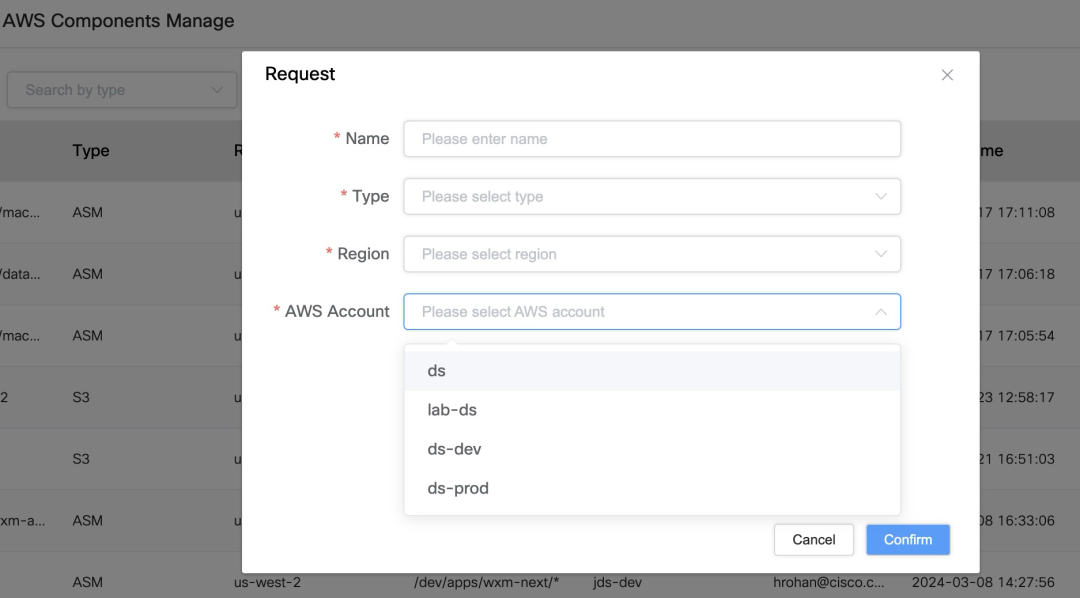
- 複数の AWS アカウントのサポート: 認証システムでは、複数の AWS アカウントを管理し、S3 バケット、ECR、ASM などのさまざまな AWS リソースをバインドできます。
- リソースのマッピングと権限のアプリケーション: ユーザーは既存の AWS リソースをマッピングし、システム内のアクセス許可を申請できるため、ジョブの実行時にアクセスする必要があるリソースを簡単に選択できます。
サービスアカウントの管理と権限のバインド
サービス アカウントとその権限をより適切に管理するために、次の機能を実装しました。
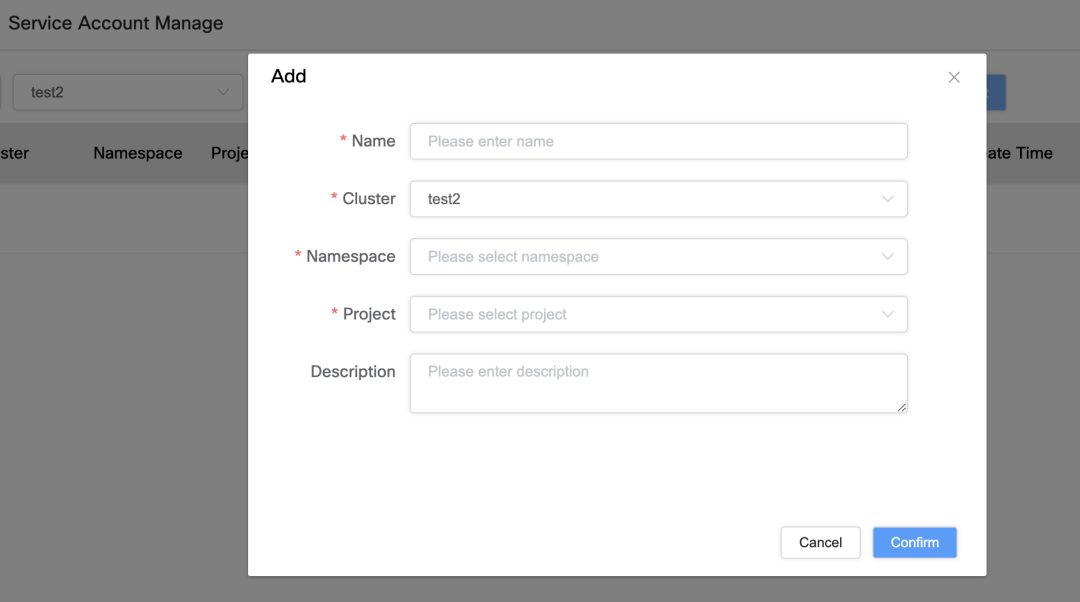
サービスアカウントのバインドと管理
- サービスアカウントの唯一の違い: サービス アカウントを特定のクラスター、名前空間、プロジェクト名を介してバインドして、一意性を確保します。
- パーミッションバインディングインターフェイス: ユーザーは、インターフェイス上でサービス アカウントを S3、ASM、ECR などの特定の AWS リソースにバインドして、アクセス許可を正確に制御できます。
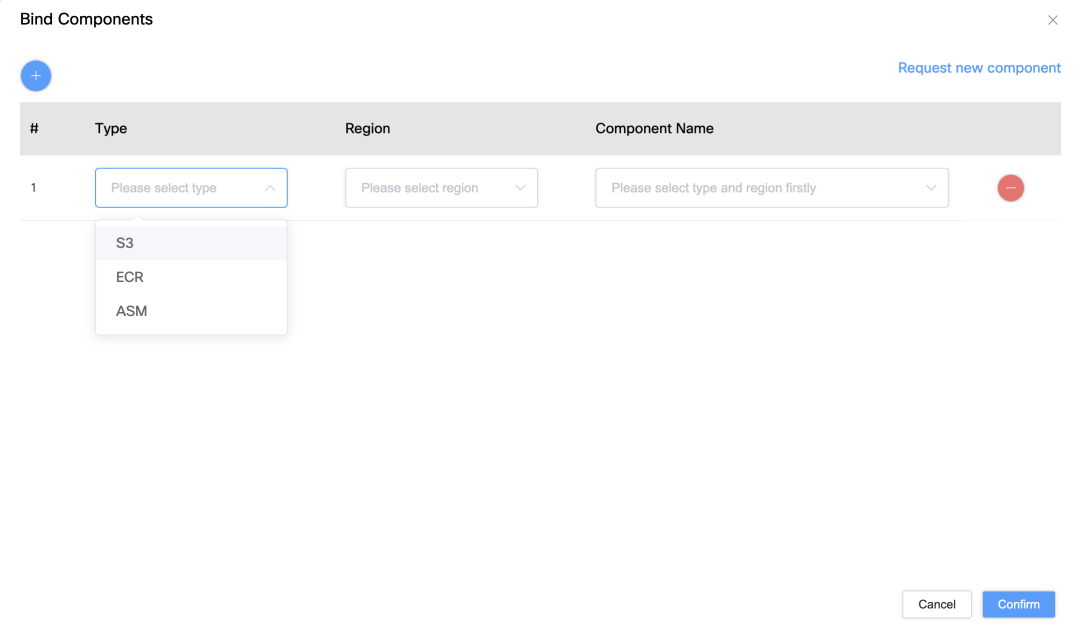
操作とリソースの同期を簡素化
いろいろ言いましたが、実際のアプリケーションのプロセス全体は、ユーザーにとっては比較的簡単です。AWS 環境での Apache DolphinScheduler のユーザー エクスペリエンスをさらに向上させるために、私たちは一連の作業を行いました。操作手順を簡素化し、リソース同期機能を強化するための措置を講じます。
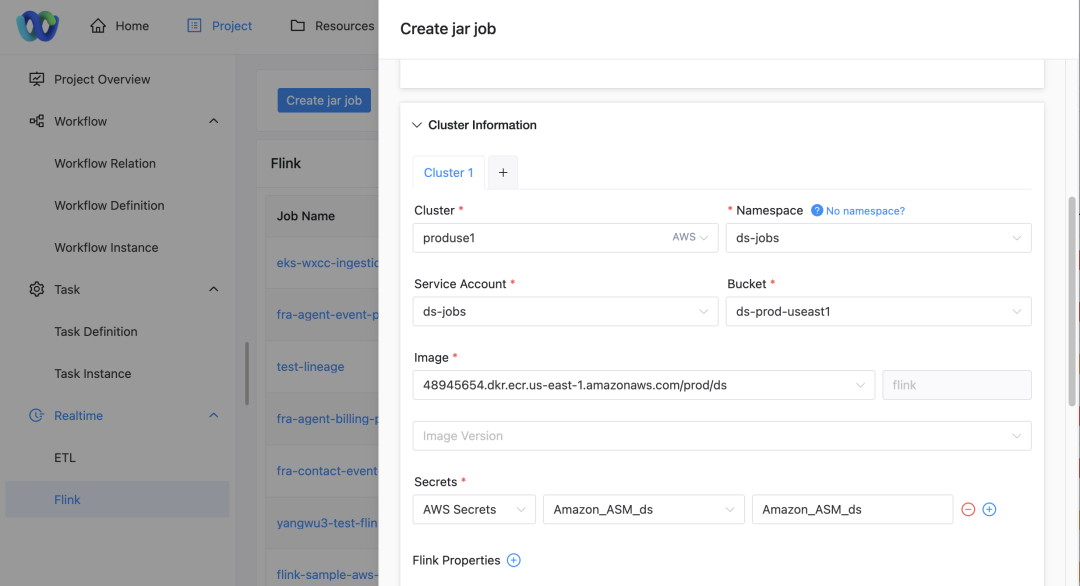
要約してみましょう:
簡素化されたユーザーインターフェース
DolphinScheduler では、ユーザーはジョブを実行する特定のクラスターと名前空間を簡単に構成できます。
クラスターと名前空間の選択
- クラスターの選択: ジョブを送信するときに、ユーザーはジョブを実行するクラスターを選択できます。
- 名前空間の構成注: 選択したクラスターに応じて、ユーザーはジョブを実行するネームスペースも指定する必要があります。
サービスアカウントとリソースの選択
- サービスアカウントの表示: このページには、選択したプロジェクト、クラスター、名前空間に基づいて、対応するサービス アカウントが自動的に表示されます。
- リソースアクセス構成: ユーザーは、ドロップダウン リストからサービス アカウントに関連付けられた S3 バケット、ECR アドレス、および ASM キーを選択できます。
今後の展望
現在の設計に関しては、ユーザーの提出を改善し、運用とメンテナンスを容易にするために最適化および改善できる領域がまだいくつかあります。
- 画像プッシュの最適化:特に EKS 固有のイメージ変更の場合は、Cisco のトランジット パッケージング プロセスをスキップし、パッケージを ECR に直接プッシュすることを検討してください。
- ワンクリック同期機能: ユーザーがリソース パッケージを S3 バケットにアップロードし、チェックボックスをオンにすると他の S3 バケットに自動的に同期され、繰り返しアップロードする作業を軽減できるワンクリック同期機能を開発する予定です。
- 認証システムに自動的にマッピング: Terraform を通じて Aws リソースが作成された後、システムはこれらのリソースをアクセス許可管理システムに自動的にマッピングし、ユーザーがリソースを手動で入力することを回避します。
- 権限制御の最適化: リソースと権限の管理が自動化されることで、ユーザーの操作が簡素化され、セットアップと管理の複雑さが軽減されます。
これらの改善により、Webex DC または EKS のいずれにおいても、ユーザーが Apache DolphinScheduler を使用してジョブをより効率的に展開および管理できるようになり、同時にリソース管理の効率とセキュリティが向上することが期待されます。
この記事を書いているのは、 Beluga オープンソース テクノロジー 出版サポートあり!

