Li Qingwang - Ingegnere dello sviluppo software, Cisco
introduzione
Ciao a tutti, mi chiamo Li Qingwang, un ingegnere di sviluppo software di Cisco. Il nostro team utilizza Apache DolphinScheduler per creare la nostra piattaforma di pianificazione dei big data da quasi tre anni. Dalla versione iniziale 2.0.3 ad oggi, siamo cresciuti insieme alla community. Le idee tecniche condivise con voi oggi sono sviluppi secondari basati sulla versione 3.1.1, aggiungendo alcune nuove funzionalità non incluse nella versione community.
Oggi condividerò come utilizziamo Apache DolphinScheduler per creare una piattaforma per big data e inviare e distribuire le nostre attività ad AWS. Alcune sfide incontrate durante il processo e le nostre soluzioni.
Progettazione e adeguamento dell'architettura
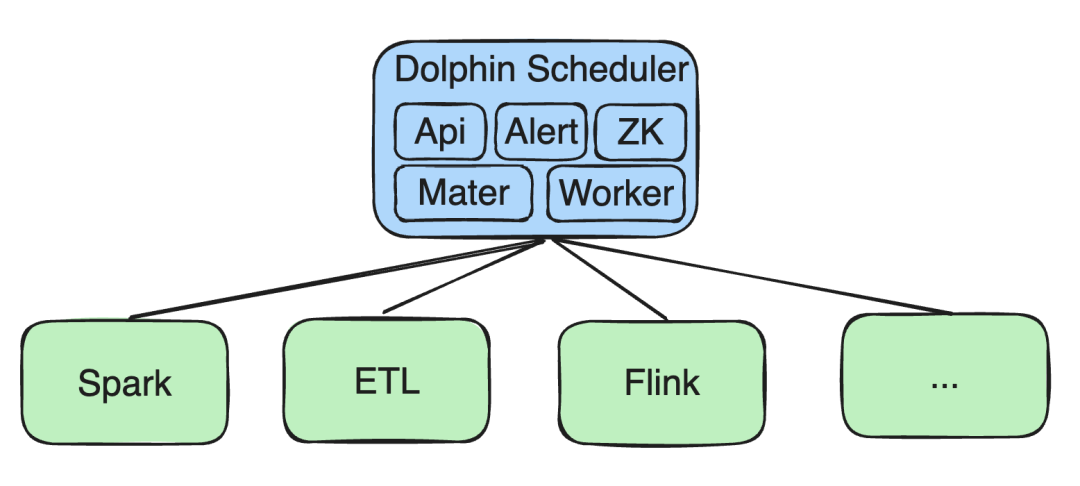
Inizialmente, tutti i nostri servizi vengono distribuiti su Kubernetes (K8), inclusi API, Alert e componenti come Zookeeper (ZK), Master e Worker.
Attività di elaborazione dei big data
Abbiamo condotto uno sviluppo secondario su attività come Spark, ETL e Flink:
Compiti ETL: Il nostro team ha sviluppato un semplice strumento di trascinamento della selezione attraverso il quale gli utenti possono generare rapidamente attività ETL.
Supporto scintilla : La prima versione supportava solo l'esecuzione di Spark su Yarn e abbiamo fatto in modo che supportasse l'esecuzione su K8 tramite lo sviluppo secondario. L'ultima versione della community attualmente supporta Spark su K8.
*Sviluppo secondario di Flink: Allo stesso modo, abbiamo aggiunto attività di streaming Flink su K8, nonché il supporto per attività SQL e attività Python su K8.
Lavoro di supporto su AWS
Man mano che l'azienda si espande e si rendono necessarie politiche sui dati, ci troviamo ad affrontare la sfida di dover eseguire attività relative ai dati in diverse regioni. Ciò richiede di costruire un'architettura in grado di supportare più cluster. Di seguito è riportata una descrizione dettagliata della nostra soluzione e del processo di implementazione.
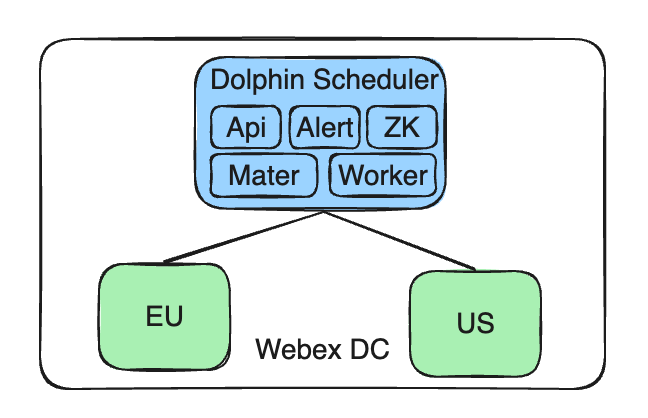
La nostra architettura attuale è costituita da un endpoint di controllo centralizzato, un singolo servizio Apache DolphinScheduler, che gestisce più cluster. Questi cluster sono distribuiti in diverse aree geografiche, come l'UE e gli Stati Uniti, per conformarsi alle politiche locali sui dati e ai requisiti di isolamento.
Adeguamento architettonico
Per soddisfare questa richiesta, abbiamo apportato le seguenti modifiche:
Mantieni il servizio Apache DolphinScheduler gestito centralmente: Il nostro servizio DolphinScheduler è ancora distribuito nel Cisco Webex DC autocostruito, mantenendo la centralizzazione e la coerenza della gestione.
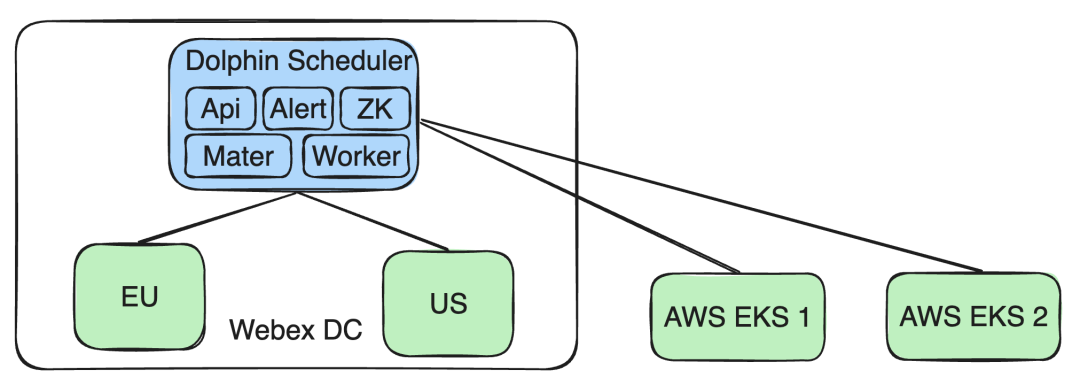
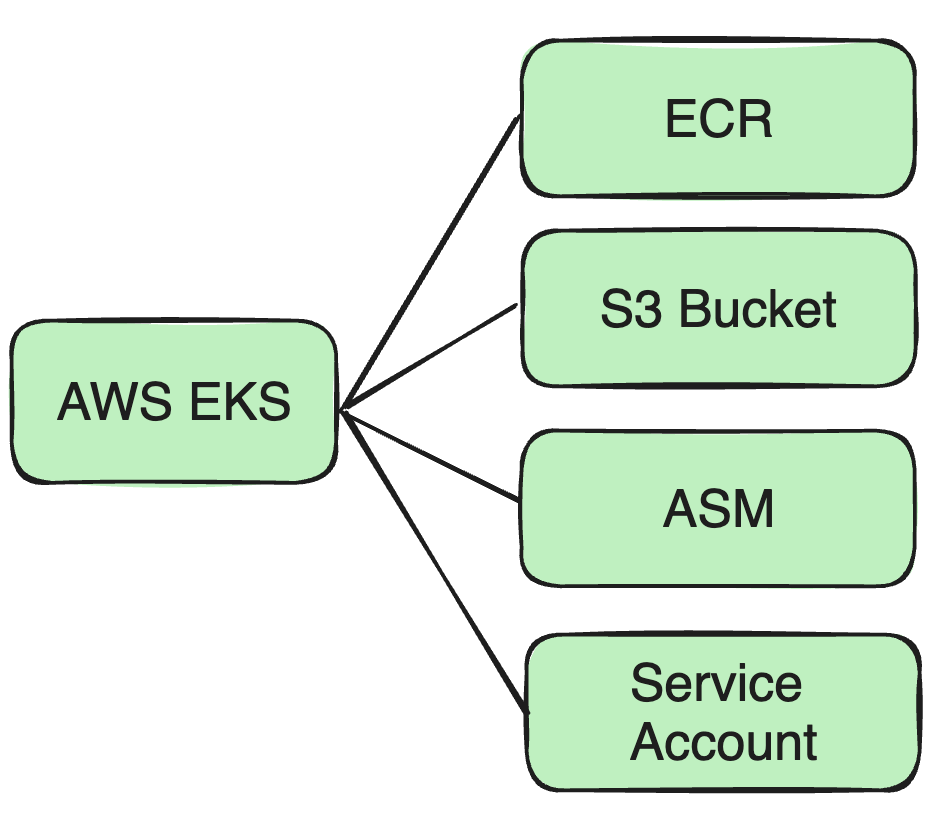
Supporta il cluster AWS EKS : Allo stesso tempo, abbiamo ampliato le capacità della nostra architettura per supportare più cluster AWS EKS. In questo modo, è possibile soddisfare i nuovi requisiti aziendali per le attività in esecuzione sul cluster EKS senza influire sul funzionamento e sull'isolamento dei dati di altri cluster Webex DC.
Attraverso questa progettazione, possiamo rispondere in modo flessibile alle diverse esigenze aziendali e sfide tecniche, garantendo al tempo stesso l'isolamento dei dati e la conformità alle policy.
Successivamente, introdurremo come gestire l'implementazione tecnica e le dipendenze delle risorse di Apache DolphinScheduler durante l'esecuzione di attività in Cisco Webex DC.
Dipendenze e archiviazione delle risorse
Poiché tutte le nostre attività vengono eseguite su Kubernetes (K8), è fondamentale per noi:
Immagine Docker
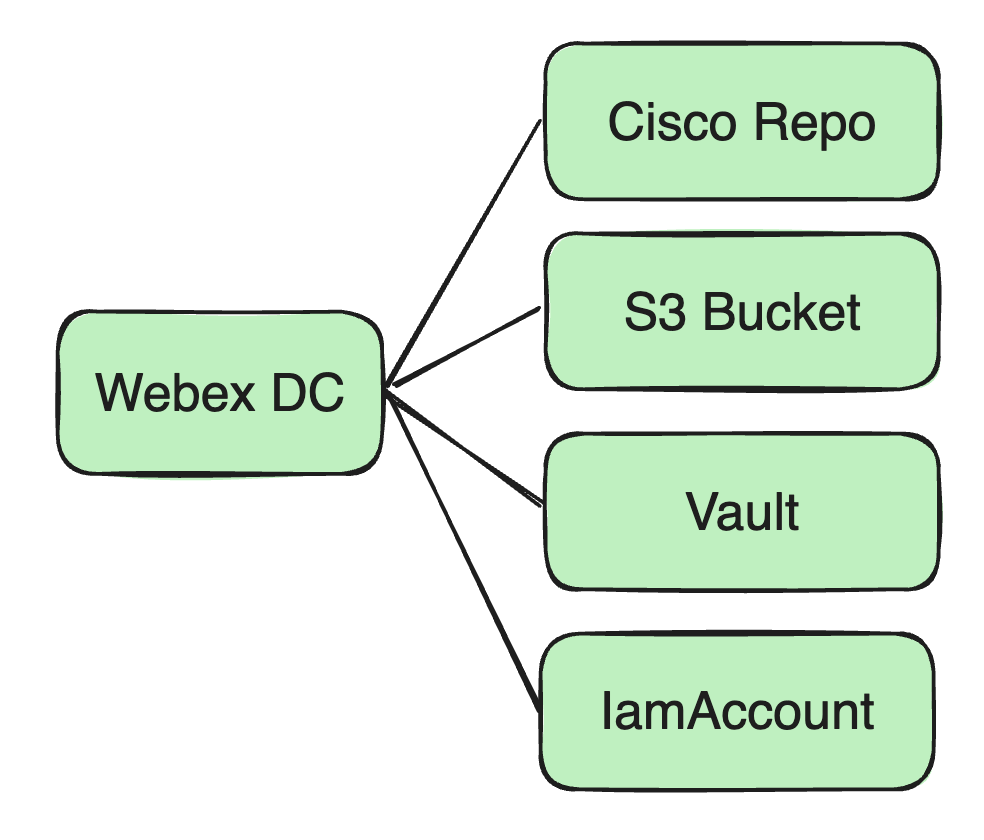
posizione di archiviazione: In precedenza, tutte le nostre immagini Docker erano archiviate in un repository Docker presso Cisco.
Gestione delle immagini: Queste immagini forniscono l'ambiente operativo e le dipendenze necessari per i vari servizi e attività che eseguiamo.
File di risorse e dipendenze
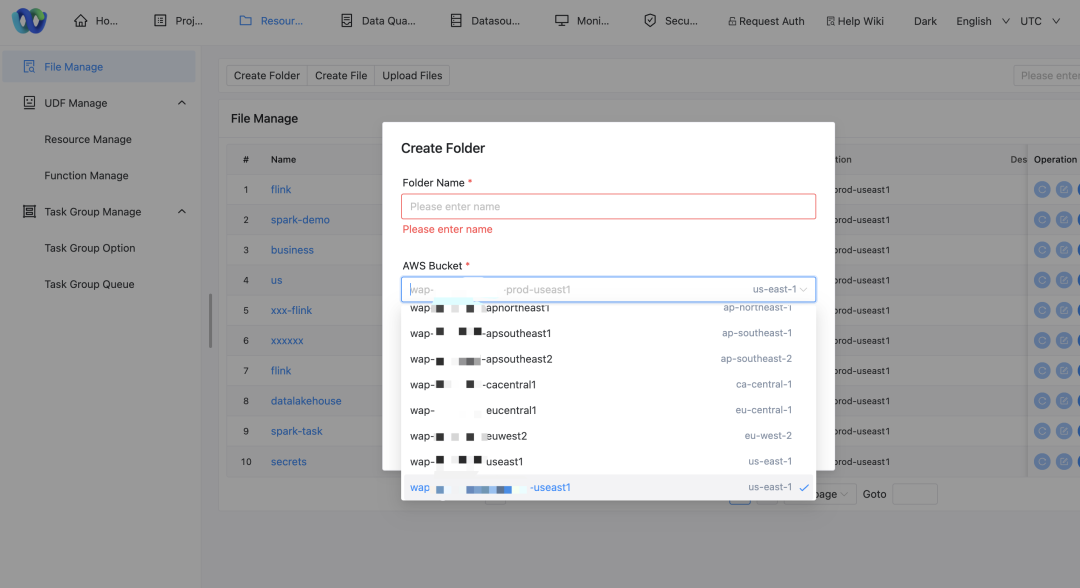
Pacchetti Jar e file di configurazione, ecc.: Utilizziamo Amazon S3 Bucket come centro di archiviazione delle risorse per archiviare il pacchetto Jar dell'utente e possibili file di configurazione dipendenti.
Gestione delle risorse di sicurezza: incluse le password del database, le informazioni sulla crittografia Kafka e le chiavi dipendenti dall'utente, ecc. Queste informazioni sensibili vengono archiviate nel servizio Vault di Cisco.
Accesso sicuro e gestione dei diritti
Per la necessità di accedere al bucket S3, dobbiamo configurare e gestire le credenziali AWS:
Configurazione dell'account IAM
Gestione delle credenziali: Utilizziamo account IAM per gestire l'accesso alle risorse AWS, comprese le chiavi di accesso e le chiavi segrete.
Integrazione K8: queste informazioni sulle credenziali vengono archiviate nel segreto Kubernetes e fanno riferimento al servizio Api per accedere in modo sicuro al bucket S3.
Controllo dei permessi e isolamento delle risorse: tramite gli account IAM, possiamo implementare un controllo capillare delle autorizzazioni per garantire la sicurezza dei dati e la conformità aziendale.
Problemi di scadenza e contromisure per le chiavi di accesso all'account IAM
Nel processo di utilizzo degli account IAM per gestire le risorse AWS, affrontiamo il problema della scadenza delle chiavi di accesso. Ecco ulteriori informazioni su come stiamo affrontando questa sfida.
Problema di scadenza della chiave di accesso
periodo chiave: la chiave AWS dell'account IAM è solitamente impostata per scadere automaticamente ogni 90 giorni, per migliorare la sicurezza del sistema.
impatto della missione: una volta scadute le chiavi, tutte le attività che si basano su queste chiavi per accedere alle risorse AWS non potranno essere eseguite, il che ci impone di aggiornare le chiavi in modo tempestivo per mantenere la continuità aziendale.
In risposta a questa situazione, impostiamo riavvii regolari per l'attività e impostiamo il monitoraggio corrispondente. Se si verifica un problema con l'account AWS prima della scadenza, dobbiamo avvisare i nostri sviluppatori corrispondenti di eseguire alcune elaborazioni.
Supporta AWS EKS
Man mano che la nostra attività si espande ad AWS EKS, dobbiamo apportare una serie di modifiche alla nostra architettura esistente e alle misure di sicurezza.
Ad esempio, come l'immagine Docker menzionata poco fa, l'abbiamo precedentemente inserita nel repository Docker di Cisco, quindi ora dobbiamo inserire l'immagine Docker su ECR.
Supporto di più bucket S3
A causa della natura decentralizzata dei cluster AWS e dei requisiti di isolamento dei dati di diverse aziende, dobbiamo supportare più bucket S3 per soddisfare le esigenze di storage dei dati di diversi cluster:
Corrispondenza tra cluster e bucket: ciascun cluster accederà al bucket S3 corrispondente per garantire la località e la conformità dei dati.
Modifica strategia: Dobbiamo adattare la nostra policy di accesso allo storage per supportare la lettura e la scrittura di dati da più bucket S3. Diverse parti aziendali devono accedere ai corrispondenti bucket S3.
Modifiche agli strumenti di gestione delle password
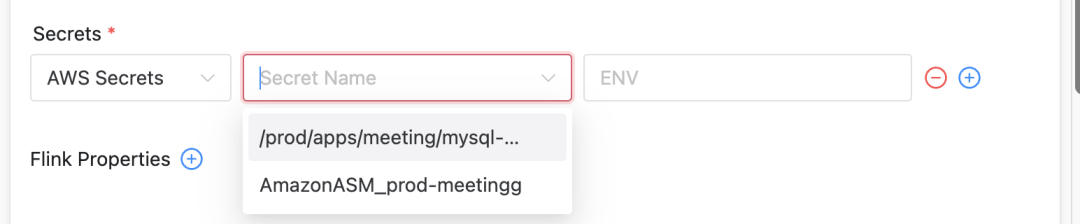
Per migliorare la sicurezza, siamo migrati dal servizio Vault autocostruito di Cisco a Secrets Manager (ASM) di AWS:
Utilizzo dell'ASM: ASM fornisce una soluzione più integrata per la gestione di password e chiavi per le risorse AWS.
Abbiamo adottato il metodo di utilizzo del ruolo IAM e dell'account di servizio per migliorare la sicurezza del pod:
Crea ruolo e policy IAM: creare innanzitutto un ruolo IAM e associarvi le policy necessarie per garantire che vengano concesse solo le autorizzazioni necessarie.
Associa l'account di servizio K8: quindi crea un account di servizio Kubernetes e associalo al ruolo IAM.
Integrazione dei permessi del pod: Quando si esegue un Pod, associandolo al Service Account, il Pod può ottenere le credenziali AWS richieste direttamente tramite il Ruolo IAM, accedendo così alle risorse AWS necessarie.
Queste modifiche non solo migliorano la scalabilità e la flessibilità del nostro sistema, ma rafforzano anche l'architettura di sicurezza complessiva per garantire che il funzionamento nell'ambiente AWS sia efficiente e sicuro. Allo stesso tempo, evita anche il precedente problema della scadenza automatica delle chiavi e della necessità di riavviare.
Ottimizzare la gestione delle risorse e i processi di archiviazione
Per semplificare il processo di distribuzione, prevediamo di inviare l'immagine Docker direttamente a ECR invece di passare attraverso un transito secondario:
spingere direttamente: modifica l'attuale processo di creazione del pacchetto in modo che l'immagine Docker venga inviata direttamente a ECR dopo essere stata creata, riducendo i ritardi temporali e i potenziali punti di errore.
Modificare l'implementazione
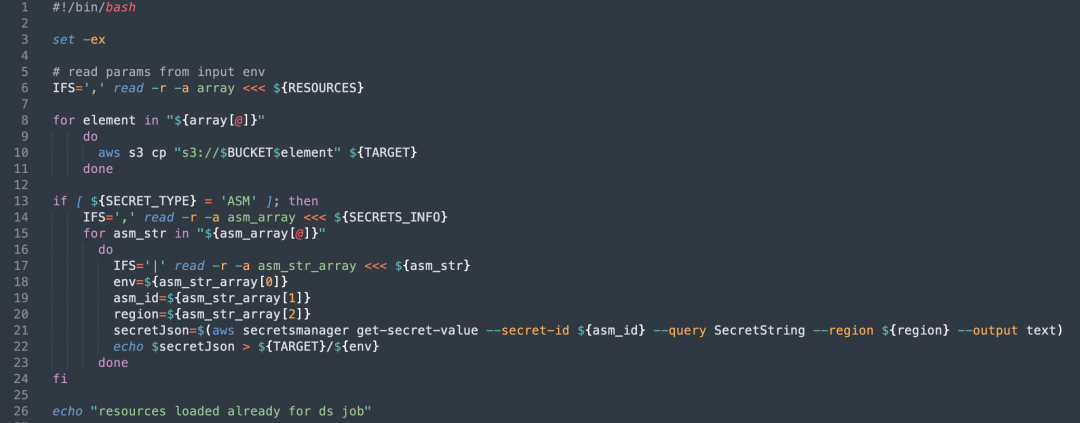
Aggiustamenti del livello di codice: Abbiamo modificato il codice DolphinScheduler per consentirgli di supportare più client S3 e aggiunto la gestione della cache per più client S3.
Aggiustamenti dell'interfaccia utente di gestione delle risorse: consente agli utenti di selezionare diversi nomi di bucket AWS per le operazioni tramite l'interfaccia.
accesso alle risorse: Il servizio Apache DolphinScheduler modificato ora può accedere a più bucket S3, consentendo una gestione flessibile dei dati tra diversi cluster AWS.
Gestione e isolamento dei permessi delle risorse AWS
Integrare AWS Secrets Manager (ASM)
Abbiamo esteso Apache DolphinScheduler per supportare AWS Secrets Manager, consentendo agli utenti di selezionare segreti tra diversi tipi di cluster:
Integrazione funzionale ASM
Miglioramenti dell'interfaccia utente: Nell'interfaccia utente di DolphinScheduler vengono aggiunte le funzioni di visualizzazione e selezione di diversi tipi di segreti.
Gestione automatica delle chiavi: associa il percorso del file che salva il segreto selezionato dall'utente alla variabile di ambiente effettiva del pod durante il runtime, garantendo l'utilizzo sicuro della chiave.
Servizio di configurazione e inizializzazione dinamica delle risorse (Init Container)
Per gestire e inizializzare le risorse AWS in modo più flessibile, abbiamo implementato un servizio chiamato Init Container:
Attrazione di risorse: Init Container estrarrà automaticamente le risorse S3 configurate dall'utente e le inserirà nella directory specificata prima dell'esecuzione del pod.
Gestione delle chiavi e della configurazione: in base alla configurazione, Init Container controllerà ed estrarrà le informazioni sulla password in ASM, quindi le memorizzerà in un file e le mapperà tramite variabili di ambiente per l'utilizzo da parte del Pod.
Applicazione di Terraform nella creazione e gestione delle risorse
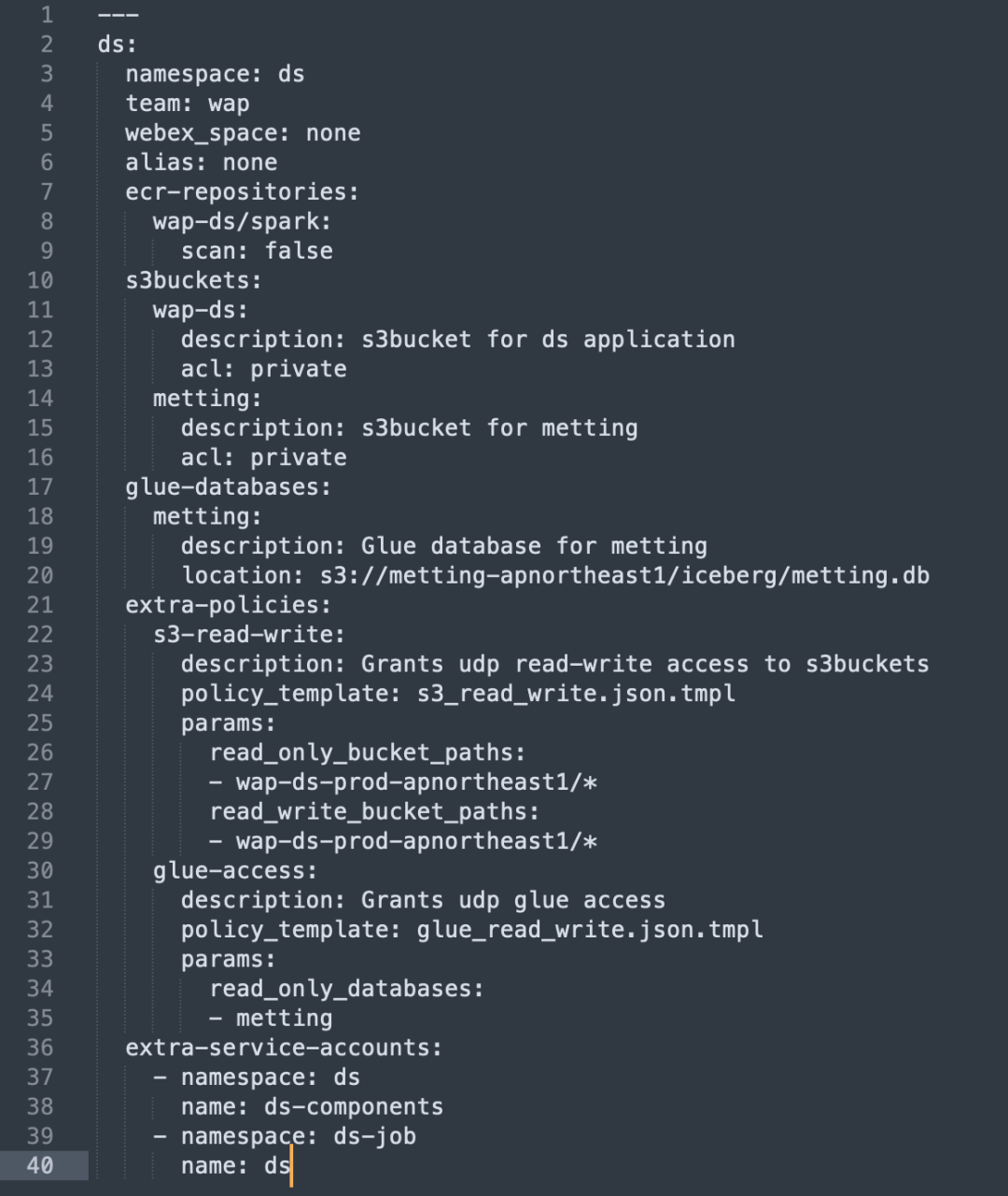
Abbiamo automatizzato il processo di configurazione e gestione delle risorse AWS tramite Terraform, semplificando l'allocazione delle risorse e le impostazioni delle autorizzazioni:
Configurazione automatica delle risorse: utilizza Terraform per creare le risorse AWS richieste come S3 Bucket ed ECR Repo.
Policy IAM e gestione dei ruoli: crea automaticamente policy e ruoli IAM per garantire che ogni unità aziendale abbia accesso su richiesta alle risorse di cui ha bisogno.
Isolamento e sicurezza dei permessi
Utilizziamo sofisticate strategie di isolamento dei permessi per garantire che diverse business unit operino in spazi dei nomi indipendenti, evitando conflitti di accesso alle risorse e rischi per la sicurezza:
Dettagli di implementazione
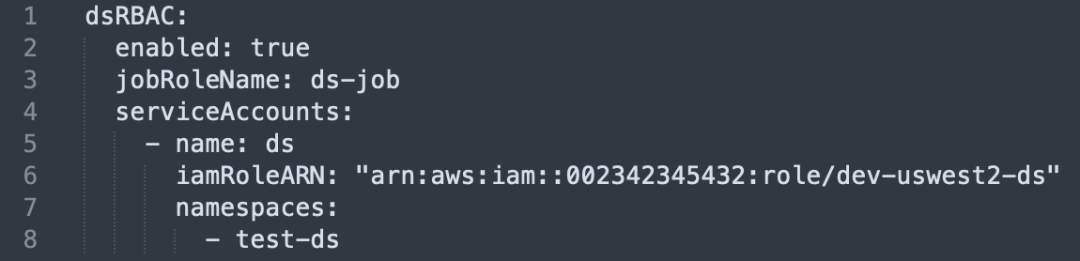
Creazione e associazione dell'account di servizio: crea un account di servizio indipendente per ciascuna business unit e associalo al ruolo IAM.
Isolamento dello spazio dei nomi: ciascuna operazione dell'account di servizio accede alle risorse AWS corrispondenti tramite il ruolo IAM all'interno dello spazio dei nomi specificato.
Miglioramenti nel supporto del cluster e nel controllo delle autorizzazioni
Estensioni di tipo cluster
Abbiamo aggiunto un nuovo campo cluster type, per supportare diversi tipi di cluster K8S, che non solo includono cluster Webex DC standard e cluster AWS EKS, ma supportano anche cluster specifici con requisiti di sicurezza più elevati:
Gestione del tipo di cluster
Campo del tipo di cluster:da Introdottocluster typecampi, possiamo facilmente gestire ed estendere il supporto per diversi cluster K8S.
Personalizzazione a livello di codice: per le esigenze specifiche di cluster specifici, possiamo apportare modifiche a livello di codice per garantire che i requisiti di sicurezza e configurazione siano soddisfatti durante l'esecuzione di lavori su questi cluster.
Sistema avanzato di controllo dei permessi (sistema Auth)
Abbiamo sviluppato il sistema di autenticazione appositamente per il controllo granulare dei permessi, inclusa la gestione dei permessi tra progetti, risorse e spazi dei nomi:
Funzione di gestione dei diritti
Autorizzazioni per progetti e risorse: gli utenti possono controllare le autorizzazioni tramite la dimensione del progetto. Una volta ottenute le autorizzazioni del progetto, hanno accesso a tutte le risorse del progetto.
controllo dei permessi dello spazio dei nomi: garantisce che un team specifico possa eseguire i processi del proprio progetto solo nello spazio dei nomi specificato, garantendo così l'esecuzione dell'isolamento delle risorse.
Ad esempio, il team A può eseguire solo determinati lavori di progetto nel proprio spazio dei nomi A. L'utente B, ad esempio, non può eseguire lavori nello spazio dei nomi dell'utente A.
Applicazione di gestione e autorizzazione delle risorse AWS
Utilizziamo il sistema Auth e altri strumenti per gestire le autorizzazioni e il controllo degli accessi alle risorse AWS, rendendo l'allocazione delle risorse più flessibile e sicura:
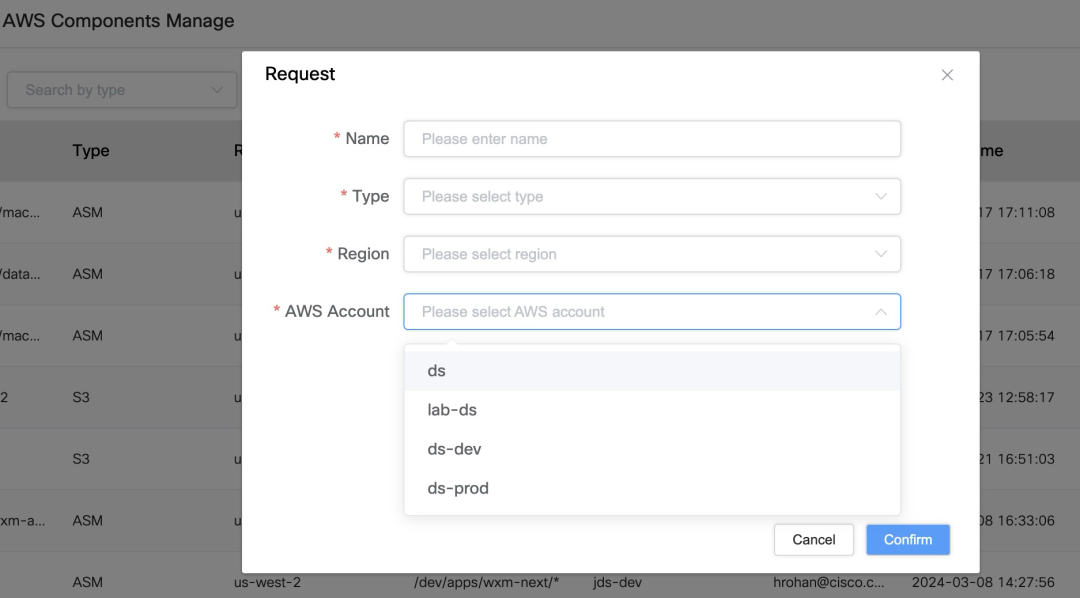
Supporto di più account AWS: nel sistema di autenticazione è possibile gestire più account AWS e associare diverse risorse AWS come bucket S3, ECR, ASM, ecc.
Mappatura delle risorse e applicazione dei permessi: gli utenti possono mappare le risorse AWS esistenti e richiedere autorizzazioni nel sistema, in modo da poter selezionare facilmente le risorse a cui devono accedere durante l'esecuzione di un lavoro.
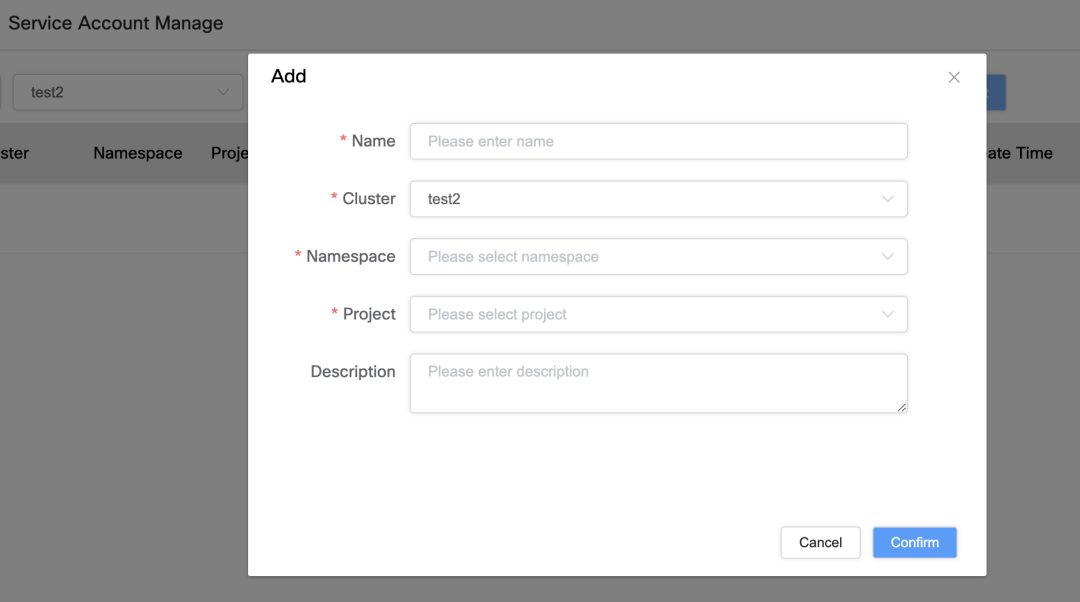
Gestione degli account di servizio e associazione dei permessi
Per poter gestire al meglio gli account di servizio e i relativi permessi, abbiamo implementato le seguenti funzionalità:
Associazione e gestione degli account di servizio
L'unica differenza tra Account di servizio: associa l'account di servizio tramite un cluster, uno spazio dei nomi e un nome di progetto specifici per garantirne l'unicità.
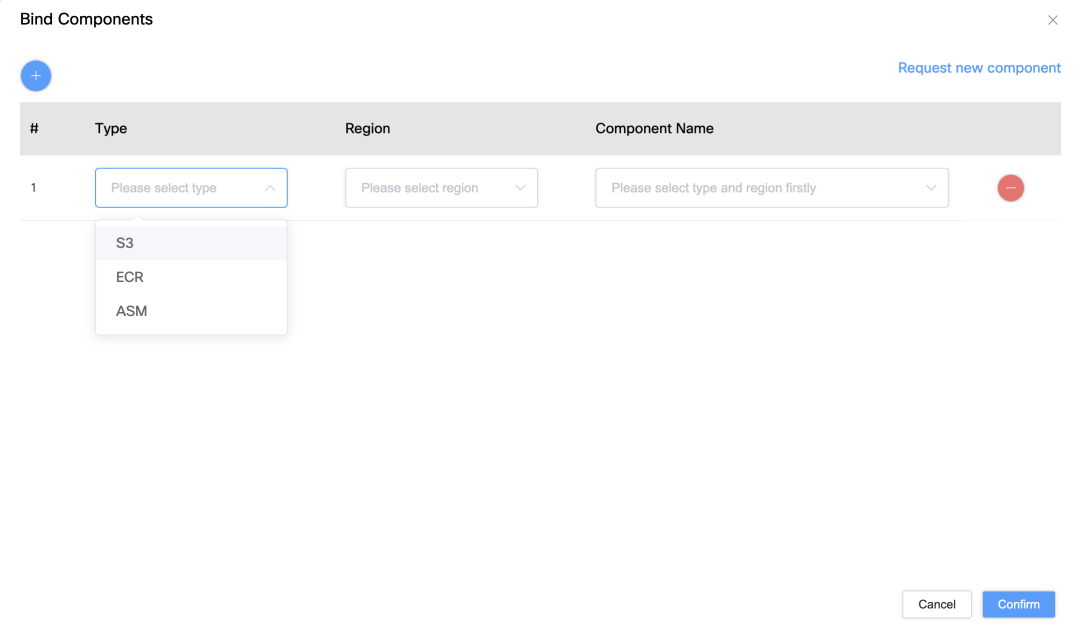
Interfaccia di associazione delle autorizzazioni: gli utenti possono associare l'account di servizio a risorse AWS specifiche, come S3, ASM o ECR, sull'interfaccia per ottenere un controllo preciso delle autorizzazioni.
Semplifica le operazioni e la sincronizzazione delle risorse
Ho appena detto molto, ma il funzionamento effettivo è relativamente semplice per gli utenti. L'intero processo di applicazione è in realtà un'attività una tantum. Per migliorare ulteriormente l'esperienza utente di Apache DolphinScheduler nell'ambiente AWS, abbiamo adottato una serie di misure per semplificare le procedure operative e migliorare le capacità di sincronizzazione delle risorse.
Lascia che te lo riassumo:
Interfaccia utente semplificata
In DolphinScheduler, gli utenti possono facilmente configurare il cluster e lo spazio dei nomi specifici in cui vengono eseguiti i loro lavori:
Selezione del cluster e dello spazio dei nomi
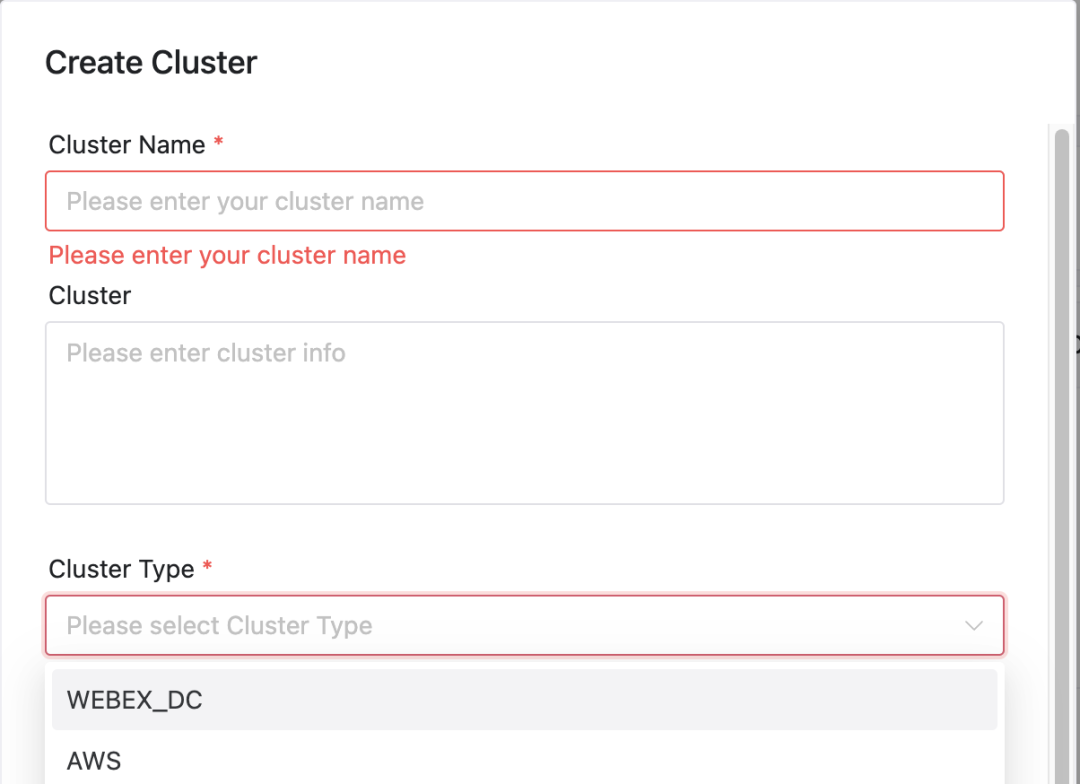
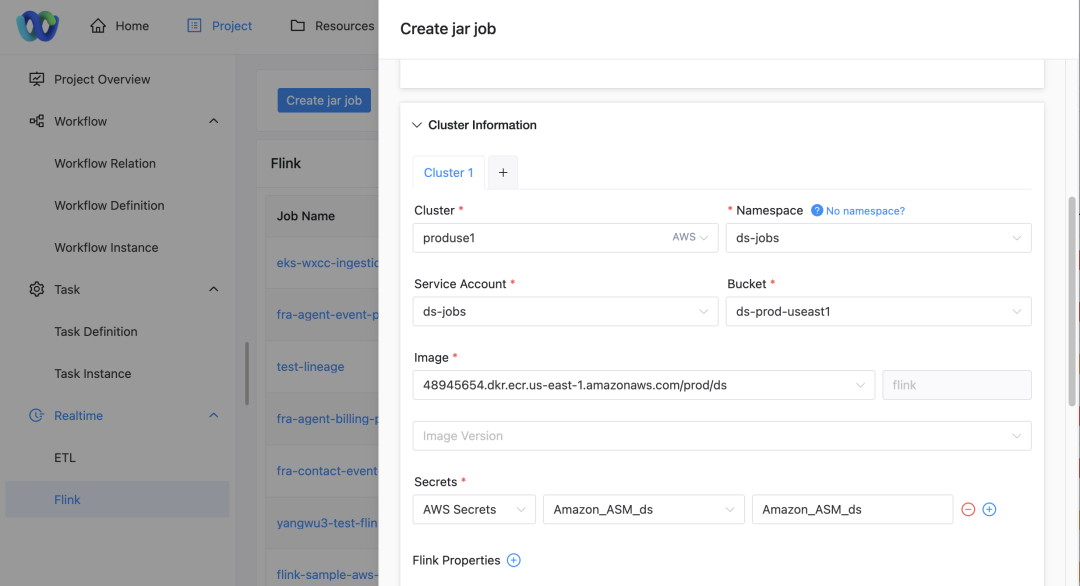
Selezione del cluster: quando inviano un lavoro, gli utenti possono selezionare il cluster su cui desiderano che venga eseguito il lavoro.
configurazione dello spazio dei nomi: a seconda del cluster selezionato, l'utente deve anche specificare lo spazio dei nomi in cui viene eseguito il lavoro.
Account di servizio e selezione delle risorse
Visualizzazione dell'account di servizio: la pagina visualizzerà automaticamente l'account di servizio corrispondente in base al progetto, al cluster e allo spazio dei nomi selezionati.
Configurazione dell'accesso alle risorse: gli utenti possono selezionare il bucket S3, l'indirizzo ECR e la chiave ASM associati all'account di servizio tramite l'elenco a discesa.
prospettiva futura
Per quanto riguarda il design attuale, ci sono ancora alcune aree che possono essere ottimizzate e migliorate per migliorare l'invio degli utenti e facilitare il funzionamento e la manutenzione:
Ottimizzazione del push delle immagini: valutare la possibilità di ignorare il processo di creazione del pacchetto di transito di Cisco e di inviare il pacchetto direttamente a ECR, in particolare per le modifiche dell'immagine specifiche di EKS.
Funzione di sincronizzazione con un clic: Abbiamo in programma di sviluppare una funzione di sincronizzazione con un clic che consenta agli utenti di caricare un pacchetto di risorse su un bucket S3 e selezionare la casella per sincronizzarlo automaticamente con altri bucket S3 per ridurre il lavoro di caricamenti ripetuti.
Mappa automaticamente al sistema di autenticazione: dopo aver creato le risorse AWS tramite Terraform, il sistema mapperà automaticamente queste risorse al sistema di gestione delle autorizzazioni per evitare che gli utenti inseriscano manualmente le risorse.
Ottimizzazione del controllo dei permessi: Attraverso la gestione automatizzata delle risorse e delle autorizzazioni, le operazioni degli utenti diventano più semplici, riducendo la complessità di configurazione e gestione.
Con questi miglioramenti, prevediamo di aiutare gli utenti a distribuire e gestire i propri lavori in modo più efficiente utilizzando Apache DolphinScheduler, sia su Webex DC che EKS, migliorando al contempo l'efficienza e la sicurezza della gestione delle risorse.