Li Qingwang - Engenheiro de Desenvolvimento de Software, Cisco
introdução
Olá a todos, meu nome é Li Qingwang, engenheiro de desenvolvimento de software da Cisco. Nossa equipe tem usado o Apache DolphinScheduler para construir nossa própria plataforma de agendamento de big data há quase três anos. Da versão inicial 2.0.3 até o presente, crescemos junto com a comunidade. As ideias técnicas compartilhadas com vocês hoje são desenvolvimentos secundários baseados na versão 3.1.1, adicionando alguns novos recursos não incluídos na versão da comunidade.
Hoje vou compartilhar como usamos o Apache DolphinScheduler para construir uma plataforma de big data e enviar e implantar nossas tarefas na AWS. Alguns desafios encontrados durante o processo e nossas soluções.
Projeto e ajuste de arquitetura
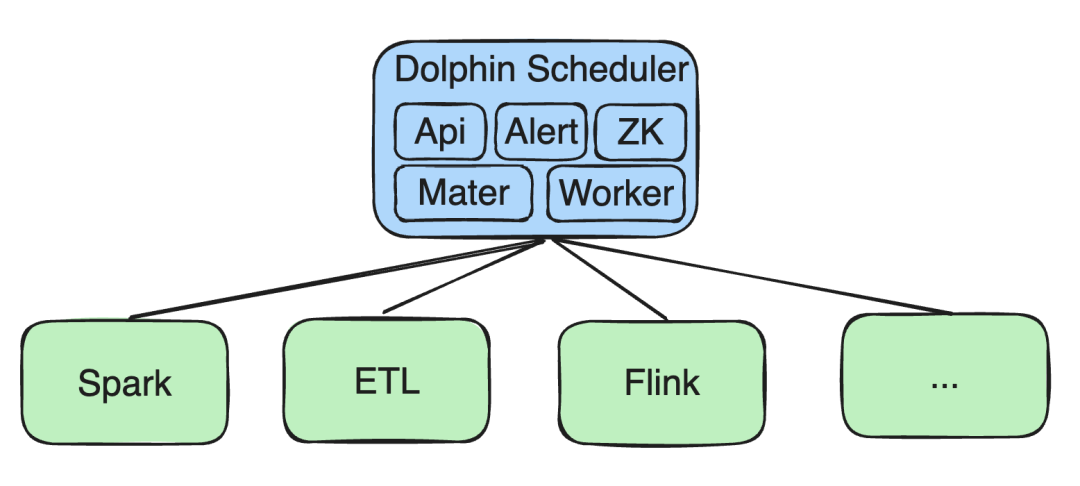
Inicialmente, todos os nossos serviços são implantados em Kubernetes (K8s), incluindo API, Alert e componentes como Zookeeper (ZK), Master e Worker.
Tarefas de processamento de big data
Conduzimos desenvolvimento secundário em tarefas como Spark, ETL e Flink:
Tarefas ETL: Nossa equipe desenvolveu uma ferramenta simples de arrastar e soltar por meio da qual os usuários podem gerar rapidamente tarefas ETL.
Suporte Spark : A versão inicial suportava apenas a execução do Spark no Yarn, e oferecemos suporte à execução no K8s por meio do desenvolvimento secundário. A versão mais recente da comunidade atualmente oferece suporte ao Spark em K8s.
*Desenvolvimento secundário Flink: Da mesma forma, adicionamos tarefas de streaming do Flink On K8s, bem como suporte para tarefas SQL e tarefas Python no K8s.
Trabalho de suporte na AWS
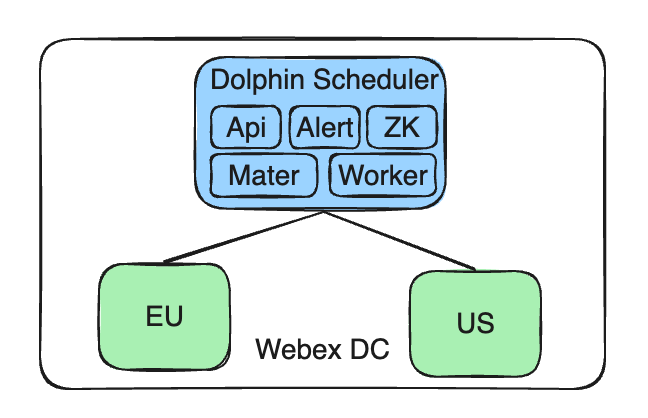
À medida que o negócio se expande e são necessárias políticas de dados, enfrentamos o desafio de ter de executar tarefas de dados em diferentes regiões. Isso exige que construamos uma arquitetura que possa suportar vários clusters. Abaixo está uma descrição detalhada de nossa solução e processo de implementação.
Nossa arquitetura atual consiste em um endpoint de controle centralizado, um único serviço Apache DolphinScheduler, que gerencia vários clusters. Estes clusters estão distribuídos em diferentes geografias, como a UE e os Estados Unidos, para cumprir as políticas de dados locais e os requisitos de isolamento.
Ajuste arquitetônico
Para atender a essa demanda, fizemos os seguintes ajustes:
Mantenha o serviço Apache DolphinScheduler gerenciado centralmente: Nosso serviço DolphinScheduler ainda é implantado no Cisco Webex DC autoconstruído, mantendo a centralização e a consistência do gerenciamento.
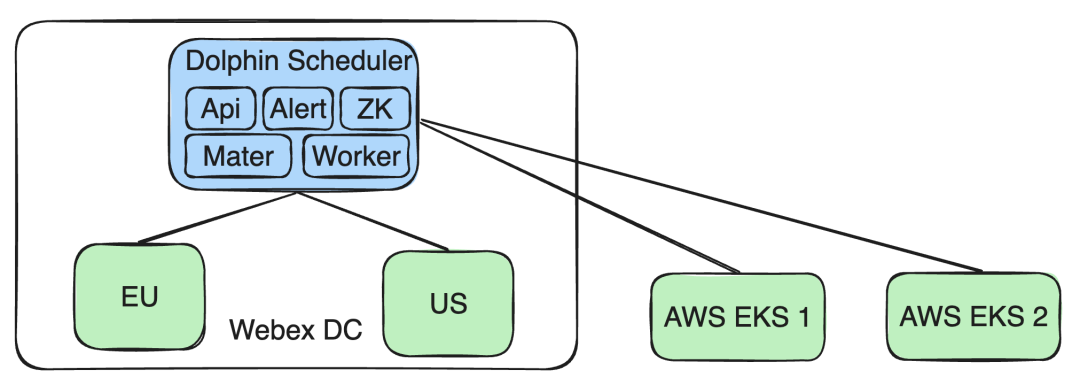
Suporte ao cluster AWS EKS : Ao mesmo tempo, expandimos os recursos de nossa arquitetura para oferecer suporte a vários clusters AWS EKS. Dessa forma, novos requisitos de negócios para tarefas em execução no cluster EKS podem ser atendidos sem afetar a operação e o isolamento de dados de outros clusters Webex DC.
Através deste design, podemos responder com flexibilidade a diferentes necessidades de negócios e desafios técnicos, garantindo ao mesmo tempo o isolamento dos dados e a conformidade com as políticas.
A seguir, apresentaremos como lidar com a implementação técnica e as dependências de recursos do Apache DolphinScheduler ao executar tarefas no Cisco Webex DC.
Dependências de recursos e armazenamento
Como todas as nossas tarefas são executadas em Kubernetes (K8s), é crucial:
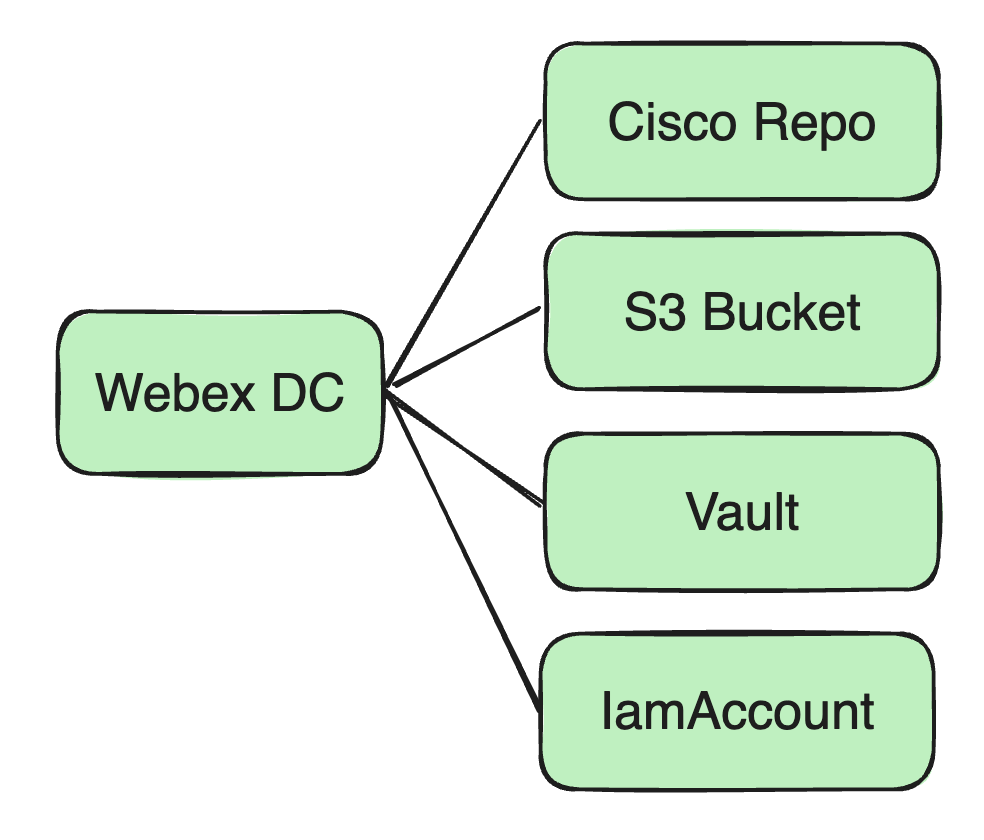
Imagem do Docker
local de armazenamento: Anteriormente, todas as nossas imagens Docker eram armazenadas em um repositório Docker na Cisco.
Gerenciamento de imagens: essas imagens fornecem o ambiente operacional e as dependências necessárias para os diversos serviços e tarefas que executamos.
Arquivos de recursos e dependências
Pacotes Jar e arquivos de configuração, etc.: usamos o Amazon S3 Bucket como centro de armazenamento de recursos para armazenar o pacote Jar do usuário e possíveis arquivos de configuração dependentes.
Gerenciamento de recursos de segurança: Incluindo senhas de banco de dados, informações de criptografia Kafka e chaves dependentes do usuário, etc. Essas informações confidenciais são armazenadas no serviço Vault da Cisco.
Acesso seguro e gerenciamento de direitos
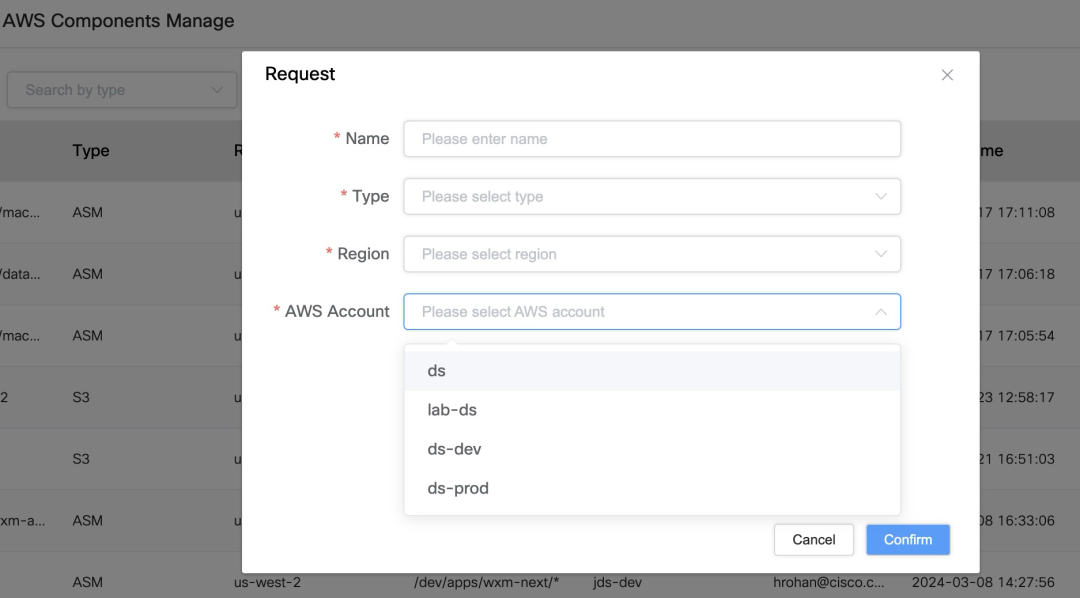
Para a necessidade de acessar o S3 Bucket, precisamos configurar e gerenciar as credenciais da AWS:
Configuração da conta IAM
Gerenciamento de credenciais: usamos contas IAM para gerenciar o acesso aos recursos da AWS, incluindo chaves de acesso e chaves secretas.
Integração K8s: essas informações de credenciais são armazenadas no segredo do Kubernetes e referenciadas pelo Api-Service para acessar com segurança o bucket S3.
Controle de permissão e isolamento de recursos: por meio de contas IAM, podemos implementar um controle de permissão refinado para garantir a segurança dos dados e a conformidade dos negócios.
Problemas de expiração e contramedidas para chaves de acesso à conta IAM
No processo de uso de contas IAM para gerenciar recursos da AWS, enfrentamos o problema de expiração da chave de acesso. Saiba mais sobre como estamos enfrentando esse desafio.
Problema de expiração da chave de acesso
período chave: a chave AWS da conta IAM geralmente é configurada para expirar automaticamente a cada 90 dias, o que aumenta a segurança do sistema.
impacto da missão: depois que as chaves expirarem, todas as tarefas que dependem dessas chaves para acessar os recursos da AWS não poderão ser executadas, o que exige que atualizemos as chaves em tempo hábil para manter a continuidade dos negócios.
Em resposta a esta situação, configuramos reinicializações regulares para a tarefa e configuramos o monitoramento correspondente. Se houver um problema com a conta AWS antes do prazo de expiração, precisaremos notificar nossos desenvolvedores correspondentes para fazer algum processamento.
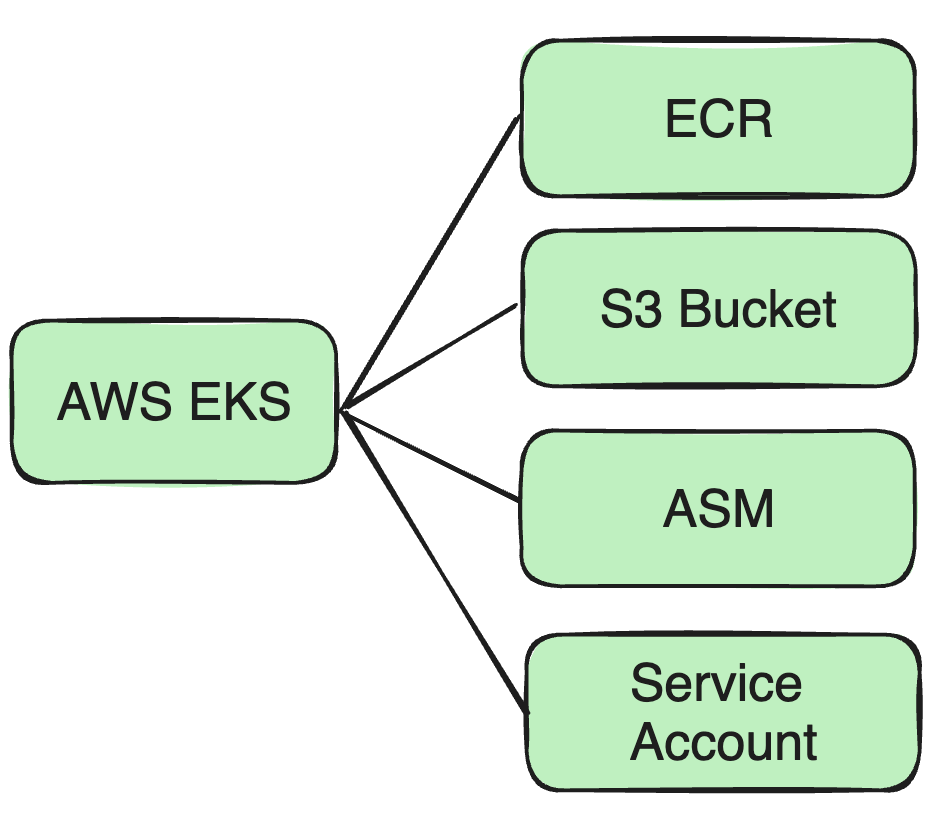
Suporte AWS EKS
À medida que nossos negócios se expandem para o AWS EKS, precisamos fazer uma série de ajustes em nossa arquitetura e medidas de segurança existentes.
Por exemplo, como a imagem Docker mencionada agora, nós a colocamos anteriormente no próprio repositório Docker da Cisco, então agora precisamos colocar a imagem Docker no ECR.
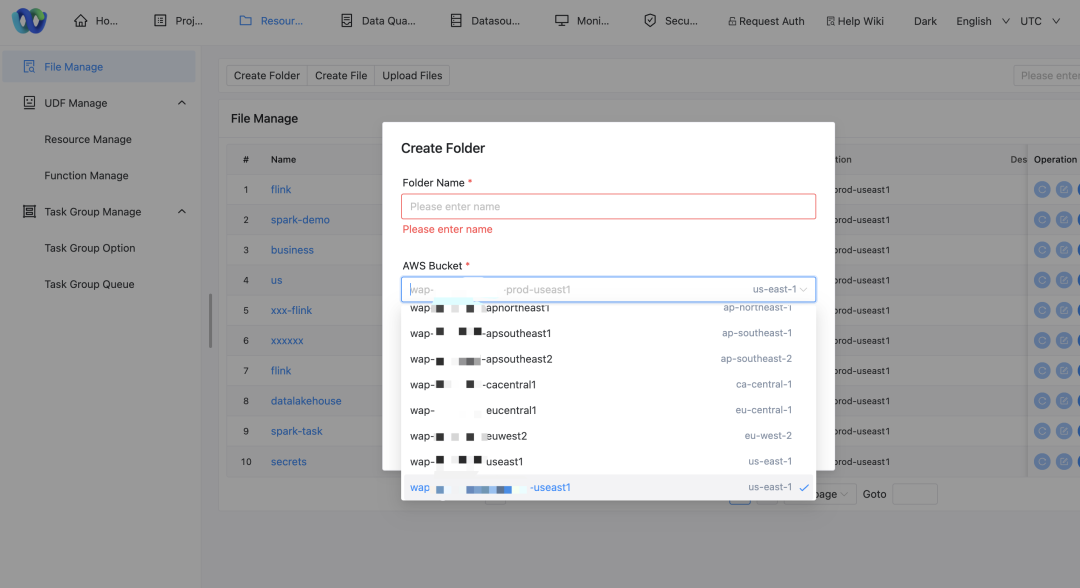
Suporte a vários buckets S3
Devido à natureza descentralizada dos clusters AWS e aos requisitos de isolamento de dados de diferentes empresas, precisamos oferecer suporte a vários buckets S3 para atender às necessidades de armazenamento de dados de diferentes clusters:
Correspondência entre cluster e bucket: cada cluster acessará seu bucket S3 correspondente para garantir a localidade e a conformidade dos dados.
Modificar estratégia: Precisamos ajustar nossa política de acesso ao armazenamento para oferecer suporte à leitura e gravação de dados de vários buckets S3. Diferentes partes de negócios precisam acessar seus buckets S3 correspondentes.
Mudanças nas ferramentas de gerenciamento de senhas
Para melhorar a segurança, migramos do serviço Vault autoconstruído da Cisco para o Secrets Manager (ASM) da AWS:
Uso de ASM: o ASM fornece uma solução mais integrada para gerenciar senhas e chaves para recursos da AWS.
Adotamos o método de usar função IAM e conta de serviço para aumentar a segurança do pod:
Criar função e política do IAM: primeiro crie uma função do IAM e vincule as políticas necessárias a ela para garantir que apenas as permissões necessárias sejam concedidas.
Vincular conta de serviço K8s: em seguida, crie uma conta de serviço Kubernetes e associe-a à função IAM.
Integração de permissão de pod: ao executar um pod, ao associá-lo à conta de serviço, o pod pode obter as credenciais necessárias da AWS diretamente por meio da função IAM, acessando assim os recursos necessários da AWS.
Esses ajustes não apenas melhoram a escalabilidade e a flexibilidade do nosso sistema, mas também fortalecem a arquitetura geral de segurança para garantir que a operação no ambiente AWS seja eficiente e segura. Ao mesmo tempo, também evita o problema anterior de expiração automática de chaves e necessidade de reinicialização.
Otimize os processos de gerenciamento e armazenamento de recursos
Para simplificar o processo de implantação, planejamos enviar a imagem do Docker diretamente para o ECR em vez de passar por um trânsito secundário:
empurre diretamente: modifique o processo de empacotamento atual para que a imagem do Docker seja enviada diretamente para o ECR após ser construída, reduzindo atrasos e possíveis pontos de erro.
Implementação de mudanças
Ajustes de nível de código: Modificamos o código DolphinScheduler para permitir que ele suporte vários clientes S3 e adicionamos gerenciamento de cache para vários S3Clients.
Ajustes na IU de gerenciamento de recursos: permite que os usuários selecionem diferentes nomes de AWS Buckets para operações por meio da interface.
acesso a recursos: o serviço Apache DolphinScheduler modificado agora pode acessar vários buckets S3, permitindo o gerenciamento flexível de dados entre diferentes clusters AWS.
Gerenciamento e isolamento de permissão de recursos AWS
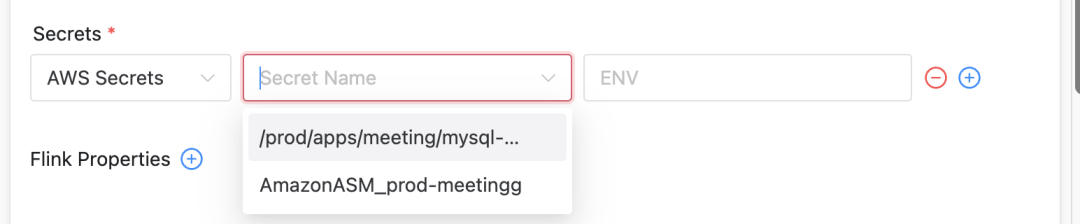
Integre o AWS Secrets Manager (ASM)
Estendemos o Apache DolphinScheduler para oferecer suporte ao AWS Secrets Manager, permitindo que os usuários selecionem segredos em diferentes tipos de cluster:
Integração funcional ASM
Melhorias na interface do usuário: Na interface do usuário do DolphinScheduler, são adicionadas as funções de exibição e seleção de diferentes tipos de segredo.
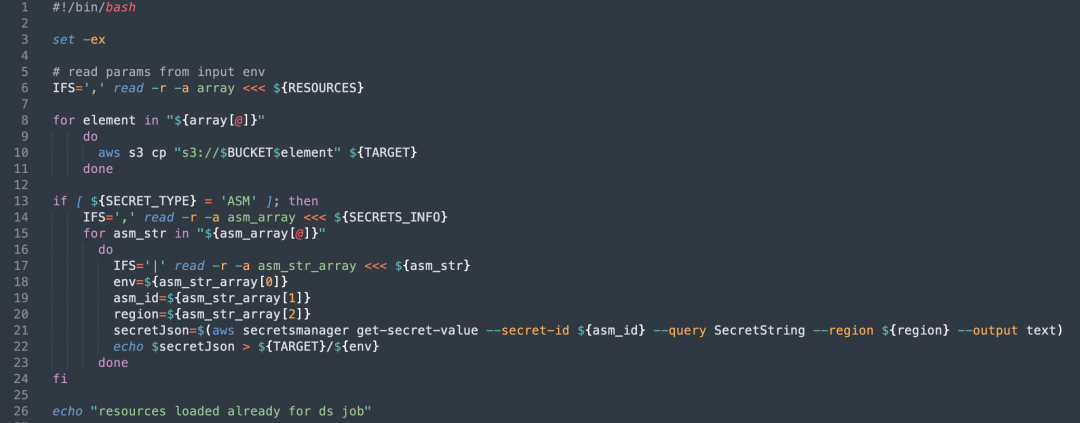
Gerenciamento automático de chaves: mapeia o caminho do arquivo que salva o segredo selecionado pelo usuário na variável de ambiente real do pod durante o tempo de execução, garantindo o uso seguro da chave.
Configuração dinâmica de recursos e serviço de inicialização (Init Container)
Para gerenciar e inicializar os recursos da AWS com mais flexibilidade, implementamos um serviço chamado Init Container:
Extração de recursos: o Init Container extrairá automaticamente os recursos S3 configurados pelo usuário e os colocará no diretório especificado antes que o pod seja executado.
Gerenciamento de chaves e configurações: De acordo com a configuração, o Init Container irá verificar e extrair as informações de senha no ASM, depois armazená-las em um arquivo e mapeá-las através de variáveis de ambiente para uso pelo Pod.
Aplicação do Terraform na criação e gerenciamento de recursos
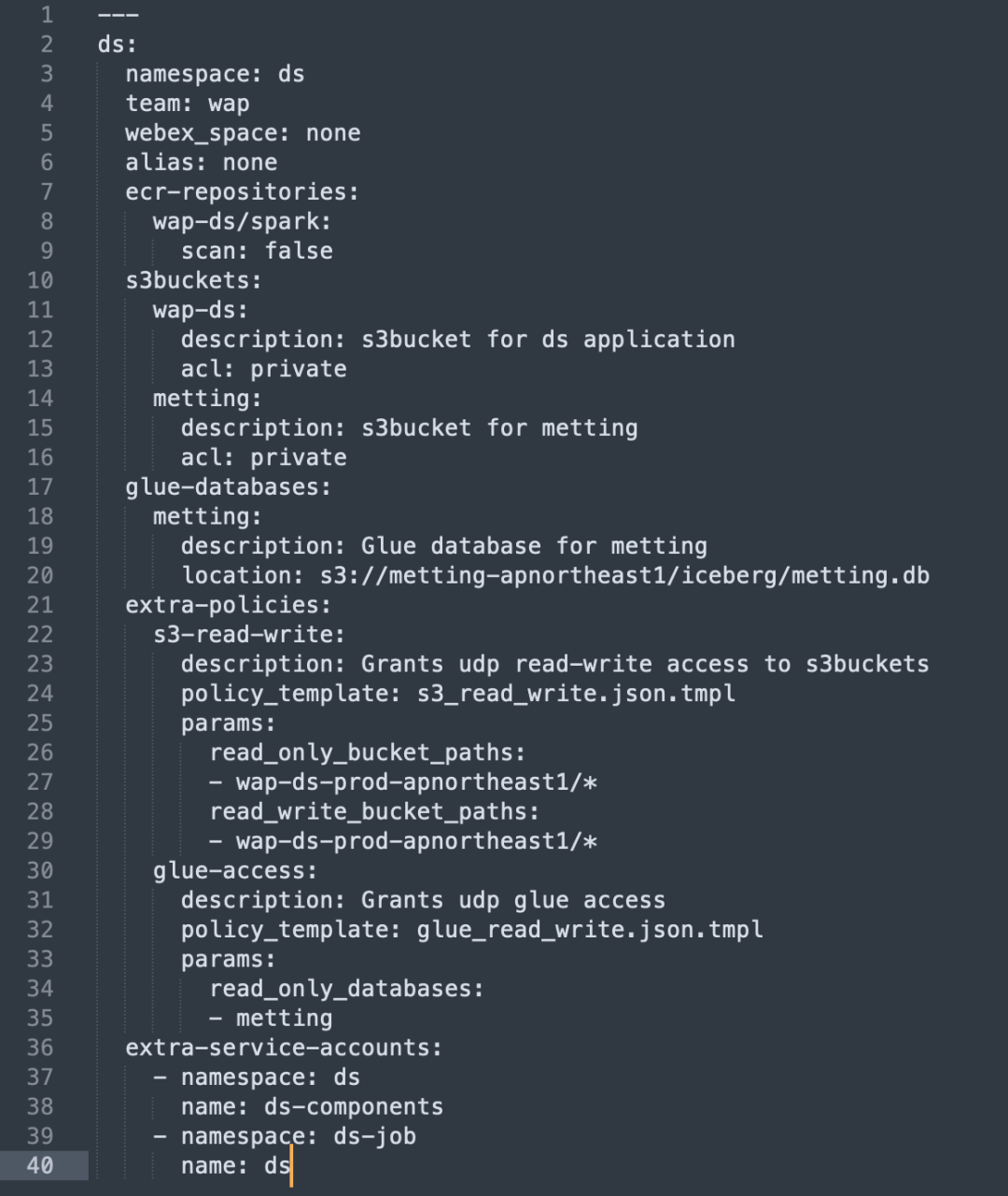
Automatizamos o processo de configuração e gerenciamento de recursos da AWS por meio do Terraform, simplificando a alocação de recursos e as configurações de permissão:
Configuração automática de recursos: use o Terraform para criar os recursos necessários da AWS, como S3 Bucket e ECR Repo.
Política de IAM e gerenciamento de funções: crie automaticamente políticas e funções de IAM para garantir que cada unidade de negócios tenha acesso sob demanda aos recursos necessários.
Isolamento de permissão e segurança
Utilizamos estratégias sofisticadas de isolamento de permissões para garantir que diferentes unidades de negócios operem em namespaces independentes, evitando conflitos de acesso a recursos e riscos de segurança:
Detalhes de implementação
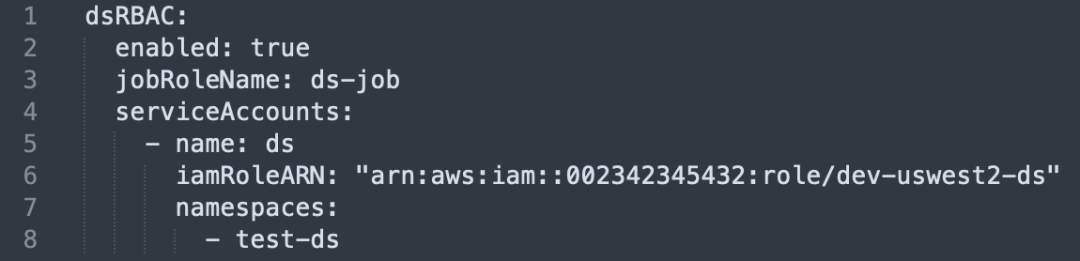
Criação e vinculação de conta de serviço: crie uma conta de serviço independente para cada unidade de negócios e vincule-a à função do IAM.
Isolamento de namespace: cada operação de conta de serviço acessa seus recursos correspondentes da AWS por meio da função do IAM no namespace especificado.
Melhorias no suporte de cluster e controle de permissão
Extensões de tipo de cluster
Adicionamos um novo campo cluster type, para oferecer suporte a diferentes tipos de clusters K8S, que não incluem apenas clusters Webex DC padrão e clusters AWS EKS, mas também oferecem suporte a clusters específicos com requisitos de segurança mais elevados:
Gerenciamento de tipo de cluster
Campo de tipo de cluster:por Introduzidocluster typecampos, podemos gerenciar e estender facilmente o suporte para diferentes clusters K8S.
Personalização em nível de código: com base nas necessidades exclusivas de clusters específicos, podemos fazer modificações no nível do código para garantir que os requisitos de segurança e configuração sejam atendidos ao executar trabalhos nesses clusters.
Sistema aprimorado de controle de permissão (sistema Auth)
Desenvolvemos o sistema Auth especificamente para controle detalhado de permissões, incluindo gerenciamento de permissões entre projetos, recursos e namespaces:
Função de gerenciamento de direitos
Permissões de projetos e recursos: os usuários podem controlar as permissões por meio da dimensão do projeto. Assim que tiverem permissões do projeto, eles terão acesso a todos os recursos do projeto.
controle de permissão de namespace: certifique-se de que uma equipe específica só possa executar os trabalhos de seu projeto no namespace especificado, garantindo assim o isolamento de recursos em execução.
Por exemplo, a equipe A só pode executar determinados trabalhos de projeto em seu namespace A. O usuário B, por exemplo, não pode executar trabalhos no namespace do usuário A.
Gerenciamento de recursos AWS e aplicativo de permissão
Utilizamos o sistema Auth e outras ferramentas para gerenciar permissões e controle de acesso aos recursos da AWS, tornando a alocação de recursos mais flexível e segura:
Suporte a múltiplas contas AWS: No sistema Auth, você pode gerenciar várias contas AWS e vincular diferentes recursos AWS, como S3 Bucket, ECR, ASM, etc.
Mapeamento de recursos e aplicativo de permissão: os usuários podem mapear recursos existentes da AWS e solicitar permissões no sistema, para que possam selecionar facilmente os recursos que precisam acessar ao executar um trabalho.
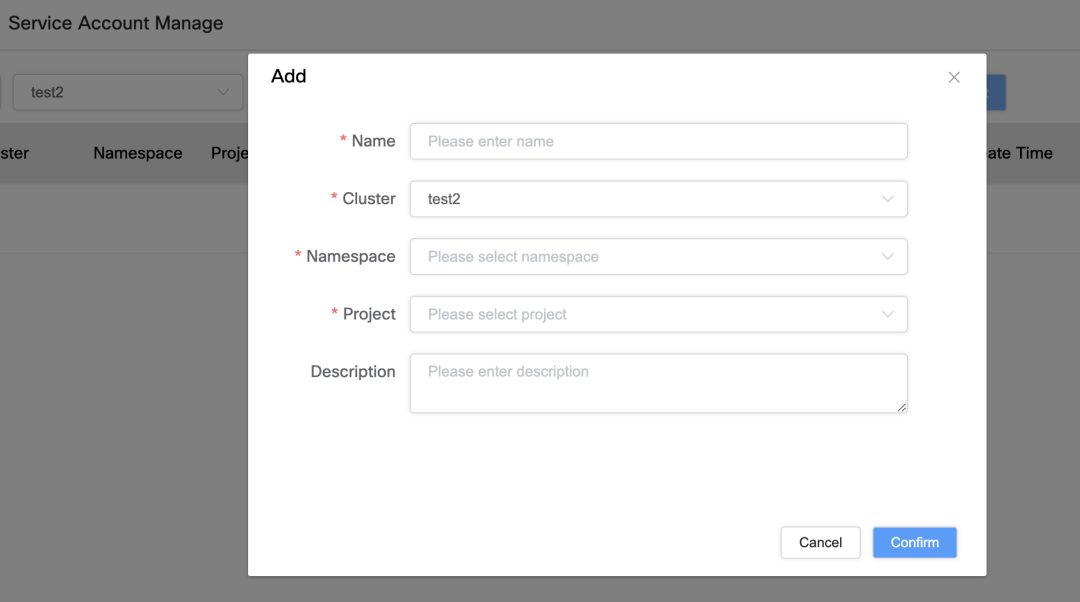
Gerenciamento de conta de serviço e vinculação de permissão
Para gerenciar melhor as contas de serviço e suas permissões, implementamos as seguintes funções:
Vinculação e gerenciamento de conta de serviço
A única diferença entre conta de serviço: vincule a conta de serviço por meio de um cluster, namespace e nome de projeto específicos para garantir sua exclusividade.
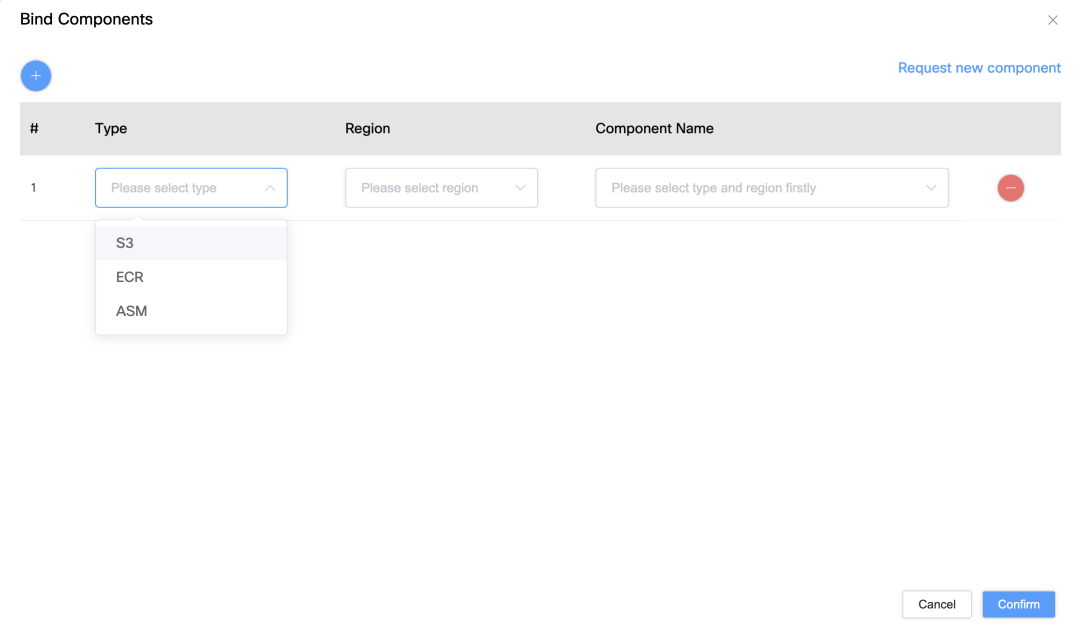
Interface de vinculação de permissão: os usuários podem vincular a conta de serviço a recursos específicos da AWS, como S3, ASM ou ECR, na interface para obter controle preciso de permissões.
Simplifique as operações e a sincronização de recursos
Acabei de dizer muito, mas a operação real é relativamente simples para os usuários. Todo o processo de aplicação é, na verdade, uma tarefa única. Para melhorar ainda mais a experiência do usuário do Apache DolphinScheduler no ambiente AWS, realizamos uma série de. medidas para simplificar os procedimentos operacionais e melhorar as capacidades de sincronização de recursos.
Deixe-me resumir para você:
Interface de usuário simplificada
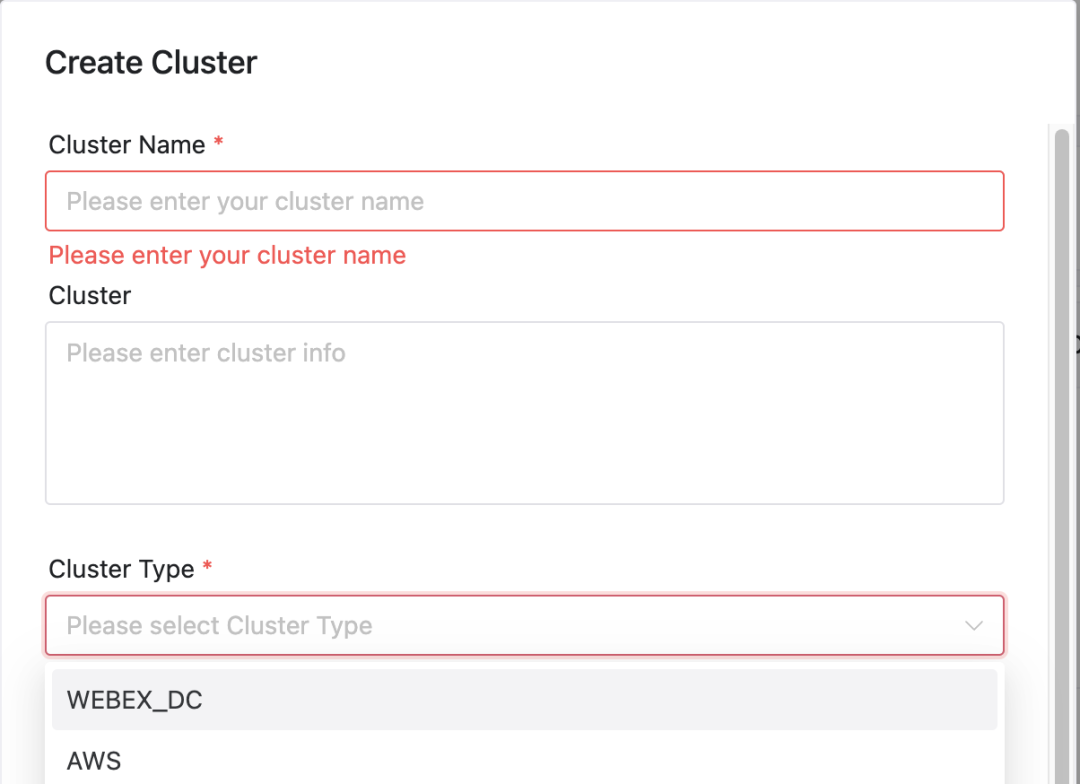
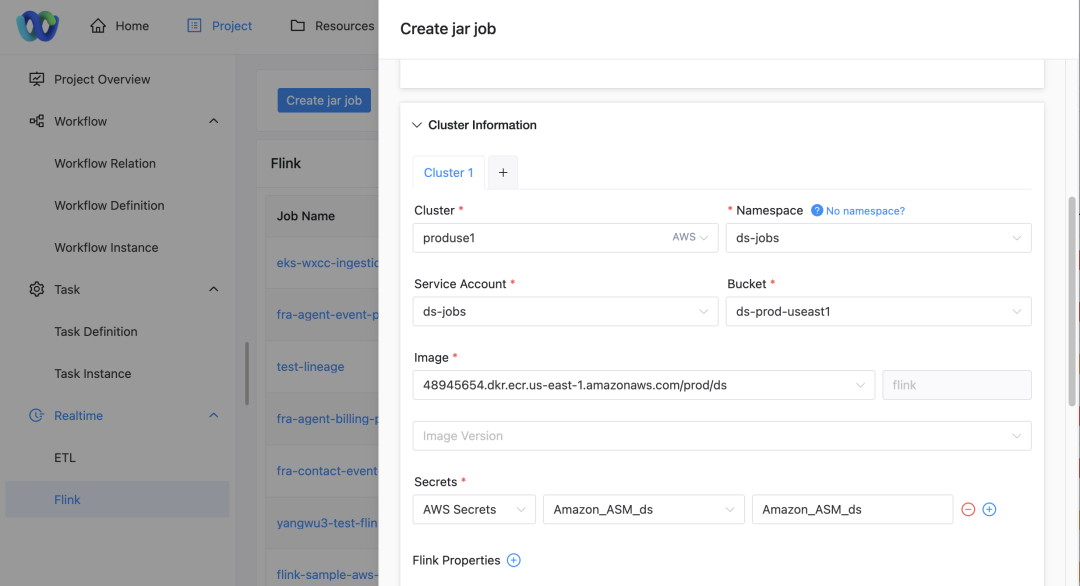
No DolphinScheduler, os usuários podem configurar facilmente o cluster e o namespace específicos nos quais seus trabalhos são executados:
Seleção de cluster e namespace
Seleção de cluster: ao enviar um trabalho, os usuários podem selecionar o cluster no qual desejam que o trabalho seja executado.
configuração de namespace: dependendo do cluster selecionado, o usuário também precisa especificar o namespace no qual a tarefa é executada.
Conta de serviço e seleção de recursos
Exibição da conta de serviço: a página exibirá automaticamente a conta de serviço correspondente com base no projeto, cluster e namespace selecionados.
Configuração de acesso a recursos: os usuários podem selecionar o bucket S3, o endereço ECR e a chave ASM associados à conta de serviço por meio da lista suspensa.
perspectiva futura
Relativamente ao design atual, ainda existem algumas áreas que podem ser otimizadas e melhoradas para melhorar a submissão ao utilizador e facilitar a operação e manutenção:
Otimização de envio de imagem: considere ignorar o processo de empacotamento de trânsito da Cisco e enviar o pacote diretamente para o ECR, especialmente para modificações de imagem específicas do EKS.
Função de sincronização com um clique: planejamos desenvolver uma função de sincronização com um clique que permita aos usuários fazer upload de um pacote de recursos para um bucket S3 e marcar a caixa para sincronizá-lo automaticamente com outros buckets S3 para reduzir o trabalho de uploads repetidos.
Mapear automaticamente para o sistema Auth: depois que os recursos AWS forem criados por meio do Terraform, o sistema mapeará automaticamente esses recursos para o sistema de gerenciamento de permissões para evitar que os usuários insiram recursos manualmente.
Otimização do controle de permissão: por meio do gerenciamento automatizado de recursos e permissões, as operações do usuário se tornam mais simples, reduzindo a complexidade de configuração e gerenciamento.
Com essas melhorias, esperamos ajudar os usuários a implantar e gerenciar seus trabalhos de forma mais eficiente usando o Apache DolphinScheduler, seja no Webex DC ou no EKS, ao mesmo tempo que melhora a eficiência e a segurança do gerenciamento de recursos.