Li Qing Wang - Ingeniero de desarrollo de software, Cisco
introducción
Hola a todos, mi nombre es Li Qingwang, ingeniero de desarrollo de software de Cisco. Nuestro equipo ha estado utilizando Apache DolphinScheduler para crear nuestra propia plataforma de programación de big data durante casi tres años. Desde la versión inicial 2.0.3 hasta la actualidad, hemos crecido junto con la comunidad. Las ideas técnicas compartidas con ustedes hoy son desarrollos secundarios basados en la versión 3.1.1, agregando algunas características nuevas no incluidas en la versión comunitaria.
Hoy, compartiré cómo usamos Apache DolphinScheduler para construir una plataforma de big data y enviar e implementar nuestras tareas en AWS. Algunos desafíos encontrados durante el proceso y nuestras soluciones.
Diseño y ajuste de arquitectura.
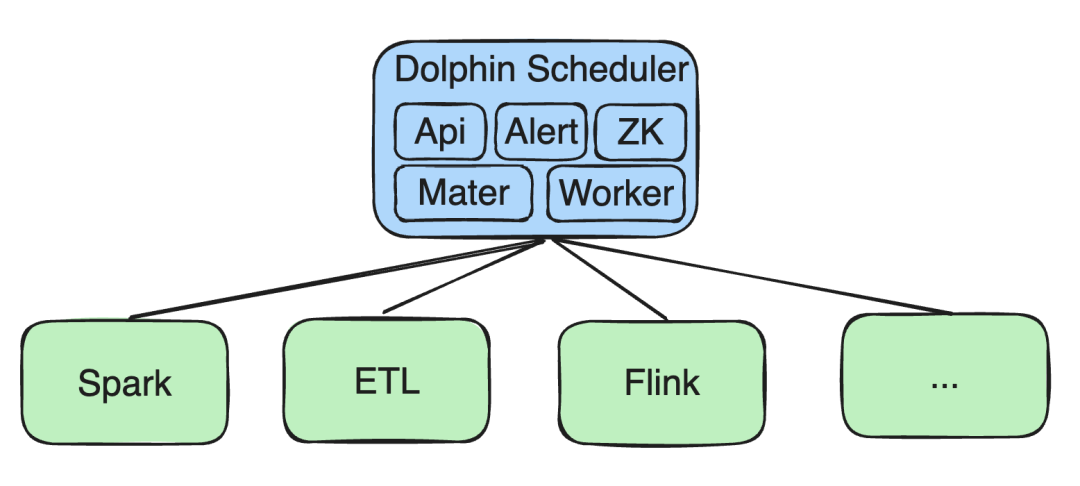
Inicialmente, todos nuestros servicios se implementan en Kubernetes (K8), incluidos API, Alert y componentes como Zookeeper (ZK), Master y Worker.
Tareas de procesamiento de big data
Hemos realizado desarrollo secundario en tareas como Spark, ETL y Flink:
Tareas ETL: Nuestro equipo ha desarrollado una herramienta sencilla de arrastrar y soltar a través de la cual los usuarios pueden generar rápidamente tareas ETL.
Soporte de chispa : La versión anterior solo admitía la ejecución de Spark en Yarn, y lo hicimos compatible con la ejecución en K8 a través del desarrollo secundario. La última versión de la comunidad actualmente admite Spark en K8.
*Desarrollo secundario de Flink: De manera similar, hemos agregado tareas de transmisión de Flink en K8, así como soporte para tareas de SQL y tareas de Python en K8.
Trabajo de soporte en AWS
A medida que el negocio se expande y se requieren políticas de datos, nos enfrentamos al desafío de tener que ejecutar tareas de datos en diferentes regiones. Esto requiere que construyamos una arquitectura que pueda admitir múltiples clústeres. A continuación se muestra una descripción detallada de nuestra solución y proceso de implementación.
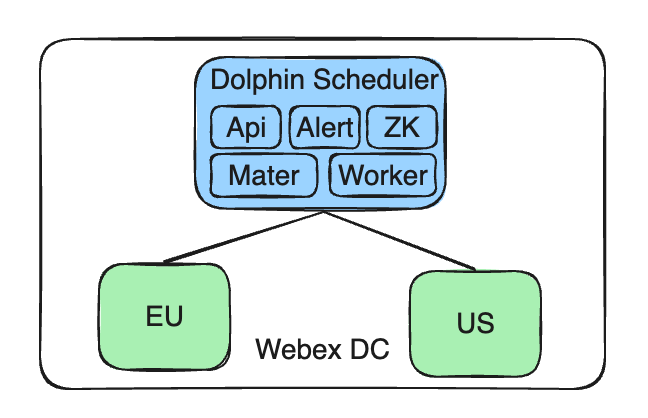
Nuestra arquitectura actual consta de un punto final de control centralizado, un único servicio Apache DolphinScheduler, que gestiona múltiples clústeres. Estos clústeres están distribuidos en diferentes geografías, como la UE y Estados Unidos, para cumplir con las políticas de datos locales y los requisitos de aislamiento.
Ajuste arquitectónico
Para satisfacer esta demanda, hemos realizado los siguientes ajustes:
Mantenga el servicio Apache DolphinScheduler administrado de forma centralizada: Nuestro servicio DolphinScheduler todavía está implementado en Cisco Webex DC de construcción propia, lo que mantiene la centralización y la coherencia de la administración.
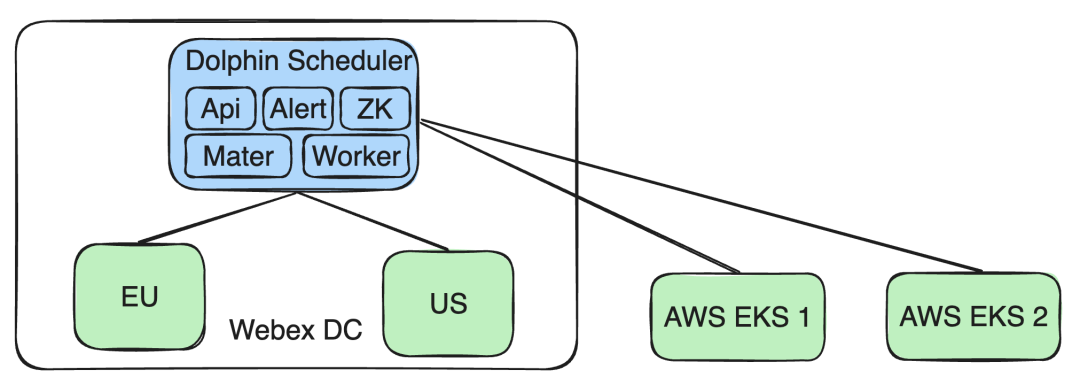
Admite el clúster AWS EKS : Al mismo tiempo, ampliamos las capacidades de nuestra arquitectura para admitir múltiples clústeres de AWS EKS. De esta manera, se pueden cumplir los nuevos requisitos comerciales para las tareas que se ejecutan en el clúster EKS sin afectar la operación y el aislamiento de datos de otros clústeres de Webex DC.
A través de este diseño, podemos responder de manera flexible a diferentes necesidades comerciales y desafíos técnicos, al tiempo que garantizamos el aislamiento de los datos y el cumplimiento de las políticas.
A continuación, presentaremos cómo manejar la implementación técnica y las dependencias de recursos de Apache DolphinScheduler al ejecutar tareas en Cisco Webex DC.
Dependencias de recursos y almacenamiento.
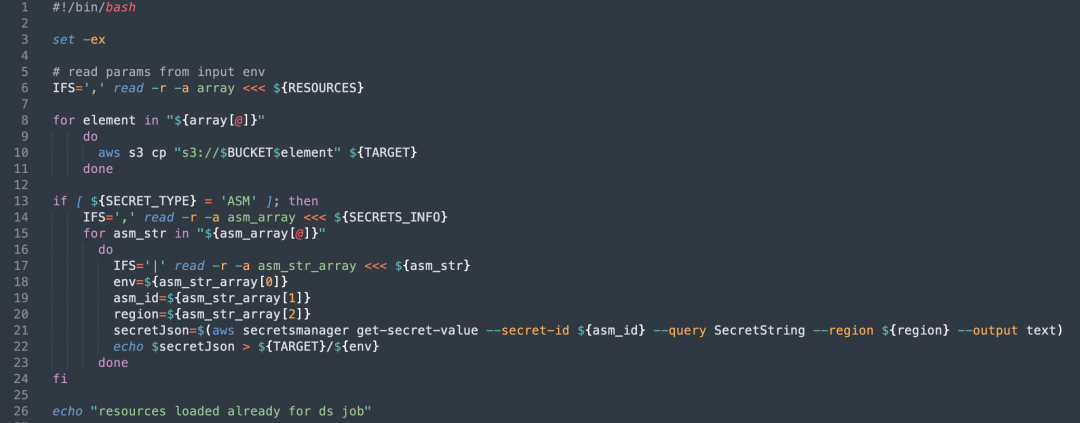
Dado que todas nuestras tareas se ejecutan en Kubernetes (K8), es fundamental para nosotros:
imagen acoplable
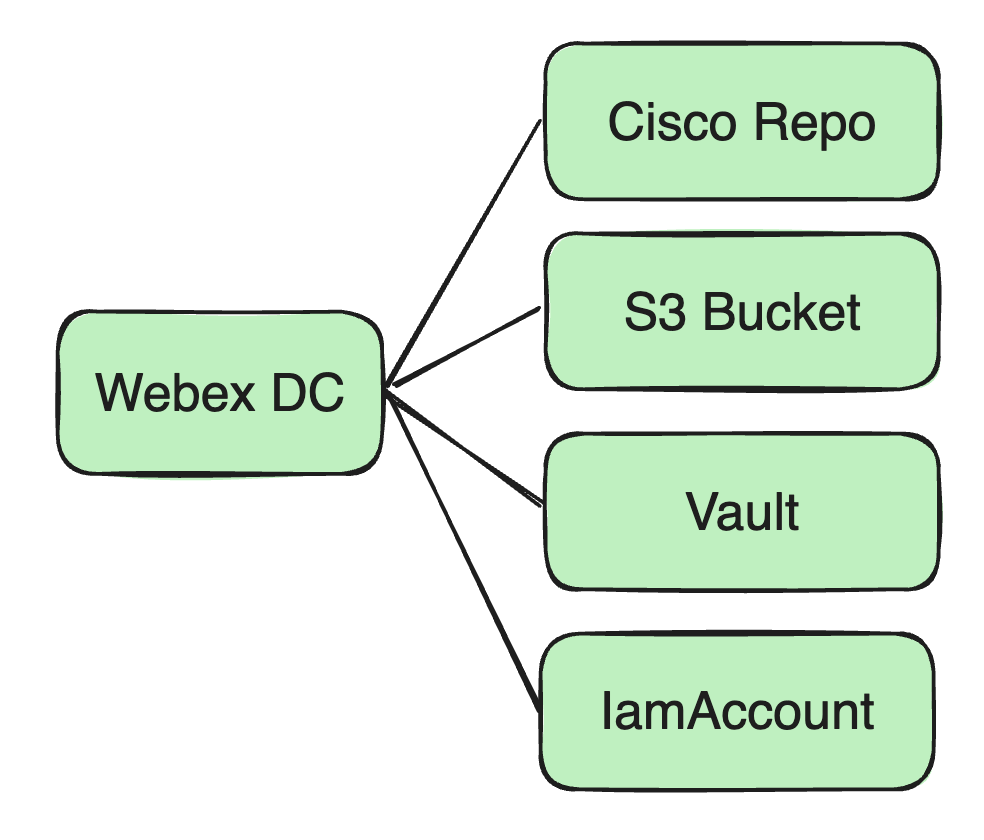
ubicación de almacenamiento: Anteriormente, todas nuestras imágenes de Docker se almacenaban en un repositorio de Docker en Cisco.
Gestión de imágenes: Estas imágenes proporcionan el entorno operativo y las dependencias necesarias para los diversos servicios y tareas que ejecutamos.
Archivos de recursos y dependencias.
Paquetes jar y archivos de configuración, etc.: Utilizamos Amazon S3 Bucket como centro de almacenamiento de recursos para almacenar el paquete Jar del usuario y los posibles archivos de configuración dependientes.
Gestión de recursos de seguridad: Incluyendo contraseñas de bases de datos, información de cifrado Kafka y claves dependientes del usuario, etc. Esta información confidencial se almacena en el servicio Vault de Cisco.
Acceso seguro y gestión de derechos
Para necesitar acceder a S3 Bucket, necesitamos configurar y administrar las credenciales de AWS:
Configuración de la cuenta IAM
Gestión de credenciales: Utilizamos cuentas de IAM para administrar el acceso a los recursos de AWS, incluidas las claves de acceso y las claves secretas.
integración de K8: Esta información de credenciales se almacena en Kubernetes Secret y el servicio Api hace referencia a ella para acceder de forma segura al depósito S3.
Control de permisos y aislamiento de recursos.: A través de cuentas de IAM, podemos implementar un control de permisos detallado para garantizar la seguridad de los datos y el cumplimiento empresarial.
Problemas de caducidad y contramedidas para las claves de acceso a cuentas de IAM
En el proceso de utilizar cuentas de IAM para administrar recursos de AWS, nos enfrentamos al problema de la caducidad de la clave de acceso. Aquí encontrará más información sobre cómo estamos abordando este desafío.
Problema de caducidad de la clave de acceso
periodo clave: La clave AWS de la cuenta IAM generalmente está configurada para que caduque automáticamente cada 90 días, lo que mejora la seguridad del sistema.
impacto de la misión: Una vez que las claves caduquen, todas las tareas que dependen de estas claves para acceder a los recursos de AWS no podrán realizarse, lo que requiere que actualicemos las claves de manera oportuna para mantener la continuidad del negocio.
En respuesta a esta situación, configuramos reinicios regulares para la tarea y configuramos el monitoreo correspondiente. Si hay un problema con la cuenta de AWS antes del tiempo de vencimiento, debemos notificar a nuestros desarrolladores correspondientes para que realicen algún procesamiento.
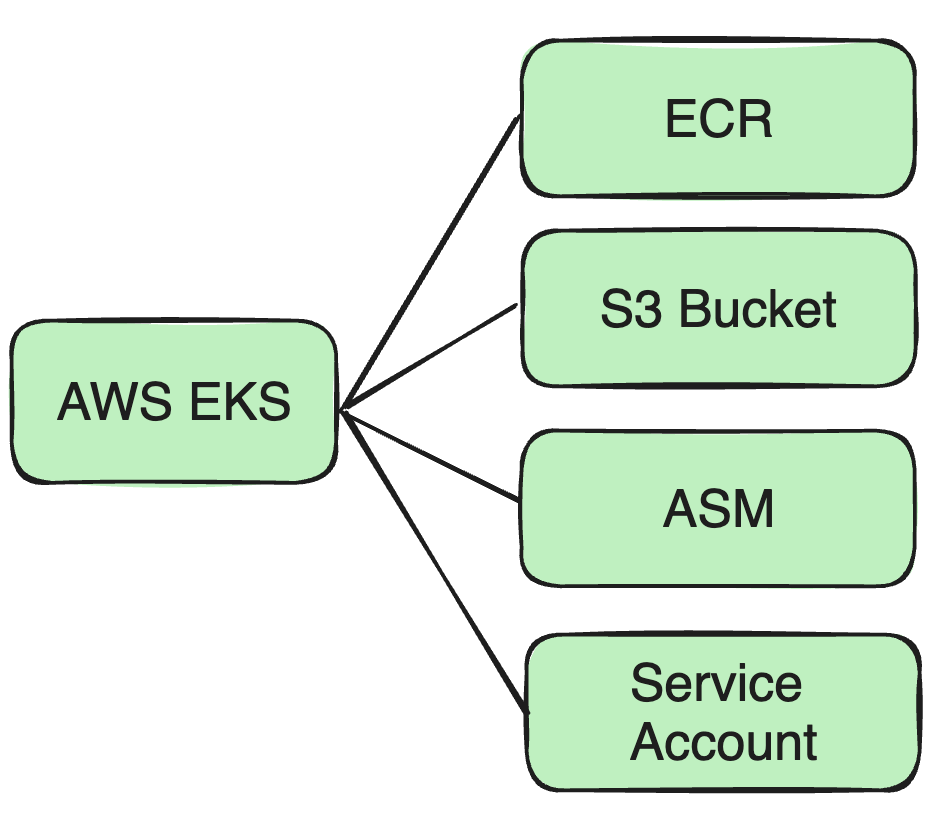
Soporte AWS EKS
A medida que nuestro negocio se expande a AWS EKS, debemos realizar una serie de ajustes a nuestra arquitectura y medidas de seguridad existentes.
Por ejemplo, al igual que la imagen de Docker mencionada hace un momento, anteriormente la colocamos en el repositorio de Docker de Cisco, por lo que ahora debemos colocar la imagen de Docker en ECR.
Compatibilidad con múltiples depósitos S3
Debido a la naturaleza descentralizada de los clústeres de AWS y los requisitos de aislamiento de datos de diferentes empresas, necesitamos admitir múltiples S3 Buckets para satisfacer las necesidades de almacenamiento de datos de diferentes clústeres:
Correspondencia entre clúster y depósito: Cada clúster accederá a su correspondiente S3 Bucket para garantizar la localidad y el cumplimiento de los datos.
Modificar estrategia: Necesitamos ajustar nuestra política de acceso al almacenamiento para admitir la lectura y escritura de datos de múltiples depósitos de S3. Diferentes partes comerciales deben acceder a sus depósitos de S3 correspondientes.
Cambios en las herramientas de administración de contraseñas.
Para mejorar la seguridad, migramos del servicio Vault autoconstruido de Cisco al Secrets Manager (ASM) de AWS:
Uso de la MAPE: ASM proporciona una solución más integrada para administrar contraseñas y claves para recursos de AWS.
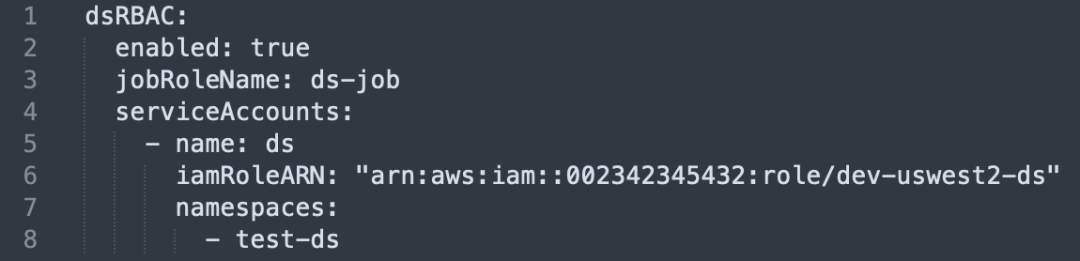
Hemos adoptado el método de utilizar la función de IAM y la cuenta de servicio para mejorar la seguridad de Pod:
Crear rol y política de IAM: Primero cree una función de IAM y vincule las políticas necesarias para garantizar que solo se otorguen los permisos necesarios.
Vincular cuenta de servicio K8s: Luego cree una cuenta de servicio de Kubernetes y asóciela con la función IAM.
Integración de permisos de pod: Al ejecutar un Pod, al asociarlo a la cuenta de servicio, el Pod puede obtener las credenciales de AWS requeridas directamente a través del rol de IAM, accediendo así a los recursos de AWS necesarios.
Estos ajustes no solo mejoran la escalabilidad y flexibilidad de nuestro sistema, sino que también fortalecen la arquitectura de seguridad general para garantizar que la operación en el entorno de AWS sea eficiente y segura. Al mismo tiempo, también evita el problema anterior de caducidad automática de claves y la necesidad de reiniciar.
Optimice los procesos de gestión y almacenamiento de recursos.
Para simplificar el proceso de implementación, planeamos enviar la imagen de Docker directamente a ECR en lugar de pasar por un tránsito secundario:
empujar directamente: Modifique el proceso de empaquetado actual para que la imagen de Docker se envíe directamente a ECR después de compilarse, lo que reduce los retrasos y los posibles puntos de error.
Implementación de cambios
Ajustes de nivel de código: Hemos modificado el código de DolphinScheduler para permitirle admitir múltiples Clientes S3 y agregamos administración de caché para múltiples Clientes S3.
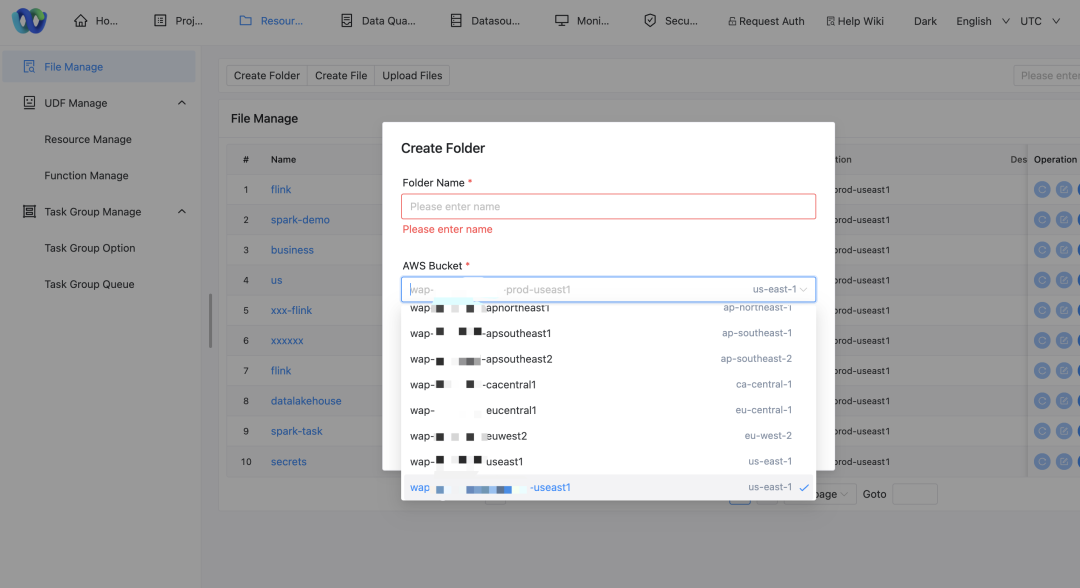
Ajustes en la interfaz de usuario de gestión de recursos: permite a los usuarios seleccionar diferentes nombres de AWS Bucket para operaciones a través de la interfaz.
acceso a recursos: El servicio Apache DolphinScheduler modificado ahora puede acceder a múltiples depósitos S3, lo que permite una gestión flexible de los datos entre diferentes clústeres de AWS.
Gestión y aislamiento de permisos de recursos de AWS.
Integre AWS Secrets Manager (ASM)
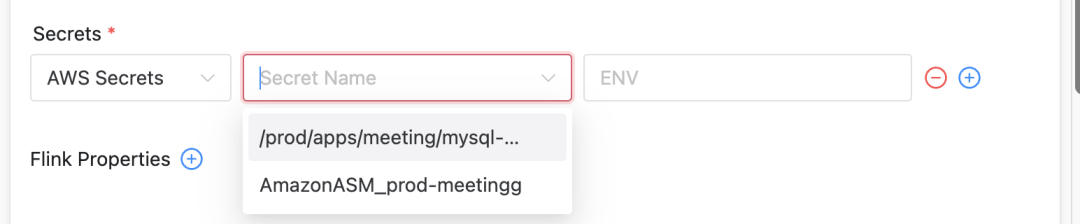
Hemos ampliado Apache DolphinScheduler para que sea compatible con AWS Secrets Manager, lo que permite a los usuarios seleccionar secretos en diferentes tipos de clústeres:
Integración funcional ASM
Mejoras en la interfaz de usuario: En la interfaz de usuario de DolphinScheduler, se agregan las funciones de visualización y selección de diferentes tipos de secretos.
Gestión automática de claves: Asigna la ruta del archivo que guarda el secreto seleccionado por el usuario a la variable de entorno real del Pod durante el tiempo de ejecución, lo que garantiza el uso seguro de la clave.
Servicio de configuración e inicialización dinámica de recursos (Init Container)
Para administrar e inicializar los recursos de AWS de manera más flexible, implementamos un servicio llamado Init Container:
Extracción de recursos: Init Container extraerá automáticamente los recursos S3 configurados por el usuario y los colocará en el directorio especificado antes de que se ejecute el Pod.
Gestión de claves y configuración.: Según la configuración, Init Container verificará y extraerá la información de la contraseña en ASM, luego la almacenará en un archivo y la asignará a través de variables de entorno para que la use Pod.
Aplicación de Terraform en la creación y gestión de recursos.
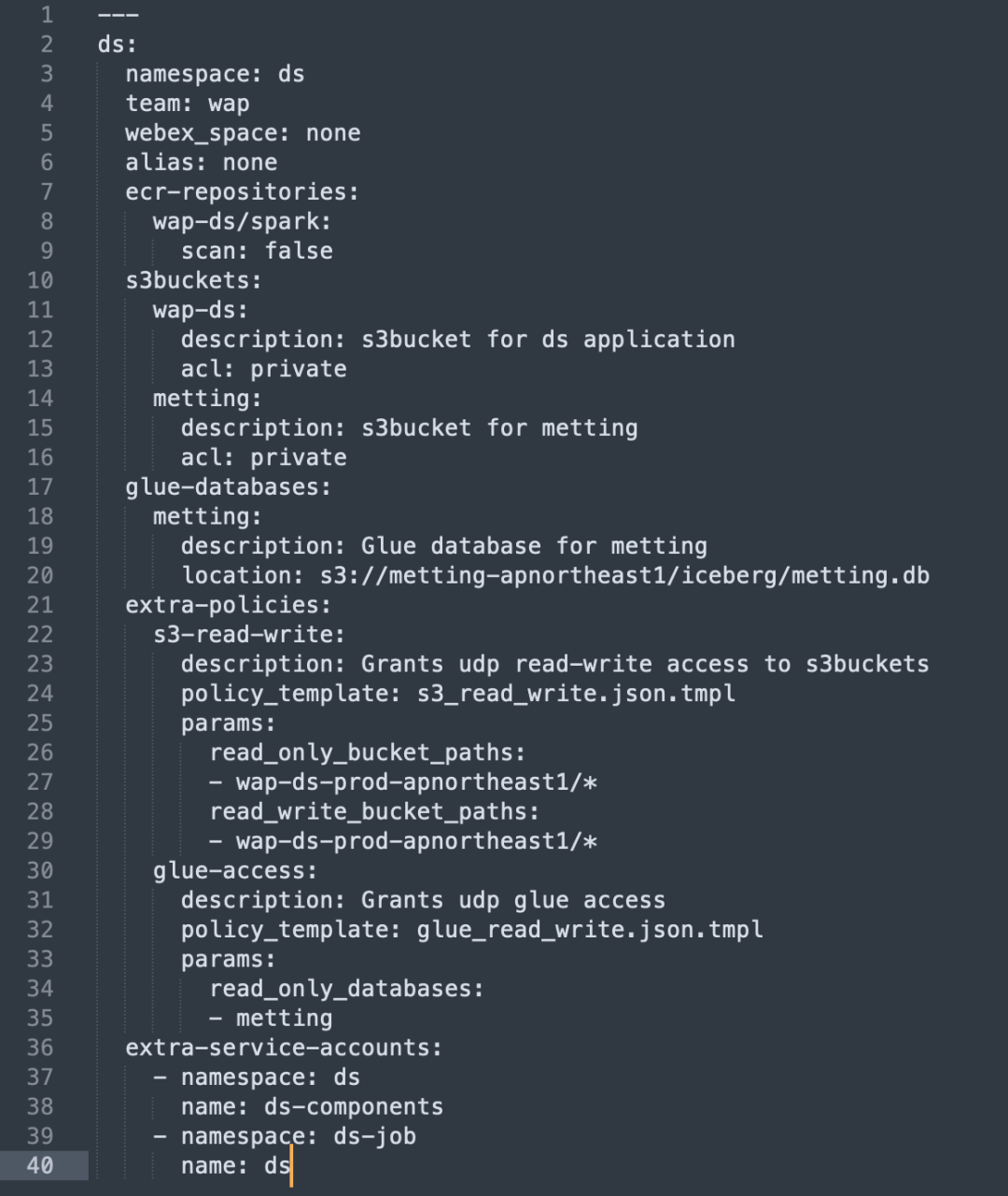
Hemos automatizado el proceso de configuración y gestión de recursos de AWS a través de Terraform, simplificando la asignación de recursos y la configuración de permisos:
Configuración automática de recursos: Utilice Terraform para crear los recursos de AWS necesarios, como S3 Bucket y ECR Repo.
Política de IAM y gestión de roles: cree automáticamente políticas y roles de IAM para garantizar que cada unidad de negocio tenga acceso bajo demanda a los recursos que necesita.
Aislamiento de permisos y seguridad.
Utilizamos estrategias sofisticadas de aislamiento de permisos para garantizar que diferentes unidades de negocio operen en espacios de nombres independientes, evitando conflictos de acceso a recursos y riesgos de seguridad:
Detalles de implementacion
Creación y vinculación de cuenta de servicio: cree una cuenta de servicio independiente para cada unidad de negocio y vincúlela a la función de IAM.
Aislamiento del espacio de nombres: cada operación de cuenta de servicio accede a sus recursos de AWS correspondientes a través del rol de IAM dentro del espacio de nombres especificado.
Mejoras en el soporte de clústeres y control de permisos.
Extensiones de tipo clúster
Agregamos un nuevo campo cluster type, para admitir diferentes tipos de clústeres K8S, que no solo incluyen clústeres estándar de Webex DC y clústeres de AWS EKS, sino que también admiten clústeres específicos con mayores requisitos de seguridad:
Gestión de tipos de clúster
Campo de tipo de clúster:por Introducidocluster typecampos, podemos administrar y ampliar fácilmente el soporte para diferentes clústeres K8S.
Personalización del nivel de código: Según las necesidades únicas de clústeres específicos, podemos realizar modificaciones a nivel de código para garantizar que se cumplan los requisitos de seguridad y configuración al ejecutar trabajos en estos clústeres.
Sistema de control de permisos mejorado (sistema de autenticación)
Desarrollamos el sistema de autenticación específicamente para un control de permisos detallado, incluida la gestión de permisos entre proyectos, recursos y espacios de nombres:
Función de gestión de derechos
Permisos de proyectos y recursos: Los usuarios pueden controlar los permisos a través de la dimensión del proyecto. Una vez que tienen los permisos del proyecto, tienen acceso a todos los recursos del proyecto.
control de permisos del espacio de nombres: Asegúrese de que un equipo específico solo pueda ejecutar los trabajos de su proyecto en el espacio de nombres especificado, garantizando así el aislamiento de recursos en ejecución.
Por ejemplo, el equipo A solo puede ejecutar ciertos trabajos del proyecto en su espacio de nombres A. El usuario B, por ejemplo, no puede ejecutar trabajos en el espacio de nombres del usuario A.
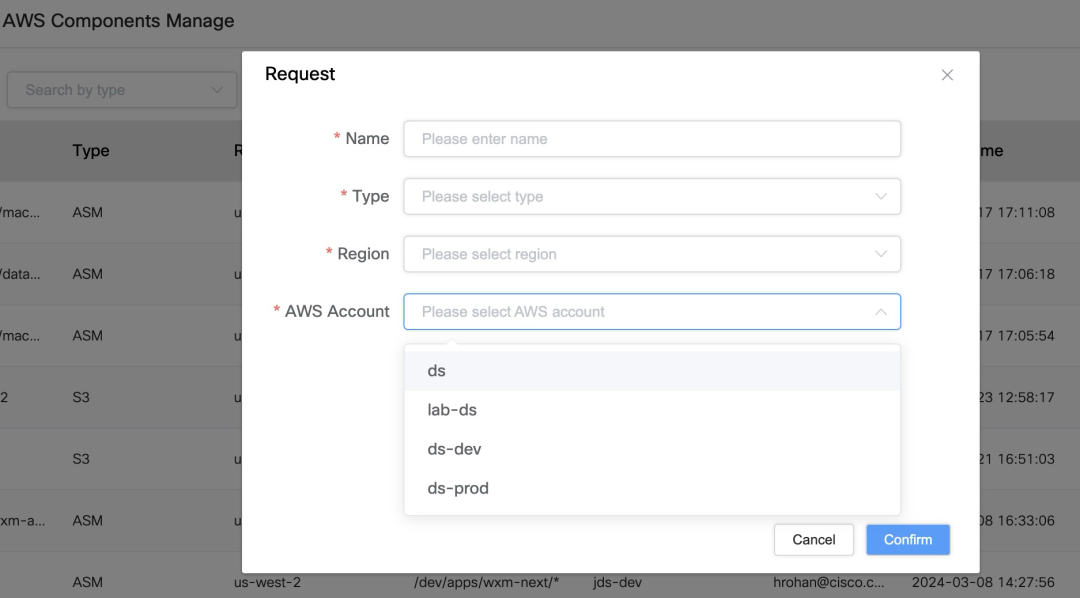
Solicitud de permisos y gestión de recursos de AWS
Utilizamos el sistema Auth y otras herramientas para gestionar permisos y control de acceso a los recursos de AWS, haciendo que la asignación de recursos sea más flexible y segura:
Soporte para múltiples cuentas de AWS: En el sistema de autenticación, puede administrar varias cuentas de AWS y vincular diferentes recursos de AWS, como S3 Bucket, ECR, ASM, etc.
Solicitud de permisos y mapeo de recursos: Los usuarios pueden mapear los recursos de AWS existentes y solicitar permisos en el sistema, de modo que puedan seleccionar fácilmente los recursos a los que necesitan acceder cuando ejecutan un trabajo.
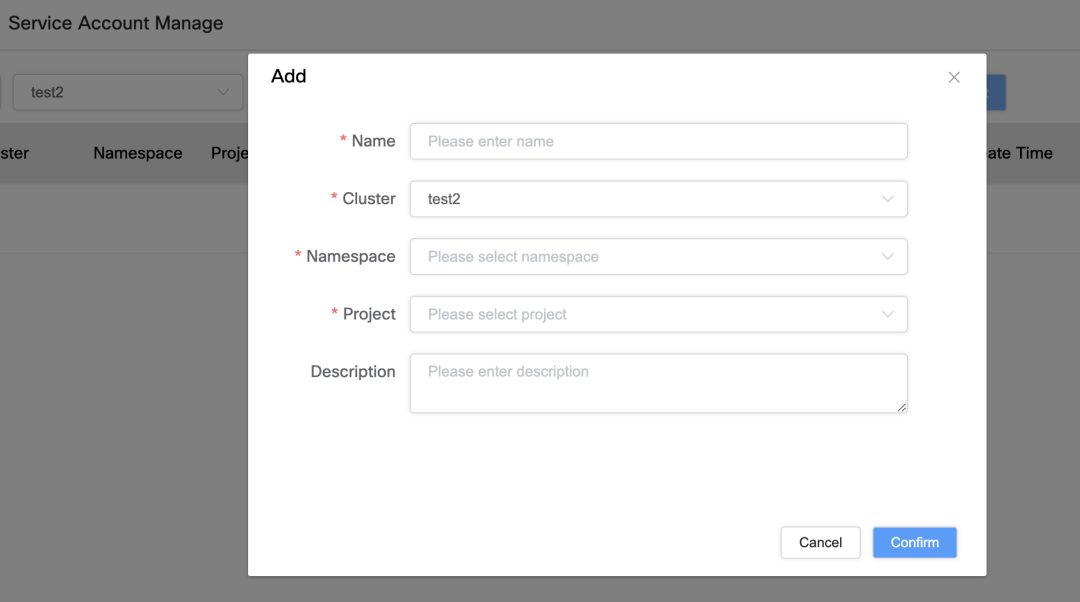
Gestión de cuentas de servicio y vinculación de permisos
Para administrar mejor las cuentas de servicio y sus permisos, hemos implementado las siguientes funciones:
Vinculación y gestión de cuentas de servicio
La única diferencia entre Cuenta de Servicio: vincula la cuenta de servicio a través de un clúster, espacio de nombres y nombre de proyecto específicos para garantizar su singularidad.
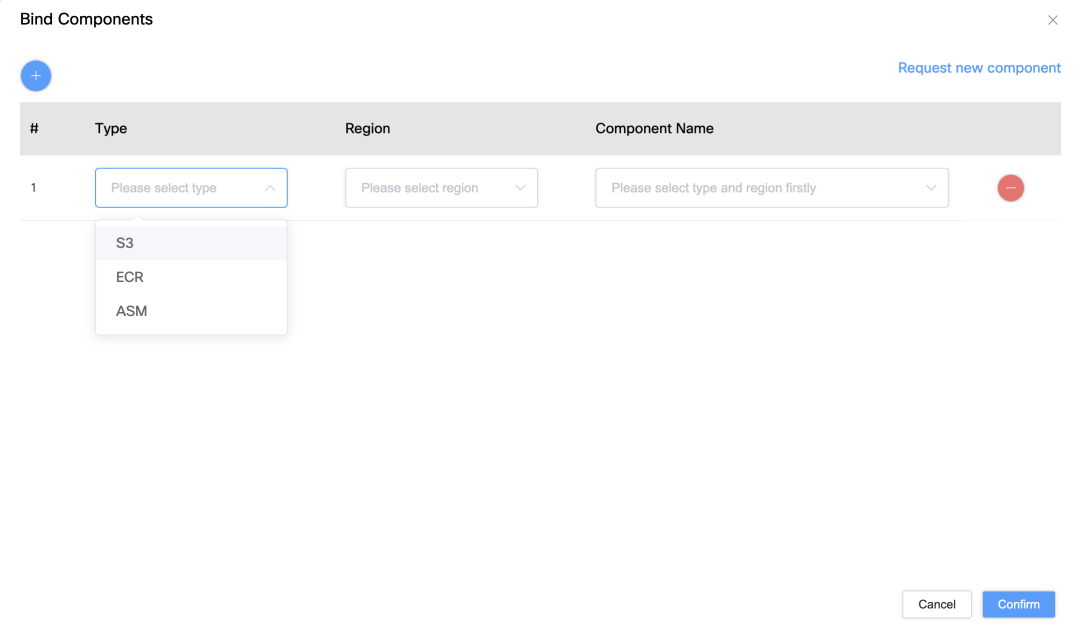
Interfaz de enlace de permisos: Los usuarios pueden vincular la cuenta de servicio a recursos específicos de AWS, como S3, ASM o ECR, en la interfaz para lograr un control preciso de los permisos.
Simplifique las operaciones y la sincronización de recursos
Acabo de decir mucho, pero la operación real es relativamente simple para los usuarios. Todo el proceso de solicitud es en realidad una tarea única. Para mejorar aún más la experiencia del usuario de Apache DolphinScheduler en el entorno de AWS, hemos tomado una serie de. medidas para simplificar los procedimientos operativos y mejorar las capacidades de sincronización de recursos.
Déjame resumirlo para ti:
Interfaz de usuario simplificada
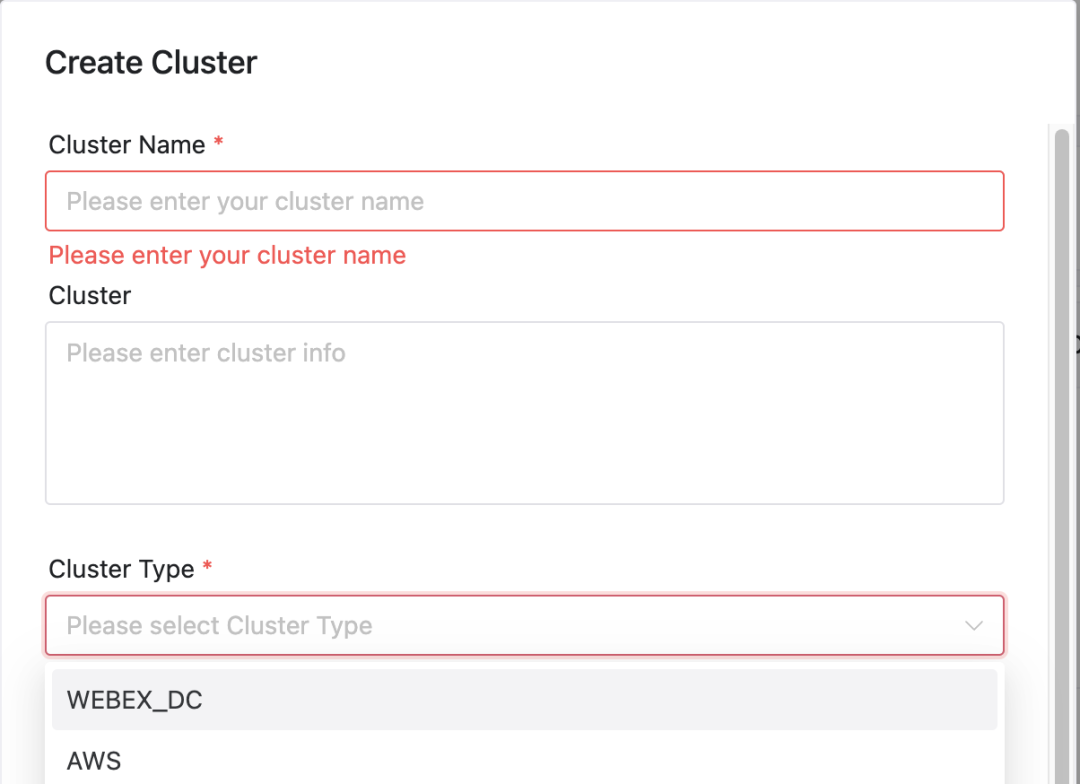
En DolphinScheduler, los usuarios pueden configurar fácilmente el clúster y el espacio de nombres específicos en los que se ejecutan sus trabajos:
Selección de clústeres y espacios de nombres
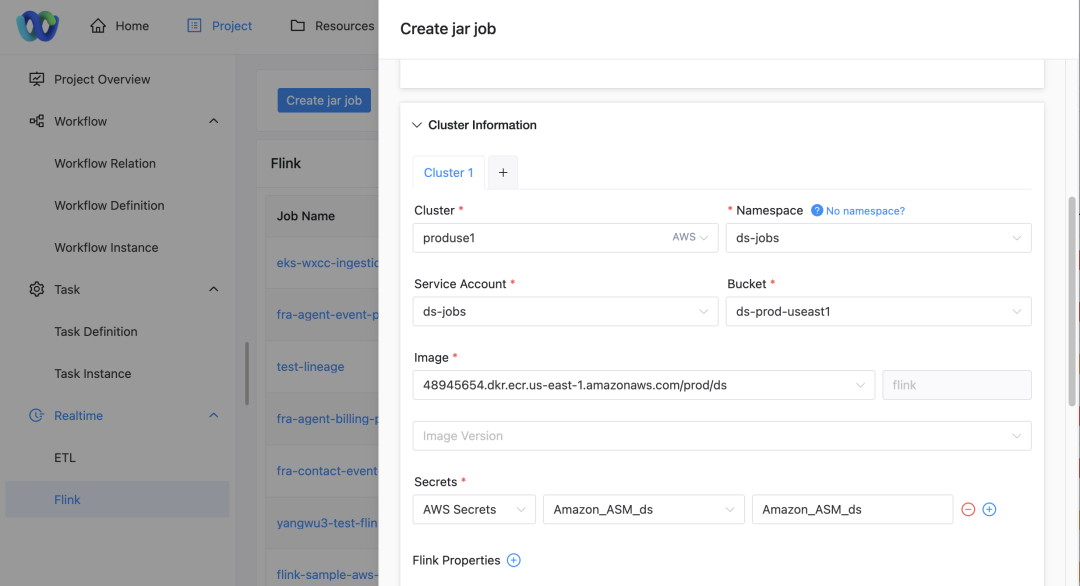
Selección de conglomerados: al enviar un trabajo, los usuarios pueden seleccionar el clúster en el que desean que se ejecute el trabajo.
configuración del espacio de nombres: Dependiendo del clúster seleccionado, el usuario también debe especificar el espacio de nombres en el que se ejecuta el trabajo.
Cuenta de servicio y selección de recursos
Visualización de cuenta de servicio: La página mostrará automáticamente la cuenta de servicio correspondiente según el proyecto, clúster y espacio de nombres seleccionados.
Configuración de acceso a recursos: Los usuarios pueden seleccionar el depósito S3, la dirección ECR y la clave ASM asociadas con la cuenta de servicio a través de la lista desplegable.
perspectiva del futuro
Con respecto al diseño actual, todavía hay algunas áreas que se pueden optimizar y mejorar para mejorar la presentación de los usuarios y facilitar la operación y el mantenimiento:
Optimización del envío de imágenes: Considere omitir el proceso de empaquetado de tránsito de Cisco y enviar el paquete directamente a ECR, especialmente para modificaciones de imágenes específicas de EKS.
Función de sincronización con un clic: Planeamos desarrollar una función de sincronización con un solo clic que permita a los usuarios cargar un paquete de recursos en un S3 Bucket y marcar la casilla para sincronizarlo automáticamente con otros S3 Buckets para reducir el trabajo de cargas repetidas.
Asignar automáticamente al sistema de autenticación: Después de crear los recursos de Aws a través de Terraform, el sistema asignará automáticamente estos recursos al sistema de administración de permisos para evitar que los usuarios ingresen recursos manualmente.
Optimización del control de permisos: A través de la gestión automatizada de recursos y permisos, las operaciones de los usuarios se vuelven más simples, lo que reduce la complejidad de la configuración y la gestión.
Con estas mejoras, esperamos ayudar a los usuarios a implementar y administrar sus trabajos de manera más eficiente utilizando Apache DolphinScheduler, ya sea en Webex DC o EKS, mientras mejoramos la eficiencia y la seguridad de la administración de recursos.