2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
- easy-rl PDF-Versionshinweis-Organisation P5, P10 - P12
- Joyrl-Vergleichsergänzung P11-P13
- OpenAI-Dokumentenorganisation ⭐ https://spinningup.openai.com/en/latest/index.html


Neueste Version als PDF herunterladen
Adresse: https://github.com/datawhalechina/easy-rl/releases
Inländische Adresse (empfohlen für inländische Leser):
Link: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw Extraktionscode: us6a
Link zur Online-Version von easy-rl (zum Kopieren des Codes)
Referenzlink 2: https://datawhalechina.github.io/joyrl-book/
andere:
[Link zum Errata-Datensatz]
——————
5. Grundlagen des Deep Reinforcement Learning ⭐️
Open-Source-Inhalt: https://linklearner.com/learn/summary/11
——————————
Identische Strategie: Der zu erlernende Agent und der mit der Umgebung interagierende Agent sind gleich.
Heterogene Strategien: Der zu lernende Agent und der mit der Umgebung interagierende Agent sind unterschiedlich
Richtliniengradient: Das Sammeln von Daten nimmt viel Zeit in Anspruch
gleiche Strategie ⟹ Wichtigkeitsstichprobe ~~~overset{Wichtigkeitsstichprobe}{Longrightarrow}~~~ ⟹Wichtigkeit der Stichprobe verschiedene Strategien
PPO: Vermeiden Sie zwei Distributionen, die sich zu stark unterscheiden. Gleicher Strategiealgorithmus
1. Ursprüngliche Optimierungselemente J ( θ , θ ′ ) J(theta,theta^prime)J(θ,θ′)
2. Einschränkungselemente: θ Thetaθ Und θ ′ theta^primeθ′ Die KL-Divergenz der Ausgabeaktion ( θ Thetaθ Und θ ′ theta^primeθ′ Je ähnlicher desto besser)
PPO hat einen Vorgänger: Trust Region Policy Optimization (TRPO)
TRPO ist schwierig zu handhaben, da es die KL-Divergenzbeschränkung als zusätzliche Einschränkung behandelt und nicht in die Zielfunktion eingefügt wird, sodass es schwierig zu berechnen ist. Daher verwenden wir im Allgemeinen PPO anstelle von TRPO. Die Leistung von PPO und TRPO ist ähnlich, PPO ist jedoch viel einfacher zu implementieren als TRPO.
KL-Divergenz: Aktionsdistanz.Wahrscheinlichkeitsverteilung der Ausführung einer Aktion Distanz.
Es gibt zwei Hauptvarianten des PPO-Algorithmus: Proximal Policy Optimization Penalty (PPO-Penalty) und Proximal Policy Optimization Clipping (PPO-Clip).
——————————
P10 Problem mit spärlicher Belohnung
1. Design-Belohnungen. Erfordert Domänenkenntnisse
Wie wäre es, wenn Sie jeder relevanten Aktion die endgültige Belohnung zuweisen?
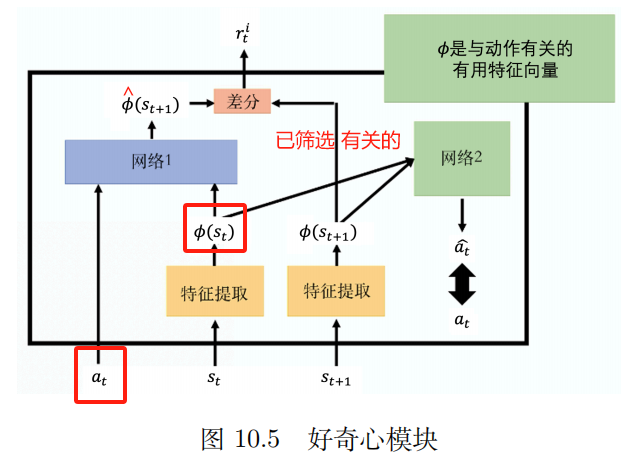
2. Neugier
Intrinsisches Neugiermodul (ICM)
eingeben: bei, st a_t,s_tAT,ST
Ausgabe: s ^ t + 1 Hut s_{t+1}S^T+1
Der vorhergesagte Wert des Netzwerks s ^ t + 1 Hut s_{t+1}S^T+1 mit wahrem Wert st + 1 s_{t+1}ST+1 Je unterschiedlicher sie sind, desto rti r_t^iRTichchchchchchchchchchchchchchchchchchchchchch Je größer
rti r_t^iRTichchchchchchchchchchchchchchchchchchchchchch : Je schwieriger der zukünftige Zustand vorherzusagen ist, desto größer ist die Belohnung für die Aktion. Fördern Sie Abenteuer und Entdeckungen.
Feature-Extraktor
Netzwerk 2:
Eingabe: Vektor ϕ ( st ) {bm phi}(s_{t})ϕ(ST) Und ϕ ( st + 1 ) {bm phi}(s_{t+1})ϕ(ST+1)
Aktionen vorhersagen ein ^ Hut einA^ Je näher an der realen Aktion, desto besser.
3. Kursstudium
Einfach -> Schwierig
Reverse-Curriculum-Lernen:
Gehen Sie ausgehend vom idealsten Endzustand [wir nennen ihn den Goldzustand] zuFinden Sie den Staat, der dem Golden State am nächsten kommt Als inszenierter „Idealzustand“, den der Agent erreichen soll. Natürlich werden wir dabei bewusst einige Extremzustände, also Zustände, die zu einfach oder zu schwierig sind, entfernen.
4. Hierarchisches Verstärkungslernen (HRL)
Die Strategie des Agenten ist in High-Level-Strategien und Low-Level-Strategien unterteilt. Die High-Level-Strategie bestimmt, wie die Low-Level-Strategie basierend auf dem aktuellen Status ausgeführt wird.
————————
P11 Nachahmungslernen
Bei der Belohnungsszene bin ich mir nicht sicher
Nachahmungslernen (IL)
Lernen durch Demonstration
Lehrlingsausbildung
Lernen durch Zuschauen
Es gibt klare Belohnungen: Brettspiele, Videospiele
Es können keine klaren Belohnungen vergeben werden: Chatbot
Sammeln Sie Expertendemonstrationen: menschliche Fahraufzeichnungen, menschliche Gespräche
Welche Art von Belohnungsfunktion hat der Experte umgekehrt bei diesen Maßnahmen?
Inverses Verstärkungslernen istFinden Sie zuerst die BelohnungsfunktionNachdem Sie die Belohnungsfunktion gefunden haben, verwenden Sie dann Verstärkungslernen, um den optimalen Akteur zu finden.
Lerntechnologie zur Nachahmung einer dritten Person
————————
P12 Tiefer deterministischer Richtliniengradient (DDPG)
Verwenden Sie eine Erfahrungswiederholungsstrategie
Analyse des Ablationsexperiments [kontrollierte Variablenmethode].jede EinschränkungEinfluss auf den Ausgang der Schlacht.
joyrl:
in NotSicherheitStrategie undkontinuierliche AktionUnter der Voraussetzung des Weltraums wird dieser Algorithmustyp ein relativ stabiler Basisalgorithmus sein.
DQN für kontinuierliche Aktionsräume
Deep Deterministic Policy Gradient Algorithmus (DDPG)
Der Erfahrungswiedergabemechanismus kann die Korrelation zwischen Proben verringern, die effektive Nutzung von Proben verbessern und die Stabilität des Trainings erhöhen.
Mangel:
1. Kann nicht im diskreten Aktionsbereich verwendet werden
2、Stark abhängig von Hyperparametern
3. Hochsensible Anfangsbedingungen. Beeinflusst die Konvergenz und Leistung des Algorithmus
4. Es ist leicht, in das lokale Optimum zu fallen.
Der Vorteil der sanften Aktualisierung besteht darin, dass sie sanfter und langsamer ist, wodurch Erschütterungen durch zu schnelle Gewichtsaktualisierungen vermieden und das Risiko einer Trainingsabweichung verringert werden können.
Deterministischer Richtliniengradientenalgorithmus mit doppelter Verzögerung
Drei Verbesserungen: Double-Q-Netzwerk, verzögerte Aktualisierung, Rauschregulierung
Double-Q-Netzwerk : Zwei Q-Netzwerke, wählen Sie das mit dem kleineren Q-Wert. Um das Überschätzungsproblem des Q-Werts zu lösen und die Stabilität und Konvergenz des Algorithmus zu verbessern.
Verzögerte Aktualisierung: Lassen Sie die Aktualisierungshäufigkeit des Akteurs niedriger sein als die Aktualisierungshäufigkeit des Kritikers
Lärm ist eher wie einRegulierungSodassAktualisierung der Wertfunktionmehrglatt
OpenAI Gym Library_Pendulum_TD3
Link zur OpenAI-Dokumentschnittstelle zu TD3
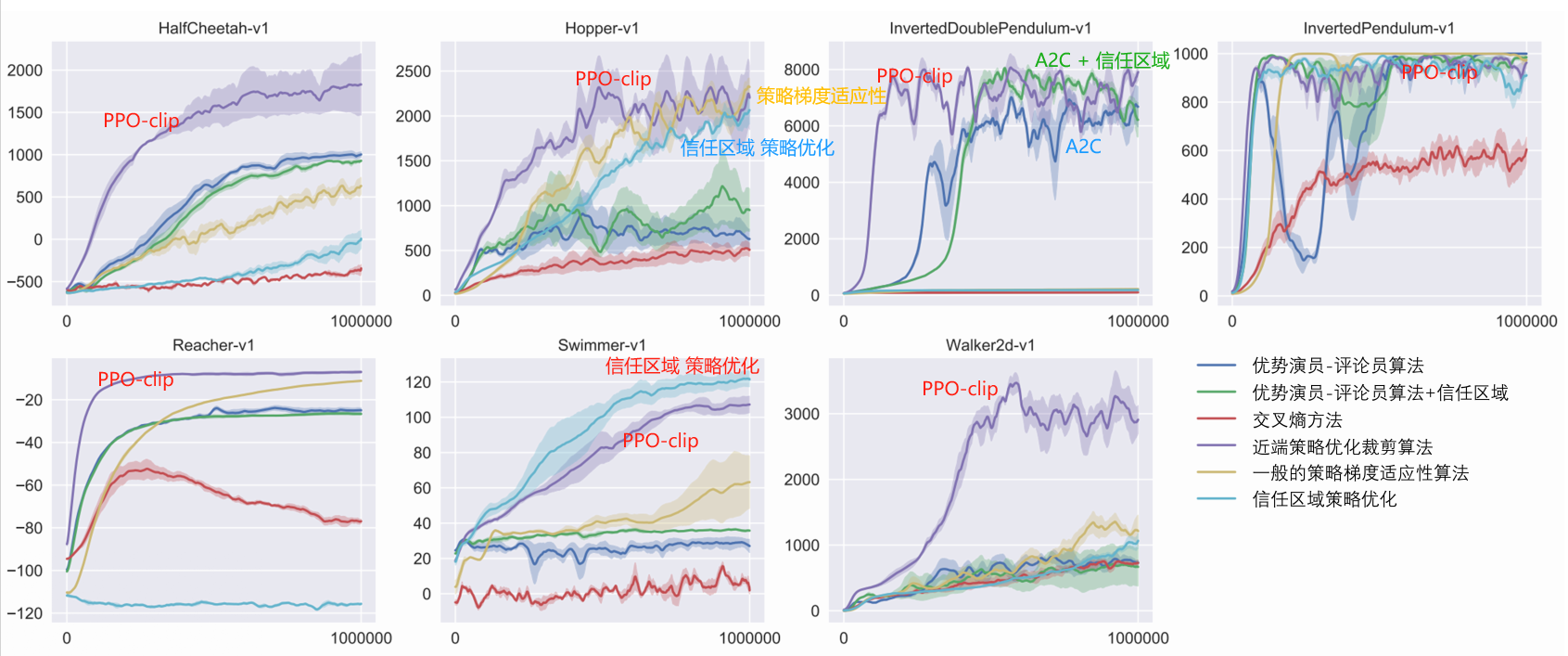
Der am häufigsten verwendete PPO-Algorithmus beim Reinforcement Learning
Diskret + kontinuierlich
Schnell und stabil, einfach anzupassende Parameter
Basisalgorithmus
Unentschlossenes PPO
In der Praxis werden im Allgemeinen Clip-Einschränkungen verwendet, da diese einfacher sind, einen geringeren Rechenaufwand erfordern und bessere Ergebnisse liefern.
Der Off-Policy-Algorithmus kannhistorische Erfahrungen nutzenVerwenden Sie im Allgemeinen die Erfahrungswiedergabe, um frühere Erfahrungen zu speichern und wiederzuverwenden.Die Effizienz der Datennutzung ist hoch。
PPO ist ein richtlinienkonformer Algorithmus
——————————————————
OpenAI-Dokumentation
Paper-Link zur arXiv-Schnittstelle: Proximal Policy Optimization Algorithms
PPO: Richtlinienkonformer Algorithmus, geeignet für diskrete oder kontinuierliche Aktionsräume.Mögliches lokales Optimum
Die Motivation für PPO ist die gleiche wie für TRPO: wie man vorhandene Daten nutztMachen Sie den größtmöglichen Verbesserungsschritt in Ihrer Strategie, ohne es zu sehr zu ändern und versehentlich einen Leistungsabsturz zu verursachen?
TRPO versucht, dieses Problem mit einem ausgefeilten Ansatz zweiter Ordnung zu lösen, während PPO ein Ansatz erster Ordnung ist, der einige andere Tricks verwendet, um die neue Strategie nahe an der alten zu halten.
Die PPO-Methode ist viel einfacher zu implementieren und liefert empirisch mindestens die gleiche Leistung wie TRPO.
Es gibt zwei Hauptvarianten von PPO: PPO-Penalty und PPO-Clip.


Algorithmus: PPO-Clip
1: Eingabe: anfängliche Strategieparameter θ 0 theta_0θ0, Anfangswert-Funktionsparameter ϕ 0 phi_0ϕ0
2: für k = 0, 1, 2, … do {bf für} ~ k=0,1,2,dots~ {bf do}für k=0,1,2,… Tun:
3: ~~~~~~ Durch Ausführen der Richtlinie in der Umgebung πk = π (θk) pi_k=pi(theta_k)πk=π(θk) Sammeln Sie den Flugbahnsatz D k = { τ i } {cal D}_k={tau_i}Dk={τichchchchchchchchchchchchchchchchchchchchchch}
4: ~~~~~~ Prämien berechnen (Rewards-to-go) R ^ das R_t~~~~~R^T ▢ R ^ t hat R_tR^T Berechnungsregeln
5: ~~~~~~ Berechnen Sie die Vorteilsschätzung basierend auf der aktuellen Wertfunktion V ϕ k V_{phi_k}Vϕk von A ^ t hat A_tA^T (Verwenden Sie eine beliebige Methode zur Dominanzschätzung) ~~~~~ ▢ Was sind die aktuellen Methoden zur Vorteilsschätzung?
6: ~~~~~~ Aktualisieren Sie die Richtlinie, indem Sie die PPO-Clip-Zielfunktion maximieren:
~~~~~~~~~~~
θ k + 1 = arg max θ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T min ( π θ ( bei ∣ st ) π θ k ( bei ∣ st ) A π θ k ( st , bei ) , g ( ϵ , A π θ k ( st , bei ) ) ) ~~~~~~~~~~~theta_{k+1}=argmaxlimits_thetafrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TminBig(frac{pi_{theta} (a_t|s_t)}{pi_{theta_k}(a_t|s_t)}A^{pi_{theta_k}}(s_t,a_t),g(epsilon,A^{pi_{theta_k}}(s_t,a_t))Groß) θk+1=arGθmax∣Dk∣T1τ∈Dk∑T=0∑TMindest(πθk(AT∣ST)πθ(AT∣ST)Aπθk(ST,AT),G(ϵ,Aπθk(ST,AT))) ~~~~~ ▢ Wie ermittelt man die Strategieaktualisierungsformel?
~~~~~~~~~~~
~~~~~~~~~~~ π θ k pi_{theta_k}πθk : Strategieparametervektor vor der Aktualisierung. Bedeutung der Probenahme. Sampling aus alten Strategien.
~~~~~~~~~~~
~~~~~~~~~~~ Allgemeiner stochastischer Gradientenaufstieg + Adam
7: ~~~~~~ mittlerer quadratischer FehlerRegressionsanpassungswertfunktion:
~~~~~~~~~~~
ϕ k + 1 = arg min ϕ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T ( V ϕ ( st ) − R ^ t ) 2 ~~~~~~~~~~~phi_{k+1}=arg minlimits_phifrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TBig(V_phi(s_t)-hat R_tBig)^2 ϕk+1=arGϕMindest∣Dk∣T1τ∈Dk∑T=0∑T(Vϕ(ST)−R^T)2
~~~~~~~~~~~
~~~~~~~~~~~ Allgemeiner Gefälleabstieg
8: Ende für bf Ende ~fürEnde für
~~~~~~~~~~~~
$dots$ … ~~~Punkte …
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) AA < 0 g(epsilon,A)=links{(1+ϵ)A A≥0(1−ϵ)AA<0Rechts. G(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0

in der ZeitungVorteilsschätzung:
A ^ t = − V ( st ) + rt + γ rt + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) ⏟ R ^ t ? ? ? Hut A_t=-V(s_t)+underbrace{r_t+gamma r_{t+1}+cdots+gamma^{T-t+1}r_{T-1}+gamma^{Tt}V(s_T)}_{textcolor{blue}{Hut R_t???}}A^T=−V(ST)+R^T??? RT+γRT+1+⋯+γT−T+1RT−1+γT−TV(ST)

machen Δ t = rt + γ V ( st + 1 ) − V ( st ) Delta_t =r_t+gamma V(s_{t+1})-V(s_t)ΔT=RT+γV(ST+1)−V(ST)
Aber rt = Δ t − γ V ( st + 1 ) + V ( st ) r_t=Delta_t - gamma V(s_{t+1})+V(s_t)RT=ΔT−γV(ST+1)+V(ST)
Ersatz A ^ t hat A_tA^T Ausdruck
A ^ t = − V ( st ) + rt + γ rt + 1 + γ 2 rt + 2 + ⋯ + γ T − tr T − 2 + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( st ) + rt + γ rt + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( st ) + Δ t − γ V ( st + 1 ) + V ( st ) + γ ( Δ t + 1 − γ V ( st + 2 ) + V ( st + 1 ) ) + γ 2 ( Δ t + 2 − γ V ( st + 3 ) + V ( st + 1 ) ) + ⋯ + γ T − t ( Δ T − t − γ V ( s T − t + 1 ) + V ( s T − t ) ) + γ T − t + 1 ( Δ T − 1 − γ V ( s T ) + V ( s T − 1 ) ) + γ T − t V ( s T ) = Δ t + γ Δ t + 1 + γ 2 Δ t + 2 + ⋯ + γ T − t Δ T − t + γ T − t + 1 Δ T − 1ˆAT=−V(ST)+RT+γRT+1+γ2RT+2+⋯+γT−TRT−2+γT−T+1RT−1+γT−TV(ST)=−V(ST)+RT+γRT+1+⋯+γT−T+1RT−1+γT−TV(ST)=−V(ST)+ ΔT−γV(ST+1)+V(ST)+ γ(ΔT+1−γV(ST+2)+V(ST+1))+ γ2(ΔT+2−γV(ST+3)+V(ST+1))+ ⋯+ γT−T(ΔT−T−γV(ST−T+1)+V(ST−T))+ γT−T+1(ΔT−1−γV(ST)+V(ST−1))+ γT−TV(ST)=ΔT+γΔT+1+γ2ΔT+2+⋯+γT−TΔT−T+γT−T+1ΔT−1 A^T=−V(ST)+RT+γRT+1+γ2RT+2+⋯+γT−TRT−2+γT−T+1RT−1+γT−TV(ST)=−V(ST)+RT+γRT+1+⋯+γT−T+1RT−1+γT−TV(ST)=−V(ST)+ ΔT−γV(ST+1)+V(ST)+ γ(ΔT+1−γV(ST+2)+V(ST+1))+ γ2(ΔT+2−γV(ST+3)+V(ST+1))+ ⋯+ γT−T(ΔT−T−γV(ST−T+1)+V(ST−T))+ γT−T+1(ΔT−1−γV(ST)+V(ST−1))+ γT−TV(ST)=ΔT+γΔT+1+γ2ΔT+2+⋯+γT−TΔT−T+γT−T+1ΔT−1

Clipping wirkt als Regularisierer, indem es den Anreiz für drastische Änderungen in der Politik beseitigt.Hyperparameter ϵ Epsilonϵ Entspricht dem Abstand zwischen der neuen Strategie und der alten Strategie。
Es ist immer noch möglich, dass diese Art des Abschneidens irgendwann zu einer neuen Strategie führt, die weit von der alten Strategie entfernt ist. Bei der Umsetzung verwenden wir hier eine besonders einfache Methode:Hören Sie früh auf . Wenn die durchschnittliche KL-Divergenz der neuen Richtlinie von der alten Richtlinie einen Schwellenwert überschreitet, beenden wir die Ausführung des Gradientenschritts.
Einfacher Ableitungslink der PPO-Zielfunktion
Die Zielfunktion von PPO-Clip ist:
~
L θ k CLIP ( θ ) = E s , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , Clip ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ k ( s , a ) ) ] L^{rm CLIP}_{theta_k}(theta)=underset{s, asimtheta_k}{rm E}Bigg[minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}A^{theta_k}(s, a), {rm Clip}Groß(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)},1-epsilon, 1+epsilonGroß)A^{theta_k}(s, a)Groß)Groß]MθkCLIP(θ)=S,A∼θkE[Mindest(πθk(A∣S)πθ(A∣S)Aθk(S,A),Beschneiden(πθk(A∣S)πθ(A∣S),1−ϵ,1+ϵ)Aθk(S,A))]
~
$underset{s, asimtheta_k}{rm E}$E s , a ∼ θ k ~~~underset{s, asimtheta_k}{rm E} S,A∼θkE
~
NEIN. k.k.k Strategieparameter für Iterationen θ k theta_kθk, ϵ Epsilonϵ ist ein kleiner Hyperparameter.
aufstellen ϵ ∈ ( 0 , 1 ) epsilonin(0,1)ϵ∈(0,1), Definition
F ( r , A , ϵ ) ≐ min ( r A , Clip ( r , 1 − ϵ , 1 + ϵ ) A ) F(r,A,epsilon)doteqminBigg(rA,{rm Clip}(r,1-epsilon,1+epsilon)ABigg)F(R,A,ϵ)≐Mindest(RA,Beschneiden(R,1−ϵ,1+ϵ)A)
Wann A ≥ 0 Alterq0A≥0
F ( r , A , ϵ ) = min ( r A , Clip ( r , 1 − ϵ , 1 + ϵ ) A ) = A min ( r , Clip ( r , 1 − ϵ , 1 + ϵ ) ) = A min ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { min ( r , 1 + ϵ ) r ≥ 1 + ϵ min ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) min ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) rr ≤ 1 − ϵ } Gemäß dem Bereich auf der rechten Seite = A min ( r , 1 + ϵ ) = min ( r A , ( 1 + ϵ ) A )begin{align}F(r,A,epsilon)&=minBigg(rA,{rm clip}(r,1-epsilon,1+epsilon)ABigg)\ &=AminBigg(r,{rm clip}(r,1-epsilon,1+epsilon)Bigg)\ &=AminBigg(r,left{begin{aligned}&1+epsilon~~&rgeq1+epsilon\ &r &rin(1-epsilon,1+epsilon)\ &1-epsilon &rleq1-epsilon\ end{aligned}rechts}Bigg)\ &=Alinks{Mindestrechts}\ &=Alinks{right}~~~~~textcolor{blue}{entsprechend dem Bereich rechts}\ &=Amin(r, 1+epsilon)\ &=minBigg(rA, (1+epsilon)ABigg) end{aligned} F(R,A,ϵ)=Mindest(RA,Beschneiden(R,1−ϵ,1+ϵ)A)=AMindest(R,Beschneiden(R,1−ϵ,1+ϵ))=AMindest(R,⎩ ⎨ ⎧1+ϵ R1−ϵR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧Mindest(R,1+ϵ) Mindest(R,R)Mindest(R,1−ϵ)R≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧1+ϵ RRR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫ Entsprechend dem Bereich rechts=AMindest(R,1+ϵ)=Mindest(RA,(1+ϵ)A)
~
Wann A < 0 A<0A<0
F ( r , A , ϵ ) = min ( r A , Clip ( r , 1 − ϵ , 1 + ϵ ) A ) = A max ( r , Clip ( r , 1 − ϵ , 1 + ϵ ) ) = A max ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { max ( r , 1 + ϵ ) r ≥ 1 + ϵ max ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) max ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { r r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } Gemäß dem Bereich auf der rechten Seite = A max ( r , 1 − ϵ ) = min ( r A , ( 1 − ϵ ) A )rechts}Bigg)\ &=Alinks{rechts}\ &=Alinks{right}~~~~~textcolor{blue}{entsprechend dem Bereich rechts}\ &=Amax(r, 1-epsilon)\ &=textcolor{blue}{min}Bigg(rA,(1-epsilon) ABigg) end{aligned} F(R,A,ϵ)=Mindest(RA,Beschneiden(R,1−ϵ,1+ϵ)A)=AMAX(R,Beschneiden(R,1−ϵ,1+ϵ))=Amax(R,⎩ ⎨ ⎧1+ϵ R1−ϵR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧max(R,1+ϵ) max(R,R)max(R,1−ϵ)R≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧R R1−ϵR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫ Entsprechend dem Bereich rechts=Amax(R,1−ϵ)=MichchchchchchchchchchchchchchchchchchchchchchN(RA,(1−ϵ)A)
~
Zusammenfassend: definierbar g ( ϵ , A ) g(epsilon,A)G(ϵ,A)
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) AA < 0 g(epsilon,A)=links{Rechts. G(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0
Warum verhindert diese Definition, dass die neue Strategie zu weit von der alten Strategie abweicht?
Effektive Wichtigkeitsstichprobenverfahren erfordern neue Strategien π θ ( a ∣ s ) pi_theta(a|s)πθ(A∣S) und alte Strategien π θ k ( a ∣ s ) pi_{theta_k}(a|s)πθk(A∣S) Der Unterschied zwischen den beiden Verteilungen darf nicht zu groß sein
1. Wenn der Vorteil positiv ist
L (s, a, θ k, θ) = min (π θ (a ∣ s) π θ k (a ∣ s), 1 + ϵ) A π θ k (s, a) L(s, a, theta_k, theta)=minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1+epsilonBigg)A^{pi_{theta_k}}(s, a)M(S,A,θk,θ)=Mindest(πθk(A∣S)πθ(A∣S),1+ϵ)Aπθk(S,A)
Vorteilsfunktion: Finden Sie ein bestimmtes Zustands-Aktionspaar mit mehr Belohnungen -> erhöhen Sie das Gewicht des Zustands-Aktionspaars.
Bei einem Zustand-Aktions-Paar (s, ein) (s, ein)(S,A) ist positiv, dann wenn die Aktion einA wahrscheinlicher ist, dass es ausgeführt wird, d. h. wenn π θ ( a ∣ s ) pi_theta(a|s)πθ(A∣S) Steigern Sie und das Ziel wird größer.
min in diesem Element begrenzt die Zielfunktion so, dass sie nur auf einen bestimmten Wert ansteigt
einmal π θ ( a ∣ s ) > ( 1 + ϵ ) π θ k ( a ∣ s ) pi_theta(a|s)>(1+epsilon)pi_{theta_k}(a|s)πθ(A∣S)>(1+ϵ)πθk(A∣S), min löst aus und begrenzt den Wert dieses Elements auf ( 1 + ϵ ) π θ k ( a ∣ s ) (1+epsilon)pi_{theta_k}(a|s)(1+ϵ)πθk(A∣S)。
die neue Politik profitiert nicht davon, wenn sie weit von der alten Politik abweicht.
Die neue Strategie wird nicht von einer Abkehr von der alten Strategie profitieren.
2. Wenn der Vorteil negativ ist
L (s, a, θ k, θ) = max (π θ (a ∣ s) π θ k (a ∣ s), 1 − ϵ) A π θ k (s, a) L(s, a, theta_k, theta)=maxBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1-epsilonBigg)A^{pi_{theta_k}}(s, a)M(S,A,θk,θ)=max(πθk(A∣S)πθ(A∣S),1−ϵ)Aπθk(S,A)
Bei einem Zustand-Aktions-Paar (s, ein) (s, ein)(S,A) Der Vorteil ist dann negativ, wenn die Aktion erfolgt einA ist noch weniger wahrscheinlich, das heißt, wenn π θ ( a ∣ s ) π_theta(a|s)πθ(A∣S) abnimmt, nimmt die Zielfunktion zu. Das Maximum in diesem Term begrenzt jedoch, um wie viel die Zielfunktion erhöht werden kann.
einmal π θ ( a ∣ s ) < ( 1 − ϵ ) π θ k ( a ∣ s ) pi_theta(a|s)<(1-epsilon)pi_{theta_k}(a|s)πθ(A∣S)<(1−ϵ)πθk(A∣S), maximale Auslöser, wodurch der Wert dieses Elements auf begrenzt wird ( 1 − ϵ ) π θ k ( a ∣ s ) (1-epsilon)pi_{theta_k}(a|s)(1−ϵ)πθk(A∣S)。
Nochmals: Die neue Politik profitiert nicht davon, dass sie sich weit von der alten Politik entfernt.
Die neue Strategie wird nicht von einer Abkehr von der alten Strategie profitieren.
Während DDPG manchmal eine hervorragende Leistung erzielen kann, ist es häufig instabil, wenn es um Hyperparameter und andere Arten der Optimierung geht.
Ein häufiger DDPG-Fehlermodus besteht darin, dass die erlernte Q-Funktion beginnt, den Q-Wert deutlich zu überschätzen, was dann dazu führt, dass die Richtlinie bricht, weil sie den Fehler in der Q-Funktion ausnutzt.
Twin Delayed DDPG (TD3) ist ein Algorithmus, der dieses Problem durch die Einführung von drei Schlüsseltechniken löst:
1、Abgeschnittenes doppeltes Q-Learning。
2、Verzögerung bei der Richtlinienaktualisierung。
3. Glättung der Zielstrategie.
TD3 ist ein Off-Policy-Algorithmus; er kann nur mit verwendet werdenkontinuierlichDie Umgebung des Aktionsraums.

Algorithmus: TD3
Verwenden Sie zufällige Parameter θ 1 , θ 2 , ϕ theta_1, theta_2, phiθ1,θ2,ϕ Kritikernetzwerk initialisieren Q θ 1 , Q θ 2 Q_{theta_1},Q_{theta_2}Qθ1,Qθ2und Akteursnetzwerk π ϕ pi_phiπϕ
Zielnetzwerk initialisieren θ 1 ' ← θ 1 , θ 2 ' ← θ 2 , ϕ ' ← ϕ theta_1^primeleftarrowtheta_1, theta_2^primeleftarrowtheta_2, phi^primeleftarrow phiθ1′←θ1,θ2′←θ2,ϕ′←ϕ
Wiedergabepuffersatz initialisieren B-Kalk BB
für t = 1 bis T {bf für}~t=1 ~{bf bis} ~Tfür T=1 Zu T :
~~~~~~ Wählen Sie Aktion mit Erkundungsgeräusch a ∼ π ϕ ( s ) + ϵ , ϵ ∼ N ( 0 , σ ) asimpi_phi(s)+epsilon,~~epsilonsim {cal N}(0,sigma)A∼πϕ(S)+ϵ, ϵ∼N(0,σ), Beobachtungsbelohnung rrR und neuer Status s ′ s^primS′
~~~~~~ Das Übergangstupel ( s , a , r , s ′ ) (s, a,r, s^Primzahl)(S,A,R,S′) Anzahlung an B-Kalk BB Mitte
~~~~~~ aus B-Kalk BB Bemusterung kleiner Chargen NNN Übergänge ( s , a , r , s ′ ) (s, a, r, s^Primzahl)(S,A,R,S′)
a ~ ← π ϕ ′ ( s ′ ) + ϵ , ϵ ∼ clip ( N ( 0 , σ ~ ) , − c , c ) ~~~~~~widetilde aleftarrow pi_{phi^prime}(s^prime)+epsilon,~~epsilonsim{rm clip}({cal N}(0,widetilde sigma),-c,c) A ←πϕ′(S′)+ϵ, ϵ∼Beschneiden(N(0,σ ),−C,C)
y ← r + γ min i = 1 , 2 Q θ i ′ ( s ′ , a ~ ) ~~~~~~yleftarrow r+gamma minlimits_{i=1,2}Q_{theta_i^prime}(s^prime,widetilde a) j←R+γichchchchchchchchchchchchchchchchchchchchchch=1,2MindestQθichchchchchchchchchchchchchchchchchchchchchch′(S′,A )
~~~~~~ Update-Kritiker θ i ← arg min θ i N − 1 ∑ ( y − Q θ i ( s , a ) ) 2 theta_ileftarrowargminlimits_{theta_i}N^{-1}Summe(y-Q_{theta_i}(s, a))^2θichchchchchchchchchchchchchchchchchchchchchch←arGθichchchchchchchchchchchchchchchchchchchchchchMindestN−1∑(j−Qθichchchchchchchchchchchchchchchchchchchchchch(S,A))2
~~~~~~ wenn t % d {bf wenn}~t~ % ~dWenn T % D:
~~~~~~~~~~~ Aktualisierung über deterministischen Richtliniengradienten ϕ phiϕ
∇ ϕ J ( ϕ ) = N − 1 ∑ ∇ a Q θ 1 ( s , a ) ∣ a = π ϕ ( s ) ∇ ϕ π ϕ ( s ) ~~~~~~~~~~~~~~~~~nabla_phi J(phi)=N^{-1}sumnabla_aQ_{theta_1}(s, a)|_{a=pi_phi(s)}nabla_phipi_phi(s) ∇ϕJ(ϕ)=N−1∑∇AQθ1(S,A)∣A=πϕ(S)∇ϕπϕ(S)
~~~~~~~~~~~ Zielnetzwerk aktualisieren:
θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ ~~~~~~~~~~~~~~~~~~theta_i^primeleftarrowtautheta_i+(1-tau)theta_i^prime~~~~~ θichchchchchchchchchchchchchchchchchchchchchch′←τθichchchchchchchchchchchchchchchchchchchchchch+(1−τ)θichchchchchchchchchchchchchchchchchchchchchch′ τ tauτ: Zielaktualisierungsrate
ϕ ′ ← τ ϕ + ( 1 − τ ) ϕ ′ ~~~~~~~~~~~~~~~~~phi^primeleftarrowtauphi+(1-tau)phi^prime ϕ′←τϕ+(1−τ)ϕ′
Ende, wenn ~~~~~~{bf Ende ~if} Ende Wenn
Ende für {bf end ~for}Ende für

Maximieren Sie die Entropie der Richtlinie und machen Sie sie dadurch robuster.
deterministische Strategie Das bedeutet, dass bei gleichem Zustand immer die gleiche Aktion gewählt wird
Zufallsstrategie Das bedeutet, dass es in einem bestimmten Zustand viele mögliche Aktionen gibt, die ausgewählt werden können.
| deterministische Strategie | Zufallsstrategie | |
|---|---|---|
| Definition | Gleicher Zustand, gleiche Aktion ausführen | gleicher Status,Kann verschiedene Aktionen ausführen |
| Vorteil | Stabil und wiederholbar | Vermeiden Sie es, in lokal optimale Lösungen zu verfallen, und verbessern Sie die globalen Suchfunktionen |
| Mangel | Mangelnde Erkundbarkeit und leichte Ergreifbarkeit durch Gegner | Dies kann dazu führen, dass die Strategie langsam konvergiert, was sich auf Effizienz und Leistung auswirkt. |
In der tatsächlichen Anwendung werden wir dies tun, sofern die Bedingungen dies zulassenVersuchen zu benutzenZufallsstrategie, wie A2C, PPO usw., weil es flexibler, robuster und stabiler ist.
Das Lernen zur Verstärkung der maximalen Entropie geht davon aus, dass wir, obwohl wir derzeit über ausgereifte Zufälligkeitsstrategien verfügen, nämlich Algorithmen wie AC, immer noch keine optimale Zufälligkeit erreicht haben.Daher führt es einInformationsentropieKonzept, inMaximieren Sie die kumulative Belohnung und maximieren Sie gleichzeitig die Entropie der Richtlinie, wodurch die Strategie robuster wird und die optimale Zufallsstrategie erreicht wird.
——————————————————
OpenAI Documentation_SAC-Schnittstellenlink
~
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning mit einem stochastischen Akteur, Haarnoja et al, 201808 ICML 2018
Soft Actor-Critic Algorithmen und Anwendungen, Haarnoja et al, 201901
Laufen lernen durch Deep Reinforcement Learning, Haarnoja et al, 201906 RSS2019
Soft Actor Critic (SAC) optimiert zufällige Strategien außerhalb der Richtlinien.
DDPG + stochastische Strategieoptimierung
Kein direkter Nachfolger von TD3 (ungefähr zur gleichen Zeit veröffentlicht).
Es beinhaltet den abgeschnittenen Double-Q-Trick und profitiert aufgrund der inhärenten Zufälligkeit der SAC-Strategie letztendlich auch davonZielpolitische Glättung。
Ein Kernmerkmal von SAC ist Entropie-Regularisierung Entropie-Regularisierung。
Die Richtlinie ist darauf trainiert, den Kompromiss zwischen erwarteter Belohnung und Entropie zu maximieren.Entropie ist ein Maß für die Zufälligkeit einer Richtlinie。
Dies hängt eng mit dem Kompromiss zwischen Exploration und Ausbeutung zusammen: Eine Erhöhung der Entropie führt zuMehr zu entdecken,das ist in OrdnungBeschleunigen Sie anschließendes Lernen .Es ist in OrdnungVerhindern Sie, dass sich die Richtlinie vorzeitig einem schlechten lokalen Optimum annähert。
Es kann sowohl im kontinuierlichen Aktionsraum als auch im diskreten Aktionsraum verwendet werden.
existieren Entropiereguliertes Verstärkungslernen, erhält der Agent undDie Entropie der Richtlinie zu diesem ZeitpunktProportionale Belohnungen.
Derzeit wird das RL-Problem wie folgt beschrieben:
π ∗ = arg max π E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ] pi^*=argmaxlimits_pi underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})textcolor{blue}{+alpha H(pi(·|s_t))}Big)Big]π∗=arGπmaxτ∼πE[T=0∑∞γT(R(ST,AT,ST+1)+αH(π(⋅∣ST)))]
In α > 0 alpha > 0α>0 ist der Kompromisskoeffizient.
Zustandswertfunktion einschließlich Entropiebelohnung bei jedem Zeitschritt V π V^piVπ für:
V π ( s ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s ] V^pi(s)=underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})+alpha H(pi(·|s_t))Big)Big|s_0=sBig]Vπ(S)=τ∼πE[T=0∑∞γT(R(ST,AT,ST+1)+αH(π(⋅∣ST))) S0=S]
Eine Aktionswertfunktion, die die Entropiebelohnung für jeden Zeitschritt außer dem ersten enthält Q π Q^piQπ:
Q π ( s , a ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α ∑ t = 1 ∞ H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s , a 0 = a ] Q^pi(s,a)=underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})+alpha sumlimits_{t=1}^infty H(pi(·|s_t))Big)Big|s_0=s,a_0=aBig]Qπ(S,A)=τ∼πE[T=0∑∞γT(R(ST,AT,ST+1)+αT=1∑∞H(π(⋅∣ST))) S0=S,A0=A]
V π V^piVπ Und Q π Q^piQπ Die Beziehung zwischen ist:
V π ( s ) = E a ∼ π [ Q π ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) V^pi(s)=underset{asimpi}{rm E}[Q^pi(s, a)]+alpha H(pi(·|s))Vπ(S)=A∼πE[Qπ(S,A)]+αH(π(⋅∣S))
um Q π Q^piQπ Die Bellman-Formel lautet:
Qπ(s, a) = Es‘ ∼ Pa‘ ∼ π[R(s, a, s‘) + γ(Qπ(s‘, a‘) + αH(π(⋅∣s‘)))] = Es‘ ∼ P[R(s, a, s‘) + γVπ(s‘)] Qπ(S,A)=A′∼πS′∼PE[R(S,A,S′)+γ(Qπ(S′,A′)+αH(π(⋅∣S′)))]=S′∼PE[R(S,A,S′)+γVπ(S′)]
SAC lernt gleichzeitig eine Richtlinie π θ π_thetaπθ und zwei FrageQ Funktion Q ϕ 1 , Q ϕ 2 Q_{phi_1}, Q_{phi_2}Qϕ1,Qϕ2。
Derzeit gibt es zwei Varianten des Standard-SAC: Die eine nutzt einen festenEntropie-Regularisierungskoeffizient α alphaα, ein weiterer durch Wechsel während des Trainings α alphaα um Entropiebeschränkungen durchzusetzen.
In der Dokumentation von OpenAI wird eine Version mit einem festen Entropie-Regularisierungskoeffizienten verwendet, in der Praxis wird diese jedoch häufig bevorzugtEntropiebeschränkungVariante.
Wie unten gezeigt, in α alphaα In der festen Version haben die anderen, mit Ausnahme des letzten Bildes, das offensichtliche Vorteile hat, nur geringfügige Vorteile, im Grunde die gleichen wie α alphaα Die Lernversion bleibt dieselbe; α alphaα Deutlicher sind die beiden mittleren Bilder, bei denen die Lernversion Vorteile hat.
SACVSTD3:
~
Gleicher Punkt:
1. Beide Q-Funktionen werden durch Minimierung des MSBE (Mean Squared Bellman Error) durch Regression auf ein einziges gemeinsames Ziel erlernt.
2. Verwenden Sie das Ziel-Q-Netzwerk, um das gemeinsame Ziel zu berechnen, und führen Sie während des Trainingsprozesses eine Polyak-Mittelung der Q-Netzwerk-Parameter durch, um das Ziel-Q-Netzwerk zu erhalten.
3. Das gemeinsame Ziel verwendet die Technik des abgeschnittenen Doppel-Q.
~
Unterschied:
1. SAC enthält einen Entropie-Regularisierungsterm
2. Die nächste staatliche Aktion, die im SAC-Ziel verwendet wird, stammt vonAktuelle Strategie, und nicht die Zielstrategie.
3. Es gibt keine klare Zielstrategie für die Glättung. TD3 trainiert eine deterministische Richtlinie, indem es zum nächsten Zustand übergehtFügen Sie zufälliges Rauschen hinzu Glätte zu erreichen. SAC trainiert eine Zufallsrichtlinie, und das durch den Zufall verursachte Rauschen reicht aus, um ähnliche Effekte zu erzielen.

Algorithmus: Soft Actor-Critic SAC
eingeben: theta_1,theta_2,phi~~~~~θ1,θ2,ϕ Initialisierungsparameter
Parameterinitialisierung:
~~~~~~ Zielnetzwerkgewichte initialisieren: θ ˉ 1 ← θ 1 , θ ˉ 2 ← θ 2 Balken theta_1leftarrowtheta_1, Balken theta_2leftarrowtheta_2θˉ1←θ1,θˉ2←θ2
~~~~~~ Der Wiedergabepool wird als leer initialisiert: D ← ∅ {cal D}linksPfeilleerSetD←∅
für {bf für}für jede Iteration tun {bf tun}Tun :
~~~~~~ für {bf für}für Jeder Umgebungsschritt tun {bf tun}Tun :
~~~~~~~~~~~ Beispielaktionen aus einer Richtlinie: bei ∼ π ϕ ( bei ∣ st ) a_tsimpi_phi(a_t|s_t)~~~~~AT∼πϕ(AT∣ST) ▢Hier π ϕ ( bei ∣ st ) pi_phi(a_t|s_t)πϕ(AT∣ST) Wie definieren?
~~~~~~~~~~~ Beispielübergänge aus der Umgebung: st + 1 ∼ p ( st + 1 ∣ st , at ) s_{t+1}sim p(s_{t+1}|s_t,a_t)ST+1∼P(ST+1∣ST,AT)
~~~~~~~~~~~ Speichern Sie den Übergang in den Wiedergabepool: D ← D ∪ { ( st , at , r ( st , at ) , st + 1 ) } {cal D}leftarrow{cal D}~cup~{(s_t,a_t,r(s_t,a_t),s_{t+1})}D←D ∪ {(ST,AT,R(ST,AT),ST+1)}
~~~~~~ Ende für {bf end ~for}Ende für
~~~~~~ für {bf für}für Jeder Farbverlaufsschritt tun {bf tun}Tun :
~~~~~~~~~~~ erneuern FrageQ Funktionsparameter: für i ∈ { 1 , 2 } iin{1,2}ichchchchchchchchchchchchchchchchchchchchchch∈{1,2}, θ i ← θ i − λ Q ∇ ^ θ i JQ ( θ i ) theta_ileftarrowtheta_i-lambda_Qhat nabla_{theta_i}J_Q(theta_i)~~~~~θichchchchchchchchchchchchchchchchchchchchchch←θichchchchchchchchchchchchchchchchchchchchchch−λQ∇^θichchchchchchchchchchchchchchchchchchchchchchJQ(θichchchchchchchchchchchchchchchchchchchchchch) ▢Hier JQ (θi) J_Q(theta_i)JQ(θichchchchchchchchchchchchchchchchchchchchchch) Wie definieren?
~~~~~~~~~~~ Strategiegewichte aktualisieren: ϕ ← ϕ − λ π ∇ ^ ϕ J π ( ϕ ) phileftarrowphi-lambda_pihat nabla_phi J_pi (phi)~~~~~ϕ←ϕ−λπ∇^ϕJπ(ϕ) ▢Hier J π ( ϕ ) J_pi (phi)Jπ(ϕ) Wie definieren?
~~~~~~~~~~~ Temperatur anpassen: α ← α − λ ∇ ^ α J ( α ) alphaleftarrowalpha-lambdahatnabla_alpha J(alpha)~~~~~α←α−λ∇^αJ(α) ▢Hier J ( α ) J(Alpha)J(α) Wie definieren?Wie ist hier die Temperatur zu verstehen?
~~~~~~~~~~~ Zielnetzwerkgewichte aktualisieren: für i ∈ { 1 , 2 } iin{1,2}ichchchchchchchchchchchchchchchchchchchchchch∈{1,2}, θ ˉ i ← τ θ i − ( 1 − τ ) θ ˉ i bar theta_ileftarrow tau theta_i-(1-tau)bar theta_i~~~~~θˉichchchchchchchchchchchchchchchchchchchchchch←τθichchchchchchchchchchchchchchchchchchchchchch−(1−τ)θˉichchchchchchchchchchchchchchchchchchchchchch ▢ Wie man das versteht τ tauτ ? ——>Zielglättungskoeffizient
~~~~~~ Ende für {bf end ~for}Ende für
Ende für {bf end ~for}Ende für
Ausgabe: theta_1,theta_1,phi~~~~~θ1,θ1,ϕ Optimierte Parameter
∇ ^ hat nabla∇^: stochastischer Gradient
$emptyset$ ∅ ~~~~leere Menge ∅


Laufen lernen durch Deep Reinforcement Learning Version in:
~
α
α
α ist der Temperaturparameter, der die relative Bedeutung des Entropieterms und der Belohnung bestimmt und so die Zufälligkeit der optimalen Strategie steuert.
α alphaα Groß: Entdecken
α alphaα Klein: ausnutzen
J ( α ) = E bei ∼ π t [ − α log π t ( bei ∣ st ) − α H ˉ ] J(alpha)=underset{a_tsimpi_t}{mathbb E}[-alphalog pi_t(a_t|s_t)-alphabar{cal H}]J(α)=AT∼πTE[−αohGπT(AT∣ST)−αHˉ]

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen







