






Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
- easy-rl versión PDF organización de notas P5, P10 - P12
- suplemento comparativo joyrl P11-P13
- Organización de documentos OpenAI ⭐ https://spinningup.openai.com/en/latest/index.html


Descargar la última versión en PDF
Dirección: https://github.com/datawhalechina/easy-rl/releases
Dirección nacional (recomendada para lectores nacionales):
Enlace: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw Código de extracción: us6a
Enlace de la versión en línea de easy-rl (para copiar el código)
Enlace de referencia 2: https://datawhalechina.github.io/joyrl-book/
otro:
[Enlace de registro de erratas]
——————
5. Conceptos básicos del aprendizaje por refuerzo profundo ⭐️
Contenido de código abierto: https://linklearner.com/learn/summary/11
——————————
Estrategia idéntica: el agente a aprender y el agente que interactúa con el entorno son el mismo.
Estrategias heterogéneas: el agente que aprende y el agente que interactúa con el entorno son diferentes
Gradiente de políticas: requiere mucho tiempo para muestrear datos
misma estrategia ⟹ Muestreo de importancia ~~~overset{Muestreo de importancia}{Longrightarrow}~~~ ⟹muestreo de importancia diferentes estrategias
PPO: Evite dos distribuciones que difieran demasiado. mismo algoritmo de estrategia
1. Elementos de optimización originales. J ( θ , θ ′ ) J(theta,theta^prima)Yo(θ,θ′)
2. Elementos de restricción: θ-thetaθ y θ ′ theta^primeθ′ La divergencia KL de la acción de salida ( θ-thetaθ y θ ′ theta^primeθ′ Cuanto más parecidos mejor)
PPO tiene un predecesor: optimización de políticas de región de confianza (TRPO)
TRPO es difícil de manejar porque trata la restricción de divergencia de KL como una restricción adicional y no se coloca en la función objetivo, por lo que es difícil de calcular. Por lo tanto, generalmente utilizamos PPO en lugar de TRPO. El desempeño de PPO y TRPO es similar, pero PPO es mucho más fácil de implementar que TRPO.
Divergencia KL: distancia de acción.Distribución de probabilidad de realizar una acción. distancia.
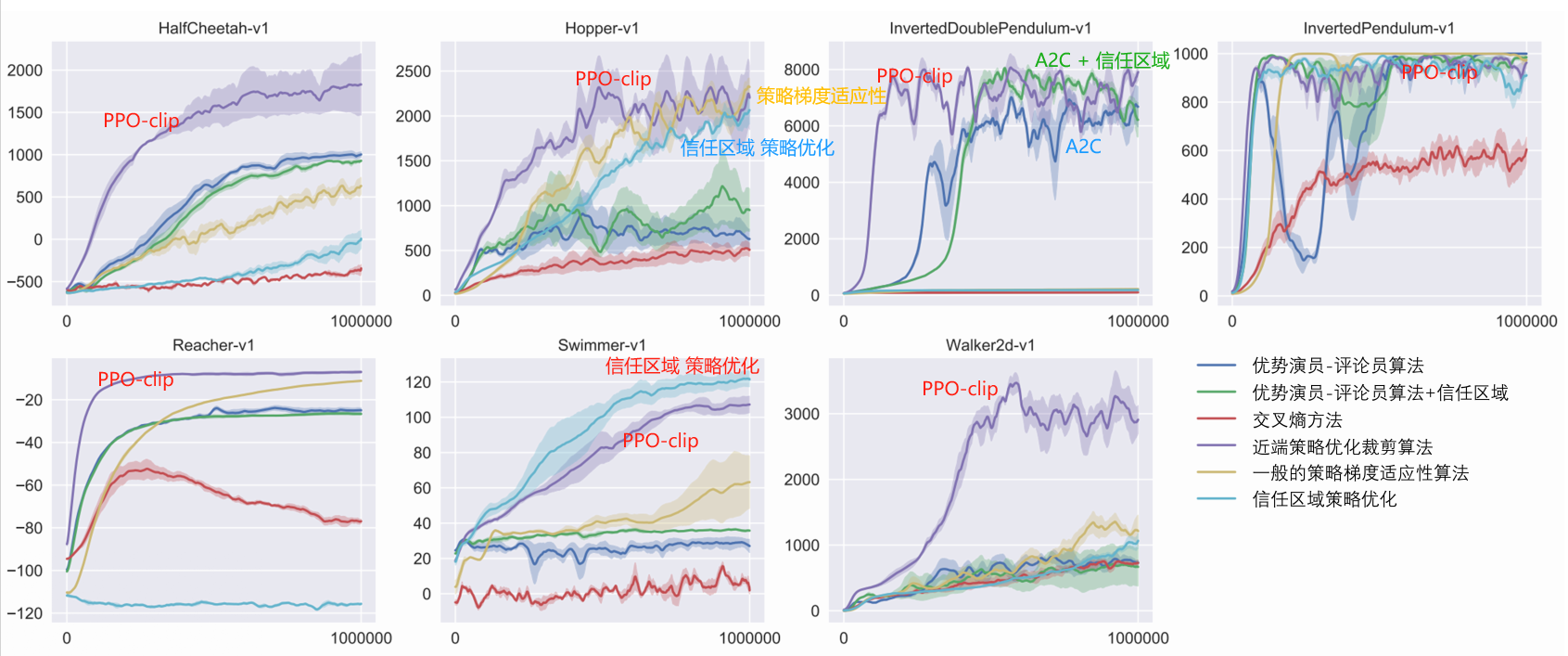
Hay dos variantes principales del algoritmo PPO: penalización de optimización de políticas proximales (penalización PPO) y recorte de optimización de políticas proximales (clip PPO).
——————————
P10 Problema de recompensa escasa
1. Diseñar recompensas. Requiere conocimiento del dominio
¿Qué tal asignar la recompensa final a cada acción relevante?
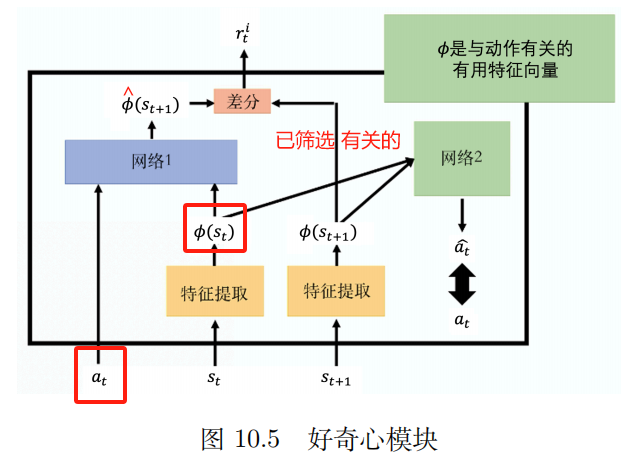
2. Curiosidad
Módulo de curiosidad intrínseca (ICM)
ingresar: en , st a_t,s_taa,sa
Producción: s ^ t + 1 sombrero s_{t+1}s^a+1
El valor previsto de la red. s ^ t + 1 sombrero s_{t+1}s^a+1 con valor verdadero s_t + 1 s_t + 1sa+1 Cuanto más diferentes sean, más rti r_t^iaai El más grande
rti r_t^iaai : Cuanto más difícil sea predecir el estado futuro, mayor será la recompensa por la acción. Fomente la aventura y la exploración.
extractor de funciones
Red 2:
Entrada: vector ϕ ( st ) {bm phi}(s_{t})ϕ(sa) y ϕ ( st + 1 ) {bm phi}(s_{t+1})ϕ(sa+1)
Predecir la acción un ^ sombrero una^ Cuanto más se acerque a la acción real, mejor.
3. Estudio del curso
Fácil -> Difícil
Aprendizaje curricular inverso:
Comenzando desde el estado final más ideal [lo llamamos estado dorado], vaya aEncuentra el estado más cercano al estado dorado Como un estado "ideal" por etapas que desea que alcance el agente. Por supuesto, eliminaremos intencionalmente algunos estados extremos en este proceso, es decir, estados que son demasiado fáciles o demasiado difíciles.
4. Aprendizaje por refuerzo jerárquico (HRL)
La estrategia del agente se divide en estrategias de alto nivel y estrategias de bajo nivel. La estrategia de alto nivel determina cómo ejecutar la estrategia de bajo nivel en función del estado actual.
————————
P11 Aprendizaje por imitación
No estoy seguro de la escena de la recompensa.
Aprendizaje por imitación (IL)
aprendiendo de la demostración
Aprendizaje
aprendiendo mirando
Hay recompensas claras: juegos de mesa, videojuegos.
No se pueden dar recompensas claras: chatbot
Recopile demostraciones de expertos: registros de conducción humanos, conversaciones humanas.
A la inversa, ¿qué tipo de función de recompensa realiza el experto ante estas acciones?
El aprendizaje por refuerzo inverso esPrimero encuentre la función de recompensa.Después de encontrar la función de recompensa, utilice el aprendizaje por refuerzo para encontrar el actor óptimo.
Tecnología de aprendizaje por imitación en tercera persona.
————————
P12 gradiente político determinista profundo (DDPG)
Utilice la estrategia de repetición de experiencia
Análisis del experimento de ablación [método de variable controlada]cada restricciónimpacto en el resultado de la batalla.
alegría:
en necesidadcertezaestrategia yacción continuaBajo la premisa del espacio, este tipo de algoritmo será un algoritmo de referencia relativamente estable.
DQN para espacios de acción continua
Algoritmo de gradiente de políticas determinista profundo (DDPG)
El mecanismo de repetición de experiencias puede reducir la correlación entre muestras, mejorar la utilización efectiva de las muestras y aumentar la estabilidad del entrenamiento.
defecto:
1. No se puede utilizar en un espacio de acción discreto.
2、Altamente dependiente de hiperparámetros
3. Condiciones iniciales muy sensibles. Afecta la convergencia y el rendimiento del algoritmo.
4. Es fácil caer en el óptimo local.
La ventaja de la actualización suave es que es más suave y lenta, lo que puede evitar los shocks causados por actualizaciones de peso demasiado rápidas y reducir el riesgo de divergencia en el entrenamiento.
Algoritmo de gradiente de política determinista de doble retraso
Tres mejoras: red Doble Q, actualización retrasada, regularización de ruido
Red Doble Q : Dos redes Q, elija la que tenga un valor Q menor. Tratar el problema de sobreestimación del valor Q y mejorar la estabilidad y convergencia del algoritmo.
Actualización retrasada: permita que la frecuencia de actualización del actor sea menor que la frecuencia de actualización crítica
El ruido es más como unRegularizaciónde una manera queactualización de la función de valormásliso
Biblioteca de gimnasio OpenAI_Pendulum_TD3
Enlace de interfaz de documento OpenAI sobre TD3
El algoritmo PPO más utilizado en el aprendizaje por refuerzo.
Discreto + continuo
Parámetros rápidos y estables, fáciles de ajustar.
algoritmo de referencia
PPO indeciso
En la práctica, las restricciones de recorte se utilizan generalmente porque son más simples, tienen un costo computacional más bajo y tienen mejores resultados.
El algoritmo fuera de política puedeaprovechar la experiencia histórica, generalmente usa la repetición de experiencias para almacenar y reutilizar experiencias anteriores,La eficiencia de utilización de datos es alta。
PPO es un algoritmo basado en políticas
——————————————————
Documentación de OpenAI
Enlace de la interfaz Paper arXiv: Algoritmos de optimización de políticas próximas
PPO: algoritmo on-policy, adecuado para espacios de acción discretos o continuos.Posible óptimo local
La motivación de PPO es la misma que de TRPO: cómo aprovechar los datos existentesDa el mayor paso de mejora posible en tu estrategia, sin cambiarlo demasiado y provocar accidentalmente una caída del rendimiento?
TRPO intenta resolver este problema con un enfoque sofisticado de segundo orden, mientras que PPO es un enfoque de primer orden que utiliza algunos otros trucos para mantener la nueva estrategia cerca de la anterior.
El método PPO es mucho más sencillo de implementar y, empíricamente, funciona al menos tan bien como TRPO.
Hay dos variaciones principales de PPO: PPO-Penalty y PPO-Clip.


Algoritmo: PPO-Clip
1: Entrada: parámetros de estrategia iniciales θ 0 theta_0θ0, parámetros de función de valor inicial ϕ 0 phi_0ϕ0
2: para k = 0, 1, 2, … hacer {bf para} ~ k=0,1,2,puntos~ {bf hacer}para a=0,1,2,… hacer:
3: ~~~~~~ Ejecutando la política en el entorno. π k = π ( θ k ) pi_k=pi(theta_k)πa=π(θa) Recoger conjunto de trayectoria D k = { τ i } {cal D}_k={tau_i}Da={τi}
4: ~~~~~~ Calcular recompensas (recompensas para llevar) R ^ ese R_t~~~~~R^a ▢ R ^ que R_tR^a reglas de cálculo
5: ~~~~~~ Calcular la estimación de la ventaja, basándose en la función de valor actual V ϕ k V_{phi_k}Vϕa de A ^ que A_tA^a (Utilice cualquier método de estimación de dominancia) ~~~~~ ▢ ¿Cuáles son los métodos actuales de estimación de ventajas?
6: ~~~~~~ Actualice la política maximizando la función objetivo de PPO-Clip:
~~~~~~~~~~~
θ k + 1 = arg max θ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T mín ( π θ ( en ∣ st ) π θ k ( en ∣ st ) A π θ k ( st , en ) , g ( ϵ , A π θ k ( st , en ) ) ) ~~~~~~~~~~theta_{k+1}=argmaxlimits_thetafrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TminBig(frac{pi_{theta} (a_t|s_t)}{pi_{theta_k}(a_t|s_t)}A^{pi_{theta_k}}(s_t,a_t),g(épsilon,A^{pi_{theta_k}}(s_t,a_t))Grande) θa+1=Arkansasgramoramoramoramoramoramoramoramoramoθmáximo∣Da∣yo1τ∈Da∑a=0∑yomín.(πθa(aa∣sa)πθ(aa∣sa)Aπθa(sa,aa),gramoramoramoramoramoramoramoramoramo(ϵ,Aπθa(sa,aa))) ~~~~~ ▢ ¿Cómo determinar la fórmula de actualización de la estrategia?
~~~~~~~~~~~
~~~~~~~~~~~ π θ k pi_theta_k}πθa : Vector de parámetros de estrategia antes de la actualización. Muestreo de importancia. Muestreo a partir de viejas estrategias.
~~~~~~~~~~~
~~~~~~~~~~~ Ascenso del gradiente estocástico general + Adam
7: ~~~~~~ error cuadrático mediofunción de valor ajustado de regresión:
~~~~~~~~~~~
ϕ k + 1 = arg min ϕ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T ( V ϕ ( st ) − R ^ t ) 2 ~~~~~~~~~~phi_{k+1}=arg minlimits_phifrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TBig(V_phi(s_t)-hat R_tBig)^2 ϕa+1=Arkansasgramoramoramoramoramoramoramoramoramoϕmín.∣Da∣yo1τ∈Da∑a=0∑yo(Vϕ(sa)−R^a)2
~~~~~~~~~~~
~~~~~~~~~~~ Descenso de gradiente general
8: fin para bf fin ~parafin para
~~~~~~~~~~~~
$dots$ … ~~~puntos …
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) AA < 0 g(epsilon,A)=izquierda{(1+ϵ)A A≥0(1−ϵ)AA<0bien. gramoramoramoramoramoramoramoramoramo(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0

en el papelEstimación de ventaja:
A ^ t = − V ( st ) + rt + γ rt + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) ⏟ R ^ t ? ? ? sombrero A_t=-V(s_t)+underbrace{r_t+gamma r_{t+1}+cdots+gamma^{T-t+1}r_{T-1}+gamma^{Tt}V(s_T)}_{textcolor{blue}{sombrero R_t???}}A^a=−V(sa)+R^a??? aa+γaa+1+⋯+γyo−a+1ayo−1+γyo−aV(syo)

hacer Δ t = rt + γ V ( st + 1 ) − V ( st ) Delta_t = r_t + gamma V(s_{t+1})-V(s_t)Δa=aa+yV(sa+1)−V(sa)
pero rt = Δ t − γ V ( st + 1 ) + V ( st ) r_t=Delta_t - gamma V(s_{t+1})+V(s_t)aa=Δa−yV(sa+1)+V(sa)
Sustituto A ^ que A_tA^a expresión
A ^ t = − V ( st ) + rt + γ rt + 1 + γ 2 rt + 2 + ⋯ + γ T − tr T − 2 + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( st ) + Δ t − γ V ( st + 1 ) + V ( st ) + γ ( Δ t + 1 − γ V ( st + 2 ) + V ( st + 1 ) ) + γ 2 ( Δ t + 2 − γ V ( st + 3 ) + V ( st + 1 ) ) + ⋯ + γ T − t ( Δ T − t − γ V ( s T − t + 1 ) + V ( s T − t ) ) + γ T − t + 1 ( Δ T − 1 − γ V ( s T ) + V ( s T − 1 ) ) + γ T − t V ( s T ) = Δ t + γ Δ t + 1 + γ 2 Δ t + 2 + ⋯ + γ T − t Δ T − t + γ T − t + 1 Δ T − 1ˆAa=−V(sa)+aa+γaa+1+γ2aa+2+⋯+γyo−aayo−2+γyo−a+1ayo−1+γyo−aV(syo)=−V(sa)+aa+γaa+1+⋯+γyo−a+1ayo−1+γyo−aV(syo)=−V(sa)+ Δa−γV(sa+1)+V(sa)+ γ(Δa+1−γV(sa+2)+V(sa+1))+ γ2(Δa+2−γV(sa+3)+V(sa+1))+ ⋯+ γyo−a(Δyo−a−γV(syo−a+1)+V(syo−a))+ γyo−a+1(Δyo−1−γV(syo)+V(syo−1))+ γyo−aV(syo)=Δa+γΔa+1+γ2Δa+2+⋯+γyo−aΔyo−a+γyo−a+1Δyo−1 A^a=−V(sa)+aa+γaa+1+γ2aa+2+⋯+γyo−aayo−2+γyo−a+1ayo−1+γyo−aV(syo)=−V(sa)+aa+γaa+1+⋯+γyo−a+1ayo−1+γyo−aV(syo)=−V(sa)+ Δa−yV(sa+1)+V(sa)+ γ(Δa+1−yV(sa+2)+V(sa+1))+ γ2(Δa+2−yV(sa+3)+V(sa+1))+ ⋯+ γyo−a(Δyo−a−yV(syo−a+1)+V(syo−a))+ γyo−a+1(Δyo−1−yV(syo)+V(syo−1))+ γyo−aV(syo)=Δa+γΔa+1+γ2Δa+2+⋯+γyo−aΔyo−a+γyo−a+1Δyo−1

El recorte actúa como un regularizador al eliminar el incentivo para cambios drásticos en las políticas.hiperparámetros épsilonϵ Corresponde a la distancia entre la nueva estrategia y la antigua estrategia.。
Todavía es posible que este tipo de recorte eventualmente dé como resultado una nueva estrategia que esté lejos de la estrategia anterior. En la implementación aquí, utilizamos un método particularmente simple:Deténgase temprano . Si la divergencia KL promedio de la nueva política de la política anterior excede un umbral, dejamos de ejecutar el paso de gradiente.
Enlace de derivación simple de la función objetivo de PPO
La función objetivo de PPO-Clip es:
~
L θ k CLIP ( θ ) = E s , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , clip ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ k ( s , a ) ) ] L^{rm CLIP}_{theta_k}(theta)=subajuste{s, asimtheta_k}{rm E}Bigg[minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}A^{theta_k}(s, a), {rm clip}Grande(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)},1-épsilon, 1+épsilonGrande)A^{theta_k}(s, a)Grande)Grande]yoθaACORTAR(θ)=s,a∼θami[mín.(πθa(a∣s)πθ(a∣s)Aθa(s,a),acortar(πθa(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aθa(s,a))]
~
$underset{s, asimtheta_k}{rm E}$E s , a ∼ θ k ~~~subestimación{s, asimtheta_k}{rm E} s,a∼θami
~
No. yoa Parámetros de estrategia para iteraciones. θ k theta_kθa, épsilonϵ es un pequeño hiperparámetro.
configuración ϵ ∈ ( 0 , 1 ) épsilon(0,1)ϵ∈(0,1), definición
F ( r , A , ϵ ) ≐ min ( r A , clip ( r , 1 − ϵ , 1 + ϵ ) A ) F(r,A,épsilon)doteqminBigg(rA,{rm clip}(r,1-épsilon,1+épsilon)ABigg)F(a,A,ϵ)≐mín.(aA,acortar(a,1−ϵ,1+ϵ)A)
cuando A ≥ 0 Edadq0A≥0
F ( r , A , ϵ ) = min ( r A , clip ( r , 1 − ϵ , 1 + ϵ ) A ) = A min ( r , clip ( r , 1 − ϵ , 1 + ϵ ) ) = A min ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { min ( r , 1 + ϵ ) r ≥ 1 + ϵ min ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) min ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) rr ≤ 1 − ϵ } Según el rango del lado derecho = A min ( r , 1 + ϵ ) = min ( r A , ( 1 + ϵ ) A )begin{alineado}F(r,A,epsilon)&=minBigg(rA,{rm clip}(r,1-epsilon,1+epsilon)ABigg)\ &=AminBigg(r,{rm clip}(r,1-epsilon,1+epsilon)Bigg)\ &=AminBigg(r,left{begin{alineado}&1+epsilon~~&rgeq1+epsilon\ &r &rin(1-epsilon,1+epsilon)\ &1-epsilon &rleq1-epsilon\ end{alineado}derecha}Bigg)\ &=Aizquierda{mín.derecha}\ &=Aizquierda{derecha}~~~~~textcolor{azul}{según el rango de la derecha}\ &=Amin(r, 1+epsilon)\ &=minBigg(rA, (1+epsilon)ABigg) end{aligned} F(a,A,ϵ)=mín.(aA,acortar(a,1−ϵ,1+ϵ)A)=Amín.(a,acortar(a,1−ϵ,1+ϵ))=Amín.(a,⎩ ⎨ ⎧1+ϵ a1−ϵa≥1+ϵa∈(1−ϵ,1+ϵ)a≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧mín.(a,1+ϵ) mín.(a,a)mín.(a,1−ϵ)a≥1+ϵa∈(1−ϵ,1+ϵ)a≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧1+ϵ aaa≥1+ϵa∈(1−ϵ,1+ϵ)a≤1−ϵ⎭ ⎬ ⎫ Según el rango de la derecha=Amín.(a,1+ϵ)=mín.(aA,(1+ϵ)A)
~
cuando A < 0 A < 0A<0
F ( r , A , ϵ ) = min ( r A , clip ( r , 1 − ϵ , 1 + ϵ ) A ) = A max ( r , clip ( r , 1 − ϵ , 1 + ϵ ) ) = A máx ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { máx ( r , 1 + ϵ ) r ≥ 1 + ϵ máx ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) máx ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { r r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } Según el rango del lado derecho = A max ( r , 1 − ϵ ) = min ( r A , ( 1 − ϵ ) A )derecha}Bigg)\ &=Aizquierda{derecha}\ &=Aizquierda{derecha}~~~~~textcolor{azul}{según el rango de la derecha}\ &=Amax(r, 1-epsilon)\ &=textcolor{blue}{min}Bigg(rA,(1-epsilon) ABigg) final {alineado} F(a,A,ϵ)=mín.(aA,acortar(a,1−ϵ,1+ϵ)A)=AmetroetroaX(a,acortar(a,1−ϵ,1+ϵ))=Amáximo(a,⎩ ⎨ ⎧1+ϵ a1−ϵa≥1+ϵa∈(1−ϵ,1+ϵ)a≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧máximo(a,1+ϵ) máximo(a,a)máximo(a,1−ϵ)a≥1+ϵa∈(1−ϵ,1+ϵ)a≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧a a1−ϵa≥1+ϵa∈(1−ϵ,1+ϵ)a≤1−ϵ⎭ ⎬ ⎫ Según el rango de la derecha=Amáximo(a,1−ϵ)=metroetroinorte(aA,(1−ϵ)A)
~
En resumen: definible g ( ϵ , A ) g(épsilon,A)gramoramoramoramoramoramoramoramoramo(ϵ,A)
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) AA < 0 g(epsilon,A)=izquierda{bien. gramoramoramoramoramoramoramoramoramo(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0
¿Por qué esta definición impide que la nueva estrategia se aleje demasiado de la antigua?
Los métodos de muestreo de importancia eficaces requieren nuevas estrategias π θ ( a ∣ s ) pi_theta(a|s)πθ(a∣s) y viejas estrategias π θ k ( a ∣ s ) pi_{theta_k}(a|s)πθa(a∣s) La diferencia entre las dos distribuciones no puede ser demasiado grande.
1. Cuando la ventaja es positiva
L ( s , a , θ k , θ ) = min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 + ϵ ) A π θ k ( s , a ) L(s,a,theta_k, theta)=minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1+epsilonBigg)A^{pi_{theta_k}}(s, a)yo(s,a,θa,θ)=mín.(πθa(a∣s)πθ(a∣s),1+ϵ)Aπθa(s,a)
Función de ventaja: encuentre un determinado par estado-acción con más recompensas -> aumente el peso del par estado-acción.
Cuando un par estado-acción (s, un) (s, un)(s,a) es positivo, entonces si la acción Automóvil club británicoa es más probable que sea ejecutado, es decir, si π θ ( a ∣ s ) pi_theta(a|s)πθ(a∣s) Aumenta y la meta aumentará.
min en este elemento limita la función objetivo para que solo aumente hasta un cierto valor
una vez π θ ( a ∣ s ) > ( 1 + ϵ ) π θ k ( a ∣ s ) pi_theta(a|s)>(1+épsilon)pi_{theta_k}(a|s)πθ(a∣s)>(1+ϵ)πθa(a∣s), disparadores mínimos, lo que limita el valor de este elemento a ( 1 + ϵ ) π θ k ( a ∣ s ) (1+épsilon)pi_{theta_k}(a|s)(1+ϵ)πθa(a∣s)。
La nueva política no se beneficia alejándose de la antigua.
La nueva estrategia no se beneficiará al alejarse de la antigua estrategia.
2. Cuando la ventaja es negativa
L ( s , a , θ k , θ ) = máx ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ ) A π θ k ( s , a ) L(s,a,theta_k, theta)=máxBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1-épsilonBigg)A^{pi_{theta_k}}(s, a)yo(s,a,θa,θ)=máximo(πθa(a∣s)πθ(a∣s),1−ϵ)Aπθa(s,a)
Cuando un par estado-acción (s, un) (s, un)(s,a) La ventaja es negativa, entonces si la acción Automóvil club británicoa es aún menos probable, es decir, si π θ ( a ∣ s ) π_theta(a|s)πθ(a∣s) disminuye, la función objetivo aumentará. Pero el máximo en este término limita cuánto se puede aumentar la función objetivo.
una vez π θ ( a ∣ s ) < ( 1 − ϵ ) π θ k ( a ∣ s ) pi_theta(a|s)<(1-épsilon)pi_{theta_k}(a|s)πθ(a∣s)<(1−ϵ)πθa(a∣s), disparadores máximos, limitando el valor de este elemento a ( 1 − ϵ ) π θ k ( a ∣ s ) (1-épsilon)pi_{theta_k}(a|s)(1−ϵ)πθa(a∣s)。
Una vez más: la nueva política no se beneficia al alejarse mucho de la antigua política.
La nueva estrategia no se beneficiará al alejarse de la antigua estrategia.
Si bien DDPG a veces puede lograr un rendimiento excelente, a menudo es inestable cuando se trata de hiperparámetros y otros tipos de ajuste.
Un modo de falla común de DDPG es que la función Q aprendida comienza a sobreestimar significativamente el valor Q, lo que luego hace que la política falle porque explota el error en la función Q.
Twin Delayed DDPG (TD3) es un algoritmo que resuelve este problema introduciendo tres técnicas clave:
1、Doble Q-Learning truncado。
2、Retraso en la actualización de la política。
3. Suavizado de la estrategia objetivo.
TD3 es un algoritmo fuera de política y sólo se puede utilizar con;continuoEl entorno del espacio de acción.

Algoritmo: TD3
Usar parámetros aleatorios θ 1 , θ 2 , ϕ theta_1, theta_2, fiθ1,θ2,ϕ Inicializar red crítica Q θ 1 , Q θ 2 Q_{theta_1}, Q_{theta_2}Qθ1,Qθ2y red de actores π ϕ pi_phiπϕ
Inicializar la red de destino θ 1 ′ ← θ 1 , θ 2 ′ ← θ 2 , ϕ ′ ← ϕ theta_1^primeleftarrowtheta_1, theta_2^primeleftarrowtheta_2, phi^primeleftarrow phiθ1′←θ1,θ2′←θ2,ϕ′←ϕ
Inicializar el conjunto de búfer de reproducción B cal BB
para t = 1 a T {bf para}~t=1 ~{bf a} ~Tpara a=1 a yo :
~~~~~~ Seleccionar acción con ruido de exploración. a ∼ π ϕ ( s ) + ϵ , ϵ ∼ N ( 0 , σ ) asimpi_phi(s)+epsilon,~~epsilonsim {cal N}(0,sigma)a∼πϕ(s)+ϵ, ϵ∼norte(0,σ), recompensa de observación rra y nuevo estatus s ′ s^primos′
~~~~~~ La tupla de transición ( s , a , r , s ′ ) (s, a,r, s^primo)(s,a,a,s′) depositar a B cal BB medio
~~~~~~ de B cal BB Muestreo de lotes pequeños Eneronorte transiciones ( s , a , r , s ′ ) (s, a, r, s^primo)(s,a,a,s′)
a ~ ← π ϕ ′ ( s ′ ) + ϵ , ϵ ∼ clip ( N ( 0 , σ ~ ) , − c , c ) ~~~~~widetilde aleftarrow pi_{phi^prime}(s^prime)+epsilon,~~epsilonsim{rm clip}({cal N}(0,widetilde sigma),-c,c) a ←πϕ′(s′)+ϵ, ϵ∼acortar(norte(0,σ ),−C,C)
y ← r + γ min i = 1 , 2 Q θ i ′ ( s ′ , a ~ ) ~~~~~~yleftarrow r+gamma minlimits_{i=1,2}Q_{theta_i^prime}(s^prime,widetilde a) y←a+γi=1,2mín.Qθi′(s′,a )
~~~~~~ Actualizar críticos θ i ← arg min θ i N − 1 ∑ ( y − Q θ i ( s , a ) ) 2 theta_ileftarrowargminlimits_{theta_i}N^{-1}suma(y-Q_{theta_i}(s, a))^2θi←Arkansasgramoramoramoramoramoramoramoramoramoθimín.norte−1∑(y−Qθi(s,a))2
~~~~~~ si t % d {bf si}~t~ % ~dsi a % d:
~~~~~~~~~~~ Actualización mediante gradiente de política determinista ϕ phiϕ
∇ ϕ J ( ϕ ) = N − 1 ∑ ∇ a Q θ 1 ( s , a ) ∣ a = π ϕ ( s ) ∇ ϕ π ϕ ( s ) ~~~~~~~~~~~~~~~~nabla _phi J(phi)=N^{-1}sumanabla_aQ_{theta_1}(s, a)|_{a=pi_phi(s)}nabla_phipi_phi(s) ∇ϕYo(ϕ)=norte−1∑∇aQθ1(s,a)∣a=πϕ(s)∇ϕπϕ(s)
~~~~~~~~~~~ Actualizar la red de destino:
θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ ~~~~~~~~~~~~~~~~theta_i^primeleftarrowtautheta_i+(1-tau)theta_i^prime~~~~~ θi′←τθi+(1−τ)θi′ τ tauτ: Tasa de actualización objetivo
ϕ ′ ← τ ϕ + ( 1 − τ ) ϕ ′ ~~~~~~~~~~~~~~~~phi^primeleftarrowtauphi+(1-tau)phi^prime ϕ′←τϕ+(1−τ)ϕ′
fin si ~~~~~~{bf fin ~si} fin si
fin para {bf fin ~para}fin para

Maximizar la entropía de la política, haciéndola más sólida.
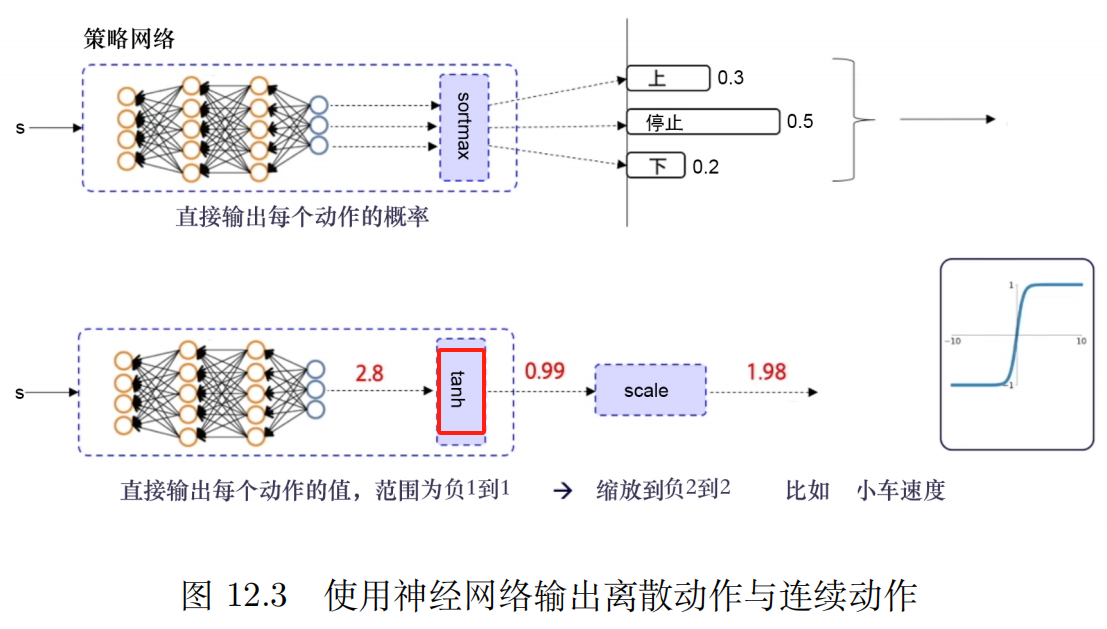
estrategia determinista Significa que ante el mismo estado, siempre eliges la misma acción.
estrategia de aleatoriedad Significa que hay muchas acciones posibles que se pueden seleccionar en un estado determinado.
| estrategia determinista | estrategia de aleatoriedad | |
|---|---|---|
| definición | Mismo estado, realizar la misma acción. | mismo estado,Puede realizar diferentes acciones. |
| ventaja | Estable y repetible | Evite caer en soluciones óptimas locales y mejore las capacidades de búsqueda global |
| defecto | Falta de explorabilidad y facilidad para ser atrapado por los oponentes. | Esto puede hacer que la estrategia converja lentamente, afectando la eficiencia y el rendimiento. |
En la aplicación real, si las condiciones lo permiten,Tratar de usarestrategia de aleatoriedad, como A2C, PPO, etc., porque es más flexible, más robusto y más estable.
El aprendizaje por refuerzo de máxima entropía cree que, aunque actualmente tenemos estrategias de aleatoriedad maduras, es decir, algoritmos como AC, todavía no hemos logrado una aleatoriedad óptima.Por tanto, introduce unaentropía de la informaciónconcepto, enMaximizar la recompensa acumulada mientras se maximiza la entropía de la política., haciendo la estrategia más robusta y logrando la estrategia de aleatoriedad óptima.
——————————————————
Enlace de interfaz OpenAI Documentation_SAC
~
Actor crítico blando: aprendizaje de refuerzo profundo de máxima entropía sin políticas con un actor estocástico, Haarnoja y otros, 201808 ICML 2018
Algoritmos y aplicaciones de actores críticos suaves, Haarnoja y otros, 201901
Aprender a caminar mediante el aprendizaje de refuerzo profundo, Haarnoja y col., 201906 RSS2019
Soft Actor Critic (SAC) optimiza estrategias aleatorias fuera de las políticas.
DDPG + optimización de estrategia estocástica
No es un sucesor directo de TD3 (lanzado aproximadamente al mismo tiempo).
Incorpora el truco de la doble Q recortada y, debido a la aleatoriedad inherente de la estrategia de SAC, en última instancia también se beneficia desuavización de políticas objetivo。
Una característica central de SAC es regularización de entropía regularización de entropía。
La política está entrenada para maximizar el equilibrio entre la recompensa esperada y la entropía,La entropía es una medida de la aleatoriedad de una política.。
Esto está estrechamente relacionado con el equilibrio entre exploración y explotación: un aumento de la entropía conduce aMás para explorar,esto esta bienAcelerar el aprendizaje posterior .está bienEvitar que la política converja prematuramente hacia un mal óptimo local.。
Se puede utilizar tanto en espacios de acción continuos como en espacios de acciones discretas.
existir Aprendizaje por refuerzo regularizado por entropía, el agente obtiene yLa entropía de la política en este paso de tiempo.Recompensas proporcionales.
En este momento el problema de RL se describe como:
π ∗ = arg max π E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ] pi^*=argmaxlimits_pi underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})textcolor{blue}{+alpha H(pi(·|s_t))}Big)Big]π∗=Arkansasgramoramoramoramoramoramoramoramoramoπmáximoτ∼πmi[a=0∑∞γa(R(sa,aa,sa+1)+αyo(π(⋅∣sa)))]
en α > 0 alfa > 0α>0 es el coeficiente de compensación.
Función de valor estatal que incluye recompensa de entropía en cada paso de tiempo V π V^piVπ para:
V π ( s ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s ] V^pi(s)=subconjunto{tausimpi}{rm E}Grande[sumalímites_{t=0}^inftygamma^tGrande(R(s_t,a_t,s_{t+1})+alfa H(pi(·|s_t))Grande)Grande|s_0=sGrande]Vπ(s)=τ∼πmi[a=0∑∞γa(R(sa,aa,sa+1)+αyo(π(⋅∣sa))) s0=s]
Una función de valor de acción que incluye la recompensa de entropía para cada paso de tiempo excepto el primer paso de tiempo. Q π Q^piQπ:
Q π ( s , a ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α ∑ t = 1 ∞ H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s , a 0 = a ] Q^pi(s,a)=subconjunto{tausimpi}{rm E}Big[sumalímites_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})+alfa sumalímites_{t=1}^infty H(pi(·|s_t))Big)Big|s_0=s,a_0=aBig]Qπ(s,a)=τ∼πmi[a=0∑∞γa(R(sa,aa,sa+1)+αa=1∑∞yo(π(⋅∣sa))) s0=s,a0=a]
V π V^piVπ y Q π Q^piQπ La relación entre es:
V π ( s ) = E a ∼ π [ Q π ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) V^pi(s)=subconjunto{asimpi}{rm E}[Q^pi(s, a)]+alfa H(pi(·|s))Vπ(s)=a∼πmi[Qπ(s,a)]+αyo(π(⋅∣s))
acerca de Q π Q^piQπ La fórmula de Bellman es:
Q π ( s , a ) = E s ′ ∼ P a ′ ∼ π [ R ( s , a , s ′ ) + γ ( Q π ( s ′ , a ′ ) + α H ( π ( ⋅ ∣ s ′ ) ) ) ] = E s ′ ∼ P [ R ( s , a , s ′ ) + γ V π ( s ′ ) ] Qπ(s,a)=a′∼πs′∼PAGAGmi[R(s,a,s′)+γ(Qπ(s′,a′)+αyo(π(⋅∣s′)))]=s′∼PAGAGmi[R(s,a,s′)+γVπ(s′)]
SAC aprende una política simultáneamente π θ π_thetaπθ y dos QQQ función Q ϕ 1 , Q ϕ 2 Q_{phi_1}, Q_{phi_2}Qϕ1,Qϕ2。
Actualmente existen dos variantes del SAC estándar: una utiliza un sistema fijoCoeficiente de regularización de entropía alfaα, otro cambiando durante el entrenamiento alfaα para imponer restricciones de entropía.
La documentación de OpenAI utiliza una versión con un coeficiente de regularización de entropía fijo, pero en la práctica suele preferirserestricción de entropíavariante.
Como se muestra a continuación, en alfaα En la versión fija, a excepción de la última imagen que tiene ventajas obvias, las demás solo tienen ligeras ventajas, básicamente las mismas que alfaα La versión de aprendizaje sigue siendo la misma; alfaα Las dos imágenes del medio donde la versión de aprendizaje tiene ventajas son más obvias.
SACContraTD3:
~
Mismo punto:
1. Ambas funciones Q se aprenden minimizando MSBE (error cuadrático medio de Bellman) mediante regresión a un único objetivo compartido.
2. Utilice la red Q objetivo para calcular el objetivo compartido y realice un promedio Polyak en los parámetros de la red Q durante el proceso de entrenamiento para obtener la red Q objetivo.
3. El objetivo compartido utiliza la técnica de la doble Q truncada.
~
diferencia:
1. SAC contiene un término de regularización de entropía
2. La siguiente acción estatal utilizada en el objetivo del SAC proviene deEstrategia actual, en lugar de la estrategia objetivo.
3. No existe una estrategia objetivo clara para la suavización. TD3 entrena una política determinista a través de acciones hacia el próximo estadoAgregar ruido aleatorio para lograr suavidad. SAC entrena una política aleatoria y el ruido de la aleatoriedad es suficiente para lograr efectos similares.

Algoritmo: SAC actor-crítico suave
ingresar: θ 1 , θ 2 , ϕ theta_1,theta_2,phi~~~~~θ1,θ2,ϕ Parámetros de inicialización
Inicialización de parámetros:
~~~~~~ Inicialice los pesos de la red de destino: θ ˉ 1 ← θ 1 , θ ˉ 2 ← θ 2 barra theta_1flecha izquierdatheta_1, barra theta_2flecha izquierdatheta_2θˉ1←θ1,θˉ2←θ2
~~~~~~ El grupo de reproducción se inicializa para que esté vacío: D ← ∅ {cal D}flecha izquierdaconjunto vacíoD←∅
para {bf para}para cada iteración hacer {bf hacer}hacer :
~~~~~~ para {bf para}para Cada paso del entorno hacer {bf hacer}hacer :
~~~~~~~~~~~ Acciones de ejemplo de una política: en ∼ π ϕ ( en ∣ st ) a_tsimpi_phi(a_t|s_t)~~~~~aa∼πϕ(aa∣sa) ▢Aquí π ϕ ( en ∣ st ) pi_phi(a_t|s_t)πϕ(aa∣sa) ¿Cómo definir?
~~~~~~~~~~~ Ejemplos de transiciones del entorno: st + 1 ∼ p ( st + 1 ∣ st , en ) s_{t+1}sim p(s_{t+1}|s_t,a_t)sa+1∼pag(sa+1∣sa,aa)
~~~~~~~~~~~ Guarde la transición al grupo de reproducción: D ← D ∪ { ( st , a , r ( st , a ) , st + 1 ) } {cal D}leftarrow{cal D}~cup~{(s_t,a_t,r(s_t,a_t),s_{t+1})}D←D ∪ {(sa,aa,a(sa,aa),sa+1)}
~~~~~~ fin para {bf fin ~para}fin para
~~~~~~ para {bf para}para Cada paso de gradiente hacer {bf hacer}hacer :
~~~~~~~~~~~ renovar QQQ Parámetros de función: para yo ∈ { 1 , 2 } yo en {1,2}i∈{1,2}, θ i ← θ i − λ Q ∇ ^ θ i JQ ( θ i ) theta_ileftarrowtheta_i-lambda_Qque es la expresión de la ecuación (theta_i) de J_Q(theta_i)~~~~~θi←θi−λQ∇^θiYoQ(θi) ▢Aquí JQ (θ i) J_Q(theta_i)YoQ(θi) ¿Cómo definir?
~~~~~~~~~~~ Actualizar pesos de estrategia: ϕ ← ϕ − λ π ∇ ^ ϕ J π ( ϕ ) phileftarrowphi-lambda_pihat nabla_phi J_pi (phi)~~~~~ϕ←ϕ−λπ∇^ϕYoπ(ϕ) ▢Aquí J π ( ϕ ) J_pi (phi)Yoπ(ϕ) ¿Cómo definir?
~~~~~~~~~~~ Ajustar la temperatura: α ← α − λ ∇ ^ α J ( α ) alphaleftarrowalpha-lambdahatnabla_alpha J(alfa)~~~~~α←α−λ∇^αYo(α) ▢Aquí J ( α ) J(alfa)Yo(α) ¿Cómo definir?¿Cómo entender la temperatura aquí?
~~~~~~~~~~~ Actualizar pesos de red de destino: para yo ∈ { 1 , 2 } yo en {1,2}i∈{1,2}, θ ˉ i ← τ θ i − ( 1 − τ ) θ ˉ i barra theta_ileftarrow tau theta_i-(1-tau)barra theta_i~~~~~θˉi←τθi−(1−τ)θˉi ▢ Cómo entender esto τ tauτ ? ——>Coeficiente de suavizado objetivo
~~~~~~ fin para {bf fin ~para}fin para
fin para {bf fin ~para}fin para
Producción: θ 1 , θ 1 , ϕ theta_1,theta_1,phi~~~~~θ1,θ1,ϕ Parámetros optimizados
∇ ^ sombrero nabla∇^: gradiente estocástico
$emptyset$ ∅ ~~~~conjunto vacío ∅


Aprender a caminar mediante el aprendizaje de refuerzo profundo Versión en:
~
α
α
α es el parámetro de temperatura, que determina la importancia relativa del término de entropía y la recompensa, controlando así la aleatoriedad de la estrategia óptima.
alfaα Grande: explorar
alfaα Pequeño: explotar
J ( α ) = E en ∼ π t [ − α log π t ( en ∣ st ) − α H ˉ ] J(alfa)=subconjunto{a_tsimpi_t}{mathbb E}[-alfalog pi_t(a_t|s_t)-alfabar{cal H}]Yo(α)=aa∼πami[−αLogramoramoramoramoramoramoramoramoramoπa(aa∣sa)−αyoˉ]

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]