2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
- facile ri PDF version notare organization P5, P10 - P12
- joyrl comparationis supplementum P11-P13
- OpenAI documentum norma https://spinningup.openai.com/en/latest/index.html


Ultimae versionis PDF download
Oratio: https://github.com/datawhalechina/easy-rl/releases
Oratio domestica (commendatur lectoribus domesticis):
Link: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw Extraction code: us6a
facile-ri online version link (exemplum codice)
Relatio link 2: https://datawhalechina.github.io/joyrl-book/
alius;
[Errata record link]
——————
5. Basics of altum subsidii cognita
Aperto fonte contentum: https://linklearner.com/learn/summary/11
——————————
Consilium idem agens: Agens ad cognoscendum et agens interacting cum ambitu idem sunt.
Insidijs heterogeneis: agens ad discendum et agens commercium cum ambitu inter se differentes
Consilium Gradiente: requirit multum tempus sample data
eodem consilio ⟹ momentum sampling ~~~overset{Importance sampling}{Longrightarrow}~~~ ⟹momenti sampling alia consilia
PPO: Vitare duas distributiones quae nimium differunt. eodem consilio algorithmus
1. Originale ipsum items J ( θ , θ ) J (theta, theta^prima)J(θ,θ′)
2. Coaint items: θ thetaθ et θ theta^primeθ′ KL distinctio actionis output θ thetaθ et θ theta^primeθ′ quo similior melior)
PPO decessorem habet: fiducia regionis consilium optimiization (TRPO)
TRPO tractari difficile est, quia de KL disiunctionem coercitionem additivam coactionem tractat et in functione obiectiva non ponitur, ideo computare difficile est. Itaque vulgo pro TRPO PPO utimur. Effectus PPO et TRPO similes sunt, sed PPO multo facilius est ad efficiendum quam TRPO.
KL distinctio: distantia agendi.Probabilitas distributionem faciendo actionem procul.
Duae sunt praecipuae variantes algorithmi PPO: consilium proximale optimization poena (PPO-poena) et consilium proximalis optimiizationis detonsio (PPO-clip).
——————————
P10 Sparse praemium quaestio
1. Dedo praemia. Scientia requirit domain
Quid de ultimo praemio ad singulas actiones pertinentes assignare?
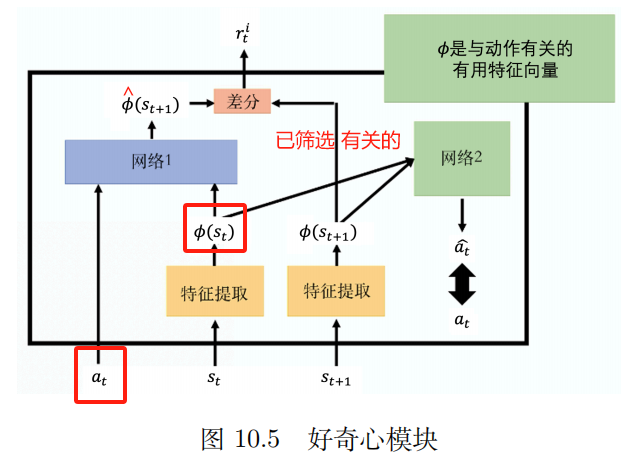
2. Curiositas
Curiositas intrinseca moduli (ICM)
introire; at , st a_t , s_tat,st
Output: s^ t + 1 hat s_{t+1}s^t+1
Predicta valorem de network s^ t + 1 hat s_{t+1}s^t+1 cum vero valorem st + 1 s_{t+1}st+1 Magis dissimiles sunt, rti r_t ^ i *r*******************************************************************************tego Maior
rti r_t ^ i *r*******************************************************************************tego Difficilior res publica futura praedicit, eo maior merces est. Ac exploratio robora casus.
pluma extractor
Retis 2:
Input: vector ( st ) {bm phi}(s_{t})ϕ(st) et ( st + 1 ) {bm phi}(s_{t+1})ϕ(st+1)
Praedic actio a^ hat aSa^ Quo propius ad rem agendam melior.
3. cursus studio
Securus -> Difficilis
Curriculum discendi inversa;
Proficiscens ab ultimo statu optimo maximo, iReperio publica proxima ad statum aureum Sicut a ridiculo "ideale" dicitur quod vis agentis attingere. Nempe in hoc processu aliquos status extremas ex intentione removebimus, id est, res nimis faciles vel nimis difficiles.
4. supplementum doctrinale hierarchicum (HRL)
Agens consilium dividitur in consilia alta et humili gradu consilia.
————————
P11 doctrina Imitatio
Non certa circa praemium scaena
Imitatio discendi (IL)
doctrina ex demonstratione
Tirocinium doctrina
doctrina a vigilantes
Luculenta sunt praemia: tabulae ludi, ludos video
Praemia clara dare non possunt: chatbot
Collige demonstrationes peritos: monumenta incessus humana, colloquia humana
Inverse quale praemium munus accipit has actiones peritus?
Auxilia inversa doctrina estPrimum munus invenire praemiumPost munus munus nactus, supplementum studiorum ad meliorem actorem invenire.
Tertius homo imitatio doctrinarum technologiarum
————————
Profundum deterministic consilium CLIVUS P12 (DDPG)
Usus belli replay experientia
Ablatio Experimenti [Modus Controlled Variabilis] Analysisomni necessitateeventum pugnae infringere.
joyrl:
in inopiacertitudoet bellicontinua actioSub praemissa spatio algorithmus hoc genus algorithmus basi relative stabilis erit.
DQN ad continuam actionem spatia
Algorithmus in altum consilium deterministic gradiente (DDPG)
Experientia remonstrandi mechanismum reducere potest ad comparationem inter exempla, efficaciam exemplorum usum emendare et stabilitatem institutionis augere.
Defectus;
1. non potest esse in discreta actio spatium
2、Maxime dependens hyperparametris
3. Valde sensitivae condiciones initiales. Afficit concursum et observantiam algorithmi
4. Facile est in loci optimum cadere.
Commodum mollium renovationum est quod levius est et tardius, quae potest vitare impulsus per nimias celeritatis momenta et periculum disciplinae discrepantiae minuere.
Duplex mora consilium deterministicum gradiente algorithmus
Tres emendationes: Duplex Q retis, renovatio morata, strepitus regularization
Duplex Q Network : Duo Q retiacula, elige unum cum valore minore Q. Agere de superestimatione problematis Q valoris et stabilitatis et concursus algorithmi melioris.
Dilatio renovatio: Actor renovatio frequency ut minor sit quam renovatio critica frequency
Sonus similior estOrdinationisita utvalorem munus updateplussmooth
OpenAI Gym Library_Pendulum_TD3
Documentum OpenAI de nexus interface TD3
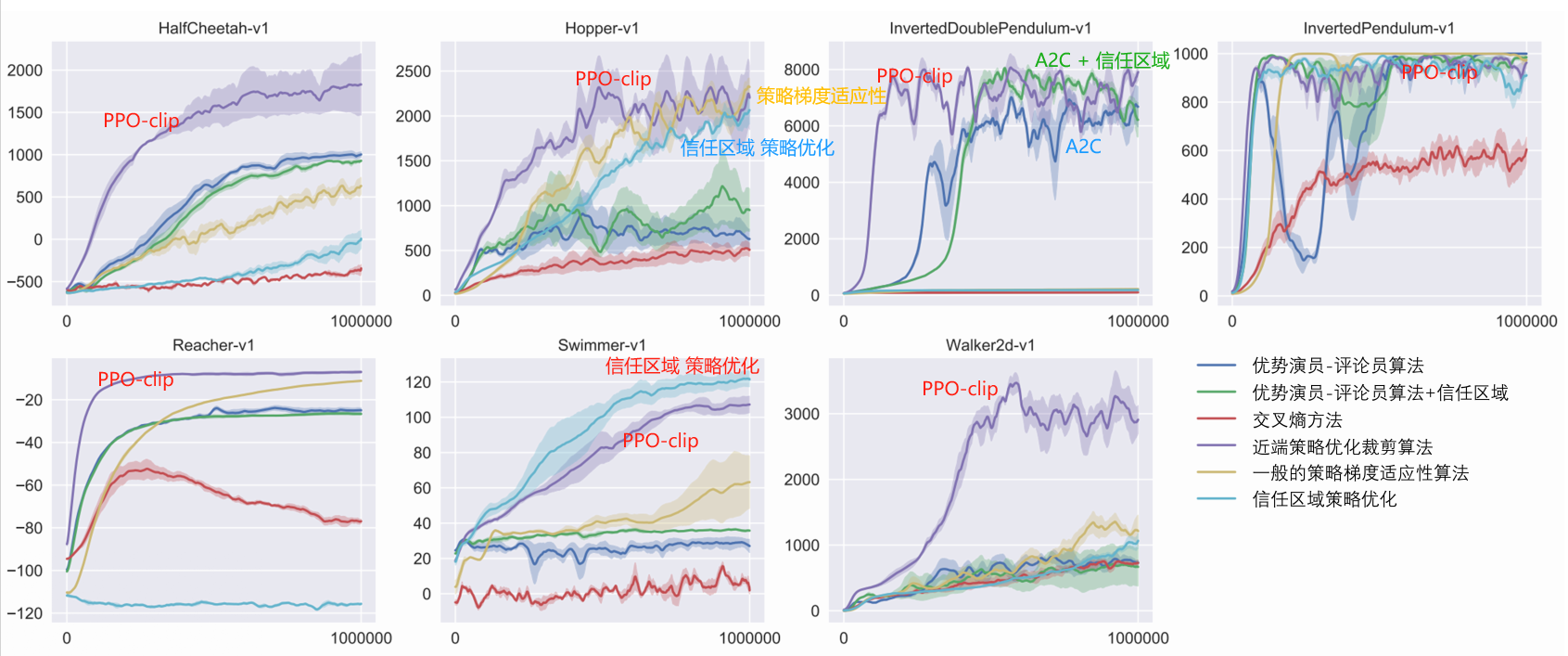
Frequentissime PPO algorithmus in supplementi studiorum usus est
Discreta + continua
Jejunium et stabile, facile parametris accommodare
collocantur algorithmus
anceps PPO
In praxi, cohibere angustias plerumque adhibentur, quia simplicior est, inferiores sumptus computationales et meliores proventus habet.
In off-consilium algorithmus canutantur historica experientiaplerumque usu remonstrandi usus est ad reponendas ac reuse peritia praecedens;Data utendo efficientiam est princeps。
PPO est on-consilium algorithmus
——————————————————
OpenAI Documenta
Paper arXiv interface link: Proximal Policy Optimization Algorithms
PPO: algorithmus on-consilium, ad discreta vel continua actionis spatia apta.Maxime loci fieri
Causa PPO idem est ac TRPO: quomodo leverage existens notitiaUt maximus gradus fieri potest emendationem in bellisine mutando nimis et fortuito faciens fragorem?
TRPO hanc quaestionem solvere conatur cum accessione secundi ordinis sapientissimi, dum PPO est ordo primi ordinis qui utitur quibusdam aliis technis ad novum consilium proxime antiquum custodiendum.
PPO methodus multo simplicior est ad efficiendum et empirice faciendum saltem ac TRPO.
Duae sunt differentiae principales PPO: PPO-Poena et PPO-Clip.


Algorithmus: PPO-Clip
I: Input: parametri belli initial θ 0 theta_0θ0, Munus valorem parametri 0 phi_0ϕ0
2: pro k = 0 , 1 , 2 , ... fac {bf pro } ~ k=0,1,2, dots~ {bf do}for********** k=0,1,2,… do:
3: ~~~~~~ Per consilium currit in environment π k = π (θ k ) pi_k=pi(theta_k)πk=π(θk) Collecta trajectoriam posuit D k = { τ i } {cal D}_k={tau_i}Dk={τego}
4: ~~~~~~ Praemia computare (praemia ut- ite) R^t hat R_t~~~~~R^t ▢ R^t proni R_tR^t calculi praecepta
5: ~~~~~~ Computo commodum aestimandum, ex valore currenti functionis V k V_{phi_k}Vϕk of* A^t hat A_tA^t (Utere aliqua aestimatione dominatum modum) ~~~~~ Quae sunt hodiernae commoda aestimationis modi?
6: ~~~~~~ Renova consilium ab maximising PPO-Clip munus obiectivum:
~~~~~~~~~~~
θ k + 1 = arg max θ 1 D k ∣ T ∑ τ ∈ D k ∑ t = 0 T min ( π θ ( at st ) π θ k ( at st ) A π θ k ( st. ) , g ( , A π θ k ( st , at ) ) ~~~~~~~~~~~ theta_{k+1}=argmaxlimits_thetafrac{1}{|{cal D}_k|T } sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TminBig(frac{pi_{theta} (a_t|s_t)}{pi_{theta_k}(a_t|s_t)}A^{pi_{theta_k}} (s_t,a_t),g(epsilon,A^{pi_{theta_k}}(s_t,a_t))Big) θk+1=arg*********θmax∣Dk∣T1τ∈Dk∑t=0∑Tmin(πθk(at∣st)πθ(at∣st)Aπθk(st,at),g*********(ϵ,Aπθk(st,at))) ~~~~~ Quomodo definire renovationem belli formulam?
~~~~~~~~~~~
~~~~~~~~~~~ π θ k pi_ theta_k}πθk : Consilium parametri vectoris ante renovationem. Sampling momentum. Sampling ab antiquis insidijs.
~~~~~~~~~~~
~~~~~~~~~~~ General Stochastic Gradiente Ascensu + Adam
7: ~~~~~~ quadrata medium errorisprocedere valorem aptavit munus:
~~~~~~~~~~~
k + 1 = arg min 1 D k ∣ T ∑ τ D k ∑ t = 0 T ( V ( st ) R ^ t ) 2 ~~~~~~~~~~~~~ phi_ {k+1}=arg minlimits_phifrac{1}{|{cal D}_k|T} sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TBig(V_phi(s_t)-hat R_tBig)^2 ϕk+1=arg*********ϕmin∣Dk∣T1τ∈Dk∑t=0∑T(Vϕ(st)−R^t)2
~~~~~~~~~~~
~~~~~~~~~~~ General descensus
8: finem pro bf finem ~ forfinis for**********
~~~~~~~~~~~~
$dots$ ... ~~~ dots …
g ( , A ) = { ( 1 + ) A ≥ 0 ( 1 ) AA < 0 g(epsilon,A)=relictum{(1+ϵ)A A≥0(1−ϵ)AA<0ius. g*********(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0

in chartaUtilitas aestimatio:
A ^ t = V ( st ) + rt + γ rt + 1 + + γ T t + 1 r T − 1 + γ T t V ( s T ) ⏟ R ^ t ? ? ? hat A_t=-V(s_t)+subbrace{r_t+gamma r_{t+1}+cdots+gamma^{T-t+1}r_{T-1}+gamma^{Tt}V(s_T)}_ {textcolor{hyacintho}{hat R_t???}}A^t=−V(st)+R^t??? r*******************************************************************************t+γr*******************************************************************************t+1+⋯+γT−t+1r*******************************************************************************T−1+γT−tV(sT)

facere t = rt + γ V ( st + 1 ) − V ( st ) Delta_t = r_t+gamma V(s_{t+1})-V(s_t)Δt=r*******************************************************************************t+γV(st+1)−V(st)
sed rt = Δ t γ γ V ( st + 1 ) + V ( st ) r_t= Delta_t - gamma V(s_{t+1})+V(s_t)r*******************************************************************************t=Δt−γV(st+1)+V(st)
Substitutus A^t hat A_tA^t expressio
A ^ t = − V ( st ) + rt + γ rt + 1 + γ 2 rt + 2 + + γ T tr T − 2 + γ T t + 1 r T 1 + γ T − t V (. s T ) = V ( st ) + rt + γ rt + 1 + + γ T − t + 1 r T − 1 + γ T t V ( s T ) = − V ( st ) + t γ V ( st + 1 ) + V ( st ) + γ ( t + 1 γ V ( st + 2 ) + V ( st + 1 ) ) + γ 2 ( t + 2 γ V ( st + 3 ) + V ( st + 1 ) ) + γ T t ( T t γ V ( s T t + 1 ) + V ( s T t ) ) + γ T t + 1 ( T . 1 γ V ( s T ) + V ( s T 1 ) + γ T t V ( s T ) = Δ t + γ Δ t + 1 + γ 2 t + 2 + + γ T − t T t + γ T − t + 1 T 1ˆAt=−V(st)+r*******************************************************************************t+γr*******************************************************************************t+1+γ2r*******************************************************************************t+2+⋯+γT−tr*******************************************************************************T−2+γT−t+1r*******************************************************************************T−1+γT−tV(sT)=−V(st)+r*******************************************************************************t+γr*******************************************************************************t+1+⋯+γT−t+1r*******************************************************************************T−1+γT−tV(sT)=−V(st)+ Δt−γV(st+1)+V(st)+ γ(Δt+1−γV(st+2)+V(st+1))+ γ2(Δt+2−γV(st+3)+V(st+1))+ ⋯+ γT−t(ΔT−t−γV(sT−t+1)+V(sT−t))+ γT−t+1(ΔT−1−γV(sT)+V(sT−1))+ γT−tV(sT)=Δt+γΔt+1+γ2Δt+2+⋯+γT−tΔT−t+γT−t+1ΔT−1 A^t=−V(st)+r*******************************************************************************t+γr*******************************************************************************t+1+γ2r*******************************************************************************t+2+⋯+γT−tr*******************************************************************************T−2+γT−t+1r*******************************************************************************T−1+γT−tV(sT)=−V(st)+r*******************************************************************************t+γr*******************************************************************************t+1+⋯+γT−t+1r*******************************************************************************T−1+γT−tV(sT)=−V(st)+ Δt−γV(st+1)+V(st)+ γ(Δt+1−γV(st+2)+V(st+1))+ γ2(Δt+2−γV(st+3)+V(st+1))+ ⋯+ γT−t(ΔT−t−γV(sT−t+1)+V(sT−t))+ γT−t+1(ΔT−1−γV(sT)+V(sT−1))+ γT−tV(sT)=Δt+γΔt+1+γ2Δt+2+⋯+γT−tΔT−t+γT−t+1ΔT−1

Tonsio fungitur ordinatoris subtrahendo incitamentum ad mutationes acris consilii.hyperparameters epsilonϵ Respondet distantiae inter novum consilium et consilium vetus。
Potest tamen fieri ut hoc genus detonsionis tandem eveniat in novo consilio, quod longe est a consilio veteri.Subsisto diluculo . Si mediocris KL-diversitas novi consilii a vetere consilio limen excedit, gradatim progredi prohibemus.
PPO munus obiectivum simplex derivatio paginae
Munus obiectivum PPO-Clip est:
~
L θ k CLIP ( θ ) = E s , a θ k [ min ( π θ ( a s ) π θ k ( a s ) A θ k ( s , a ) , clip ( π θ ( a ) s ) π θ k ( a s ) , 1 , 1 + ) A θ k ( s , a ) ] L^{rm CLIP}_{theta_k}(theta)=underset{s, asimtheta_k}{ rm E}Bigg[minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}A^{theta_k}(s, a), {rm clip}Big(frac{pi_theta(a| s)}{pi_{theta_k}(a|s)},1-epsilon, 1+epsilonBig)A^{theta_k}(s, a)Bigg]LθkCLIP(θ)=s,a∼θkE[min(πθk(a∣s)πθ(a∣s)Aθk(s,a),tonde(πθk(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aθk(s,a))]
~
$underset{s, asimtheta_k}{rm E}$E s , a θ k ~~~intellectus{s, asimtheta_k}{rm E} s,a∼θkE
~
Nec. kkk Belli parametri iterations θ k theta_kθk, epsilonϵ hyperparameter parvum est.
extruxerat ( 0 , 1) epsilonin (0,1)ϵ∈(0,1), definition
F ( r , A , ) min ( r A , clip ( r , 1 , 1 + ) A ) F(r,A,epsilon)doteqminBigg(rA,{rm clip}(r,1- epsilon,1+epsilon)ABigg)F(r*******************************************************************************,A,ϵ)≐min(r*******************************************************************************A,tonde(r*******************************************************************************,1−ϵ,1+ϵ)A)
quando A ≥ 0 Ageq0A≥0
F ( r , A , ) = min ( r A , clip ( r , 1 , 1 + ) A ) = A min ( r , clip ( r , 1 , 1 + ) ) = A min ( r , { 1 + r ≥ 1 + rr ( 1 , 1 + ) 1 r ≤ 1 } ) = A { min (r, 1 + ) r ≥. 1 + min ( r , r ) r ( 1 , 1 + ) min ( r , 1 ) r ≤ 1 } = A { 1 + r ≥ 1 + rr ∈ (. 1 , 1 + ) rr ≤ 1 } Secundum latitudinem ad latus dextrum = A min ( r , 1 + ) = min ( r A , ( 1 + ) A )incipiunt{aligned}F(r,A,epsilon)&=minBigg(rA,{rm clip}(r,1-epsilon,1+epsilon)ABigg)\ &=AminBigg(r,{rm clip}(r,1 -epsilon,1+epsilon)Bigg)\ &=AminBigg(r,left{incipe{aligned}&1+epsilon~~&rgeq1+epsilon\ &r &rin(1-epsilon,1+epsilon)\ &1-epsilon &rleq1-epsilon\ finisright}Bigg)\ &=Aleft{minius}\ &=Aleft{ius}~~~~~ textcolor{hyacinthinum}{iuxta latitudinem a dextra}\ &=Amin(r, 1+epsilon)\ &=minBigg(rA, (1+epsilon)ABigg) finis{aligned} F(r*******************************************************************************,A,ϵ)=min(r*******************************************************************************A,tonde(r*******************************************************************************,1−ϵ,1+ϵ)A)=Amin(r*******************************************************************************,tonde(r*******************************************************************************,1−ϵ,1+ϵ))=Amin(r*******************************************************************************,⎩ ⎨ ⎧1+ϵ r*******************************************************************************1−ϵr*******************************************************************************≥1+ϵr*******************************************************************************∈(1−ϵ,1+ϵ)r*******************************************************************************≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧min(r*******************************************************************************,1+ϵ) min(r*******************************************************************************,r*******************************************************************************)min(r*******************************************************************************,1−ϵ)r*******************************************************************************≥1+ϵr*******************************************************************************∈(1−ϵ,1+ϵ)r*******************************************************************************≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧1+ϵ r*******************************************************************************r*******************************************************************************r*******************************************************************************≥1+ϵr*******************************************************************************∈(1−ϵ,1+ϵ)r*******************************************************************************≤1−ϵ⎭ ⎬ ⎫ Secundum range in dextro=Amin(r*******************************************************************************,1+ϵ)=min(r*******************************************************************************A,(1+ϵ)A)
~
quando A <0 A<0A<0
F ( r , A , ) = min ( r A , clip ( r , 1 , 1 + ) A ) = A max ( r , clip ( r , 1 , 1 + ) ) = A max ( r , { 1 + r ≥ 1 + rr ( 1 , 1 + ) 1 r ≤ 1 } ) = A { max ( r , 1 + ) r ≥ 1 + max ( r , r ) r ( 1 , 1 + ) max ( r , 1 ) r ≤ 1 } = A { r r ≥ 1 + rr ∈ ( 1 . , 1 + ) 1 r ≤ 1 } Secundum extensionem a dextra parte = A max ( r , 1 ) = min ( r A , ( 1 ) A )right}Bigg)\ &=Aleft{ius}\ &=Aleft{ius}~~~~~ textcolor{hyacinthinum}{iuxta ius}\ &=Amax(r, 1-epsilon)\ &=textcolor{hyacinthinum}{min}Bigg(rA,(1-epsilon) ABigg) finis F(r*******************************************************************************,A,ϵ)=min(r*******************************************************************************A,tonde(r*******************************************************************************,1−ϵ,1+ϵ)A)=Amax*(r*******************************************************************************,tonde(r*******************************************************************************,1−ϵ,1+ϵ))=Amax(r*******************************************************************************,⎩ ⎨ ⎧1+ϵ r*******************************************************************************1−ϵr*******************************************************************************≥1+ϵr*******************************************************************************∈(1−ϵ,1+ϵ)r*******************************************************************************≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧max(r*******************************************************************************,1+ϵ) max(r*******************************************************************************,r*******************************************************************************)max(r*******************************************************************************,1−ϵ)r*******************************************************************************≥1+ϵr*******************************************************************************∈(1−ϵ,1+ϵ)r*******************************************************************************≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧r******************************************************************************* r*******************************************************************************1−ϵr*******************************************************************************≥1+ϵr*******************************************************************************∈(1−ϵ,1+ϵ)r*******************************************************************************≤1−ϵ⎭ ⎬ ⎫ Secundum range in dextro=Amax(r*******************************************************************************,1−ϵ)=megon(r*******************************************************************************A,(1−ϵ)A)
~
Perorare: quidd g ( , A ) g (epsilon, A)g*********(ϵ,A)
g ( , A ) = { ( 1 + ) A ≥ 0 ( 1 ) AA < 0 g(epsilon,A)=relictum{ius. g*********(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0
Cur haec definitio impedit novum consilium ne a consilio antiquo longius evadat?
Efficax momenti sampling modi novas strategies require π θ ( a s ) pi_theta(a|s)πθ(a∣s) et vetera consilia π θ k ( a s ) pi_{theta_k}(a|s)πθk(a∣s) Differentia duarum distributionum nimis magna esse non potest
1. Cum utilitas affirmativa
L ( s , a , θ k , θ ) = min ( π θ ( a s ) π θ k ( a s ) , 1 + ) A π θ k ( s , a ) L ( s , a ; theta_k, theta)=minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1+epsilonBigg)A^{pi_{theta_k}}(s, a)L(s,a,θk,θ)=min(πθk(a∣s)πθ(a∣s),1+ϵ)Aπθk(s,a)
Munus commodum: Invenire certas actiones par cum pluribus praemiis -> auge pondus status-actionis par.
Cum status-actio par ( s , a )(s,a) positivum, si actio aaa supplicium verisimilius est, i.e π θ ( a s ) pi_theta(a|s)πθ(a∣s) Augeatur et augebit finis.
min in hac item munus obiectivum limitat ad certum valorem tantum augendum
semel π θ ( a s ) > ( 1 + ) π θ k ( a s ) pi_theta(a|s)>(1+epsilon) pi_{theta_k}(a|s)πθ(a∣s)>(1+ϵ)πθk(a∣s), min triggers, valorem item to huius limitis ( 1 + ϵ ) π θ k (a s ) (1+epsilon) pi_{theta_k}(a|s)(1+ϵ)πθk(a∣s)。
non prosit nova consilia longe a vetere consilio eundo.
Novum consilium ab antiquo consilio regredi non prodest.
2. Cum utilitas negativa
L ( s , a , θ k , θ ) = max ( π θ ( a s ) π θ k ( a s ) , 1 ) A π θ k ( s , a ) L ( s , a ; theta_k, theta)=maxBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1-epsilonBigg)A^{pi_{theta_k}}(s, a)L(s,a,θk,θ)=max(πθk(a∣s)πθ(a∣s),1−ϵ)Aπθk(s,a)
Cum status-actio par ( s , a )(s,a) Utilitas negativa est, si actio aaa id est, si π θ ( a s ) π_theta(a|s)πθ(a∣s) diminui, munus obiectivum augere. Max autem in hoc termino limites quantum munus obiectivum augeri potest.
semel π θ ( a s ) < ( 1 ) π θ k ( a s ) pi_theta(a|s)<(1-epsilon) pi_{theta_k}(a|s)πθ(a∣s)<(1−ϵ)πθk(a∣s), triggers max, valore huius item in limitando ( 1 ) π θ k ( a s ) (1-epsilon) pi_{theta_k}(a|s)(1−ϵ)πθk(a∣s)。
Item: Novum consilium non prodest longe abesse a vetere consilio.
Novum consilium ab antiquo consilio regredi non prodest.
Dum DDPG interdum excellentem observantiam consequi potest, saepe instabilis est cum ad hyperparametris et alias species incedit.
Communis DDPG defectus modus est quod doctus Q munus incipit signanter aestimare valorem Q, quod tunc consilium frangere facit quod errorem in Q functione gerit.
Didymus Moratus DDPG (TD3) est algorithmus qui hanc quaestionem solvit tribus technicis clavis inductis:
1、Truncata duplex Q Doctrina。
2、Consilium update mora。
3. Scopum consiliorum delenimenta.
TD3 algorithmus off-consilium est;continuusAmbitu actionis spatium.

Algorithmus: TD3
Utere temere parametri θ 1 , θ 2 , theta_1, theta_2, phiθ1,θ2,ϕ Initialize critica network Q θ 1 , Q θ 2 Q_{theta_1}, Q_{theta_2}Qθ1,Qθ2Et actorem retis π pi_phiπϕ
Initialize scopum network θ 1 θ 1 , θ 2 θ 2 , ϕ theta_1^primeleftarrowtheta_1, theta 2^primeleftarrowtheta_2, phi primeleftarrow phiθ1′←θ1,θ2′←θ2,ϕ′←ϕ
Initialize playback quiddam set B B* calB
pro t = 1 ad T {bf pro }~t=1 ~{bf ad} ~Tfor********** t=1 to T :
~~~~~~ Select actio cum strepitu exploratio a π (s) + , N ( 0 , σ ) asimpi_phi(s)+epsilon,~~epsilonsim {cal N}(0,sigma)a∼πϕ(s)+ϵ, ϵ∼N(0,σ), observationis praemium rrr******************************************************************************* ac novus status s s^primes′
~~~~~~ Transitus tuple ( s , a , r , s )(s,a,r*******************************************************************************,s′) deposit to B B* calB medium
~~~~~~ e* B B* calB Sampling parva batches NNN transitus ( s , a , r , s )(s,a,r*******************************************************************************,s′)
a ~ π (s ) + , clip (N (0, σ~) , c, c) ~~~~~~ ( epsilon, ~~epsilonsim{rm clip}({cal N}(0, latum sigma), -c, c) a ←πϕ′(s′)+ϵ, ϵ∼tonde(N(0,σ ),−c**,c**)
y ← r + γ min i = 1 , 2 Q θ i ′ ( s , a ~ ) ~~~~~~ yleftarrow r+gamma minlimits_{i=1,2}Q_{theta_i^prime}(s^ primus, widetilde a) y**←r*******************************************************************************+γego=1,2minQθego′(s′,a )
~~~~~~ Updatecritics θ i ← arg min θ i N 1 ∑ ( y Q θ i ( s , a ) ) ^2θego←arg*********θegominN−1∑(y**−Qθego(s,a))2
~~~~~~ si t % d {bf si}~t~ % ~dsi t % d*:
~~~~~~~~~~~ Renova per deterministic consilium gradiente phiϕ
J ( ) = N 1 a Q θ 1 (s, a) a = π (s) π (s) ~~~~~~~~~~~~~~ ~~~nabla _phi J(phi)=N^{-1}sumnabla_aQ_{theta_1}(s, a)|_{a=pi_phi(s)}nabla_phipi_phi(s) ∇ϕJ(ϕ)=N−1∑∇aQθ1(s,a)∣a=πϕ(s)∇ϕπϕ(s)
~~~~~~~~~~~ Renova scopum retis:
θ i ′ τ θ i + ( 1 τ ) θ i ′ ~~~~~~~~~~~~~~~~~~~ theta_i^primeleftarrowtautheta_i+(1-tau)theta_i^prime~~~~~ θego′←τθego+(1−τ)θego′ τ tauτ: Target update rate
τ + ( 1 τ ) ~~~~~~~~~~~~~~~~~~~~~ phi^primeleftarrowtauphi+(1-tau)phi^primi ϕ′←τϕ+(1−τ)ϕ′
finem, si ~~~~~~{ bf finem ~if} finis si
finem pro {bf fine ~ pro}finis for**********

Maximize entropy of the policy, thus making the policy robustior.
determinatici belli Significat eodem statu data, semper eandem actionem eligere
fortuiti belli Significat quod multae sunt actiones possibiles quae in aliqua civitate possunt eligi.
| determinatici belli | fortuiti belli | |
|---|---|---|
| definition | Idem status, eadem actio | eodem statu;Ut diversis actibus praestare |
| commodum | Firmum et iterabile | Ne incidant in solutiones locorum optimales et facultates investigationis globalis meliorem |
| defectus | Defectus explorability et facile capiuntur ab adversariis | Hoc consilium potest tardius convenire, efficacia et effectus afficiens. |
In ipsa applicatione, si condiciones permittunt, volumusTry utfortuiti belliut A2C, PPO, etc., quia flexibilior, robustior & stabilior est.
Maximum entropy supplementi discendi credit quod, quamvis nunc fortuiti consilia matura habeamus, algorithmos scilicet ac AC, tamen optimales fortuiti non sumus consecuti.Ideo inducit anotitia entropyconceptum, inPraemium cumulativum maximize dum maxima entropy of the policybatque consilium robustiorem et ad meliorem fortuiti belli rationem assequendam.
——————————————————
OpenAI Documentation_SAC Interface Link
~
Mollis Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning cum Stochastic Actor, Haarnoja et al, 201808 ICML 2018
Mollis Actor-Criticus Algorithmus et Applications, Haarnoja et al, 201901
Ut ambulare per altum Reinforcement Learning, Haarnoja et al, 201906 RSS2019
Mollis Actor Criticus (SAC) optimizes strategies temere in modo off-consilii.
DDPG + stochastic belli optimization
Haud immediatus successor TD3 (per idem tempus dimissus est).
Dolum duplicem-Q tonsum incorporat, et ob fortuiti SAC instrumenti inhaerens, etiam tandem prodest ex.scopum consilium delenimenta。
A core pluma est SAC entropy regularization entropy regularization。
Consilium exercetur ad mercaturam maximizandam inter exspectationem mercedis et entropy;Entropy est mensura fortuiti consilii。
Hoc finitimum est commercio inter explorationem et abusionem: augmentum entropy ducit adMagis explorandumHoc est OKAccelerare subsequent doctrina .Bene estPreoccupo consilium de malis intempestive convergentibus ad loci optimam。
Adhiberi potest in utroque spatio continua actio, et discreta actio spatii.
exist Entropy regularized Reinforcement Learningagens obtinetEntropy of the policy at this time stepPraemia proportionalia.
Hoc tempore quaestio RL sic describitur:
π = arg max π E τ ∼ π [ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( st ) ) ) ] pi^*= argmaxlimits_pi underset {tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})textcolor{hyacinthinum}{+alpha H(pi(·|s_t))} Big)Big]π∗=arg*********πmaxτ∼πE[t=0∑∞γt(R(st,at,st+1)+αH(π(⋅∣st)))]
in α > 0 alpha > 0α>0 est commercium-off coefficiens.
Munus rei publicae valorem entropy comprehendo merces singulis diebus gradus V π V^piVπ ad:
V π ( s ) = E τ π [ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( st ) ) s 0 = s ] V^pi (s)=underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})+alpha H(pi(·|s_t))Big )Big|s_0=sBig]Vπ(s)=τ∼πE[t=0∑∞γt(R(st,at,st+1)+αH(π(⋅∣st))) s0=s]
Actio valoris functionis quae entropy includit praemium pro omni tempore gradus praeter primum gradum Q π Q^piQπ:
Q π ( s , a ) = E τ π [ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α t = 1 ∞ H ( π ( st ) ) s 0 = s , a 0 = a ] Q^pi(s,a)=underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1 })+alpha sumlimits_{t=1}^infty H(pi(·|s_t))Big)Big|s_0=s,a_0=aBig]Qπ(s,a)=τ∼πE[t=0∑∞γt(R(st,at,st+1)+αt=1∑∞H(π(⋅∣st))) s0=s,a0=a]
V π V^piVπ et Q π Q^piQπ Necessitudo est:
V π ( s ) = E a π [ Q π ( s , a ) ] + α H ( π ( s ) ) V^pi(s)=underset{asimpi}{rm E}[Q^pi( s, a)]+alpha H(pi(·|s))Vπ(s)=a∼πE[Qπ(s,a)]+αH(π(⋅∣s))
de " Q π Q^piQπ Formula Bellman est;
Q π ( s , a ) = E s P a π [ R ( s , a , s ) + γ ( Q ( s , a ) + α H ( π ( s ′ ) ) ] = E s P [ R ( s , a , S ) + γ V π ( s ) ] Qπ(s,a)=a′∼πs′∼PE[R(s,a,s′)+γ(Qπ(s′,a′)+αH(π(⋅∣s′)))]=s′∼PE[R(s,a,s′)+γVπ(s′)]
SAC discit consilium eodem tempore π θ π_thetaπθ et duo QQQ officium Q 1, Q 2 Q_{phi_1}, Q_{phi_2}Qϕ1,Qϕ2。
Adsunt duae variantes vexillum SAC: una certa utiturEntropy regularization coefficientis α alphaαalius, mutando in disciplina α alphaα exeat entropy angustiis.
Documenta OpenAI versione utitur cum coefficiente certo entropy regularizationis, sed in usu saepe praefertur.entropy angustiavariant.
Ut infra, in α alphaα In versione fixa, praeter ultimam picturam, quae perspicuas utilitates habet, ceterae leves tantum utilitates habent, plerumque eadem α alphaα Eadem litera discendi manet; α alphaα Duae imagines mediae sunt ubi literae literae utilitates manifestiores sunt.
SACVSTD3:
~
Eodem loco:
1. Ambae Q functiones discuntur extenuando MSBE (Error Mean Squared Bellman) per regressionem ad unum objectum commune.
2. Utere scopo Q-retis ad scopum commune computare, et polyak fere in parametris Q-retis per processum disciplinae ad obtinendum scopum Q-retis.
3. Communis clypei Q ars duplici mutila utitur.
~
differentia;
1. SAC continet entropy regularization terminus
2. Sequens actio publica usus in SAC metam venit exCurrent bellipotius quam scopo consilio.
3. Nulla patet scopo militaris ad delenimenta. TD3 docet determinatum consilium per actiones ad proximum statumAdde temere sonitus consequatur blanditiis ut. SAC impedimenta temere consilium, et strepitus fortuiti satis est effectus similes efficere.

Algorithmus: Mollis Actor-Criticus SAC
introire; θ 1 , θ 2 , theta_1, theta_2, phi~~~~~θ1,θ2,ϕ Initialization parametri
Parameter initialization:
~~~~~~ Initialize scopum network weights: θ 1 θ 1 , θ 2 θ 2 talea theta_1leftarrowtheta_1, talea theta 2leftarrowtheta_2θˉ1←θ1,θˉ2←θ2
~~~~~~ Piscina playback initialized vacua est; D {cal D} leftarrowemptysetD←∅
ad {bf for}for********** per iterationem facere {m}do :
~~~~~~ ad {bf for}for********** Quisque amet gradum facere {m}do :
~~~~~~~~~~~ Ac- tiones specimen ex consilio: at π (at st ) a_tsimpi_phi(a_t|s_t)~~~~~at∼πϕ(at∣st) Hic π (at st ) pi_phi(a_t|s_t)πϕ(at∣st) Quomodo definis?
~~~~~~~~~~~ Sample transitus e ambitu: st + 1 p ( st + 1 st ) s_{t+1}sim p(s_{t+1}|s_t,a_t)st+1∼p(st+1∣st,at)
~~~~~~~~~~~ Serva transitus ad piscinam playback: D D { ( st , r ( st ) , st + 1 ) {cal D}leftarrow{cal D}~cup~{(s_t, a_t, r(s_t, a_t), s_{t +1})}D←D ∪ {(st,at,r*******************************************************************************(st,at),st+1)}
~~~~~~ finem pro {bf fine ~ pro}finis for**********
~~~~~~ ad {bf for}for********** Quisque gradus gradiente facere {m}do :
~~~~~~~~~~~ renovare QQQ Munus parametri: nam i { 1, 2 } iin{1,2}ego∈{1,2}, θ i ← θ i − λ Q ^ θ i JQ ( θ i ) theta_ileftarrowtheta i-lambda_Qhat nabla_{theta_i}J_Q(theta_i)~~~~~θego←θego−λQ∇^θegoJQ(θego) Hic JQ ( θ i ) J_Q(theta_i)JQ(θego) Quomodo definis?
~~~~~~~~~~~ Pondera update belli: λ π ^ J π ( ) phileftarrowphi lambda_pihat nabla_phi J_pi (phi)~~~~~~ϕ←ϕ−λπ∇^ϕJπ(ϕ) Hic J π ( ) J_pi (phi)Jπ(ϕ) Quomodo definis?
~~~~~~~~~~~ Adjust tortor: α α − λ ∇ ^ α J ( α ) alphaleftarrowalpha-lambdahatnabla_alpha Jα←α−λ∇^αJ(α) Hic J ( α ) J(alpha)J(α) Quomodo definis?Quomodo intellegendum est hie temperatus?
~~~~~~~~~~~ Renova scopum network weights: nam i { 1, 2 } iin{1,2}ego∈{1,2}, θ i τ θ i − ( 1 τ ) θ i bar theta_ileftarrow tau theta_i-(1-tau) bar theta_i~~~~~θˉego←τθego−(1−τ)θˉego Quomodo intelligere hoc τ tauτ ? --> Target delenimenta coefficientis
~~~~~~ finem pro {bf fine ~ pro}finis for**********
finem pro {bf fine ~ pro}finis for**********
Output: θ 1 , θ 1 , theta_1, theta_1, phi~~~~~θ1,θ1,ϕ Optimized parametri
^ hat nabla∇^: Stochastic CLIVUS
$emptyset$ ~~~~ inanes ∅


Ut ambulare per altum Reinforcement Learning Versio in:
~
α
α
α modulus temperatus est, qui relativum momenti entropy terminus et merces determinat, fortuiti optimalis consilii moderatur.
α alphaα Magna: Explore
α alphaα Parvus: facinus
J ( α ) = E at ∼ π t [ α log π t ( at st ) α H ] J(alpha)=intellectu{a_tsimpi_t}{ mathbb E}[-alphalog pi_t(a_t|s_t)- alphabar{cal H}]J(α)=at∼πtE[−αlog*********πt(at∣st)−αHˉ]

technologiae technologiae plus quam 30 annos operam dedit et in variis linguis proficit ut java, linux, javascript, php, css, etc. Multas contributiones in aperto fonte campo fecit elit documentorum statione ad communicandas quaestiones technologiarum progressus ad futuram referentiam







