






informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
- organisasi catatan versi PDF easy-rl P5, P10 - P12
- suplemen perbandingan joyrl P11-P13
- Organisasi dokumen OpenAI ⭐ https://spinningup.openai.com/en/latest/index.html


Unduh PDF versi terbaru
Alamat: https://github.com/datawhalechina/easy-rl/releases
Alamat domestik (direkomendasikan untuk pembaca domestik):
Tautan: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw Kode ekstraksi: us6a
tautan versi online easy-rl (untuk menyalin kode)
Tautan referensi 2: https://datawhalechina.github.io/joyrl-book/
lainnya:
[Tautan catatan kesalahan]
——————
5. Dasar-dasar pembelajaran penguatan mendalam ⭐️
Konten sumber terbuka: https://linklearner.com/learn/summary/11
——————————
Strategi identik: Agen yang akan dipelajari dan agen yang berinteraksi dengan lingkungan adalah sama.
Strategi heterogen: agen yang belajar dan agen yang berinteraksi dengan lingkungan berbeda
Gradien kebijakan: membutuhkan banyak waktu untuk mengambil sampel data
strategi yang sama ⟹ Pengambilan sampel kepentingan ~~~overset{Pengambilan sampel kepentingan}{Longrightarrow}~~~ ⟹pengambilan sampel penting strategi yang berbeda
PPO: Hindari dua distribusi yang perbedaannya terlalu jauh. algoritma strategi yang sama
1. Item optimasi asli J ( θ , θ ′ ) J(theta,theta^prima)J(θ,θ′)
2. Item kendala: θ thetaθ Dan θ ′ theta^primaθ′ Divergensi KL dari tindakan keluaran ( θ thetaθ Dan θ ′ theta^primaθ′ Semakin mirip semakin baik)
PPO memiliki pendahulunya: optimalisasi kebijakan wilayah kepercayaan (TRPO)
TRPO sulit ditangani karena memperlakukan batasan divergensi KL sebagai batasan tambahan dan tidak ditempatkan pada fungsi tujuan sehingga sulit untuk dihitung. Oleh karena itu, kami biasanya menggunakan PPO, bukan TRPO. Kinerja PPO dan TRPO serupa, namun PPO lebih mudah diterapkan dibandingkan TRPO.
Divergensi KL: jarak aksi.Distribusi probabilitas untuk melakukan suatu tindakan jarak.
Ada dua varian utama algoritma PPO: penalti optimasi kebijakan proksimal (PPO-penalty) dan kliping optimasi kebijakan proksimal (PPO-clip).
——————————
P10 Masalah imbalan yang jarang
1. Rancang hadiah. Membutuhkan pengetahuan domain
Bagaimana dengan menetapkan imbalan akhir untuk setiap tindakan yang relevan?
2. Rasa ingin tahu
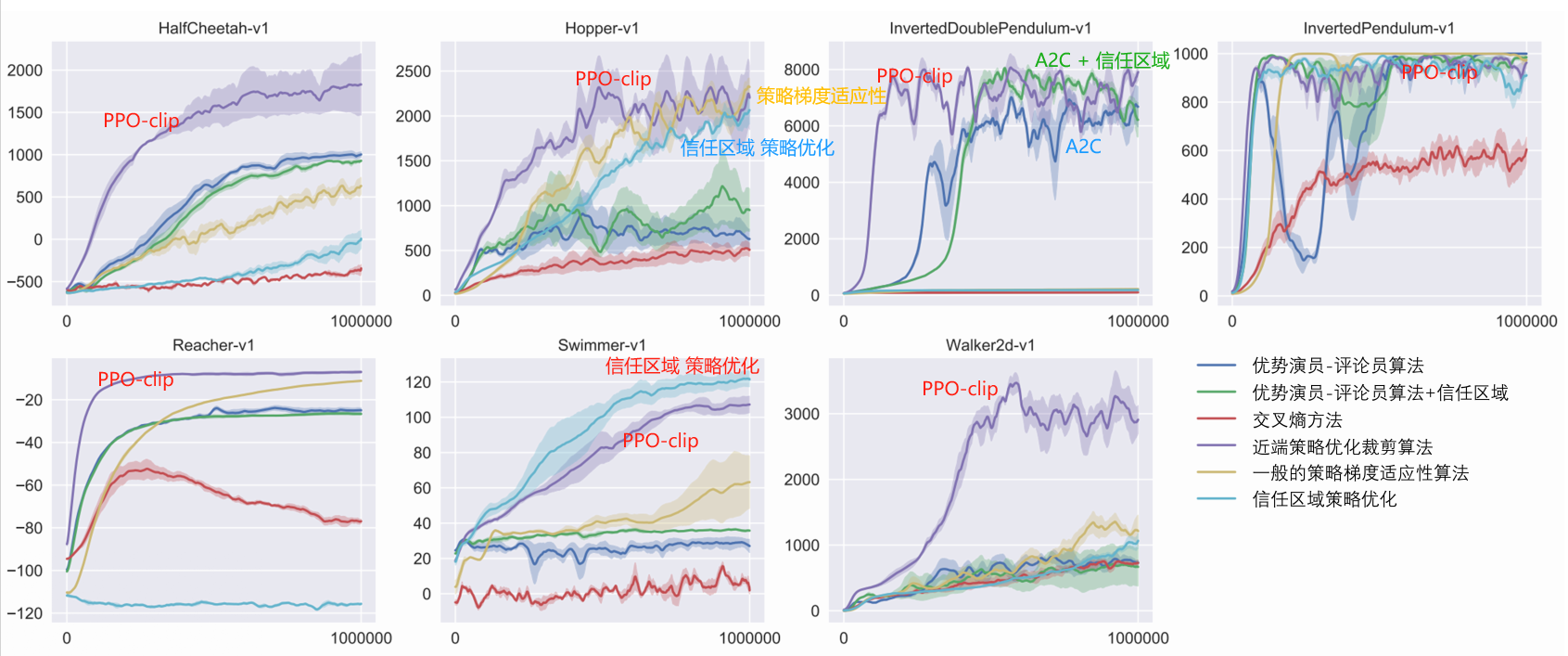
Modul rasa ingin tahu intrinsik (ICM)
memasuki: di , st a_t,s_tAT,ST
Keluaran: s ^ t + 1 topi s_{t+1}S^T+1
Nilai prediksi jaringan s ^ t + 1 topi s_{t+1}S^T+1 dengan nilai sebenarnya t+1 = t+1ST+1 Semakin berbeda mereka, semakin besar rti r_t^iRTSaya Semakin besar
rti r_t^iRTSaya : Semakin sulit memprediksi keadaan di masa depan, semakin besar imbalan atas tindakan tersebut. Mendorong petualangan dan eksplorasi.
ekstraktor fitur
Jaringan 2:
Masukan: vektor ϕ ( st ) { bm phi }(s_{t})ϕ(ST) Dan ϕ ( st + 1 ) { bm phi } ( s_{t + 1} )ϕ(ST+1)
Memprediksi tindakan sebuah ^ topi sebuahA^ Semakin dekat dengan tindakan nyata, semakin baik.
3. Kursus belajar
Mudah -> Sulit
Pembelajaran kurikulum terbalik:
Mulai dari keadaan terakhir yang paling ideal [kami menyebutnya keadaan emas], lanjutkan keTemukan keadaan yang paling dekat dengan keadaan emas Sebagai keadaan "ideal" bertahap yang ingin Anda capai oleh agen. Tentu saja, kami sengaja menghilangkan beberapa keadaan ekstrim dalam proses ini, yaitu keadaan yang terlalu mudah atau terlalu sulit.
4. Pembelajaran penguatan hierarki (HRL)
Strategi agen dibagi menjadi strategi tingkat tinggi dan strategi tingkat rendah. Strategi tingkat tinggi menentukan bagaimana mengeksekusi strategi tingkat rendah berdasarkan keadaan saat ini.
————————
P11 Pembelajaran imitasi
Tidak yakin dengan adegan hadiahnya
Pembelajaran imitasi (IL)
belajar dari demonstrasi
Pembelajaran magang
belajar sambil menonton
Ada imbalan yang jelas: permainan papan, video game
Tidak dapat memberikan imbalan yang jelas: chatbot
Kumpulkan demonstrasi ahli: catatan mengemudi manusia, percakapan manusia
Sebaliknya, fungsi penghargaan seperti apa yang dilakukan pakar dalam tindakan ini?
Pembelajaran penguatan terbalik adalahPertama temukan fungsi hadiah, setelah menemukan fungsi reward, kemudian gunakan pembelajaran penguatan untuk menemukan aktor yang optimal.
Teknologi pembelajaran imitasi orang ketiga
————————
P12 Gradien kebijakan deterministik mendalam (DDPG)
Gunakan strategi pemutaran ulang pengalaman
Analisis Eksperimen Ablasi [Metode Variabel Terkendali].setiap kendalaberdampak pada hasil pertempuran.
kegembiraan:
sedang membutuhkankepastianstrategi dantindakan terus menerusDi bawah premis ruang, algoritma jenis ini akan menjadi algoritma dasar yang relatif stabil.
DQN untuk ruang tindakan berkelanjutan
Algoritme gradien kebijakan deterministik mendalam (DDPG)
Mekanisme pemutaran ulang pengalaman dapat mengurangi korelasi antar sampel, meningkatkan pemanfaatan sampel secara efektif, dan meningkatkan stabilitas pelatihan.
kekurangan:
1. Tidak dapat digunakan dalam ruang tindakan diskrit
2、Sangat bergantung pada hyperparameter
3. Kondisi awal yang sangat sensitif. Mempengaruhi konvergensi dan kinerja algoritma
4. Mudah untuk masuk ke dalam optimum lokal.
Keuntungan dari pembaruan lunak adalah lebih lancar dan lambat, sehingga dapat menghindari guncangan yang disebabkan oleh pembaruan bobot yang terlalu cepat dan mengurangi risiko perbedaan pelatihan.
Algoritma gradien kebijakan deterministik penundaan ganda
Tiga peningkatan: Jaringan Double Q, pembaruan tertunda, regularisasi kebisingan
Jaringan Q Ganda : Dua jaringan Q, pilih salah satu yang nilai Q-nya lebih kecil. Untuk mengatasi masalah overestimasi nilai Q dan meningkatkan stabilitas dan konvergensi algoritma.
Pembaruan tertunda: Biarkan frekuensi pembaruan aktor lebih rendah dari frekuensi pembaruan kritik
Kebisingan lebih seperti aRegularisasisedemikian rupa sehinggapembaruan fungsi nilailagimulus
Perpustakaan Gym OpenAI_Pendulum_TD3
Tautan antarmuka dokumen OpenAI tentang TD3
Algoritma PPO yang paling umum digunakan dalam pembelajaran penguatan
Diskrit + kontinu
Cepat dan stabil, mudah untuk menyesuaikan parameter
algoritma dasar
PPO yang belum diputuskan
Dalam praktiknya, batasan klip umumnya digunakan karena lebih sederhana, biaya komputasi lebih rendah, dan hasil lebih baik.
Algoritme di luar kebijakan bisauntuk memanfaatkan pengalaman sejarah, umumnya menggunakan pemutaran ulang pengalaman untuk menyimpan dan menggunakan kembali pengalaman sebelumnya,Efisiensi pemanfaatan data tinggi。
PPO adalah algoritma berdasarkan kebijakan
——————————————————
Dokumentasi OpenAI
Tautan antarmuka Paper arXiv: Algoritma Pengoptimalan Kebijakan Proksimal
PPO: algoritme sesuai kebijakan, cocok untuk ruang tindakan terpisah atau berkelanjutan.Kemungkinan optimal lokal
Motivasi PPO sama dengan TRPO: bagaimana memanfaatkan data yang adaAmbil langkah perbaikan sebesar mungkin dalam strategi Anda, tanpa mengubahnya terlalu banyak dan secara tidak sengaja menyebabkan penurunan kinerja?
TRPO mencoba memecahkan masalah ini dengan pendekatan tingkat kedua yang canggih, sedangkan PPO adalah pendekatan tingkat pertama yang menggunakan beberapa trik lain untuk menjaga strategi baru tetap dekat dengan strategi lama.
Metode PPO jauh lebih sederhana untuk diterapkan dan, secara empiris, kinerjanya setidaknya sama baiknya dengan TRPO.
Ada dua variasi utama PPO: PPO-Penalti dan PPO-Klip.


Algoritma: PPO-Klip
1: Masukan: parameter strategi awal θ 0 theta_0θ0, parameter fungsi nilai awal ϕ 0 phi_0ϕ0
2: untuk k = 0, 1, 2, … lakukan {bf untuk} ~ k=0,1,2,titik~ {bf lakukan}untuk aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu=0,1,2,… Mengerjakan:
3: ~~~~~~ Dengan menjalankan kebijakan di lingkungan πk = π(θk) pi_k=pi(theta_k)πaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu=π(θaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu) Kumpulkan kumpulan lintasan D k = { τ i } {kal D}_k={tau_i}Daaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu={τSaya}
4: ~~~~~~ Hitung imbalan (rewards-to-go) R ^ itu R_t~~~~~R^T ▢ R ^ itu R_tR^T aturan perhitungan
5: ~~~~~~ Hitung perkiraan keuntungan, berdasarkan fungsi nilai saat ini V ϕ k V_{phi_k}Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Vϕaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu dari Sebuah ^ yang A_tA^T (Gunakan metode estimasi dominasi apa pun) ~~~~~ ▢ Apa saja kelebihan metode estimasi yang ada saat ini?
6: ~~~~~~ Perbarui kebijakan dengan memaksimalkan fungsi tujuan PPO-Clip:
~~~~~~~~~~~
Bahasa Indonesia: θ k + 1 = arg maks θ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T min ( π θ ( pada ∣ st ) π θ k ( pada ∣ st ) A π θ k ( st , pada ) , g ( ϵ , A π θ k ( st , pada ) ) ) ~~~~~~~~~~~~theta_{k+1}=argmaxlimits_thetafrac{1}{|{cal D}_k|T}batas jumlah_{tauin{cal D}_k}batas jumlah_{t=0}^TminBig(frac{pi_{theta} (a_t|s_t)}{pi_{theta_k}(a_t|s_t)}A^{pi_{theta_k}}(s_t,a_t),g(epsilon,A^{pi_{theta_k}}(s_t,a_t))Besar) θaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu+1=Bahasa InggrisGθmaks∣Daaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu∣T1τ∈Daaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu∑T=0∑Tmenit(πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(AT∣ST)πθ(AT∣ST)Aπθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(ST,AT),G(ϵ,Aπθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(ST,AT))) ~~~~~ ▢ Bagaimana cara menentukan formula pembaruan strategi?
~~~~~~~~~~~
~~~~~~~~~~~ π θ k = pi_{theta_k}πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu : Vektor parameter strategi sebelum pembaruan. Pengambilan sampel penting. Mengambil sampel dari strategi lama.
~~~~~~~~~~~
~~~~~~~~~~~ Pendakian Gradien Stochastic Umum + Adam
7: ~~~~~~ kesalahan kuadrat rata-ratafungsi nilai pas regresi:
~~~~~~~~~~~
Bahasa Indonesia: ϕ k + 1 = arg min ϕ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T ( V ϕ ( st ) − R ^ t ) 2 ~~~~~~~~~~~~phi_{k+1}=arg minlimits_phifrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TBig(V_phi(s_t)-hat R_tBig)^2 ϕaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu+1=Bahasa InggrisGϕmenit∣Daaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu∣T1τ∈Daaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu∑T=0∑T(Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Vϕ(ST)−R^T)2
~~~~~~~~~~~
~~~~~~~~~~~ Penurunan gradien umum
8: akhir untuk bf akhir ~untukakhir untuk
~~~~~~~~~~~~
$dots$ … ~~~titik …
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) AA < 0 g(epsilon,A)=kiri{(1+ϵ)A A≥0(1−ϵ)AA<0Kanan. G(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0

di kertasPerkiraan keuntungan:
Bahasa Indonesia: Sebuah ^ t = − V ( st ) + rt + γ rt + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) ⏟ R ^ t ? ? ? topi A_t=-V(s_t)+underbrace{r_t+gamma r_{t+1}+cdots+gamma^{T-t+1}r_{T-1}+gamma^{Tt}V(s_T)}_{warnateks{biru}{topi R_t???}}A^T=−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+R^T??? RT+γRT+1+⋯+γT−T+1RT−1+γT−TBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)

membuat Persamaan t = rt + γ V ( st + 1 ) − V ( st ) Delta t = r_t + gamma V(s_{t+1})-V(s_t)ΔT=RT+γV(ST+1)−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)
Tetapi Rumus untuk t = Δt − γ V(st + 1) + V(st)RT=ΔT−γV(ST+1)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)
Pengganti Sebuah ^ yang A_tA^T ekspresi
Bahasa Indonesia: Jika ^ t = − V ( st ) + rt + γ rt + 1 + γ 2 rt + 2 + ⋯ + γ T − tr T − 2 + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( st ) + rt + γ rt + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( st ) + Δ t − γ V ( st + 1 ) + V ( st ) + γ ( Δ t + 1 − γ V ( st + 2 ) + V ( st + 1 ) Bahasa Indonesia: ) + γ 2 ( Δ t + 2 − γ V ( st + 3 ) + V ( st + 1 ) ) + ⋯ + γ T − t ( Δ T − t − γ V ( s T − t + 1 ) + V ( s T − t ) ) + γ T − t + 1 ( Δ T − 1 − γ V ( s T ) + V ( s T − 1 ) ) + γ T − t V ( s T ) = Δ t + γ Δ t + 1 + γ 2 Δ t + 2 + ⋯ + γ T − t Δ T − t + γ T − t + 1 Δ T − 1ˆAT=−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+RT+γRT+1+γ2RT+2+⋯+γT−TRT−2+γT−T+1RT−1+γT−TBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)=−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+RT+γRT+1+⋯+γT−T+1RT−1+γT−TBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)=−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+ ΔT−γBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST+1)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+ γ(ΔT+1−γBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST+2)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST+1))+ γ2(ΔT+2−γBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST+3)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST+1))+ ⋯+ γT−T(ΔT−T−γBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST−T+1)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST−T))+ γT−T+1(ΔT−1−γBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST−1))+ γT−TBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)=ΔT+γΔT+1+γ2ΔT+2+⋯+γT−TΔT−T+γT−T+1ΔT−1 A^T=−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+RT+γRT+1+γ2RT+2+⋯+γT−TRT−2+γT−T+1RT−1+γT−TBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)=−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+RT+γRT+1+⋯+γT−T+1RT−1+γT−TBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)=−Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+ ΔT−γV(ST+1)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)+ γ(ΔT+1−γV(ST+2)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST+1))+ γ2(ΔT+2−γV(ST+3)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST+1))+ ⋯+ γT−T(ΔT−T−γV(ST−T+1)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST−T))+ γT−T+1(ΔT−1−γV(ST)+Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST−1))+ γT−TBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: V(ST)=ΔT+γΔT+1+γ2ΔT+2+⋯+γT−TΔT−T+γT−T+1ΔT−1

Kliping bertindak sebagai pengatur dengan menghilangkan insentif untuk perubahan drastis dalam kebijakan.hyperparameter ϵ epsilonϵ Sesuai dengan jarak antara strategi baru dan strategi lama。
Masih ada kemungkinan bahwa pemotongan seperti ini pada akhirnya akan menghasilkan strategi baru yang jauh dari strategi lama. Dalam penerapannya di sini, kami menggunakan metode yang sangat sederhana:Berhenti lebih awal . Jika rata-rata perbedaan KL kebijakan baru dan kebijakan lama melebihi ambang batas, kami berhenti menjalankan langkah gradien.
Tautan derivasi sederhana fungsi tujuan PPO
Fungsi tujuan PPO-Clip adalah:
~
Bahasa Indonesia: L θ k KLIP ( θ ) = Es , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , klip ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ k ( s , a ) ) ] L^{rm KLIP}_{theta_k}(theta)=himpunan bawah{s, asimtheta_k}{rm E}Bigg[minBigg(frak{pi_theta(a|s)}{pi_{theta_k}(a|s)}A^{theta_k}(s, a), {rm klip}Besar(frak{pi_theta(a|s)}{pi_{theta_k}(a|s)},1-epsilon, 1+epsilonBesar)A^{theta_k}(s, a)Besar)Besar]SayaθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuKLIP(θ)=S,A∼θaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuBahasa Inggris[menit(πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S)πθ(A∣S)Aθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(S,A),klip(πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S)πθ(A∣S),1−ϵ,1+ϵ)Aθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(S,A))]
~
$underset{s, asimtheta_k}{rm E}$E s, a ∼ θ k ~~~himpunan bawah{s, asimtheta_k}{rm E} S,A∼θaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuBahasa Inggris
~
TIDAK. kkaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu Parameter strategi untuk iterasi θ k theta_kθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu, ϵ epsilonϵ adalah hyperparameter kecil.
mempersiapkan ϵ ∈ ( 0 , 1 ) epsilon(0,1)ϵ∈(0,1), definisi
F ( r , A , ϵ ) ≐ min ( r A , klip ( r , 1 − ϵ , 1 + ϵ ) A ) F(r,A,epsilon)doteqminBigg(rA,{rm klip}(r,1-epsilon,1+epsilon)ABigg)F(R,A,ϵ)≐menit(RA,klip(R,1−ϵ,1+ϵ)A)
Kapan A ≥ 0 Umurq0A≥0
F ( r , A , ϵ ) = min ( r A , klip ( r , 1 − ϵ , 1 + ϵ ) A ) = A min ( r , klip ( r , 1 − ϵ , 1 + ϵ ) ) = A min ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { min ( r , 1 + ϵ ) r ≥ 1 + ϵ min ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) min ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) rr ≤ 1 − ϵ } Berdasarkan rentang di sebelah kanan = A min ( r , 1 + ϵ ) = min ( r A , ( 1 + ϵ ) A )mulai{sejajar}F(r,A,epsilon)&=minBigg(rA,{klip rm}(r,1-epsilon,1+epsilon)ABigg)\ &=AminBigg(r,{klip rm}(r,1-epsilon,1+epsilon)Bigg)\ &=AminBigg(r,kiri{mulai{sejajar}&1+epsilon~~&rgeq1+epsilon\ &r &rin(1-epsilon,1+epsilon)\ &1-epsilon &rleq1-epsilon\ akhir{sejajar}kanan}Bigg)\ &=Aleft{menitkanan}\ &=Akiri{kanan}~~~~~textcolor{biru}{sesuai dengan rentang di sebelah kanan}\ &=Amin(r, 1+epsilon)\ &=minBigg(rA, (1+epsilon)ABigg) end{aligned} F(R,A,ϵ)=menit(RA,klip(R,1−ϵ,1+ϵ)A)=Amenit(R,klip(R,1−ϵ,1+ϵ))=Amenit(R,⎩ ⎨ ⎧1+ϵ R1−ϵR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧menit(R,1+ϵ) menit(R,R)menit(R,1−ϵ)R≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧1+ϵ RRR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫ Menurut kisaran di sebelah kanan=Amenit(R,1+ϵ)=menit(RA,(1+ϵ)A)
~
Kapan Sebuah < 0 Sebuah < 0A<0
F ( r , A , ϵ ) = min ( r A , klip ( r , 1 − ϵ , 1 + ϵ ) A ) = A maks ( r , klip ( r , 1 − ϵ , 1 + ϵ ) ) = Maks ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { maks ( r , 1 + ϵ ) r ≥ 1 + ϵ maks ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) maks ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { r r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } Menurut rentang di sisi kanan = A max ( r , 1 − ϵ ) = min ( r A , ( 1 − ϵ ) A )kanan}Bigg)\ &=Aleft{kanan}\ &=Akiri{kanan}~~~~~textcolor{blue}{sesuai dengan rentang di sebelah kanan}\ &=Amax(r, 1-epsilon)\ &=textcolor{blue}{min}Bigg(rA,(1-epsilon) ABigg) akhir{sejajar} F(R,A,ϵ)=menit(RA,klip(R,1−ϵ,1+ϵ)A)=AMAX(R,klip(R,1−ϵ,1+ϵ))=Amaks(R,⎩ ⎨ ⎧1+ϵ R1−ϵR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧maks(R,1+ϵ) maks(R,R)maks(R,1−ϵ)R≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧R R1−ϵR≥1+ϵR∈(1−ϵ,1+ϵ)R≤1−ϵ⎭ ⎬ ⎫ Menurut kisaran di sebelah kanan=Amaks(R,1−ϵ)=MSayaN(RA,(1−ϵ)A)
~
Singkatnya: dapat ditentukan g(epsilon,A)G(ϵ,A)
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) AA < 0 g(epsilon,A)=kiri{Kanan. G(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0
Mengapa definisi ini mencegah strategi baru menyimpang terlalu jauh dari strategi lama?
Metode pengambilan sampel kepentingan yang efektif memerlukan strategi baru jika π θ ( a ∣ s ) pi_theta(a|s)πθ(A∣S) dan strategi lama Jika π θ k ( a ∣ s ) pi_{theta_k}(a|s)πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S) Perbedaan antara kedua distribusi tersebut tidak boleh terlalu besar
1. Ketika keuntungannya positif
Bahasa Indonesia: L(s,a,theta_k, theta) = min ( π θ (a ∣ s) π θ k (a ∣ s), 1 + ϵ ) A π θ k (s,a) L(s,a,theta_k, theta)=minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1+epsilonBigg)A^{pi_{theta_k}}(s, a)Saya(S,A,θaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu,θ)=menit(πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S)πθ(A∣S),1+ϵ)Aπθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(S,A)
Fungsi keuntungan: Temukan pasangan tindakan negara tertentu dengan lebih banyak hadiah -> tingkatkan bobot pasangan tindakan negara.
Ketika pasangan tindakan negara (s, sebuah) (s, sebuah)(S,A) positif, maka jika tindakan A AA lebih mungkin untuk dieksekusi, yaitu jika jika π θ ( a ∣ s ) pi_theta(a|s)πθ(A∣S) Tingkatkan dan tujuannya akan meningkat.
min pada item ini membatasi fungsi tujuan hanya meningkat hingga nilai tertentu
sekali Jika π θ ( a ∣ s ) > ( 1 + ϵ ) π θ k ( a ∣ s ) pi_theta(a|s)>(1+epsilon)pi_{theta_k}(a|s)πθ(A∣S)>(1+ϵ)πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S), min pemicu, membatasi nilai item ini menjadi ( 1 + ϵ ) π θ k ( a ∣ s ) (1+epsilon)pi_{theta_k}(a|s)(1+ϵ)πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S)。
kebijakan baru tidak mendapat keuntungan dengan menjauh dari kebijakan lama.
Strategi baru tidak akan mendapatkan keuntungan jika kita beralih dari strategi lama.
2. Ketika keuntungannya negatif
Bahasa Indonesia: L ( s , a , θ k , θ ) = maks ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ ) A π θ k ( s , a ) L(s,a,theta_k, theta)=maksBigg(frak{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1-epsilonBigg)A^{pi_{theta_k}}(s, a)Saya(S,A,θaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu,θ)=maks(πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S)πθ(A∣S),1−ϵ)Aπθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(S,A)
Ketika pasangan tindakan negara (s, sebuah) (s, sebuah)(S,A) Keuntungannya negatif, lalu jika tindakannya A AA bahkan lebih kecil kemungkinannya, yaitu jika Rumus untuk persamaan a ∣ s adalah π θ (a ∣ s)πθ(A∣S) menurun maka fungsi tujuan akan meningkat. Namun nilai maksimal pada suku ini membatasi seberapa besar fungsi tujuan dapat ditingkatkan.
sekali Jika k(a ∣ s) < (1 − ϵ) maka k(a ∣ s) adalah p(a|s)<(1-epsilon)p(a|s)πθ(A∣S)<(1−ϵ)πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S), pemicu maksimal, membatasi nilai item ini menjadi Persamaan (1 − ϵ) π θ k ( a ∣ s ) (1-epsilon)pi_{theta_k}(a|s)(1−ϵ)πθaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaakuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(A∣S)。
Sekali lagi: kebijakan baru tidak akan memberikan manfaat jika kita menjauhi kebijakan lama.
Strategi baru tidak akan mendapatkan keuntungan jika kita beralih dari strategi lama.
Meskipun DDPG terkadang dapat mencapai performa luar biasa, seringkali DDPG tidak stabil dalam hal hyperparameter dan jenis penyetelan lainnya.
Mode kegagalan DDPG yang umum adalah fungsi Q yang dipelajari mulai melebih-lebihkan nilai Q secara signifikan, yang kemudian menyebabkan kebijakan rusak karena mengeksploitasi kesalahan dalam fungsi Q.
Twin Delayed DDPG (TD3) adalah algoritma yang memecahkan masalah ini dengan memperkenalkan tiga teknik utama:
1、Pembelajaran Q Ganda Terpotong。
2、Keterlambatan pembaruan kebijakan。
3. Pemulusan strategi sasaran.
TD3 adalah algoritma di luar kebijakan; hanya dapat digunakan dengankontinuLingkungan ruang aksi.

Algoritma: TD3
Gunakan parameter acak θ 1 , θ 2 , ϕ theta_1, theta_2, phiθ1,θ2,ϕ Inisialisasi jaringan kritik Q θ 1 , Q θ 2 Q_{theta_1},Q_{theta_2}Qθ1,Qθ2, dan jaringan aktor π ϕ pi_phiπϕ
Inisialisasi jaringan target Bahasa Indonesia: θ 1 ′ ← θ 1 , θ 2 ′ ← θ 2 , ϕ ′ ← ϕ theta_1^primeleftarrowtheta_1, theta_2^primeleftarrowtheta_2, phi^primeleftarrow phiθ1′←θ1,θ2′←θ2,ϕ′←ϕ
Inisialisasi kumpulan buffer pemutaran B kal BB
untuk t = 1 sampai T {bf untuk}~t=1 ~{bf sampai} ~Tuntuk T=1 ke T :
~~~~~~ Pilih tindakan dengan kebisingan eksplorasi sebuah ∼ π ϕ ( s ) + ϵ , ϵ ∼ N ( 0 , σ ) asimpi_phi(s)+epsilon,~~epsilonsim {kal N}(0,sigma)A∼πϕ(S)+ϵ, ϵ∼N(0,σ), hadiah observasi rrR dan status baru s ′ s^primaS′
~~~~~~ Tupel transisi ( s , a , r , s ′ ) (s, a,r, s^prima)(S,A,R,S′) setor ke B kal BB tengah
~~~~~~ dari B kal BB Pengambilan sampel dalam jumlah kecil Tidak adaN transisi ( s , a , r , s ′ ) (s, a, r, s^prima)(S,A,R,S′)
a ~ ← π ϕ ′ ( s ′ ) + ϵ , ϵ ∼ klip ( N ( 0 , σ ~ ) , − c , c ) ~~~~~~widetilde aleftarrow pi_{phi^prime}(s^prime)+epsilon,~~epsilonsim{rm klip}({cal N}(0,widetilde sigma),-c,c) A ←πϕ′(S′)+ϵ, ϵ∼klip(N(0,σ ),−C,C)
y ← r + γ min i = 1 , 2 Q θ i ′ ( s ′ , a ~ ) ~~~~~~yleftarrow r+gamma minlimits_{i=1,2}Q_{theta_i^prima}(s^prima,widetilde a) kamu←R+γSaya=1,2menitQθSaya′(S′,A )
~~~~~~ Kritik pembaruan θ i ← arg min θ i N − 1 ∑ ( y − Q θ i ( s , a ) ) 2 theta_ileftarrowargminlimits_{theta_i}N^{-1}jumlah(y-Q_{theta_i}(s, a))^2θSaya←Bahasa InggrisGθSayamenitN−1∑(kamu−QθSaya(S,A))2
~~~~~~ jika t %d {bf jika}~t~ %~djika T % D:
~~~~~~~~~~~ Pembaruan melalui gradien kebijakan deterministik ϕ phiϕ
Bahasa Indonesia: ∇ ϕ J ( ϕ ) = N − 1 ∑ ∇ a Q θ 1 ( s , a ) ∣ a = π ϕ ( s ) ∇ ϕ π ϕ ( s ) ~~~~~~~~~~~~~~~~~~nabla _phi J(phi)=N^{-1}jumlahnabla_aQ_{theta_1}(s, a)|_{a=pi_phi(s)}nabla_phipi_phi(s) ∇ϕJ(ϕ)=N−1∑∇AQθ1(S,A)∣A=πϕ(S)∇ϕπϕ(S)
~~~~~~~~~~~ Perbarui jaringan target:
Bahasa Indonesia: θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ ~~~~~~~~~~~~~~~~~~~theta_i^primeleftarrowtautheta_i+(1-tau)theta_i^prima~~~~~ θSaya′←τθSaya+(1−τ)θSaya′ aku tahuτ: Tingkat pembaruan target
ϕ ′ ← τ ϕ + ( 1 − τ ) ϕ ′ ~~~~~~~~~~~~~~~~~~phi^primeleftarrowtauphi+(1-tau)phi^prima ϕ′←τϕ+(1−τ)ϕ′
berakhir jika ~~~~~~{bf berakhir ~jika} akhir jika
akhir untuk {bf akhir ~untuk}akhir untuk

Memaksimalkan entropi kebijakan, sehingga menjadikan kebijakan lebih kuat.
strategi deterministik Artinya, dalam keadaan yang sama, selalu pilih tindakan yang sama
strategi keacakan Artinya ada banyak kemungkinan tindakan yang dapat dipilih dalam keadaan tertentu.
| strategi deterministik | strategi keacakan | |
|---|---|---|
| definisi | Keadaan yang sama, lakukan tindakan yang sama | status yang sama,Dapat melakukan tindakan yang berbeda |
| keuntungan | Stabil dan dapat diulang | Hindari terjebak dalam solusi optimal lokal dan tingkatkan kemampuan pencarian global |
| kekurangan | Kurangnya kemampuan untuk dijelajahi dan mudah ditangkap oleh lawan | Hal ini dapat menyebabkan strategi menyatu dengan lambat, sehingga mempengaruhi efisiensi dan kinerja. |
Dalam penerapan sebenarnya, jika kondisi memungkinkan, kami akan melakukannyaCobalah untuk menggunakanstrategi keacakan, seperti A2C, PPO, dll, karena lebih fleksibel, lebih kuat, dan lebih stabil.
Pembelajaran penguatan entropi maksimum meyakini bahwa meskipun saat ini kita telah memiliki strategi keacakan yang matang, yaitu algoritma seperti AC, kita masih belum mencapai keacakan yang optimal.Oleh karena itu, ia memperkenalkan aentropi informasikonsep, diMaksimalkan imbalan kumulatif sambil memaksimalkan entropi kebijakan, membuat strategi lebih kuat dan mencapai strategi keacakan yang optimal.
——————————————————
Dokumentasi OpenAI_Tautan Antarmuka SAC
~
Soft Actor-Critic: Pembelajaran Penguatan Mendalam Entropi Maksimum di Luar Kebijakan dengan Aktor Stokastik, Haarnoja dkk, 201808 ICML 2018
Algoritma dan Aplikasi Soft Actor-Critic, Haarnoja dkk, 201901
Belajar Berjalan melalui Pembelajaran Penguatan Mendalam, Haarnoja dkk, 201906 RSS2019
Soft Actor Critic (SAC) mengoptimalkan strategi acak dengan cara di luar kebijakan.
DDPG + optimasi strategi stokastik
Bukan penerus langsung TD3 (dirilis pada waktu yang hampir bersamaan).
Ini menggabungkan trik double-Q yang terpotong, dan karena keacakan yang melekat pada strategi SAC, strategi ini juga pada akhirnya mendapat manfaat darikelancaran kebijakan sasaran。
Fitur inti SAC adalah regularisasi entropi regularisasi entropi。
Kebijakan ini dilatih untuk memaksimalkan trade-off antara imbalan yang diharapkan dan entropi,Entropi adalah ukuran keacakan suatu kebijakan。
Hal ini berkaitan erat dengan trade-off antara eksplorasi dan eksploitasi: peningkatan entropi menyebabkan peningkatanLebih banyak untuk dijelajahi,ini bagusMempercepat pembelajaran selanjutnya .tidak apa-apaMencegah kebijakan agar tidak mengalami konvergensi sebelum waktunya ke optimal lokal yang buruk。
Ini dapat digunakan baik di ruang aksi berkelanjutan maupun ruang aksi diskrit.
ada Pembelajaran Penguatan yang Diatur Entropi, agen memperoleh danEntropi kebijakan pada langkah saat iniImbalan yang proporsional.
Saat ini masalah RL digambarkan sebagai:
π ∗ = arg max π E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ] pi^*=argmaxlimits_pi underset{tausimpi}{rm E}Besar[sumlimits_{t=0}^inftygamma^tBesar(R(s_t,a_t,s_{t+1})warnateks{biru}{+alfa H(pi(·|s_t))}Besar)Besar]π∗=Bahasa InggrisGπmaksτ∼πBahasa Inggris[T=0∑∞γT(R(ST,AT,ST+1)+αH(π(⋅∣ST)))]
di dalam α > 0 alfa > 0α>0 adalah koefisien trade-off.
Nyatakan fungsi nilai termasuk imbalan entropi pada setiap langkah waktu V = V^piBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Vπ untuk:
Bahasa Indonesia: V π ( s ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s ] V^pi(s)=himpunan bawah{tausimpi}{rm E}Besar[sumlimits_{t=0}^inftygamma^tBesar(R(s_t,a_t,s_{t+1})+alfa H(pi(·|s_t))Besar)Besar|s_0=sBesar]Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Vπ(S)=τ∼πBahasa Inggris[T=0∑∞γT(R(ST,AT,ST+1)+αH(π(⋅∣ST))) S0=S]
Fungsi nilai tindakan yang menyertakan imbalan entropi untuk setiap langkah waktu kecuali yang pertama Q = Q^piQπ:
Bahasa Indonesia: Q π ( s , a ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α ∑ t = 1 ∞ H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s , a 0 = a ] Q^pi(s,a)=himpunan bawah{tausimpi}{rm E}Besar[jumlahbatas_{t=0}^takterhinggagamma^tBesar(R(s_t,a_t,s_{t+1})+alfa jumlahbatas_{t=1}^takterhingga H(pi(·|s_t))Besar)Besar|s_0=s,a_0=aBesar]Qπ(S,A)=τ∼πBahasa Inggris[T=0∑∞γT(R(ST,AT,ST+1)+αT=1∑∞H(π(⋅∣ST))) S0=S,A0=A]
V = V^piBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Vπ Dan Q = Q^piQπ Hubungan antara adalah:
V π ( s ) = E a ∼ π [ Q π ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) V^pi(s)=himpunan bawah{asimpi}{rm E}[Q^pi(s, a)]+alfa H(pi(·|s))Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Vπ(S)=A∼πBahasa Inggris[Qπ(S,A)]+αH(π(⋅∣S))
tentang Q = Q^piQπ Rumus Bellmannya adalah:
Bahasa Indonesia: Q π ( s , a ) = Es ′ ∼ P a ′ ∼ π [ R ( s , a , s ′ ) + γ ( Q π ( s ′ , a ′ ) + α H ( π ( ⋅ ∣ s ′ ) ) ) ] = Es ′ ∼ P [ R ( s , a , s ′ ) + γ V π ( s ′ ) ] Qπ(S,A)=A′∼πS′∼PBahasa Inggris[R(S,A,S′)+γ(Qπ(S′,A′)+αH(π(⋅∣S′)))]=S′∼PBahasa Inggris[R(S,A,S′)+γBahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Bahasa Indonesia: Vπ(S′)]
SAC mempelajari suatu kebijakan secara bersamaan π θ π_thetaπθ dan dua Bahasa Indonesia: QQQ fungsi Q 1 , Q 2 Q_{phi_1}, Q_{phi_2}Qϕ1,Qϕ2。
Saat ini ada dua varian SAC standar: satu menggunakan yang tetapKoefisien regularisasi entropi α alfaα, yang lain dengan mengubah selama pelatihan α alfaα untuk menerapkan batasan entropi.
Dokumentasi OpenAI menggunakan versi dengan koefisien regularisasi entropi tetap, namun dalam praktiknya sering kali lebih disukaibatasan entropivarian.
Seperti yang ditunjukkan di bawah ini, di α alfaα Pada versi fix, kecuali gambar terakhir yang memiliki kelebihan yang jelas, yang lain hanya memiliki sedikit kelebihan, pada dasarnya sama α alfaα Versi pembelajarannya tetap sama; α alfaα Dua gambar tengah dimana versi pembelajaran memiliki kelebihan lebih jelas.
SACMelawanTD3:
~
Poin yang sama:
1. Kedua fungsi Q dipelajari dengan meminimalkan MSBE (Mean Squared Bellman Error) melalui regresi ke satu tujuan bersama.
2. Gunakan jaringan Q target untuk menghitung target bersama, dan lakukan rata-rata polyak pada parameter jaringan Q selama proses pelatihan untuk mendapatkan jaringan Q target.
3. Target bersama menggunakan teknik Q ganda terpotong.
~
perbedaan:
1. SAC berisi istilah regularisasi entropi
2. Tindakan keadaan selanjutnya yang digunakan dalam tujuan SAC berasal dariStrategi saat ini, bukan strategi sasaran.
3. Belum ada target strategi kelancaran yang jelas. TD3 melatih kebijakan deterministik dengan berpindah ke keadaan berikutnyaTambahkan kebisingan acak untuk mencapai kehalusan. SAC melatih kebijakan acak, dan gangguan dari keacakan sudah cukup untuk mencapai efek serupa.

Algoritma: SAC Aktor-Kritikus Lembut
memasuki: θ 1 , θ 2 , ϕ theta_1, theta_2, phi~~~~~θ1,θ2,ϕ Parameter inisialisasi
Inisialisasi parameter:
~~~~~~ Inisialisasi bobot jaringan target: θ ˉ 1 ← θ 1 , θ ˉ 2 ← θ 2 batang theta_1panah kiri theta_1, batang theta_2panah kiri theta_2θˉ1←θ1,θˉ2←θ2
~~~~~~ Kumpulan pemutaran diinisialisasi menjadi kosong: D ← ∅ {cal D}panah kiri kosongD←∅
untuk {bf untuk}untuk setiap iterasi melakukan {bf melakukan}Mengerjakan :
~~~~~~ untuk {bf untuk}untuk Setiap langkah lingkungan melakukan {bf melakukan}Mengerjakan :
~~~~~~~~~~~ Contoh tindakan dari suatu kebijakan: pada ∼ π ϕ ( pada ∣ st ) a_tsimpi_phi(a_t|s_t)~~~~~AT∼πϕ(AT∣ST) ▢Di sini π ϕ ( pada ∣ st ) pi_phi(a_t|s_t)πϕ(AT∣ST) Bagaimana cara mendefinisikannya?
~~~~~~~~~~~ Contoh transisi dari lingkungan: st + 1 ∼ p ( st + 1 ∣ st , di ) s_{t+1}sim p(s_{t+1}|s_t,a_t)ST+1∼P(ST+1∣ST,AT)
~~~~~~~~~~~ Simpan transisi ke kumpulan pemutaran: D ← D ∪ { (st, di, r(st, di), st + 1)} {kal D}panah kiri{kal D}~cangkir~{(s_t,a_t,r(s_t,a_t),s_{t+1})}D←D ∪ {(ST,AT,R(ST,AT),ST+1)}
~~~~~~ akhir untuk {bf akhir ~untuk}akhir untuk
~~~~~~ untuk {bf untuk}untuk Setiap langkah gradien melakukan {bf melakukan}Mengerjakan :
~~~~~~~~~~~ memperbarui Bahasa Indonesia: QQQ Parameter fungsi: untuk saya ∈ { 1 , 2 } idalam{1,2}Saya∈{1,2}, θ i ← θ i − λ Q ∇ ^ θ i JQ ( θ i ) theta_ileftarrowtheta_i-lambda_Qhat nabla_{theta_i}J_Q(theta_i)~~~~~θSaya←θSaya−λQ∇^θSayaJQ(θSaya) ▢Di sini JQ ( θ i ) J_Q(theta_i)JQ(θSaya) Bagaimana cara mendefinisikannya?
~~~~~~~~~~~ Perbarui bobot strategi: ϕ ← ϕ − λ π ∇ ^ ϕ J π ( ϕ ) phileftarrowphi-lambda_pihat nabla_phi J_pi (phi)~~~~~ϕ←ϕ−λπ∇^ϕJπ(ϕ) ▢Di sini J π ( ϕ ) J_pi (phi)Jπ(ϕ) Bagaimana cara mendefinisikannya?
~~~~~~~~~~~ Sesuaikan suhu: α ← α − λ ∇ ^ α J ( α ) alfa panah kiri alfa-lambdahatnabla_alpha J(alfa)~~~~~α←α−λ∇^αJ(α) ▢Di sini J (α) J(alfa)J(α) Bagaimana cara mendefinisikannya?Bagaimana memahami suhu di sini?
~~~~~~~~~~~ Perbarui bobot jaringan target: untuk saya ∈ { 1 , 2 } idalam{1,2}Saya∈{1,2}, Bahasa Indonesia: θ ˉ i ← τ θ i − ( 1 − τ ) θ ˉ i batang theta_ileftarrow tau theta_i-(1-tau)batang theta_i~~~~~θˉSaya←τθSaya−(1−τ)θˉSaya ▢ Bagaimana memahami hal ini aku tahuτ ? ——>Koefisien pemulusan target
~~~~~~ akhir untuk {bf akhir ~untuk}akhir untuk
akhir untuk {bf akhir ~untuk}akhir untuk
Keluaran: θ 1 , θ 1 , ϕ theta_1,theta_1,phi~~~~~θ1,θ1,ϕ Parameter yang dioptimalkan
∇ ^ topi nabla∇^: gradien stokastik
$emptyset$ ∅ ~~~~set kosong ∅


Belajar Berjalan melalui Pembelajaran Penguatan Mendalam Versi dalam:
~
α
α
α adalah parameter suhu, yang menentukan kepentingan relatif dari istilah entropi dan imbalan, sehingga mengendalikan keacakan strategi optimal.
α alfaα Besar: Jelajahi
α alfaα Kecil: eksploitasi
J ( α ) = E pada ∼ π t [ − α log π t ( pada ∣ st ) − α H ˉ ] J(alfa)=himpunan bawah{a_tsimpi_t}{mathbb E}[-alfalog pi_t(a_t|s_t)-alfabar{cal H}]J(α)=AT∼πTBahasa Inggris[−αlihatGπT(AT∣ST)−αHˉ]

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]