2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
- easy-rl PDF संस्करण नोट संगठन P5, P10 - P12
- joyrl तुलना पूरक P11-P13
- OpenAI दस्तावेज संगठन ⭐ https://spinningup.openai.com/en/latest/index.html


नवीनतम संस्करण PDF डाउनलोड
पता: https://github.com/datawhalechina/easy-rl/releases इति
घरेलुसम्बोधनम् (घरेलुपाठकानां कृते अनुशंसितम्) २.:
लिंकः https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw निष्कर्षण कोडः us6a
easy-rl online version link (प्रतिलिपिसङ्केतस्य कृते)
सन्दर्भलिङ्कः २: https://datawhalechina.github.io/joyrl-book/
इतर:
[Errata record link] इति ।
——————
5. गहन सुदृढीकरण सीखने के मूल बातें ⭐️
मुक्तस्रोतसामग्री: https://linklearner.com/learn/summary/11
——————————
समाना रणनीतिः - शिक्षितव्यः कारकः पर्यावरणेन सह अन्तरक्रियां कुर्वन् कारकः च समानाः सन्ति ।
विषमरणनीतयः : शिक्षितुं कारकः पर्यावरणेन सह अन्तरक्रियां कुर्वन् कारकः च भिन्नाः सन्ति
नीति-ढालः : आँकडानां नमूनाकरणाय बहुकालस्य आवश्यकता भवति
समान रणनीति ⟹ महत्व नमूना ~~~overset{महत्व नमूना}{दीर्घ दक्षिणबाण}~~~ ⟹महत्व नमूनाकरणम् भिन्नाः रणनीतयः
पीपीओ : अत्यधिकं भिन्नं वितरणद्वयं परिहरतु। समान रणनीति एल्गोरिदम
1. मूल अनुकूलन आइटम J ( θ , θ ′ ) J(थीटा,थीटा ^ अभाज्य)जे(θ,θ′)
2. बाध्यतावस्तूनि : १. θ थेताθ तथा θ ′ थेता^प्राइमθ′ निर्गमक्रियायाः केएल विचलनं ( . θ थेताθ तथा θ ′ थेता^प्राइमθ′ यावत् अधिकं समानं तावत् श्रेयस्करम्)
पीपीओ इत्यस्य पूर्ववर्ती अस्ति: विश्वासक्षेत्रनीतिअनुकूलनम् (TRPO) ।
TRPO इत्यस्य संचालनं कठिनं भवति यतोहि एतत् KL विचलनप्रतिबन्धं अतिरिक्तप्रतिबन्धरूपेण व्यवहरति तथा च उद्देश्यकार्य्ये न स्थापितं भवति, अतः तस्य गणना कठिना भवति अतः वयं सामान्यतया TRPO इत्यस्य स्थाने PPO इत्यस्य उपयोगं कुर्मः । पीपीओ तथा टीआरपीओ इत्येतयोः कार्यप्रदर्शनं समानं भवति, परन्तु पीपीओ इत्यस्य कार्यान्वयनम् टीआरपीओ इत्यस्मात् बहु सुकरम् अस्ति ।
KL divergence: क्रियायाः दूरम्।क्रियां कर्तुं संभाव्यतावितरणं दूरी।
पीपीओ एल्गोरिदमस्य मुख्यौ रूपौ स्तः : समीपस्थनीतिअनुकूलनदण्डः (पीपीओ-दण्डः) तथा समीपस्थनीतिअनुकूलनच्छेदनम् (पीपीओ-क्लिप्)
——————————
P10 विरलपुरस्कारसमस्या
1. डिजाइन पुरस्कार। डोमेनज्ञानस्य आवश्यकता भवति
प्रत्येकं प्रासंगिकं कार्यं अन्तिमपुरस्कारं नियुक्तं कथं भवति ?
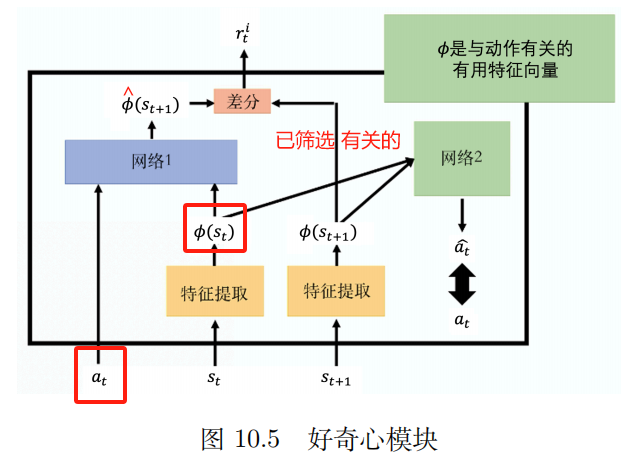
2. जिज्ञासा
आन्तरिक जिज्ञासा मॉड्यूल (ICM) 1.1.
प्रवेश: अत् , स्त अ_त,स_तएकःत,सत
उत्पादनम् : १. स ^ त् + १ हत् स्_{त्+१} ।स^त+1
जालस्य पूर्वानुमानितं मूल्यम् स ^ त् + १ हत् स्_{त्+१} ।स^त+1 सत्यमूल्येन सह स्त + १ स_{त+१} २.सत+1 यथा यथा अधिकं विषमाः सन्ति तथा तथा र्ति र_त^इरतअहम् यथा बृहत्तरम्
र्ति र_त^इरतअहम् : भविष्यस्य स्थितिः यथा यथा कठिना भवति तथा तथा कार्यस्य फलं अधिकं भवति। साहसिकं अन्वेषणं च प्रोत्साहयन्तु।
विशेषता निष्कर्षक
जालम् २ : १.
इनपुट: सदिश φ ( स्त ) {बं फि}(स_{त}) .ϕ(सत) तथा φ ( स्त + 1 ) {bm phi}(s_{t+1}) .ϕ(सत+1)
क्रियायाः पूर्वानुमानं कुरुत a ^ टोपी aएकः^ यथार्थक्रियायाः यावत् समीपं भवति तावत् उत्तमम्।
3. पाठ्यक्रमाध्ययनम्
सुलभम् -> कठिनम्
विपर्ययपाठ्यक्रमशिक्षणम् : १.
अन्तिम-अत्यन्त-आदर्श-अवस्थातः आरभ्य [वयं तत् सुवर्ण-अवस्था इति वदामः], गच्छन्तुसुवर्णराज्यस्य समीपस्थं राज्यं ज्ञातव्यम् मञ्चित "आदर्श" इति रूपेण कथयतु यत् भवन्तः एजेण्टं प्राप्तुं इच्छन्ति। अवश्यं अस्मिन् क्रमे वयं काश्चन चरमावस्थाः अर्थात् अतिसुलभाः अतिकठिनाः वा अवस्थाः इच्छया अपसारयिष्यामः ।
4. श्रेणीबद्धसुदृढीकरणशिक्षणम् (HRL) .
एजेण्टस्य रणनीतिः उच्चस्तरीयरणनीतिषु निम्नस्तरीयरणनीतिषु च विभक्ता अस्ति उच्चस्तरीयरणनीतिः वर्तमानस्थितेः आधारेण निम्नस्तरीयरणनीतिः कथं निष्पादनीया इति निर्धारयति।
————————
पृ11 अनुकरणशिक्षणम्
पुरस्कारदृश्यस्य विषये निश्चितः नास्ति
अनुकरणशिक्षणम् (IL) ९.
प्रदर्शनात् शिक्षमाणः
अप्रेंटिसशिप शिक्षण
पश्यन् शिक्षणम्
तत्र स्पष्टपुरस्काराः सन्ति : बोर्डक्रीडाः, वीडियोक्रीडाः
स्पष्टं पुरस्कारं दातुं असमर्थः: chatbot
विशेषज्ञप्रदर्शनानि संग्रहयन्तु : मानववाहनचालनस्य अभिलेखाः, मानवीयवार्तालापाः
विपर्ययम् एतानि कर्माणि निपुणः कीदृशं फलकार्यं करोति ?
विलोम सुदृढीकरणशिक्षणम् अस्तिप्रथमं पुरस्कारकार्यं ज्ञातव्यम्, पुरस्कारकार्यं ज्ञात्वा, ततः इष्टतमं अभिनेतारं अन्वेष्टुं सुदृढीकरणशिक्षणस्य उपयोगं कुर्वन्तु।
तृतीय व्यक्ति अनुकरण शिक्षण प्रौद्योगिकी
————————
P12 गहन नियतात्मक नीति ढाल (DDPG) 1.1.
अनुभवपुनःक्रीडारणनीत्याः उपयोगं कुर्वन्तु
विच्छेदन प्रयोग [नियंत्रित चर विधि] विश्लेषणप्रत्येकं बाध्यतायुद्धस्य परिणामे प्रभावः भवति ।
joyrl: ९.
आवश्यकतायांनिश्चयःरणनीति तथानिरन्तर कर्मअन्तरिक्षस्य आधारेण एषः प्रकारः एल्गोरिदम् तुल्यकालिकरूपेण स्थिरः आधाररेखा एल्गोरिदम् भविष्यति ।
निरन्तरक्रियास्थानानां कृते DQN
गहन नियतात्मक नीति ढाल एल्गोरिदम (DDPG) 1.1.
अनुभवपुनःक्रीडातन्त्रं नमूनानां मध्ये सहसंबन्धं न्यूनीकर्तुं, नमूनानां प्रभावी उपयोगं सुधारयितुम्, प्रशिक्षणस्य स्थिरतां वर्धयितुं च शक्नोति ।
अभावः : १.
1. विच्छिन्नक्रियास्थाने उपयोक्तुं न शक्यते
2、अतिमापदण्डेषु अत्यन्तं निर्भरः
3. अत्यन्तं संवेदनशीलाः प्रारम्भिकाः परिस्थितयः। एल्गोरिदम् इत्यस्य अभिसरणं कार्यक्षमतां च प्रभावितं करोति
4. स्थानीय इष्टतमं पतनं सुलभम् अस्ति।
मृदु-अद्यतनस्य लाभः अस्ति यत् एतत् सुचारुतरं मन्दतरं च भवति, यत् अत्यन्तं द्रुतगतिना भार-अद्यतन-कारणात् उत्पद्यमानं आघातं परिहरितुं शक्नोति तथा च प्रशिक्षण-विचलनस्य जोखिमं न्यूनीकर्तुं शक्नोति
द्वि-विलम्ब नियतात्मक नीति ढाल एल्गोरिदम
त्रयः सुधाराः : डबल क्यू नेटवर्क्, विलम्बितं अपडेट्, शोर नियमितीकरणं
डबल क्यू नेटवर्क : द्वौ Q जालौ, लघु Q मूल्ययुक्तं चिनुत । Q मूल्यस्य अतिआकलनसमस्यायाः निवारणं कर्तुं तथा एल्गोरिदमस्य स्थिरतां अभिसरणं च सुधारयितुम्।
विलम्बितम् अद्यतनम् : अभिनेता अद्यतन-आवृत्तिः समीक्षक-अद्यतन-आवृत्तितः न्यूना भवतु
कोलाहलः अधिकः कनियमितीकरणएवं प्रकारेण यत्मूल्य फ़ंक्शन अपडेटअधिकःमसृणः
OpenAI जिम पुस्तकालय_पेंडुलम_टीडी3
TD3 विषये OpenAI दस्तावेजान्तरफलकलिङ्कः
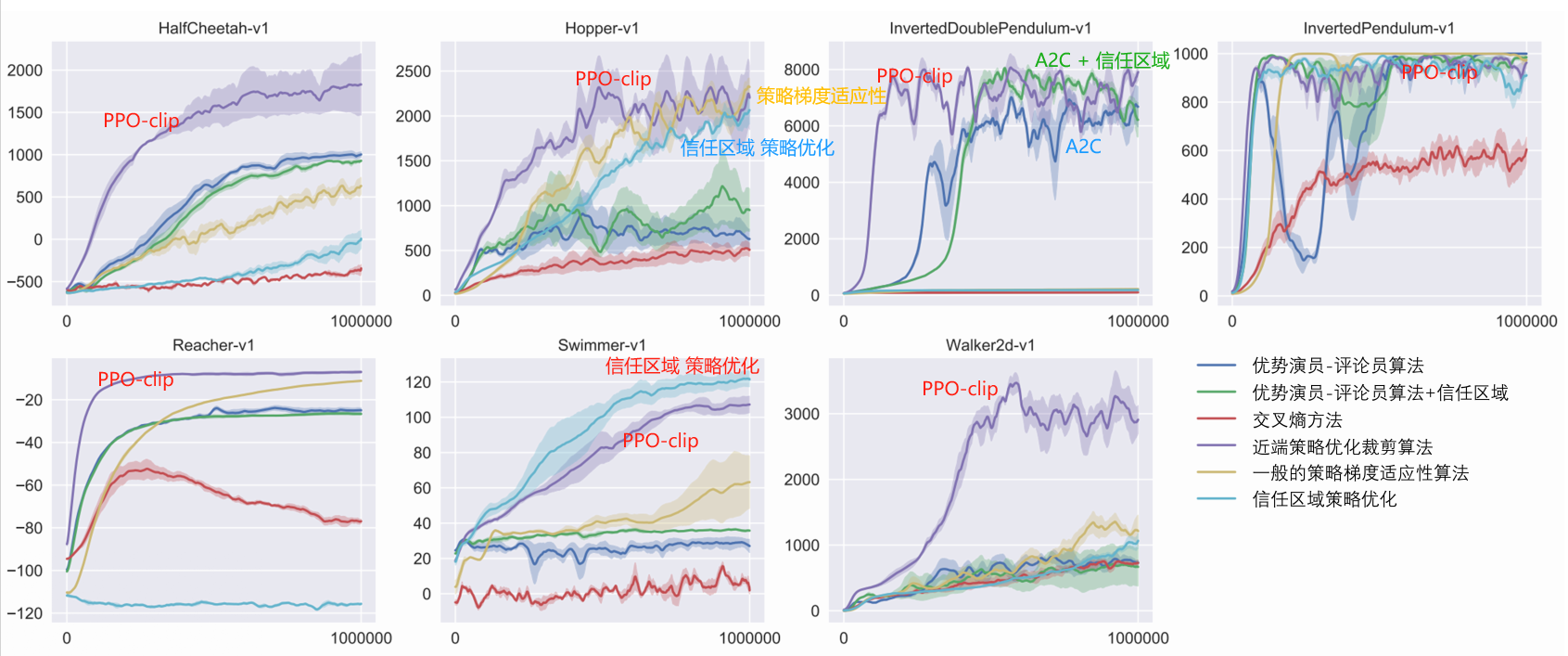
सुदृढीकरणशिक्षणे सर्वाधिकं प्रयुक्तः पीपीओ एल्गोरिदम्
विच्छिन्न + निरन्तर
द्रुतं स्थिरं च, मापदण्डं समायोजयितुं सुलभम्
आधाररेखा एल्गोरिदम
अनिर्णयित पीपीओ
व्यवहारे सामान्यतया क्लिप्-प्रतिबन्धानां उपयोगः भवति यतोहि एतत् सरलतरं, न्यूनगणनव्ययः, उत्तमपरिणामं च भवति ।
नीतितः बहिः एल्गोरिदम् कर्तुं शक्नोतिऐतिहासिक अनुभवस्य लाभं ग्रहीतुं, सामान्यतया पूर्वानुभवस्य संग्रहणार्थं पुनः उपयोगाय च अनुभवपुनर्क्रीडायाः उपयोगं कुर्वन्ति,दत्तांशस्य उपयोगस्य दक्षता अधिका अस्ति。
पीपीओ इति नीतिगतं एल्गोरिदम् अस्ति
——————————————————
OpenAI दस्तावेजीकरणम्
कागज arXiv अन्तरफलकलिङ्कः: निकटतमनीतिअनुकूलन एल्गोरिदम्
पीपीओ: नीतिगत-एल्गोरिदम्, असतत-अथवा निरन्तर-क्रिया-स्थानानां कृते उपयुक्तम् ।संभव स्थानीय इष्टतम
पीपीओ इत्यस्य प्रेरणा टीआरपीओ इत्यस्य समाना एव अस्ति यत् विद्यमानदत्तांशस्य लाभः कथं भवति इतिस्वस्य रणनीत्यां बृहत्तमं सम्भवं सुधारपदं गृह्यताम्, अत्यधिकं परिवर्तनं विना तथा च आकस्मिकतया प्रदर्शनदुर्घटनाम् अकुर्वन्?
TRPO परिष्कृतेन द्वितीय-क्रम-पद्धत्या एतस्याः समस्यायाः समाधानं कर्तुं प्रयतते, यदा तु PPO प्रथम-क्रम-पद्धत्या नूतन-रणनीतिं पुरातन-रणनीत्याः समीपे एव स्थापयितुं अन्येषां केषाञ्चन युक्तीनां उपयोगं करोति
पीपीओ पद्धतिः कार्यान्वितुं बहु सरलं भवति तथा च अनुभवजन्यरूपेण न्यूनातिन्यूनं टीआरपीओ इव कार्यं करोति ।
पीपीओ इत्यस्य मुख्यौ द्वौ भिन्नौ स्तः - पीपीओ-दण्डः पीपीओ-क्लिप् च ।


एल्गोरिदम: पीपीओ-क्लिप
1: Input: प्रारम्भिकरणनीतिमापदण्डाः θ ० थेता_०θ0, प्रारम्भिकमूल्यकार्यमापदण्डाः φ ० फि_०ϕ0
2: for k = 0 , 1 , 2 , ... do {bf for} ~ k=0,1,2,बिन्दव~ {bf do}कृते k=0,1,2,… करोतु:
3: ~~~~~~ पर्यावरणे नीतिं चालयित्वा π k = π ( θ k ) पि_क=पि(थेटा_क)πk=π(θk) प्रक्षेपवक्रसमूहं संग्रहयन्तु D k = { τ i } {cal D}_k={तौ_इ}घk={τअहम्}
4: ~~~~~~ पुरस्कारस्य गणनां कुरुत (rewards-to-go) २. र ^ त हत् R_t~~~~~आर^त ▢ र ^ त हत् R_tआर^त गणनानियमाः
5: ~~~~~~ लाभानुमानं गणयन्तु, वर्तमानमूल्यकार्यस्य आधारेण वि φ क व_{फी_क}विϕk इत्यस्य अ ^ त हत् अ_तएकः^त (किमपि वर्चस्वानुमानपद्धतिं प्रयुञ्जीत) ~~~~~ ▢ वर्तमान-लाभ-अनुमान-विधयः कानि सन्ति ?
6: ~~~~~~ PPO-Clip उद्देश्यकार्यं अधिकतमं कृत्वा नीतिं अद्यतनं कुर्वन्तु:
~~~~~~~~~~~
θ k + 1 = arg अधिकतम θ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T min ( π θ ( at ∣ st ) π θ k ( at ∣ st ) A π θ k ( st , at ) , g ( ε , A π θ k ( st , at ) ) ) ~~~~~~~~~~~~theta_{k+1}=argmaxlimits_thetafrac{1}{|{cal D}_k|T }समसीमा_{तौइन्{कल डी}_क}समसीमा_{t=0}^TminBig(frac{pi_{theta} (a_t|s_t)}{पि_{थेटा_क}(a_t|s_t)}A^{pi_{थेटा_क}} (s_t,a_t),g(epsilon,A^{pi_{थेटा_क}}(s_t,a_t))बृहत्) θk+1=अर्छθअधिकतमम्∣घk∣टी1τ∈घk∑त=0∑टीमि(πθk(एकःत∣सत)πθ(एकःत∣सत)एकःπθk(सत,एकःत),छ(ϵ,एकःπθk(सत,एकःत))) ~~~~~ ▢ रणनीति-अद्यतन-सूत्रं कथं निर्धारयितव्यम् ?
~~~~~~~~~~~
~~~~~~~~~~~ π θ k पि_{थेता_क}πθk : अद्यतनीकरणात् पूर्वं रणनीतिः पैरामीटर् सदिशः। महत्व नमूनाकरणम्। पुरातनरणनीतिभ्यः नमूनाकरणम्।
~~~~~~~~~~~
~~~~~~~~~~~ सामान्य आकस्मिक ढाल आरोहण + एडम
7: ~~~~~~ मध्यमवर्गदोषःप्रतिगमन फिट मूल्य कार्य:
~~~~~~~~~~~
φ k + 1 = arg min φ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T ( V φ ( st ) − R ^ t ) 2 ~~~~~~~~~~~phi_ {k+1}=arg minlimits_phifrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TBig(V_phi(s_t)-टोपी R_tBig)^2 ϕk+1=अर्छϕमि∣घk∣टी1τ∈घk∑त=0∑टी(विϕ(सत)−आर^त)2
~~~~~~~~~~~
~~~~~~~~~~~ सामान्य ढाल अवरोह
8: end for bf अन्त्य ~ forअंत कृते
~~~~~~~~~~~~
$dots$ ... ~~~बिन्दवः …
g ( ε , A ) = { ( 1 + ε ) A A ≥ 0 ( 1 − ε ) AA < 0 g(epsilon,A)=वाम{(1+ϵ)एकः एकः≥0(1−ϵ)एकःएकः<0दक्षिणः। छ(ϵ,एकः)={(1+ϵ)एकः (1−ϵ)एकःएकः≥0एकः<0

पत्रेलाभस्य अनुमानम् : १.
A ^ t = − V ( st ) + rt + γ rt + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) ⏟ R ^ t ? ? ? hat A_t=-V(s_t)+अंडरब्रेस{r_t+गामा r_{t+1}+cdots+गामा^{T-t+1}r_{T-1}+गामा^{Tt}V(s_T)}_ {पाठरङ्ग{नील}{हत् र_त???}}एकः^त=−वि(सत)+आर^त??? रत+γरत+1+⋯+γटी−त+1रटी−1+γटी−तवि(सटी)

निर्मीयताम् Δ t = rt + γ V ( st + 1 ) − V ( st ) डेल्टा_t =r_t+गामा V(s_{t+1})-V(s_t)Δत=रत+γV(सत+1)−वि(सत)
किन्तु rt = Δ t − γ V ( st + 1 ) + V ( st ) r_t=डेल्टा_ट - गामा V(s_{t+1})+V(s_t)रत=Δत−γV(सत+1)+वि(सत)
पर्याय अ ^ त हत् अ_तएकः^त अभिव्यक्ति
A ^ t = − V ( st ) + rt + γ rt + 1 + γ 2 rt + 2 + ⋯ + γ T − tr T − 2 + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( st ) + rt + γ rt + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( st ) + Δ t − γ वि ( स्त + 1 ) + वि ( स्त ) + γ ( Δ टी + 1 − γ वि ( स्त + 2 ) + वि ( स्त + 1 ) ) + γ 2 ( Δ त + 2 − γ वि ( स्त + 3 ) . + V ( st + 1 ) ) + ⋯ + γ T − t ( Δ T − t − γ V ( s T − t + 1 ) + V ( s T − t ) ) + γ T − t + 1 ( Δ T − 1 − γ V ( s T ) + V ( s T − 1 ) ) + γ T − t V ( s T ) = Δ t + γ Δ t + 1 + γ 2 Δ t + 2 + ⋯ + γ T − t Δ T − t + γ T − t + 1 Δ T − 1ˆएकःत=−वि(सत)+रत+γरत+1+γ2रत+2+⋯+γटी−तरटी−2+γटी−त+1रटी−1+γटी−तवि(सटी)=−वि(सत)+रत+γरत+1+⋯+γटी−त+1रटी−1+γटी−तवि(सटी)=−वि(सत)+ Δत−γवि(सत+1)+वि(सत)+ γ(Δत+1−γवि(सत+2)+वि(सत+1))+ γ2(Δत+2−γवि(सत+3)+वि(सत+1))+ ⋯+ γटी−त(Δटी−त−γवि(सटी−त+1)+वि(सटी−त))+ γटी−त+1(Δटी−1−γवि(सटी)+वि(सटी−1))+ γटी−तवि(सटी)=Δत+γΔत+1+γ2Δत+2+⋯+γटी−तΔटी−त+γटी−त+1Δटी−1 एकः^त=−वि(सत)+रत+γरत+1+γ2रत+2+⋯+γटी−तरटी−2+γटी−त+1रटी−1+γटी−तवि(सटी)=−वि(सत)+रत+γरत+1+⋯+γटी−त+1रटी−1+γटी−तवि(सटी)=−वि(सत)+ Δत−γV(सत+1)+वि(सत)+ γ(Δत+1−γV(सत+2)+वि(सत+1))+ γ2(Δत+2−γV(सत+3)+वि(सत+1))+ ⋯+ γटी−त(Δटी−त−γV(सटी−त+1)+वि(सटी−त))+ γटी−त+1(Δटी−1−γV(सटी)+वि(सटी−1))+ γटी−तवि(सटी)=Δत+γΔत+1+γ2Δत+2+⋯+γटी−तΔटी−त+γटी−त+1Δटी−1

नीतियां तीव्रपरिवर्तनस्य प्रोत्साहनं दूरीकृत्य क्लिपिंग् नियमितीकरणस्य कार्यं करोति ।अतिपैरामीटर् ε epsilon इतिϵ नूतनरणनीत्याः पुरातनरणनीत्याः च दूरं सङ्गतम् अस्ति。
अद्यापि सम्भवति यत् एतादृशस्य च्छेदनस्य परिणामः अन्ते नूतना रणनीतिः भविष्यति या पुरातनरणनीत्याः दूरम् अस्ति अत्र कार्यान्वयनस्य मध्ये वयं विशेषतया सरलपद्धतिं उपयुञ्ज्महे ।प्राक् स्थगयतु . यदि पुरातननीत्याः नूतननीतेः औसतं KL-विचलनं सीमां अतिक्रमति तर्हि वयं ढालपदं निष्पादयितुं त्यजामः ।
पीपीओ उद्देश्य कार्य सरल व्युत्पत्ति कड़ी
पीपीओ-क्लिप् इत्यस्य उद्देश्यकार्यं अस्ति : १.
~
L θ k CLIP ( θ ) = E s , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , क्लिप ( π θ ( a ∣ ) s ) π θ k ( a ∣ s ) , 1 − ε , 1 + ε ) A θ k ( s , a ) ) ] L^{rm CLIP}_{थेटा_क}(थीटा)=अंडरसेट्{स, असिम्थेटा_क}{ rm E}बिग्ग[minBigg(frac{pi_theta(a|s)}{पि_{थेटा_क}(क|s)}A^{थेटा_क}(s, a), {rm clip}बृहत्(frac{pi_theta(a|..)। s)}{पि_{थेटा_क}(क|स)},1-एप्सिलोन, 1+एप्सिलोनबिग)अ^{थेटा_क}(स, क)बिग्ग)बिग्ग]।लθkCLIP इति(θ)=स,एकः∼θkई[मि(πθk(एकः∣स)πθ(एकः∣स)एकःθk(स,एकः),clip(πθk(एकः∣स)πθ(एकः∣स),1−ϵ,1+ϵ)एकःθk(स,एकः))]
~
$underset{s, asimtheta_k}{rm E}$E s , a ∼ θ k ~~~अण्डरसेट{s, असिमथेता_क्}{र्म ई} स,एकः∼θkई
~
नहि। क्क्k पुनरावृत्तीनां कृते रणनीतिमापदण्डाः θ क थेता_क्θk, ε epsilon इतिϵ लघु अतिपरामीटर् अस्ति ।
स्थापयति ε ∈ ( 0 , 1 ) एप्सिलोनिन (0,1) .ϵ∈(0,1), परिभाषा
F ( आर , ए , ε ) ≐ min ( आर ए , क्लिप ( आर , 1 − ε , 1 + ε ) ए ) च (आर, ए, एप्सिलॉन) doteqminBigg (rA, {rm क्लिप} (आर, 1- एप्सिलॉन,१+एप्सिलॉन)ABigg) २.च(र,एकः,ϵ)≐मि(रएकः,clip(र,1−ϵ,1+ϵ)एकः)
कदा A ≥ 0 Ageq0एकः≥0
F ( r , A , ε ) = min 2 ( r A , क्लिप ( r , 1 − ε , 1 + ε ) A ) = A min ( r , क्लिप ( r , 1 − ε , 1 + ε ) ) = A min ( r , { 1 + ε r ≥ 1 + ε rr ∈ ( 1 − ε , 1 + ε ) 1 − ε r ≤ 1 − ε } ) = A { min ( r , 1 + ε ) r ≥ 1 + ε min ( r , r ) r ∈ ( 1 − ε , 1 + ε ) min ( r , 1 − ε ) r ≤ 1 − ε } = A { 1 + ε r ≥ 1 + ε rr ∈ ( 1 − ε , 1 + ε ) rr ≤ 1 − ε } दक्षिणपार्श्वे परिधिनुसारम् = A min ( r , 1 + ε ) = min ( r A , ( 1 + ε ) A ) .begin {aligned} F (आर, ए, एप्सिलॉन) & = minBigg (आर ए, {आर एम क्लिप} (आर, 1-एप्सिलॉन, 1 + एप्सिलॉन) एबिग) \ & = अमीन बिग (आर, {आर एम क्लिप} (आर, 1 -एप्सिलॉन, 1 + एप्सिलॉन) बिग) \ &=अमिनबिग्ग (आर, बाएं {शुरु {संरेखित} & 1 + एप्सिलॉन ~ ~ & rgeq1 + एप्सिलॉन \ & आर & rin (1- एप्सिलॉन, 1 + एप्सिलॉन) \ & 1- एप्सिलॉन & rleq1- एप्सिलॉन \ अन्त{संरेखित} २.right}बृहत्)\ &=बाम{मिदक्षिण}\ &=वाम{right}~~~~~textcolor{blue}{दक्षिणतः श्रेणी के अनुसार}\ &=अमीन(r, 1+epsilon)\ &=minBigg(rA, (1+epsilon)ABigg) end{aligned} च(र,एकः,ϵ)=मि(रएकः,clip(र,1−ϵ,1+ϵ)एकः)=एकःमि(र,clip(र,1−ϵ,1+ϵ))=एकःमि(र,⎩ ⎨ ⎧1+ϵ र1−ϵर≥1+ϵर∈(1−ϵ,1+ϵ)र≤1−ϵ⎭ ⎬ ⎫)=एकः⎩ ⎨ ⎧मि(र,1+ϵ) मि(र,र)मि(र,1−ϵ)र≥1+ϵर∈(1−ϵ,1+ϵ)र≤1−ϵ⎭ ⎬ ⎫=एकः⎩ ⎨ ⎧1+ϵ ररर≥1+ϵर∈(1−ϵ,1+ϵ)र≤1−ϵ⎭ ⎬ ⎫ दक्षिणतः श्रेण्यानुसारम्=एकःमि(र,1+ϵ)=मि(रएकः,(1+ϵ)एकः)
~
कदा क < ० क<०एकः<0
F ( r , A , ε ) = min ( r A , क्लिप ( r , 1 − ε , 1 + ε ) A ) = A max 2 ( r , क्लिप ( r , 1 − ε , 1 + ε ) ) = A max ( r , { 1 + ε r ≥ 1 + ε rr ∈ ( 1 − ε , 1 + ε ) 1 − ε r ≤ 1 − ε } ) = A { अधिकतम ( r , 1 + ε ) r ≥ 1 + ε अधिकतम ( आर , आर ) आर ∈ ( 1 − ε , 1 + ε ) अधिकतम ( आर , 1 − ε ) आर ≤ 1 − ε } = A { आर आर ≥ 1 + ε r ∈ ( 1 − ε , 1 + ε ) 1 − ε r ≤ 1 − ε } दक्षिणपार्श्वे परिधिनुसारम् = A max ( r , 1 − ε ) = min ( r A , ( 1 − ε ) A ) .right}बृहत्)\ &=बाम{दक्षिण}\ &=वाम{right}~~~~~textcolor{blue}{दक्षिणतः श्रेणी के अनुसार}\ &=Amax(r, 1-epsilon)\ &=textcolor{blue}{min}Bigg(rA,(1-epsilon) एबिग्ग्) अन्त{संरेखित} २. च(र,एकः,ϵ)=मि(रएकः,clip(र,1−ϵ,1+ϵ)एकः)=एकःपुएकःx(र,clip(र,1−ϵ,1+ϵ))=एकःअधिकतमम्(र,⎩ ⎨ ⎧1+ϵ र1−ϵर≥1+ϵर∈(1−ϵ,1+ϵ)र≤1−ϵ⎭ ⎬ ⎫)=एकः⎩ ⎨ ⎧अधिकतमम्(र,1+ϵ) अधिकतमम्(र,र)अधिकतमम्(र,1−ϵ)र≥1+ϵर∈(1−ϵ,1+ϵ)र≤1−ϵ⎭ ⎬ ⎫=एकः⎩ ⎨ ⎧र र1−ϵर≥1+ϵर∈(1−ϵ,1+ϵ)र≤1−ϵ⎭ ⎬ ⎫ दक्षिणतः श्रेण्यानुसारम्=एकःअधिकतमम्(र,1−ϵ)=पुअहम्न(रएकः,(1−ϵ)एकः)
~
सारांशतः : परिभाषितव्यः g ( ε , A ) g(एप्सिलॉन,A) 1 .छ(ϵ,एकः)
g ( ε , A ) = { ( 1 + ε ) A A ≥ 0 ( 1 − ε ) AA < 0 g(epsilon,A)=वाम{दक्षिणः। छ(ϵ,एकः)={(1+ϵ)एकः (1−ϵ)एकःएकः≥0एकः<0
एषा परिभाषा नूतनरणनीत्याः पुरातनरणनीत्याः अतिदूरं गन्तुं किमर्थं निवारयति ?
प्रभावी महत्त्वनमूनाकरणपद्धतीनां कृते नूतनानां रणनीतयः आवश्यकाः सन्ति π θ ( a ∣ s ) पि_थेता(क|स) .πθ(एकः∣स) तथा पुरातन रणनीतयः π θ k ( a ∣ s ) पि_{थेता_क}(क|स) .πθk(एकः∣स) द्वयोः वितरणयोः भेदः अतिबृहत् न भवितुम् अर्हति
1. यदा लाभः सकारात्मकः भवति
L ( s , a , θ k , θ ) = min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 + ε ) A π θ k ( s , a ) L(s,a, थेटा_क, थेटा)=मिनबिग्ग(फ्रक्{पी_थेटा(क|स)}{पि_{थेटा_क}(क|स)}, 1+एप्सिलोनबिग्ग)ए^{पि_{थेटा_क}}(स, क)ल(स,एकः,θk,θ)=मि(πθk(एकः∣स)πθ(एकः∣स),1+ϵ)एकःπθk(स,एकः)
लाभकार्यम् : अधिकपुरस्कारयुक्तं निश्चितं राज्य-क्रियायुगलं ज्ञातव्यम् -> राज्य-क्रियायुग्मस्य भारं वर्धयन्तु।
यदा अवस्थाकर्मयुग्मम् ( स , क ) (स, क) .(स,एकः) सकारात्मकं तर्हि यदि कर्म आएकः निष्पादनस्य अधिका सम्भावना भवति अर्थात् यदि π θ ( a ∣ s ) पि_थेता(क|स) .πθ(एकः∣स) वर्धयतु लक्ष्यं च वर्धते।
min अस्मिन् द्रव्ये उद्देश्यकार्यं केवलं निश्चितमूल्यं यावत् वर्धयितुं सीमितं करोति
एकदा π θ ( a ∣ s ) > ( 1 + ε ) π θ k ( a ∣ s ) पि_थेटा(क|स)>(1+एप्सिलोन)पि_{थेटा_क}(क|स)πθ(एकः∣स)>(1+ϵ)πθk(एकः∣स), min triggers, अस्य द्रव्यस्य मूल्यं यावत् सीमितं करोति ( 1 + ε ) π θ k ( a ∣ s ) (1+एप्सिलोन)पि_{थेटा_क}(क|स)(1+ϵ)πθk(एकः∣स)。
पुरातननीत्याः दूरं गत्वा नूतननीतेः लाभः न भवति।
पुरातनरणनीत्याः दूरं गत्वा नूतनरणनीत्याः लाभः न भविष्यति।
2. यदा लाभः नकारात्मकः भवति
L ( s , a , θ k , θ ) = max ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ε ) A π θ k ( s , a ) L(s,a, थेटा_क, थेटा)=मैक्सबिग्ग(फ्रैक{पि_थेटा(क|स)}{पि_{थेटा_क}(क|स)}, 1-एप्सिलोनबिग्ग)ए^{पि_{थेटा_क}}(स, क)ल(स,एकः,θk,θ)=अधिकतमम्(πθk(एकः∣स)πθ(एकः∣स),1−ϵ)एकःπθk(स,एकः)
यदा अवस्थाकर्मयुग्मम् ( स , क ) (स, क) .(स,एकः) लाभः नकारात्मकः, तर्हि यदि कर्म आएकः अपि न्यूनसंभावना इत्यर्थः π θ ( a ∣ s ) π_थेटा(क|s) .πθ(एकः∣स) न्यूनीभवति, उद्देश्यकार्यं वर्धते। परन्तु अस्मिन् पदे अधिकतमः उद्देश्यकार्यं कियत् वर्धयितुं शक्यते इति सीमां ददाति ।
एकदा π θ ( a ∣ s ) < ( 1 − ε ) π θ k ( a ∣ s ) पि_थेटा(क|स)<(1-एप्सिलोन)पि_{थेटा_क}(क|स)πθ(एकः∣स)<(1−ϵ)πθk(एकः∣स), max triggers, अस्य द्रव्यस्य मूल्यं यावत् सीमितं करोति ( 1 − ε ) π θ k ( a ∣ s ) (1-एप्सिलोन)पि_{थेटा_क}(क|स)(1−ϵ)πθk(एकः∣स)。
पुनः : पुरातननीत्याः दूरं गत्वा नूतननीतेः लाभः न भवति।
पुरातनरणनीत्याः दूरं गत्वा नूतनरणनीत्याः लाभः न भविष्यति।
यद्यपि DDPG कदाचित् उत्तमं प्रदर्शनं प्राप्तुं शक्नोति तथापि हाइपरपैरामीटर् इत्यादिप्रकारस्य ट्यूनिङ्गस्य विषये प्रायः अस्थिरः भवति ।
एकः सामान्यः DDPG विफलताविधिः अस्ति यत् ज्ञातं Q-कार्यं Q-मूल्यं महत्त्वपूर्णतया अति-आकलनं कर्तुं आरभते, यत् ततः नीतिं भङ्गं जनयति यतोहि एतत् Q-कार्यं त्रुटिं शोषयति
Twin Delayed DDPG (TD3) इति एकः एल्गोरिदम् अस्ति यः त्रीणि प्रमुखाणि तकनीकानि परिचययित्वा एतस्याः समस्यायाः समाधानं करोति:
1、ट्रंकटेड डबल क्यू-शिक्षण。
2、नीति अद्यतनविलम्ब。
3. लक्ष्यरणनीतिसुचारुकरणम्।
TD3 एकः नीतितः बहिः एल्गोरिदम् अस्ति तस्य उपयोगः केवलं सह कर्तुं शक्यते;निरन्तरम्क्रियास्थानस्य परिवेशः ।

एल्गोरिदम: TD3
यादृच्छिकमापदण्डानां उपयोगं कुर्वन्तु θ 1 , θ 2 , φ थेटा_1, थेटा_2, फिθ1,θ2,ϕ समीक्षकजालस्य आरम्भं कुर्वन्तु Q θ 1 , Q θ 2 Q_{थीटा_1},Q_{थीटा_2}प्रθ1,प्रθ2, तथा अभिनेताजालम् π φ पि_फिπϕ
लक्ष्यजालस्य आरम्भं कुर्वन्तु θ 1 ′ ← θ 1 , θ 2 ′ ← θ 2 , φ ′ ← φ थीटा_1^प्राइमेलेफ्ताररोथेटा_1, थेटा_2^प्रिमलेफ्ताररोथेटा_2, फि^प्रिमलेफ्ताररो फिθ1′←θ1,θ2′←θ2,ϕ′←ϕ
प्लेबैक बफर सेट् आरभत B cal Bख
for t = 1 to T {bf for}~t=1 ~{bf to} ~Tकृते त=1 इत्यस्मै टी :
~~~~~~ अन्वेषणशब्देन सह क्रियायाः चयनं कुर्वन्तु a ∼ π φ ( s ) + ε , ε ∼ N ( 0 , σ ) asimpi_phi (s) + एप्सिलॉन, ~ ~ एप्सिलोनसिम {cal N} (0, सिग्मा)एकः∼πϕ(स)+ϵ, ϵ∼न॰(0,σ), अवलोकनपुरस्कारः र्र्र तथा नवीन स्थिति s ′ s^प्राइमस′
~~~~~~ संक्रमण तुपलः ( स , क , र , स ′ ) (स, अ, र, स^प्राइम)(स,एकः,र,स′) निक्षेपं प्रति B cal Bख मध्यं
~~~~~~ इत्यस्मात् B cal Bख लघुसमूहानां नमूनाकरणम् एन.एनन॰ संक्रमणानि ( स , क , र , स ′ ) (स, क, र, स^ अभाज्य)(स,एकः,र,स′)
a ~ ← π φ ′ ( s ′ ) + ε , ε ∼ क्लिप ( N ( 0 , σ ~ ) , − c , c ) ~~~~~~widetilde aleftarrow pi_{phi^prime}(s^prime)+ एप्सिलॉन, ~ ~ एप्सिलोनसिम {आर एम क्लिप} ({कैल एन} (0, वाइडेटिल्ड सिग्मा),-ग, सी) एकः ←πϕ′(स′)+ϵ, ϵ∼clip(न॰(0,σ ),−ग,ग)
y ← r + γ min i = 1 , 2 Q θ i ′ ( s ′ , a ~ ) ~~~~~~yleftarrow r+गामा minlimits_{i=1,2}Q_{थेटा_i^प्राइम}(s^ अभाज्य,विस्तृति क) २. य्←र+γअहम्=1,2मिप्रθअहम्′(स′,एकः )
~~~~~~ अद्यतनसमीक्षकाः θ i ← arg min θ i N − 1 ∑ ( y − Q θ i ( s , a ) ) 2 theta_ileftarrowargminlimits_{theta_i}N^{-1}sum(y-Q_{theta_i}(s, a)) ^2θअहम्←अर्छθअहम्मिन॰−1∑(य्−प्रθअहम्(स,एकः))2
~~~~~~ यदि t % d {bf यदि}~t~ % ~dयदि त % घ:
~~~~~~~~~~~ नियतात्मकनीतिप्रवणतायाः माध्यमेन अद्यतनं कुर्वन्तु φ फिϕ
∇ φ J ( φ ) = N − 1 ∑ ∇ a Q θ 1 ( s , a ) ∣ a = π φ ( s ) ∇ φ π φ ( s ) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ~~~नबला _फी ज(फी)=न^{-1}सुम्नाब्ला_क_{थेटा_1}(स, क)|_{क=पि_फी(स)}नबला_फिपि_फी(स) ∇ϕजे(ϕ)=न॰−1∑∇एकःप्रθ1(स,एकः)∣एकः=πϕ(स)∇ϕπϕ(स)
~~~~~~~~~~~ लक्ष्यजालम् अद्यतनं कुर्वन्तु : १.
θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ ~~~~~~~~~~~~~~~~~~~~थेटा_इ^प्रिमलेफ्तारौथेटा_इ+(1-तौ)थेटा_इ^प्राइम~~~~~~ θअहम्′←τθअहम्+(1−τ)θअहम्′ τ तौτ: लक्ष्य अद्यतन दर
φ ′ ← τ φ + ( 1 − τ ) φ ′ ~~~~~~~~~~~~~~~~~~~~फि^प्रिमलेफ्ताररोतौफी+(1-तौ)फी^प्राइम ϕ′←τϕ+(1−τ)ϕ′
अन्त यदि ~~~~~~{bf अन्त ~यदि} अंत यदि
अन्तः {bf अन्तः ~ कृते} कृते ।अंत कृते

नीतेः एन्ट्रोपी अधिकतमं कुर्वन्तु, तस्मात् नीतिः अधिका दृढा भवति ।
नियतात्मक रणनीति समानावस्था दत्ता सदा समानं कर्म चिनुत इत्यर्थः
यादृच्छिकता रणनीति दत्तावस्थायां चयनं कर्तुं शक्यन्ते बहूनि सम्भाव्यक्रियाः इति भावः ।
| नियतात्मक रणनीति | यादृच्छिकता रणनीति | |
|---|---|---|
| परिभाषा | समानावस्था, समानं कर्म कुरु | समाना स्थितिः, २.भिन्नानि कर्माणि कुर्वन्तु |
| लाभ | स्थिरं पुनरावर्तनीयं च | स्थानीय इष्टतमसमाधानयोः पतनं परिहरन्तु तथा वैश्विकसन्धानक्षमतासु सुधारं कुर्वन्तु |
| अभावः | अन्वेषणीयतायाः अभावः, प्रतिद्वन्द्वीभिः सुलभः च गृहीतः | एतेन रणनीतिः मन्दं मन्दं अभिसरणं कर्तुं शक्नोति, येन कार्यक्षमता, कार्यप्रदर्शनं च प्रभावितं भवति । |
वास्तविकप्रयोगे यदि परिस्थितयः अनुमन्यन्ते तर्हि वयं करिष्यामःप्रयोगं कर्तुं प्रयतस्वयादृच्छिकता रणनीति, यथा A2C, PPO इत्यादयः, यतः इदं अधिकं लचीलं, अधिकं दृढं, अधिकं स्थिरं च भवति ।
अधिकतम-एन्ट्रोपी-सुदृढीकरण-शिक्षणस्य मतं यत् वर्तमानकाले अस्माकं समीपे परिपक्व-यादृच्छिकता-रणनीतयः सन्ति, अर्थात् एसी-सदृशाः एल्गोरिदम्-इत्येतत् अपि, अद्यापि अस्माभिः इष्टतम-यादृच्छिकता न प्राप्ताअतः क इति प्रवर्तयतिसूचना एन्ट्रोपीअवधारणा, inनीतेः एन्ट्रोपी अधिकतमं कुर्वन् सञ्चितपुरस्कारं अधिकतमं कुर्वन्तु, रणनीतिं अधिकं दृढं कृत्वा इष्टतमं यादृच्छिकता रणनीतिं प्राप्तुं च।
——————————————————
OpenAI Documentation_SAC अन्तरफलकलिङ्कः
~
मृदु अभिनेता-आलोचकः : एकेन आकस्मिकनटेन सह नीतितः बहिः अधिकतमं एन्ट्रोपी गहनसुदृढीकरणशिक्षणम्, हार्नोजा एट अल, 201808 आईसीएमएल 2018
मृदु अभिनेता-समीक्षक एल्गोरिदम एवं अनुप्रयोग, हार्नोजा एट अल, 201901
गहनसुदृढीकरणशिक्षणद्वारा चलितुं शिक्षणम्, हार्नोजा एट अल, 201906 आरएसएस2019
मृदु अभिनेता समीक्षकः (SAC) नीतितः बहिः रीत्या यादृच्छिकरणनीतयः अनुकूलयति ।
DDPG + आकस्मिक रणनीति अनुकूलन
न तु TD3 (तत् एव समये एव मुक्तम्) इत्यस्य प्रत्यक्षं उत्तराधिकारी ।
अस्मिन् क्लिप्ड् डबल-क्यू युक्तिः समाविष्टा अस्ति, तथा च SAC इत्यस्य रणनीतेः निहितस्य यादृच्छिकतायाः कारणात्, अन्ततः तस्य लाभः अपि भवतिलक्ष्य नीति सुचारूीकरण。
SAC इत्यस्य एकं मूलविशेषता अस्ति एन्ट्रोपी नियमितीकरण एन्ट्रोपी नियमितीकरण。
अपेक्षितपुरस्कारस्य एन्ट्रोपी च अधिकतमं व्यापारं कर्तुं नीतिः प्रशिक्षिता अस्ति,एन्ट्रोपी इति नीतेः यादृच्छिकतायाः मापः。
एतस्य अन्वेषणस्य शोषणस्य च व्यापारस्य निकटतया सम्बन्धः अस्ति : एन्ट्रोपीयाः वृद्धिः भवतिअधिकं अन्वेषणीयम्,एतत् ठीकम् अस्तितदनन्तरं शिक्षणं त्वरयन्तु .अयं अस्तुनीतिः अकालं दुष्टस्थानीय इष्टतमं प्रति अभिसरणं न भवतु。
निरन्तरक्रियास्थाने, विच्छिन्नक्रियास्थाने च अस्य उपयोगः कर्तुं शक्यते ।
अस्ति एन्ट्रोपी-नियमित सुदृढीकरण शिक्षण, कारकं प्राप्नोति चअस्मिन् समयपदे नीतेः एन्ट्रोपीआनुपातिक पुरस्कार।
अस्मिन् समये RL समस्या एतादृशी वर्णिता अस्ति :
π ∗ = arg अधिकतम π E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ) ] pi^*=argmaxlimits_pi अंडरसेट {tausimpi}{rm E}बृहत्[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})textcolor{blue}{+अल्फा H(pi(·|s_t))} बृहत्)बृहत्] २.π∗=अर्छπअधिकतमम्τ∼πई[त=0∑∞γत(आर(सत,एकःत,सत+1)+αह(π(⋅∣सत)))]
इत्यस्मिन् α > 0 अल्फा > 0α>0 इति व्यापार-गुणकम् ।
प्रत्येकं समयपदे एन्ट्रोपीपुरस्कारं सहितं राज्यमूल्यकार्यं वि π वि^पिविπ कृते:
V π ( s ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s ] V^pi (s)=अंडरसेट{तौसिम्पी}{र्म ई}बृहत्[समसीमा_{टी=0}^इन्फ्टिगम्मा^टबड(आर(स_ट,ए_ट,स_{ट+1})+अल्फा एच(पी(·|स_ट))बड )बृहत्|s_0=sबृहत्]विπ(स)=τ∼πई[त=0∑∞γत(आर(सत,एकःत,सत+1)+αह(π(⋅∣सत))) स0=स]
एकं क्रियामूल्यं कार्यं यस्मिन् प्रथमसमयपदं विहाय प्रत्येकस्य समयपदस्य एन्ट्रोपीपुरस्कारः समाविष्टः भवति Q π Q^piप्रπ:
Q π ( s , a ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( st , at , st + 1 ) + α ∑ t = 1 ∞ H ( π ( ⋅ ∣ st ) ) ) ∣ s 0 = s , a 0 = a ] Q^pi(s,a)=अंडरसेट{तौसिम्पि}{rm E}बृहत्[समसीमा_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1 })+अल्फा शिखर_{t=1}^infty H(pi(·|s_t))बड़े)बड़े|s_0=s,a_0=aBig]प्रπ(स,एकः)=τ∼πई[त=0∑∞γत(आर(सत,एकःत,सत+1)+αत=1∑∞ह(π(⋅∣सत))) स0=स,एकः0=एकः]
वि π वि^पिविπ तथा Q π Q^piप्रπ तयोः सम्बन्धः अस्ति : १.
V π ( s ) = E a ∼ π [ Q π ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) V^pi(s)=अंडरसेट{asimpi}{rm E}[Q^pi( स, क)]+अल्फा ह(पि(·|स)) २.विπ(स)=एकः∼πई[प्रπ(स,एकः)]+αह(π(⋅∣स))
विषये Q π Q^piप्रπ बेल्मैन् सूत्रम् अस्ति : १.
Q π ( s , a ) = E s ′ ∼ P a ′ ∼ π [ R ( s , a , s ′ ) + γ ( Q π ( s ′ , a ′ ) + α H ( π ( ⋅ ∣ s ′ ) ] । ) ) ] = E s ′ ∼ P [ R ( s , a , s ′ ) + γ V π ( s ′ ) ] । प्रπ(स,एकः)=एकः′∼πस′∼पुई[आर(स,एकः,स′)+γ(प्रπ(स′,एकः′)+αह(π(⋅∣स′)))]=स′∼पुई[आर(स,एकः,स′)+γविπ(स′)]
SAC एकत्रैव नीतिं शिक्षते π θ π_थेताπθ द्वे च QQप्र नियोग Q φ 1 , Q φ 2 Q_{phi_1}, Q_{phi_2} .प्रϕ1,प्रϕ2。
सम्प्रति मानक SAC इत्यस्य द्वौ रूपौ स्तः : एकः नियतस्य उपयोगं करोतिएन्ट्रोपी नियमितीकरण गुणांक α अल्फाα, प्रशिक्षणकाले परिवर्तनेन अन्यः α अल्फाα एन्ट्रोपी-प्रतिबन्धान् प्रवर्तयितुं ।
OpenAI इत्यस्य दस्तावेजीकरणं नियत-एन्ट्रोपी-नियमितीकरण-गुणकं युक्तं संस्करणं उपयुज्यते, परन्तु व्यवहारे प्रायः तत् प्राधान्यं भवतिएन्ट्रोपी बाध्यताvariant.
यथा अधः दर्शितं, इ α अल्फाα नियतसंस्करणे अन्तिमचित्रं विहाय यस्य स्पष्टलाभाः सन्ति, अन्येषां केवलं किञ्चित् लाभाः सन्ति, मूलतः यथा... α अल्फाα शिक्षणसंस्करणं तथैव तिष्ठति यदा अपि अस्ति α अल्फाα मध्यद्वयं चित्रं यत्र शिक्षणसंस्करणस्य लाभाः सन्ति तत्र अधिकं स्पष्टौ स्तः।
SACवि.संTD3:
~
स एव बिन्दुः : १.
1. एकस्मिन् साझा उद्देश्यं प्रति प्रतिगमनेन MSBE (Mean Squared Bellman Error) इत्यस्य न्यूनीकरणेन Q कार्यद्वयं ज्ञातं भवति।
2. साझालक्ष्यस्य गणनाय लक्ष्य Q-जालस्य उपयोगं कुर्वन्तु, लक्ष्य Q-जालं प्राप्तुं प्रशिक्षणप्रक्रियायाः समये Q-जालमापदण्डेषु polyak औसतीकरणं कुर्वन्तु।
3. साझा लक्ष्यं truncated double Q तकनीकस्य उपयोगं करोति ।
~
अंतरण:
1. SAC इत्यस्मिन् एन्ट्रोपी नियमितीकरणपदं भवति
2. SAC लक्ष्ये प्रयुक्ता अग्रिमा राज्यक्रिया तः आगच्छतिवर्तमान रणनीति, लक्ष्यरणनीत्याः अपेक्षया।
3. सुस्पष्टीकरणस्य स्पष्टं लक्ष्यरणनीतिः नास्ति। TD3 अग्रिमराज्यं प्रति कार्याणां माध्यमेन नियतात्मकनीतिं प्रशिक्षयतियादृच्छिकं कोलाहलं योजयन्तु स्निग्धतां प्राप्तुं । SAC यादृच्छिकनीतिं प्रशिक्षयति, यादृच्छिकतायाः कोलाहलः च समानप्रभावं प्राप्तुं पर्याप्तः भवति ।

एल्गोरिदम : मृदु अभिनेता-समीक्षक एसएसी
प्रवेश: θ 1 , θ 2 , φ थेटा_1,थीटा_2,फी~~~~~θ1,θ2,ϕ आरंभीकरण मापदण्ड
पैरामीटर् आरंभीकरणम् : १.
~~~~~~ लक्ष्यजालभारस्य आरम्भं कुर्वन्तु : १. θ ˉ 1 ← θ 1 , θ ˉ 2 ← θ 2 बार थेटा_1लेफ्टररोथेटा_1, बार थेटा_2लेफ्टररोथेटा_2θˉ1←θ1,θˉ2←θ2
~~~~~~ प्लेबैक् पूलः रिक्तः भवितुं आरभते: D ← ∅ {cal D}लेफटारोरिक्तसमूहघ←∅
{bf for} कृते ।कृते प्रत्येकं पुनरावृत्तिः करो {bf करो}करोतु :
~~~~~~ {bf for} कृते ।कृते प्रत्येकं पर्यावरणपदं करो {bf करो}करोतु :
~~~~~~~~~~~ नीतेः नमूनानि क्रियाः : १. at ∼ π φ ( at ∣ st ) a_tsimpi_phi(a_t|s_t)~~~~~एकःत∼πϕ(एकःत∣सत) ▢अत्र π φ ( at ∣ st ) pi_phi(a_t|s_t) २.πϕ(एकःत∣सत) कथं परिभाषितव्यम् ?
~~~~~~~~~~~ पर्यावरणात् नमूनासंक्रमणानि : १. स्त + 1 ∼ प ( स्त + 1 ∣ स्त , अत ) स_{त+1}सिं प(स_{त+1}|स_त,क_त)सत+1∼पृ(सत+1∣सत,एकःत)
~~~~~~~~~~~ संक्रमणं प्लेबैक् पूल् मध्ये रक्षन्तु: D ← D ∪ { ( st , at , r ( st , at ) , st + 1 ) } {cal D}leftarrow{cal D}~cup~{(s_t,a_t,r(s_t,a_t),s_{t +१})} २.घ←घ ∪ {(सत,एकःत,र(सत,एकःत),सत+1)}
~~~~~~ अन्तः {bf अन्तः ~ कृते} कृते ।अंत कृते
~~~~~~ {bf for} कृते ।कृते प्रत्येकं ढालपदं करो {bf करो}करोतु :
~~~~~~~~~~~ नवीकरणम् QQप्र फ़ंक्शन पैरामीटर्स: for इ ∈ { १ , २ } इन्{१,२}अहम्∈{1,2}, θ i ← θ i − λ Q ∇ ^ θ i JQ ( θ i ) थेटा_इलेफ्तरोथेटा_इ-लम्बदा_Qhat नबला_{थेटा_i}J_Q(थेटा_i)~~~~~θअहम्←θअहम्−λप्र∇^θअहम्जेप्र(θअहम्) ▢अत्र JQ ( θ i ) J_Q(थीटा_i) .जेप्र(θअहम्) कथं परिभाषितव्यम् ?
~~~~~~~~~~~ रणनीतिभारं अद्यतनं कुर्वन्तु : १. φ ← φ − λ π ∇ ^ φ J π ( φ ) फिलेफ्तरोफी-लम्ब्दा_पिहत नबला_फी J_पि (फी)~~~~~ϕ←ϕ−λπ∇^ϕजेπ(ϕ) ▢अत्र ज π ( φ ) ज_पि (फी) .जेπ(ϕ) कथं परिभाषितव्यम् ?
~~~~~~~~~~~ तापमानं समायोजयन्तु : १. α ← α − λ ∇ ^ α J ( α ) अल्फालेफ्तारोवल्फा-लम्ब्दहत्नाब्ला_अल्फा जे (अल्फा)~~~~~α←α−λ∇^αजे(α) ▢अत्र ज ( α ) ज(अल्फा) .जे(α) कथं परिभाषितव्यम् ?अत्र तापमानं कथं अवगन्तुं शक्यते ?
~~~~~~~~~~~ लक्ष्यजालभारं अद्यतनं कुर्वन्तु: कृते इ ∈ { १ , २ } इन्{१,२}अहम्∈{1,2}, θ ˉ i ← τ θ i − ( 1 − τ ) θ ˉ इ बार थेटा_इलेफ्तरो तौ थेटा_इ-(1-तौ)बार थेटा_इ~~~~~θˉअहम्←τθअहम्−(1−τ)θˉअहम् ▢ एतत् कथं अवगन्तुम् τ तौτ ? ——>लक्ष्य स्मूथिंग गुणांक
~~~~~~ अन्तः {bf अन्तः ~ कृते} कृते ।अंत कृते
अन्तः {bf अन्तः ~ कृते} कृते ।अंत कृते
उत्पादनम् : १. θ 1 , θ 1 , φ थेटा_1,थेटा_1,फी~~~~~θ1,θ1,ϕ अनुकूलित मापदण्ड
∇ ^ हत् नबला∇^: आकस्मिक ढाल
$emptyset$ ∅ ~~~~रिक्तसेट् ∅


गहनसुदृढीकरणशिक्षणद्वारा चलितुं शिक्षणम् संस्करणम् अस्ति : १.
~
α
α
α तापमानमापदण्डः अस्ति, यः एन्ट्रोपीपदस्य पुरस्कारस्य च सापेक्षिकं महत्त्वं निर्धारयति, तस्मात् इष्टतमरणनीतेः यादृच्छिकतां नियन्त्रयति
α अल्फाα बृहत् : अन्वेषणं कुर्वन्तु
α अल्फाα लघुः शोषणम्
J ( α ) = E at ∼ π t [ − α log π t ( at ∣ st ) − α H ˉ ] J(alpha)=अंडरसेट{a_tsimpi_t}{mathbb E}[-अल्फालॉग pi_t(a_t|s_t)- अल्फाबर{cal H}] इति ।जे(α)=एकःत∼πतई[−αलोछπत(एकःत∣सत)−αहˉ]

सः ३० वर्षाणाम् अधिकं कालात् प्रौद्योगिक्याः शोधकार्यं कर्तुं समर्पितः अस्ति, तथा च जावा, लिनक्स, जावास्क्रिप्ट्, php, css इत्यादिषु विविधभाषासु प्रवीणः अस्ति, मुक्तस्रोतक्षेत्रे सः बहु योगदानं कृतवान् अस्ति विकासक दस्तावेजीकरणस्थानकं भविष्ये सन्दर्भार्थं प्रौद्योगिकीविकासे केचन विषयाः साझां कर्तुं सर्वे तत् पश्यन्तु







