2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
- easy-rl PDF version notes organization P5, P10 - P12
- joyrl Compare and supplement P11 - P13
- OpenAI document compilation ⭐ https://spinningup.openai.com/en/latest/index.html


Download the latest version PDF
Address: https://github.com/datawhalechina/easy-rl/releases
Domestic address (recommended for domestic readers):
Link: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw Extraction code: us6a
easy-rl online version link (for copying code)
Reference link 2: https://datawhalechina.github.io/joyrl-book/
other:
【Correction record link】
——————
5. Basics of Deep Reinforcement Learning⭐️
Open source content: https://linklearner.com/learn/summary/11
——————————
Same-policy: The agent to learn and the agent that interacts with the environment are the same.
Off-policy: The agent to learn and the agent interacting with the environment are different
Policy Gradient: It takes a lot of time to sample data
Same strategy ⟹ Importance sampling ~~~overset{Importance sampling}{Longrightarrow}~~~ ⟹Importance Sampling Different strategies
PPO: Avoid two distributions that differ too much. Same strategy algorithm
1. Original optimization items
J
(
θ
,
θ
′
)
J(theta,theta^prime)
J(θ,θ′)
2. Constraints:
θ
theta
θ and
θ
′
theta^prime
θ′ The KL divergence of the output action (
θ
theta
θ and
θ
′
theta^prime
θ′ The more similar the better)
PPO has a predecessor: trust region policy optimization (TRPO)
TRPO is difficult to handle because it treats the KL divergence constraint as an additional constraint and does not put it in the objective function, so it is difficult to calculate. Therefore, we generally use PPO instead of TRPO. The performance of PPO and TRPO is similar, but PPO is much easier to implement than TRPO.
KL divergence: the distance of the actions.The probability distribution of performing an action distance.
There are two main variants of the PPO algorithm: Proximal Policy Optimization Penalty (PPO-penalty) and Proximal Policy Optimization Clipping (PPO-clip).
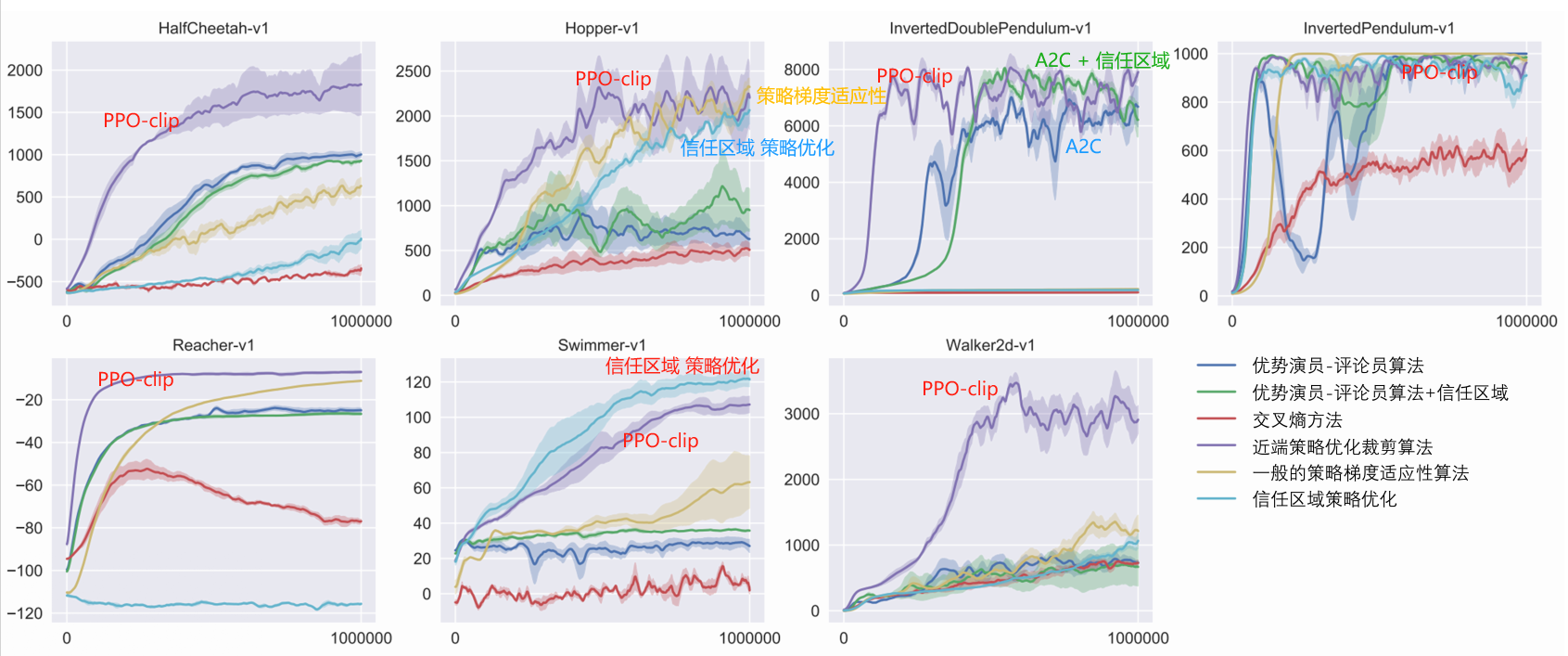
——————————
P10 Sparse Reward Problem
1. Design rewards. Domain knowledge required
How about distributing the final reward to each relevant action?
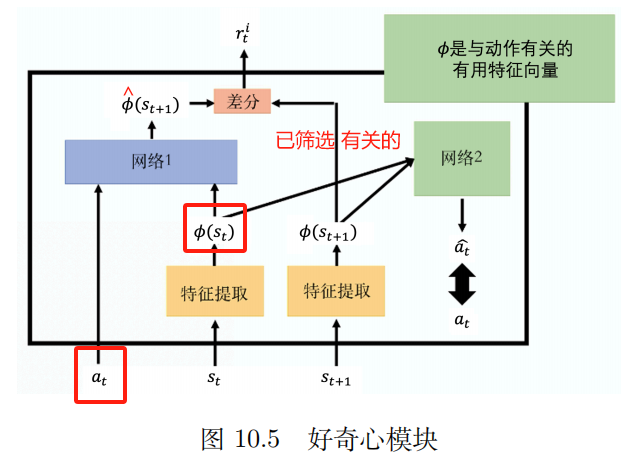
2. Curiosity
Intrinsic curiosity module (ICM)
enter:
a
t
,
s
t
a_t,s_t
at,st
Output:
s
^
t
+
1
hat s_{t+1}
s^t+1
The network's predicted value
s
^
t
+
1
hat s_{t+1}
s^t+1 With the true value
s
t
+
1
s_{t+1}
st+1 The more dissimilar,
r
t
i
r_t^i
rti The bigger
r t i r_t^i rti : The more difficult it is to predict the future state, the greater the reward for the action. Encourage risk-taking and exploration.
Feature extractor
Network 2:
Input: Vector
ϕ
(
s
t
)
{bm phi}(s_{t})
ϕ(st) and
ϕ
(
s
t
+
1
)
{bm phi}(s_{t+1})
ϕ(st+1)
Predicting Actions a ^ hat a a^ The closer to the real action the better.
3. Course study
Easy -> Difficult
Reverse curriculum learning:
Starting from the final most ideal state (which we call the gold state), go toFind the state closest to the golden stateAs the "ideal" state that we want the intelligent agent to reach at certain stages. Of course, we will intentionally remove some extreme states in the process, that is, states that are too simple or too difficult.
4. Hierarchical reinforcement learning (HRL)
The agent's strategies are divided into high-level strategies and low-level strategies. The high-level strategy determines how to execute the low-level strategy based on the current state.
————————
P11 Imitation Learning
Unclear about the reward scenario
Imitation learning (IL)
Learning from demonstration
Apprenticeship learning
Learning by watching
There are clear rewards: board games, video games
No clear reward: Chatbots
Collect expert demonstrations: recordings of human driving, human conversations
Conversely, what kind of reward function makes the experts take these actions?
Inverse reinforcement learning isFirst find the reward function, after finding the reward function, we use reinforcement learning to find the optimal actor.
Third person imitation learning technology
————————
P12 Deep deterministic policy gradient (DDPG)
Used experience replay strategy
Ablation experiment [Control variable method] analysisEach constraintThe impact on the outcome of the battle.
joyrl:
In needDeterminismStrategy andContinuous ActionUnder the premise of space, this type of algorithm will be a relatively stable baseline algorithm
DQN in Continuous Action Space
Deep deterministic policy gradient (DDPG)
The experience replay mechanism can reduce the correlation between samples, improve the effective utilization of samples, and increase the stability of training.
shortcoming:
1. Cannot be used in discrete action spaces
2、Highly dependent on hyperparameters
3. Highly sensitive initial conditions. Affects the convergence and performance of the algorithm
4. It is easy to fall into local optimum.
The advantage of soft update is that it is smoother and slower, which can avoid shocks caused by too rapid weight updates and reduce the risk of training divergence.
Double-delayed deterministic policy gradient algorithm
Three improvements: dual Q network, delayed update, noise regularization
Double Q Network: Two Q networks, choose the one with smaller Q value. This can solve the problem of overestimation of Q value and improve the stability and convergence of the algorithm.
Delayed updates: make the actor update frequency lower than the critic update frequency
Noise is more like aRegularizationway, so thatValue function updatemoresmooth
OpenAI Gym Library_Pendulum_TD3
OpenAI's documentation interface link for TD3
The most commonly used PPO algorithm in reinforcement learning
Discrete + Continuous
Fast and stable, easy to adjust parameters
Baseline Algorithm
PPO
In practice, the clip constraint is generally used because it is simpler, less computationally expensive, and produces better results.
The off-policy algorithm canTo use historical experience, generally use experience replay to store and reuse previous experience,High data utilization efficiency。
PPO is an on-policy algorithm
——————————————————
OpenAI Documentation
Paper arXiv interface link: Proximal Policy Optimization Algorithms
PPO: on-policy algorithm, applicable to discrete or continuous action space. Possible local optimum
The motivation for PPO is the same as TRPO: how to use existing dataTake the biggest possible step in strategy improvement, without changing it too much and accidentally causing performance problems?
TRPO tries to solve this problem with a complicated second-order method, while PPO is a first-order method that uses some other tricks to keep the new policy close to the old one.
The PPO method is much simpler to implement and has been empirically shown to perform at least as well as TRPO.
There are two main variations of PPO: PPO-Penalty and PPO-Clip.


Algorithm: PPO-Clip
1: Input: Initial strategy parameters θ 0 theta_0 θ0, initial value function parameters ϕ 0 phi_0 ϕ0
2: f o r k = 0 , 1 , 2 , … d o {bf for} ~ k=0,1,2,dots~ {bf do} for k=0,1,2,… do:
3: ~~~~~~ By running the policy in the environment π k = π ( θ k ) pi_k=pi(theta_k) πk=π(θk) Collecting Trajectory Sets D k = { τ i } {cal D}_k={tau_i} Dk={τi}
4: ~~~~~~ Calculating rewards (rewards-to-go) R ^ t hat R_t~~~~~ R^t ▢ R ^ t hat R_t R^t Calculation rules
5: ~~~~~~ Compute advantage estimate, based on current value function V ϕ k V_{phi_k} Vϕk of A ^ t hat A_t A^t (Use any dominance estimation method) ~~~~~ ▢ What are the current methods for edge estimation?
6: ~~~~~~ Update the policy by maximizing the PPO-Clip objective function:
~~~~~~~~~~~
θ k + 1 = arg max θ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T min ( π θ ( a t ∣ s t ) π θ k ( a t ∣ s t ) A π θ k ( s t , a t ) , g ( ϵ , A π θ k ( s t , a t ) ) ) ~~~~~~~~~~~theta_{k+1}=argmaxlimits_thetafrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TminBig(frac{pi_{theta} (a_t|s_t)}{pi_{theta_k}(a_t|s_t)}A^{pi_{theta_k}}(s_t,a_t),g(epsilon,A^{pi_{theta_k}}(s_t,a_t))Big) θk+1=argθmax∣Dk∣T1τ∈Dk∑t=0∑Tmin(πθk(at∣st)πθ(at∣st)Aπθk(st,at),g(ϵ,Aπθk(st,at))) ~~~~~ ▢ How to determine the policy update formula?
~~~~~~~~~~~
~~~~~~~~~~~ π θ k pi_{theta_k} πθk: Policy parameter vector before update. Importance sampling. Sampling from the old policy.
~~~~~~~~~~~
~~~~~~~~~~~ General Stochastic Gradient Ascent + Adam
7: ~~~~~~ Mean square errorRegression fit value function:
~~~~~~~~~~~
ϕ k + 1 = arg min ϕ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T ( V ϕ ( s t ) − R ^ t ) 2 ~~~~~~~~~~~phi_{k+1}=arg minlimits_phifrac{1}{|{cal D}_k|T}sumlimits_{tauin{cal D}_k}sumlimits_{t=0}^TBig(V_phi(s_t)-hat R_tBig)^2 ϕk+1=argϕmin∣Dk∣T1τ∈Dk∑t=0∑T(Vϕ(st)−R^t)2
~~~~~~~~~~~
~~~~~~~~~~~ General Gradient Descent
8: e n d f o r bf end ~for end for
~~~~~~~~~~~~
$dots$
…
~~~dots
…
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) A A < 0 g(epsilon,A)=left{(1+ϵ)A A≥0(1−ϵ)AA<0right. g(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0

In the paperAdvantage Estimate:
A ^ t = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) ⏟ R ^ t ? ? ? hat A_t=-V(s_t)+underbrace{r_t+gamma r_{t+1}+cdots+gamma^{T-t+1}r_{T-1}+gamma^{T-t}V(s_T)}_{textcolor{blue}{hat R_t???}} A^t=−V(st)+R^t??? rt+γrt+1+⋯+γT−t+1rT−1+γT−tV(sT)

make
Δ
t
=
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
Delta_t =r_t+gamma V(s_{t+1})-V(s_t)
Δt=rt+γV(st+1)−V(st)
but
r
t
=
Δ
t
−
γ
V
(
s
t
+
1
)
+
V
(
s
t
)
r_t=Delta_t - gamma V(s_{t+1})+V(s_t)
rt=Δt−γV(st+1)+V(st)
Substitution A ^ t hat A_t A^t expression
A ^ t = − V ( s t ) + r t + γ r t + 1 + γ 2 r t + 2 + ⋯ + γ T − t r T − 2 + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( s t ) + Δ t − γ V ( s t + 1 ) + V ( s t ) + γ ( Δ t + 1 − γ V ( s t + 2 ) + V ( s t + 1 ) ) + γ 2 ( Δ t + 2 − γ V ( s t + 3 ) + V ( s t + 1 ) ) + ⋯ + γ T − t ( Δ T − t − γ V ( s T − t + 1 ) + V ( s T − t ) ) + γ T − t + 1 ( Δ T − 1 − γ V ( s T ) + V ( s T − 1 ) ) + γ T − t V ( s T ) = Δ t + γ Δ t + 1 + γ 2 Δ t + 2 + ⋯ + γ T − t Δ T − t + γ T − t + 1 Δ T − 1 ˆAt=−V(st)+rt+γrt+1+γ2rt+2+⋯+γT−trT−2+γT−t+1rT−1+γT−tV(sT)=−V(st)+rt+γrt+1+⋯+γT−t+1rT−1+γT−tV(sT)=−V(st)+ Δt−γV(st+1)+V(st)+ γ(Δt+1−γV(st+2)+V(st+1))+ γ2(Δt+2−γV(st+3)+V(st+1))+ ⋯+ γT−t(ΔT−t−γV(sT−t+1)+V(sT−t))+ γT−t+1(ΔT−1−γV(sT)+V(sT−1))+ γT−tV(sT)=Δt+γΔt+1+γ2Δt+2+⋯+γT−tΔT−t+γT−t+1ΔT−1 A^t=−V(st)+rt+γrt+1+γ2rt+2+⋯+γT−trT−2+γT−t+1rT−1+γT−tV(sT)=−V(st)+rt+γrt+1+⋯+γT−t+1rT−1+γT−tV(sT)=−V(st)+ Δt−γV(st+1)+V(st)+ γ(Δt+1−γV(st+2)+V(st+1))+ γ2(Δt+2−γV(st+3)+V(st+1))+ ⋯+ γT−t(ΔT−t−γV(sT−t+1)+V(sT−t))+ γT−t+1(ΔT−1−γV(sT)+V(sT−1))+ γT−tV(sT)=Δt+γΔt+1+γ2Δt+2+⋯+γT−tΔT−t+γT−t+1ΔT−1

Clipping acts as a regularizer by removing the incentive to make drastic policy changes.Hyperparameters ϵ epsilon ϵ Corresponding to the distance between the new strategy and the old strategy。
This kind of clipping may still end up with a new strategy that is far from the old one. In the implementation here, we use a particularly simple method:Early StoppingIf the average KL-divergence between the new policy and the old policy exceeds a threshold, we stop executing the gradient step.
Simple derivation of PPO objective function link
The objective function of PPO-Clip is:
~
L θ k C L I P ( θ ) = E s , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , c l i p ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ k ( s , a ) ) ] L^{rm CLIP}_{theta_k}(theta)=underset{s, asimtheta_k}{rm E}Bigg[minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}A^{theta_k}(s, a), {rm clip}Big(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)},1-epsilon, 1+epsilonBig)A^{theta_k}(s, a)Bigg)Bigg] LθkCLIP(θ)=s,a∼θkE[min(πθk(a∣s)πθ(a∣s)Aθk(s,a),clip(πθk(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aθk(s,a))]
~
$underset{s, asimtheta_k}{rm E}$E s , a ∼ θ k ~~~underset{s, asimtheta_k}{rm E} s,a∼θkE
~
No. k k k The strategy parameters for the iteration θ k theta_k θk, ϵ epsilon ϵ is a small hyperparameter.
set up ϵ ∈ ( 0 , 1 ) epsilonin(0,1) ϵ∈(0,1), Definition
F ( r , A , ϵ ) ≐ min ( r A , c l i p ( r , 1 − ϵ , 1 + ϵ ) A ) F(r,A,epsilon)doteqminBigg(rA,{rm clip}(r,1-epsilon,1+epsilon)ABigg) F(r,A,ϵ)≐min(rA,clip(r,1−ϵ,1+ϵ)A)
when A ≥ 0 Ageq0 A≥0
F ( r , A , ϵ ) = min ( r A , clip ( r , 1 − ϵ , 1 + ϵ ) A ) = A min ( r , clip ( r , 1 − ϵ , 1 + ϵ ) ) = A min ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { min ( r , 1 + ϵ ) r ≥ 1 + ϵ min ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) min ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) rr ≤ 1 − ϵ } From the range on the right = A min ( r , 1 + ϵ ) = min ( r A , ( 1 + ϵ ) A )begin{aligned}F(r,A,epsilon)&=minBigg(rA,{rm clip}(r,1-epsilon,1+epsilon)ABigg)\ &=AminBigg(r,{rm clip}(r,1-epsilon,1+epsilon)Bigg)\ &=AminBigg(r,left{begin{aligned}&1+epsilon~~&rgeq1+epsilon\ &r &rin(1-epsilon,1+epsilon)\ &1-epsilon &rleq1-epsilon\ end{aligned}right}Bigg)\ &=Aleft{minright}\ &=Aleft{right}~~~~~textcolor{blue}{According to the range on the right}\ &=Amin(r, 1+epsilon)\ &=minBigg(rA, (1+epsilon)ABigg) end{aligned} F(r,A,ϵ)=min(rA,clip(r,1−ϵ,1+ϵ)A)=Amin(r,clip(r,1−ϵ,1+ϵ))=Amin(r,⎩ ⎨ ⎧1+ϵ r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧min(r,1+ϵ) min(r,r)min(r,1−ϵ)r≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧1+ϵ rrr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫ According to the range on the right=Amin(r,1+ϵ)=min(rA,(1+ϵ)A)
~
when A < 0 A<0 A<0
F ( r , A , ϵ ) = min ( r A , clip ( r , 1 − ϵ , 1 + ϵ ) A ) = A max ( r , clip ( r , 1 − ϵ , 1 + ϵ ) ) = A max ( r , { 1 + ϵ r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { max ( r , 1 + ϵ ) r ≥ 1 + ϵ max ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) max ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { r r ≥ 1 + ϵ rr ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } From the range on the right = A max ( r , 1 − ϵ ) = min ( r A , ( 1 − ϵ ) A )right}Bigg)\ &=Aleft{right}\ &=Aleft{right}~~~~~textcolor{blue}{According to the range on the right}\ &=Amax(r, 1-epsilon)\ &=textcolor{blue}{min}Bigg(rA,(1-epsilon)ABigg) end{aligned} F(r,A,ϵ)=min(rA,clip(r,1−ϵ,1+ϵ)A)=Amax(r,clip(r,1−ϵ,1+ϵ))=Amax(r,⎩ ⎨ ⎧1+ϵ r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧max(r,1+ϵ) max(r,r)max(r,1−ϵ)r≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧r r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫ According to the range on the right=Amax(r,1−ϵ)=min(rA,(1−ϵ)A)
~
In summary: it can be defined g ( ϵ , A ) g(epsilon,A) g(ϵ,A)
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) A A < 0 g(epsilon,A)=left{right. g(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0
Why does this definition ensure that the new strategy does not stray too far from the old one?
Importance sampling methods effectively require new strategies
π
θ
(
a
∣
s
)
pi_theta(a|s)
πθ(a∣s) and the old strategy
π
θ
k
(
a
∣
s
)
pi_{theta_k}(a|s)
πθk(a∣s) The two distributions cannot be too far apart
1. When advantage is positive
L
(
s
,
a
,
θ
k
,
θ
)
=
min
(
π
θ
(
a
∣
s
)
π
θ
k
(
a
∣
s
)
,
1
+
ϵ
)
A
π
θ
k
(
s
,
a
)
L(s,a,theta_k, theta)=minBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1+epsilonBigg)A^{pi_{theta_k}}(s, a)
L(s,a,θk,θ)=min(πθk(a∣s)πθ(a∣s),1+ϵ)Aπθk(s,a)
Advantage function: If a state-action pair is found to have a high reward, increase the weight of the state-action pair.
When the state-action pair
(
s
,
a
)
(s, a)
(s,a) The advantage of is positive, then if the action
a
a
a is more likely to be executed if
π
θ
(
a
∣
s
)
pi_theta(a|s)
πθ(a∣s) Increase, and the goal will increase.
The min in this item limits the objective function to only increase to a certain value
once
π
θ
(
a
∣
s
)
>
(
1
+
ϵ
)
π
θ
k
(
a
∣
s
)
pi_theta(a|s)>(1+epsilon)pi_{theta_k}(a|s)
πθ(a∣s)>(1+ϵ)πθk(a∣s), min trigger, limit the value of this item
(
1
+
ϵ
)
π
θ
k
(
a
∣
s
)
(1+epsilon)pi_{theta_k}(a|s)
(1+ϵ)πθk(a∣s)。
the new policy does not benefit by going far away from the old policy.
New strategies do not benefit from moving away from old strategies.
2. When the advantage is negative
L ( s , a , θ k , θ ) = max ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ ) A π θ k ( s , a ) L(s,a,theta_k, theta)=maxBigg(frac{pi_theta(a|s)}{pi_{theta_k}(a|s)}, 1-epsilonBigg)A^{pi_{theta_k}}(s, a) L(s,a,θk,θ)=max(πθk(a∣s)πθ(a∣s),1−ϵ)Aπθk(s,a)
When a state-action pair
(
s
,
a
)
(s, a)
(s,a) The advantage of is negative, then if the action is executed
a
a
a is less likely, that is, if
π
θ
(
a
∣
s
)
π_theta(a|s)
πθ(a∣s) If decreases, the objective function will increase. However, the max in this term limits how much the objective function can increase.
once
π
θ
(
a
∣
s
)
<
(
1
−
ϵ
)
π
θ
k
(
a
∣
s
)
pi_theta(a|s)<(1-epsilon)pi_{theta_k}(a|s)
πθ(a∣s)<(1−ϵ)πθk(a∣s), max trigger, limit the value of this item to
(
1
−
ϵ
)
π
θ
k
(
a
∣
s
)
(1-epsilon)pi_{theta_k}(a|s)
(1−ϵ)πθk(a∣s)。
To reiterate: the new policy does not benefit by going far away from the old policy.
New strategies do not benefit from moving away from old strategies.
While DDPG can sometimes achieve excellent performance, it is often unstable when it comes to hyperparameters and other types of tuning.
A common DDPG failure mode is that the learned Q-function starts to significantly overestimate the Q-values, which then causes the policy to break because it exploits the error in the Q-function.
Twin Delayed DDPG (TD3) is an algorithm that solves this problem by introducing three key tricks:
1、Truncated Double Q Learning。
2、Policy update delay。
3. Target strategy smoothing.
TD3 is an off-policy algorithm; it can only be used withcontinuousThe environment of the action space.

Algorithm: TD3
With random parameters θ 1 , θ 2 , ϕ theta_1, theta_2, phi θ1,θ2,ϕ Initialize the critic network Q θ 1 , Q θ 2 Q_{theta_1},Q_{theta_2} Qθ1,Qθ2, and actor networks π ϕ pi_phi πϕ
Initialize the target network θ 1 ′ ← θ 1 , θ 2 ′ ← θ 2 , ϕ ′ ← ϕ theta_1^primeleftarrowtheta_1, theta_2^primeleftarrowtheta_2, phi^primeleftarrow phi θ1′←θ1,θ2′←θ2,ϕ′←ϕ
Initialize the playback buffer set B cal B B
f o r t = 1 t o T {bf for}~t=1 ~{bf to} ~T for t=1 to T :
~~~~~~ Selecting actions with exploration noise a ∼ π ϕ ( s ) + ϵ , ϵ ∼ N ( 0 , σ ) asimpi_phi(s)+epsilon,~~epsilonsim {cal N}(0,sigma) a∼πϕ(s)+ϵ, ϵ∼N(0,σ), Observation Reward r r r and the new state s ′ s^prime s′
~~~~~~ The transition tuple ( s , a , r , s ′ ) (s, a,r, s^prime) (s,a,r,s′) Save to B cal B B middle
~~~~~~ from B cal B B Sampling small batches N N N transitions ( s , a , r , s ′ ) (s, a, r, s^prime) (s,a,r,s′)
a ~ ← π ϕ ′ ( s ′ ) + ϵ , ϵ ∼ c l i p ( N ( 0 , σ ~ ) , − c , c ) ~~~~~~widetilde aleftarrow pi_{phi^prime}(s^prime)+epsilon,~~epsilonsim{rm clip}({cal N}(0,widetilde sigma),-c,c) a ←πϕ′(s′)+ϵ, ϵ∼clip(N(0,σ ),−c,c)
y ← r + γ min i = 1 , 2 Q θ i ′ ( s ′ , a ~ ) ~~~~~~yleftarrow r+gamma minlimits_{i=1,2}Q_{theta_i^prime}(s^prime,widetilde a) y←r+γi=1,2minQθi′(s′,a )
~~~~~~ Update critics θ i ← arg min θ i N − 1 ∑ ( y − Q θ i ( s , a ) ) 2 theta_ileftarrowargminlimits_{theta_i}N^{-1}sum(y-Q_{theta_i}(s, a))^2 θi←argθiminN−1∑(y−Qθi(s,a))2
~~~~~~ i f t % d {bf if}~t~ % ~d if t % d:
~~~~~~~~~~~ Updated via deterministic policy gradient ϕ phi ϕ
∇ ϕ J ( ϕ ) = N − 1 ∑ ∇ a Q θ 1 ( s , a ) ∣ a = π ϕ ( s ) ∇ ϕ π ϕ ( s ) ~~~~~~~~~~~~~~~~~nabla _phi J(phi)=N^{-1}sumnabla_aQ_{theta_1}(s, a)|_{a=pi_phi(s)}nabla_phipi_phi(s) ∇ϕJ(ϕ)=N−1∑∇aQθ1(s,a)∣a=πϕ(s)∇ϕπϕ(s)
~~~~~~~~~~~ Update the target network:
θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ ~~~~~~~~~~~~~~~~~theta_i^primeleftarrowtautheta_i+(1-tau)theta_i^prime~~~~~ θi′←τθi+(1−τ)θi′ τ tau τ: Target update rate
ϕ ′ ← τ ϕ + ( 1 − τ ) ϕ ′ ~~~~~~~~~~~~~~~~~phi^primeleftarrowtauphi+(1-tau)phi^prime ϕ′←τϕ+(1−τ)ϕ′
e n d i f ~~~~~~{bf end ~if} end if
e n d f o r {bf end ~for} end for

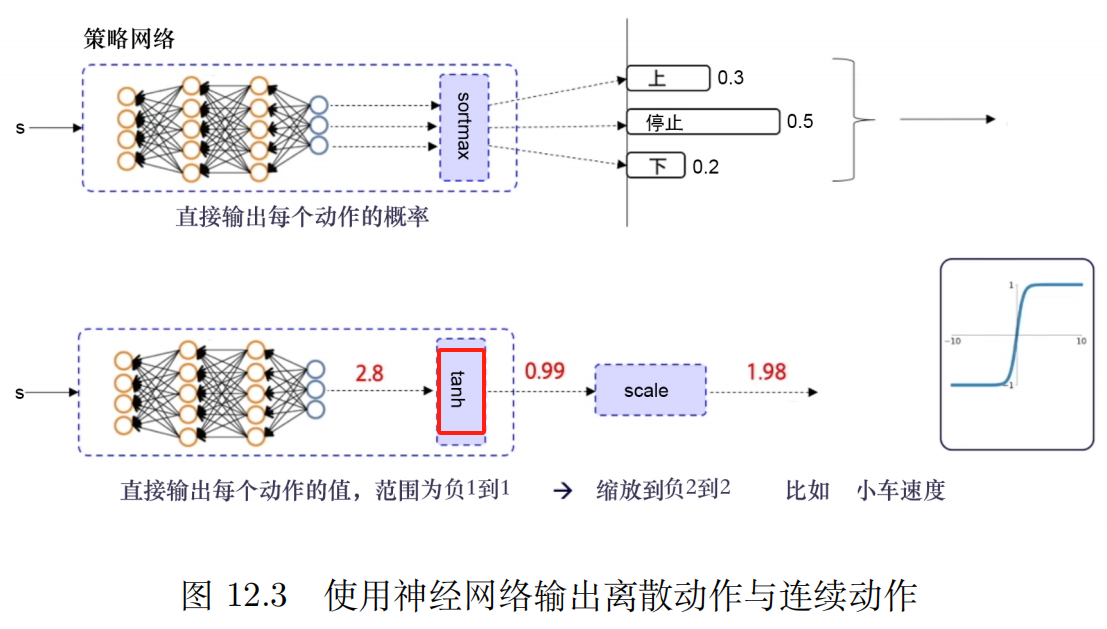
Maximize the entropy of the policy, thus making the policy more robust.
Deterministic Strategy It means that given the same state, the same action is always chosen.
Randomness strategy There are multiple possible actions that can be chosen in a given state.
| Deterministic Strategy | Randomness strategy | |
|---|---|---|
| definition | Same state, same action | The same state,Different actions may be performed |
| advantage | Stable and repeatable | Avoid falling into local optimal solutions and improve global search capabilities |
| shortcoming | Lack of exploration, easy to be caught by opponents | This may result in slower convergence of the strategy, affecting efficiency and performance. |
In practical applications, if conditions permit, we willUse as much as possibleRandomness strategy, such as A2C, PPO, etc., because it is more flexible, more robust and more stable.
Maximum entropy reinforcement learning believes that even though we currently have mature random strategies, such as AC algorithms, we still have not achieved optimal randomness. Therefore, it introduces aInformation EntropyThe concept ofMaximize the cumulative reward while maximizing the entropy of the strategy, making the strategy more robust, thus achieving the optimal stochastic strategy.
——————————————————
OpenAI Documentation_SAC interface link
~
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja et al, 201808 ICML 2018
Soft Actor-Critic Algorithms and Applications, Haarnoja et al, 201901
Learning to Walk via Deep Reinforcement Learning, Haarnoja et al, 201906 RSS2019
Soft Actor Critic (SAC) optimizes random policies in an off-policy manner.
DDPG + Stochastic Strategy Optimization
Not a direct successor to TD3 (published almost simultaneously).
It incorporates the clipped double-Q trick, and due to the inherent randomness of SAC's strategy, it also ultimately benefits fromTarget strategy smoothing。
A core feature of SAC is entropy regularization。
The policy is trained to maximize the trade-off between expected reward and entropy,Entropy is a measure of the randomness of a policy。
This is closely related to the trade-off between exploration and exploitation: an increase in entropy leads toMore to explore,this is OKAccelerate subsequent learningIt can alsoPrevent the strategy from converging to a bad local optimum prematurely。
It can be used in both continuous and discrete action spaces.
exist Entropy-Regularized Reinforcement LearningIn the example, the agent obtains the sameThe entropy of the policy at this time stepProportional rewards.
At this time, the RL problem is described as:
π ∗ = arg max π E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( s t , a t , s t + 1 ) + α H ( π ( ⋅ ∣ s t ) ) ) ] pi^*=argmaxlimits_pi underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})textcolor{blue}{+alpha H(pi(·|s_t))}Big)Big] π∗=argπmaxτ∼πE[t=0∑∞γt(R(st,at,st+1)+αH(π(⋅∣st)))]
in
α
>
0
alpha > 0
α>0 is the trade-off coefficient.
The state-value function includes an entropy bonus at each time step
V
π
V^pi
Vπ for:
V π ( s ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( s t , a t , s t + 1 ) + α H ( π ( ⋅ ∣ s t ) ) ) ∣ s 0 = s ] V^pi(s)=underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})+alpha H(pi(·|s_t))Big)Big|s_0=sBig] Vπ(s)=τ∼πE[t=0∑∞γt(R(st,at,st+1)+αH(π(⋅∣st))) s0=s]
Action-value function including entropy bonus for every time step except the first Q π Q^pi Qπ:
Q π ( s , a ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( s t , a t , s t + 1 ) + α ∑ t = 1 ∞ H ( π ( ⋅ ∣ s t ) ) ) ∣ s 0 = s , a 0 = a ] Q^pi(s,a)=underset{tausimpi}{rm E}Big[sumlimits_{t=0}^inftygamma^tBig(R(s_t,a_t,s_{t+1})+alpha sumlimits_{t=1}^infty H(pi(·|s_t))Big)Big|s_0=s,a_0=aBig] Qπ(s,a)=τ∼πE[t=0∑∞γt(R(st,at,st+1)+αt=1∑∞H(π(⋅∣st))) s0=s,a0=a]
V π V^pi Vπ and Q π Q^pi Qπ The relationship between them is:
V π ( s ) = E a ∼ π [ Q π ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) V^pi(s)=underset{asimpi}{rm E}[Q^pi(s, a)]+alpha H(pi(·|s)) Vπ(s)=a∼πE[Qπ(s,a)]+αH(π(⋅∣s))
about Q π Q^pi Qπ The Bellman formula is:
Q π ( s , a ) = E s ′ ∼ P a ′ ∼ π [ R ( s , a , s ′ ) + γ ( Q π ( s ′ , a ′ ) + α H ( π ( ⋅ ∣ s ′ ) ) ) ] = E s ′ ∼ P [ R ( s , a , s ′ ) + γ V π ( s ′ ) ] Qπ(s,a)=a′∼πs′∼PE[R(s,a,s′)+γ(Qπ(s′,a′)+αH(π(⋅∣s′)))]=s′∼PE[R(s,a,s′)+γVπ(s′)]
SAC learns a policy at the same time
π
θ
π_theta
πθ and two
Q
Q
Q function
Q
ϕ
1
,
Q
ϕ
2
Q_{phi_1}, Q_{phi_2}
Qϕ1,Qϕ2。
There are currently two standard SAC variants: one that uses a fixedEntropy regularization coefficient
α
alpha
α, and another by changing
α
alpha
α to enforce the entropy constraint.
OpenAI's documentation uses a version with a fixed entropy regularization coefficient, but in practice one usually prefersEntropy ConstraintVariant of .
As shown in the figure below, α alpha α In the fixed version, except for the last figure which has a clear advantage, the others are only slightly better, basically the same as α alpha α The learning version is flat; α alpha α The learning version has advantages in the two middle pictures, with more obvious advantages.
SACVSTD3:
~
Same point:
1. Both Q functions are learned by regressing to a single shared objective by minimizing the MSBE (Mean Squared Bellman Error).
2. Use the target Q-network to calculate the shared target, and perform polyak averaging on the Q-network parameters during training to obtain the target Q-network.
3. The shared target uses a truncated double Q technique.
~
difference:
1. SAC contains entropy regularization term
2. The next state action used in SAC’s goal comes fromCurrent Strategy, rather than a target strategy.
3. There is no clear target policy smoothing. TD3 trains a deterministic policy that takes actions to the next state.Add random noiseSAC trains a random policy, and the noise from randomness is enough to achieve similar effects.

Algorithm: Soft Actor-Critic SAC
enter: θ 1 , θ 2 , ϕ theta_1,theta_2,phi~~~~~ θ1,θ2,ϕ Initialization parameters
Parameter initialization:
~~~~~~ Initialize the target network weights: θ ˉ 1 ← θ 1 , θ ˉ 2 ← θ 2 bar theta_1leftarrowtheta_1, bar theta_2leftarrowtheta_2 θˉ1←θ1,θˉ2←θ2
~~~~~~ The playback pool is initialized to be empty: D ← ∅ {cal D}leftarrowemptyset D←∅
f o r {bf for} for Each iteration d o {bf do} do :
~~~~~~ f o r {bf for} for Each environment step d o {bf do} do :
~~~~~~~~~~~ Sample actions from the policy: a t ∼ π ϕ ( a t ∣ s t ) a_tsimpi_phi(a_t|s_t)~~~~~ at∼πϕ(at∣st) ▢ Here π ϕ ( a t ∣ s t ) pi_phi(a_t|s_t) πϕ(at∣st) How to define?
~~~~~~~~~~~ Sample transitions from the environment: s t + 1 ∼ p ( s t + 1 ∣ s t , a t ) s_{t+1}sim p(s_{t+1}|s_t,a_t) st+1∼p(st+1∣st,at)
~~~~~~~~~~~ Save the transition to the replay pool: D ← D ∪ { ( s t , a t , r ( s t , a t ) , s t + 1 ) } {cal D}leftarrow{cal D}~cup~{(s_t,a_t,r(s_t,a_t),s_{t+1})} D←D ∪ {(st,at,r(st,at),st+1)}
~~~~~~ e n d f o r {bf end ~for} end for
~~~~~~ f o r {bf for} for Each gradient step d o {bf do} do :
~~~~~~~~~~~ renew Q Q Q Function parameters: For i ∈ { 1 , 2 } iin{1,2} i∈{1,2}, θ i ← θ i − λ Q ∇ ^ θ i J Q ( θ i ) theta_ileftarrowtheta_i-lambda_Qhat nabla_{theta_i}J_Q(theta_i)~~~~~ θi←θi−λQ∇^θiJQ(θi) ▢ Here J Q ( θ i ) J_Q(theta_i) JQ(θi) How to define?
~~~~~~~~~~~ Update policy weights: ϕ ← ϕ − λ π ∇ ^ ϕ J π ( ϕ ) phileftarrowphi-lambda_pihat nabla_phi J_pi (phi)~~~~~ ϕ←ϕ−λπ∇^ϕJπ(ϕ) ▢ Here J π ( ϕ ) J_pi (phi) Jπ(ϕ) How to define?
~~~~~~~~~~~ Adjust the temperature: α ← α − λ ∇ ^ α J ( α ) alphaleftarrowalpha-lambdahatnabla_alpha J(alpha)~~~~~ α←α−λ∇^αJ(α) ▢ Here J ( α ) J(alpha) J(α) How to define? How to understand the temperature here
~~~~~~~~~~~ Update the target network weights: For i ∈ { 1 , 2 } iin{1,2} i∈{1,2}, θ ˉ i ← τ θ i − ( 1 − τ ) θ ˉ i bar theta_ileftarrow tau theta_i-(1-tau)bar theta_i~~~~~ θˉi←τθi−(1−τ)θˉi ▢ How to understand this τ tau τ? ——> Target smoothing coefficient
~~~~~~ e n d f o r {bf end ~for} end for
e n d f o r {bf end ~for} end for
Output: θ 1 , θ 1 , ϕ theta_1,theta_1,phi~~~~~ θ1,θ1,ϕ Optimized parameters
∇ ^ hat nabla ∇^: Stochastic gradient
$emptyset$
∅
~~~~emptyset
∅


Learning to Walk via Deep Reinforcement Learning Versions in:
~
α
α
α is the temperature parameter, which determines the relative importance of the entropy term and the reward, thereby controlling the stochasticity of the optimal policy.
α
alpha
α Large: Explore
α
alpha
α Small: Utilize
J ( α ) = E a t ∼ π t [ − α log π t ( a t ∣ s t ) − α H ˉ ] J(alpha)=underset{a_tsimpi_t}{mathbb E}[-alphalog pi_t(a_t|s_t)-alphabar{cal H}] J(α)=at∼πtE[−αlogπt(at∣st)−αHˉ]

I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.







