2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Esipuhe: Tämä artikkeli tarjoaa yksityiskohtaisia vastauksia joihinkin epäilyihin pikalajittelualgoritmin varhaisesta oppimisesta ja tarjoaa optimoidun version nopean lajittelun perusalgoritmista.
Pikalajittelualgoritmin ydin on分治思想,Haja ja hallitse -strategia on jaettu kolmeen seuraavaan vaiheeseen:
Sovelletaan nopeaan lajittelualgoritmiin:
Nopean lajittelun avainkoodi on如何根据基准元素划分数组区间(parttion), hajotustapoja on monia, tässä tarjotaan vain yksi menetelmä.挖坑法
Koodi:
class Solution {
public int[] sortArray(int[] nums) {
quick(nums, 0, nums.length - 1);
return nums;
}
private void quick(int[] arr, int start, int end) {
if(start >= end) return;// 递归结束条件
int pivot = parttion(arr, start, end);
// 递归解决子问题
quick(arr, start, pivot - 1);
quick(arr, pivot + 1, end);
}
// 挖坑法进行分解
private int parttion(int[] arr, int left, int right) {
int key = arr[left];
while(left < right) {
while(left < right && arr[right] >= key) right--;
arr[left] = arr[right];
while(left < right && arr[left] <= key) ++left;
arr[right] = arr[left];
}
arr[left] = key;
return left;
}
}
Yksityiskohtaiset vastaukset:
1. Miksistart>=endOnko se rekursion loppuehto?
Jatketaan alitehtävän kokoa 1, eli siinä on vain yksi elementti. Alku- ja loppuosoittimet osoittavat samaan aikaan aika.
2. Miksi oikean pitäisi mennä ensin vasemman sijasta?
Riippuu siitä kumpi menee ensin
基准元素的位置,Yllä olevassa koodissa peruselementti (avain) on vasemmanpuoleisin elementti, jos se siirretään ensinleft, vasen kohtaa ensin peruselementtiä suuremman elementin ja suorittaa sen sittenarr[right] = arr[left], koska ei ole tallennettuarr[right], tämä elementti katoaa
Jos siirryt ensin oikealle, oikea kohtaa ensin peruselementtiä pienemmän elementin ja suorittaa sen sittenarr[left]=arr[right], koska vasen ei ole liikkunut tällä hetkellä, se on edelleen pivot, mutta me olemme tallentaneet pivotin avaimella.
3. Miksi arr[right]>=key?>Eikö se ole mahdollista?
Suurempi tai yhtä suuri kuin on tarkoitettu pääasiassa käsittelyyn
重复元素问题
Esimerkiksi siellä on taulukko[6,6,6,6,6]Jos se on >, oikea osoitin ei liiku, eikä vasen osoitin myöskään, ja se juuttuu äärettömään silmukkaan.
4. Miksi sitä kutsutaan kaivantomenetelmäksi?
Kun r-osoitin kohtaa ensimmäisen
arr[r] = arr[l], tällä hetkellä l-paikka on tyhjä ja muodostaa kuopan.
On olemassa kaksi pääasiallista optimointisuuntaa:
O(N*logN), eli paras aika monimutkaisuus数组分三块Samaan aikaan, jos kohtaat erityisiä testitapauksia (peräkkäinen matriisi tai käänteinen matriisi), aika monimutkaisuus heikkeneeO(N^2)Ensinnäkin kysymyksen perusteella (lajitella värin mukaan) ymmärtää mikä on数组分三块
analysoida
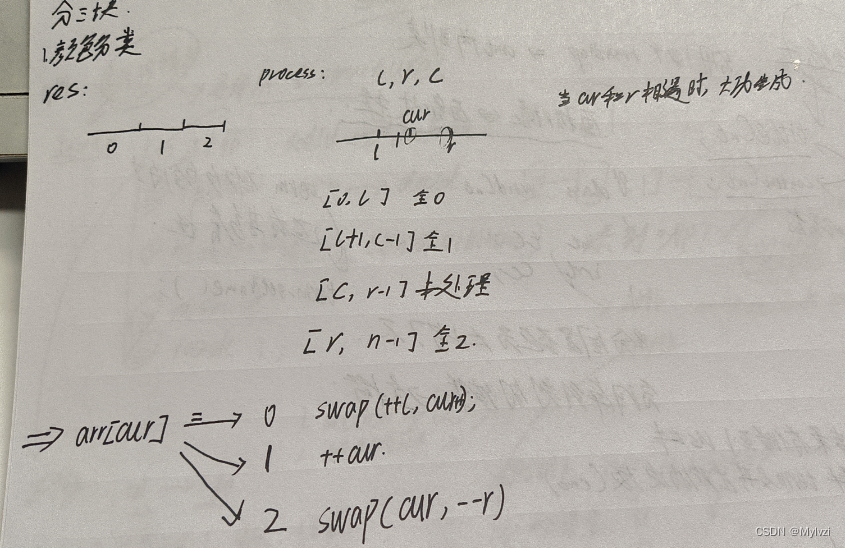
Koodi:
class Solution {
public void sortColors(int[] nums) {
// 分治 --
// 1.定义三指针
int i = 0;// 遍历整个数组
int l = -1, r = nums.length;
while(i < r) {
if(nums[i] == 0) swap(nums,++l,i++);
else if(nums[i] == 1) i++;
else swap(nums,--r,i);
}
return;
}
private void swap(int[] nums,int x,int y) {
int tmp = nums[x]; nums[x] = nums[y]; nums[y] = tmp;
}
}
l,r的起始位置, ensimmäinen elementti ja viimeinen elementti kuuluvat未处理状态, joten `l, r ei voi osoittaa näihin kahteen elementtiin ja sen on oltava välin ulkopuolella三个指针去分别维护四个区间, yksi intervalleista on未处理区间, kun kohdistin jatkaa liikkumista, kaikki intervallit käsitellään, ja lopulta on vain kolme väliä.Käytä yllä olevia ideoita快速排序的parttion中, lopputulos jaetaan kolmeen väliin
Koodi:
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
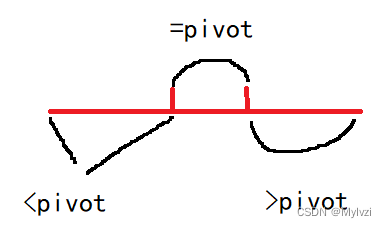
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp;
}
}
2. Valitse perusarvo satunnaisesti
Valitse perusarvo satunnaisesti satunnaislukujen avulla
int pivot = nums[start + new Random().nextInt(end - start + 1)];
// 起始位置 随机产生的偏移量
Täydellinen parannettu koodi:
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start + new Random().nextInt(end - start + 1)];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}

Pikavalintaalgoritmi on基于快速排序优化版本Aika monimutkaisuusO(N)Valintaalgoritmi, käyttöskenaario on第K大/前K大valintakysymyksiä, kuten
01.Matriisin K:nneksi suurin elementti
Linkki: https://leetcode.cn/problems/kth-largest-element-in-an-array/
analysoida
sortLajittele ja palaa K:nneksi suurimpaanO(N*logN)O(logN)Pinoa rekursiolla luodut kutsutSeuraavaksi toteutuksessa käytetään nopeaa valintaalgoritmiaO(N)Aika monimutkaisuus
Koodi:
class Solution {
public int findKthLargest(int[] nums, int k) {
return qsort(nums, 0, nums.length - 1, k);
}
private int qsort(int[] nums, int start, int end, int k) {
if(start >= end) return nums[start];
int pivot = nums[start + new Random().nextInt(end - start + 1)];
// 数组分三块 <pivot ==pivot >pivot
int l = start - 1, r = end + 1, i = start;
while(i < r) {
if(nums[i] < pivot) swap(nums, ++l, i++);
else if(nums[i] == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r - 1] [r, end]
int c = end - r + 1, b = r - 1 - (l + 1) + 1, a = l - start + 1;
// 分情况讨论 进行选择
if(c >= k) return qsort(nums, r, end, k);
else if(b + c >= k) return pivot;
else return qsort(nums, start, l, k - b - c);// 找较小区间的第(k-b-c)大
}
private void swap(int[] arr, int i, int j) {
int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;
}
}
O(N)
Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema jakaaksesi joitain teknologian kehittämisen ongelmia tulevaa käyttöä varten

