
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Prefacio: este artículo proporciona respuestas detalladas a algunas dudas sobre el aprendizaje temprano del algoritmo de clasificación rápida y proporciona una versión optimizada del algoritmo de clasificación rápida básica.
El núcleo del algoritmo de clasificación rápida es分治思想La estrategia divide y vencerás se divide en los siguientes tres pasos:
Aplicado al algoritmo de clasificación rápida:
El código clave para la clasificación rápida es如何根据基准元素划分数组区间(parttion)Hay muchos métodos de descomposición, aquí solo se proporciona uno.挖坑法
Código:
class Solution {
public int[] sortArray(int[] nums) {
quick(nums, 0, nums.length - 1);
return nums;
}
private void quick(int[] arr, int start, int end) {
if(start >= end) return;// 递归结束条件
int pivot = parttion(arr, start, end);
// 递归解决子问题
quick(arr, start, pivot - 1);
quick(arr, pivot + 1, end);
}
// 挖坑法进行分解
private int parttion(int[] arr, int left, int right) {
int key = arr[left];
while(left < right) {
while(left < right && arr[right] >= key) right--;
arr[left] = arr[right];
while(left < right && arr[left] <= key) ++left;
arr[right] = arr[left];
}
arr[left] = key;
return left;
}
}
Respuestas detalladas:
1.Por quéstart>=end¿Es la condición final de la recursividad?
Descomponer continuamente el subproblema. El tamaño final del subproblema es 1, es decir, solo hay un elemento. No es necesario continuar descomponiendo en este momento. Los punteros de inicio y fin apuntan al elemento al mismo tiempo. tiempo.
2. ¿Por qué debería ir primero la derecha y no la izquierda?
Depende de quien vaya primero
基准元素的位置En el código anterior, el elemento base (clave) es el elemento más a la izquierda si se mueve primero.left, la izquierda primero encuentra un elemento más grande que el elemento base y luego ejecutaarr[right] = arr[left],por no guardararr[right], este elemento se perderá
Si va primero a la derecha, la derecha primero encontrará un elemento más pequeño que el elemento base y luego ejecutaráarr[left]=arr[right]Debido a que la izquierda no se ha movido en este momento, sigue siendo el pivote, pero el pivote lo hemos guardado usando la tecla.
3. ¿Por qué arr[right]>=key?>¿No es posible?
Mayor o igual a es principalmente para procesamiento
重复元素问题
Por ejemplo, hay una matriz[6,6,6,6,6]Si es >, el puntero derecho no se moverá, y el puntero izquierdo tampoco se moverá, y quedará atrapado en un bucle infinito.
4. ¿Por qué se llama método de excavación de pozos?
Cuando el puntero r encuentra el primero
arr[r] = arr[l]En este momento, la posición l está en blanco, formando un hoyo.
Hay dos direcciones principales de optimización:
O(N*logN), es decir, la mejor complejidad temporal.数组分三块Al mismo tiempo, si encuentra casos de prueba especiales (matriz secuencial o matriz inversa), la complejidad del tiempo se degradará aO(N^2)Primero, basado en una pregunta (ordenar por color) entender lo que es数组分三块
analizar
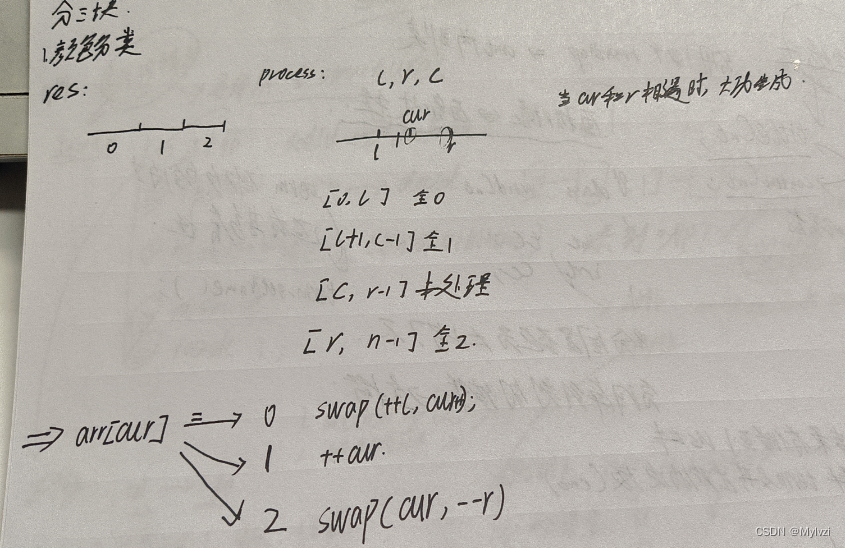
Código:
class Solution {
public void sortColors(int[] nums) {
// 分治 --
// 1.定义三指针
int i = 0;// 遍历整个数组
int l = -1, r = nums.length;
while(i < r) {
if(nums[i] == 0) swap(nums,++l,i++);
else if(nums[i] == 1) i++;
else swap(nums,--r,i);
}
return;
}
private void swap(int[] nums,int x,int y) {
int tmp = nums[x]; nums[x] = nums[y]; nums[y] = tmp;
}
}
l,r的起始位置, el primer elemento y el último elemento pertenecen a未处理状态, entonces `l, r no puede apuntar a estos dos elementos y debe estar fuera del intervalo三个指针去分别维护四个区间, uno de los intervalos es未处理区间, A medida que el puntero cur continúa moviéndose, se procesan todos los intervalos y, finalmente, solo quedan tres intervalos.Aplicar las ideas anteriores a快速排序的parttion中, el resultado final se divide en tres intervalos
Código:
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp;
}
}
2. Seleccione aleatoriamente el valor base
Seleccione aleatoriamente el valor base usando números aleatorios
int pivot = nums[start + new Random().nextInt(end - start + 1)];
// 起始位置 随机产生的偏移量
Código completo mejorado:
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start + new Random().nextInt(end - start + 1)];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}

El algoritmo de selección rápida es基于快速排序优化版本Una complejidad temporal deO(N)El algoritmo de selección, el escenario de uso es第K大/前K大cuestiones de elección como
01.El Késimo elemento más grande de la matriz.
Enlace: https://leetcode.cn/problems/kth-largest-element-in-an-array/
analizar
sortOrdenar y luego regresar al K-ésimo mayorO(N*logN)O(logN)Llamadas a pila generadas por recursividadA continuación, se utiliza un algoritmo de selección rápida para implementarO(N)La complejidad temporal de
Código:
class Solution {
public int findKthLargest(int[] nums, int k) {
return qsort(nums, 0, nums.length - 1, k);
}
private int qsort(int[] nums, int start, int end, int k) {
if(start >= end) return nums[start];
int pivot = nums[start + new Random().nextInt(end - start + 1)];
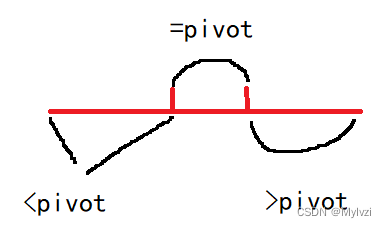
// 数组分三块 <pivot ==pivot >pivot
int l = start - 1, r = end + 1, i = start;
while(i < r) {
if(nums[i] < pivot) swap(nums, ++l, i++);
else if(nums[i] == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r - 1] [r, end]
int c = end - r + 1, b = r - 1 - (l + 1) + 1, a = l - start + 1;
// 分情况讨论 进行选择
if(c >= k) return qsort(nums, r, end, k);
else if(b + c >= k) return pivot;
else return qsort(nums, start, l, k - b - c);// 找较小区间的第(k-b-c)大
}
private void swap(int[] arr, int i, int j) {
int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;
}
}
O(N)
Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]