
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Prefazione: questo articolo fornisce risposte dettagliate ad alcuni dubbi sull'apprendimento precoce dell'algoritmo di ordinamento rapido e fornisce una versione ottimizzata dell'algoritmo di ordinamento rapido di base.
Il nucleo dell'algoritmo di ordinamento rapido è分治思想La strategia “divide et impera” è suddivisa nei seguenti tre passaggi:
Applicato all'algoritmo di ordinamento rapido:
Il codice chiave per l'ordinamento rapido è如何根据基准元素划分数组区间(parttion), esistono molti metodi di scomposizione, qui viene fornito solo un metodo.挖坑法
Codice:
class Solution {
public int[] sortArray(int[] nums) {
quick(nums, 0, nums.length - 1);
return nums;
}
private void quick(int[] arr, int start, int end) {
if(start >= end) return;// 递归结束条件
int pivot = parttion(arr, start, end);
// 递归解决子问题
quick(arr, start, pivot - 1);
quick(arr, pivot + 1, end);
}
// 挖坑法进行分解
private int parttion(int[] arr, int left, int right) {
int key = arr[left];
while(left < right) {
while(left < right && arr[right] >= key) right--;
arr[left] = arr[right];
while(left < right && arr[left] <= key) ++left;
arr[right] = arr[left];
}
arr[left] = key;
return left;
}
}
Risposte dettagliate:
1.Perchéstart>=endÈ la condizione finale della ricorsione?
Scomporre continuamente il sottoproblema. La dimensione finale del sottoproblema è 1, ovvero c'è un solo elemento. Non è necessario continuare la scomposizione in questo momento. I puntatori di inizio e fine puntano allo stesso elemento tempo.
2. Perché dovrebbe andare prima la destra invece della sinistra?
Dipende da chi inizia per primo
基准元素的位置,Nel codice precedente, l'elemento base (chiave) è l'elemento più a sinistra se viene spostato per primoleft, left incontra prima un elemento più grande dell'elemento base e quindi eseguearr[right] = arr[left],a causa del mancato salvataggioarr[right], questo elemento andrà perso
Se vai prima a destra, destra incontra prima un elemento più piccolo dell'elemento base e poi eseguearr[left]=arr[right], poiché la sinistra non si è mossa in questo momento, è ancora il perno, ma il perno è stato salvato da noi utilizzando la chiave.
3.Perché arr[right]>=key?>Non è possibile?
Maggiore o uguale a serve principalmente per l'elaborazione
重复元素问题
Ad esempio, c'è un array[6,6,6,6,6]Se è >, il puntatore destro non si sposterà, e neanche il puntatore sinistro si sposterà, e sarà bloccato in un ciclo infinito.
4. Perché si chiama metodo di scavo?
Quando il puntatore r incontra il primo
arr[r] = arr[l], in questo momento, la posizione l è vuota e forma una fossa.
Esistono due direzioni principali di ottimizzazione:
O(N*logN), cioè la migliore complessità temporale数组分三块Allo stesso tempo, se si incontrano casi di test speciali (array sequenziale o array inverso), la complessità temporale diminuiràO(N^2)Innanzitutto, sulla base di una domanda (ordinare per colore) capire di cosa si tratta数组分三块
analizzare
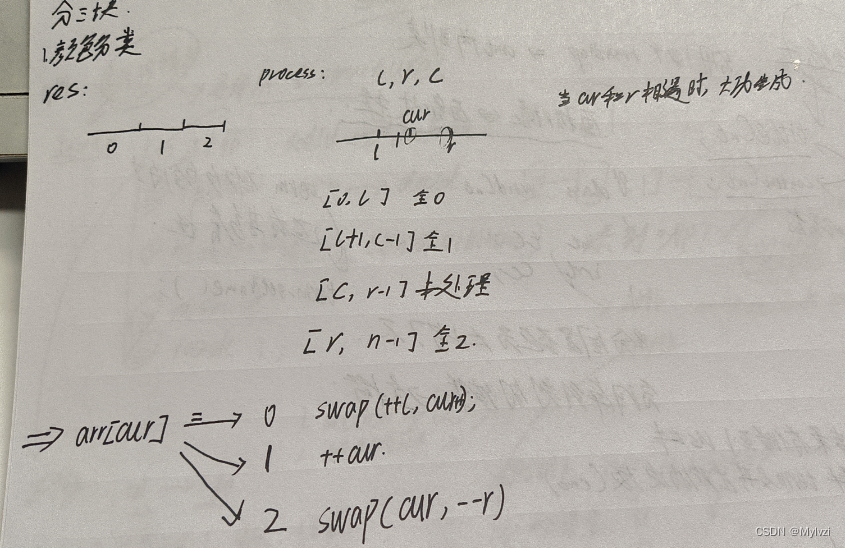
Codice:
class Solution {
public void sortColors(int[] nums) {
// 分治 --
// 1.定义三指针
int i = 0;// 遍历整个数组
int l = -1, r = nums.length;
while(i < r) {
if(nums[i] == 0) swap(nums,++l,i++);
else if(nums[i] == 1) i++;
else swap(nums,--r,i);
}
return;
}
private void swap(int[] nums,int x,int y) {
int tmp = nums[x]; nums[x] = nums[y]; nums[y] = tmp;
}
}
l,r的起始位置, a cui appartengono il primo elemento e l'ultimo elemento未处理状态, quindi `l, r non possono puntare a questi due elementi e devono essere al di fuori dell'intervallo三个指针去分别维护四个区间, uno degli intervalli è未处理区间, man mano che il puntatore continua a spostarsi, tutti gli intervalli vengono elaborati e infine ci sono solo tre intervalli.Applica le idee di cui sopra a快速排序的parttion中, il risultato finale è diviso in tre intervalli
Codice:
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
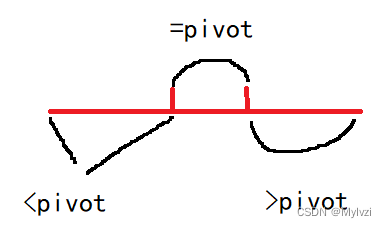
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp;
}
}
2. Selezionare casualmente il valore base
Seleziona casualmente il valore base utilizzando numeri casuali
int pivot = nums[start + new Random().nextInt(end - start + 1)];
// 起始位置 随机产生的偏移量
Codice migliorato completo:
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start + new Random().nextInt(end - start + 1)];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}

L'algoritmo di selezione rapida è基于快速排序优化版本Una complessità temporale diO(N)L'algoritmo di selezione, lo scenario di utilizzo è第K大/前K大questioni di scelta come
01.Il K-esimo elemento più grande dell'array
Collegamento: https://leetcode.cn/problems/kth-largest-element-in-an-array/
analizzare
sortOrdina e poi torna al K-esimo più grandeO(N*logN)O(logN)Chiamate stack generate dalla ricorsioneSuccessivamente, viene utilizzato un algoritmo di selezione rapida per l'implementazioneO(N)La complessità temporale di
Codice:
class Solution {
public int findKthLargest(int[] nums, int k) {
return qsort(nums, 0, nums.length - 1, k);
}
private int qsort(int[] nums, int start, int end, int k) {
if(start >= end) return nums[start];
int pivot = nums[start + new Random().nextInt(end - start + 1)];
// 数组分三块 <pivot ==pivot >pivot
int l = start - 1, r = end + 1, i = start;
while(i < r) {
if(nums[i] < pivot) swap(nums, ++l, i++);
else if(nums[i] == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r - 1] [r, end]
int c = end - r + 1, b = r - 1 - (l + 1) + 1, a = l - start + 1;
// 分情况讨论 进行选择
if(c >= k) return qsort(nums, r, end, k);
else if(b + c >= k) return pivot;
else return qsort(nums, start, l, k - b - c);// 找较小区间的第(k-b-c)大
}
private void swap(int[] arr, int i, int j) {
int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;
}
}
O(N)
Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]