2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Préface : Cet article fournit des réponses détaillées à certains doutes concernant l'apprentissage précoce de l'algorithme de tri rapide et fournit une version optimisée de l'algorithme de tri rapide de base.
Le cœur de l’algorithme de tri rapide est分治思想La stratégie diviser pour mieux régner est divisée en trois étapes :
Appliqué à l'algorithme de tri rapide :
Le code clé pour le tri rapide est如何根据基准元素划分数组区间(parttion), il existe de nombreuses méthodes de décomposition, une seule méthode est proposée ici.挖坑法
Code:
class Solution {
public int[] sortArray(int[] nums) {
quick(nums, 0, nums.length - 1);
return nums;
}
private void quick(int[] arr, int start, int end) {
if(start >= end) return;// 递归结束条件
int pivot = parttion(arr, start, end);
// 递归解决子问题
quick(arr, start, pivot - 1);
quick(arr, pivot + 1, end);
}
// 挖坑法进行分解
private int parttion(int[] arr, int left, int right) {
int key = arr[left];
while(left < right) {
while(left < right && arr[right] >= key) right--;
arr[left] = arr[right];
while(left < right && arr[left] <= key) ++left;
arr[right] = arr[left];
}
arr[left] = key;
return left;
}
}
Réponses détaillées :
1.Pourquoistart>=endEst-ce la condition finale de la récursion ?
Décomposez continuellement le sous-problème. La taille finale du sous-problème est de 1, c'est-à-dire qu'il n'y a qu'un seul élément. Il n'est pas nécessaire de continuer la décomposition pour le moment. Les pointeurs de début et de fin pointent vers l'élément en même temps. temps.
2. Pourquoi la droite devrait-elle passer en premier plutôt que la gauche ?
Cela dépend de qui commence
基准元素的位置,Dans le code ci-dessus, l'élément de base (clé) est l'élément le plus à gauche s'il est déplacé en premier.left, la gauche rencontre d'abord un élément plus grand que l'élément de base, puis exécutearr[right] = arr[left], parce que je n'ai pas sauvegardéarr[right], cet élément sera perdu
Si vous allez d'abord à droite, la droite rencontre d'abord un élément plus petit que l'élément de base, puis exécutearr[left]=arr[right], parce que la gauche n'a pas bougé à ce moment, c'est toujours le pivot, mais le pivot a été sauvegardé par nos soins à l'aide de la clé.
3.Pourquoi arr[right]>=key ?>N'est-ce pas possible ?
Supérieur ou égal à est principalement destiné au traitement
重复元素问题
Par exemple, il existe un tableau[6,6,6,6,6]Si c'est >, le pointeur droit ne bougera pas, et le pointeur gauche ne bougera pas non plus, et il sera coincé dans une boucle infinie.
4. Pourquoi est-ce appelé méthode de creusement de fosses ?
Lorsque le pointeur r rencontre le premier
arr[r] = arr[l], à ce moment, la position l est vide, formant un creux.
Il existe deux directions principales d'optimisation :
O(N*logN), c'est-à-dire la meilleure complexité temporelle数组分三块Dans le même temps, si vous rencontrez des cas de tests particuliers (tableau séquentiel ou tableau inversé), la complexité temporelle se dégradera àO(N^2)Tout d'abord, sur la base d'une question (trier par couleur) comprendre ce que c'est数组分三块
analyser
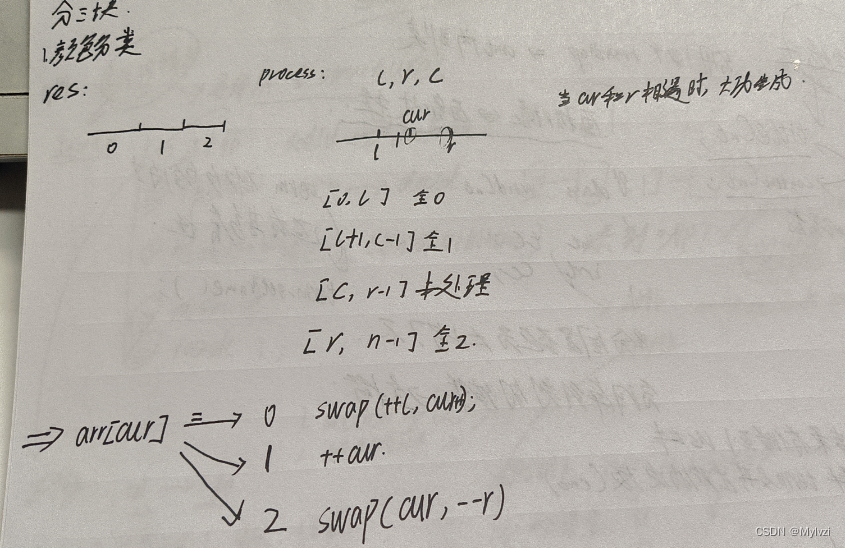
Code:
class Solution {
public void sortColors(int[] nums) {
// 分治 --
// 1.定义三指针
int i = 0;// 遍历整个数组
int l = -1, r = nums.length;
while(i < r) {
if(nums[i] == 0) swap(nums,++l,i++);
else if(nums[i] == 1) i++;
else swap(nums,--r,i);
}
return;
}
private void swap(int[] nums,int x,int y) {
int tmp = nums[x]; nums[x] = nums[y]; nums[y] = tmp;
}
}
l,r的起始位置, le premier élément et le dernier élément appartiennent à未处理状态, donc `l, r ne peut pas pointer vers ces deux éléments et doit être en dehors de l'intervalle三个指针去分别维护四个区间, l'un des intervalles est未处理区间, à mesure que le pointeur cur continue de se déplacer, tous les intervalles sont traités et finalement il n'y a que trois intervalles.Appliquez les idées ci-dessus à快速排序的parttion中, le résultat final est divisé en trois intervalles
Code:
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i]; nums[i] = nums[j]; nums[j] = tmp;
}
}
2. Sélectionnez au hasard la valeur de base
Sélectionnez au hasard la valeur de base en utilisant des nombres aléatoires
int pivot = nums[start + new Random().nextInt(end - start + 1)];
// 起始位置 随机产生的偏移量
Code amélioré complet :
class Solution {
// 快速排序优化版
// 分解--解决--合并
public int[] sortArray(int[] nums) {
qsort(nums, 0, nums.length - 1);
return nums;
}
private void qsort(int[] nums, int start, int end) {
if(start >= end) return;// 递归结束条件
// 分解
int pivot = nums[start + new Random().nextInt(end - start + 1)];
int l = start - 1, r = end + 1, i = start;
while(i < r) {
int cur = nums[i];
if(cur < pivot) swap(nums, ++l, i++);
else if(cur == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r-1] [r, end]
// 递归解决
qsort(nums, start, l);
qsort(nums, r, end);
}
private void swap(int[] nums,int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}

L'algorithme de sélection rapide est基于快速排序优化版本Une complexité temporelle deO(N)L'algorithme de sélection, le scénario d'utilisation est第K大/前K大des problèmes de choix comme
01.Le Kème plus grand élément du tableau
Lien : https://leetcode.cn/problems/kth-largest-element-in-an-array/
analyser
sortTrier puis revenir au Kième plus grandO(N*logN)O(logN)Appels de pile générés par récursionEnsuite, un algorithme de sélection rapide est utilisé pour implémenterO(N)La complexité temporelle de
Code:
class Solution {
public int findKthLargest(int[] nums, int k) {
return qsort(nums, 0, nums.length - 1, k);
}
private int qsort(int[] nums, int start, int end, int k) {
if(start >= end) return nums[start];
int pivot = nums[start + new Random().nextInt(end - start + 1)];
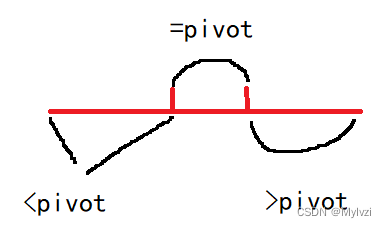
// 数组分三块 <pivot ==pivot >pivot
int l = start - 1, r = end + 1, i = start;
while(i < r) {
if(nums[i] < pivot) swap(nums, ++l, i++);
else if(nums[i] == pivot) ++i;
else swap(nums, --r, i);
}
// [start, l] [l+1, r - 1] [r, end]
int c = end - r + 1, b = r - 1 - (l + 1) + 1, a = l - start + 1;
// 分情况讨论 进行选择
if(c >= k) return qsort(nums, r, end, k);
else if(b + c >= k) return pivot;
else return qsort(nums, start, l, k - b - c);// 找较小区间的第(k-b-c)大
}
private void swap(int[] arr, int i, int j) {
int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;
}
}
O(N)
Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

