2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Hallo Freunde! Lasst uns heute gemeinsam die Datenstruktur des Stapels lernen!

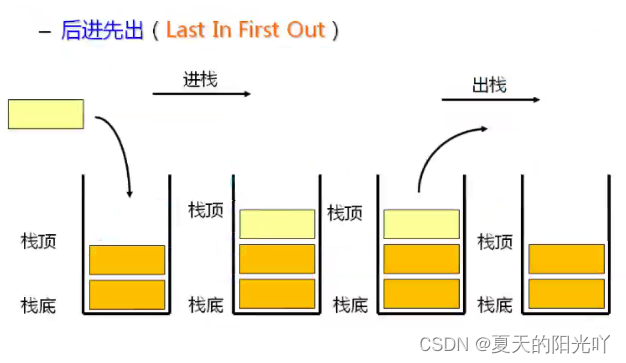
Stapel: Eine spezielle lineare Liste, die nur Einfüge- und Löschvorgänge an einem festen Ende zulässt. Das Ende, an dem die Dateneinfügungs- und -löschvorgänge eingegeben werden, wird als oberes Ende des Stapels bezeichnet, und das andere Ende wird als unteres Ende des Stapels bezeichnet.Datenelemente im Stapel entsprechenLIFO (Last In First Out)-Prinzip. Wir können es uns so vorstellen, als würden wir Hammelkebabs essen,Ziehen Sie es zuerst anDie Hammelfleischstücke werden hineingedrücktunten,der LetzteDie Hammelstücke sind daAn der Spitzevon.

Schieben des Stapels: Der Einfügevorgang des Stapels wird Push/Push/Push genannt.Fügen Sie Daten von oben in den Stapel ein。
Pop: Der Löschvorgang des Stapels wird als Popping bezeichnet.Die ausgehenden Daten liegen ebenfalls oben auf dem Stapel。
Der Stapel kann im Allgemeinen mithilfe eines Arrays zur Implementierung des Stapels oder mithilfe einer verknüpften Liste zur Implementierung des Stapels implementiert werden, je nachdem, was relativ gesehen besser istArray-StrukturDie Implementierung des Stacks ist einfacher und effizienter.
Denn bei der Implementierung werden die Schnittstellen zum Hinzufügen, Löschen, Ändern und Abfragen der vorherigen Sequenztabelle implementiert (Datenstruktur-Sequenztabelle) Es ist für uns sehr praktisch, die Struktur des Arrays zum Einfügen und Löschen am Ende zu verwenden. Daher definieren wir bei der Implementierung des Stapels das Ende des Arrays als die Oberseite des Stapels und den Kopf als die Unterseite der Stapel.
Der Stapel kann wie die Sequenzliste als statischer Stapel fester Länge oder als dynamisch wachsender Stapel ausgelegt sein.Da der Stapel mit fester Länge große Einschränkungen aufweist und in der Praxis nicht praktikabel ist, implementieren wir hauptsächlich UnterstützungDynamisch wachsender Stapel。
Wie bei der vorherigen Implementierung der Sequenzlisten-/verknüpften Listenschnittstelle erstellen wir zunächst eine Header-Datei „Stack.h“ und zwei Quelldateien „Stack.c“ und „Test.c“. Die spezifischen Funktionen sind:
| Stack.h | Stack-Definition, Header-Dateireferenz und Schnittstellenfunktionsdeklaration |
| Stapel.c | Implementierung von Schnittstellenfunktionen |
| Test.c | Testen Sie jede Funktion |
Lassen Sie uns zunächst den vollständigen Code von „Stack.h“ zeigen. Vergessen Sie nicht, „Stack.h“ in den beiden Quelldateien anzugeben
- #pragma once //防止头文件被二次引用
- #include<stdio.h>
- #include<stdlib.h>
- #include<assert.h>
-
- typedef int ElemType; //如果要修改存储的数据类型可直接在此修改
- typedef struct Stack {
- ElemType* arr; //动态数组
- int top; //栈顶
- int capacity; //容量
- }Stack;
-
-
- void StackInit(Stack* ps);//初始化栈
-
- void StackPush(Stack* ps, ElemType x);//入栈
-
- void StackPop(Stack* ps);//出栈
-
- ElemType StackTop(Stack* ps);//获取栈顶元素
-
- int StackSize(Stack* ps);//获取栈中有效元素的个数
-
- int StackEmpty(Stack* ps);//检测栈是否为空,如果为空返回非零结果,如果不为空返回0
-
- void StackDestroy(Stack* ps);//销毁栈
Unter diesen wird die Bedeutung von „oben“ durch den Anfangswert bestimmt, der im Folgenden ausführlich erläutert wird. Als nächstes beginnen wir mit der Implementierung der Schnittstelle.
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
Zum besseren Verständnis verstehen wir oben in der Struktur ungefähr den Index des Arrays.Wenn wir beim Initialisieren des Stapels top auf 0 initialisieren, befinden sich keine Daten im Stapel und top zeigt auf die nächste Position der obersten Daten im Stapel.

Wenn wir top auf -1 initialisieren, zeigt top auf die Position der obersten Daten auf dem Stapel. Es ist für uns besser, es hier auf 0 zu initialisieren, da es praktisch ist, Elemente hinzuzufügen und Elemente zu löschen.
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
Da es einen Unterschied zwischen dem Stapel und der Sequenztabelle gibt, können wir die Elemente im Stapel nicht direkt durchlaufen und drucken. Daher müssen wir die Funktionen StackEmpty und StackPop verwenden, die später erläutert werden .
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
Aus diesem Grund muss StackEmpty in der vorherigen Behauptung hinzugefügt werdenlogischer NegationsoperatorDer Grund dafür ist, dass StackEmpty true zurückgibt, wenn der Stapel leer ist, und die Negation von false beweisen kann, dass sich Elemente im Stapel befinden.
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
Nachdem alle Schnittstellen fertiggestellt sind, testen wir den Code in Test.c:
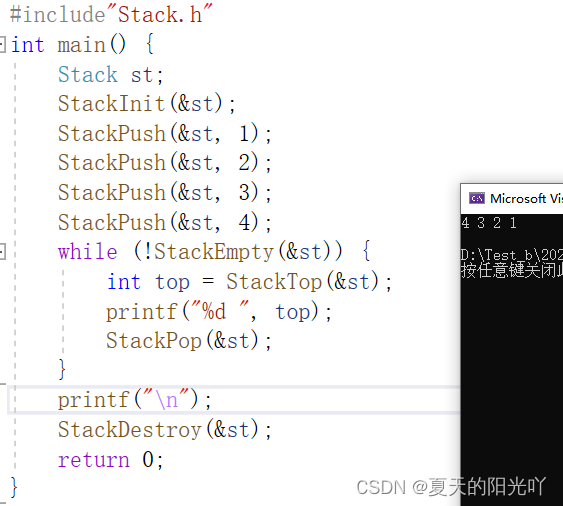
Lass es uns noch einmal testen:
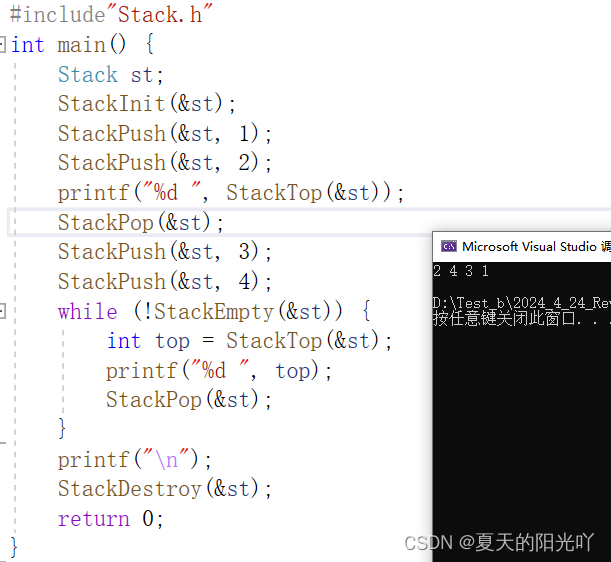
Überhaupt kein Problem. Herzlichen Glückwunsch zur Fertigstellung der Stack-Schnittstelle! Das Folgende ist der vollständige Code der Datei „Stack.c“:
- #include"Stack.h"
-
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
-
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
-
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
-
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
-
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
-
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
-
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
1. Welche der folgenden Aussagen zu Stapeln ist richtig ( )
A. Der Stapel ist eine „First In First Out“-Datenstruktur
B. Der Stapel kann mithilfe einer verknüpften Liste oder einer sequentiellen Liste implementiert werden
C. Der Stapel kann nur Daten am unteren Ende des Stapels einfügen
D. Der Stack kann keine Daten löschen
korrekte Antwort: B
Ein Fehler: Der Stapel ist eine Last-In-First-Out-Datenstruktur und die Warteschlange ist First-In, First-Out.
B ist richtig: Sowohl Sequenzlisten als auch verknüpfte Listen können zum Implementieren von Stapeln verwendet werden, aber Sequenzlisten werden im Allgemeinen verwendet, da der Stapel als kastrierte Version der Sequenzliste betrachtet wird. Nur die Schwanzeinfügungs- und Schwanzlöschoperationen der Sequenztabelle Die Endeinfügung und die Endlöschung der Sequenztabelle erfordern keine beweglichen Elemente und sind sehr effizient. Daher werden sie im Allgemeinen mithilfe sequentieller Tabellen implementiert.
C-Fehler: Der Stapel kann Eingabeeinfügungs- und -löschvorgänge nur oben im Stapel ausführen
D-Fehler: Der Stapel verfügt über Push- und Pop-Operationen, um ein Element aus dem Stapel zu löschen.
2. Die Push-Sequenz eines Stapels ist ABCDE und die unmögliche Pop-Sequenz ist ( )
A.ABCDE
B.EDCBA
C.DCEBA
D.ECDBA
korrekte Antwort: D
Wenn E zuerst herauskommt, bedeutet dies, dass ABCDE vollständig auf den Stapel geschoben wurde. Nachdem E aus dem Stapel entfernt wurde, ist das oberste Element des Stapels D. Wenn es erneut herausspringt, sollte es D und nicht C sein .
Daher sollte D ausgewählt werden
3. Im Vergleich zum sequentiellen Stapel sind die offensichtlichen Vorteile des Kettenstapels ( )
A. Der Einfügevorgang ist bequemer
B. Der Löschvorgang ist bequemer
C. Beim Einschieben in den Stapel ist keine Erweiterung erforderlich
korrekte Antwort: C
Fehler A. Wenn es sich um einen Kettenstapel handelt, sind im Allgemeinen Vorgänge zum Einfügen oder Löschen des Kopfes erforderlich, während bei einem sequentiellen Stapel im Allgemeinen Vorgänge zum Einfügen und Löschen des Endes ausgeführt werden. Die Operation einer verknüpften Liste ist komplizierter als die einer sequentiellen Tabelle Es ist einfacher, eine sequentielle Struktur zum Implementieren eines Stapels zu verwenden.
B ist falsch. Den Grund finden Sie bei A.
C ist korrekt. Wenn der Stapel in einer Kettenstruktur implementiert ist, entspricht jeder Push in den Stapel dem Einfügen eines Knotens in den Kopf der verknüpften Liste.
4. Welche der folgenden Aussagen zur Verwendung von Stacks zur Implementierung von Warteschlangen ist falsch ( )
A. Durch die Stapelsimulation zum Implementieren einer Warteschlange können zwei Stapel verwendet werden, ein Stapel simuliert das Betreten der Warteschlange und ein Stapel simuliert das Verlassen der Warteschlange.
B. Jedes Mal, wenn Sie die Warteschlange entfernen, müssen Sie alle Elemente in einem Stapel in einen anderen Stapel importieren und ihn dann herausnehmen.
C. Wenn Sie in die Warteschlange eintreten, speichern Sie die Elemente einfach direkt im Stapel, der das Eintreten in die Warteschlange simuliert.
D. Die zeitliche Komplexität der Warteschlangenoperation beträgt O(1)
korrekte Antwort: B
Bei Option B simuliert ein Stapel das Eintreten in die Warteschlange und ein Stapel das Entnehmen aus der Warteschlange. Wenn der Stapel leer ist, werden alle Elemente im simulierten Warteschlangenstapel importiert . Es ist notwendig, jedes Mal Elemente zu importieren, daher ist es falsch.
Bei Option A sind die Eigenschaften von Stapeln und Warteschlangen entgegengesetzt. Ein Stapel kann keine Warteschlange implementieren.
Bei Option C simuliert ein Stapel das Betreten der Warteschlange und ein Stapel das Verlassen der Warteschlange. Beim Betreten der Warteschlange werden die Elemente direkt in dem Stapel gespeichert, der das Betreten der Warteschlange simuliert.
In Option D bedeutet Warteschlangen, Elemente auf den Stapel zu legen, sodass die Zeitkomplexität O(1) beträgt.
Heute haben wir etwas über die Datenstruktur eines Stapels erfahren. Ist das nicht viel einfacher als eine verknüpfte Liste? Ich hoffe, dieser Artikel wird meinen Freunden hilfreich sein!!!
bittenLiken, favorisieren und folgen!!!
Danke euch allen! ! !


Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

