
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Ciao! Ciao amici! Impariamo insieme la struttura dei dati dello stack oggi!

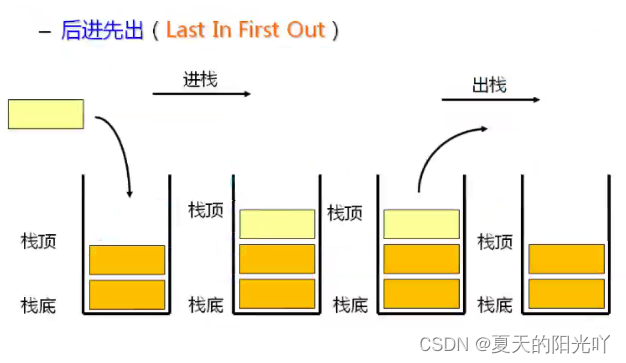
Stack: uno speciale elenco lineare che consente solo operazioni di inserimento e cancellazione ad un'estremità fissa. L'estremità che entra nelle operazioni di inserimento ed eliminazione dei dati è chiamata la parte superiore dello stack, mentre l'altra estremità è chiamata la parte inferiore dello stack.Gli elementi dati nello stack sono conformiLIFO (Last In First Out). Possiamo immaginarlo come mangiare spiedini di montone,Mettilo primaI pezzi di montone vengono pressatimetter il fondo a,l'ultimoCi sono i pezzi di montoneSulla cimaDi.

Push dello stack: l'operazione di inserimento dello stack è chiamata push/push/push.Inserisci i dati dalla cima dello stack。
Pop: L'operazione di cancellazione dello stack è detta popping.Anche i dati in uscita si trovano in cima allo stack。
Lo stack può generalmente essere implementato utilizzando un array per implementare lo stack o utilizzando un elenco collegato per implementare lo stack, a seconda di quale sia il migliore, relativamente parlandostruttura dell'arrayL'implementazione dello stack è più semplice ed efficiente.
Perché nell'implementazione dell'interfaccia di aggiunta, cancellazione, modifica e query della tabella di sequenza precedente (tabella di sequenza della struttura dei dati) Per noi è molto comodo utilizzare la struttura dell'array per inserire ed eliminare dalla fine, quindi nell'implementazione dello stack definiamo la fine dell'array come la parte superiore dello stack e la testa come la parte inferiore dello la pila.
Lo stack, come l'elenco di sequenze, può essere progettato come uno stack statico a lunghezza fissa o come uno stack a crescita dinamica.Poiché lo stack a lunghezza fissa presenta grandi limitazioni e non è pratico nella pratica, implementiamo principalmente il supportoStack in crescita dinamica。
Come per la precedente implementazione dell'interfaccia elenco sequenze/elenco collegato, creiamo prima un file di intestazione "Stack.h" e due file sorgente "Stack.c" e "Test.c".
| Pila.h | Definizione dello stack, riferimento al file di intestazione e dichiarazione della funzione dell'interfaccia |
| Pila.c | Implementazione delle funzioni di interfaccia |
| Prova.c | Testare ogni funzione |
Mostriamo prima il codice completo di "Stack.h", non dimenticare di citare "Stack.h" nei 2 file sorgente
- #pragma once //防止头文件被二次引用
- #include<stdio.h>
- #include<stdlib.h>
- #include<assert.h>
-
- typedef int ElemType; //如果要修改存储的数据类型可直接在此修改
- typedef struct Stack {
- ElemType* arr; //动态数组
- int top; //栈顶
- int capacity; //容量
- }Stack;
-
-
- void StackInit(Stack* ps);//初始化栈
-
- void StackPush(Stack* ps, ElemType x);//入栈
-
- void StackPop(Stack* ps);//出栈
-
- ElemType StackTop(Stack* ps);//获取栈顶元素
-
- int StackSize(Stack* ps);//获取栈中有效元素的个数
-
- int StackEmpty(Stack* ps);//检测栈是否为空,如果为空返回非零结果,如果不为空返回0
-
- void StackDestroy(Stack* ps);//销毁栈
Tra questi, il significato di "top" è determinato dal valore iniziale, che verrà spiegato in dettaglio di seguito. Successivamente iniziamo a implementare l'interfaccia.
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
Per facilità di comprensione, nella struttura intendiamo approssimativamente top come il pedice dell'array.Se inizializziamo top a 0 durante l'inizializzazione dello stack, non ci sono dati nello stack e top punta alla posizione successiva dei dati top nello stack.

Se inizializziamo top a -1, top punterà alla posizione dei dati principali nello stack. È meglio per noi inizializzarlo su 0 qui perché è conveniente aggiungere elementi ed eliminare elementi.
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
Poiché esiste una differenza tra lo stack e la tabella di sequenza, non possiamo attraversare e stampare direttamente. Pertanto, se vogliamo stampare gli elementi nello stack, dobbiamo utilizzare la funzione StackEmpty e la funzione StackPop, di cui parleremo più avanti. .
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
Questo è il motivo per cui è necessario aggiungere StackEmpty nell'affermazione precedenteoperatore logico di negazioneIl motivo è che se lo stack è vuoto, StackEmpty restituisce true e la negazione di false può dimostrare che ci sono elementi nello stack.
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
Dopo aver completato tutte le interfacce, testiamo il codice in Test.c:
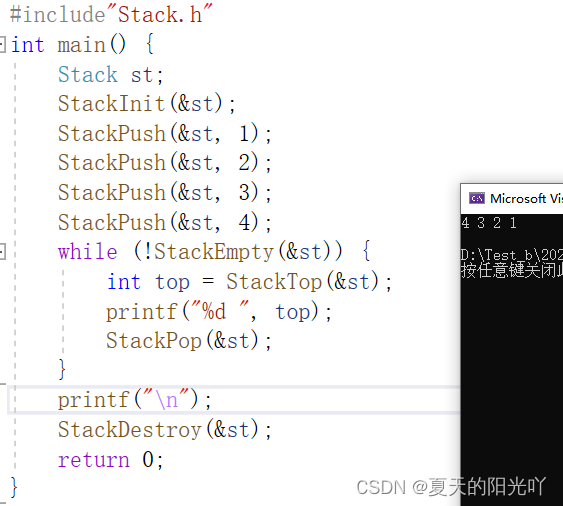
Proviamolo ancora un po':
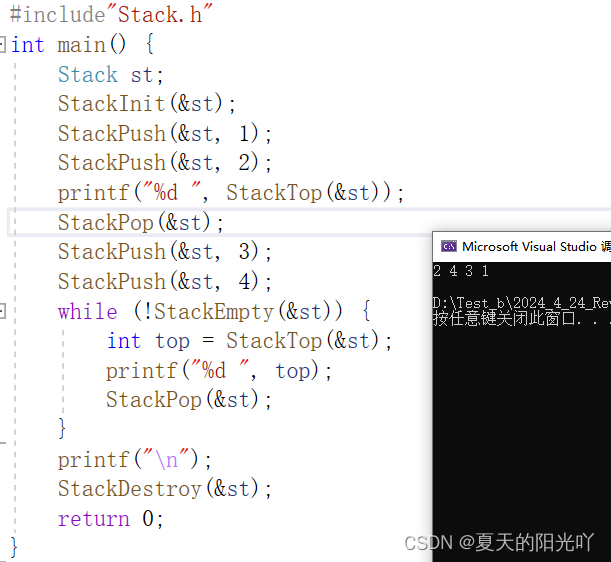
Nessun problema. Congratulazioni per aver completato l'implementazione dell'interfaccia stack. Quello che segue è il codice completo del file "Stack.c":
- #include"Stack.h"
-
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
-
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
-
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
-
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
-
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
-
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
-
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
1. Quale delle seguenti affermazioni sugli stack è corretta ( )
R. Lo stack è una struttura dati "first in first out".
B. Lo stack può essere implementato utilizzando un elenco collegato o un elenco di sequenze
C. Lo stack può inserire dati solo nella parte inferiore dello stack
D. Lo stack non può eliminare i dati
risposta corretta: B
Errore A: lo stack è una struttura dati last-in-first-out e la coda è first-in, first-out.
B è corretto: sia gli elenchi di sequenze che gli elenchi collegati possono essere utilizzati per implementare gli stack, ma gli elenchi di sequenze vengono generalmente utilizzati perché lo stack è considerato una versione castrata dell'elenco di sequenze. Solo le operazioni di inserimento ed eliminazione della coda della tabella di sequenza lo sono utilizzato e viene utilizzato l'inserimento della coda della tabella di sequenza. L'eliminazione della coda e l'eliminazione della coda non richiedono lo spostamento di elementi e sono molto efficienti, quindi vengono generalmente implementate utilizzando tabelle sequenziali.
Errore C: lo stack può eseguire solo operazioni di inserimento ed eliminazione di input nella parte superiore dello stack
Errore D: lo stack ha operazioni push e pop. Pop consiste nell'eliminare un elemento dallo stack.
2. La sequenza di push di uno stack è ABCDE e la sequenza di pop impossibile è ( )
A.ABCDE
B. EDCBA
C.DCEBA
D.ECDBA
risposta corretta: D
Se E esce per primo, significa che ABCDE è stato tutto messo in pila. Dopo che E è stato tolto dallo stack, l'elemento in cima alla pila è D. Se viene tolto di nuovo, dovrebbe essere D, non C. .
Pertanto, è opportuno selezionare D
3. Rispetto allo stack sequenziale, gli ovvi vantaggi dello stack a catena sono ( )
R. L'operazione di inserimento è più conveniente
B. L'operazione di cancellazione è più conveniente
C. Non è necessaria alcuna espansione quando si inserisce nella pila
risposta corretta: C
Errore A. Se si tratta di uno stack concatenato richiede in genere operazioni di inserimento o cancellazione di testa, mentre uno stack sequenziale generalmente esegue operazioni di inserimento e cancellazione di coda. Il funzionamento di una lista concatenata è più complicato di una tabella sequenziale, quindi lo è più semplice utilizzare una struttura sequenziale per implementare uno stack.
B ha torto, fare riferimento ad A per il motivo.
C è corretto Quando lo stack è implementato in una struttura a catena, ogni inserimento nello stack equivale a inserire un nodo in testa alla lista concatenata.
4. Quale delle seguenti affermazioni sull'utilizzo degli stack per implementare le code è errata ( )
R. Utilizzando la simulazione dello stack per implementare una coda è possibile utilizzare due stack, uno stack simula l'ingresso nella coda e uno stack simula l'uscita dalla coda.
B. Ogni volta che si rimuove dalla coda, è necessario importare tutti gli elementi di uno stack in un altro stack e quindi estrarli.
C. Quando si entra in coda è sufficiente memorizzare gli elementi direttamente nello stack che simula l'ingresso in coda.
D. La complessità temporale dell'operazione in coda è O(1)
risposta corretta: B
Nell'opzione B, uno stack simula l'ingresso nella coda e un altro stack simula l'eliminazione dalla coda, l'elemento superiore dello stack di rimozione dalla coda simulato viene visualizzato direttamente. Quando lo stack è vuoto, tutti gli elementi nello stack della coda simulata vengono importati Gli elementi devono essere importati ogni volta, quindi è un errore
Nell'opzione A, le caratteristiche degli stack e delle code sono opposte. Uno stack non può implementare una coda.
Nell'opzione C, uno stack simula l'ingresso nella coda e l'altro stack simula l'uscita dalla coda. Quando si entra nella coda, gli elementi vengono memorizzati direttamente nello stack che simula l'ingresso nella coda.
Nell'opzione D, accodare significa mettere elementi in pila, quindi la complessità temporale è O(1)
Oggi abbiamo imparato a conoscere la struttura dei dati di uno stack Non è molto più semplice di una lista concatenata Hahahahaha, spero che questo articolo sia utile ai miei amici!!!
elemosinareMetti mi piace, aggiungi ai preferiti e segui!!!
grazie a tutti! ! !


Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]