
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Привет, друзья! Давайте сегодня вместе изучим структуру данных стека! Вы готовы?

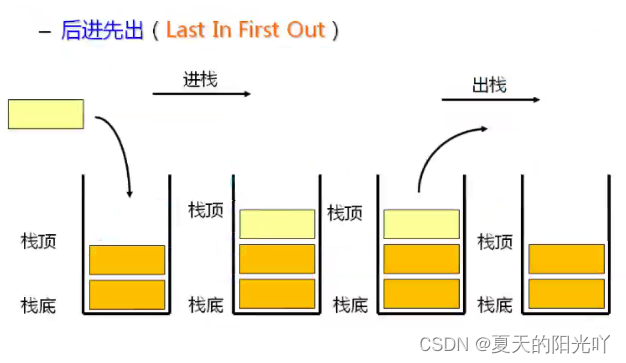
Стек: специальный линейный список, который допускает операции вставки и удаления только на фиксированном конце. Конец, который выполняет операции вставки и удаления данных, называется вершиной стека, а другой конец — низом стека.Элементы данных в стеке соответствуютЛИФО Принцип (Последний пришел — первый ушел). Мы можем представить это как поедание шашлыка из баранины,Сначала надень этоКусочки баранины прессуютсянижний,последнийКусочки баранины находятся вНа вершинеиз.

Перемещение стека. Операция вставки стека называется push/push/push.Вставка данных из вершины стека。
Pop: операция удаления стека называется извлечением.Исходящие данные также находятся на вершине стека.。
Стек обычно можно реализовать с помощью массива для реализации стека или использования связанного списка для реализации стека. В зависимости от того, что лучше, условно говоря, используйте.структура массиваРеализация стека проще и эффективнее.
Потому что при реализации добавления, удаления, изменения и запроса интерфейса предыдущей таблицы последовательности (таблица последовательности структуры данных) Нам очень удобно использовать структуру массива для вставки и удаления с конца, поэтому в реализации стека мы определяем конец массива как вершину стека, а голову как низ стек.
Стек, как и список последовательностей, может быть спроектирован как статический стек фиксированной длины или как динамически растущий стек.Поскольку стек фиксированной длины имеет большие ограничения и на практике непрактичен, мы в основном реализуем поддержкуДинамически растущий стек。
Как и в предыдущей реализации интерфейса списка последовательностей/связанного списка, мы сначала создаем заголовочный файл «Stack.h» и два исходных файла «Stack.c» и «Test.c». Конкретные функции:
| Стек.h | Определение стека, ссылка на заголовочный файл и объявление функции интерфейса. |
| Стек.c | Реализация интерфейсных функций |
| Тест.c | Тестируйте каждую функцию |
Давайте сначала покажем полный код «Stack.h», не забудьте заключить «Stack.h» в кавычки в двух исходных файлах.
- #pragma once //防止头文件被二次引用
- #include<stdio.h>
- #include<stdlib.h>
- #include<assert.h>
-
- typedef int ElemType; //如果要修改存储的数据类型可直接在此修改
- typedef struct Stack {
- ElemType* arr; //动态数组
- int top; //栈顶
- int capacity; //容量
- }Stack;
-
-
- void StackInit(Stack* ps);//初始化栈
-
- void StackPush(Stack* ps, ElemType x);//入栈
-
- void StackPop(Stack* ps);//出栈
-
- ElemType StackTop(Stack* ps);//获取栈顶元素
-
- int StackSize(Stack* ps);//获取栈中有效元素的个数
-
- int StackEmpty(Stack* ps);//检测栈是否为空,如果为空返回非零结果,如果不为空返回0
-
- void StackDestroy(Stack* ps);//销毁栈
Среди них значение «верхнего» определяется начальным значением, которое будет подробно объяснено ниже. Далее мы приступаем к реализации интерфейса.
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
Для простоты понимания под верхним индексом массива будем понимать приблизительно верхнюю часть структуры.Если мы инициализируем top значением 0 при инициализации стека, в стеке нет данных, а top указывает на следующую позицию верхних данных в стеке.

Если мы инициализируем top значением -1, top будет указывать на расположение верхних данных в стеке. Здесь нам лучше инициализировать его значением 0, поскольку удобно добавлять и удалять элементы.
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
Поскольку существует разница между стеком и таблицей последовательности, мы не можем напрямую перемещаться и печатать. Поэтому, если мы хотим напечатать элементы в стеке, нам нужно использовать функцию StackEmpty и функцию StackPop, которые будут обсуждаться позже. .
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
Вот почему необходимо добавить StackEmpty в предыдущем утверждении.оператор логического отрицанияПричина в том, что если стек пуст, StackEmpty возвращает true, а отрицание false может доказать, что в стеке есть элементы.
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
После того, как все интерфейсы готовы, давайте проверим код в Test.c:
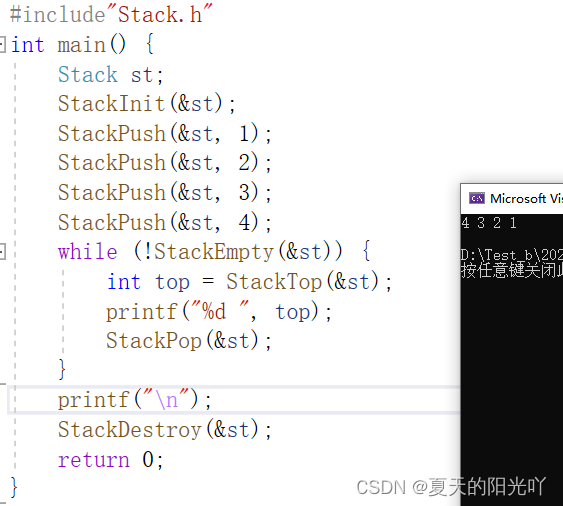
Давайте проверим это еще раз:
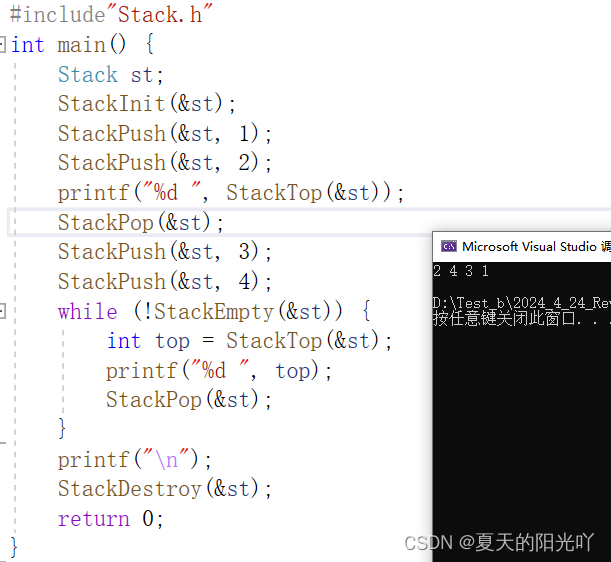
Никаких проблем. Поздравляем с завершением реализации интерфейса стека. Ниже приведен полный код файла Stack.c:
- #include"Stack.h"
-
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
-
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
-
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
-
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
-
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
-
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
-
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
1. Какое из следующих утверждений о стеках верно ( )
А. Стек представляет собой структуру данных по принципу «первым пришел – первым обслужен».
Б. Стек может быть реализован с использованием связанного списка или последовательного списка.
C. Стек может вставлять данные только в нижнюю часть стека.
D. Стек не может удалить данные
правильный ответ: Б
Ошибка: стек представляет собой структуру данных «последний пришел — первый обслужен», а очередь — «первым пришел — первым обслужен».
Б верен: для реализации стеков можно использовать как списки последовательностей, так и связанные списки, но обычно используются списки последовательностей, поскольку стек рассматривается как кастрированная версия списка последовательностей. В таблице последовательностей используются только операции вставки и удаления хвостов. используется и вставка хвоста таблицы последовательности. Удаление хвоста и удаление хвоста не требуют перемещения элементов и очень эффективны, поэтому они обычно реализуются с использованием последовательных таблиц.
Ошибка C: стек может выполнять операции вставки и удаления только в верхней части стека.
Ошибка D: в стеке есть операции push и pop. Pop — это удаление элемента из стека.
2. Последовательность перемещения стека — ABCDE, а невозможная последовательность извлечения — ( )
А.ABCDE
Б.EDCBA
C.DCEBA
D.ECDBA
правильный ответ: Д
Если E выходит первым, это означает, что все элементы ABCDE были помещены в стек. После извлечения E из стека верхним элементом стека является D. Если он извлекается снова, это должен быть D, а не C. .
Поэтому следует выбрать D.
3. По сравнению с последовательным стеком очевидными преимуществами цепного стека являются ( )
А. Операция вставки более удобна
B. Операция удаления более удобна
C. При вставке в стек расширение не требуется.
правильный ответ: С
Ошибка A. Если это цепной стек, он обычно требует операций вставки или удаления заголовка, тогда как последовательный стек обычно выполняет операции вставки и удаления хвоста. Операция связанного списка более сложна, чем последовательная таблица, поэтому это так. проще использовать последовательную структуру для реализации стека.
Б неверен, пожалуйста, обратитесь к А, чтобы узнать причину.
C верно. Когда стек реализован в виде цепочечной структуры, каждое нажатие в стек эквивалентно вставке узла в заголовок связанного списка. Расширение отсутствует.
4. Какое из следующих утверждений об использовании стеков для реализации очередей неверно ( )
О. При использовании моделирования стека для реализации очереди можно использовать два стека: один стек имитирует вход в очередь, а другой стек имитирует выход из очереди.
Б. Каждый раз, когда вы удаляете из очереди, вам необходимо импортировать все элементы из одного стека в другой стек, а затем извлечь его.
C. При входе в очередь просто сохраняйте элементы непосредственно в стеке, который имитирует вход в очередь.
D. Временная сложность операции с очередью равна O(1).
правильный ответ: Б
В варианте B один стек имитирует вход в очередь, а другой стек имитирует удаление из очереди. При удалении из очереди верхний элемент стека имитируемого удаления из очереди непосредственно выскакивает. Когда стек пуст, все элементы стека имитируемой очереди импортируются. Приходится каждый раз импортировать элементы, так что это неправильно.
В варианте А характеристики стеков и очередей противоположны. Стек не может реализовать очередь.
В варианте С один стек имитирует вход в очередь, а другой стек имитирует выход из очереди. При входе в очередь элементы сохраняются непосредственно в стеке, имитирующем вход в очередь.
В варианте D организация очереди означает помещение элементов в стек, поэтому временная сложность равна O(1).
Сегодня мы узнали о структуре данных стека. Разве это не намного проще, чем связанный список? Ха-ха-ха-ха, надеюсь, эта статья будет полезна моим друзьям!
очень прошуСтавьте лайк, ставьте лайк и подписывайтесь!!!
Спасибо вам всем! ! !


Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com