2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Hi guys! Today we are going to learn about the stack data structure! Are you ready? Let’s get started!

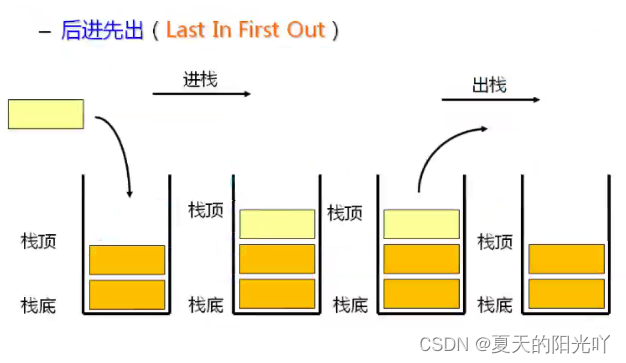
Stack: A special linear table that allows insertion and deletion operations only at one fixed end. The end where data is inserted and deleted is called the top of the stack, and the other end is called the bottom of the stack. The data elements in the stack followLIFO(Last In First Out) principle. We can imagine it as eating kebabs.Wear it firstThe mutton pieces are pressedBottom,the last oneLamb chunks areOn the topof.

Push: The insertion operation of the stack is called push/push/pull.Insert data from the top of the stack。
Pop: The deletion operation of the stack is called pop.The output data is also at the top of the stack。
The stack can generally be implemented by using an array or a linked list. Whichever is better, useArray StructureImplementing stack is easier and more efficient.
Because in the previous implementation of the sequence table add, delete, modify and query interface (Sequence table of data structure) It is very convenient for us to use the array structure to insert and delete the tail, so in the implementation of the stack, we define the tail of the array as the top of the stack and the head as the bottom of the stack.
Like sequence lists, stacks can be designed as static stacks with fixed length or dynamically growing stacks. Because fixed-length stacks have great limitations and are not practical in practice, we mainly implement support forDynamically growing stack。
Similar to the previous sequential list/linked list interface implementation, we first create a header file "Stack.h" and two source files "Stack.c" and "Test.c", with the following specific functions:
| Stack.h | Definition of stack, reference to header file and declaration of interface function |
| Stack.c | Implementation of interface functions |
| Test.c | Test each function |
We will first show the complete code of "Stack.h". Don't forget to reference "Stack.h" in both source files.
- #pragma once //防止头文件被二次引用
- #include<stdio.h>
- #include<stdlib.h>
- #include<assert.h>
-
- typedef int ElemType; //如果要修改存储的数据类型可直接在此修改
- typedef struct Stack {
- ElemType* arr; //动态数组
- int top; //栈顶
- int capacity; //容量
- }Stack;
-
-
- void StackInit(Stack* ps);//初始化栈
-
- void StackPush(Stack* ps, ElemType x);//入栈
-
- void StackPop(Stack* ps);//出栈
-
- ElemType StackTop(Stack* ps);//获取栈顶元素
-
- int StackSize(Stack* ps);//获取栈中有效元素的个数
-
- int StackEmpty(Stack* ps);//检测栈是否为空,如果为空返回非零结果,如果不为空返回0
-
- void StackDestroy(Stack* ps);//销毁栈
The meaning of "top" is determined by the initial value, which will be explained in detail below. Next, we start to implement the interface.
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
For ease of understanding, we will roughly understand the top in the structure as the subscript of the array. If we initialize top to 0 when initializing the stack, there is no data in the stack at this time, and top points to the next position of the top data of the stack.

If we initialize top to -1, top will point to the location of the top data in the stack. It is better to initialize it to 0 here because it is convenient to add and delete elements.
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
Because stacks are different from sequential lists, they cannot be traversed and printed directly. Therefore, if we want to print the elements in the stack, we need to use the StackEmpty function and the StackPop function, which will be discussed later.
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
This is why the StackEmpty in the previous assertion needs to be addedLogical negation operatorThe reason is that if the stack is empty, StackEmpty returns true, and the inversion is false to prove that there are elements in the stack.
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
After all interfaces are completed, we test the code in Test.c:
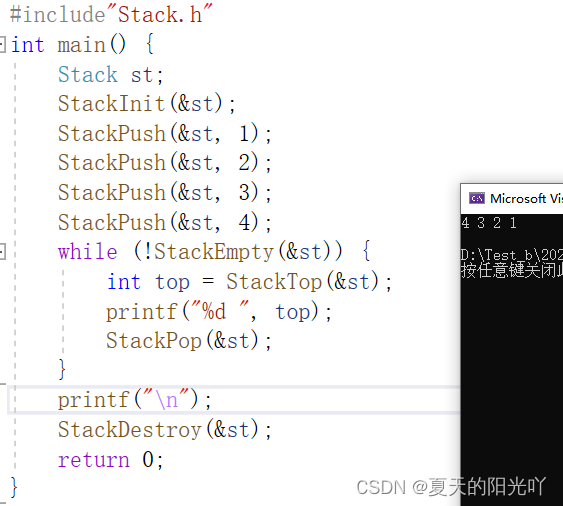
Let's test it a little more:
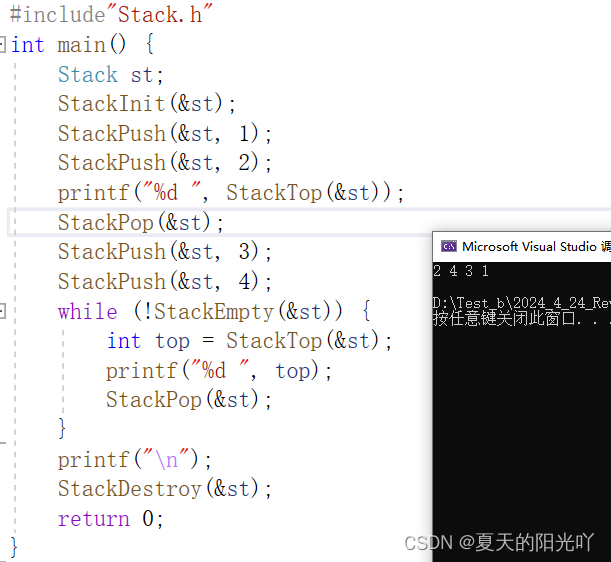
No problem at all, congratulations on completing the stack interface implementation! Here is the complete code of the "Stack.c" file:
- #include"Stack.h"
-
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
-
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
-
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
-
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
-
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
-
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
-
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
1. Which of the following statements about stack is correct? ( )
A. A stack is a "first in, first out" data structure
B. The stack can be implemented using a linked list or a sequential list
C. The stack can only insert data at the bottom of the stack
D. The stack cannot delete data
correct answer: B
A is wrong: a stack is a last-in-first-out data structure, while a queue is a first-in-first-out data structure.
B is correct: Both sequence lists and linked lists can be used to implement stacks, but sequence lists are generally used because stacks are like castrated sequence lists, which only use the tail insertion and tail deletion operations of sequence lists. The tail insertion and tail deletion of sequence lists do not require moving elements and are very efficient, so they are generally implemented using sequence lists.
C error: The stack can only be inserted and deleted at the top of the stack
D error: The stack has push and pop operations, and popping is to delete an element from the stack
2. The push sequence of a stack is ABCDE, then the impossible pop sequence is ( )
A.ABCDE
B.EDCBA
C.DCEBA
D.ECDBA
correct answer: D
If E is popped out first, it means that ABCDE have all been pushed into the stack. After E is popped out, the top element of the stack is D. If another element is to be popped out, it should be D, not C.
So you should choose D
3. Compared with the sequential stack, the obvious advantage of the link stack is ( )
A. Insertion operation is more convenient
B. Deletion operation is more convenient
C. No need to expand capacity when entering the stack
correct answer: C
A is wrong. If it is a linked stack, it generally needs to perform head insertion or head deletion operations, while a sequential stack generally performs tail insertion and tail deletion operations. The operation of a linked list is more complicated than that of a sequential list, so it is simpler to use a sequential structure to implement a stack.
B is wrong, please refer to A for the reason
C is correct. When a stack is implemented with a linked structure, each push into the stack is equivalent to inserting a node at the head of the linked list. There is no such thing as expansion.
4. Which of the following statements about using stacks to implement queues is wrong? ( )
A. To use stack simulation to implement queues, you can use two stacks, one stack to simulate the queue entry and one stack to simulate the queue exit.
B. Each time you dequeue, you need to import all the elements in one stack into another stack, and then pop the stack.
C. When entering the queue, just store the element directly in the stack that simulates the queue.
D. The time complexity of the queue entry operation is O(1)
correct answer: B
In option B, one stack simulates queue entry and one stack simulates queue exit. When exiting the queue, the top element of the simulated queue exit stack is directly popped out. When the stack is empty, all elements in the simulated queue entry stack are imported. It is not necessary to import elements every time, so it is wrong.
In option A, the characteristics of a stack and a queue are opposite, and a stack cannot implement a queue.
In option C, one stack simulates queue entry and one stack simulates queue exit. When queue entry, the element is directly stored in the stack simulating queue entry.
In option D, enqueueing means putting the element into the stack, so the time complexity is O(1)
Today we learned about the stack data structure. Isn't it much simpler than a linked list? Hahahahaha, I hope this article will be helpful to you! ! !
begLike, collect and follow!!!
thank you all! ! !


I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.

