
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
こんにちは!皆さん、今日はスタックのデータ構造を学びましょう!

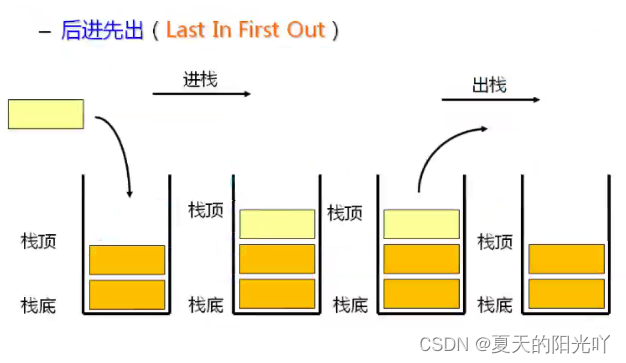
スタック: 固定端での挿入および削除操作のみを許可する特殊な線形リスト。データの挿入および削除操作を開始する端をスタックの最上位と呼び、もう一方の端をスタックの最下位と呼びます。スタック内のデータ要素は以下に準拠します。LIFO (後入れ先出し) 原則。マトンケバブを食べるようなものだと想像できますが、まずは履いてください羊肉が圧入されています底,最後のもの羊肉が入っています頂上での。

スタックのプッシュ: スタックの挿入操作は、プッシュ/プッシュ/プッシュと呼ばれます。スタックの先頭からデータを挿入。
ポップ: スタックの削除操作はポップと呼ばれます。送信データもスタックの最上位にあります。
スタックは通常、配列を使用してスタックを実装するか、リンク リストを使用してスタックを実装するか、どちらか適切な方を使用して実装できます。配列構造スタックの実装はより簡単かつ効率的です。
なぜなら、以前のシーケンステーブルの追加、削除、変更、クエリインターフェイスの実装では(データ構造シーケンステーブル) 配列の構造を使用して末尾から挿入したり削除したりするのは非常に便利なので、スタックの実装では、配列の末尾をスタックの先頭、先頭をスタックの末尾として定義します。スタック。
スタックは、シーケンス リストと同様に、固定長の静的スタックまたは動的に成長するスタックとして設計できます。固定長スタックには大きな制限があり、実際には実用的ではないため、主にサポートを実装します。動的に成長するスタック。
前のシーケンス リスト/リンク リスト インターフェイスの実装と同様に、最初にヘッダー ファイル「Stack.h」と 2 つのソース ファイル「Stack.c」および「Test.c」を作成します。具体的な関数は次のとおりです。
| スタック.h | スタック定義、ヘッダーファイル参照、インターフェース関数宣言 |
| スタック.c | インターフェース機能の実装 |
| テスト.c | 各機能をテストする |
まず「Stack.h」の完全なコードを示します。2 つのソース ファイルで「Stack.h」を引用符で囲むことを忘れないでください。
- #pragma once //防止头文件被二次引用
- #include<stdio.h>
- #include<stdlib.h>
- #include<assert.h>
-
- typedef int ElemType; //如果要修改存储的数据类型可直接在此修改
- typedef struct Stack {
- ElemType* arr; //动态数组
- int top; //栈顶
- int capacity; //容量
- }Stack;
-
-
- void StackInit(Stack* ps);//初始化栈
-
- void StackPush(Stack* ps, ElemType x);//入栈
-
- void StackPop(Stack* ps);//出栈
-
- ElemType StackTop(Stack* ps);//获取栈顶元素
-
- int StackSize(Stack* ps);//获取栈中有效元素的个数
-
- int StackEmpty(Stack* ps);//检测栈是否为空,如果为空返回非零结果,如果不为空返回0
-
- void StackDestroy(Stack* ps);//销毁栈
このうち「top」の意味は初期値によって決まりますが、これについては後で詳しく説明します。次にインターフェースの実装を開始します。
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
理解を容易にするために、構造内の top を配列の添字として近似的に理解します。スタックを初期化するときに top を 0 に初期化すると、スタックにはデータがなく、top はスタック上の先頭データの次の位置を指します。

top を -1 に初期化すると、top はスタック上の最上位データの位置を指します。要素の追加や削除に便利なので、ここでは 0 に初期化しておいた方がよいでしょう。
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
スタックとシーケンステーブルには違いがあるため、直接走査して出力することはできません。そのため、スタック内の要素を出力したい場合は、後述する StackEmpty 関数と StackPop 関数を使用する必要があります。 。
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
これが、前のアサーションの StackEmpty を追加する必要がある理由です。論理否定演算子その理由は、スタックが空の場合、StackEmpty は true を返し、false の否定によってスタック内に要素が存在することを証明できるためです。
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
すべてのインターフェイスが完了したら、Test.c でコードをテストしてみましょう。
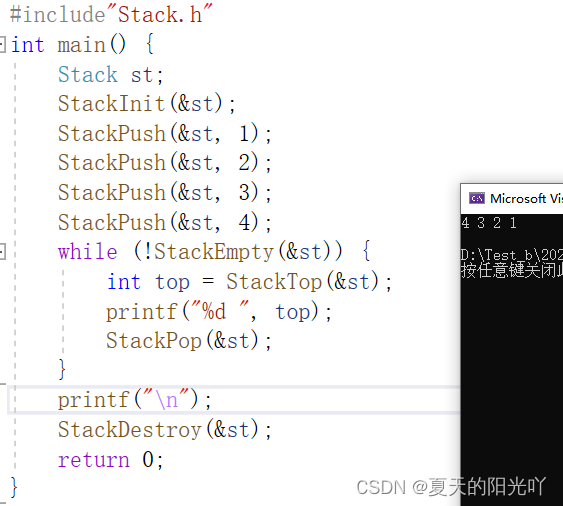
さらにテストしてみましょう:
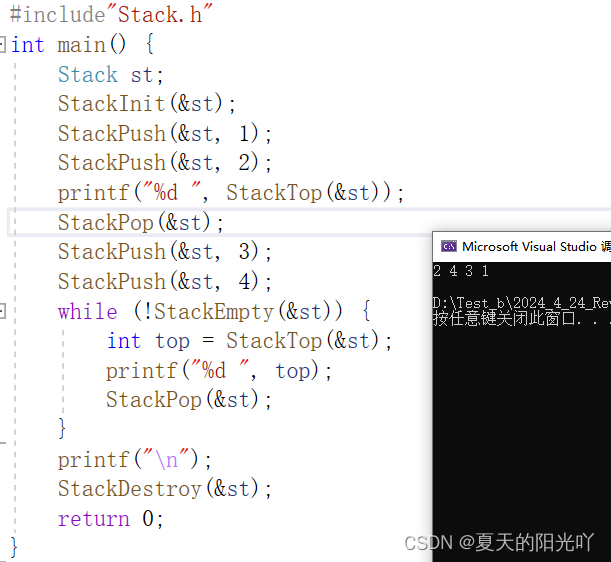
まったく問題ありません。おめでとうございます。スタック インターフェイスの実装は次のとおりです。「Stack.c」ファイルの完全なコードは次のとおりです。
- #include"Stack.h"
-
- //初始化栈
- void StackInit(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- ps->arr = NULL; //初始化数组,置空
- ps->capacity = 0;//top指向栈顶元素的下一个位置
- ps->top = 0; //初始化容量
- }
-
- //入栈
- void StackPush(Stack* ps, ElemType x) {
- //扩容
- if (ps->capacity == ps->top) //容量已满,需要扩容
- {
- //如果容量为0,则扩容到4; 否则扩大2倍
- int newCapacity = ps->capacity == 0 ? 4 : 2 * (ps->capacity);
- //创建一个临时指针变量来存储新空间地址,防止开辟失败
- ElemType* temp = realloc(ps->arr, newCapacity * sizeof(ElemType));
- if (temp == NULL) //防止开辟失败出现空指针
- {
- perror("realloc fail!n");
- exit(1);
- }
- ps->arr = temp; //将临时指针变量中存放的新空间地址赋给arr
- ps->capacity = newCapacity;//空间容量更新
- }
- ps->arr[ps->top] = x;//将数据存放进栈顶元素的下一个位置
- ps->top++;//位置更新
- }
-
- //出栈
- void StackPop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈中没有元素,却还在执行删除
- ps->top--; //top指针往前挪动一位(相当于这个位置被覆盖了)
- }
-
- //获取栈顶元素
- ElemType StackTop(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- assert(ps->top); //断言,防止栈为空
- return ps->arr[ps->top - 1];//top-1为栈顶元素的位置,返回其值
- }
-
- //获取栈中有效元素的个数
- int StackSize(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top; //top即为有效元素的个数
- }
-
- //检测栈是否为空,如果为空返回非零结果,如果不为空返回0
- int StackEmpty(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- return ps->top == 0; //如果top==0, 说明栈为空
- }
-
- //销毁栈
- void StackDestroy(Stack* ps) {
- assert(ps); //断言,防止传入空指针
- if (ps->arr) //如果动态数组有效
- {
- free(ps->arr); //释放arr
- ps->arr = NULL; //将arr置空
- }
- ps->capacity = 0; //数组的容量为0
- ps->top = 0; //数组的栈顶top为0
-
- }
1. スタックに関する次の記述のうち正しいものはどれですか ( )
A. スタックは「先入れ先出し」のデータ構造です。
B. スタックはリンク リストまたはシーケンス リストを使用して実装できます。
C. スタックはスタックの一番下にのみデータを挿入できます。
D. スタックはデータを削除できません
正解: B
エラー A: スタックは後入れ先出しのデータ構造であり、キューは先入れ先出しです。
B は正解です。スタックの実装にはシーケンス リストとリンク リストの両方を使用できますが、スタックはシーケンス リストの去勢されたバージョンとみなされ、シーケンス テーブルの末尾挿入および末尾削除操作のみが実行されるため、一般的にシーケンス リストが使用されます。末尾削除と末尾削除は要素の移動を必要とせず、非常に効率的であるため、一般に順序テーブルを使用して実装されます。
C エラー: スタックはスタックの最上位でのみ入力の挿入および削除操作を実行できます。
D エラー: スタックにはプッシュ操作とポップ操作があります。ポップとはスタックから要素を削除することです。
2. スタックのプッシュシーケンスは ABCDE、不可能なポップシーケンスは ( )
A.ABCDE
B.EDCBA
C.DCEBA
D.ECDBA
正解: だ
E が最初に飛び出した場合、ABCDE がすべてスタックにプッシュされたことを意味します。E がスタックから飛び出した後、スタックの最上位要素は D になります。再度飛び出した場合は、C ではなく D になるはずです。 。
したがって、D を選択する必要があります。
3. シーケンシャル スタックと比較して、チェーン スタックの明らかな利点は次のとおりです ( )
A. 挿入操作がより便利になりました
B. 削除操作がより便利になりました
C. スタックにプッシュするときに拡張は必要ありません
正解: C
エラー A. リンク スタックの場合、通常は先頭の挿入または先頭の削除操作が必要ですが、順次スタックの場合は通常、末尾の挿入と末尾の削除操作が実行されます。リンク リストの操作は順次テーブルよりも複雑であるため、シーケンシャル構造を使用してスタックを実装する方が簡単です。
B は間違っています。理由については A を参照してください。
C は正解です。スタックがチェーン構造で実装されている場合、スタックへの各プッシュは、リンクされたリストの先頭にノードを挿入することと同じです。展開は行われません。
4. スタックを使用してキューを実装することに関する次の記述のうち、間違っているものはどれですか ( )
A. スタック シミュレーションを使用してキューを実装すると、2 つのスタックを使用できます。1 つのスタックはキューに入るシミュレーション、もう 1 つのスタックはキューから出るシミュレーションです。
B. デキューするたびに、あるスタック内のすべての要素を別のスタックにインポートしてからポップアウトする必要があります。
C. キューに入るときは、キューに入るのをシミュレートするスタックに要素を直接格納するだけです。
D. キュー操作の時間計算量は O(1) です
正解: B
オプション B では、1 つのスタックがキューへの入力をシミュレートし、もう 1 つのスタックがデキューをシミュレートします。スタックが空の場合、シミュレートされたデキュー スタックの最上位要素が直接ポップアップされます。要素は毎回インポートする必要があるため、エラーになります。
オプション A では、スタックとキューの特性が逆になります。スタックはキューを実装できません。
オプション C では、1 つのスタックがキューに入るのをシミュレートし、1 つのスタックがキューから出るをシミュレートします。キューに入るとき、要素はキューに入るのをシミュレートするスタックに直接格納されます。
オプション D では、キューイングとは要素をスタックに置くことを意味するため、時間計算量は O(1) になります。
今日はスタックのデータ構造について学びました。リンクされたリストよりもはるかに単純ではないでしょうか。はははは、この記事が友達に役立つことを願っています。
懇願するいいね、お気に入り、フォローしてください!
皆さん、ありがとうございました! ! !


彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: